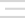
Conducting an SEO Content Audit: 6 Things You Might Be Overlooking
Tory Gray & Tyler Tafelsky
Posted 15 November, 2021 by Tory Gray & Tyler Tafelsky in SEO
Conducting an SEO Content Audit: 6 Things You Might Be Overlooking
Table of Contents
- What’s an SEO Content Audit?
- What Should I Look For in a Content Audit?
- 1. Ensure Content Is Being Fully Accessed and Rendered (Hello, JavaScript SEO)
- 2. Audit Core Web Vitals and Optimize for Page Speed
- 3. Audit Index Bloat and Keyword Redundancies, and Prune Mindfully
- 4. Determine (And Improve) Pages Where You’re Losing Users
- 5. Leverage Content Gaps Inspired by Competitors and Keyword Data
- 6. Consider non-SEO Segments and Overall Conversion Value
- Embarking on Your SEO Content Audit
The process of conducting an SEO content audit can take many shapes. It can be an interpretive review of a site’s top organic landing pages. Or it can take the form of a data-driven inventory that documents an entire site’s URLs.
There are many ways to assess content through an SEO lens. But the overarching purpose is generally unified – to pinpoint disruptive bottlenecks and uncover new opportunities that can effectively grow search (and brand) visibility.
This article is a guest contribution from Tory Gray and Tyler Tafelsky.
What’s an SEO Content Audit? And What’s the Point?
In a general sense, an SEO content audit is an actionable inventory of indexable content that’s organized in ways to better determine what to consolidate (or remove!), what to improve upon, and what to leave as-is.
In many cases, a specific intention is set to find duplicate content, cannibalization issues, index bloat, or mysterious problems – like persistent layout shifts or JavaScript SEO issues. In other cases, it can be a broader exercise in identifying untapped ideas and new topics to help grow a site’s online footprint.
The art of performing an SEO content audit is a balance between both the right and left brain. Depending on the project, the process involves a combination of perspectives, tools, and procedures to methodically peel the onion on the many layers that impact SEO.
The underlying point of employing a regular content audit (especially for large websites) is to investigate issues that may be “slowing its SEO roll”. The fact is, you could be producing the most engaging and valued content, but it may struggle to rank if there are technical disruptions holding it back. And that’s what a majority of this post seeks to outline.
Alternatively, an external analysis of search trends, predictions, keyword data, and competitor strategies can inspire new opportunities to further grow and differentiate. While not directly focused on the site itself, these off-site insights can be of tremendous use for SEO content creation.
What Should I Look For in a Content Audit?
There’s no shortage of step-by-step, how-to guides on how to perform a content audit with SEO in mind. No doubt, they’re useful resources for those getting started, especially learning the basics like what metrics to include in a crawl report, how to organize your spreadsheets, and how to identify duplicate or redundant content.
Many great posts teach these systematic fundamentals and what you should look for when performing a content audit. But most guides of this type leave out advanced technical SEO issues and high-level strategic perspectives.
With that in mind, this post seeks to broaden your horizons by highlighting specific matters that often get overlooked when SEO-auditing a site’s content.
So let’s dive into the good stuff!
1. Ensure Content Is Being Fully Accessed and Rendered (Hello, JavaScript SEO)
As web content has evolved from static HTML pages to interactive graphics, videos, and more dynamic forms, the programming languages to support such elements have also evolved. Among the most powerful and popular of those languages is JavaScript.
JavaScript can power many forms of content, ranging from collapsible accordions and product sliders to animations and dynamic navigations, to name just a few. While JavaScript provides tremendous versatility in delivering rich and engaging content, it can also come with a fair share of limitations and challenges for SEO.
Unlike simple web content that search engine crawlers like Googlebot can easily crawl and index, the issue with more advanced JavaScript-driven content is that it can be difficult and potentially time/resource-intensive to process, especially if a site relies on client-side rendering in the browser versus server-side rendering or pre-rendering.
The problem is that Googlebot isn’t always going to do the heavy lifting to process JavaScript content. As a result, it’s important to proactively audit for JavaScript errors and accessibility issues to ensure your site’s content is being fully rendered and indexed.
There are a couple of underlying issues worth investigating to ensure JavaScript sites retain and maximize the SEO potential of their content. Thanks to ground-breaking advancements with its SEO Spider software, Screaming Frog now makes it easy to crawl JavaScript rendered content and audit these potential issues.
Can Search Engines Discover All Content on Your Pages?
One of the most common JavaScript issues is when search engine bots are unable to identify and crawl critical content on your pages. This can result from general coding mistakes or because the content is not made readily available for rendering and indexation.
To audit this, it’s important to be able to view the rendered DOM after JavaScript has been executed to pinpoint discrepancies to the original response HTML. Essentially, we’re evaluating differences in the raw HTML with that of the rendered HTML – and the visible content on the page.
While there are a few ways to do this, SEO Spider can streamline the comparison process by enabling you to view the original HTML and rendered HTML when using JavaScript.
Within the tool, you can set this up by clicking into Configuration > Spider > Extraction and selecting the appropriate options to both “store HTML” and “store rendered HTML”.

In the View Source pane, this will display the original source HTML and the rendered HTML side-by-side, allowing you to compare differences and assess whether or not critical content and links are actually interpreted in the rendered DOM. The check box to Show Differences above the original HTML window makes this comparison process even more efficient.

This feature is extremely helpful, not only for SEO content audits but a number of debugging scenarios. What’s nice about the SEO Spider tool is that you can also choose to store and crawl JavaScript files independently. When this filter has been activated, you can switch the ‘HTML’ filter to ‘Visible Content’ to identify exactly which text content is only in the rendered HTML.
Are URL Accessibility Issues Present on the Site?
Another common JavaScript-related issue – which is typically more straightforward and easier to troubleshoot – is found within your site’s URLs.
By default, many JavaScript frameworks do not generate unique URLs that can be accessed individually, which is especially the case with single-page applications (SPAs) and certain web apps. Rather, the contents of a page change dynamically for the user and the URL remains exactly the same.
As you can imagine, when search engines can’t access all of the URLs on a site, it creates a lot of problems for SEO. To check if your URLs are available and indexable, use Screaming Frog to crawl the site, and assemble a dashboard of URLs and the data associated with them.

This simple process will let you know which URLs are in fact indexable, which are not, and why that’s the case.
If you have certain URLs on your site that should be indexed but aren’t being found, there are problems that need to be addressed. Some of the most common issues to consider are pages:
- with blocked resources
- that contain a noindex
- that contain a nofollow
- that contain a different canonical link
- redirects being handled at a page level instead of at the server request
- that utilize a fragment URL (or hash URL)
SEO Spider’s JavaScript tab is equipped with 15 different filters that highlight common JavaScript issues, making it easier to find disruptive accessibility problems hindering SEO performance.
2. Audit Core Web Vitals and Optimize for Page Speed
While SEO and user behaviour metrics are most commonly used when conducting a content audit, you can potentially move the needle by bringing Core Web Vitals into the mix.
While a fast website won’t make up for low-quality content that doesn’t meet the needs of real users, optimizing for page speed can be a differentiator that helps you edge ahead in the “competitive race” that is SEO.
Simply put, these metrics are designed to measure both page speed and user experience variables. The primary three Core Web Vitals include:
- Largest Contentful Paint (LCP) – measures the time it takes for the primary content on a page to become visible to users. Google recommends an LCP of fewer than 2.5 seconds.
- First Input Delay (FID) – measures a page’s response time when a user can interact with the page, such as clicking a link or interacting with JavaScript elements. Google recommends an FID of 100 milliseconds or less.
- Cumulative Layout Shift (CLS) – measures the number of layout shifts that reposition a page’s primary, which ultimately affects a user’s ability to engage with content. Google recommends a CLS score of 0.1 or less.
Since Google has added Core Web Vitals to its search algorithm, it has become more widely known that improving LCP, FID, and CLS can positively affect a page’s SEO potential.
Measuring Core Web Vitals
It’s now easy to measure Core Web Vitals through several commonly used tools. The foundational tool is the Chrome User Experience Report, which collects real user data and shares it via tools like PageSpeed Insights and Google Search Console.
- Within Google Search Console, the Core Web Vitals feature utilizes the data collected from the Chrome User Experience Report to reveal any issues throughout your website.
- PageSpeed Insights, which can be used as a standalone audit tool, analyses the performance of your pages and makes suggestions on how to improve, both on mobile and desktop browsers. The field data refers to the actual user data pulled from the Chrome User Experience Report.
- The Chrome Web Vitals Extension is a handy way to see Core Web Vitals while browsing the web or making changes to your site. Not only is this extension great for internal audits, but it can be quite useful in measuring up against your competitors.
Each of these tools enables you to effectively measure LCP, FID, and CLS for a site, which in turn can lead to actionable improvements. Google also shares a collection of tools and workflow considerations to measure and improve Core Web Vitals at Web.Dev.
3. Audit Index Bloat and Keyword Redundancies, and Prune Mindfully
Pages that have low-quality content, duplicate content, cannibalizing content, or no content pages should be kept out of the search results. These low-value pages contribute to wasted crawl budget, keyword dilution, and index bloat. As such, auditing index bloat is a powerful exercise that’s intended to correct this very problem.
What Causes Index Bloat?
In simple terms, index bloat is when a site has too many URLs being indexed – that likely shouldn’t be indexed. This occurs when search engines find and index a considerable excess of URLs – more than what’s desired or specified in the sitemap. It’s a particularly common scenario with very large websites, such as eComm stores with thousands of pages.
Most often, index bloat is an ominous occurrence that stems from:
- Dynamically generated URLs (unique and indexable pages created by functions like filters, search results, pagination, tracking parameters, categorization, or tagging)
- User-generated content (UGC)
- Coding mistakes (e.g broken URL paths in a site’s footer)
- Subdomains (thin or non-search value pages on domains you accidentally aren’t paying attention to.
Orphan pages are also a common source of index bloat worth investigating. These are pages that exist but aren’t being linked to on the site in a crawl. That doesn’t necessarily mean they’re low-quality pages, but that they’re not easily accessible and have no internal links pointing to them.
The SEO Spider makes it easy to identify orphan pages and review them as part of a comprehensive SEO content audit. While some of these URLs may be worthy of keeping and restoring (building internal links to), in many cases, they can add bloat and should be pruned.
Lastly, the more mistakenly intentional form of index bloat occurs when a site has too many pages covering the same topic or keyword theme (e.g. the classic SEO mistake of pumping out blog posts targeting the same keyword). Such content overlap and keyword redundancy dilutes SEO by confusing search engines as to which URL to prioritize ranking.
How to Identify Index Bloat
There are a few different techniques we like to use to identify index bloat in all of its forms. For deep websites showing signs of significant bloat, we recommend a combination of the first techniques mentioned below, as these practices are more comprehensive and thorough.
Do a Cannibalisation Analysis
If you have more than one page aiming to rank for the same keyword (on purpose or accidentally), you may encounter cannibalization issues. Cannibalization issues aren’t inherently bad; for example, if you are able to rank in positions 1 & 2, or 2 & 3, for the same keyword, that’s a GREAT result.
But in many cases, your content ends up competing against itself, and suddenly you are ranking on page 3 and 5 with little to no organic visibility.
Pull data on potential cannibalization issues, identity which might be problematic, and put together a plan to either:
- Update one page’s content (and internal anchor links) so it’s no longer competing
- Retire and redirect the lower performing pages.
- Consolidate the pages into one, leveraging the best content from both to cover the subject matter better and more comprehensively. Use the better performing URL (if possible), and redirect the other to the new page.
Compare Index Coverage With Sitemaps in Google Search Console
First, pin down exactly what property you’re investigating in Google Search Console. This could involve auditing the HTTPS vs HTTP properties of a domain, including any additional subdomain variations. Alternatively, it’s often easier to pull data from one Domain property and access URLs across all associated subdomains.
This distinction is important, especially for sites that use subdomains. All too often SEOs overlook subdomain-induced index bloat purely because it’s a different property than the ‘main’ site they’re focusing on. Out of sight and out of mind, the result can leave substantial bloat on the table.
Whether you’re cross-auditing different properties or using one Domain property (the preferred method) the next step is to get your XML sitemap right. This should hinge on the sitemap page that includes links to pages you value the most and seek to index. But with XML sitemaps, that’s not always the case.
Sometimes a cursory glance at the XML sitemap unveil obvious signs of index bloat, like unwanted tag pages and pagination URLs. This can especially be the case with sites on platforms that automatically generate XML sitemaps in a disorganized, lackadaisical fashion. Ultimately you don’t want to submit a bloated XML sitemap to Google Search Console.
Google Search Console itself offers helpful tools to help you identify and clean up index bloat. Under the Index option, you can use the Coverage feature to see “All known pages” that Google has indexed.
While this tool is generally used to pinpoint pages with error and warning statuses by default (e.g. submitted pages that are broken), you can view all valid pages that Google is picking up as indexable.
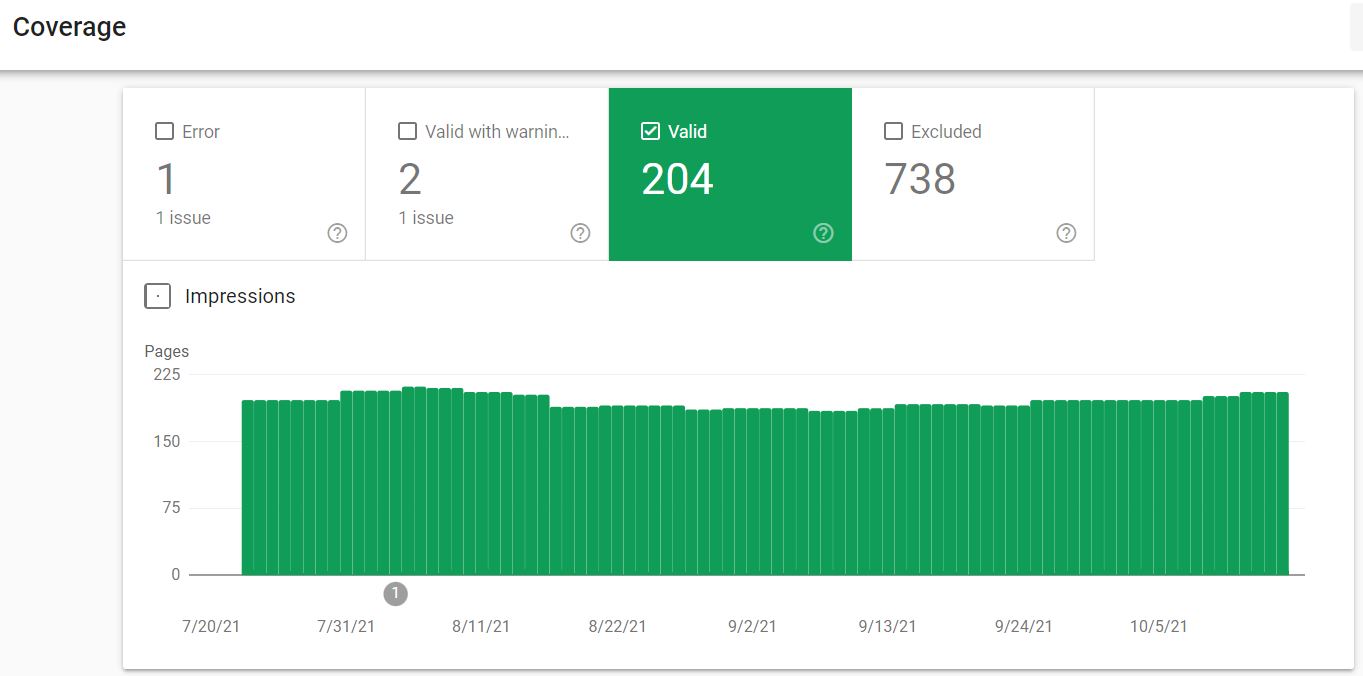
The true insights from this report are found just below the graph under Details, specifically under valid pages that are “Indexed, not submitted in sitemap.” These URLs are not specified in the sitemap but are still being discovered and indexed by Google, making them worth auditing for potential index bloat issues.
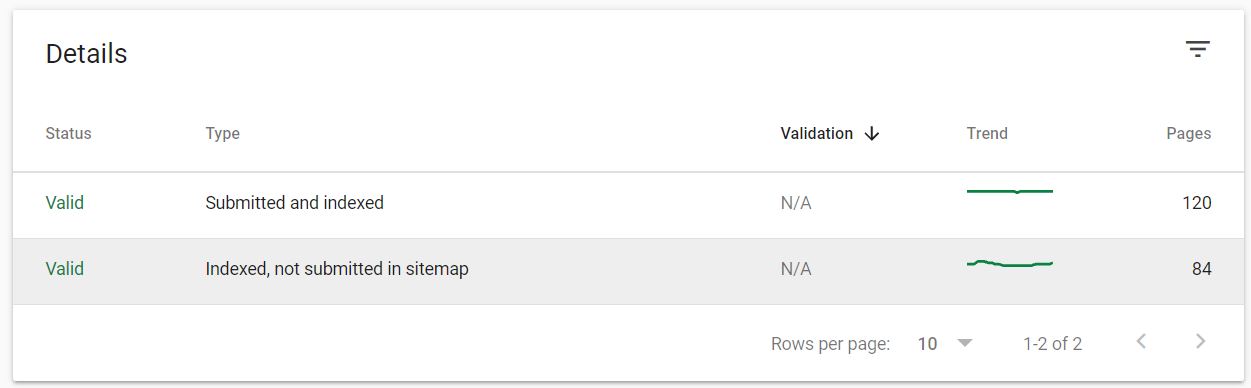
Using these reporting tools in Google Search Console are handy for this audit process, but they do come with limitations. For instance, the list of URLs in the report is based on the last crawl, which may not be the most up-to-date. Additionally, the report is limited to a maximum of 1,000 URLs, so this approach alone may not suffice for very large sites with considerable bloat.
Run a Crawl Report with SEO Spider
Another more comprehensive way to audit index bloat is to run a crawl report using SEO Spider along with API data (‘Configuration > API Access’) from Google Analytics and Search Console. This will enable you to see URLs from these tools that might not be accessible via a crawl, and whether or not they’re indexable.
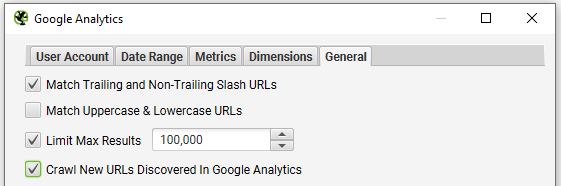
After running the crawl, export the Internal HTML report into a spreadsheet and extract all URLs that are not indexable into a separate sheet. This provides you with a holistic view of all pages that can be discovered and indexed.
Next, by crawling and/or organizing all URLs listed in the XML sitemap, you can compare these two lists to filter and determine any outliers that should not be discoverable nor indexed, and are otherwise adding bloat to the site. This slightly more manual approach works great in identifying URLs that should be removed, redirected, or attributed with noindex, nofollow, or canonical tags.
This approach, combined with using a Domain property as the Google Search Console property, provides a complete look into all potential index bloat that may be hindering a site’s SEO performance.
Leverage Crawl Analysis to Filter Relevant URL Data
Screaming Frog has streamlined this process with its Crawl Analysis feature, which enables you to leverage certain filters post-crawl that are invaluable for the auditing process. When integrated with the Google Analytics or Google Search Console API, Crawl Analysis offers crucial insights when matching a site’s crawl data against the URLs on these platforms, particularly the “Indexed, not submitted in sitemap” report.
At the end of a crawl (or when a crawl has been paused), click into Crawl Analysis > Configure to activate certain data points of interest. In this case, Sitemaps and Content are the most useful when troubleshooting index bloat, however, all of these options have merit when conducting an SEO content audit.
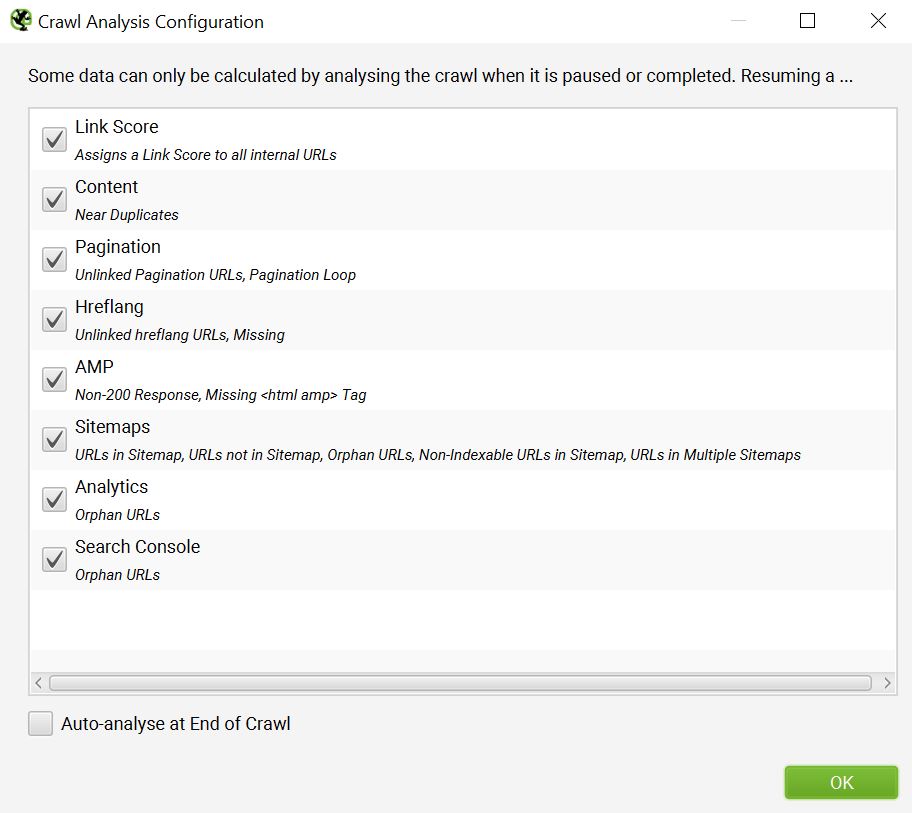
Once the desired data points have been selected, you’ll need to start the actual Crawl Analysis to gather data for these filters. You can also tick the checkbox to “Auto-analyse at End of Crawl” to have this done automatically.

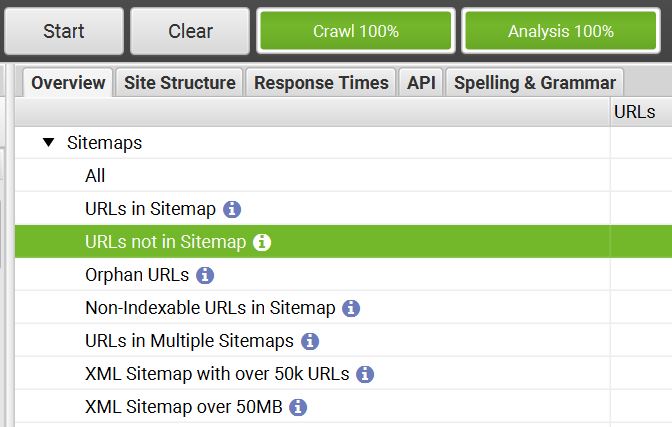
When the Crawl Analysis has been completed, the insightful data you’re looking for will be available and filterable from the right-hand ‘overview’ window pane. In the Sitemaps drop-down, you can filter to see data like:
- URLs in Sitemap
- URLs not in Sitemap (most useful for auditing unwanted index bloat)
- Non-indexable URLs in Sitemap
- Orphan pages
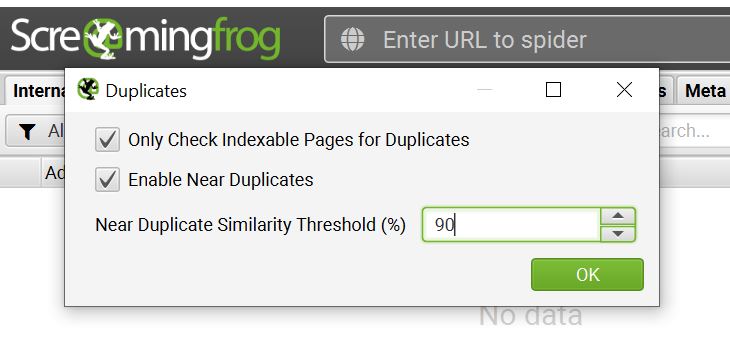
In addition to these data points, the Content filtering option can also help you find duplicate content or near-duplicates worth reviewing for keyword redundancies/dilution. SEO Spider’s configurations enable you to set the percentage of duplicate similarity threshold, an algorithm that’s designed to pinpoint similarities in page text.
By default, the threshold percentage is set at 90%, which is highly sensitive. For large websites, this can be a high percentage that requires significant auditing. Alternatively, you can adjust to a lower similarity threshold to help sort and find duplicates that may be more bloat-indicative and SEO-damaging.
Together, these features available in SEO Spider provide a comprehensive view into what URLs should and should not be indexed. This video provides a nice overview of the Crawl Analysis features that you can leverage.
Pruning Index Bloat and Problematic URLs
Once you’ve determined which URLs are in the category of index bloat, or appear redundant and/or duplicate in nature, the next step is to prune them. This where having an organized spreadsheet with relevant metrics, notes, and action items is very helpful.
Before removing all of them from the indexes all at once, it’s important to make a mindful assessment of these URLs and how to best handle how they should be pruned. For instance, some URLs might be earning organic traffic or backlinks. Removing them entirely (instead of 301 redirecting them) might result in losing all SEO value that could otherwise be retained and allocated to other pages.
Here are a few ways to assess the value of URLs, which can then help you determine how they should be pruned.
- Review organic metrics in Google Analytics, such as organic search traffic, conversions, user behaviour, and engagement to better gauge how much SEO value a URL has.
- Review All User segment metrics as well, so you don’t accidentally prune content that’s driving business value. More about this below.
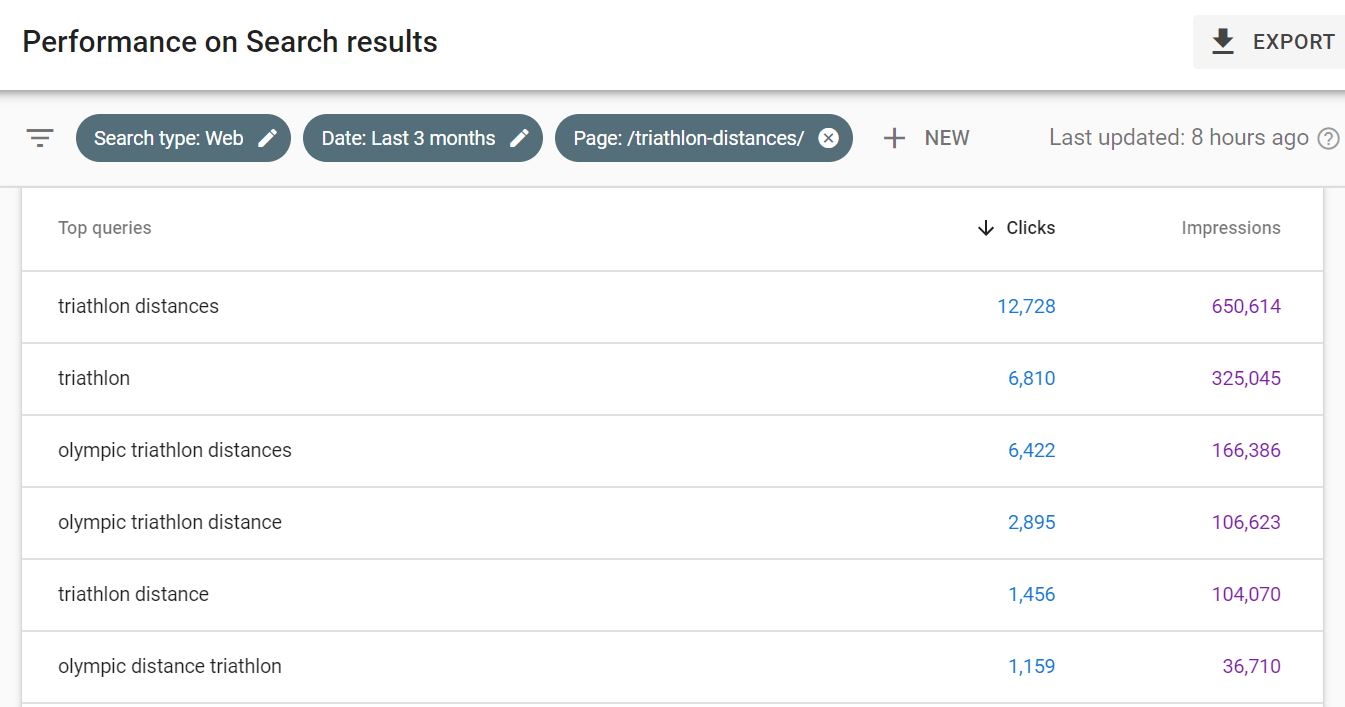
- In Google Search Console, use Performance > Search Results to see how certain pages perform across different queries. Near the top are filter options (Search type: Web and Date: Last 3 months will be activated by default; we prefer to review at least 12 months of data at a time to account for seasonality). Add a Page filter to show the search performance of specific URLs of interest. In addition to impressions and clicks from search, you can click into each URL to see if they rank for any specific queries.
- Use the Link Score metric (a value range of 1-100) from the SEO Spider Crawl Analysis. URLs that have a very low Link Score typically indicate a low-value page that could perhaps be pruned via redirect or noindex/removal.
- Additional tools like Ahrefs can help determine if a URL has any backlinks pointing to it. You can also utilize certain metrics that indicate how well a page performs organically, such as organic keywords and (estimated) organic traffic.
It helps to have some SEO experience and a keen eye during this evaluation process to effectively identify URLs that do contain some degree of value as well as others that are purely bloat. In any case, taking measures to prune, and prune mindfully, helps search engines cut through the clutter and prioritize the real content you want driving your SEO strategy,
The actual pruning process will more than likely involve a combination of these approaches, depending on the evaluation conducted above. For instance, a page with thin or duplicate content, but has a few high-quality will be pruned differently (e.g. 301 redirected) versus just a page with thin or duplicate content.
- Remove & Redirect – In most cases, the URLs you’d like to prune from index can be removed and redirected to the next most topically relevant URL you wish to prioritize for SEO. This is our preferred method for pruning index bloat, where historical SEO value can be appropriately allocated with the proper 301 redirect.
In cases when strategic business reasons take priority (and remove & redirect is not an option), the next best alternatives include:
- Meta Robots Tags – Depending on the nature of the page, you can set a URL as “noindex,nofollow” or “noindex,follow” using the meta robots tag.
- “Noindex,nofollow” prevents search engines from indexing as well as following any internal links on the page (commonly used for pages you want to be kept entirely private, like sponsored pages, PPC landing pages, or advertorials). You are also welcome to use “Noindex, follow” if preferred, but keep in mind that this follow will eventually be treated as a nofollow.
- Disallow via Robots.txt – In cases that involve tons of pages that need to be entirely omitted from crawling (e.g. complete URL paths, like all tag pages), the “disallow” function via Robots.txt file is the machete in your pruning toolkit. Using robots.txt prevents crawling, which is resourceful for larger sites in preserving crawl budget. But it’s critical to fix indexation issues FIRST and foremost (via removing URLs in Search Console, meta robots noindex tag, and other pruning methods).
- Canonicalization – Not recommended as an end-all solution to fixing index bloat, the canonical tag is a handy tool that tells search engines the target URL you wish to prioritize indexing. The canonical tag is especially vital to ensure proper indexation of pages that are similar or duplicative in nature, like syndicated content or redundant pages that are necessary to keep for business, UX, or other purposes.
These are the fundamental pruning options in a nutshell. Before deploying significant changes in removing/redirecting/blocking URLs, be sure to take a performance benchmark so that you can clearly see the impact once the index bloat has been pruned.
4. Determine (And Improve) Pages Where You’re Losing Users
A good auditor’s mindset is to embrace performance pitfalls and weaknesses as room for improvement. Identifying pages where users are exiting the site (without converting) is a great place to prioritize such opportunities.
Pinpointing pages with high exit rates is not synonymous with pages with high bounce rates, however many of the same improvements can apply to both. Unlike bounce rate which is specifically associated with the entrance pages (user leaves the site from the first page they enter on), exit rate indicates how often users exit from a page after visiting any number of pages on a site. Exit rate is calculated as a percentage (number of exits/number of pageviews).
Pinpointing Pages with High Exit Rates
In Google Analytics, you can view pages with high exit rates by navigating to Behavior > Site Content. Under All Pages, there’s a % Exit column that shows exit rate metrics for all pages of the site, as well as other general performance metrics. You can drill deeper via Behaviour > Site Content > Exit Pages which sorts pages by highest volume of exits and the associated exit rate for each page.
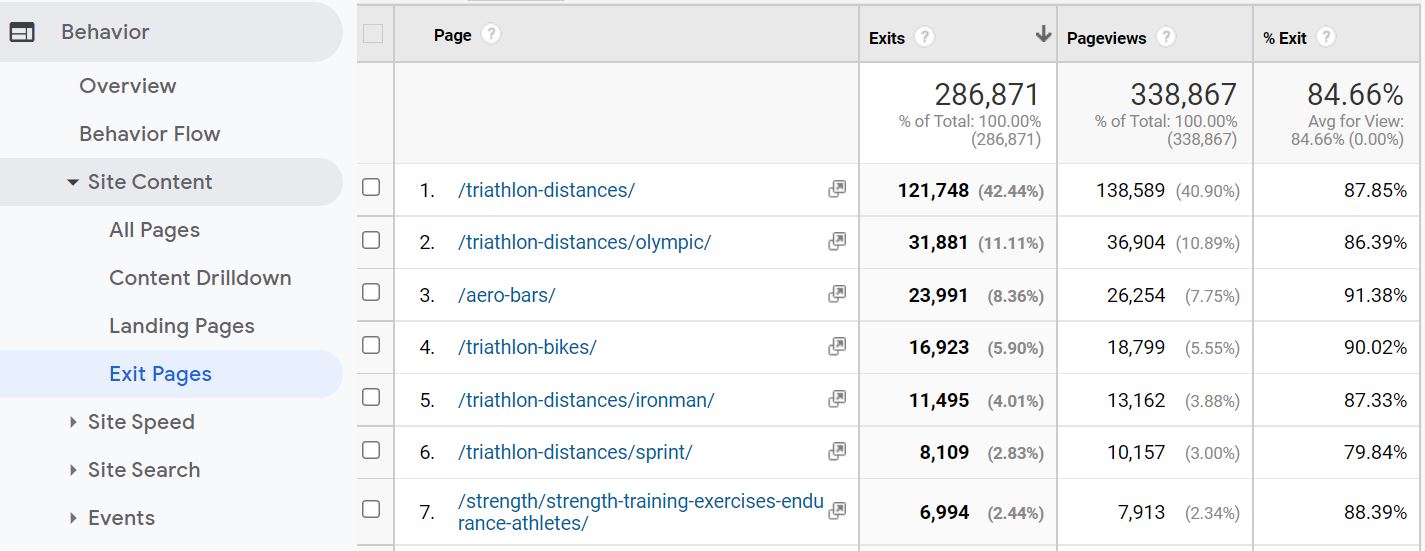
The Exit Pages report in Google Analytics is a great place to start in assessing which URLs users are dropping off the most. Keep in mind it’s best to set the date range of this report to include a significant sample size of data, such as the last 6-12 months.
Depending on the size of the site, you may want to export the data to include more than just the top ten URLs shown in the report by default. For instance, there may be several pages of importance that don’t quite have as high of a volume of exits but still have an enormously high exit rate worth troubleshooting.
How to Improve Exit Pages and Reduce Drop Offs
Finding pages with high exit rates is one thing. Implementing changes to reduce drop offs is another. While some problems might be obvious (slow loading pages, broken links, media not rendering, etc.) deciding where and how to improve content and user experience takes some investigation.
Here is a series of tips to help you reduce exit rates, improve engagement, and boost conversions:
- Enhance UX & Content Readability – Ensure your content is easy to digest by keeping organized and easy to navigate. Avoid lengthy paragraphs, complex sentences, and wording. Structure pages with table of contents, subheadings, lists, tables, images, and visual media whenever possible.
- Speed-up Slow Loading Pages – Slow page load times are a major contributor to high exit rates. In fact, over 50% of users abandon a site if it takes more than three seconds to load. Prioritizing page speed by improving Core Web Vitals, leveraging Accelerated Mobile Pages, optimizing images, minifying code, etc.
- Test Cross-Browser Compatibility – It’s critical to ensure that proper testing is done across all web browsers, especially when most users are using mobile devices, to ensure content renders appropriately without any technical issues. Pages with content formatting problems can result in immediate drop-offs.
- Propel the Next Step with CTA’s – One of the biggest reasons for users dropping off is failing to include calls to action to invoke the next step in the conversion funnel. Use graphics, buttons, and other obvious elements to grab the attention of users and compel desired action that you want them to take.
- Improve Internal Linking – Similar to CTAs, page copy should include internal links to other useful and related pages of a site. Not only is this SEO best practice, but it logically guides users to relevant content that they might be interested in, keeping them on the site longer while aiding conversion.
- Include Related Posts/Content – Either between paragraphs of copy or at the end of the page, another best practice to minimize exists is to include links to related content, such as blog posts, resources, and other pages that might be of interest to users. These typically work best when placed within the content naturally with thumbnails and span the width of the page.
- Avoid Intrusive Pop-ups & Too Many Ads – Pages that are riddled with intrusive pop-ups and/or too many banner ads are notorious for having high exit rates. When tastefully implementing pop-ups and ads can serve a good purpose, but in many cases, they can lead to a frustrating user experience when overdone.
For deeper investigations, it can be helpful to collect additional user behavior data and feedback with tools like session recordings, heatmaps, and on-site surveys. While these efforts can be more labour and resource-intensive, they can often yield valuable insights for improvement.
5. Leverage Content Gaps Inspired by Competitors and Keyword Data
A fundamental step in any SEO content audit is conducting a content gap analysis to identify untapped topics and new ideas for content. Some of the best insights can be found by analysing close competitors and scoping out what type of content they’re publishing (that you’re not).
We find it useful to support competitive content audits with good ole’ fashioned keyword analysis and research. Data validates the SEO potential of new ideas and helps guide the strategy. Together, these approaches can help you discover and leverage content gaps as new growth opportunities.
Peeling the Onion on Your Competitors’ SEO Content Strategies
While large sites like Amazon, eBay, and Wikipedia might be top-ranking SEO competitors, they probably won’t offer much insight for this exercise. Instead, target closely related competitors who are concentrated in your niche.
You can gain a lot of insight by manually auditing competitors’ sites to see what topics they’re covering and what strategies they’re using. It’s also worth delivering into the content of close competitors to see the effort and quality they’ve invested and how they’ve positioned themselves.
While your analytical eye is among the best of tools, it’s crucial to support your findings with tangible data. Using tools like SEMrush, Ahrefs, SpyFu, and Sistrix for content gap analysis is extraordinarily helpful in pulling the curtain on valuable gaps worth exploring.
What’s especially handy about some of these SEO tools is that they allow you to see your competitors’ top organic content, what keywords it ranks for, and other interesting metrics.

As you can imagine, it’s easy to go down a rabbit hole in more ways than one. Not only can you immerse yourself in a library of competitor content – from blogs and resources to core pages of a site’s hierarchy – but you can go off the rails exploring new keyword themes you may have never even considered.
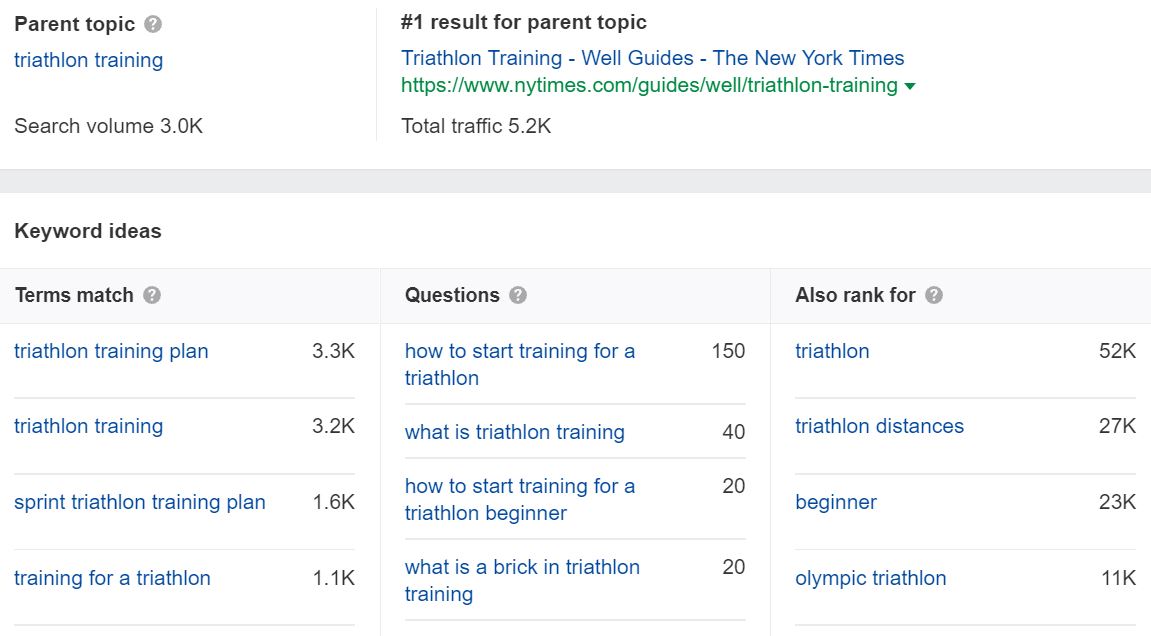
Scoping competitors is one of the best ways to find gaps in your existing SEO strategy. This approach also helps inspire new directions when conducting a keyword refresh or pulling data to back ideas.
Certainly having access to SEO tools like Ahrefs and Semrush helps peel the onion, as these tools provide unbeatable features when performing any type of SEO competitor analysis. But even a manual audit combined with cursory keyword research via Google Keyword Planner can be enough to guide your future SEO roadmap strategy.
6. Consider non-SEO Segments and Overall Conversion Value
When gathering data to support your audit and pruning process, it’s common best practice to pull and evaluate user data across different user segments, particularly when using the SEO Spider tool integrated with Google Analytics’ API.
It’s a natural mistake to prioritize only Organic user segment data when pulling this data. But that fact is, fixating on just Organic users likely means you’re overlooking important data from other channels/segments. Neglecting and writing off all value from non-SEO segments is a huge miss. Not only can these pages be mistakenly pruned and wastefully retired, but in most cases, the content on these pages goes neglected and unutilized.
As a more holistic alternative, use All Users as a separate segment and apply a VLOOKUP to get important metrics – like sessions, user behavior, and conversions – from BOTH segments. Cross-referencing more than just Organic segments into a single dashboard can help you avoid missed opportunities by discounting content that might have more value than expected (especially if certain pages do have content, links, and sessions.)
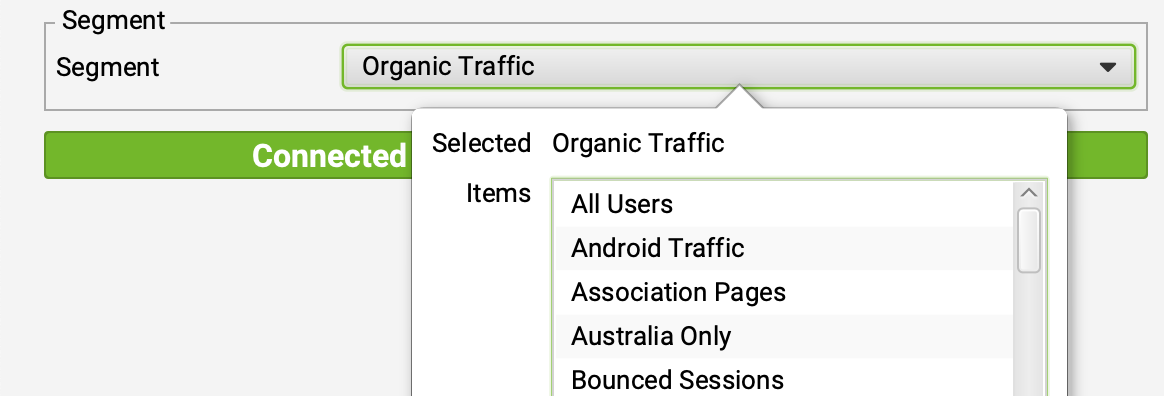
Equipping your arsenal with greater depth and support from your data helps steer the story and conversation, especially with the clients or senior team members who are alarmed by the idea of pruning content. Being able to clearly articulate that a page contains little-to-no value – for any marketing channel! – over a year-long period, for instance, can help alleviate their concerns and get ahead of the issue.
Dashboarding Your Data and Bringing Action to the Audit
As any good audit requires, we recommend assembling your findings into a dashboard (or a master spreadsheet) – not just for collecting data but encouraging a more collaborative, hands-on approach in defining actionable next steps.
Beyond documenting metrics, it’s valuable to conduct a more manual review of target pages, which is often facilitated by the blog editor, copywriter, or content strategist (or those that are more intimately involved in developing the content). Columns can be added to the dashboard to annotate specific issues and opportunities, like:
- Old/outdated content – If the page is performing for SEO, then what next steps can be done to update the content
- Off-brand tone – Similarly, if there’s SEO value, then reframe the content or remove and redirect to a better page.
- Wrong tone or target audience – If not completely low-value or obvious index bloat, then update the content to better align the voice and context.
Content can be pruned, or “retired” even if it provides SEO value – if that’s the right move for the business as a whole. This analysis will help you determine the relative value for SEO, and therefore the right next steps for HOW to prune or re-frame that content appropriately.
A dashboard is pivotal in helping set priorities and keeping communication straight among teams. Other filterable data points that will help with analyzing performance include:
- Author – If you have a multi-author blog, it’s likely some authors might produce better results on average versus others.
- Content category – Which categories are over or underperforming, and why? Are there ways to breathe life into priority categories?
- Business alignment – Should certain pieces of content be emphasized/prioritized to support product features?
- Customer funnel stage – Outline the target funnel stage for individual pages (e.g. a blog might target Awareness or Consideration stages, or be targeted at making Advocates of existing customers); then specify different goals per stage to move them along the funnel, and/or identify gaps where you’re not meeting the needs of your customers at a particular stage (e.g. not enough pages targeted at a specific stage.)
- Other notes & action items – Other specific notes, edits, or general enhancements can provide a subjective view for improvement or discussion.
The point is to assemble insights at scale and cultivate hypotheses on the “why” behind each data point while noting actionable improvements that can be made. This can include improving the content of less authoritative authors, or updating content to better suit patterns and trends that can be leveraged.
These insights, which can include a more analytical and subjective review, are invaluable to a great content audit update strategy. Not only does it bring actionable creativity to the mix, but a collaborative dashboard helps clients feel more involved with the audit process, oftentimes granting them more say in what stays, what goes, and what gets improved (which usually makes the whole project easier).
Embarking on Your SEO Content Audit
There are many ways to embrace an SEO content audit and the manner you collect, organize, and share your findings can take many forms.
The real value-add is knowing how to use your toolkit and peeling the onion in all the right places.
With the basic how-to guides in abundance, hopefully these ideas bring a refreshing point of view on a popular topic. How do you approach an SEO Content audit?







Hey Tory and Tyler
Some awesome points here that I think get overlooked a lot.
#3 on pruning index bloat is huge. Especially for large ecommerce sites or even just non ecom sites that have been around for a long time. We’ve seen great results on a lot of sites after some pretty brutal content auditing / pruning.
Must admit, I’ve never really played with the Crawl Analysis feature in Screaming Frog before. I’ve always just dug through the GSC data manually to identify any unwanted indexing issues, but the limited data set size in the GSC reports can sometimes mean you miss issues if you’re working on larger sites with more complex filtering.
Super intrigued to connect into the GA and GSC APIs and run the Crawl Analysis on my next audit to try it out.
Thanks for the great tips!
Great article! SEO content audits are vital for ensuring your website and its content is fully optimised. Thanks for sharing!
Nice stuff, thanks a lot for this awesome content. I will test it with Screaming Frog next time. SEO is a web analytics issue as well. It is enough with monitoring the rankings. You have to measure the behaviour of the users, the efficiency of keywords, bounce rate and further different metrics.
I do SEO for many years and I have just discovered Screaming Frog. It changed my SEO strategy from some perspective. Nice tool with useful data.
Always nice discovering “how to” like this, thank you for this stuff.
This was really interesting and useful for my SEO training thank you!
Thank you so much for this in-depth guide! The cannibalization analysis part is really inspiring and I’ll make sure to try these techniques out with one of my clients.
Been doing seo for many years now, and used a lot of tools.
Screaming Frog and this guide has made my work much more efficient and thorough.
Me and my clients thank you
I have been using screaming frog for multiple years ever since i found it randomly online . We will recommend it to our customers since its amazing . Thanks guys