Log File Analyser Tabs
User Guide
Overview
The overview tab provides a summary of the imported log file data, based upon the chosen time period and user-agent(s). These can both be configured in the top right hand corner.
While this data can’t current be exported, the tabular data can be copied and pasted and the graphs will need to be screenshot.
The summarised data includes the following –
- Unique URLs – The number of unique URLs in the log(s).
- Unique URLs per day – The average number of unique URLs in the log events per day.
- Total Events – The total number of log events.
- Events Per Day – The average number of events per day.
- Average Bytes – The average bytes of all log events.
- Average Time Taken (ms) – The length of time taken (measured in milliseconds) to download the files on average.
- Errors – The number of events with errors (4XX or 5XX responses).
- Provisional (1XX) – Number of events with with a provisional response code.
- Success (2XX) – Number of events with with a success response code.
- Redirection (3XX) – Number of events with with a redirect response code.
- Client Error (4XX) – Number of events with with a client error response code.
- Client Error (5XX) – Number of events with with a server error response code.
- Matched With URL Data – The number of log file URLs matched against ‘Imported URL Data’. You’ll need to import URL data for this not to be a ‘0’.
- Not In URL Data – The number of log file URLs not matched against ‘Imported URL Data’. You’ll need to import URL data for this not to be the same number as ‘unique URLs’. If you have imported crawl data, these could be orphan URLs for example.
- Not In Log File – The number of ‘Imported Data URLs’ not matched against log files. You’ll need to import URL data for this not to be a ‘0’. If you have imported crawl data, these could be URLs that have yet to be crawled for example.
URLs
The URLs tab aggregates the log file data for every unique URL discovered, based upon the chosen time period and user-agent(s). These can both be configured in the top right hand corner.
The summarised data includes the following –
- URL – The URL discovered.
- Last Response Code – The last response code from events.
- Time Of Last Response – The date and time of the last log event.
- Days Since Last Crawl – Days since a URL was crawled based upon the time of last response, and last date of events available in the log file uploaded.
- Content Type – The content type is guessed from the file extension, as it’s not provided in a log file and there is no crawling involved. So it’s not from the HTTP response. Hence, these will not be completely accurate, merely a best guess at this stage.
- Total Bytes – The total bytes downloaded of all log events for the URL.
- Average Bytes – The average size in bytes of all log events for the URL.
- Total CO2 (mg) – The total CO2 in mg of all log events for the URL.
- Average CO2 (mg) – The average CO2 in mg of all log events for the URL.
- Average Response Time (ms) – The length of time taken (measured in milliseconds) to download the URL on average.
- Num Events – The total number of events for the URL.
- All Bots – The total number of bot events for the URL.
- Googlebot – The total number of Googlebot events for the URL.
- Bingbot – The total number of Bingbot events for the URL.
- Googlebot Mobile – The total number of Googlebot Mobile events for the URL.
- Googlebot Smartphone – The total number of Googlebot Smartphone events for the URL.
- Yandex – The total number of Yandex events for the URL.
- Baidu – The total number of Baidu events for the URL.
Response Codes
This tab aggregates response code data from the log file for every unique URL discovered, based upon the chosen time period and user-agent(s).
It shows the last response code, the time of last response and the number of log events for every URL. It also groups events by response codes buckets, 1XX, 2XX, 3XX, 4XX and 5XX, so you can quickly see an overview of all responses for the time period you’re analysing.
The summarised data includes the following –
- URL – The URL discovered.
- Last Response Code – The last response code from events.
- Time of Last Response – The latest response time from the events.
- Num Events – The total number of events for the URL.
- Inconsistent – This is true or false. True means the URL has inconsistent response codes from all events analysed. So if a URL had two events, one was a 200 response and the other a 404, this would be ‘true’. If both responses were 200, then it would be ‘false’.
- 1XX – The total number of 1XX events for the URL.
- 2XX – The total number of 2XX events for the URL.
- 3XX – The total number of 3XX events for the URL.
- 4XX – The total number of 4XX events for the URL.
- 5XX – The total number of 5XX events for the URL.
User Agents
The user-agents tab aggregates data from the log file for every user-agent discovered, based upon the chosen time period, user-agent(s) and project type (‘Bot only’, or ‘All’).
The summarised data includes the following –
- User-Agent – The specific user-agent of the event.
- Unique URLs – The number of unique URLs with events.
- Num Events – The total number of events for the user-agent.
- Total Bytes – The total bytes downloaded of all log events for the URL.
- Average Bytes – The average size in bytes of all log events for the URL.
- Total CO2 (mg) – The total CO2 in mg of all log events for the URL.
- Average CO2 (mg) – The average CO2 in mg of all log events for the URL.
- Average Response Time (ms) – The length of time taken (measured in milliseconds) to download URLs on average for the user-agent.
- Errors – The number of events with errors (4XX or 5XX responses).
- 1XX – The total number of 1XX events for the user-agent.
- 2XX – The total number of 2XX events for the user-agent.
- 3XX – The total number of 3XX events for the user-agent.
- 4XX – The total number of 4XX events for the user-agent.
- 5XX – The total number of 5XX events for the user-agent.
Referers
The Referer tab aggregates data from the log file for every Referer discovered, based upon the chosen time period, user-agent(s) and project type (‘Bot only’, or ‘All’). The Referer comes from the Referer header field in the HTTP request. It identifies the web page that linked to the page being requested. Referer is not a mandatory field, so it maybe that this was not included in your imported log files and this tab has little value to you. If the imported log files did have Referer information in them, it will very probably not be included in every event as it’s an optional field. Depending on log file type the Referer will either be shown as empty or “-” when missing. Log events from search engines, or users visiting pages directly will typically not have any Referer information in them.
The summarised data includes the following –
- Referer – The referer URL of the event.
- Unique URLs – The number of unique URLs with the referer.
- Num Events – The total number of events for the referer.
- Total Bytes – The total bytes downloaded of all log events for the URL.
- Average Bytes – The average size in bytes of all log events for the URL.
- Total CO2 (mg) – The total CO2 in mg of all log events for the URL.
- Average CO2 (mg) – The average CO2 in mg of all log events for the URL.
- Average Response Time (ms) – The length of time taken (measured in milliseconds) to download URLs on average for the referer.
- Errors – The number of events with errors (4XX or 5XX responses).
- 1XX – The total number of 1XX events for the referer.
- 2XX – The total number of 2XX events for the referer.
- 3XX – The total number of 3XX events for the referer.
- 4XX – The total number of 4XX events for the referer.
- 5XX – The total number of 5XX events for the referer.
Directories
The directories tab aggregates the log file data by directory path, based upon the chosen time period and user-agent(s). These can both be configured in the top right hand corner.
The summarised data includes the following –
- Path – The directory path.
- Num Events – The total number of events for the directory path.
- Total Bytes – The total bytes downloaded of all log events for the URL.
- Average Bytes – The average size in bytes of all log events for the URL.
- Total CO2 (mg) – The total CO2 in mg of all log events for the URL.
- Average CO2 (mg) – The average CO2 in mg of all log events for the URL.
- Average Response Time (ms) – The length of time taken (measured in milliseconds) to download URLs in the directory on average.
- All Bots – The total number of bot events for the URL.
- Googlebot – The total number of Googlebot events for the directory.
- Bingbot – The total number of Bingbot events for the directory.
- Googlebot Mobile – The total number of Googlebot Mobile events for the directory.
- Googlebot Smartphone – The total number of Googlebot Smartphone events for the directory.
- Yandex – The total number of Yandex events for the directory.
- Baidu – The total number of Baidu events for the directory.
- 1XX – The total number of 1XX events in the directory.
- 2XX – The total number of 2XX events in the directory.
- 3XX – The total number of 3XX events in the directory.
- 4XX – The total number of 4XX events in the directory.
- 5XX – The total number of 5XX events in the directory.
IPs
The IPs tab aggregates data from the log file for every IP discovered, based upon the chosen time period, user-agent(s) and project type (‘Bot only’, or ‘All’).
The summarised data includes the following –
- Remote Host – The IP address of the events.
- Unique URLs – The number of unique URLs requested by the IP.
- Num Events – The total number of events for the IP.
- Total Bytes – The total bytes downloaded of all log events for the URL.
- Average Bytes – The average size in bytes of all log events for the URL.
- Total CO2 (mg) – The total CO2 in mg of all log events for the URL.
- Average CO2 (mg) – The average CO2 in mg of all log events for the URL.
- Average Response Time (ms) – The length of time taken (measured in milliseconds) to download URLs on average for the IP.
- Errors – The number of events with errors (4XX or 5XX responses).
- 1XX – The total number of 1XX events for the IP.
- 2XX – The total number of 2XX events for the IP.
- 3XX – The total number of 3XX events for the IP.
- 4XX – The total number of 4XX events for the IP.
- 5XX – The total number of 5XX events for the IP.
Countries
The countries tab aggregates data from the log file to count the number of events from countries based upon the IP address of events.
The summarised data includes the following –
- Country – The country identified for the events based upon the IP address.
- Num Events – The total number of events for the country.
- Rank – The highest to least number of events by country.
Bytes
The Bytes tab includes data around the size in bytes of log events for every URL, based upon the chosen time period and user-agent(s). These can both be configured in the top right hand corner.
The summarised data includes the following –
- URL – The URL discovered.
- Num Events – The total number of events for the URL.
- Total Bytes – The total bytes downloaded of all log events for the URL.
- Average Bytes – The average size in bytes of all log events for the URL.
- Total CO2 (mg) – The total CO2 in mg of all log events for the URL.
- Average CO2 (mg) – The average CO2 in mg of all log events for the URL.
This CO2 calculation comes from the CO2.js library to estimate the emissions of log events. The CO2 calculation uses the ‘The Sustainable Web Design Model‘, which considers datacentres, network transfer and device usage in calculations.
Events
The ‘events’ tab shows you the raw events from the log file, with every attribute available.
Please bare in mind, if you’re analysing 10 million log file events, this view will contain 10 million events and take some time to generate. Filters, sorting and searching will also take more time.
The data includes exactly what’s in the logs –
- URL
- Timestamp
- IP
- Method (GET / POST)
- Response Code
- Bytes
- Time Taken(ms). ms stands for milliseconds. There are 1000 milliseconds in a second. So 500 milliseconds is half a second etc.
- User-Agent
- Referer
Imported URL Data
The ‘Imported URL Data’ tab allows you to import CSVs or Excel files with any data which have a ‘URLs’ heading and column. For example, you can import crawl data, URLs from a sitemap or a ‘top pages’ export from Majestic or OSE for example. You can import multiple files and data will be matched up automatically against URLs, similar to VLOOKUP.
Combining crawl data with log file events obviously allows for more powerful analysis, as it enables you to discover URLs which are in a crawl, but not in a log file, or orphan pages which have been crawled by search bots, but are not found in a crawl.
Importing Crawl Data
You can export the ‘internal’ tab of a Screaming Frog SEO Spider crawl and drag and drop the file directly into the ‘Imported URL Data’ tab window. Alternatively you can use the ‘Import > URL Data’ button or ‘Project > Import URL Data’ option in the top level menu. This will import the data quickly into the Log File Analyser ‘Imported URL data’ tab and database.
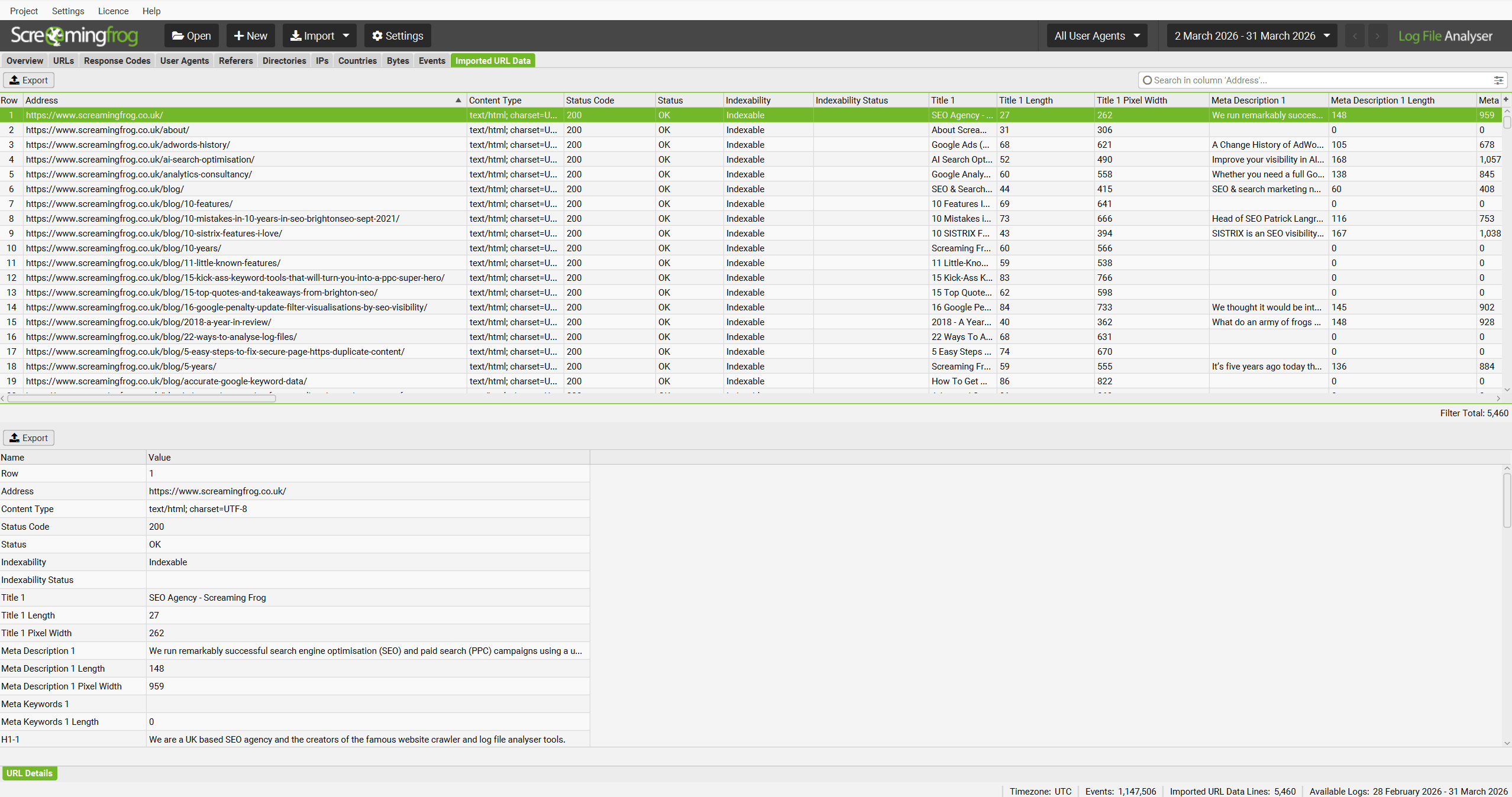
The ‘Imported crawl data’ tab only shows you the data you imported, nothing else. However, you can now view the crawl data alongside the log file data, by using the ‘View’ filters available in the ‘URLs’ and ‘Response Codes’ tabs.
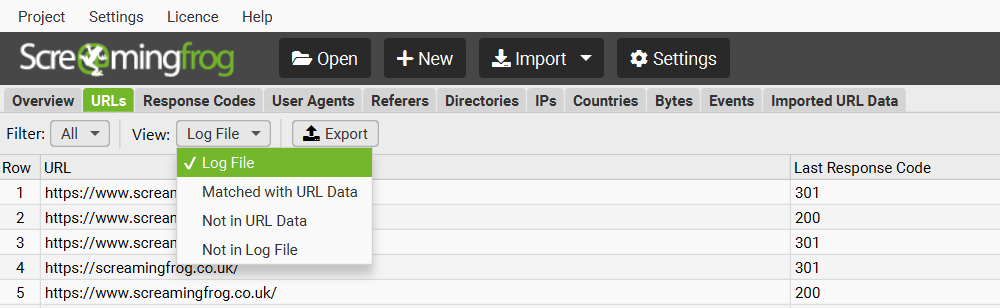
The Log File Analyser defaults to ‘Log File’, but if you change the view to ‘Matched With URL Data’ it will show you crawl data alongside the log file data (scroll to the right).
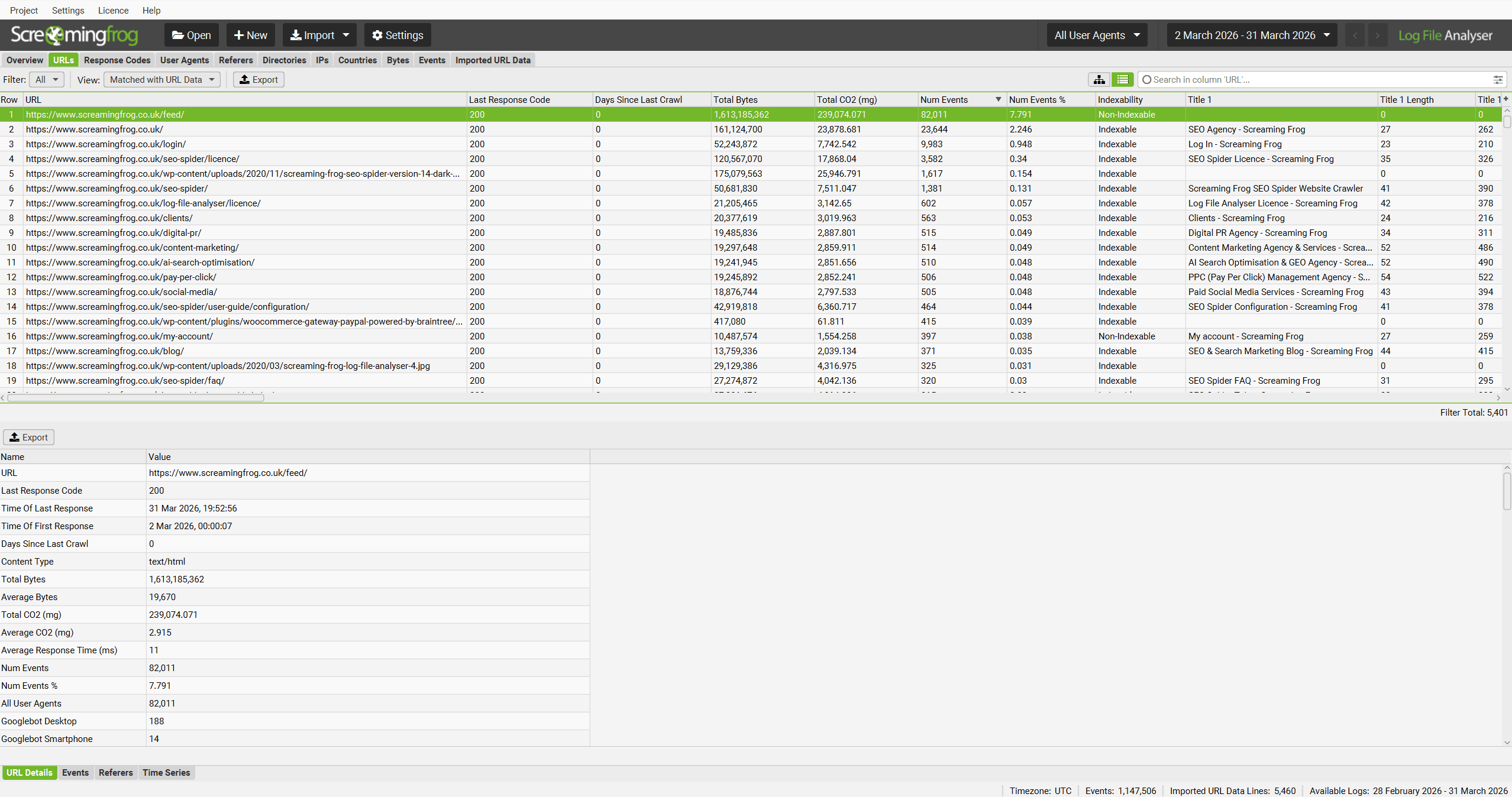
‘Not In URL Data’ will show you URLs which were discovered in your logs, but are not present in the crawl data imported. These might be orphan URLs, old URLs which now redirect, or just incorrect linking from external websites for example.
‘Not In Log File’ will show you URLs which have been found in a crawl, but are not in the log file. These might be URLs which haven’t been crawled by search bots, or they might be new URLs recently published for example.
Deleting Imported URL Data
You can quickly delete the ‘Imported URL data’ from a project by clicking on ‘Project > Clear URL Data’ in the top level menu options.
Please note, once the data has been deleted, it can’t be recovered unless you import the data again.




