FAQ
For the SEO Spider
Licencing
Why is my licence key invalid?
If the SEO Spider says your ‘licence key is invalid’, then it's because it has been entered incorrectly. This can be seen under 'Licence > Enter Licence Key' in the interface.
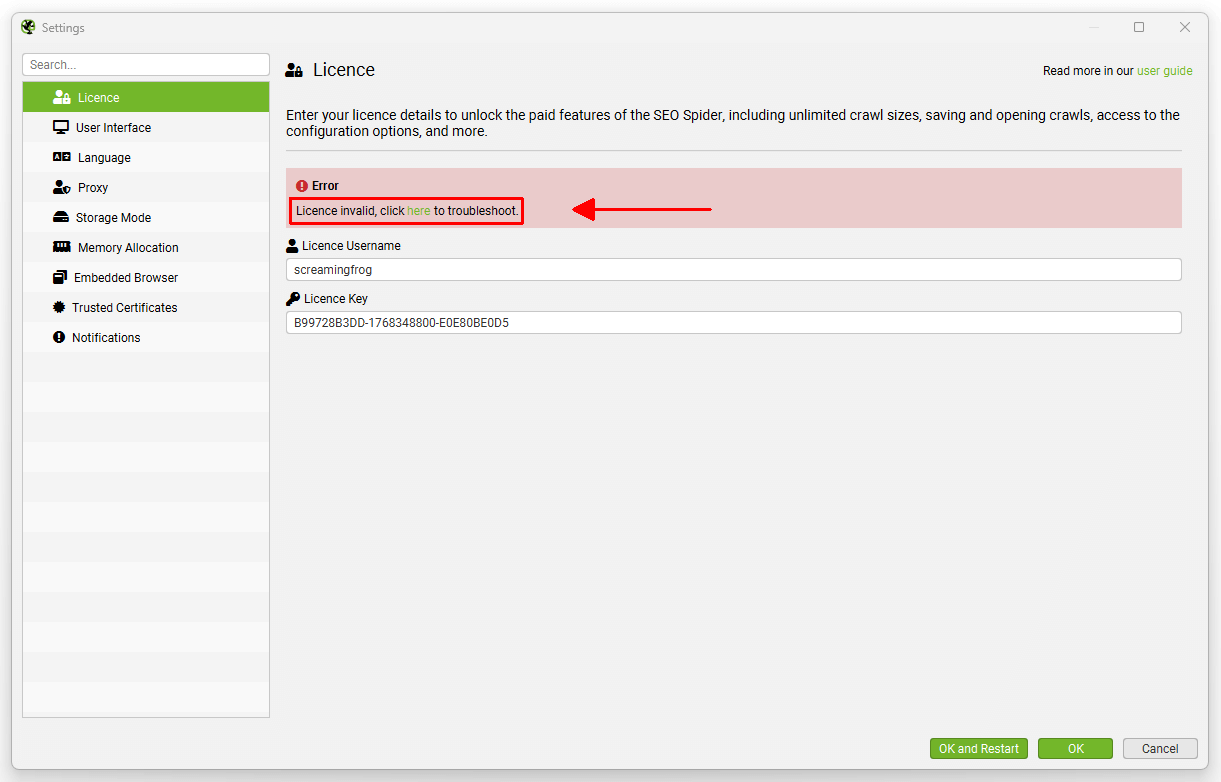
Licence keys are displayed when you checkout, sent in an email with the subject "Screaming Frog SEO Spider licence details" and are available at any time by logging into your account and viewing within the 'licence keys' section.
Before contacting us, please view your licence details and copy and paste them into the correct field - they are not designed to be entered manually. Please follow our tips below on common issues encountered.
- Ensure you are using the username provided for your licence key, as this isn't always the same as your 'account username' and it's not your exact email address. Usernames are lowercase. This is by far the most common issue we see.
- Please also double check you have inserted the provided ‘Username’ in the ‘Username’ field and the provided ‘Licence Key’, in the ‘Licence Key’ field.
- Ensure you are not entering a Log File Analyser licence into the SEO Spider.
- Ensure you are not entering a SEO Spider licence into the Log File Analyser.
If your licence key still does not work, then please contact support with the details.
Why is my licence lease invalid?
Screaming Frog software licences are for a single user only. Every individual user requires their own licence.
Whilst it is acceptable for a single user to use a licence on more than one device, our licencing system will block any licences that are being used by multiple users.
If you require additional licences, these can be purchased online. If your licence key has been shared and requires a reset, please contact support.
Why do I get a PKIX Certificate Path Error?
Some companies deploy Internet Access proxies such as Zscaler or McAfee Web Gateway. By default the SEO Spider does not trust these proxies, so you have to add their certificate to the Trusted Certificates store in the SEO Spider to validate the licence.
The error reads 'javax.net.ssl.SSLHandshakeException: PKIX path building failed:' as per the screenshot below.
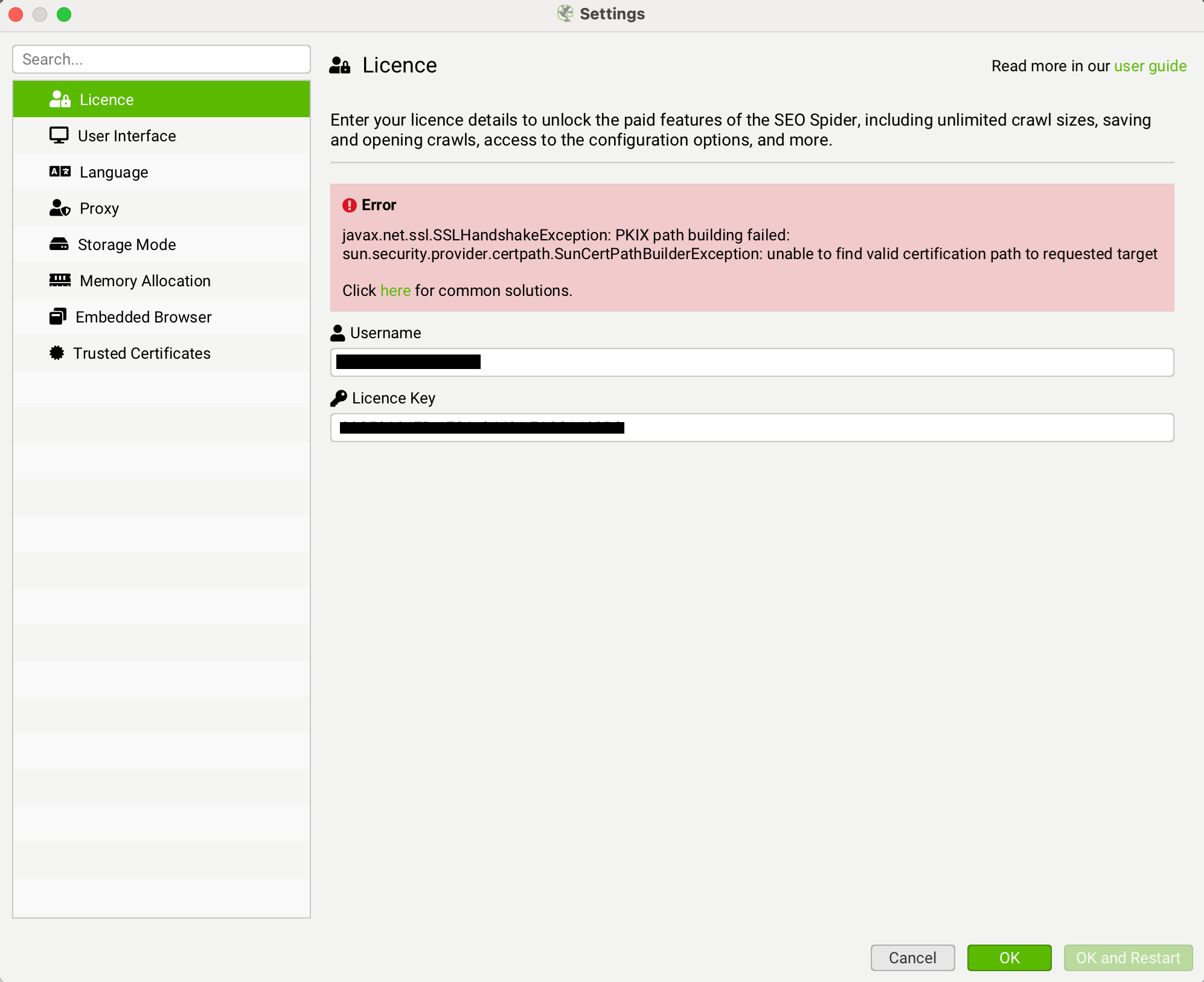
The quickest way to obtain this certificate is by using the 'Discover' button in 'File > Settings > Trusted Certificates' in Screaming Frog. If you're not seeing this option, then please ensure you're using 20.2 or later of the SEO Spider. This can be done by following the instructions below.
How To Add A Trusted Certificate
When a proxy is changing the issuer of a certificate, it can be quickly seen within Screaming Frog. Click 'File > Settings > Trusted Certificates' on Windows or 'Screaming Frog SEO Spider > Settings > Trusted Certificates' on macOS and then click the 'Discover' button.
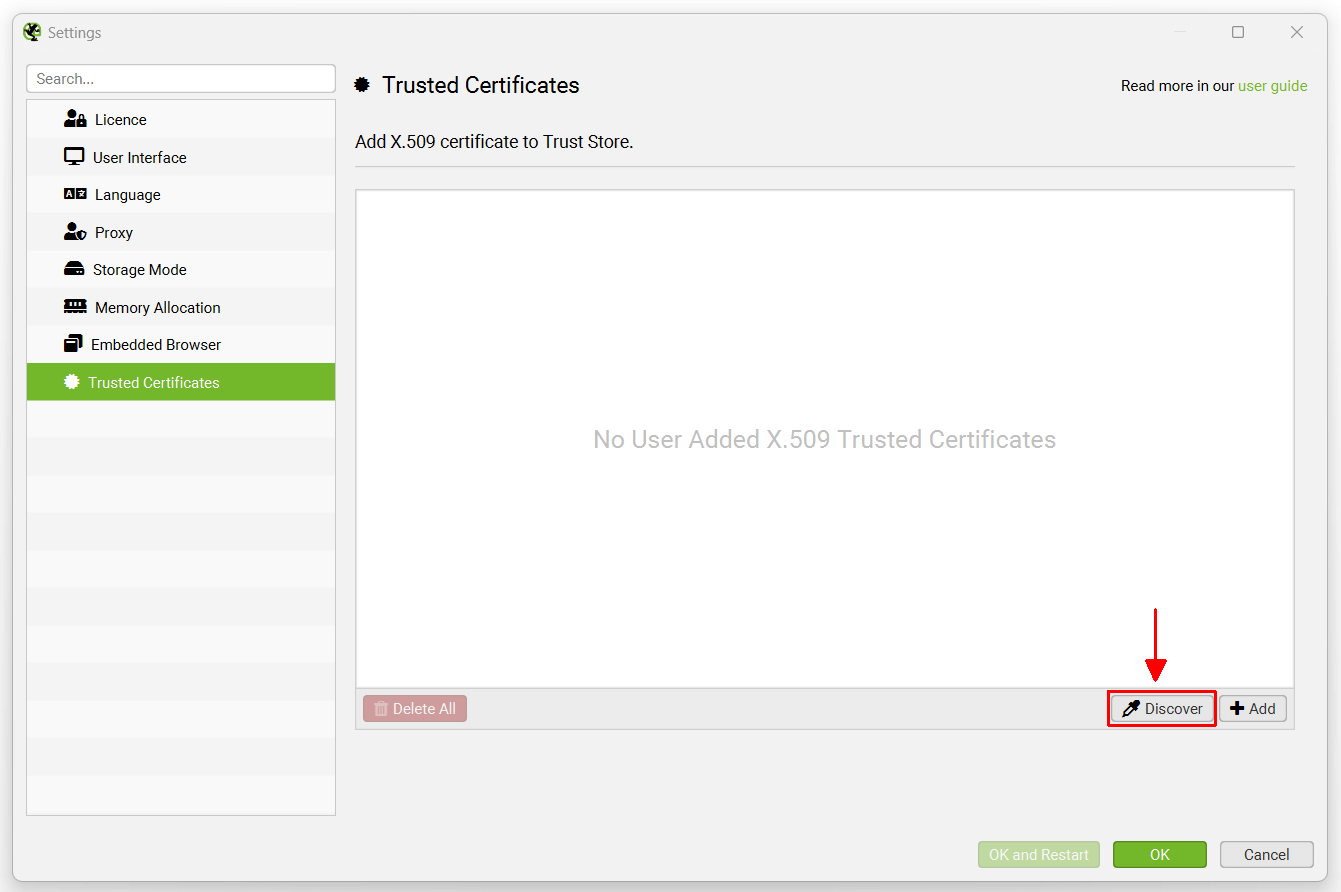
The genuine issuer for the Screaming Frog website certificate is 'GTS CA 1P5', however, you should see this is as something different - such as your proxy, for example ZScaler or McAfee. This shows the issuer of the certificate is being changed in your networking environment.
If you are seeing 'ZScaler, McAfee' etc as the issuer certificate, then click the 'Add' button next to it.
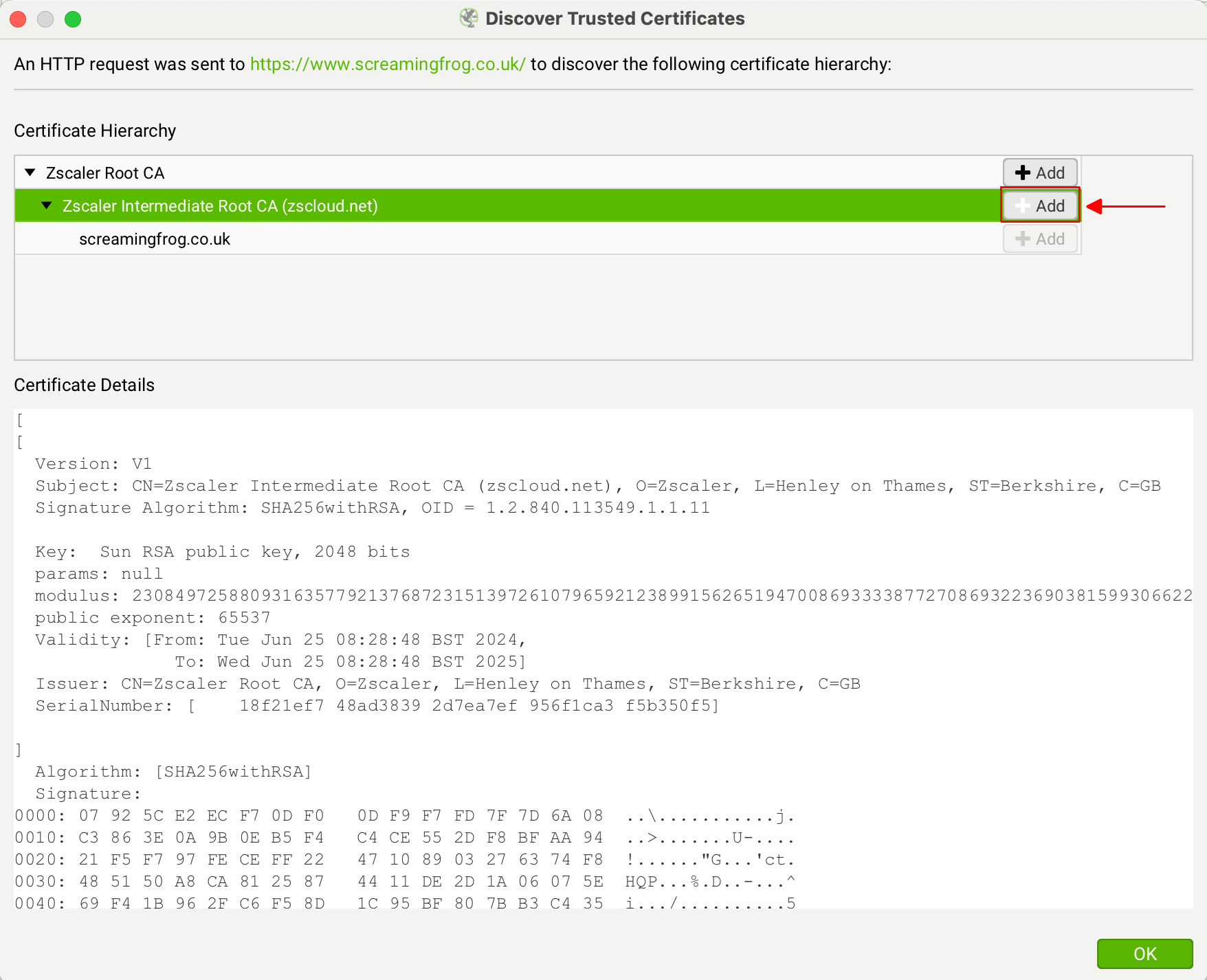
This will add the certificate file to the SEO Spider trusted certificates trust store.
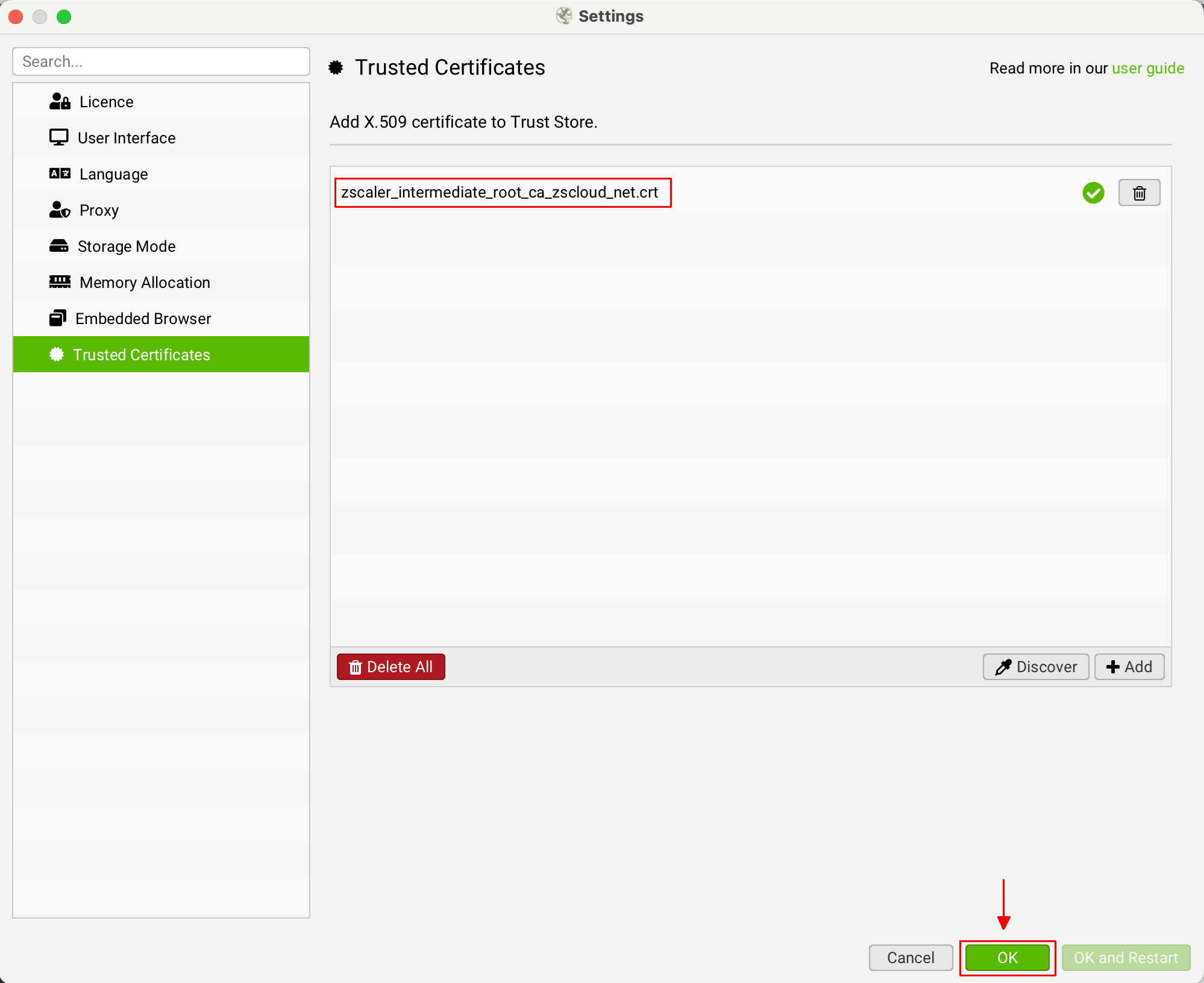
You can then click 'OK'. You should then be able to validate your licence.
How many users are permitted to use one licence?
Each licence key is to be used by only the one authorised User (individual person) for the entire term of the licence.
If you have five people from your team that wish to use the SEO Spider, you will require 5 Licences. One for each User.
If the authorised User of a licence leaves the company, you may request the remaining term of the licence be transferred to an alternative authorised User. This transfer is subject to reasonable use and is limited to one such transfer each year.
Discounts are available for 5 users or more, as shown in our our pricing.
Please see section 3 of our terms and conditions for full details.
Is it possible to use a licence on more than one device?
The licence allows you to install the SEO Spider on multiple devices, subject to reasonable use, however, those devices must only be accessible by the licenced user.
Each person using the software must have their own licence, as licences are per person.
Please see section 3 of our terms and conditions for full details.
What happens when the licence expires?
Licences are annual. The SEO Spider returns to the restricted free version upon expiry of the licence.
This means the SEO Spider’s configuration options are unavailable, there is a 500 URL maximum crawl limit and previously saved crawls cannot be opened.
To remove the crawl limit, access the configuration, enable all features and open up saved crawls, simply purchase a new licence upon expiry.
How do I transfer a licence to a different user?
You are able to transfer the licence to a new user once during its annual term, such as someone leaving the company.
You can do this by logging into your account, clicking on 'Licence Keys', and updating the email address of the 'Assigned User' against the relevant licence, and clicking 'Update'.
 The new user can then download and install the SEO Spider on their device and click on 'Licence > Enter Licence Key' in the top level menu.
The new user can then download and install the SEO Spider on their device and click on 'Licence > Enter Licence Key' in the top level menu.
 They can then input their username and password into the relevant fields in the SEO Spider.
They can then input their username and password into the relevant fields in the SEO Spider.
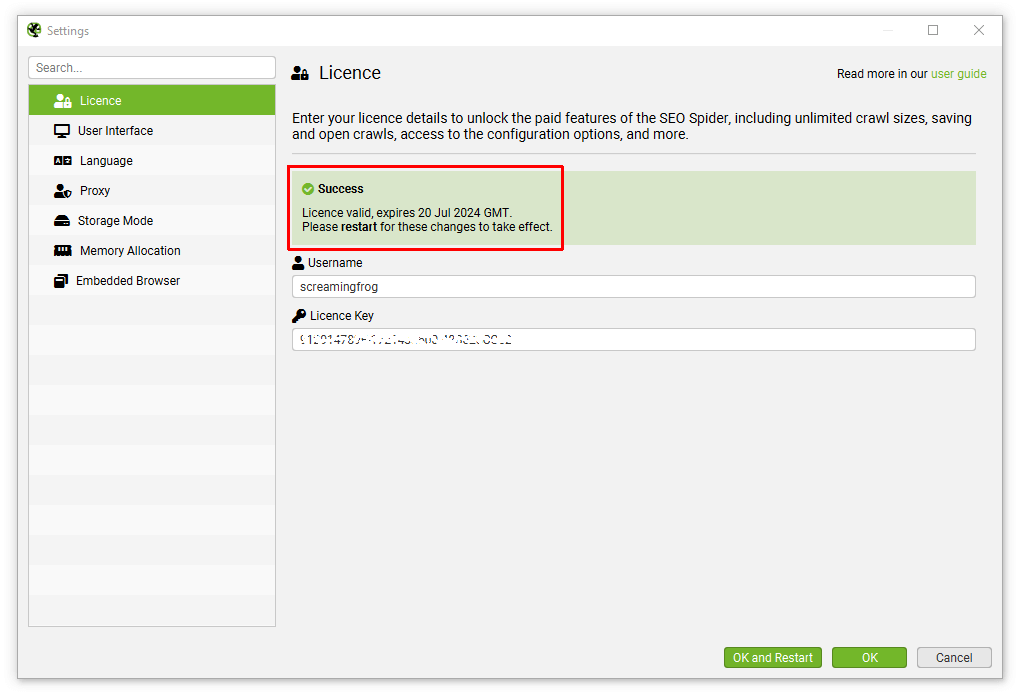 When entered correctly the licence will say it’s valid and show the expiry date. The new user will then be required to restart the application to remove the crawl limit and enable access to the configuration and paid features.
When entered correctly the licence will say it’s valid and show the expiry date. The new user will then be required to restart the application to remove the crawl limit and enable access to the configuration and paid features.
For new users, please see our getting started guide.
If the licence says it’s invalid, please read our FAQ on common invalid licence issues to troubleshoot.
If the licence says 'licence lease invalid', then please contact us via support to reset the licence.
Please also note that licences are per person, but can be used on multiple devices by a single user.
What features does a licence provide?
A licence removes the 500 URL crawl limit, allows you to save and open crawls, access the configuration options and the custom source code search, custom extraction, Google Analytics integration, Google Search Console integration and JavaScript rendering features. We also provide support for technical issues related to the SEO Spider for licensed users.
A full comparison of features between the paid and free versions can be found on the Pricing page.
In the same way as the free ‘lite’ version, there are no restrictions on the number of websites you can crawl with a licence. Licences are however, individual per user. If you have five members of the team who would like to use the licensed version, you will need five licences.
I have lost my licence or invoice, how do I get another one?
Please login to your account to retrieve the details.
If you have lost your account password, then request a new password via the form.
If you purchased your licence via invoice rather than online via the website, then please contact [email protected] directly.
Is it possible to move my licence to a new computer?
Licences can be used on multiple devices by the same user. Licences are individual per user.
This means a single user with a licence, can use the software on multiple devices. It cannot be used by multiple users, each user would require a separate licence.
If you wish to transfer the licence away from an existing machine, please take a note of your licence key (you can find this under 'Licence > Enter Licence Key' in the software), uninstall the SEO Spider on the old device, before installing and entering your licence on the new machine.
If you experience any issues during this move, please contact our support.
Why can’t my licence key be saved (Unable to update licence file)?
The SEO Spider stores the licence in a file called licence.txt in the users home directory in a ‘.ScreamingFrogSEOSpider’ folder. You can see this location by going to Help->Debug and looking at the line labeled “Licence File”. Please check the following to resolve this issue:
- Ensure you are able to create the licence file in the correct location.
- If you are using a Mac, see the answer to this stackoverflow question.
- If you are using Windows is could be the default user.home value supplied to Java is incorrect. Ideally your IT team should fix this. As a workaround you can add:-Duser.home=DRIVE_LETTER:\path\to\new\directory\ to the ScreamingFrogSEOSpider.l4j.ini file that controls memory settings.
I have purchased a licence, why have I not received it?
If you have just purchased a licence and have not received an email with the details, please check your spam / junk folder. Licences are sent via email immediately upon purchase.
Licences are able displayed on screen at checkout and you can also view your licence(s) details and invoice(s) by logging into your account at anytime.
Where can I find your EULA (terms & conditions)?
You can read our EULA here.
Billing
How do I buy a licence?
Simply click on the ‘buy a licence’ option in the SEO Spider ‘licence’ menu or visit our purchase a licence page directly.
You can then create an account & make payment. When this is complete, you will be provided with your licence key to open up tool & remove the crawl limit. If you have just purchased a licence and have not received your licence, please check your spam / junk folder. You can also view your licence(s) details and invoice(s) by logging into your account.
Please note, if you purchased via bank transfer or PayPal invoice you will not have an account. An account is only created when you checkout via our online purchase system. If you have lost any of your details you can contact us for this information.
How do I renew my licence?
There are two options to renew your licence - Manual purchase, or auto renew. By default a new annual licence needs to be purchased each year.
To renew the licence, you will need to login to your existing account and purchase another licence upon expiry.
Please don't purchase a licence pre-expiry as it will not extend your existing licence expiry. Updated licence details will be provided upon purchase to continue using the tool.
The second option is to select 'auto renew' when you purchase a licence.
If this is enabled, you can view this in your account and the 'Subscriptions' section.
With this option enabled, no action is required to renew your licence - you will receive an email prior to renewal confirming the details. The licence will then automatically renew and update within the software without requiring your input.
If this was not selected at the time of purchase, it cannot be activated retrospectively for your current licence.
How do I cancel a licence or auto renewal?
By default SEO Spider licences are not set to auto renew. The licence will simply expire naturally at the end of the period.
There's no notice period, you don't need to email in and inform us.
If you wanted to renew, you would need to purchase a new licence on expiry.
You can check to see if you enabled auto renewal, by logging into your account and viewing 'subscriptions'. If it is enabled, you have the ability to cancel it.
How much does the Screaming Frog SEO Spider cost?
The SEO Spider is free to download and use. However, without a licence the SEO Spider is limited to crawling a maximum of 500 URLs each crawl, crawls can't be saved, and advanced features and the configuration are restricted.
For £199 per annum you can purchase a licence which opens up the Spider’s configuration options and removes restrictions on the 500 URL maximum crawl. Please see our pricing page which shows a comparison between free and paid.
Licences are individual per user of the tool. When the licence expires, the SEO Spider returns to the restricted free lite version.
Do you offer licence discounts?
We only provide discounts on bulk purchases of 5 or more SEO Spider licences at a time. We do not offer discounts at any other time, both new and renewed licences are the same price.
We do not offer discounts or deals during Black Friday or Cyber Monday, as it would be unfair on other users who will have paid a different price.
We simply keep the price as competitive as possible for everyone all the time.
We don't provide discount codes or coupons. If you have found them on other websites, they are not genuine and should be ignored.
Please see the SEO Spider licence page for more details on discounts.
What payment methods do you accept & from which countries?
We accept most major credit and debit cards and PayPal.
The price of the SEO Spider is in pound sterling (GBP), but it can be purchased worldwide.
If you are outside of the UK, please take a look at the current exchange rate to work out the cost. The automatic currency conversion will be dependent on the current foreign exchange rate and perhaps your card issuer, so we are not able to give an exact fee (other than in GBP).
We do not accept cheques (or checks!) as payment.
I’m a business in the EU, can I pay without being charged VAT?
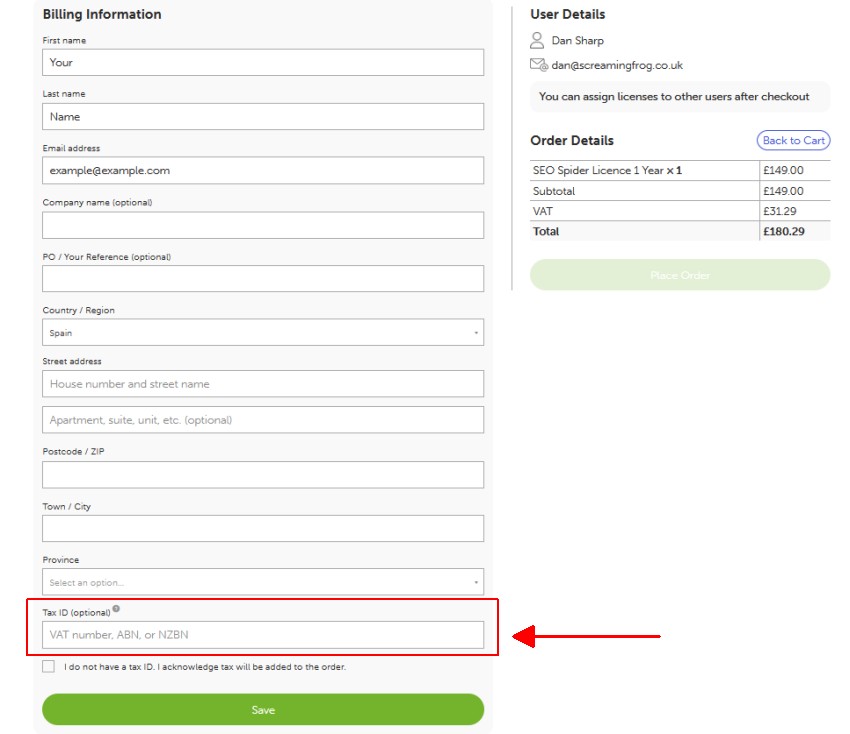
Yes, if you are not in the UK and are in the EU. To do this you must have a valid VAT number and enter this in the Billing Information section during checkout.
Enter your VAT number in the 'Tax ID' field, and then remember to click 'Save'.
 Your Tax ID number will be checked using the official VIES tax validation service and the VAT charge removed if it is valid. You as the buyer are now responsible for reporting VAT under the reverse charge mechanism.
Your Tax ID number will be checked using the official VIES tax validation service and the VAT charge removed if it is valid. You as the buyer are now responsible for reporting VAT under the reverse charge mechanism.
You can check your VAT number using the official VIES VAT validation system here. The VIES service can go down from time to time, please see here for your options if this happens.
If you don't have a VAT number you must confirm the 'I do not have a tax ID. I acknowledge tax will be added to the order' button.
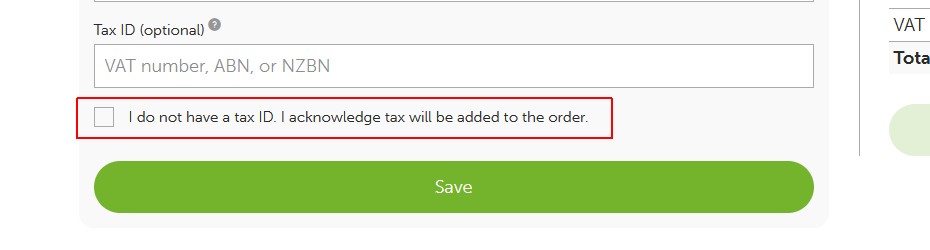 If you confirmed you do not have a tax ID when you do have one, then VAT will be kept on your order.
If you confirmed you do not have a tax ID when you do have one, then VAT will be kept on your order.
We cannot refund VAT once a purchase has been made and are unable to add your tax ID to the invoice. Unfortunately legally there can be no exceptions to this, it's your responsibility to ensure it's completed accurately.
What should I do if the External Tax Validator service is down?
During checkout we use the official EU VIES service to validate Tax IDs.
During busy times this service can fail, or their can be specific issues for member states. You can see data for each member state here. Unfortunately there is nothing Screaming Frog can do about the reliability of this external service which all of the EU rely on.
If this service is down there are 2 options.
- Wait until the service is up - You can supply us with your email and we can keep trying your VAT number on your behalf every minute, and let you know when it has validated and the result has been cached. You will then be able to make the purchase as expected.
- Clear your Tax ID and make the purchase with Tax - You can then claim this back later from your local Tax Authority. We are unable to refund tax after purchase.
As above, we are never able to refund the tax after purchase.
Why is my credit card payment being declined?
Unfortunately we do not get to see why a payment has been declined. There are a few reasons this could happen:
- Incorrect card details: Double check you have filled out your card details correctly.
- Incorrect billing address: Please check the billing address you provided matches the address of the payment card.
- Blocked by payment provider: Please contact your card issuer. Screaming Frog does not have access to failure reasons. It’s quite common for a card issuer to automatically block international purchases.
The most common of the above is an international payment to the UK. So please contact your card issuer and ask them directly why a payment has been declined, and they can often authorise international payments.
Alternatively, you can try a different card, PayPal, or you can contact us via support and pay via bank transfer.
Has the SEO Spider price changed?
We try and keep the price as low as possible to allow SEOs worldwide to benefit from the use of the software. We believe it's the best value tool on the market.
The price is £199 a year, which is the same for both existing and new customers, and software resellers working on behalf of enterprise clients. We also don't ever provide discount codes or do promotions such as Black Friday. We believe this keeps it fair.
To provide transparency on price, our pricing history is detailed below.
- Launch (November 2010) - £99 / $N/A / €N/A. (Only sold in £ GBP)
- Price Increase (August 2016) - £149 / $209 / €185.
- Price Increase (January 2023) - £199 / $259 / €239.
- Currency Adjustment (May 2025) - £199 / $279 / €245.
There have been two price increases in 15 years since launch in 2010.
Over this time, there have been significant updates in new releases, including industry-first features such as JavaScript rendering, as well as crawl comparison, and change detection.
Between our most recent pricing update in 2023 from 2016, there have been 12 major releases and many updates with improvements.
The rate of inflation between increases should also be considered and can be checked using the Bank of England inflation calculator. The licence cost in 2016 has an equivalent cost of £205 in 2025 for example.
Updating our price allows us to continue to improve the tool and continue to provide world-class technical support.
Currency Adjustment
Whilst we have not changed our base price of £199 a year since 2023, we have adjusted our currency pricing to account for some significant movements in exchange rates. Users are welcome to purchase in any supported currency that suits them.
Legacy User Pricing
On renewal after a price increase, existing users are not retained on old pricing. All users pay the same price for the same tool, without exception.
Some tools choose to 'grandfather' existing users, but often this results in new features being restricted in 'legacy' user plans to encourage them onto new pricing.
Our licencing is an annual purchase, rather than auto monthly subscription. This allows users to decide whether the product is still right for them each year.
Free Users!
We are committed to supporting the freemium model, which provides a completely free version of the tool for crawling up to 500 URLs at a time.
Hundreds of thousands of professionals, small business owners, freelancers and hobbyists continue to utilise our free version, which does not require any form of email capture, or sign up.
Simply download, and use - without the sales.
Do you have a refund policy?
Absolutely! If you are not completely satisfied with the SEO Spider you purchased from this website, you can get a full refund if you contact us within 14 days of purchasing the software. We do not provide 'pro rata' refunds for any period of non-use of a licence.
To obtain a refund, please follow the procedure below.
Contact us via [email protected] or support and provide the following information:
- Your contact information (last name, first name and email address).
- Your order number.
- Your reason for refund! If there's an issue, we can generally help.
If you wish to continue using the free version of the sofware, we recommend removing the licence from the app via 'Licence > Enter Licence Key' and deleting the username and licence key.
If you have purchased your item by credit card the refund is re-credited to the account associated with the credit card used for the order.
If you have purchased your item by PayPal the refund is re-credited to the same PayPal account used to purchase the software.
If you have purchased your item using any other payment method, we will issue the refund by BACS, once approved by our Financial Department.
Refunds can take 3-5 working days to be processed by Braintree and the banks.
Resellers
Do you work with resellers?
Resellers can purchase an SEO Spider licence online on behalf of a client.
Please be aware that licence usernames are automatically generated from the account username created during registering the account.
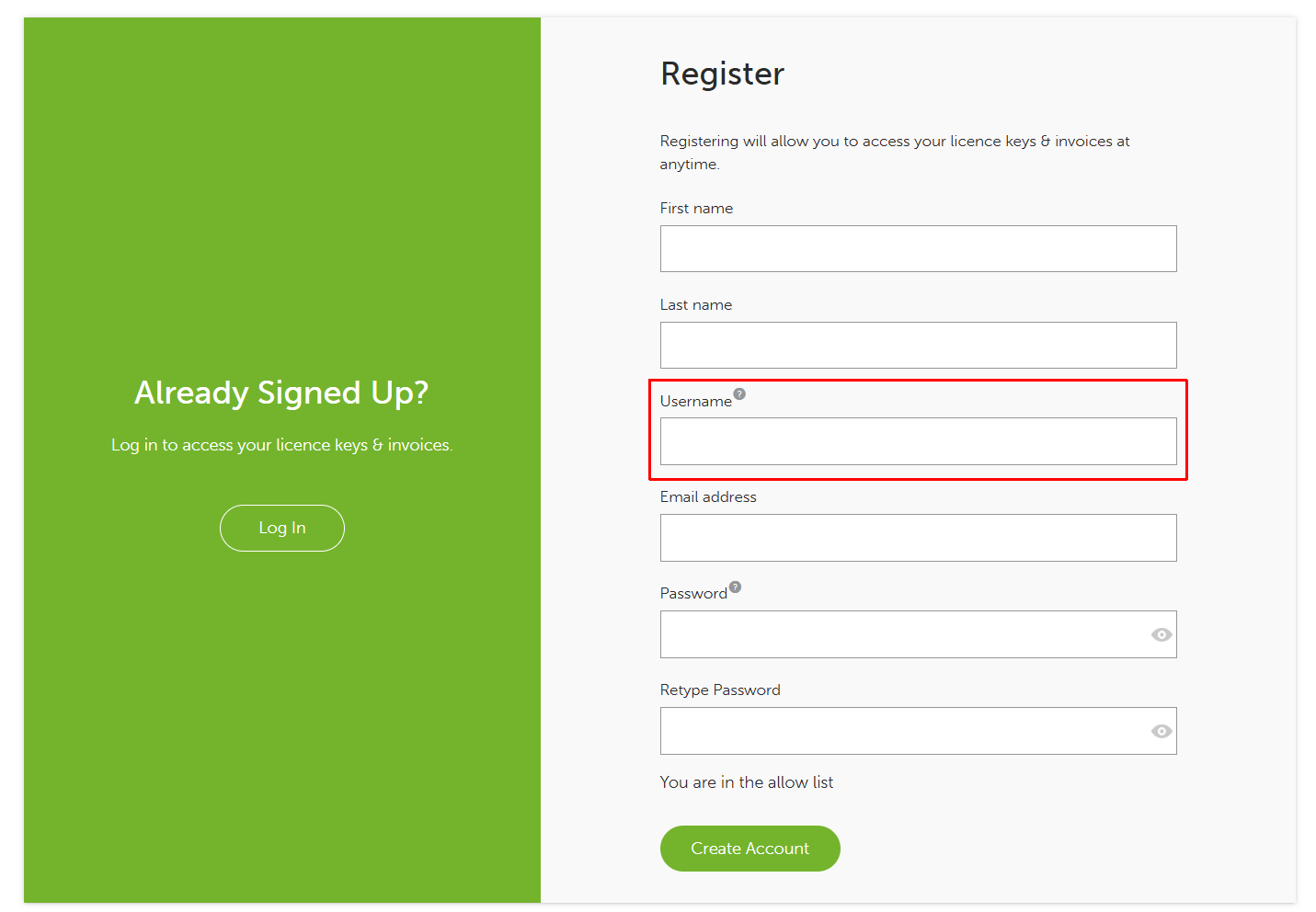 In this scenario, it often makes sense to make the account username the business name, or end user name, rather than the resellers name or resellers company name.
In this scenario, it often makes sense to make the account username the business name, or end user name, rather than the resellers name or resellers company name.
For resellers who are unable to purchase online with PayPal or a credit card and encumber us with admin such as vendor forms, we reserve the right to charge an administration fee of £50.
How is the software delivered?
The software needs to be downloaded from our website, the licence key is delivered electronically by email.
What is the part number?
There is no part number or SKU.
What is the reseller price?
We do not offer discounted rates for resellers. The pricing is £199 / €245 / $279 USD per annum per person.
Where can I get company information?
On our contact page.
Where can I get licensing terms?
Licensing details can be found here.
Where can I get Form W-9 information?
Screaming Frog is a UK based company, so this is not applicable.
Installation
Why does the Installer take a while to start?
This is often due to Windows Defender running a security scan on it, which can take up to a couple of minutes. Unfortunately when downloading the file using Google Chrome it gives no indication that it is running the scan.
Internet Explorer does give an indication of this, and Firefox does not scan at all.
If you go directly to your downloads folder and run the installer from there you don’t have to wait for the security scan to run.
Why do I get “error opening file for writing” when installing?
Please reboot your computer and restart the installation process.
Can I do a silent install?
Yes, please see our User Guide.
Can the SEO Spider work on a Chromebook?
We don't have a Chromebook version of the SEO Spider, however, since 2018, Chromebooks have been able to run a Linux VM natively meaning that our Ubuntu download will open straight from the Chrome OS.
The SEO Spider may need some packages that haven't been installed by default, so for those not familiar with Linux, it's worth familiarising yourself a little bit with some basic commands. The Reddit Crostini site is an excellent place to start. A package which is required is mscorefonts, so if this isn't installed, the latest version can be downloaded from here using the following command in the linux terminal:
wget http://ftp.us.debian.org/debian/pool/contrib/m/msttcorefonts/ttf-mscorefonts-installer_3.8.1_all.deb
Currently version 3.8.1 is the latest but check for the newest version in the filename. To install the package use:
sudo dpkg -i ttf-mscorefonts-installer_3.8.1_all.deb
Once installed, the SEO Spider can be simply opened in the Chrome OS by double-clicking the icon.
On older Chromebooks, you can install Crouton, set up Ubuntu and download and install the Ubuntu version of the SEO Spider.
Please note, most Chromebook's hardware is not very powerful by design and RAM is normally limited. This will mean the number of URLs that can be crawled in memory mode will be restricted. You can read more about SEO Spider memory in our user guide.
Why doesn't the SEO Spider start after installation on Windows?
We occasionally see start-up issues related to font settings. If this is the issue, then users will need to reset some font-related settings to fix it.
The signature for this issue in the logs ('Help > Debug > Save Logs' and within the 'trace.txt' file located C:\Users\Your Name\.ScreamingFrogSEOSpider) is -
java.lang.RuntimeException: Exception in Application init method
at com.sun.javafx.application.LauncherImpl.launchApplication1(LauncherImpl.java:895)
at com.sun.javafx.application.LauncherImpl.lambda$launchApplication$2(LauncherImpl.java:195)
at java.base/java.lang.Thread.run(Unknown Source)
Caused by: java.lang.ExceptionInInitializerError
at seo.spider.serps.SERPHelpers.init(SERPHelpers.java:79)
at seo.spider.serps.SERPHelpers.
at seo.spider.serps.SERPItemFactory.createGoogleDesktopSERPItem(SERPItemFactory.java:54)
at seo.spider.config.SpiderFilterWatermarkConfig.
at seo.spider.config.SpiderConfigPersistableState.
at seo.spider.config.AbstractSpiderConfig.
at seo.spider.config.DiffDivertSpiderConfig.
at seo.spider.results.SpiderResults.
at uk.co.screamingfrog.seospider.StartupCheckers.performAll(StartupCheckers.java:46)
at uk.co.screamingfrog.seospider.SeoSpider.createContext(SeoSpider.java:83)
at uk.co.screamingfrog.seospider.ui.SeoSpiderUi.init(SeoSpiderUi.java:146)
at com.sun.javafx.application.LauncherImpl.launchApplication1(LauncherImpl.java:824)
... 2 more
Caused by: java.lang.IllegalArgumentException: 1009298 incompatible with Text-specific LCD contrast key
at java.desktop/java.awt.RenderingHints.put(Unknown Source)
at java.desktop/sun.awt.windows.WDesktopProperties.getDesktopAAHints(Unknown Source)
at java.desktop/sun.awt.windows.WToolkit.getDesktopAAHints(Unknown Source)
at java.desktop/sun.awt.SunToolkit.getDesktopFontHints(Unknown Source)
at java.desktop/sun.awt.windows.WDesktopProperties.getProperties(Unknown Source)
at java.desktop/sun.awt.windows.WToolkit.lazilyInitWProps(Unknown Source)
at java.desktop/sun.awt.windows.WToolkit.lazilyLoadDesktopProperty(Unknown Source)
at java.desktop/java.awt.Toolkit.getDesktopProperty(Unknown Source)
at java.desktop/javax.swing.UIManager.
To reset ClearType settings and solve this issue, on Windows 10 users need to follow these steps:
- 1. Open the Settings app
- 2. Navigate to Personalisation
- 3. Click on Fonts in the left-hand navigation bar
- 4. In the top right, click the “Adjust ClearType text” link
- 5. Leave ClearType turned on, and click “Next”
- 6. Follow the wizard, selecting the best-looking text sample in each step
- 7. Click finish at the end
- 8. Restart the computer (or log out and log back in)
The font settings should now be reset, and the SEO Spider should launch.
Do you have a server version?
Every version of the SEO Spider is a server version and always has been. You’re able to run the SEO Spider locally on your PC or a dedicated machine, or remotely on a dedicated server or in the cloud.
This allows users to –
- 1) Access all crawls via ‘File > Crawls’ (in database storage mode). Using RDC multiple users are able to view crawls.
- 2) Crawl multiple sites concurrently.
- 3) Access crawl data from anywhere in the world.
- 4) Crawl millions of URLs. Though, you don’t really need a server to do this. Just a reasonably powerful machine using database storage mode.
- 5) Still run crawls locally on your own machine.
You can also still choose whether to run on Windows, macOS or Linux depending on your server choice.
Every user accessing the machine will require their own user licence.
We have a guide for running the SEO Spider in the cloud.
Do You Need To Run Crawls On A Server?
No.
Most modern machines are more than capable enough to allow you to crawl websites while performing other work at the same time. Even for larger crawls of millions of URLs.
You can share crawls and exports with team mates by saving/exporting crawls and exporting any data.
Setup
What hardware is recommended?
TL;DR: A 64-bit OS is required to run the SEO Spider. To be able to crawl millions of URLs, an SSD and 16GB of RAM is recommended.
Hard Disk: We highly recommend an SSD and using database storage to crawl large websites. A 500GB SSD will suffice, but 1TB is recommended if you're performing lots of crawls. If you don't have an SSD, you will need to use the memory storage, where crawl data is kept in RAM. Please see our guide on storage modes.
Memory: The SEO Spider stores all crawl data in a database by default, which allows it to crawl large websites. However, the more RAM you have allocated within the SEO Spider, the more URLs you will be able to crawl in both database storage, and the older memory storage mode. Each website is unique in terms of how much memory it requires, so we cannot give exact figures on how much memory is required to crawl a certain number of URLs. As a rough guide, 4GB of memory allocated to the SEO Spider in database storage mode should allow for crawling up to 2 million URLs. 8GB of memory allocated will generally allow you to crawl about 200,000 URLs in memory storage mode. Please see our guide on memory allocation.
CPU: The speed of a crawl will normally be limited by the website itself, rather than the SEO Spider, as most sites limit the number of concurrent connections they will accept from a single IP. When crawling hundreds of thousand URLs some operations will be limited by CPU, such as sorting and searching, so a fast CPU will help minimise these slowdowns.
Recommended Set-up: Our recommended set up is a machine with a 1TB SSD and 16GB of RAM. We recommend using the default database storage mode ('File > Settings > Storage Mode') and allocating 4GB of RAM ('File > Settings > Memory Allocaton') for all crawls up to 2m URLs.
How do I crawl millions of URLs?
We recommend using a machine with an SSD and ensure you are using database storage mode ('File > Settings > Storage Mode' on Windows or Linux, or 'Screaming Frog SEO Spider > Settings > Storage Mode' on macOS). This auto stores all data to disk, rather than keeping it in RAM - and allows you to crawl more URLs.
We then recommend increasing memory allocation to 4GB of RAM in the tool ('File > Settings > Memory Allocation') to crawl up to 2m URLs.
To crawl more than 2m URLs, you'll need to allocate more RAM. Please read our how to crawl large websites tutorial.
When using database storage, you will no longer be required to click 'File > Save' to store crawls, as they are auto saved and are accessible via the 'File > Crawls' menu.
The main benefits to database storage compared to the older memory storage format:
- 1) You can crawl more URLs.
- 2) Opening crawls is much quicker, nearly instant even for large crawls.
- 3) Crawls are auto saved, so you can just go and open it via 'File > Crawls'. If you lose power, accidentally clear, or close a crawl, it won't be lost forever.
- 4) You can peform crawl comparison, change detection and utilise segments.
You can export the database file, or as a .seospider crawl file still if you need to share the crawl for another user to open, and memory storage mode works the same way. Please read our guide on saving, opening, exporting and importing crawls.
What operating systems does the SEO Spider run on?
A 64-bit OS is required to run the SEO Spider. It runs on Windows, macOS and Linux.
It’s a Java application, that includes a bundled runtime - there's no need to install Java separately. You can download the SEO Spider for free to try it on your system.
Windows: The SEO Spider can be run on Windows 10 and 11, and server variants. The SEO Spider doesn't run on Windows XP.
The fully supported Windows variants are:
- Windows 11
- Windows 10
- Windows Server 2022
- Windows Server 2019
- Windows Server 2016
The SEO Spider may work on older Windows variants, but these have not been tested - and not all features may work as expected.
macOS: macOS 11 (Big Sur) or later. If you are running macOS version 10.14 "Mojave" or 10.15 "Catalina" you will not be able to use version 19.3 or later unless you update your operating system. This is available to licenced users only and can be requested by contacting support. We do not support macOS versions below 10.7.3 (and 32-bit Macs).
Linux: We provide an Ubuntu and Fedora package for Linux.
Please note that the rendering feature is not available on older operating systems.
What version of Java is used?
The latest version uses Java Adoptium, which is an OpenJDK distribution.
This does not require a licence to use.
You can view the version of Java used in the software, by navigating to 'Help > Debug' and viewing the 'Java Info' line. As of writing, version 23 uses Java 21. However, this is updated in regular intervals.
We use the latest stable version available that is compatible with components used in the SEO Spider.
Why do I get error initialising embedded browser on startup?
This is normally triggered by some third-party software, such as a firewall or antivirus. Please try disabling this or adding an exception.
The exception you need to add varies depending on what operating system you are using:
Windows:
C:\Users\YOUR_USER_NAME\.ScreamingFrogSEOSpider\chrome\VERSION_NUMBER\chrome.exe
macOS:
~/.ScreamingFrogSEOSpider/chrome/VERSION_NUMBER/Chromium.app
You will still be able to use the SEO Spider, but enabling JavaScript rendering mode will not be possible.
You can prevent this initialisation happening by going to 'File > Settings> Embedded Browser'.
How do I increase memory?
Please see the how to increase memory section in our user guide.
The TL;DR is: If you have experienced a memory warning, crash or are trying to perform large crawls, we recommend using a machine with an SSD and switching to database storage mode ('File > Settings > Storage Mode'). We recommend increasing memory allocation to 4GB of RAM in the tool via 'File > Settings > Memory Allocation' to crawl up to 2m URLs.
To crawl more than 2 URLs, you'll need to allocate more RAM. Please read our how to crawl large websites tutorial.
Why is the JVM failing to allocate memory?
This crash is caused by the Java Virtual Machine trying to allocate memory from your operating system and there not being enough memory available. This can be caused by a number of reasons:
- Memory being used by other applications.
- Multiple instances of the SEO Spider running.
- Allocating too much memory to the SEO Spider.
To avoid you have the following options:
- Switch to database mode.
- Reduce the amount of memory allocated to the SEO Spider, see User Guide.
- Reduce the amount of memory used by other applications running on your machine by running fewer of them when running the SEO Spider.
- Run fewer instances of the SEO Spider (check for concurrent scheduling).
For example:
- If you have 16GB of system RAM and allocate 8GB to the SEO Spider, running 2 instances as the same time will leave no memory for the operating system and other applications.
- If you have 8GB of system RAM and allocate 6GB to the SEO Spider, you'll only have 2GB available for other applications and the operating system.
Why am I running out of disk space?
When using database storage mode the SEO Spider monitors how much disk space you have and will automatically pause if you have less than 5GB remaining. If you receive this warning you can free up some disk space to continue the crawl.
If you are unable to free up any disk space, you can either configure the SEO Spider to use another drive with more space by going to 'File > Settings > Storage Mode' and selecting a folder on another disk, or switch to 'Memory Storage' via the same configuration.
Changing either of these settings requires a restart, so if you'd like to continue the current crawl you will have to export it and reload it in after restarting.
Can I use an external SSD?
If you don't have an internal SSD and you'd like to crawl large websites using database storage mode, then an external SSD can help.
There are a few things to remember with this set-up. It's important to ensure your machine has USB 3.0 and your system supports UASP mode. Most new systems do automatically, if you already have USB 3.0 hardware. When you connect the external SSD, ensure you connect to the USB 3.0 port, otherwise reading and writing will be slow.
USB 3.0 ports generally have a blue inside (as recommended in their specification), but not always; and you will typically need to connect a blue ended USB cable to the blue USB 3.0 port. Simple!
After that, you need to switch to database storage mode ('File > Settings > Storage Mode'), and then select the database location on the external SSD (the 'D' drive in the example below).
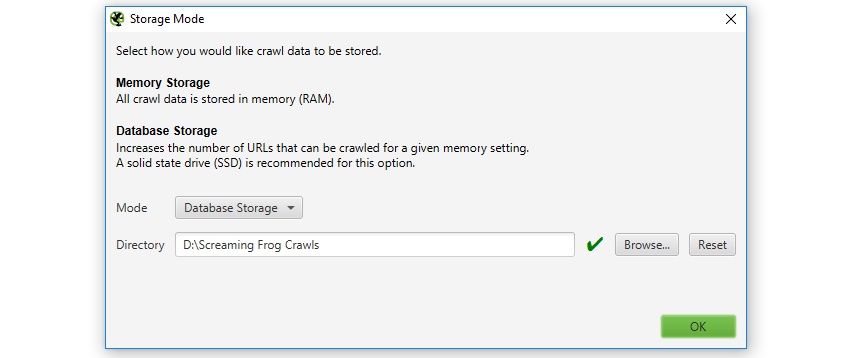 You will then need to restart the SEO Spider, before beginning the crawl.
You will then need to restart the SEO Spider, before beginning the crawl.
Please note - ExFAT/MS-DOS (FAT) file systems are not supported on macOS due to JDK-8205404. You will need to reformat the drive to another file system to use it, which is typically a simple task.
Interface Issues
Why is the UI unresponsive after reconnecting via RDP/VNC?
If the SEO Spider user interface isn't rendering for you, then the chances are you've run into this Java bug. This can be worked around by performing the following steps:
Close the SEO Spider, then open up the following file in a text editor:
C:\Program Files (x86)\Screaming Frog SEO Spider\ScreamingFrogSEOSpider.l4j.ini
then add the following under the -Xmx line:
-Dprism.order=sw
(You may have a permission issue here, so copying your desktop, editing, then copying back may be easier).
Now when you start the SEO Spider the user interface should repaint correctly.
Why do I get a blank / flashing screen?
If the SEO Spider user interface isn't rendering for you, then the chances are you've run into this Java bug. In our experience this seems to be an issue with Intel HD 5xx series graphics cards. We've had less of these recently, so a driver update might help resolve this issue.
If not, please close the SEO Spider, then open up the following file in a text editor:
C:\Program Files (x86)\Screaming Frog SEO Spider\ScreamingFrogSEOSpider.l4j.ini
then add the following under the -Xmx line:
-Dprism.order=sw
(You may have a permission issue here, so copying your desktop, editing, then copying back may be easier).
Now when you start the SEO Spider the user interface should render correctly.
Why is the GUI text/font text garbled?
This is related to fonts on the machine.
To solve the issue, please ensure you're using the latest version of the SEO Spider.
Please contact us via support if you're still having issues.
Why is the title bar still grey in dark mode on Windows?
The colour of the Windows title bar is controlled by the operating system.
 You can change the colour by going to the search menu and typing in 'Settings', then 'Personalisation' and 'Colours'.
You can change the colour by going to the search menu and typing in 'Settings', then 'Personalisation' and 'Colours'.
You're then able to choose a dark accent colour under 'Choose your accent colour', and tick the 'title bars and window borders' button at the bottom.
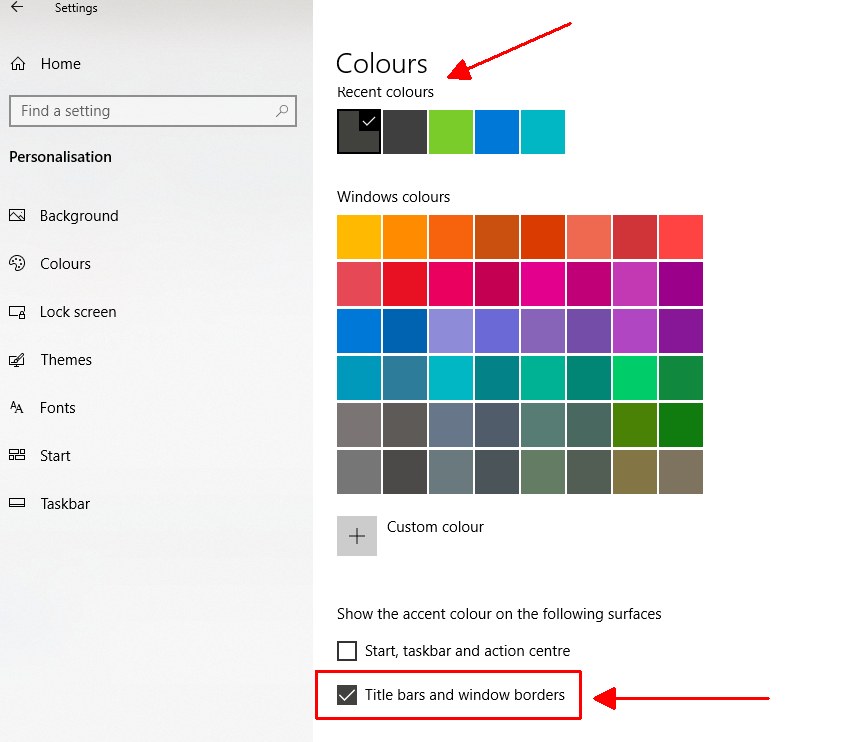 It will then match the rest of the application.
It will then match the rest of the application.
 Please note - The title bar will return to a grey colour when the application is not in focus still. This is a Windows thing.
Please note - The title bar will return to a grey colour when the application is not in focus still. This is a Windows thing.
Why does the Spider show in the taskbar but not on screen?
The SEO Spider is opening off screen, possibly due to a multi monitor setup that has recently changed.
To move the SEO Spider on to the active monitor use Alt + Tab to select it, then hold in the Windows key and use the arrow keys to move it window into view.
Why does the SEO Spider freeze?
This will generally be due to the SEO Spider reaching its memory limit. Please read how to increase memory.
Why am I experiencing slow down?
There are a number of reasons why you might be experiencing slow crawl rate or slow down of the SEO Spider. These include –
- If you’re performing a large crawl, you might be reaching the memory capacity of the SEO Spider. Learn how to increase the SEO Spider’s memory and read our guide on crawling large websites.
- Slow response of the site or server (or specific directives for hitting them too hard).
- Internet connection.
- Problems with the site you are crawling.
- Large pages or files.
- Crawling or viewing a large number of URLs.
Crawl Issues
Why won’t the SEO Spider crawl my website?
This could be for a number of reasons outlined below:
- The very first thing to look at is the status code and status in the Internal tab. The site should respond with a 200 status code and 'OK' status. However, if it doesn't, please read our guide on common HTTP status codes when crawling, what they mean and how to resolve any issues.
- The site is blocked by robots.txt. The 'status code' column in the internal tab will be a '0' and the 'status' column for the URL will say 'Blocked by Robots.txt'. You can configure the SEO Spider to ignore robots.txt under 'Configuration > Robots.txt > Settings'.
- The site behaves differently depending on User-Agent. Try changing the User-Agent under Configuration->HTTP Header->User Agent.
- The site requires JavaScript. Try looking at the site in your browser with JavaScript disabled after clearing your cache. The SEO Spider does not execute JavaScript by default, however it does have JavaScript rendering functionality in the paid version of the tool. If the site is built in a JavaScript framework, or has dynamic content, adjust the rendering configuration to 'JavaScript' under 'Configuration > Spider > Rendering tab > JavaScript' to crawl it. Remember to ensure JS and CSS files are not blocked by robots.txt. Please see our guide on how to crawl JavaScript websites.
- The site doesn't link to pages using proper crawlable a tags.
- The site requires Cookies. Can you view the site with cookies disabled in your browser after clearing your cache? Licensed users can enable cookies by going to Configuration->Spider and ticking “Allow Cookies” in the “Advanced” tab.
- The ‘nofollow’ attribute is present on links not being crawled. There is an option in 'Configuration > Spider' under the 'Crawl' tab to follow ‘nofollow’ links.
- The page has a page level ‘nofollow’ attribute. The could be set by either a meta robots tag or an X-Robots-Tag in the HTTP header. These can be seen in the 'Directives' tab in the 'Nofollow' filter. To ignore the nofollow directive go to 'Configuration > Spider > Crawl' and tick 'Follow Internal nofollow' under the 'crawl behaviour section' and recrawl.
- The website is using framesets. The SEO Spider does not crawl the frame src attribute.
- The website requires an Accept-Language header (Go to 'Configuration > HTTP Header' and add a header called 'Accept Language' with a value of 'en-gb').
- The website requires you to prove you are not a bot before crawling via a Captcha (Go to 'Configuration > Authentication > Forms Based').
- The Content-Type header did not indicate the page is HTML. This is shown in the Content column and should be either
text/htmlorapplication/xhtml+xml. JavaScript rendering mode will additionally inspect the page content to see if it's specified, eg:<meta http-equiv="content-type" content="text/html; charset=UTF-8">. If the content-type is not set in either the header or HTML, then use the 'Assume Pages are HTML' config. - The configuration is limiting the crawl. Reset to the default configuration to ensure this is not occurring 'File > Configuration > Clear Default Configuration'.
If the above does not help, please get in touch with details of the website, the status and status code you're experiencing via support.
Why do I get a “Connection Refused” response?
Connection refused is displayed in the 'Status' column when the SEO Spider's connection attempt has been refused at some point between the local machine and website. If this happens for all sites consistently then it is an issue with the local machine/network. Please check the following:
- You can view websites in your browser.
- Make sure you have the latest version of the SEO Spider installed.
- That software such as ZoneAlarm, anti-virus (such as the premium version of Avira Antivirus, and Kaspersky) or firewall protection software are not blocking your machine/SEO Spider from making requests. The SEO Spider needs to be trusted / accepted. We recommend your IT team is consulted on what might be the cause in office environments.
- The proxy is not accidentally ‘on’, under 'File > Settings > Proxy'. Ensure the box is not ticked, or the proxy details are accurate and working.
If this is preventing you from crawling a particular site, then this is typically due to the server either refusing connection to the user-agent, or it uses anti bot protection software. Please try the following -
- Changing the User Agent under 'Configuration > User Agent'. Try switching to 'Chrome', the server might be refusing requests made from particular user-agents. A ‘Googlebot’ user-agent is also worth testing, although it is not unusual for sites to block a spoofed Googlebot.
- Use Forms Based Authentication under 'Configuration > Authentication > Forms Based'. Add the website into our inbuilt browser, and view the site to see if a captcha needs to be completed. Click 'OK' and 'OK' to accept any cookies and see if you're able to crawl.
- Our recommended approach is to add your IP address and the 'Screaming Frog SEO Spider' user-agent to an allowlist in the website's CDN security settings to be able to crawl it. Your CDN provider will be able to advise on how to do this.
If this is happening intermittently during a crawl then please try the following:
- Adjusting the crawl speed / number of threads under 'Configuration > Speed'.
- In the ‘lite’ version where you cannot control the speed, try right clicking on the URL and choosing re-spider.
- Our recommended approach is to add your IP address and the 'Screaming Frog SEO Spider' user-agent to an allowlist in the website's CDN security settings to be able to crawl it. Your CDN provider will be able to advise on how to do this.
Why do I get a “Connection Error” response?
Connection error or connection timeout is a message when there is an issue in receiving an HTTP response at all.
This is generally due to network issues or proxy settings. Please check that you can connect to the internet.
If you have changed the SEO Spider proxy settings (under 'File > Settings > Proxy'), please ensure that these are correct (or they are disabled).
Why do I get a “Connection Timeout” response?
Connection timeout occurs when the SEO Spider struggles to receive an HTTP response at all and the request times out.
It can often be due to a slow responding website or server when under load, or it can be due to network issues. We recommend the following –
- Ensure you can view the website (or any websites) in your browser and check their loading time for any issues. Hard refresh your browser to ensure you’re not seeing a cached version.
- Decrease the speed of the crawl in the SEO Spider configuration to decrease load on any servers struggling to respond. Try 1 URL per second for example.
- Increase the default response timeout configuration of 10 seconds, up to 20 or 30 seconds if the website is slow responding.
If you're experiencing this issue for every website, please try the following -
- Ensure the proxy settings are not enabled accidentally and if enabled that the details are accurate. This can be viewed via 'File > Settings > Proxy' in the app.
- Ensure that ZoneAlarm, anti virus or firewall protection software (such as the premium version of Avira Antivirus) are not blocking your machine from making requests. The SEO Spider needs to be trusted / accepted. We generally recommend your IT team who know your systems are consulted on what might be the cause.
Why do I get a “403 Forbidden” error response?
The 403 forbidden status codes occurs when a web server or security platform denies access to the SEO Spider’s request. Some security platforms may try and detect bots from real users. A server can also respond with a 400 Bad Request or 406 Not Acceptable, which are similar and have the same solutions.
If this happens consistently and you can see the website in a browser, it's often because the server is behaving differently to the user-agent of the request.
In the paid version of the SEO Spider, adjust the User Agent via 'Config > User-agent' and try crawling as a browser, such as ‘Chrome’. This request is often allowed and solves the problem.
If switching the user-agent doesn't solve the problem, then the following should be performed -
- Try crawling in JavaScript rendering mode. This can be enabled via 'Config > Spider > Rendering' and choosing 'JavaScript'.
- Verify it's a security issue by going to 'Config > Authentication > Forms Based', clicking 'Add' and entering the websites homepage into our inbuilt browser. You should see a security based message from the security provider. If there is a captcha or puzzle to solve, you might be able to complete it, verify you're human and crawl. However, often this can fail.
If both of the above fail, you will need to add your IP address and the 'Screaming Frog SEO Spider' user-agent to an allowlist in the website's security or hosting platform settings to be able to crawl it. This is our recommended solution and your provider will be able to advise on how to do this.
If the 403 response occurs intermittently during a crawl, it could be due to the speed the SEO Spider is requesting pages, which is overwhelming the server. In the paid version of the SEO Spider you can reduce the speed of requests. If you are running the free version you may find that right clicking the URL and choosing re-spider will help.
Please note - It's common for sites to block a spoofed Googlebot request, as CDNs such as Cloudflare check to see whether the request has been made from the known Google IP range, as part of their bot protection of their managed firewalls.
Please see our FAQ on how to crawl with Googlebot for sites that use Cloudflare.
Why do I get a "429 Too Many Requests" error response?
This occurs when the web server indicates that too many HTTP requests have been made by the SEO Spider in a set period of time. This is known as 'rate limiting', and is often based upon the user-agent and IP address.
It can often be a default security platform response to a user-agent that it believes might be a bot.
In the SEO Spider you can adjust the following to help -
- Adjust the user-agent to 'Chrome' via 'Config > User-agent'.
- Reduce the crawl speed via 'Config > Speed'.
However, our recommended approach is to add your IP address and the 'Screaming Frog SEO Spider' user-agent to an allowlist in the server or security platform settings to be able to crawl it, without triggering the "429 Too Many Requests" error. Your provider will be able to advise on how to do this.
If the site is Shopify, then you will need to set up web bot auth and HTTP message signatures to let you securely authorize your own crawlers, scripts, or tools to access your public Shopify online store.
Check out Shopifys guide on crawling your store to set this up. To add your signatures to the HTTP headers of your requests, you can use custom HTTP Headers.
They should look like this, but with 'Your signature input value' and 'Your signature value' replaced with the real values.
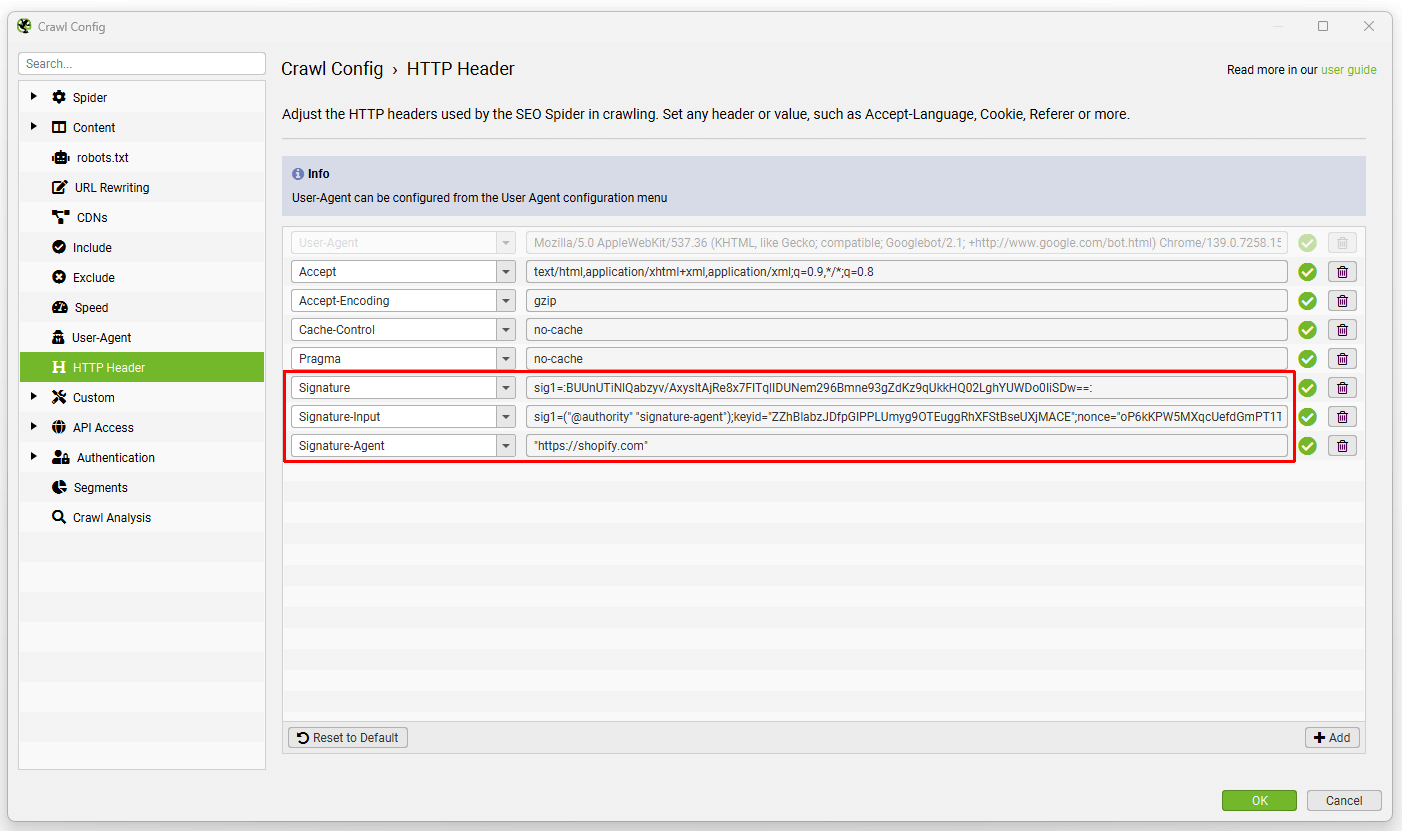
Please ensure you copy every value, do not try and type any of them into the fields as they will be prone to subtle mistakes. When set up correctly, it will mean you won't keep receiving 429 errors when you crawl your store.
Why do I get a "429 Too Many Requests" error response crawling a Shopify site?
This occurs when the web server indicates that too many HTTP requests have been made by the SEO Spider in a set period of time. This is known as 'rate limiting', and is often based upon the user-agent and IP address.
It can often be a default security platform response to a user-agent that it believes might be a bot. In this case, it is Cloudflare that is used by Shopify.
To crawl a Shopify site reliably and not receive '429 Too Many Requests' errors, then you will need to set up web bot auth and HTTP message signatures to let you securely authorize your own crawlers, scripts, or tools to access your public Shopify online store.
Check out Shopifys guide on crawling your store to set this up. To add your signatures to the HTTP headers of your requests, you can use custom HTTP Headers.
They should look like this, but with 'Your signature input value' and 'Your signature value' replaced with the real values.
Please ensure you copy every value, do not try and type any of them into the fields as they will be prone to subtle mistakes. When set up correctly, it will mean you won't keep receiving 429 errors when you crawl your store.
Tips If You Continue To Experience 429 Errors
- It can take 30mins -1hr to propogate with Shopify, particularly if you have already been crawling and received 429 errors. There is nothing we can do about this behaviour, it is Shopify's system.
- Please ensure you copy and paste the values into the relevant fields directly from Shopify. Do not attempt to write any of the x3 header values into the header fields, as it will be prone to mistakes. We often see the Signature-Agent value which has shopify.com in it include a trailing slash on the end for example, when it shouldn't have one. This will mean it doesn't work. So copy and paste in every single value.
- If you have entered the custom headers via 'Config > HTTP Header', then restarted the app, they might not be present if you haven't saved your config and loaded it in or set it as default. So be sure you're crawling with it enabled.
- Shopify HTTP message signatures expire after 90 days by default. If they used to work, but do not now, check the expiry.
Typically there will be one of the issues above. If the above tips do not help, then we recommend speaking to Shopify directly.
Why do I get a "500 Internal Server Error" response?
This occurs when the web server indicates that the server encountered an unexpected condition that prevented it from fulfilling the request.
It is a generic 'catch-all' response that can mean the server cannot find a better 5xx error code to respond with.
500 Internal Server Errors can often be valid and lead to an error page for users.
If the page does not error for a user in a browser, then it might be due to the server responding differently to the SEO Spider's requests when under load, or due to security.
If the server is responding differently, then we recommend the following -
- Adjust the user-agent to 'Chrome' via 'Config > User-agent'.
- Reduce the crawl speed via 'Config > Speed'.
- Add your IP address and the 'Screaming Frog SEO Spider' user-agent to an allowlist in the server or CDN security settings.
Why do I get a "502 Bad Gateway" Error response?
This occurs when the web server indicates that the server (while acting as a gateway or proxy) received an invalid response from the upstream server.
If the page does not error for a user in a browser, then it might be due to the server responding differently to the SEO Spider's requests when under load, or due to security.
If the server is responding differently, then we recommend the following -
- Adjust the user-agent to 'Chrome' via 'Config > User-agent'.
- Reduce the crawl speed via 'Config > Speed'.
- Add your IP address and the 'Screaming Frog SEO Spider' user-agent to an allowlist in the server or CDN security settings.
Why do I get a “503 Service Unavailable” error response?
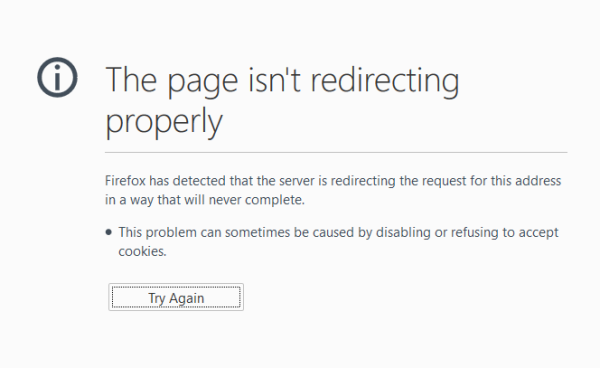
Why do URLs redirect to themselves?
When a website requires cookies this often appears in the SEO Spider as if the starting URL is redirecting to itself or to another URL and then back to itself (any necessary cookies are likely being dropped along the way). This can also be seen when viewing in a browser with cookies disabled:
The easiest way to work around this issue is to first load up the page using forms based authentication.
‘Configuration > Authentication > Forms Based’
Select ‘Add’, then enter the URL that is redirecting, and wait for the page to load before clicking ‘OK’.
The SEO Spider's in-built Chromium browser has thus accepted the cookies, and you should now be able to crawl the site normally.
A secondary method to bypass this kind of redirect is to ensure the ‘Cookie Storage’ is set to 'Persistent':
'Configuration > Spider > Advanced > Cookie Storage > Persistent'
To bypass the redirect behaviour, as the SEO Spider only crawls each URL once, a parameter must be added to the starting URL:
http://www.example.com/?rewrite-me
A URL rewriting rule that removes this parameter when the spider is redirected back to the starting URL must then be added:
'Configuration > URL Rewriting > Remove Parameters'
The SEO Spider should then be able crawl normally from the starting page now it has any required Cookies.
Why won’t my crawl complete?
We recommend checking that the SEO Spider is still crawling the site (by viewing the crawl speed and totals at the bottom of the GUI), and reviewing the URLs its been crawling.
It's normal for the crawl progress bar to change during a crawl, as the SEO Spider doesn't know how many URLs exist at the start of a crawl. As it crawls and discovers new URLs, they are added to the crawl queue. As an extreme example, it could reach 99% progress, and on the very last URL crawled discover another 10,000 URLs - which would see the progress bar suddenly drop!
Depending on the URLs the SEO Spider has been discovering in the crawl, it will explain why the crawl percentage is not increasing:
- URLs seem normal – The Spider keeps finding new URLs on a very large site. Consider splitting the crawl up into sections.
- Many similar URL parameters – The Spider keeps finding the same URLs with different parameters, possibly from faceted navigation. Use the 'URL > Parameters' tab and filter to help spot these. Try setting the query string limit to 0 ('Configuration > Spider > Limits > Limit Number of Query Strings', use the exclude or custom robots.txt feature.).
- There are many long URLs with parts that repeat themselves – There is a relative linking error where the Spider keeps finding URLs that cause a never-ending loop. These can often be identified via the 'URL > Repetitive Path' tab and filter. Use the exclude feature to exclude the offending URLs.
- There are lots of URLs in a single folder – This could indicate a crawlable calendar section with an infinite number of pages. Review the “Site Structure” tab in the right-hand window. Use the exclude feature to exclude the offending URLs.
It's possible to view URLs that are still in the crawl queue by exporting the 'Queued URLs' report under 'Bulk Exports' in the top-level menu. We also recommend reading our guide on how to crawl large websites, which has lots of practical tips.
Why am I seeing old data? Is there a cache?
There is no cache in the SEO Spider.
However, websites do have caches and your local system might as well, which might be why you're seeing older data, particularly if you've just made an update to the site.
Many CDNs include a cache related header in HTTP responses, which can help debug caching. To view them, enable 'HTTP Headers' via 'Config > Spider > Extraction', crawl the URL, and use the lower 'HTTP Headers' tab to see if there is a cache-hit or cache-miss header response and value.
To see the latest data, please ensure you have:
- Published any changes to the live website. Ensure you can see them in Incognito mode in Chrome.
- Purged your website / CDN cache.
- Some CDN's will purge caches in different ways. We recommend going to 'Config > User-agent' in the SEO Spider and selecting 'Chrome' and crawling again. This can sometimes mean the updated version of the site is crawled.
- Finally, restart your machine. Some networks will have outbound proxies which might cache.
If none of the above work, we recommend speaking to the site's developer to discuss why old data is still being seen.
Please note: If you've made updates such as correcting broken links, then merely re-crawling the source pages won't mean the URLs that 404 error will disappear from the SEO Spider. They will need to be deleted (right click 'remove'), or you will need to perform a new crawl.
Why do I get a ‘Project open failed java.io.EOFException’ when attempting to open a saved crawl?
This means the crawl did not save completely, which is why it can’t be opened. EOF stands for ‘end of file’, which means the SEO Spider was unable to read to the expected end of the file.
 This can be due to the SEO Spider crashing during save, which is normally due to running out of memory. This can also happen if you exit the SEO Spider during save, or your machine restarts or you suffer a powercut.
Unfortunately there is no way to open or retrieve the crawl data, as it’s incomplete and therefore lost.
This can be due to the SEO Spider crashing during save, which is normally due to running out of memory. This can also happen if you exit the SEO Spider during save, or your machine restarts or you suffer a powercut.
Unfortunately there is no way to open or retrieve the crawl data, as it’s incomplete and therefore lost.
Please consider switching to database storage mode where crawls are stored automatically (you don't need to 'save'), or increasing your memory allocation in memory storage mode, which will help reduce any problems saving a crawl in the future.
Why does JavaScript rendering not crawl any site & return a 0 status code?
This is generally due to anti-virus software on your machine stopping the headless Chrome browser from launching to run JavaScript rendering mode.
You can verify this by going to 'Help > Debug > Save Logs' in the SEO Spider, and then opening the 'trace.txt' file within the zip file logs.
You will see an error in the logs like this -
Cannot run program "C:\Users\your name\.ScreamingFrogSEOSpider\chrome\91.0.4472.77-sf1\chrome.exe": CreateProcess error=1260, This program is blocked by group policy. For more information, contact your system administrator
The chrome.exe file in this location needs to be given permission to run within any antivirus programs on your machine if it has blocked them.
How do I crawl sites that use Cloudflare?
Cloudflare security rules can be set to block requests made by the Screaming Frog SEO Spider or other automated bots. These will appear as a 403 'forbidden' error response in the SEO Spider.
You can read more about why a website might respond with a 403 error.
The most reliable, and sometimes only way to crawl websites with strict security rules is to configure the security platform to allow you to crawl them. Obviously you must have access to the security platform to be able to configure it.
To set this up in Cloudflare, login and go to 'Security > Security Rules'. Click 'Create Rule > Custom Rules' -
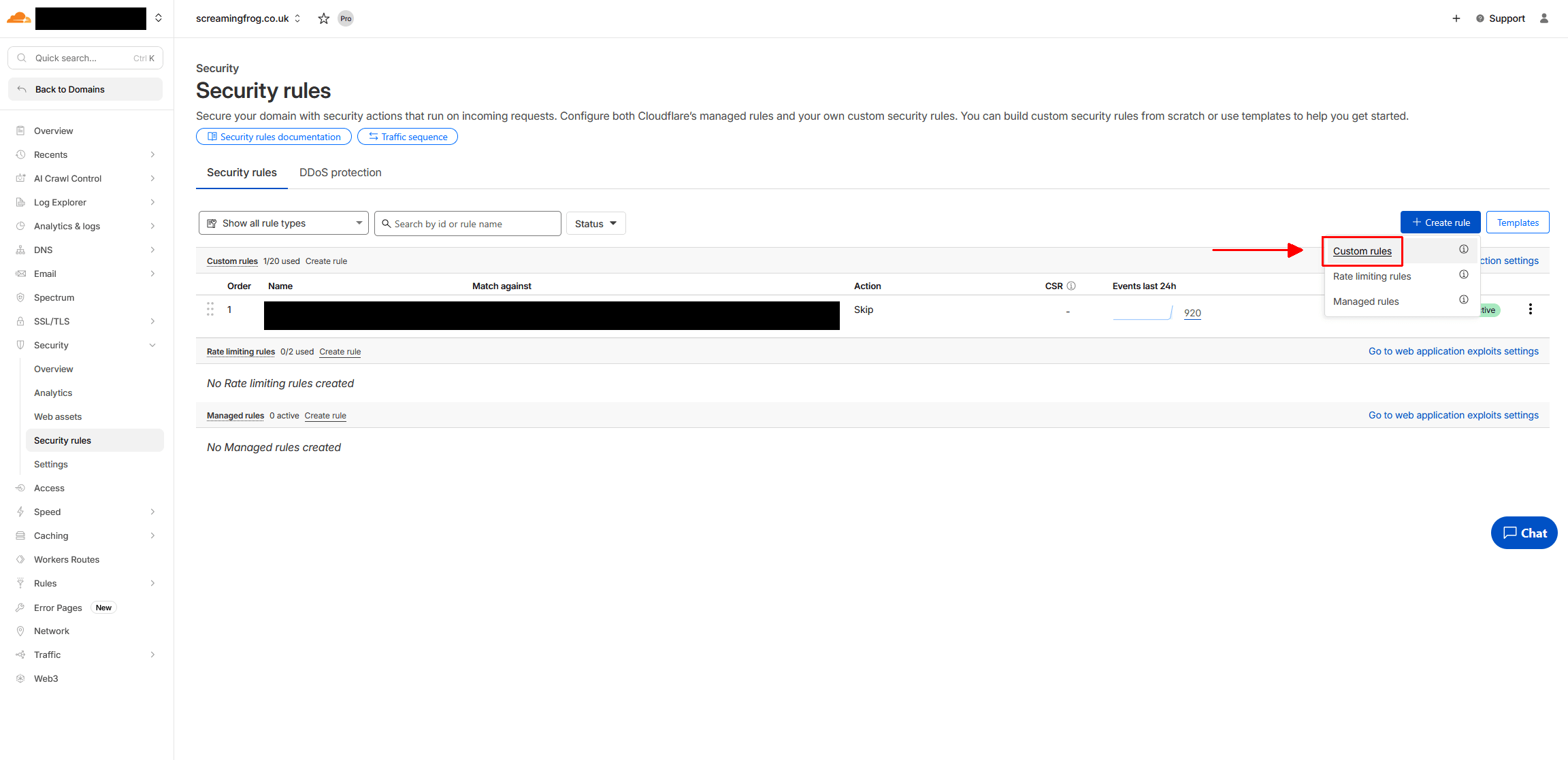
Now name the rule appropriately, and select the 'field' as 'IP Source Address' and enter your own public IP address that you're crawling from. If you're what your IP address is, just Google 'What is my IP address' from the machine you're crawling from.
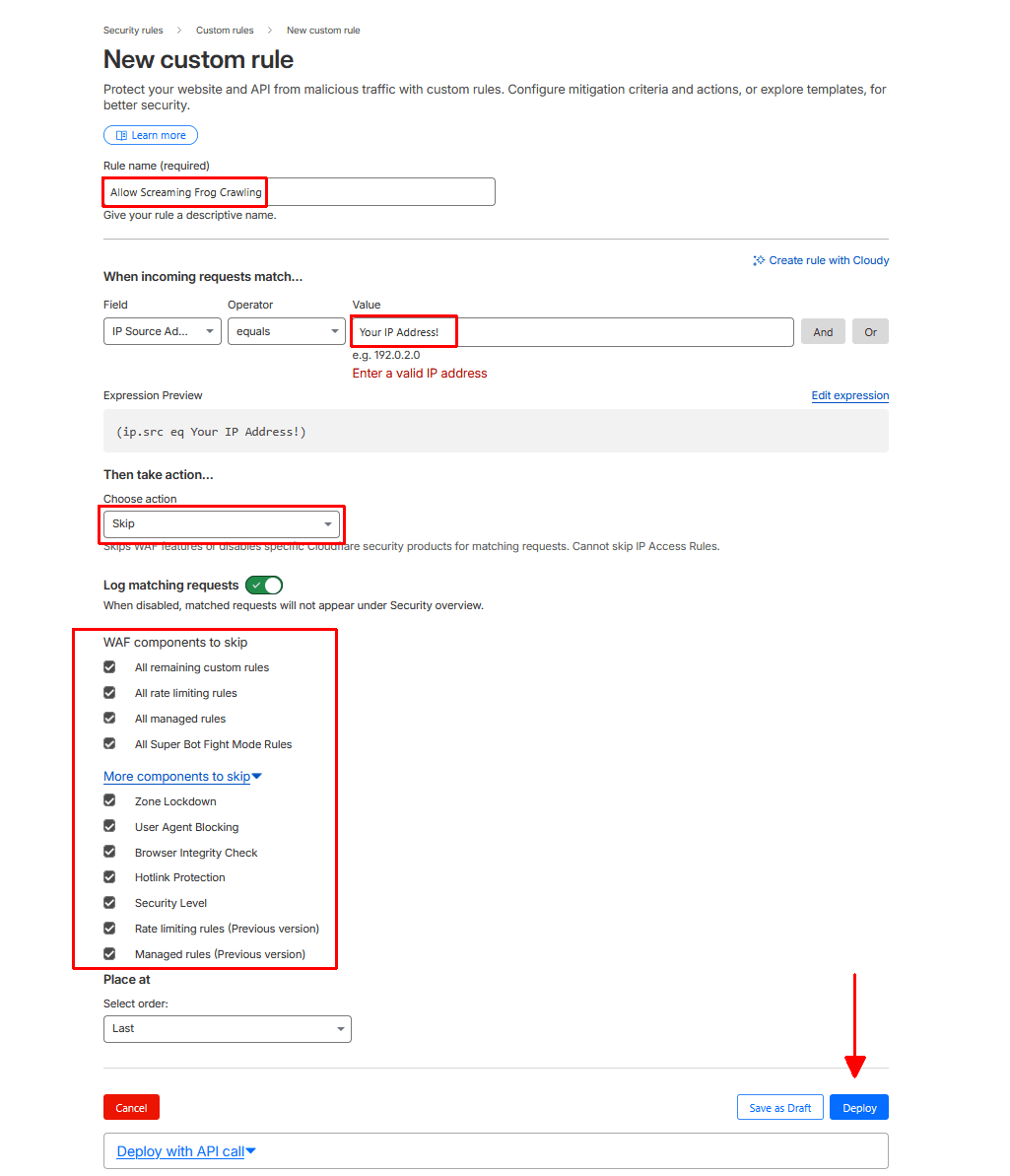
Select 'Skip' as the action, and enable all the relevant options under 'WAF components to skip' and 'More components to skip', before deploying.
When this has been updated, you should then be able to crawl the website without any problems using any user-agent (including spoofing as different Googlebot user-agent strings).
If this does not work for you, we recommend speaking to Cloudflare support directly, as they will be best placed to advise on their platform and your set up.
Configuration
Why do I get an 'Unexpected non-whitespace character error' after installing the Claude MCP extension?
This can be due to three reasons:
1) Using version 24, which has a bug related to some non-English languages causing this issue. Please update to use 24.1.
2) Installing the MCP extension, before installing version 24.1 of the software which has the MCP Server functionality.
3) The Claude MCP extension (spider-mcp.mcpb file) assumes the SEO Spider is installed in the default location. If it's installed in a different location, you can either install the SEO Spider to the default location, or edit spider-mcp.mcpb file to point to the correct location.
The Screaming Frog SEO Spider MCP was launched in version 24.1. So you need to download and install this version first.
If you have already installed the MCP Extension and now have this error, we recommend uninstalling it (Settings > Extensions > ... > Uninstall'), restarting Claude (ensuring it is fully shutdown via task manager or the tray icon), installing version 24.1 of the SEO Spider, and then installing the MCP Extension again.
If the error persists, restart Claude again.
This should then allow you to communicate with Claude.
How many URLs can the SEO Spider crawl?
The SEO Spider uses a configurable hybrid storage engine, which enables it to crawl millions of URLs. However, it does require the correct hardware and some configuration as outlined below.
In general the SEO Spider is recommended for crawls below 2 million URLs, however it is capable of crawling far more.
By default the SEO Spider will crawl in database storage mode, automatically saving URLs and data to disk, which helps it crawl at scale.
The SEO Spider will allocate 2GB of RAM for crawling by default. This will usually allow crawling between 100k - 1m URLs depending on the website.
To crawl more URLs, we recommend increasing memory allocation ('File > Settings > Memory Allocation') to 4GB of RAM. This will allow it typically to crawl up to 2m URLs.
To crawl up to 5m URLs, you'd likely need around 10GB of RAM allocated as an example.
Please see our guide on crawling large websites for more information.
What IP address and ports does the SEO Spider use?
The SEO Spider runs from the machine it is installed on, so the IP address is simply that of this machine/network. You can find out what this is by typing “IP Address” into Google.
The local port used for the connection will be from the ephemeral range. The port being connected to will generally be port 80, the default http port or port 443, the default HTTPS port. Other ports will be connected to if the site being crawled or any of its links specify a different port. For example: http://www.example.com:8080/home.html
Does the SEO Spider crawl PDFs?
Yes, the SEO Spider will crawl PDFs, discover links within them and show the document title as the page title and any PDF keywords as meta keywords.
This means users can check to see whether links within PDFs are functioning as expected and issues like broken links will be identified reported in the usual way.
Please read our guide on How To Audit PDFs for more detail.
The outlinks tab from PDFs will be populated, and include details such as response codes, anchor text and even what page of the PDF a link is on.
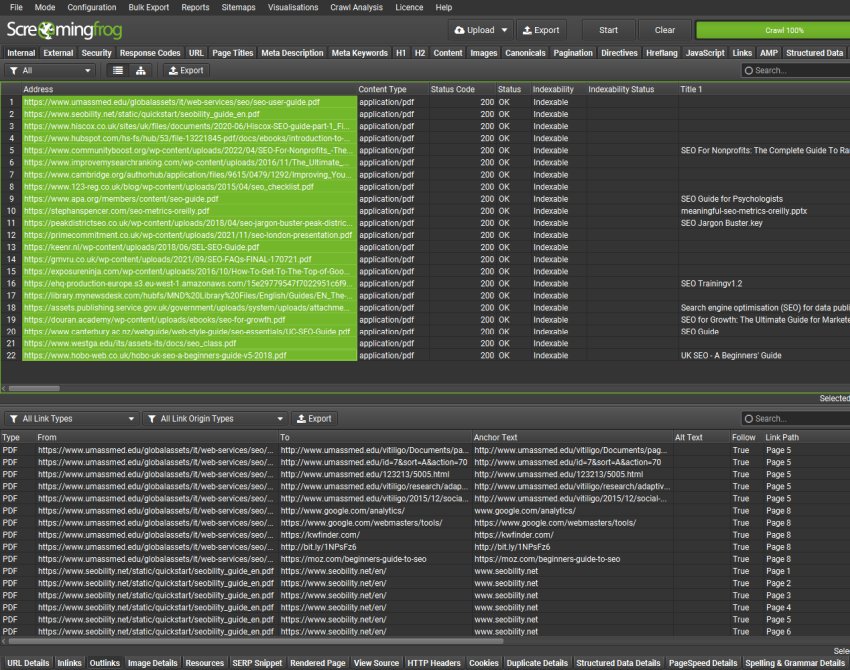
You can also choose to ‘Extract PDF Properties’ and ‘Store PDF’ under ‘Config > Spider > Extraction’ and the PDF subject, author, created and modified dates, page count and word count will be stored and shown as columns in the Internal tab.
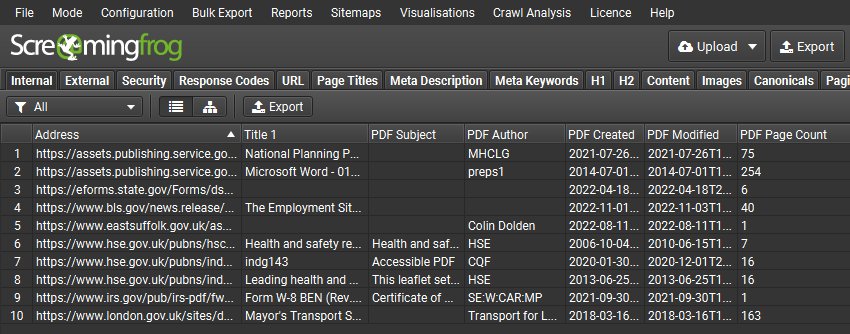
The text content of PDFs is also parsed, so features such as custom search and spelling and grammar checks can also be performed on PDFs.
PDFs can be bulk saved and exported via ‘Bulk Export > Web > All PDF Documents’.
If you’re interested in how search engines crawl and index PDFs, check out a couple of tweets where we shared some insights from internal experiments for both Google and Bing.
Why isn’t my Include/Exclude function working?
The Include and Exclude are case sensitive, so any functions need to match the URL exactly as it appears. Please read both guides for more information.
Functions will be applied to URLs that have not yet been discovered by the SEO Spider or are in the crawl queue to be processed. Any URLs that are currently being processed by the SEO Spider will not be affected.
Functions will not be applied to the starting URL of a crawl in Spider mode. However, they do apply to all URLs in list mode.
.* is the regex wildcard.
What’s the difference between ‘Crawl outside of start folder’ & ‘Check links outside folder’?
The ‘Crawl outside of start folder’ configuration means you can crawl an entire website from anywhere. As an example, if you crawl www.example.com/example/ with this configuration ticked, the SEO Spider will crawl the whole website. So this just provides nice flexibility on where you start, or if some (sometimes poor!) set-ups have ‘homepages’ as sub folders.
The ‘check links outside of folder’ option is different. It provides the ability to crawl ‘within’ a sub folder, but still see details on any URLs that they link out to which are outside of that sub folder. But it won’t crawl any further than this! An example –
If you started a crawl at www.example.com/example/ and it linked to www.example.com/different/ which returns a 404 page.
If you unticked the ‘check links outside of folder’ option, it wouldn’t crawl this 404 page as it sits outside the start folder. With it ticked, this page will be included under the ‘internal’ tab as a 404.
We felt users sometimes need to know about potential issues which start within the start folder, but which link outside. But at the same time, didn’t need to crawl the entire website! This option now provides that flexibility.
How does the SEO Spider treat robots.txt?
The SEO Spider is robots.txt compliant. It checks robots.txt in the same way as Google.
It will check robots.txt of the (sub) domain and follow directives specifically any for Googlebot, or for all user-agents. You are able to adjust the user-agent, and it will follow specific directives based upon the configuration.
The tool also supports URL matching of file values (wildcards * / $) like Googlebot. Please see the above document for more information or our robots.txt section in the user guide. You can turn this feature off in the premium version.
Can the SEO Spider crawl staging or development sites that are password protected or behind a login?
The SEO Spider supports two forms of authentication, standards based which includes basic and digest authentication, and web forms based authentication.
Basic & Digest Authentication
There is no set-up required for basic and digest authentication, it is detected automatically during a crawl of a page which requires a login. If you visit the website and your browser gives you a pop-up requesting a username and password, that will be basic or digest authentication. If the login screen is contained in the page itself, this will be a web form authentication, which is discussed in the next section.
Often sites in development will also be blocked via robots.txt as well, so make sure this is not the case or use the ‘ignore robot.txt configuration'. Then simply insert the staging site URL, crawl and a pop-up box will appear, just like it does in a web browser, asking for a username and password.
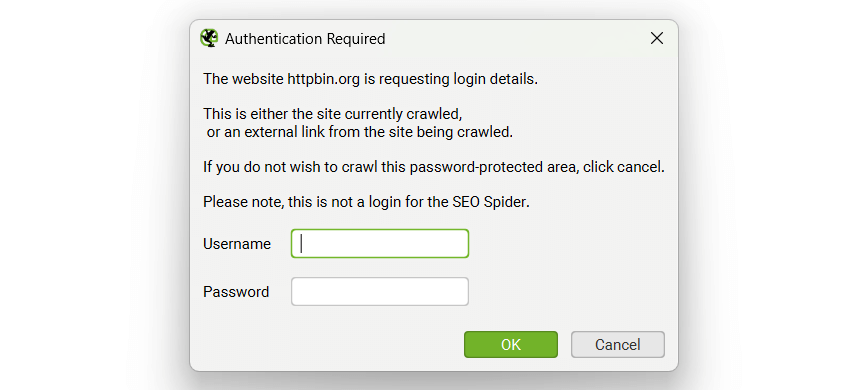 Enter your credentials and the crawl will continue as normal. You cannot pre-enter login credentials – they are entered when URLs that require authentication are crawled. This feature does not require a licence key.
Try to following pages to see how authentication works in your browser, or in the SEO Spider.
Enter your credentials and the crawl will continue as normal. You cannot pre-enter login credentials – they are entered when URLs that require authentication are crawled. This feature does not require a licence key.
Try to following pages to see how authentication works in your browser, or in the SEO Spider.
- Basic Authentication Username:user Password: password
- Digest Authentication Username:user Password: password
Web Form Authentication
There are other web forms and areas which require you to login with cookies for authentication to be able to view or crawl it. The SEO Spider allows users to log in to these web forms within the SEO Spider’s built in Chromium browser, and then crawl it. This feature requires a licence to use it.
To log in, simply navigate to ‘Configuration > Authentication’ then switch to the ‘Forms Based’ tab, click the ‘Add’ button, enter the URL for the site you want to crawl, and a browser will pop up allowing you to log in.
Please read about crawling web form password protected sites in our user guide, before using this feature. Some website’s may also require JavaScript rendering to be enabled when logged in to be able to crawl it.
Please note – This is a very powerful feature, and should therefore be used responsibly. The SEO Spider clicks every link on a page; when you’re logged in that may include links to log you out, create posts, install plugins, or even delete data.
How do I bulk export or move database crawls?
In database storage mode the SEO Spider will auto save crawls into a database.
These crawl files are contained within the 'ProjectInstanceData' folder within a ScreamingFrogSEOSpider folder in your user directory.
The location of this folder can be viewed by clicking 'File > Settings > Storage Mode' and viewing the directory line -
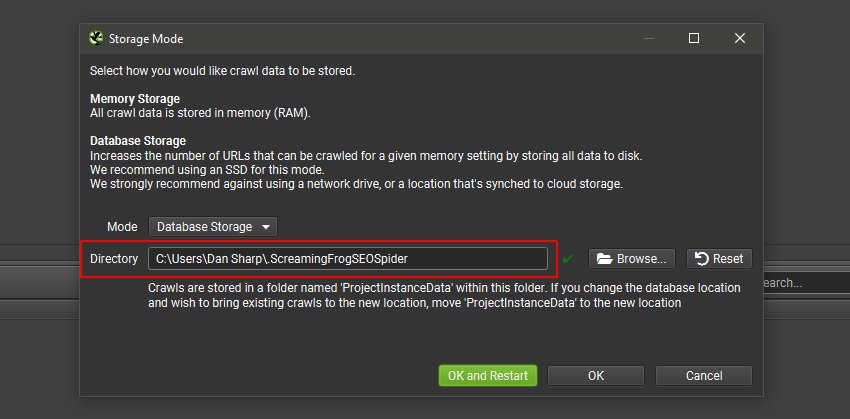 If you wish to move crawls to a new location, simply copy the 'ProjectInstanceData' folder into the new \.ScreamingFrogSEOSpider folder location on the new drive or machine. This is cross OS compatible, so you are able to move from Windows to Mac, or vice versa.
If you wish to move crawls to a new location, simply copy the 'ProjectInstanceData' folder into the new \.ScreamingFrogSEOSpider folder location on the new drive or machine. This is cross OS compatible, so you are able to move from Windows to Mac, or vice versa.
 Ensure the SEO Spider installed on the machine has the database storage location set as the \.ScreamingFrogSEOSpider folder.
The transferring of crawls will also work across OS, when switching from one to another.
Ensure the SEO Spider installed on the machine has the database storage location set as the \.ScreamingFrogSEOSpider folder.
The transferring of crawls will also work across OS, when switching from one to another.
Can I crawl more than one site at a time?
Yes. There are two ways you can do this:
1) Open up multiple instances of the SEO Spider, one for each domain you want to crawl. For Mac users, please see how to open up multiple instances on macOS.
2) Use list mode ('Mode->List'). Remove the crawl depth limit ('Config >Spider->Limits') and upload your list of domains to crawl.
Crawl Results
Why is the SEO Spider not finding a particular page or set of pages?
The SEO Spider finds pages by scanning the HTML code of the entered starting URL for <a href> links, which it will then crawl to find more links. Therefore to find a page there must be a clear linking path to it from the starting point of a crawl for the SEO Spider to follow.
If there is a clear path, then these links or the pages the links are on must exist in a way the SEO Spider either cannot 'see' or crawl.
Hence please make sure of the following:
- The link is an HTML anchor tag, the SEO Spider does not execute JavaScript in the standard configuration, so links that exist only in JavaScript will not be ‘seen’ or crawled. If the site is built in a JavaScript framework, or has dynamic content, adjust the rendering configuration to 'JavaScript' under 'Configuration > Spider > Rendering tab > JavaScript' to crawl the website.
- If any links or linking pages have ‘nofollow’ attributes or directives preventing the SEO Spider from following these links. By default the SEO Spider obeys ‘nofollow’ directives unless the 'follow internal nofollow' configuration is checked.
- The expected page(s) are on the same subdomain as your starting page. By default links to different subdomains are treated as external unless the Crawl all subdomains option is checked.
- If the expected page(s) are in a different subfolder to the starting point of the crawl the Crawl outside start folder option is checked.
- The linking page(s) are not blocked by Robots.txt. By default the robots.txt is obeyed so any links on a blocked page will not be seen unless the Ignore robots.txt option is checked. If the site uses JavaScript and the rendering configuration is set to 'JavaScript', ensure JS and CSS are not blocked by robots.txt.
- You do not have an Include or Exclude function set up that is limiting the crawl.
- Ensure category pages (or similar) were not temporarily unreachable during the crawl, giving a connection timeout, server error etc. preventing linked pages from being discovered.
- By default the SEO Spider won't crawl the XML Sitemap of a website to discover new URLs. However, you can select to 'Crawl Linked XML Sitemaps' in the configuration.
Why do the results change between crawls?
The most common reasons for this are:
- Crawl settings are different, which can lead to different pages being crawled or different responses being given, leading to different results. You can reset your configuration via 'Config > Profiles > Clear Default Config'.
- The site has changed, meaning the different elements of the crawl are reported differently.
- The SEO Spider receives different responses, specific URLs timing out or giving server errors. This could mean less pages are discovered overall as well as these being inconsistent between crawls. Remember to double check under 'Response Codes > No Responses' and 'Response Codes > Server Error', and right click on URLs and click to 're-spider' on URLs that might have intermittent issues (such as timing out or server errors).
- When using JavaScript rendering, pages are not fully rendering within 5 seconds when the snapshot of the page is taken. If some are failing to load correctly, then content and links (to other pages) might not be seen. Adjust the 'AJAX timeout' under 'Config > Spider > Rendering' if ‘response times’ in the ‘Internal’ tab are longer than 5 seconds, or web pages don’t appear to have loaded and rendered correctly in the ‘rendered page’ tab. Please read our guide on how to crawl JavaScript websites for more information.
Another point that could affect crawl results, is the order in which pages are found. If allowing cookies, a page that drops a cookie that leads to certain URLs being treated different (such as redirecting to a different language version after a language selector is used) could lead to wildly different results depending on which cookies are picked up when during the crawl. In these situations multiple crawls may need to be undertaken, excluding particular sections so that only a single cookie behaviour is set at a time.
Why is the SEO Spider not finding images?
There are generally three reasons for this:
- The images are loaded using JavaScript. Try viewing the page in your browser with JavaScript disabled to see if this is the case. The SEO Spider does not execute JavaScript by default. If the site is built in a JavaScript framework, or has dynamic content, adjust the rendering configuration to 'JavaScript' under 'Config > Spider > Rendering > JavaScript' to crawl it. Remember to ensure JS and CSS files are not blocked.
- Images defined in the CSS, such as "background-image", also require JavaScript rendering to be enabled in order for the Spider to observe and report them. Any images loaded dynamically in this way will be classified as background images in the 'Issues' tab and 'Images > Background Images' filter'.
- The images are blocked by robots.txt. You can either ignore robots.txt or customise the robots.txt to allow crawling.
Why am I experiencing a different response in a browser?
The SEO Spider's HTTP request is often different to a traditional browser and other tools, so you can sometimes experience a different response than if you visit the page or use a different tool to check the response. The SEO Spider simply reports on the response given to it by the server when it makes a request, which won’t be incorrect but can differ from what might be experienced elsewhere. Some of the common factors that can cause servers to give a different response, that are configurable in the SEO Spider are -
- User-Agent - The SEO Spider uses its own user-agent as default, and so do browsers. You can find the User-Agent configuration under ‘Configuration > HTTP Header > User-Agent’. If you adjust this to a browser user-agent (Chrome etc), you may experience a different response.
- JavaScript - Browsers will execute JavaScript, and by default the SEO Spider does not. So you may experience small changes in page content, to much larger differences if the site is built using a JavaScript framework, or be redirected to a new location completely in a browser. Similar to Google, the SEO Spider can render web pages, and crawl them after JavaScript has come into play. You can turn this on, by navigating to 'Configuration > Spider > Rendering' and choosing 'JavaScript Rendering'. The 'rendered page' tab at the bottom will help debug any differences between what the SEO Spider can see, in comparison to a browser. If your site is built using a JavaScript framework, then please read our 'How To Crawl JavaScript Websites' guide.
- JavaScript Window Size - By default the SEO Spider uses "Googlebot Mobile: Smartphone", switching to "Desktop" will more closely match a browser.
- Accept-Language Header - Your browser will supply an accept language header with your language. Similar to Googlebot, the SEO Spider doesn't supply an Accept-Language header for requests by default. However, you can adjust the Accept-Language configuration under 'Configuration > HTTP Header > Accept-Language'.
- Cookies - Your browser will allow cookies to be loaded, and so will the SEO Spider. However, the SEO Spider will mimic Googlebot and cookies will not persist between requests like in a browser.
- Speed - Servers can respond differently when under stress and load. Their responses can be less stable. We recommend reducing the crawl speed and seeing if the responses then change, and using WireShark to verify responses independently.
Why does the 'Completed' URL total not match what I export?
The ‘Completed’ URL total is the number of URLs the SEO Spider has encountered. This is the total URLs crawled, plus any ‘Internal’ and ‘External’ URLs blocked by robots.txt.
Depending on the settings in the robots.txt section of the ‘Configuration > Spider >Basic’ menu, these blocked URLs may not be visible in the SEO Spider interface.
If the ‘Respect Canonical’ or ‘Respect Noindex’ options in the ‘Configuration > Spider > Advanced’ tab are checked, then these URLs will count towards the ‘Total Encountered’ (Completed Total) and ‘Crawled’, but will not be visible within the SEO Spider interface.
The ‘Response Codes’ Tab and Export will show all URLs encountered by the Spider except those hidden by the settings detailed above.
How is the response time calculated?
It is calculated from the time it takes to issue an HTTP request and get the full HTTP response back from the server. The figure displayed on the SEO Spider interface is in seconds.
Please note that this figure may not be 100% reproducible as it depends very much on server load and client network activity at the time the request was made.
This figure does not include the time taken to download additional resources when in JavaScript rendering mode. Each resource appears separately in the user interface with its own individual response time.
What do Indexable & Non-Indexable mean?
Every URL discovered in a crawl is classified as either ‘Indexable' or ‘Non-Indexable' within the Indexability column in the SEO Spider.
'Indexable' means a URL that can be crawled, responds with a ‘200’ status code and is permitted to be indexed.
'Non-Indexable' is a URL that can't be crawled, doesn't respond with a '200' status code, or has an instruction not to be indexed.
Every non-indexable URL has an 'Indexability Status' associated with it, which explains quickly why it isn't indexable.
It's important to remember that 'Indexability' does not tell you whether Google is indexing a URL or not - only Google ultimately decides that. Indexability tells you what you're instructing Google to do, which goes a long way in getting Google to do what you want.
Non-indexable can include URLs that are the following -
- Blocked by robots.txt.
- No Response.
- Redirect (3XX, meta refresh, or JavaScript redirect).
- Client Error (4XX).
- Server Error (5XX).
- Noindex (or 'None').
- Canonicalised.
- Nofollowed.
Check out our video guide on indexability below.
The SEO Spider will consider meta robots, X-Robots-Tag, canonical link elements and the rel="canonical" HTTP header information for directives and canonicals.
It's fairly common for sites to have a self referencing meta refresh for various reasons and generally this doesn't impact indexing of the page. However, it should be investigated further, as it's redirecting to itself, and this is why it's flagged as 'non-indexable'.
To stop self referencing meta refresh URLs being considered as 'non-indexable', untick the 'Respect Self Referencing Meta Refresh' configuration under 'Configuration > Spider > Advanced'.
Why are page titles &/or meta descriptions not being displayed/displayed incorrectly?
If the site or URL in question has page titles and meta descriptions, but one (or both!) are not showing in the SEO Spider this is generally due to the following reasons -
1) The SEO Spider reads up to a maximum of 20 meta tags. So, if there are over 20 meta tags and the meta description is after the 20th meta tag, it will be ignored.
2) The SEO Spider does not execute JavaScript by default. Modifications to any HTML elements via JavaScript will not be seen by the SEO Spider. If the site uses JavaScript, amend the rendering configuration to 'JavaScript' under 'Configuration > Spider > Rendering' to crawl it. Remember to ensure JS and CSS files are not blocked.
Why does the number of URLs crawled not match the number of results indexed in Google or errors reported within Google Search Console?
There’s a number of reasons why the number of URLs found in a crawl might not match the number of results indexed in Google (via a site: query) or errors reported in the SEO Spider match those in Google Search Console.
First of all, crawling and indexing are quite separate, so there will always be some disparity. URLs might be crawled, but it doesn’t always mean they will actually be indexed in Google. This is an important area to consider, as there might be content in Google’s index which you didn’t know existed, or no longer want indexed for example. Equally, you may find more URLs in a crawl than in Google’s index due to directives used (noindex, canonicalisation) or even duplicate content, low site reputation etc.
Secondly, the SEO Spider only crawls internal links of a website at that moment of time of the crawl. Google (more specifically Googlebot) crawls the entire web, so not just the internal links of a website for discovery, but also external links pointing to a website.
Googlebot’s crawl is also not a snapshot in time, it’s over the duration of a site’s lifetime from when it’s first discovered. Therefore, you may find old URLs (perhaps from discontinued products or an old section on the site which still serve a 200 ‘OK’ response) that isn't linked to anymore, or content that is only linked to via external sources in their index still. The SEO Spider won’t be able to discover URLs which are not linked to internally, like orphan pages or URLs only accessible by external links by default. However, read our tutorial on how to find orphan pages, as the SEO Spider can use URLs found in GA, GSC and XML Sitemaps as an additional source of discovery.
There are other reasons as well, these may include –
- The set-up of the SEO Spider crawl. As default the SEO Spider will respect robots.txt, respect ‘nofollow’ of internal and external URLs & crawl canonicals but not execute JavaScript. So please check your configuration. Please remember, Google may have been able to previously access these URLs which are now blocked, nofollowed etc.
- The SEO Spider does not execute JavaScript by default. If the site is built in a JavaScript framework, or has dynamic content, adjust the rendering configuration to 'JavaScript' under 'Configuration > Spider > Rendering tab > JavaScript' to crawl it. Remember to ensure JS and CSS files are not blocked.
- Google include URLs which are blocked via robots.txt in their search results number. Don’t forget, robots.txt just stops a URL from being crawled, it doesn’t stop the URL from being indexed and appearing in Google.
- Google crawl XML sitemaps. The SEO Spider does not currently crawl XML sitemaps by default, you need to enable them to be crawled. Please read our tutorial on how to audit XML Sitemaps.
- Google’s results number via a site: query can be pretty unreliable!
- Google’s error reporting can be pretty slow and outdated!
Why does the number of URLs crawled (or errors discovered) not match another crawler?
First of all, the free ‘lite’ version is restricted to a 500 URLs crawl limit and obviously a website might be significantly larger. If you have a licence, the main reason an SEO Spider crawl might discover more or less links (and indeed broken links etc), than another crawler is simply down to the different default configuration set-ups of each.
As default the SEO Spider will respect robots.txt, respect ‘nofollow’ of internal and external URLs & crawl canonicals. But other crawlers sometimes don’t respect these as default and hence why there might be differences. Obviously these can all be adjusted to your own preferences within the configuration.
While crawling more URLs might seem to be a good thing, actually it might be completely unnecessary and a waste of time and effort. So please choose wisely what you want to crawl.
We believe the SEO Spider is the most advanced crawler available and it will often find more URLs than other crawls as it crawl canonicals and AJAX similar to Googlebot which other crawlers might not have as standard, or within their current capability.
There are other reasons as well, these may include –
- User-agent, speed or time of the crawl may play a part.
- Some other crawlers may use XML sitemaps for discovery and crawling. The SEO Spider does not currently crawl XML sitemaps by default, you currently have to upload them in list mode. The reason we decided against crawling XML sitemaps by default is that it shouldn’t make up for a site’s architecture. If a page is not linked to in the sites internal link structure, and only in an XML sitemap, it will help it be discovered and indexed, but the chances are it won’t perform very well organically. This is obviously because it won’t be passed any real PageRank, like a proper internal link. So we believe, it’s useful to analyse websites via the natural crawling and indexing process of internal links to get a better idea of a sites set-up. There are some scenarios where it does make sense to crawl XML sitemaps though and we may make this possible in the future as an option.
- Some other crawlers might crawl analytics landing pages, or URLs in Google Search Console Tools top pages. Again, this is not the natural crawling and indexing process, but might be something we consider in the future.
Why is word count not accurate?
Word count is all ‘words’ inside the body tag, excluding HTML markup. The count is based upon the content area that can be adjusted under ‘Config > Content > Area’.
By default, the nav and footer HTML5 elements are excluded to focus on content within the main content area of a page.
Our figures may not be exactly what performing this calculation manually would find, as the parser performs certain fix-ups on invalid HTML. Your rendering settings also affect what HTML is considered. Our definition of a word is taking the text and splitting it by spaces.
No consideration is given to visibility of content (such as text inside a div set to hidden).
You may experience a less accurate word count, if the website is not using HTML5 elements. You can include or exclude HTML elements, classes and IDs to calculate a refined word count via ‘Config > Content > Area’.
Reporting
How do I maintain order in a list mode export?
If you wish to export data in list mode in the same order it was uploaded, then use the ‘Export’ button which appears next to the ‘upload’ and ‘start’ buttons at the top of the user interface.

The data in the export will be in the same order and include all of the exact URLs in the original upload, including duplicates or any fix-ups performed.
Why is the character encoding incorrect?
The SEO Spider determines the character encoding of a web page by the “charset=” parameter in the HTTP Content-Type header, eg:
“text/html; charset=UTF-8”
You can see this in the SEO Spider’s interface in the ‘Content’ columns (in various tabs). If this is not present in the HTTP header, the SEO Spider will then read the first 2048 bytes of the html page to see if there is a charset within the html.
For example –
“meta http-equiv=”Content-Type” content=”text/html; charset=windows-1255″
If this is not the case, we continue assuming the page is UTF-8.
The Spider does log any character encoding issues. If there is a specific page that is causing problems, perform a crawl of only that page by setting the maximum number of URLs to crawl to be 1, then crawling the URL. You may see a line in the trace.txt log file (the location is – C:UsersYourprofile.ScreamingFrogSEOSpidertrace.txt):
20-06-12 20:32:50 INFO seo.spider.net.InputStreamWrapper:logUnsupportedCharset Unsupported Encoding ‘windows-‘ reverting to ‘UTF-8’ on page ‘http://www.example.com’ java.io.UnsupportedEncodingException: windows-‘. This could be an error on the site or you may need to install an additional language pack.
The solution to fix this is to specify the format of the data by either the Content-Type field of the accompanying HTTP header or ensuring the charset parameter in the source code is within the first 2048 bytes of the html within the head element.
How do I bulk export all inlinks to 3XX, 4XX (404 error etc) or 5XX pages?
You can bulk export data via the ‘Bulk Export’ option in the top level menu. You can then choose to export all links discovered, or all inlinks to specific status codes such as 2XX, 3XX, 4XX or 5XX responses.
For example, selecting ‘Bulk Export > Response Codes > Client Error 4XX Inlinks’ option will export all source pages to all error pages (such as 404 error pages).
Please see more on exporting in our user guide.
How do I bulk export all images missing alt text?
You can bulk export data via the ‘Bulk Export’ option in the top level navigation menu.
Simply select 'Bulk Export > Images > Images Missing Alt Text Inlinks’ option to export all references of images without alt text. Please see more in our guide 'how to find missing image alt text'.
How do I bulk export all image alt text?
You can bulk export data via the ‘Bulk Export’ option in the top level navigation menu.
Select 'Bulk Export > Images > All Image Inlinks' to export all images and associated alt text found in our crawl. Please see more on exporting in our user guide.
Where can I see the pages blocked by robots.txt?
You can simply view URLs blocked via robots.txt in the UI (within the ‘Internal’ and ‘Response Codes’ tabs for example). Ensure you have the ‘Show internal URLs blocked by robots.txt’ configuration ticked under 'Configuration > Robots.txt'.
You can view external URLs blocked by robots.txt within the 'External' and 'Response Codes' tabs by ticking the ‘Show External URLs blocked by robots.txt’ configuration under 'Configuration > Robots.txt'.
Disallowed URLs will appear with a ‘status’ as ‘Blocked by Robots.txt’ and there’s a ‘Blocked by Robots.txt’ filter under the ‘Response Codes’ tab, where these can be viewed.
The ‘Blocked by Robots.txt’ filter also displays a ‘Matched Robots.txt Line’ column, which provides the line number and disallow path of the robots.txt entry that’s excluding each URL. If multiple lines in robots.txt block a URL, the SEO Spider will just report on the first encountered, similar to Google within Search Console.

Please see our guide on using the SEO Spider as a robots.txt tester.
What are the Looker Studio Export breaking changes?
If you have received a 'Looker Studio Export Breaking Changes' message when editing a scheduled crawl task, this means your Export for Looker Studio might be impacted by forced updates to PageSpeed filters.
If you click 'Cancel', then there will be no issue with the Export for Looker Studio or the automated crawl report.
However, if you need to make any change to an existing scheduled crawl task, then you will need to read-on and make any appropriate changes to the Export for Looker Studio in the scheduled crawl task, and the corresponding 'custom_summary_report' Google Sheet export.
Why There Are Breaking Changes
Lighthouse and PageSpeed Insights have moved to performance insight audits, which means some page speed audits have been removed, consolidated and new audits added.
In version 23 of the SEO Spider, we updated our PageSpeed Insights integration to this new format.
This means we have updated our PageSpeed filters/issues in line with the Lighthouse changes. This obviously has an impact on the Export for Looker Studio and automated crawl reports that use these filters, as some of the filters no longer exist, have been renamed, and new audits introduced.
There are two options to update your Export for Looker Studio, removing the data completely, or retaining it.
Remove PageSpeed Filters & Columns
The simplest way to ensure there are no issues with the Export for Looker Studio, is to remove the Pagespeed filters from the scheduled crawl task Looker Studio export.
Move all PageSpeed issues from 'Selected' back to 'Available' on the left hand side so they are de-selected.
Next, delete the columns from the Export for Looker Studio Google Sheet as well. The Google Sheet location is 'My Drive > Screaming Frog SEO Spider > Project Name > [task_name]_custom_summary_report' and this is where all the data from the Export for Looker Studio is kept.
This will mean you have no problems with columns lining up in the Export for Looker Studio, and automated crawl reports will continue as normal.
Keeping PageSpeed Filters & Columns
If you have been integated PageSpeed into the automated crawl reports and wish to retain the data, then this will require a little more work.
Filters have been removed, renamed, and added. Hence, it is possible to keep data for filters that still exist, or have been renamed.
Here's a summary of what has been removed, retained, renamed and added.
Removed Filters (11 in total):
- PageSpeed:Defer Offscreen Images
- PageSpeed:Preload Key Requests
- PageSpeed:Efficiently Encode Images (Now part of Improve Image Delivery)
- PageSpeed:Properly Size Images (Now part of Improve Image Delivery)
- PageSpeed:Serve Images in Next-Gen Formats (Now part of Improve Image Delivery)
- PageSpeed:Use Video Formats for Animated Content (Now part of Improve Image Delivery)
- PageSpeed:Enable Text Compression (Now part of Document Request Latency)
- PageSpeed:Reduce Server Response Times (TTFB) (Now part of Document Request Latency)
- PageSpeed:Avoid Multiple Page Redirects (Now part of Document Request Latency)
- PageSpeed:Preconnect to Required Origins (Now part of Network Dependency Tree)
- PageSpeed:Image Elements Do Not Have Explicit Width & Height (Now part of Layout Shift Culprits)
Retained Filters (8 in total):
- PageSpeed:All
- PageSpeed:Minify CSS
- PageSpeed:Minify JavaScript
- PageSpeed:Reduce Unused CSS
- PageSpeed:Reduce Unused JavaScript
- PageSpeed:Reduce JavaScript Execution Time
- PageSpeed:Minimize Main-Thread Work
- PageSpeed:Request Errors
Renamed Filters (6 in total):
- PageSpeed:Eliminate Render-Blocking Resources (Now - PageSpeed:Render Blocking Requests)
- PageSpeed:Avoid Excessive DOM Size (Now - PageSpeed:Optimize DOM Size)
- PageSpeed:Serve Static Assets with an Efficient Cache Policy (Now - PageSpeed:Use Efficient Cache Lifetimes)
- PageSpeed:Ensure Text Remains Visible During Webfont Load (Now - PageSpeed:Font Display)
- PageSpeed:Avoid Large Layout Shifts (Now - PageSpeed:Layout Shift Culprits)
- PageSpeed:Avoid Serving Legacy JavaScript to Modern Browsers (Now - PageSpeed:Legacy JavaScript)
Added Filters (7 in total) -
- PageSpeed:Document Request Latency
- PageSpeed:Improve Image Delivery
- PageSpeed:LCP Request Discovery
- PageSpeed:Forced Reflow
- PageSpeed:Avoid Enormous Network Payloads
- PageSpeed:Network Dependency Tree
- PageSpeed:Duplicated JavaScript
If you wish to retain existing data and pull in new PageSpeed data, then the existing Export for Looker Studio report and corresponding spread sheet will both require adjustments inline with the above.
The order of the 'Selected' filters in the Export for Looker Studio from top to bottom must match the order of columns in the 'custom_summary_report' Google Sheet from left to right.
While you are welcome to match these up as you see fit, we recommend moving PageSpeed filters to the bottom of 'Selected' in the Export for Looker Studio for ease.
Then move the existing PageSpeed columns in the spreadsheet to the end, and ensure they match the order. Rather than write out the header names of the columns, you can right click and 'Copy' the PageSpeed names from the Export for Looker Studio 'Selected' list displayed above, and then right click 'paste special' and 'transposed' to paste them across columns. Or you can copy them from our Google Sheet here, which is the default ordering.
In summary - The 'removed' filters will need to be removed as columns as they will now have been removed from 'Selected' in the Export for Looker Studio. The retained filters can be kept and data retained. The renamed filters can be renamed and data retained if you'd like. Finally new filters can be added to the end.
As highlighted above, the order from top to bottom in the Export for Looker Studio list must match the order of the columns in the Google Sheet from left to right.
Why are attachments missing in notification emails?
This is often due to reaching the file size limit of your email provider. While the SEO Spider will compress exports included in notification emails, if lots of exports are selected, or exports have lots of data, they might be over the size limit.
The file attachment limits for common providers are displayed below:
- Gmail - 25 MB limit
- Outlook Web - 20 MB limit
- Microsoft 365 - 35 MB Limit (but can be configured for more!)
- Yahoo - 25 MB limit
- iCloud Mail - 20MB limit
- Proton Mail - 25MB limit
Please check your email providers own limits for up to date limits, and ensure the size of the reports you have selected are below the file size.
It's important to remember, that email, and this feature, is designed for selective usage, not for exporting everything. Consider exporting files to a shared drive or Google Sheets as alternatives.
Please note - In scheduled crawl task 'Output Settings', there is a 'Skip Empty Reports' configuration. You will not receive an attached report if it's blank and this is enabled.
XML Sitemaps
How do I create an XML sitemap?
Read our ‘How To Create An XML Sitemap‘ tutorial, which explains how to generate an XML Sitemap, include or exclude pages or images and runs through all the configuration settings available.
Why is my exported sitemap missing some URLs?
Canonicalised, robots.txt blocked, noindex and paginated URLs are not included in the sitemap by default.
You may choose to include these in your sitemap by ticking the appropriate checkbox(s) in the 'Pages' tab when you export the sitemap.
Please read our user guide on XML Sitemap Creation.
Why can't I generate an image sitemap from a list of images?
Image sitemap protocol require the HTML page the image is referenced on to be included in the sitemap. A list of images only does not have this information, so a sitemap cannot be generated.
Details on Google's requirements for image sitemaps can be seen at - https://support.google.com/webmasters/answer/178636.
Custom Extraction
How can I extract all tags matching my XPath?
Why is my regex extracting more than expected?
If you are using a regex like .* that contains a greedy quantifier you may end up matching more than you want. The solution to this is to use a regex like .*?.
For example if you are trying to extract the id from the following JSON:
"agent":
{
"id":"007",
"name":"James Bond"
}
Using "id":"(.*)" you will get:
007", "name":"James Bond
If you use "id":"(.*?)" you will extract:
007
How do I extract multiple matches of a regex?
If you want all the H1s from the following HTML:
<html>
<head>
<title>2 h1s</title>
</head>
<body>
<h1>h1-1</h1>
<h1>h1-2</h1>
</body>
</html>
Then we can use: <h1>(.*?)</h1>
Google Analytics Integration
Why do I receive an error when granting access to my Google account?
After allowing the SEO Spider access to your Google account you should be redirected to a screen that looks like this:
 However, if you receive an error like this:
However, if you receive an error like this:
 There are a few things to check:
There are a few things to check:
- Is there any security software running on your machine preventing the SEO Spider listening on the port specified in the URL? The port is the number after localhost: in the address bar, 63212 in the screenshots above.
- Is your browser sending the request, intended for localhost, to a proxy instead? You can sometimes tell this if the failure screen mentions the name of a proxy server, such as Squid for example.
- You may have HSTS enabled for localhost. Go to chrome://net-internals/#hsts, then under "Delete domain security policies" delete "localhost" and try again. You can reinstate this setting afterwards if required.
Why does my connection to Google Analytics fail?
If you are receiving the following error when trying to connect to Google Analytics or Search Console:
 Please read our guide on resolving this.
Please read our guide on resolving this.
Why doesn’t GA data populate against my URLs?
The URLs in your chosen Google Analytics view have to match the URLs discovered in the SEO Spider crawl exactly, for data to be matched and populated accurately. If they don’t match, then GA data won’t be able to be matched and won’t populate. This is the single most common reason.
If Google Analytics data does not get pulled into the SEO Spider as you expected, then analyse the URLs provided in the ‘orphan pages’ report via 'Reports > Orphan Pages', which shows a list of URLs returned from the Google Analytics & Search Analytics (from Search Console) API’s for your query, that didn’t match URLs in the crawl.
Check the URLs with source as ‘GA’ for Google Analytics specifically (those marked as ‘GSC’ are Google Search Analytics, from Google Search Console). The URLs here need to match those in the crawl, for the data to be matched accurately.
If they don’t match, then the SEO Spider won’t be able to match up the data accurately. We recommend checking your default Google Analytics view settings (such as ‘default page’) and filters such as ‘extended URL’ hacks, which all impact how URLs are displayed and hence matched against a crawl. If you want URLs to match up, you can often make the required amends within Google Analytics or use a ‘raw’ unedited view (you should always have one of these ideally).
Please note – There are some very common scenarios where URLs in Google Analytics might not match URLs in a crawl, so we cover these by matching trailing and non-trailing slash URLs and case sensitivity (upper and lowercase characters in URLs). Google doesn’t pass the protocol (HTTP or HTTPS) via their API, so we also match this data automatically as well.
Why doesn’t the GA API data in the SEO Spider match what’s reported in the GA interface?
There’s a variety of reasons why data fetched via the Google API into the SEO Spider might be different to the data reported within the Google Universal Analytics or GA4 interface.
First of all, we recommend triple checking that you’re viewing the exact same account, property, view, segment, date range and metrics and dimensions for UA. For GA4, we recommend ensuring you're using connecting to the correct account, property, data stream, date range and have the same filters applied.
If data still doesn’t match, then there are some common reasons why –
- Google APIs can just return slightly different metrics. We’ve tested this and sometimes the data from the API, can just be a little different to what’s reported in the interface.
- For GA4, we're using landingPagePlusQueryString as the default dimension. This is different to unifiedPagePathScreen that is used in the 'Engagement > Pages and screens' report in GA4. You can update to use pagePathPlusQueryString in the 'Dimensions' tab of the GA4 config, which will match for URLs.
- GA4 data is limited to 100k URLs by default. So if some data is missing, the 'Limit Max Results' option under 'Config > API Access > GA4 > General' should be increased or disabled completely.
For GA4, debug using the GA4 API Query Explorer and view URLs and data returned using the following parameters -
 You will also need to enable 'show advanced options', and add a 'Not' dimension filter for when 'LandingPagePlusQueryString' contains '(not set)' to throw those away.
You will also need to enable 'show advanced options', and add a 'Not' dimension filter for when 'LandingPagePlusQueryString' contains '(not set)' to throw those away.
 For GA4, you can also set dimension filters, so do ensure that the dimension type and values in the SEO Spider match any of those selected in the GA4 query explorer.
For GA4, you can also set dimension filters, so do ensure that the dimension type and values in the SEO Spider match any of those selected in the GA4 query explorer.
You can also set up an 'Exploration' (also known as a custom report) in GA4 and match this against the data shown in the SEO Spider. This takes 1min to set up with the parameters as shown below.
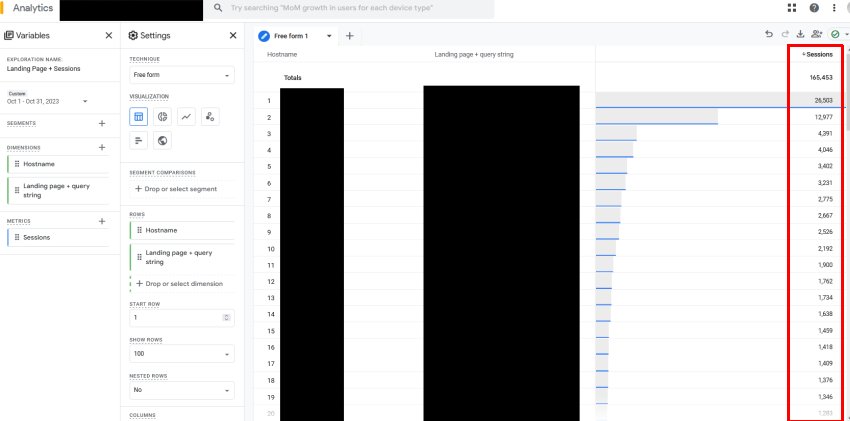
You should see that data returned via the API matches pretty closely to what is reported within the SEO Spider.
Why can't I see GA4 properties when I connect my Google Analytics account?
Please ensure you're using version 18.0 or higher. You will then need to ensure you're logging into GA4 specifically, via 'Config > API Access > GA4'.
PageSpeed Insights Integration
Why is there no Core Web Vitals data?
If your URLs aren’t showing any page level Core Web Vitals data and the PSI status lists ‘success’ then it is likely they don't receive enough real world user visits to generate sufficient speed data for the Chrome User Experience (CrUX) report.
 In the example above, our 'contact us' page has missing or blank Core Web Vitals data, whereas the much higher trafficked homepage has data.
In the example above, our 'contact us' page has missing or blank Core Web Vitals data, whereas the much higher trafficked homepage has data.
Core Web Vitals data are gathered from real user monitoring (RUM), which is available in the CrUX report, and via the PSI API used in the SEO Spider. You can verify whether a URL has any data by running it through the PageSpeed Insights web interface, where it will display a message at the top.
 The 'Origin Summary' below the highlighted area in the screenshot above is aggregated data for all pages across the site, rather than data for the specific page. Hence, this does not mean the page itself has data.
The 'Origin Summary' below the highlighted area in the screenshot above is aggregated data for all pages across the site, rather than data for the specific page. Hence, this does not mean the page itself has data.
When there is no data, you can check to see if the other device type (desktop, or mobile) has data instead. For example, our 'contact us' page used in the example above, does have data for desktop (just not mobile) - as we have a high proportion of desktop users.
Alternatively, you can analyse a similar page (in layout) that does have CrUX data, or you can use simulated lab data instead. Lab data can be found under the ‘Lighthouse’ dropdown of the Metrics tab in the PSI config (this is enabled by default). Please see our tutorial on How To Audit Core Web Vitals for more.
Does the PageSpeed Insights API affect analytics?
As of writing, using the PageSpeed Insights API appears to inflate analytics data. PSI renders web pages to get lab data about their performance. These Chrome instances appear to be recorded in Google Analytics as direct, even when the 'Exclude all hits from known bots and spiders' view setting is enabled.
Google is aware of the issue, and we understand they are working to resolve it. To stop PageSpeed Insights from inflating GA data, you can use either of the two methods below, depending on your setup:
- Include a filter to exclude known Google IP addresses, or
- Add User Agent as a custom dimension in analytics, and then exclude traffic based on this. (You need access to the site or GTM)
Method 1 - The following IP address exclude filter regex pattern appears to work from our own testing. However, we recommend using with caution, setting this up in a view that isn't important to you and testing first.
^66\.249\.(6[4-9]|[7-8][0-9]|9[0-5])\.([0-9]|[1-9][0-9]|1([0-9][0-9])|2([0-4][0-9]|5[0-5]))$
Method 2 - An outline of steps for this method is below:
- Create a custom dimension in Analytics - this can be found under the Admin for the property and Custom Definitions > Custom Dimensions
- In GTM, create a JavaScript variable and in the settings enter navigator.userAgent
- In the Google Analytics Settings variable add the custom dimension's details created in the first step with the user agent variable created in the second step
- An exclude filter can now be created for the newly-created custom dimension for the Chrome-Lighthouse user agent.
Again, we recommend using with caution and all the usual GA / GTM caveats, using best-practices such as setting up in a testing workspace and view first. As GTM and GA implementations vary we haven’t gone into specifics with these steps, but it should make sense to analytics stakeholders.
We hope that Google will resolve this issue internally over the coming months.
Why is my PageSpeed Insights API key invalid & displaying 'failed to connect'?
This is usually because the PSI API hasn't been enabled as per our PageSpeed Insights integration guide.
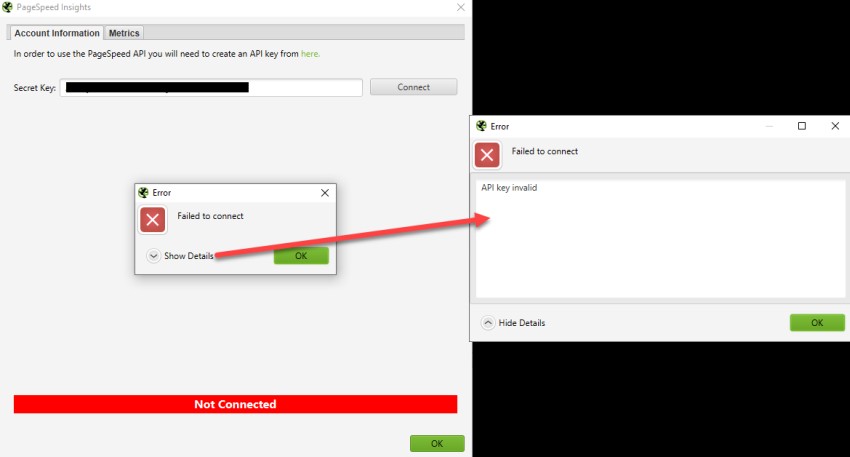 To enable the API, run a search from the API credentials page using the search bar for the PageSpeed Insights API in the API library (or just click on this link potentially).
To enable the API, run a search from the API credentials page using the search bar for the PageSpeed Insights API in the API library (or just click on this link potentially).
 On the PageSpeed Insights API Library page, click the 'Enable' button.
On the PageSpeed Insights API Library page, click the 'Enable' button.
 Now the API is activated. Give it a couple of mins and try connecting again, it should now work.
Now the API is activated. Give it a couple of mins and try connecting again, it should now work.
Why do I see an 'Error' Status for PageSpeed Insights?
The PSI Status column shows whether an API request for a URL has been a success, or there has been an error. An 'error' usually reflects the web interface, where you would see the same error and message. In the example below, there are two errors. A full list of errors can be viewed using the 'Request Errors' filter in the PageSpeed tab.
 The PSI Error column explains "500: Lighthouse returned error: ERRORED_DOCUMENT_REQUEST. Lighthouse was unable to reliably load the page you requested. Make sure you are testing the correct URL and that the server is properly responding to all requests. (Status code: 404)".
The PSI Error column explains "500: Lighthouse returned error: ERRORED_DOCUMENT_REQUEST. Lighthouse was unable to reliably load the page you requested. Make sure you are testing the correct URL and that the server is properly responding to all requests. (Status code: 404)".
If you search for the URL in the interface, right click on it and then choose 'PageSpeed Insights' it will open it up in the PSI web interface. For the Netflix example above, you can see the same error in the web interface.
 So this is generally not an issue with Screaming Frog, or the API, it is directly related to the Lighthouse audit conducted by PSI.
Our testing also shows that from time to time the PSI API is unable to process requests, possibly due to overall load capacity. The following message is displayed when this occurs.
So this is generally not an issue with Screaming Frog, or the API, it is directly related to the Lighthouse audit conducted by PSI.
Our testing also shows that from time to time the PSI API is unable to process requests, possibly due to overall load capacity. The following message is displayed when this occurs.
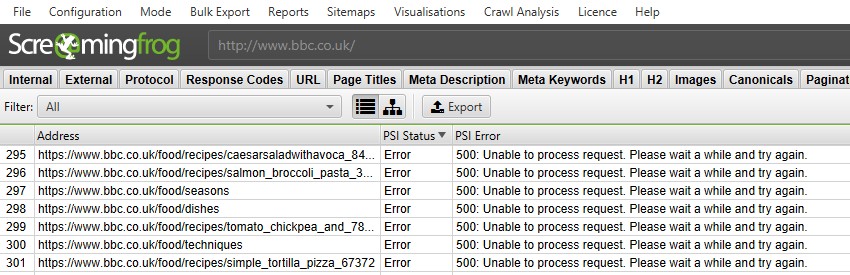 Once again, this can be replicated in the web interface, where the same message will be displayed. We recommend pausing the crawl, waiting for 10mins (until it's available again), and then right clicking on URLs and 're-spidering' them. This will re-request the PSI data.
Once again, this can be replicated in the web interface, where the same message will be displayed. We recommend pausing the crawl, waiting for 10mins (until it's available again), and then right clicking on URLs and 're-spidering' them. This will re-request the PSI data.
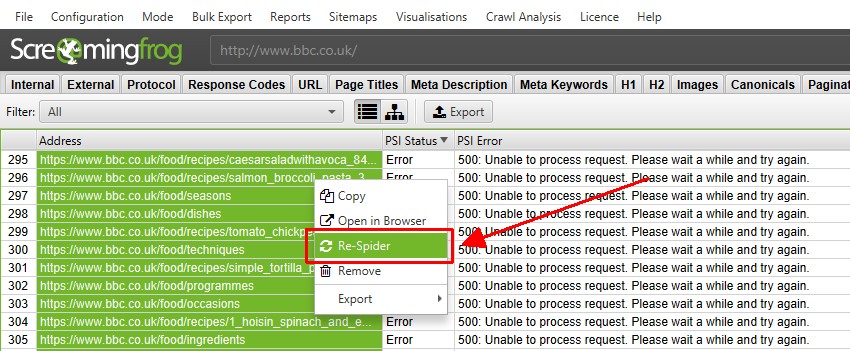 You can provide Google with feedback about any errors you experience directly on their mailing list or ask questions via Stack Overflow.
You can provide Google with feedback about any errors you experience directly on their mailing list or ask questions via Stack Overflow.
The total count of errors from PSI can be seen in the right hand window 'API' tab and 'Errors' count.

Why do PageSpeed Insights Lighthouse scores differ in a browser?
The PSI API uses Lighthouse which is run from Google servers which emulates a page load on a mid-tier device (Moto G4) on a mobile network. More information can be found here. The exact mobile throttling presets used by PSI can be seen on Github here.
When Lighthouse is run within your browser there are a number of variables which can vary the scores. Lighthouse is throttled by your own network, browser settings, the applications running on your machine and whatever emulation settings you’re currently using. Google go into some detail about this in their Lighthouse scoring guide.
Even when using the same API and conditions, the scores can also change. Google say "Variability in performance measurement is introduced via a number of channels with different levels of impact. Several common sources of metric variability are local network availability, client hardware availability, and client resource contention."
We recommend reading the following 'Lighthouse Metric Variability and Accuracy' report by one of the Chromium team.
MacOS
Why do I get an error saying "Screaming Frog SEO Spider" is not supported on my Mac?
If you are seeing the following dialog when you mount the dmg:
 and when you try to run it:
and when you try to run it:
 You have downloaded the Apple Silicon version of the SEO Spider and are running it on an Intel mac.
For details on choosing the correct download please see here.
You have downloaded the Apple Silicon version of the SEO Spider and are running it on an Intel mac.
For details on choosing the correct download please see here.
What version of the SEO Spider do I need for my Mac?
As of version 17 we now ship two versions of the SEO Spider; one for Apple Silicon processors that were introduced in late 2020, and one for the previous generation of machines that used Intel processors. You need to select the correct download based on the type of processor your machine has.
You can identify what processor your machine has by clicking the Apple logo in the top left of your screen and selecting "About This Mac". You can now see what machine you have by looking at the value for Processor/Chip. If this says "Apple M1", "Apple M2", or "Apple M3", you have an Apple Silicon machine. If it says "Intel" anywhere, then you have an Intel machine.
If you have an Apple Silicon machine, please download the version labelled "macOS (Apple Silicon)".
If you have an Intel machine you will most likely need the version labelled "macOS (Intel) version 11 or later". If you are running macOS version 10.14 "Mojave" or 10.15 "Catalina" you will not be able to use version 19.3 or later unless you update your operating system. The latest version you'll be able to use is 19.2. This is available to licenced users only and can be requested by contacting support.
You will not be able to update your operating systems if your machine is too old, in which case you will have to remain on Spider 19.2 until you update your machine.
How do I enter a licence key on a Mac?
Scroll to the top of your screen while the app is in focus, for the top level application menu to appear.
Please see the screenshot below, or our video demonstration.
 This works in the same way as other Mac native applications.
This works in the same way as other Mac native applications.
Do you support Macs below macOS Version 10.7.3 (& 32-Bit Macs)?
No, we do not support macOS versions below 10.7.3 (and 32-bit) Macs.
From version 2.50 released in 2014, the SEO Spider requires a version of Java not supported by this version of macOS.
This means much older 32-bit Macs (the last of which we understand were made over a decade ago) will not be able to use the SEO Spider. 64-bit Macs which haven’t yet updated their version of macOS, will just need to update their OS.
How can I open multiple instances of the SEO Spider?
To open additional instances of the SEO Spider open a Terminal and type the following:
open -n /Applications/Screaming\ Frog\ SEO\ Spider.app/
Windows
Why am I getting a crash using the SEO Spider remotely on Windows
This is is a known Java bug (more details here). A permanent fix is scheduled for October 2026, at which point we will release a new version of the SEO Spider.
If your machine has just done a Windows update you can ignore this.
This issue can occur if you are using the SEO Spider via RDP/VNC, or if your machine goes to sleep while crawling. There are three options available:
- Avoid using the SEO Spider over RDP/VNC, and prevent your machine from going to sleep while crawling.
- Install version 24.2. Note: This version contains Java 25.0.3 with a fix for the crash. However, because it has caused alternative stability issues for some customers, this is considered a "best-effort" workaround if you require version 24 features and cannot wait until October.
- Install version 23.3.
Misc
Why am I seeing “The WebKit component could not be loaded”?
There are a few reasons why you might be seeing this error.
- It’s a transient, one off error. Simply try again.
- Not enough disk space. The application requires enough disk space, roughly 100Mb, to extract files into the C:\Users[YOUR_USERNAME]\ScreamingFrogSEOSpider\javafx\ directory or your platform equivalent.
- Permissions. Your IT security policy is blocking access to read or write files to the C:\Users[YOUR_USERNAME]\ScreamingFrogSEOSpider\javafx\ directory or your platform equivalent.
If the problem persists, you have plenty of disk space and you have checked your security policy then we’d be happy to look into it further. Please follow the steps on the support page so we can help you as quickly as possible.
Can I run the Screaming Frog SEO Spider on a Raspberry Pi?
The SEO Spider doesn't run on a Raspberry Pi. Several of the components used by the SEO Spider don't run on the ARM architecture.
Can You Support A New Language For Spelling & Grammar Checks?
The SEO Spider uses an Open Source project called LanguageTool for spelling and grammar checks.
It's developed by a group of language enthusiasts and software developers and is used in a variety of applications, such as Libre Office, Open Office, Firefox, Google Chrome and other software packages like macOS, InDesign, memoQ, Opera, SDL Trados and JetBrains IDEs. They also have various free browser plugins.
LanguageTool have funding from the EU for the project, but also rely on contributions from the public to improve spelling and grammar in different languages. A list of current supported languages can be viewed here.
If you wish to see a new language in the SEO Spider, then you can help by making LanguageTool better and supporting the project. You're able to contribute by adding a new language and you can suggest new features and ask questions in the forum.
Does the Screaming Frog SEO Spider have an API?
In short, no. The Screaming Frog SEO Spider is a desktop application you download, install and run locally. So there is no API.
However, there is a command line interface to use the tool programmatically.
There is also a scheduling feature built into the SEO Spider.
How do I block the SEO Spider from crawling my site?
The spider obeys robots.txt protocol. Its user agent is ‘Screaming Frog SEO Spider’ so you can include the following in your robots.txt if you wish the Spider not to crawl your site –
User-agent: Screaming Frog SEO Spider
Disallow: /
Please note – There is an option to ‘ignore’ robots.txt and change user-agent, which is down to the responsibility of the user entirely.
Do you collect data & can you see the websites I am crawling?
We do not see what sites you are crawling or the data you have crawled. All crawl data is stored on your machine.
Google APIs use the OAuth 2.0 protocol for authentication and authorisation, and by default, the data provided via Google Analytics and other APIs is only accessible locally on your machine. If you use features involving external AI APIs (such as OpenAI or Gemini) they may involve sending crawl data, to those AI services. You should be conscious of and responsible for the privacy of all such data sent to such services.
How we collect data relating to licence usage, crashes and debug reports is detailed in our privacy policy.
The software does not contain any spyware, malware or adware (as verified by Softpedia for Windows and macOS).
Do you have an affiliate program?
No, we do not have an affiliate program for the SEO Spider software at this time.
Contact & Support
How do I submit a bug / receive support?
We love to receive bug reports. Please follow the steps on the support page so we can help you as quickly as possible.
Please note, we only offer full support for licensed users of the tool although we will generally try and fix any bugs or issues discovered.
How do I provide feedback?
We welcome feedback, feature requests and suggestions to improve the SEO Spider. The tool has been built on feedback from the awesome SEO community.
Please just follow the steps on the support page to submit feedback.
Alternatively, just e-mail support[at]screamingfrog.co.uk with your feedback. (Replacing the [at] with @).