SEO Spider
How To Audit PDFs
Introduction To Auditing PDFs
The Screaming Frog SEO Spider is able to crawl and parse PDFs, enabling it to extract document properties, content and links for SEO auditing and general compliance.
While PDFs are not the ideal format for ranking in search engines, they are commonly used in government, education and corporate environments for integrity, compatibility and consistency.
It can be vital to ensure they are up to date, and without error. Occasionally they need to be optimised for search engines, or internal search systems.
PDFs are crawled by search engines such as Google and Bing, and they are converted and indexed as HTML. Content and links within PDFs are parsed, and in some cases the document properties are utilised in scoring.
This tutorial explains how to set-up the SEO Spider to audit for common issues and use cases, such as –
- Audit links in PDFs, for broken links or other errors.
- Extract and analyse PDF properties.
- Review content, such as word count, readability and check spelling and grammar.
- Download and save PDFs.
- Bulk extract and export PDF content.
Read on for detail on each of the items above.
Audit Links In PDFs
Links within PDFs can be discovered and crawled in a similar way to regular HTML pages. However, the set-up can differ a little, depending on whether you’re crawling a website for PDFs, or have a list of PDF URLs already.
Crawling a Website
In regular ‘Spider’ mode, PDFs will be discovered if they are linked to internally. They will then be crawled and links within them will be discovered, crawled and reported.
Just input the homepage in the URL bar at the top and click ‘Start’.

Any PDFs that are linked to will be discovered during the crawl and appear under the Internal tab and ‘PDF’ filter.

Links within them will be crawled, and common issues such as broken links can be viewed in the usual way, under the ‘Response Codes’ tab and ‘Client Error (4xx)’ filter.

Alternatively, use the ‘Issues‘ tab, where issues, warnings or opportunities are flagged automatically to you.

The source of broken links can be viewed using the lower ‘Inlinks’ tab. Click the image below to enlarge.
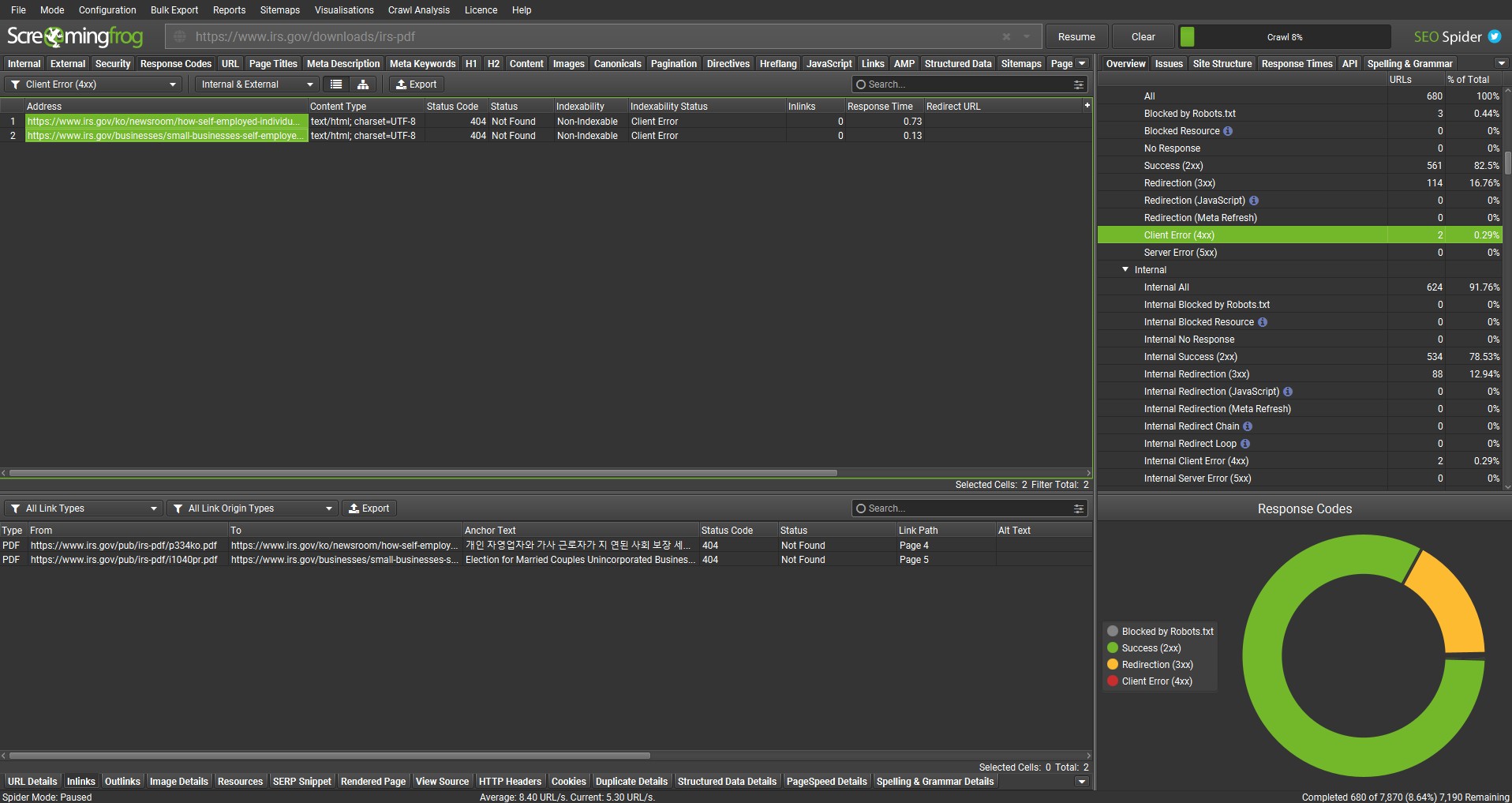
The Inlinks tab will display the ‘type’ as PDF for any broken links found within a PDF, as well as the URL of the PDF, anchor text and page number it was discovered on.

This data can be exported in bulk via ‘Bulk Export > Response Codes > Internal & External > Client Error (4xx) Inlinks’.
Read our tutorial on how to find broken links in the SEO Spider for more details.
It’s also possible to highlight all PDFs in the Internal tab, then click the lower ‘Outlinks’ tab to view links in them. The outlinks tab will populate with details of links contained within the PDFs.

The data can be exported using the ‘Export’ button on the lower window pane, right click ‘Export > Outlinks’, or via the ‘Bulk Export’ top level menu.
Crawling a List of PDFs
You’re able to upload a list of PDF URLs by switching to list mode (‘Mode > List’) and pasting them (‘Upload > Paste’).

However, this will only crawl the PDFs, it won’t crawl the links within the PDFs.
To crawl the outlinks in the PDF, adjust the ‘Limit Crawl Depth’ configuration under ‘Config > Spider > Limits’ to ‘1’ from ‘0’.

This means when you upload the list of PDFs, not only will they be crawled, but the outlinks contained within them will be crawled.
If there are any outlinks that are redirects, you can choose to follow the redirects until the final destination by enabling ‘Always Follow Redirects’ under ‘Config > Spider > Advanced’ as well.

Extract PDF Properties
You can view a PDFs document properties, by opening it in Chrome, then clicking the ‘More Actions’ button in the top right-hand corner and ‘Document Properties’.

By default the SEO Spider will extract the document title and keywords properties and display them in the ‘Title’ and ‘Meta Keywords’ columns in the Internal tab.

Google will convert the PDF to HTML and use the PDF document title as the title element and the document keywords as meta keywords in the HTML, although it doesn’t actually use meta keywords in ranking web results.
Page titles are used in scoring, so it’s important that PDF document titles are unique, relevant and descriptive – like a regular web page title element.
While Google will ignore the keywords property in a similar way to meta keywords, Bing will parse a PDFs property keywords into an HTML table and use them in ranking – along with title, author, subject and created date.
Additional properties can be extracted by enabling ‘Extract PDF properties‘ under ‘Config > Spider > Extraction’.

Properties include:
- Subject
- Author
- Creation Date
- Modification Date
- Page Count
When selected new columns are displayed in the Internal.

Some SEO guides indicate that the ‘subject’ document property is used by search engines as the meta description. However, there’s no evidence this is used by Google in the HTML or under search.
Bing may use the content of the subject property as a meta description, as its parsed into the HTML and will be treated like any text on the page.
Review PDF Content
Enabling ‘Store PDF‘ under ‘Config > Spider > Extraction’ will mean the content of the PDF will be parsed and stored and various additional details are available.

Word Count & Readability
Both word count and readability will be available for PDFs, and can be seen in the Content tab.

Spelling & Grammar
Like regular HTML web pages, PDFs can also be checked for spelling and grammar.
To enable this feature, click ‘Config > Content > Spelling & Grammar’ and enable both ‘Spell Check’ and ‘Grammar Check’.

Details of the spelling and grammar errors will then be displayed in the Content tab, and as outlined in our tutorial on ‘Spell & Grammar Check Your Website‘.
Custom Search
As the SEO Spider is able to see the content within the PDF, custom search is applied to PDFs. This means you’re able to search PDFs alongside webpages for any text, such as an old brand name, or phone number.
Ensure ‘Store PDF’ is enabled under ‘Config > Spider > Extraction’, then set up custom search.
Click ‘Config > Custom > Search’, input the text you wish to find and choose ‘Page Text’. Look under the ‘Custom Search’ tab for details of pages that contain the text.

In the above, the PDF at the top has ‘1’ occurrence of the phone number.
Bulk Save PDFs
To save copies of PDFs while crawling, enable ‘Store PDF‘ under ‘Config > Spider > Extraction’ and then use ‘Bulk Export > Web > All PDF Documents’ export.

This will save every PDF file discovered and crawled to a folder of your choice.
Bulk Export PDF Content
The SEO Spider allows you to export the raw text content of PDFs as .txt files.
Enable ‘Store PDF‘ under ‘Config > Spider > Extraction’ and click ‘Bulk Export > Web > All PDF Content’.

This will export each PDFs content to a separate text file in a chosen location.
Summary
The guide above should illustrate how to use the SEO Spider when auditing PDFs, both for common SEO related issues, general website maintenance and compliance.
Please see our user guide, tutorials and FAQs for more information on the tool.
If you have any further queries, feedback or suggestions to improve the spell checker tool in the SEO Spider then just get in touch with our team via support.




