SEO Spider
How To Crawl JavaScript Websites
Introduction To Crawling JavaScript
Historically search engine bots such as Googlebot didn’t crawl and index content created dynamically using JavaScript and were only able to see what was in the static HTML source code.
However with growth in JavaScript rich websites and frameworks such as Angular, React, Vue.JS, single page applications (SPAs) and progressive web apps (PWAs) this changed. Google evolved and deprecated their old AJAX crawling scheme, and now renders web pages like a modern-day browser before indexing them.
While Google are generally able to crawl and index most JavaScript content, they still advise using server-side rendering or pre-rendering, rather than relying on a client-side approach as its ‘difficult to process JavaScript, and not all search engine crawlers are able to process it successfully or immediately’.
Due to this growth and search engine advancements, it’s essential to be able to read the DOM after JavaScript has been executed to understand the differences to the original response HTML when evaluating websites.
Traditionally website crawlers were not able to crawl JavaScript websites either, until we launched the first ever JavaScript rendering functionality into our Screaming Frog SEO Spider software.

This means pages are fully rendered in a headless browser first, and the rendered HTML after JavaScript has been executed is crawled.
Like Google we use Chrome for our web rendering service (WRS) and keep this updated to be as close to ‘evergreen’. The exact version used in the SEO Spider can be viewed within the app (‘Help > Debug’ on the ‘Chrome Version’ line).
This guide contains 4 sections –
- JavaScript SEO Basics
- How To Identify JavaScript
- When To Crawl Using JavaScript
- How To Crawl JavaScript Websites
If you’re already familiar with JavaScript SEO basics, you can skip straight to How To Crawl a JavaScript Websites section, or read on.
JavaScript SEO Basics
If you’re auditing a website you should get to know how it’s built and whether it’s relying on any client-side JavaScript for key content or links. JavaScript frameworks can be quite different to one another, and the SEO implications are different to a traditional HTML site.
Core JavaScript Principles
While Google can typically crawl and index JavaScript, there’s some core principles and limitations that need to be understood.
- All the resources of a page (JS, CSS, imagery) need to be available to be crawled, rendered and indexed.
- Google still require clean, unique URLs for a page, and links to be to be in proper HTML anchor tags (you can offer a static link, as well as calling a JavaScript function).
- They don’t click around like a user and load additional events after the render (a click, a hover or a scroll for example).
- The rendered page snapshot is taken when network activity is determined to have stopped, or over a time threshold. There is a risk if a page takes a very long time to render it might be skipped and elements won’t be seen and indexed.
- Typically Google will render all pages, however they will not queue pages for rendering if they have a ‘noindex’ in the initial HTTP response or static HTML.
- Google’s rendering is separate to indexing. Google initially crawls the static HTML of a website, and defers rendering until it has resource. Only then will it discover further content and links available in the rendered HTML. Historically this could take a week, but Google have made significant improvements to the point that the median time is now down to just 5 seconds.
It’s essential you know these things with JavaScript SEO, as a website will live and die by the render in rankings.
Rendering Strategy
Google advise developing with progressive enhancement, building the site’s structure and navigation using only HTML and then improving the site’s appearance and interface with JavaScript.
Rather than relying on client-side JavaScript, Google recommend server-side rendering, static rendering or hydration as a solution which can improve performance for users and search engine crawlers.
- Server-side rendering (SSR) and pre-rendering execute the pages JavaScript and delivering a rendered initial HTML version of the page to both users and search engines.
- Hydration and hybrid rendering (also called ‘Isomorphic’) is where rendering can take place on the server-side for the initial page load and HTML, and client-side for non critical elements and pages afterwards.
Many JavaScript frameworks such as React or Angular Universal allow for server-side and hybrid rendering.
Dynamic rendering can be used as a workaround, however Google do not recommend this as a long-term solution. This can be useful when changes can’t be made to the front-end codebase. Dynamic rendering means switching between client-side rendered for users and pre-rendered content for specific user agents (in this case, the search engines). This means crawlers will be served a static HTML version of the web page for crawling and indexing.
Dynamic rendering is seen as a stop-gap, rather than a long-term strategy as it doesn’t have the user experience or performance benefits that some of the above solutions. If you have this set-up, then you can test this by switching the user-agent to Googlebot within the SEO Spider (‘Config > User-Agent’).
JavaScript Indexing Complications
Even though Google are generally able to crawl and index JavaScript, there are further considerations.
Google have a two-phase indexing process, where by they initially crawl and index the static HTML, and then return later when resources are available to render the page and crawl and index content and links in the rendered HTML.
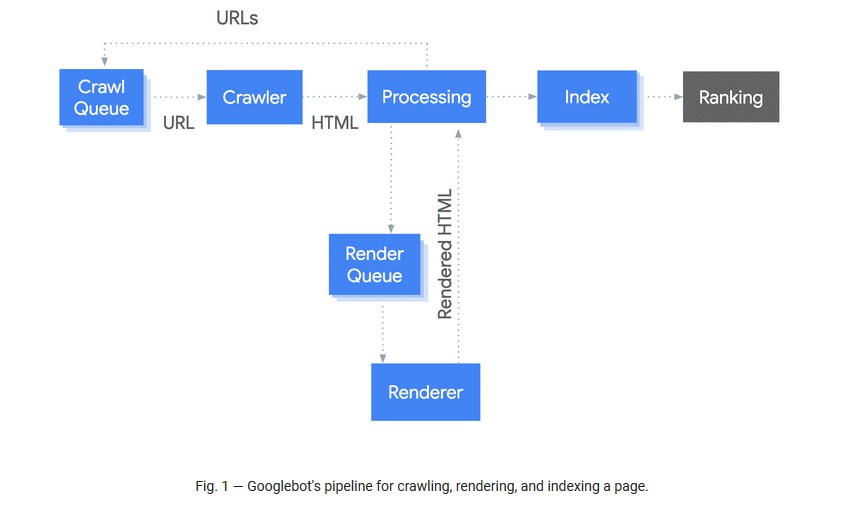
The median time between crawling and rendering is 5 seconds – however, it is dependent on resource availability and therefore it can be longer, which might be problematic for websites that rely on timely content (such as publishers).
If for some reason the render takes longer, then elements in the original response (such as meta data and canonicals) can be used for the page, until Google gets around to rendering it when resources are available. All pages will be rendered unless they have a robots meta tag or header instructing Googlebot not to index the page. So the initial HTML response also needs to be consistent.
Other search engines like Bing struggle to render and index JavaScript at scale and due to the fragility of JavaScript, it’s fairly easy to experience errors or block resources required for rendering – that may hinder the render, and indexing of content.
In summary, there are lots of subtleties in rendering and indexing –
Whether it’s two-phase indexing, JavaScript errors, blocking of resources, or directives in the raw HTML that instruct bots to not even go to the rendering phase.
While often these are not a problem, relying on client-side rendering can mean that a mistake or simple oversight is extremely costly as it impacts the indexing of pages.
How To Identify JavaScript
Identifying a site built using a JavaScript framework can be pretty simple, however, identifying pages, sections, or HTML elements and tags which are dynamically adapted using JavaScript can be more challenging.
There’s a number of ways you’ll know whether the site is built using JavaScript.
Crawling
This is a start point for many, and you can just go ahead and start a crawl of a website with default settings using the Screaming Frog SEO Spider.
By default it will crawl in ‘text only’ mode, which means it crawls the raw HTML before JavaScript has been executed.
If the site is built using client-side JavaScript only, then you will often find only the homepage is crawled with a 200 ‘OK’ response, with a few JavaScript and CSS files.

You’ll also find that the page has no hyperlinks in the lower ‘outlinks’ tab, as they are not being rendered and therefore can’t be seen.

While this is often a sign that the website is using a JavaScript framework, with client-side rendering – it doesn’t tell you about other JavaScript dependencies across the site.
For example, a website might only JavaScript to load products onto category pages, or update title elements.
How do you find these with ease?
To identify JavaScript more efficiently, you’ll need to switch to JavaScript rendering mode (‘Config > Spider > Rendering’) and crawl the site, or a sample of templates from across the website.
The SEO Spider will then crawl both the original and rendered HTML to identify pages that have content or links only available client-side and report other key dependencies.

View the ‘JavaScript tab‘, which contains a comprehensive list of filters around common issues related to auditing websites using client-side JavaScript.
The tool will flag whether there is content only found in the rendered HTML after JavaScript.

In this example, 100% of the content is only in the rendered HTML as the site relies entirely upon JavaScript.
You can also find pages with links that are only in the rendered HTML in a similar way.

Or catch when JavaScript is used to update page titles, or meta descriptions from what’s in the raw HTML.

Find out more about each of the filters in the JavaScript tab in the next section.
While these features help with scale, you can use other tools and techniques to further identify JavaScript.
Client Q&A
This should really be the first step. One of the simplest ways to find out about a website is to speak to the client and the development team and ask the question.
What’s the site built in? Does it use a JavaScript framework, or have any client-side JavaScript dependencies for loading content or links?
Pretty sensible questions, and you might just get a useful answer.
Disable JavaScript
You can turn JavaScript off in your browser and view content available. This is possible in Chrome using the built-in developer tools, or if you use Firefox, the web developer toolbar plugin has the same functionality. Is content available with JavaScript turned off? You may just see a blank page.

Typically it’s also useful to disable cookies and CSS during an audit as well to diagnose for other crawling issues that can be experienced.
Audit View Source
Right click and ‘view page source’ in Chrome. This is the HTML before JavaScript has changed the page.
Is there any text content, or HTML? Often there are signs and hints to JS frameworks and libraries used. Are you able to see the content and hyperlinks within the HTML source code?

You’re viewing code before it’s processed by the browser and what the SEO Spider will crawl, when not in JavaScript rendering mode.
If you run a search and can’t find content or links within the source, then they will be dynamically generated in the DOM and will only be viewable in the rendered code.
If the body is empty like the above example, it’s a pretty clear indication.
Audit The Rendered Source
How different is the rendered code to the static HTML source? Right click and ‘inspect element’ in Chrome, to view the rendered HTML which is after JavaScript execution.

You can often see the JS Framework name in the rendered code, like ‘React’ in the example below.
You will find that the content and hyperlinks are in the rendered code, but not the original HTML source code. This is what the SEO Spider will see, when in JavaScript rendering mode.
By clicking on the opening HTML element, then ‘copy > outerHTML’ you can compare the rendered source code, against the original source.
Toolbars & Plugins
Various toolbars and plugins such as the BuiltWith toolbar, Wappalyser and JS library detector for Chrome can help identify the technologies and frameworks being utilised on a web page at a glance.
These are not always accurate, but can provide some valuable hints, without much work.
When To Crawl Using JavaScript
While Google generally render every web page, we still recommend using JavaScript crawling selectively –
- When analysing a website for the first time to identify JavaScript.
- Auditing with known client-side dependencies.
- During large site deployments.
Why Selectively?
JavaScript crawling is slower and more intensive, as all resources (whether JavaScript, CSS and images) need to be fetched to render each web page in a headless browser in the background to construct the DOM.
While this isn’t an issue for smaller websites, for a large site with many thousands or more pages, this can make a big difference. If your site doesn’t rely on JavaScript to dynamically manipulate a web page significantly, then there’s no need to waste time and resource.
If you’d prefer to crawl with JavaScript rendering enabled by default, then set JavaScript rendering mode via ‘Config > Spider > Rendering’ and save your configuration.
How To Crawl JavaScript Rich Websites
To crawl JavaScript rich websites and frameworks, such as Angular, React and Vue.js and identify dependencies, switch to JavaScript rendering mode.
The following 10 steps should help you configure and audit a JavaScript website for most cases encountered.
1) Configure Rendering To ‘JavaScript’
To crawl a JavaScript website, open up the SEO Spider, click ‘Configuration > Spider > Rendering’ and change ‘Rendering’ to ‘JavaScript’.

2) Configure User-Agent & Window Size
The default viewport for rendering is set to Googlebot Smartphone, as Google primarily crawls and indexes pages with their smartphone agent for mobile-first indexing.

This will mean you’ll see a mobile sized screenshot in the lower ‘rendered page’ tab.
You can configure both the user-agent under ‘Configuration > HTTP Header > User-Agent’ and window size by clicking ‘Configuration > Spider > Rendering’ in JavaScript rendering mode to your own requirements.
3) Check Resources & External Links
Ensure resources such as images, CSS and JS are ticked under ‘Configuration > Spider’.
If resources are on a different subdomain, or a separate root domain, then ‘check external links‘ should be ticked, otherwise they won’t be crawled and hence rendered either.

This is the default configuration in the SEO Spider, so you can simply click ‘File > Default Config > Clear Default Configuration’ to revert to this set-up.
4) Crawl The Website
Now type or paste in the website you wish to crawl in the ‘enter url to spider’ box and hit ‘Start’.

The crawling experience is different to a standard crawl, as it can take time for anything to appear in the UI to start with, then all of a sudden lots of URLs appear together at once. This is due to the SEO Spider waiting for all the resources to be fetched to render a page before the data is displayed.
5) View JavaScript Tab
The JavaScript tab has 15 filters that help make you aware of JavaScript dependencies and common issues.
You’re able to filter by the following SEO related items –
- Pages with Blocked Resources – Pages with resources (such as images, JavaScript and CSS) that are blocked by robots.txt. This can be an issue as the search engines might not be able to access critical resources to be able to render pages accurately. Update the robots.txt to allow all critical resources to be crawled and used for rendering of the websites content. Resources that are not critical (e.g. Google Maps embed) can be ignored.
- Contains JavaScript Links – Pages that contain hyperlinks that are only discovered in the rendered HTML after JavaScript execution. These hyperlinks are not in the raw HTML. While Google is able to render pages and see client-side only links, consider including important links server side in the raw HTML.
- Contains JavaScript Content – Pages that contain body text that’s only discovered in the rendered HTML after JavaScript execution. While Google is able to render pages and see client-side only content, consider including important content server side in the raw HTML.
- Noindex Only in Original HTML – Pages that contain a noindex in the raw HTML, and not in the rendered HTML. When Googlebot encounters a noindex tag, it skips rendering and JavaScript execution. Because Googlebot skips JavaScript execution, using JavaScript to remove the ‘noindex’ in the rendered HTML won’t work. Carefully review pages with noindex in the raw HTML are expected to not be indexed. Remove the ‘noindex’ if the pages should be indexed.
- Nofollow Only in Original HTML – Pages that contain a nofollow in the raw HTML, and not in the rendered HTML. This means any hyperlinks in the raw HTML pre to JavaScript execution will not be followed. Carefully review pages with nofollow in the raw HTML are expected not to be followed. Remove the ‘nofollow’ if links should be followed, crawled and indexed.
- Canonical Only in Rendered HTML – Pages that contain a canonical only in the rendered HTML after JavaScript execution. Google can process canonicals in the rendered HTML, however they do not recommend relying upon JavaScript and prefer them earlier in the raw HTML. Problems with rendering, conflicting, or multiple rel=”canonical” link tags may lead to unexpected results. Include a canonical link in the raw HTML (or HTTP header) to ensure Google can see it and avoid relying only on the canonical in the rendered HTML only.
- Canonical Mismatch – Pages that contain a different canonical link in the raw HTML to the rendered HTML after JavaScript execution. Google can process canonicals in the rendered HTML after JavaScript has been processed, however conflicting rel=”canonical” link tags may lead to unexpected results. Ensure the correct canonical is in the raw HTML and rendered HTML to avoid conflicting signals to search engines.
- Page Title Only in Rendered HTML – Pages that contain a page title only in the rendered HTML after JavaScript execution. This means a search engine must render the page to see it. While Google is able to render pages and see client-side only content, consider including important content server side in the raw HTML.
- Page Title Updated by JavaScript – Pages that have page titles that are modified by JavaScript. This means the page title in the raw HTML is different to the page title in the rendered HTML. While Google is able to render pages and see client-side only content, consider including important content server side in the raw HTML.
- Meta Description Only in Rendered HTML – Pages that contain a meta description only in the rendered HTML after JavaScript execution. This means a search engine must render the page to see it. While Google is able to render pages and see client-side only content, consider including important content server side in the raw HTML.
- Meta Description Updated by JavaScript – Pages that have meta descriptions that are modified by JavaScript. This means the meta description in the raw HTML is different to the meta description in the rendered HTML. While Google is able to render pages and see client-side only content, consider including important content server side in the raw HTML.
- H1 Only in Rendered HTML – Pages that contain an h1 only in the rendered HTML after JavaScript execution. This means a search engine must render the page to see it. While Google is able to render pages and see client-side only content, consider including important content server side in the raw HTML.
- H1 Updated by JavaScript – Pages that have h1s that are modified by JavaScript. This means the h1 in the raw HTML is different to the h1 in the rendered HTML. While Google is able to render pages and see client-side only content, consider including important content server side in the raw HTML.
- Uses Old AJAX Crawling Scheme URLs – URLs that are still using the Old AJAX crawling scheme (a URL containing a #! hash fragment) which was officially deprecated as of October 2015. Update URLs to follow JavaScript best practices on the web today. Consider server-side rendering or pre-rendering where possible, and dynamic rendering as a workaround solution.
- Uses Old AJAX Crawling Scheme Meta Fragment Tag – URLs include a meta fragment tag that indicates the page is still using the Old AJAX crawling scheme which was officially deprecated as of October 2015. Update URLs to follow JavaScript best practices on the web today. Consider server-side rendering or pre-rendering where possible, and dynamic rendering as a workaround solution. If the site still has the old meta fragment tag by mistake, then this should be removed.
6) Monitor Blocked Resources
Keep an eye on anything appearing under the ‘Pages With Blocked Resources’ filter in the ‘JavaScript’ tab. You can glance at the right-hand overview pane, rather than click on the tab. If JavaScript, CSS or images are blocked via robots.txt (don’t respond, or error), then this will impact rendering, crawling and indexing.

Blocked resources can also be viewed for each page within the ‘Rendered Page’ tab, adjacent to the rendered screen shot in the lower window pane. In severe cases, if a JavaScript site blocks JS resources completely, then the site simply won’t crawl.
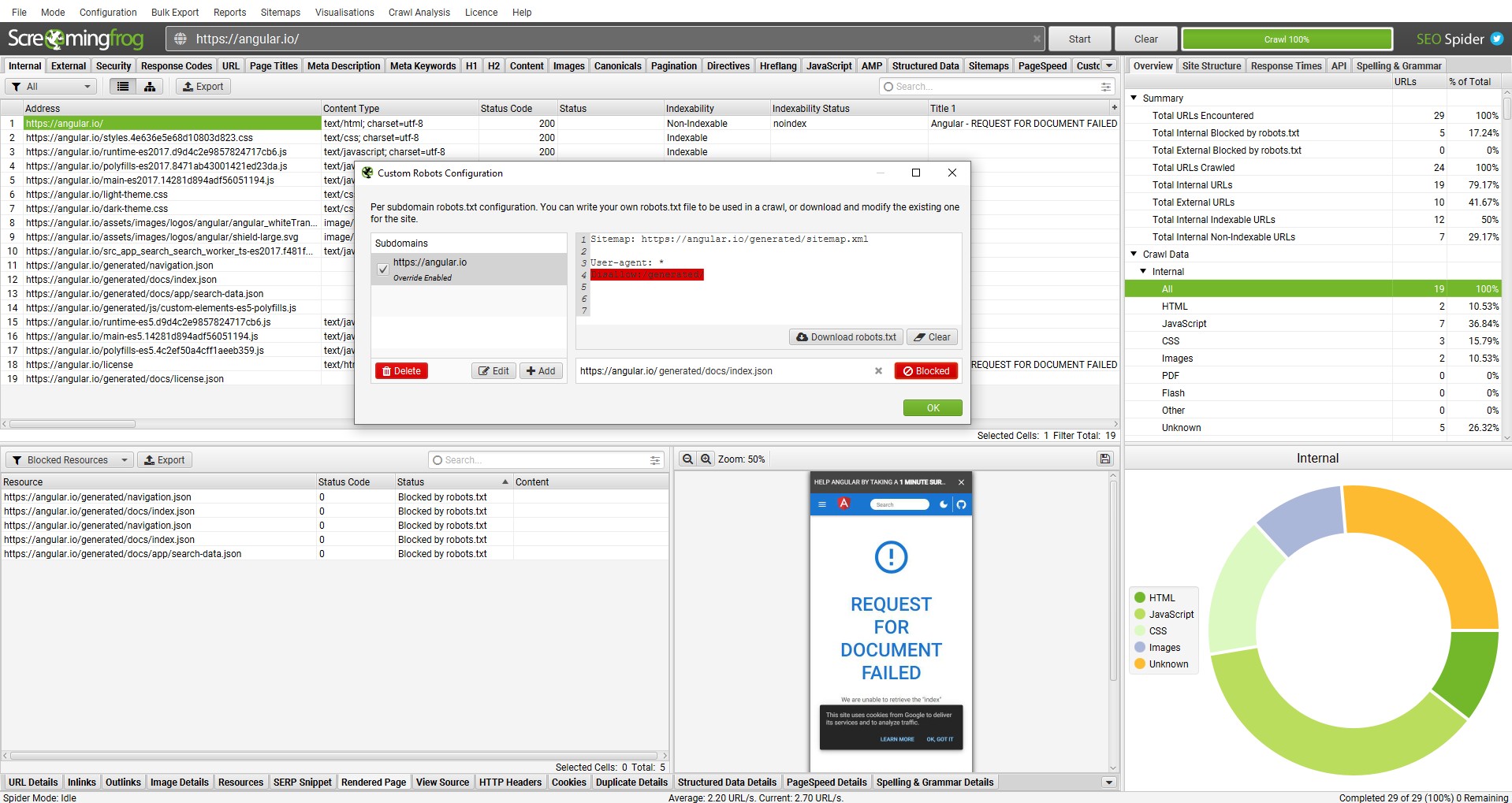
If key resources which impact the render are blocked, then unblock them to crawl (or allow them using the custom robots.txt for the crawl). You can test different scenarios using both the exclude and custom robots.txt features.
The individual blocked resources can also be viewed under ‘Response Codes > Blocked Resource’.

They can be exported in bulk including the source pages via the ‘Bulk Export > Response Codes > Blocked Resource Inlinks’ report.

7) View Rendered Pages
You can view a rendered page screenshot the SEO Spider crawled in the lower ‘Rendered Page’ tab when crawling in JavaScript rendering mode and selecting URLs in the top window.
Viewing the rendered page can be useful when analysing what a modern search bot is able to see and is particularly useful when performing a review in staging, where you can’t use Google’s own URL Inspection Tool in Google Search Console.

If you spot any problems in the rendered page screen shots and it isn’t due to blocked resources, you may need to consider adjusting the AJAX timeout, or digging deeper into the rendered HTML source code for further analysis.
8) Compare Raw & Rendered HTML & Visible Content
You may wish to store and view HTML and rendered HTML within the SEO Spider when working with JavaScript. This can be set-up under ‘Configuration > Spider > Extraction’ and ticking the appropriate store HTML & store rendered HTML options.
This then populates the lower window ‘view source’ pane, to enable you to compare the differences, and be confident that critical content or links are present within the DOM. Click ‘Show Differences’ to see a diff.

This is super useful for a variety of scenarios, such as debugging the differences between what is seen in a browser and in the SEO Spider, or just when analysing how JavaScript has been rendered, and whether certain elements are within the code.
If the ‘JavaScript Content’ filter has triggered for a page, you can switch the ‘HTML’ filter to ‘Visible Content’ to identify exactly which text content is only in the rendered HTML.

9) Identify JavaScript Only Links
If the ‘Contains JavaScript Links’ filter has triggered, you can identify which hyperlinks are only discovered in the rendered HTML after JavaScript execution by clicking on a URL in the top window, then the lower ‘Outlinks’ tab and selecting the ‘Rendered HTML’ link origin filter.
This can be helpful when only specific links, such as products on category pages are loaded using JavaScript. You can bulk export all links that rely on JavaScript via ‘Bulk Export > JavaScript > Contains JavaScript Links’.
10) Adjust The AJAX Timeout
Based upon the responses of your crawl, you can choose when the snapshot of the rendered page is taken by adjusting the ‘AJAX timeout‘ which is set to 5 seconds, under ‘Configuration > Spider > Rendering’ in JavaScript rendering mode.

The 5 second timeout is generally fine for most websites, and Googlebot is more flexible as they adapt based upon how long a page takes to load content, considering the event loop to determine when the network is at idle. They also perform a lot of caching. However, Google and users obviously won’t wait forever, so content that you want to be crawled and indexed, needs to be available quickly, or it simply won’t be seen.
It’s worth noting that a crawl by our software will often be more resource intensive than a regular Google crawl over time. This might mean that the site response times are typically slower, and the AJAX timeout requires adjustment.
You’ll know this might need to be adjusted if the site fails to crawl properly, ‘response times’ in the ‘Internal’ tab are longer than 5 seconds, or web pages don’t appear to have loaded and rendered correctly in the ‘rendered page’ tab.
How To Crawl JavaScript Video
If you prefer video, then check out our tutorial on crawling JavaScript.

Closing Thoughts
The guide above should help you identify JavaScript websites and crawl them efficiently using the Screaming Frog SEO Spider tool in JavaScript rendering mode.
While we have performed plenty of research internally and worked hard to mimic Google’s own rendering capabilities, a crawler is still only ever a simulation of real search engine bot behaviour.
We highly recommend using log file analysis and Google’s own URL Inspection Tool or Rich Results Tool to understand what they are able to crawl, render and index, alongside a JavaScript crawler.
Additional Reading
- Understand the JavaScript SEO Basics – From Google.
- Core Principles of JS SEO – From Justin Briggs.
- Progressive Web Apps Fundamentals Guide – From Builtvisible.
- Crawling JS Rich Sites – From Onely.
If you experience any problems when crawling JavaScript, or encounter any differences between how we render and crawl, and Google, we’d love to hear from you. Please get in touch with our support team directly.




