Readability of Spanish Texts: Alternative Metrics to ‘Flesch Reading Ease’?
MJ Cachón
Posted 9 June, 2025 by MJ Cachón in Screaming Frog SEO Spider, SEO
Readability of Spanish Texts: Alternative Metrics to ‘Flesch Reading Ease’?
When we face the challenge of examining the readability of content in web projects, we find well-known publications and metrics such as Flesch Reading Ease. The importance of these metrics lies in something simple that we should keep in mind: if our texts or contents are not easily understood, we will lose our users.
Readability is a metric that tells us how easy it is to read and understand a text, usually taking into account the length of sentences, the complexity of the words used and, above all, the structure of the language.
The most commonly known metric is the Flesch Reading Ease, created by Rudolf Flesch in 1948. This formula will generate a score where the higher it is, the easier it will be to read the text and will help us to identify content that can be improved and aligned to the level of our target audience.
This article is a guest contribution from MJ Cachón, Managing Director of Laika.
Relationship Between Readability and SEO
We have been hearing for years and years about EEAT, content quality and user experience (UX) in everything related to SEO projects. If search engines reward useful, clear and user-friendly content, readability can be an additional component to consider, or at least the starting point before analysing the quality of the content itself.
On the other hand, understanding how users interact with our content can be key to offering the best, most easily scannable and, above all, understandable content.
When the text is dense, poorly structured or full of unnecessary technical jargon, it generates friction. And where there is friction, the user leaves, loses trust or simply doesn’t understand.
Additionally, in certain complex sectors that require a higher level of research, motivation and even attention, such as medical or financial, where the user may start from a low level of prior knowledge, the language and wording we use can complicate it even more.
And keep in mind, we don’t write simply for SEO, we write to connect with the user and show them that we are an option for them, and for that we have to be readable, understandable and show all our expertise.
Why Look for Alternatives for Spanish?
The original Flesch Reading Ease metric is designed for the English language, so using it for the Spanish language is not entirely reliable, especially if we look at the differences between the two languages:
- In Spanish there are much longer sentences
- Words have more syllables
- The syntactic structures can be much more complex
- Verb conjugations are more extensive
The justification for creating this approach is that languages are quite different:
We need a more granular and language-specific approach that avoids biases by containing longer words or words with a higher number of syllables.
For these reasons, it is better to look for an alternative and not to incur ‘false positives’ or ‘false negatives’ of readability in our Spanish content projects.
What options do we have as an alternative?
Flesch-Szigriszt
An adaptation of the Flesch index to Spanish is the mathematical formula developed by the researcher Pedro Szigriszt Pazos in 1993 which takes into account the number of words per sentence and the number of syllables per 100 words.
The formula he proposes and its coefficients were empirically adjusted using Spanish corpus, so this adaptation is not a simple translation of the English-based Flesch index.
Flesch-Fernández Huerta
It is a direct adaptation of the Flesch Reading Ease, but adjusted with specific weights for Spanish structures.
It is practically the same formula as Flesch-Szigriszt, but applied on a different evaluation basis and it is quite common to see both authors related.
However, it is less popular nowadays.
INFLESZ
It is a set of metrics developed by Barrio-Cantalejo, which combines several metrics for Spanish mainly in the health and academic fields. It would probably be the best method to use in these areas.
There is no public formula as clear and accessible as Flesch-Szigriszt, but conceptually it also uses syllables/words/phrases.
Why use Flesch-Szigriszt?
There are several reasons:
- It has been tested on real Spanish language corpus.
- The interpretation is easy and simple
- It is the most commonly used and popular
We can use either the original formula or the simplified one.
Original formula proposed by Pedro Szigriszt Pazos in his 1993 doctoral thesis:
Flesch-Szigriszt Index = 206.835 - (62.3 × (syllables / words)) - (words / sentences)
Simplified version of the original formula by Pedro Szigriszt Pazos:
Flesch-Szigriszt Index = 206.84-(0.60×Syllables per 100 words)-(1.02×Words per sentence)
Practical Example
If we had a text with 100 words in 10 sentences, this would mean 10 words per sentence. The original readability formula would reduce it by 10 points, in the simplified one by 10.2.
However, if we had a text with 100 words in 2 sentences, this would mean 50 words per sentence. The original readability formula would reduce it by 50 points, in the simplified one by 51 points.
The concept is the same, the level of correction may vary.
After all, these approaches only reaffirm the consequences that complex writing can have on users:
- Cognitive overload: amount of information to store in memory
- Complex structure: excessively subordinated language
- Increased risk of confusion: it would be easier to get lost in the reading because of the structure
Data Interpretation
Using the original formula or the simplified one will depend on how concise we want to be and the context of the project we are analysing.
While the simplified one is based on rescaled coefficients from the English model and tends to smooth the results, but may fail in texts with many words of more than 3 syllables, the original one is tested and validated in Spanish corpus, as well as adapting more accurately to the language.
However, for large-scale studies or analyses, it may be sufficient to use the simplified formula, and if we are going to go into more academic or accessibility studies, we can use the original formula.
To interpret the Flesch-Szigriszt index, the higher the value, the easier it is to read.
As Olga Carreras recommends in her article on readability:
‘If we had to select therefore the most appropriate formula today to measure the readability of texts in Spanish, I think we can say that it would be the Flesch-Szigriszt formula, but using for the interpretation of the score obtained the Inflesz scale ’.
Therefore, these would be the ranges of the score and their levels of readability or type of reader using the Inflesz scale:

To interpret the data we can set that texts for the general public should be from 65.
Based on the type of project we are working on and the level of knowledge of the users, we could define our own ranges. For example, a technical topic may justify lower scores, but if the users aren’t experts, they will not be able to understand the content, these are the two variables to consider.
For example, for texts whose scores are below 55, we can consider simplifying the syntax, reducing long sentences and avoiding complex words.
This metric can also be used in combination with other qualitative analysis techniques with users, such as user recordings, surveys or eye tracking systems.
Finally, it is highly recommended to be aware of the content consumption patterns of online users, such as F-patterns and other trends that suggest the existence of factors why people scan and do not read, among other things.
How to Configure the Screaming Frog SEO Spider to Analyse Readability in Spanish: Step by Step
Since the SEO Spider does not yet have a specific metric for Spanish, we can create it using its Custom Javascript option.
I am going to show two ways to do it, in both of them, the path to follow is the same, I will explain it step by step.
Step 1: Configuration
To use this functionality you need to use JavaScript rendering in:
Crawl Config > Spider > Rendering
Once this is done, we can go to our JavaScript snippets from:
Crawl Config > Custom > Custom JavaScript

Step 2: Add Code From Scratch or From the Library
We will come up with something like this:
- We use ‘Add’ when we want to create a blank JS snippet from scratch.
- We use ‘Add From Library’ when we want to access the default saved JS snippets or those you have previously saved to use more times.
Now let’s see what the panel looks like where we upload our code assuming we have chosen ‘Add’ to start blank:

- The left panel is where we paste our code
- We can choose whether the JS snippet is to extract information (calculate and return readability data) or to perform an action (e.g. scroll), there is more information on this here.
- We can also choose what type of content to apply the JS snippet to
- If it is a common snippet that we usually use, we can save it in ‘Add Snippet to User Library’, to access it quickly in other crawls.
- Finally, in the right area you can test the JS snippet before crawling the site, which is very useful for spotting errors and not wasting time.
Step 3: Create as Many as We Need and Test Them Before Crawling the Site.

In my case I have added 8 snippets, the more you add, the slower the crawl will go, keep this in mind.
Now it only remains to explain how to approach the creation of the code to control the process and avoid false positives or negatives.
Two Readability Analysis Methodologies in the Screaming Frog SEO Spider
For the analysis I suggest two ways of doing it, a first one in which we look at the whole <body> to find its content, put it together, remove spaces or line breaks, make it lowercase and even remove accents, as a clean up prior to performing the calculation of the Flesch-Szigriszt index.
And a second one in which we will use an Xpath expression specific to the area of the html where the main content is located.
Finally, in order to have a clear idea of the differences between the original formula and the simplified formula, I am going to extract both calculations for the 2 suggested methods.
Method 1: Based on the Full Content of the Body
These codes will extract all the nodes from the body and do the text extraction and cleaning to proceed to calculate the index, all in one step.
This first code refers to the original formula:
// Flesch-Szigriszt Index (original 1993 formula)
function countSentences(text) {
return (text.match(/[.!?¡¿]+/g) || []).length || 1; // avoid division by 0
}
function countWords(text) {
return text.split(/\s+/).filter(Boolean).length;
}
function countSyllables(word) {
word = word.toLowerCase().normalize("NFD").replace(/[\u0300-\u036f]/g, ""); // removes accents
const syllableGroups = word.match(/[aeiouáéíóúü]{1,2}/g);
return syllableGroups ? syllableGroups.length : 1;
}
function totalSyllables(text) {
const words = text.split(/\s+/).filter(Boolean);
return words.reduce((acc, word) => acc + countSyllables(word), 0);
}
// Extract and clean text from body
let bodyText = document.body.innerText
.replace(/\s+/g, ' ')
.replace(/[\r\n\t]+/g, ' ')
.trim();
// Base calculations
let sentenceCount = countSentences(bodyText);
let wordCount = countWords(bodyText);
let syllableCount = totalSyllables(bodyText);
// Original formula: 206.835 - (62.3 * (syllables/words)) - (words/sentences)
let fleschSzigriszt = 206.835 - (62.3 * (syllableCount / wordCount)) - (wordCount / sentenceCount);
// Round result
fleschSzigriszt = Math.round(fleschSzigriszt * 100) / 100;
// Return result
return seoSpider.data(fleschSzigriszt);This second code refers to the simplified formula:
// Flesch-Szigriszt Index (simplified formula)
function countSentences(text) {
return (text.match(/[.!?]+/g) || []).length || 1; // avoid division by 0
}
function countWords(text) {
return text.split(/\s+/).filter(Boolean).length;
}
function countSyllables(word) {
word = word.toLowerCase().normalize("NFD").replace(/[\u0300-\u036f]/g, ""); // removes accents
const syllableGroups = word.match(/[aeiouáéíóúü]{1,2}/g);
return syllableGroups ? syllableGroups.length : 1;
}
function totalSyllables(text) {
const words = text.split(/\s+/).filter(Boolean);
return words.reduce((acc, word) => acc + countSyllables(word), 0);
}
// Extract clean text
let bodyText = document.body.innerText
.replace(/\s+/g, ' ')
.replace(/[\r\n\t]+/g, ' ')
.trim();
// Calculate basic elements
let sentenceCount = countSentences(bodyText);
let wordCount = countWords(bodyText);
let syllableCount = totalSyllables(bodyText);
// Calculate Flesch-Szigriszt index
let syllablesPerWord = syllableCount / wordCount;
let wordsPerSentence = wordCount / sentenceCount;
let fleschSzigriszt = 206.84 - (0.60 * syllablesPerWord * 100) - (1.02 * wordsPerSentence);
// Round result
fleschSzigriszt = Math.round(fleschSzigriszt * 100) / 100;
// Return result
return seoSpider.data(fleschSzigriszt);Additionally, I recommend creating an extra code as a control field to understand on which specific text the readability index is being generated and to check for possible weird data. You just need to create an extra custom JavaScript to query it if needed or you can always extract the raw content using Xpath and Custom Extraction, choose what you prefer!
// Extracts visible text from <body> and cleans it for analysis
let bodyText = document.body.innerText
.replace(/\s+/g, ' ') // Unifies spaces, line breaks, tabs, etc.
.replace(/^\s+|\s+$/g, '') // Removes spaces at the beginning and end
.normalize("NFD") // Normalizes accents for readability if desired
.replace(/[\u0300-\u036f]/g, '') // Removes accents if you want neutral text
return seoSpider.data(bodyText);
Method 2: Based on the Custom Xpath Where the Specific Content Is Located
This version of the code will extract all the nodes from the given Xpath and do the text extraction and cleanup to proceed to calculate the index.
Note that the code will use all the nodes hanging from the Xpath expression, if you only want the first node, you would have to adapt the code.
This first code refers to the original formula:
// Flesch-Szigriszt Index Original + XPath
let xpath = "//div[@class='left-column']//p";
// Helper functions (declared outside the main block)
function countSentences(t) {
return (t.match(/[.!?¡¿]+/g) || []).length || 1;
}
function countWords(t) {
return t.split(/\s+/).filter(Boolean).length;
}
function countSyllables(w) {
w = w.toLowerCase().normalize("NFD").replace(/[\u0300-\u036f]/g, "");
const syllableGroups = w.match(/[aeiouáéíóúü]{1,2}/g);
return syllableGroups ? syllableGroups.length : 1;
}
function totalSyllables(t) {
const words = t.split(/\s+/).filter(Boolean);
return words.reduce((acc, word) => acc + countSyllables(word), 0);
}
// Retrieve all nodes matching the XPath
let snapshot = document.evaluate(xpath, document, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null);
let combinedText = '';
for (let i = 0; i < snapshot.snapshotLength; i++) {
let node = snapshot.snapshotItem(i);
if (node && node.innerText) {
combinedText += node.innerText + ' ';
}
}
// Clean combined text
let text = combinedText
.replace(/\s+/g, ' ')
.replace(/^\s+|\s+$/g, '')
.trim();
if (text.length === 0) {
return seoSpider.data("XPath contains no text");
}
// Calculate base values
let sentenceCount = countSentences(text);
let wordCount = countWords(text);
let syllableCount = totalSyllables(text);
// Calculate original Flesch-Szigriszt index
// Formula: 206.835 - (62.3 × syllables/words) - (words/sentences)
let fleschSzigriszt = 206.835 - (62.3 * (syllableCount / wordCount)) - (wordCount / sentenceCount);
// Round
fleschSzigriszt = Math.round(fleschSzigriszt * 100) / 100;
// Return result
return seoSpider.data(fleschSzigriszt);This second code refers to the simplified formula:
// Flesch-Szigriszt Simplified Index + XPath...
let xpath = "//div[@class='left-column']//p";
function countSentences(t) {
return (t.match(/[.!?¡¿]+/g) || []).length || 1;
}
function countWords(t) {
return t.split(/\s+/).filter(Boolean).length;
}
function countSyllables(w) {
w = w.toLowerCase().normalize("NFD").replace(/[\u0300-\u036f]/g, "");
const syllableGroups = w.match(/[aeiouáéíóúü]{1,2}/g);
return syllableGroups ? syllableGroups.length : 1;
}
function totalSyllables(t) {
const words = t.split(/\s+/).filter(Boolean);
return words.reduce((acc, word) => acc + countSyllables(word), 0);
}
let snapshot = document.evaluate(xpath, document, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null);
let combinedText = '';
for (let i = 0; i < snapshot.snapshotLength; i++) {
let node = snapshot.snapshotItem(i);
if (node && node.innerText) {
combinedText += node.innerText + ' ';
}
}
// Clean combined text
let text = combinedText
.replace(/\s+/g, ' ')
.replace(/^\s+|\s+$/g, '')
.trim();
if (text.length === 0) {
return seoSpider.data("XPath contains no text");
}
// Calculate Flesch-Szigriszt index
let sentenceCount = countSentences(text);
let wordCount = countWords(text);
let syllableCount = totalSyllables(text);
let syllablesPer100Words = (syllableCount / wordCount) * 100;
let wordsPerSentence = wordCount / sentenceCount;
let fleschSzigriszt = 206.84 - (0.60 * syllablesPer100Words) - (1.02 * wordsPerSentence);
fleschSzigriszt = Math.round(fleschSzigriszt * 100) / 100;
return seoSpider.data(fleschSzigriszt);
As in method 1, we need to create our ‘security field’ to validate the extracted content and see if the calculated readability index makes sense:
// Extracts visible text from the custom XPath
let xpath = "//div[@class='left-column']//p";
// Finds all nodes that match the XPath
let snapshot = document.evaluate(xpath, document, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null);
// Concatenates the visible text from all matched nodes
let combinedText = '';
for (let i = 0; i < snapshot.snapshotLength; i++) {
let node = snapshot.snapshotItem(i);
if (node && node.innerText) {
combinedText += node.innerText + ' ';
}
}
// Cleans the combined text
let cleanText = combinedText
.replace(/\s+/g, ' ') // Unifies spaces, line breaks, etc.
.replace(/^\s+|\s+$/g, '') // Removes leading and trailing spaces
.trim();
// Return the cleaned result or warning
if (cleanText.length > 0) {
return seoSpider.data(cleanText);
} else {
return seoSpider.data("No text found for the specified XPath");
}
If you want to customize the code for your specific case, in any of the codes, replace the Xpath expression inside the line let xpath = ‘//div[@class=’left-column‘]//p’; and replace the expression with your own.
Extra Bonus: Adds Only the Readability Rating Based on the Inflesz Scale
Just as the Screaming Frog SEO Spider displays a numerical readability field and an additional field, with the text scale, we can also replicate this second one, applying the Inflesz scale based on the score each text gets. We could configure the JS snippet for the whole body:
// Flesch-Szigriszt Original Index - Inflesz Scale
function countSentences(text) {
return (text.match(/[.!?¡¿]+/g) || []).length || 1; // avoid division by 0
}
function countWords(text) {
return text.split(/\s+/).filter(Boolean).length;
}
function countSyllables(word) {
word = word.toLowerCase().normalize("NFD").replace(/[\u0300-\u036f]/g, ""); // removes accents
const syllableGroups = word.match(/[aeiouáéíóúü]{1,2}/g);
return syllableGroups ? syllableGroups.length : 1;
}
function totalSyllables(text) {
const words = text.split(/\s+/).filter(Boolean);
return words.reduce((acc, word) => acc + countSyllables(word), 0);
}
function getInfleszScale(score) {
// Inflesz Scale based on research by Inés Mª Barrio Cantalejo
if (score < 40) return "Muy difícil";
if (score < 55) return "Algo difícil";
if (score < 65) return "Normal";
if (score < 80) return "Bastante fácil";
return "Muy fácil";
}
// Extract and clean text from body
let bodyText = document.body.innerText
.replace(/\s+/g, ' ')
.replace(/[\r\n\t]+/g, ' ')
.trim();
// Base calculations
let sentenceCount = countSentences(bodyText);
let wordCount = countWords(bodyText);
let syllableCount = totalSyllables(bodyText);
// Original formula: 206.835 - (62.3 * (syllables/words)) - (words/sentences)
let fleschSzigriszt = 206.835 - (62.3 * (syllableCount / wordCount)) - (wordCount / sentenceCount);
// Round
fleschSzigriszt = Math.round(fleschSzigriszt * 100) / 100;
// Get classification on the Inflesz Scale
let infleszGrade = getInfleszScale(fleschSzigriszt);
// Return only the textual classification (without numeric score)
return seoSpider.data(infleszGrade);And to apply to a specific Xpath:
// Flesch-Szigriszt Original Index Xpath - Inflesz Scale
let xpath = "//div[@class='left-column']//p";
// Helper functions (declared outside the main block)
function countSentences(t) {
return (t.match(/[.!?¡¿]+/g) || []).length || 1;
}
function countWords(t) {
return t.split(/\s+/).filter(Boolean).length;
}
function countSyllables(w) {
w = w.toLowerCase().normalize("NFD").replace(/[\u0300-\u036f]/g, "");
const syllableGroups = w.match(/[aeiouáéíóúü]{1,2}/g);
return syllableGroups ? syllableGroups.length : 1;
}
function totalSyllables(t) {
const words = t.split(/\s+/).filter(Boolean);
return words.reduce((acc, word) => acc + countSyllables(word), 0);
}
function getInfleszScale(score) {
// Inflesz Scale based on research by Inés Mª Barrio Cantalejo
if (score < 40) return "Muy difícil";
if (score < 55) return "Algo difícil";
if (score < 65) return "Normal";
if (score < 80) return "Bastante fácil";
return "Muy fácil";
}
// Retrieve all nodes that match the XPath
let snapshot = document.evaluate(xpath, document, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null);
let combinedText = '';
for (let i = 0; i < snapshot.snapshotLength; i++) {
let node = snapshot.snapshotItem(i);
if (node && node.innerText) {
combinedText += node.innerText + ' ';
}
}
// Clean combined text
let text = combinedText
.replace(/\s+/g, ' ')
.replace(/^\s+|\s+$/g, '')
.trim();
if (text.length === 0) {
return seoSpider.data("XPath contains no text");
}
// Calculate base values
let sentenceCount = countSentences(text);
let wordCount = countWords(text);
let syllableCount = totalSyllables(text);
// Calculate original Flesch-Szigriszt index
// Formula: 206.835 - (62.3 × syllables/words) - (words/sentences)
let fleschSzigriszt = 206.835 - (62.3 * (syllableCount / wordCount)) - (wordCount / sentenceCount);
// Round
fleschSzigriszt = Math.round(fleschSzigriszt * 100) / 100;
// Get classification on the Inflesz Scale
let infleszGrade = getInfleszScale(fleschSzigriszt);
// Return only the textual classification (without numeric score)
return seoSpider.data(infleszGrade);Note that the output of this calculation will be with a scale with texts in Spanish, if you want it to be in English or in another language, you can modify it inside the code:
- Muy difícil → Very difficult
- Algo difícil → Somewhat difficult
- Normal → Fairly easy
- Bastante fácil → Quite easy
For all of the above based on JS snippets it is worth mentioning that Screaming Frog has a fantastic tutorial for identifying problems that can be useful when we don’t know why they don’t work as expected, which you can find here.
Comparing Results
With the crawl finished we can see from the Custom JS tab, all the final values and we are ready to analyse.
This is an example using the SEO Spider’s list mode and adding the URL of the sitemap of my personal blog articles.

Now let’s compare the different methods and see what conclusions we can learn from them.
Original vs. Simplified Formula
If we compare the original and the simplified formula, in the full content method of the <body>, we find average differences of less than 1.35 points.
If we compare the original and the simplified formula, but this time with the content method based on a customized Xpath, we find average differences of around 4 points.
This may be a more objective and realistic figure, but the differences are still small between methods, although it could have an impact on the scale that evaluates the scores.
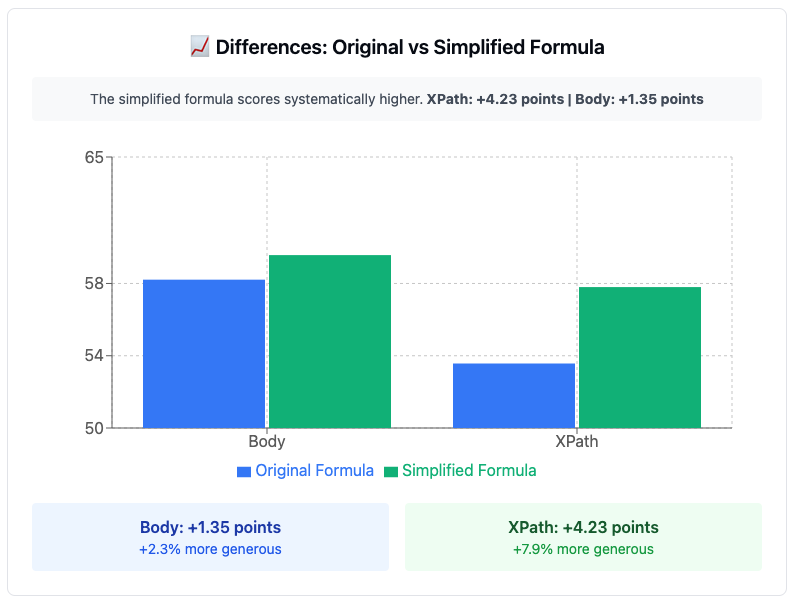
Body vs Xpath
I didn’t want to comment on whether to use the whole content of the <body> or to use only a piece of content based on Xpath, I don’t want to generalizs if one is better or worse.
The point here is that every project is different and I wanted to give two options to make it more actionable.
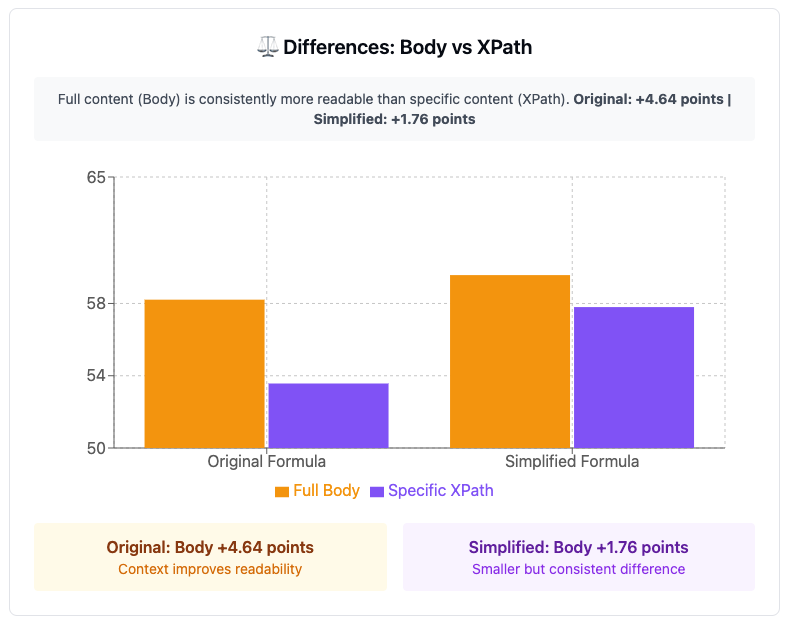
The results show that the complete <body> content is consistently more readable than the specific XPath-based content as it is influenced by additional elements such as navigation, menus and context improve the readability score.
It is worth bearing in mind that choosing one formula or the other, as well as applying it to the
or using a specific Xpath, can make relevant changes to the final scale of interpreting the results.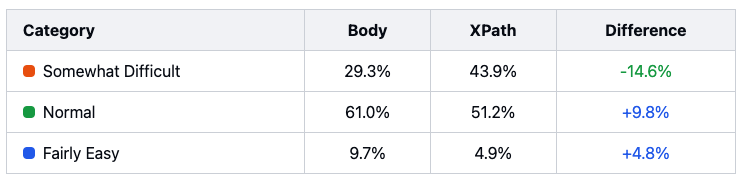
The more specific analysis using Xpath leads us to have almost 15% more difficult content than if we were to look at the <body>, which is not insignificant, on the other hand.
Flesch Reading Ease (en) vs Flesch-Szigriszt (ES)
Despite not being comparable, the Spanish formulas score 12-13 points HIGHER than Flesch Reading Ease, this is neither good nor bad, each formula tries to adapt to the idiosyncrasies of each language and particularities of the language.

This reinforces the need for language-specific metrics in order to have an approximate idea of the real readability of a specific text or a complete url and to avoid making mistakes in analysis and interpretation.
Conclusions, Limitations and Next Steps
Readability is an important factor as a prelude to analysing the content quality of a website. User behaviour can be highly influenced not only by design, reliability, brand awareness, but also by the way the content is written.
The subject matter of the project also plays a fundamental role along with the level of knowledge of the target users, with this in mind, it is crucial to adapt the content and make it as readable as possible as a gateway to retention and loyalty: if they like us, they won’t leave, if they love us, they will come back!
The methodology used is based on expert studies and available literature for the Spanish language, which may include other models or references, but we have chosen to use the most well-known or consolidated ones.
For other languages, the same approach can be replicated, as long as there is a scientific adaptation of the English readability metrics, as a reference or otherwise.
With this approach, I think it is clearly proven that we need language-specific metrics in order to best analyse and measure the readability of texts.
Also to consider that the codes presented may have certain limitations for more special cases that may be outside the use cases covered here.
Despite this, the code has been reviewed and validated by Alfonso Moure, SEO expert and programmer by training, although, of course, comments for improvement are welcome :)
If you come up with other ways to expand this to other cases I’ll be happy to read you in comments and cooperate as much as possible.
Hopefully we’ll see this or a similar approach in a future Screaming Frog SEO Spider update, who knows..!
Finally, if you want to read this article in Spanish, you can do so here.






0 Comments