Custom extraction
si digital
Posted 27 November, 2015 by si digital in
Custom extraction
Configuration > Custom > Extraction
Custom extraction allows you to collect any data from the HTML of a URL. Extraction is performed on the static HTML returned by internal HTML pages with a 2XX response code. You can switch to JavaScript rendering mode to extract data from the rendered HTML (for any data that’s client-side only).
The SEO Spider supports the following modes to perform data extraction:
- XPath: XPath selectors, including attributes.
- CSS Path: CSS Path and optional attribute.
- Regex: For more advanced uses, such as scraping HTML comments or inline JavaScript.
When using XPath or CSS Path to collect HTML, you can choose what to extract:
- Extract HTML Element: The selected element and its inner HTML content.
- Extract Inner HTML: The inner HTML content of the selected element. If the selected element contains other HTML elements, they will be included.
- Extract Text: The text content of the selected element and the text content of any sub elements.
- Function Value: The result of the supplied function, eg count(//h1) to find the number of h1 tags on a page.
To set up custom extraction, click ‘Config > Custom > Custom Extraction’.

Just click ‘Add’ to start setting up an extractor.

Then insert the relevant expression to scrape data. Up to 100 separate extractors can be configured to scrape data from a website with a limit of up to 1,000 extractions across all extractors.

If you’re unfamiliar with XPath, CSSPath and regex, you can use the visual custom extraction feature to select elements to scrape using an inbuilt browser. Click on the ‘browser’ icon next to the extractor.

Enter a URL you wish to extract data from in the URL bar and select the element you wish to scrape.
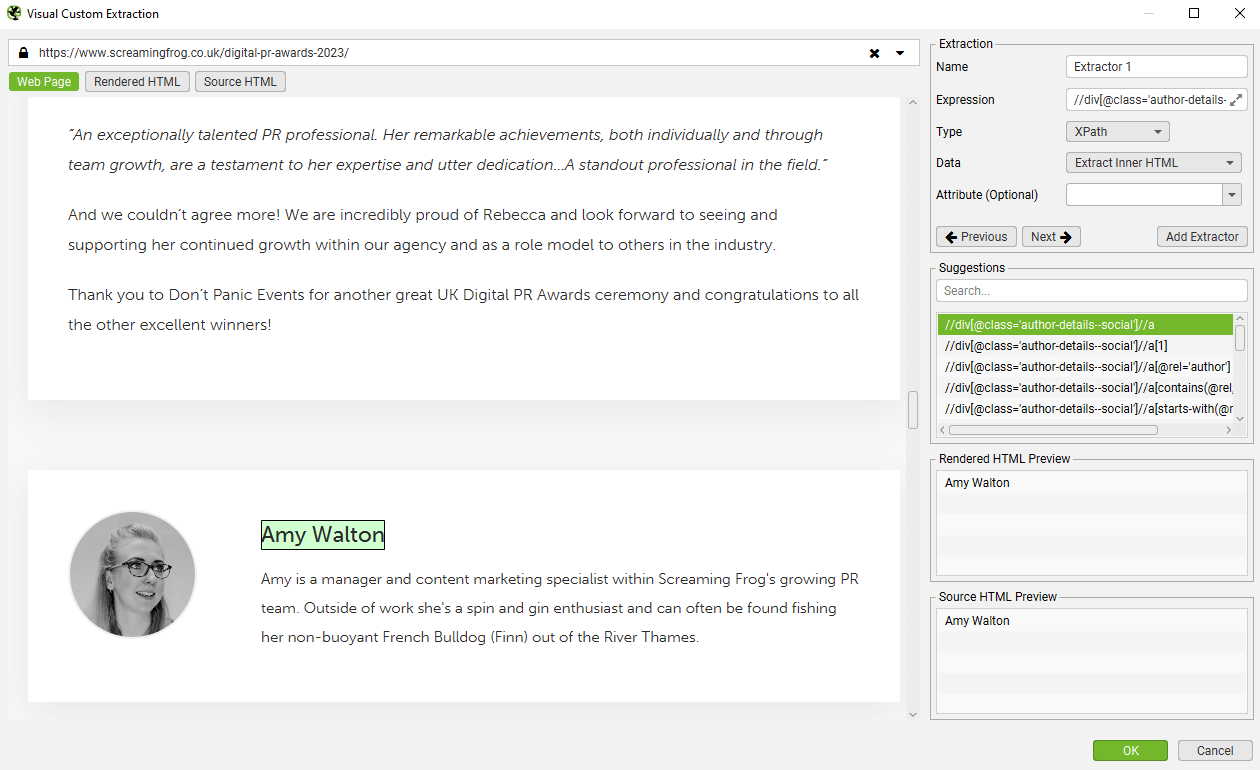
The SEO Spider will then highlight the area on the page, and create a variety of suggested expressions, and a preview of what will be extracted based upon the raw or rendered HTML. In this case, an author name from a blog post.
The data extracted can be viewed in the Custom Extraction tab Extracted data is also included as columns within the ‘Internal’ tab as well.
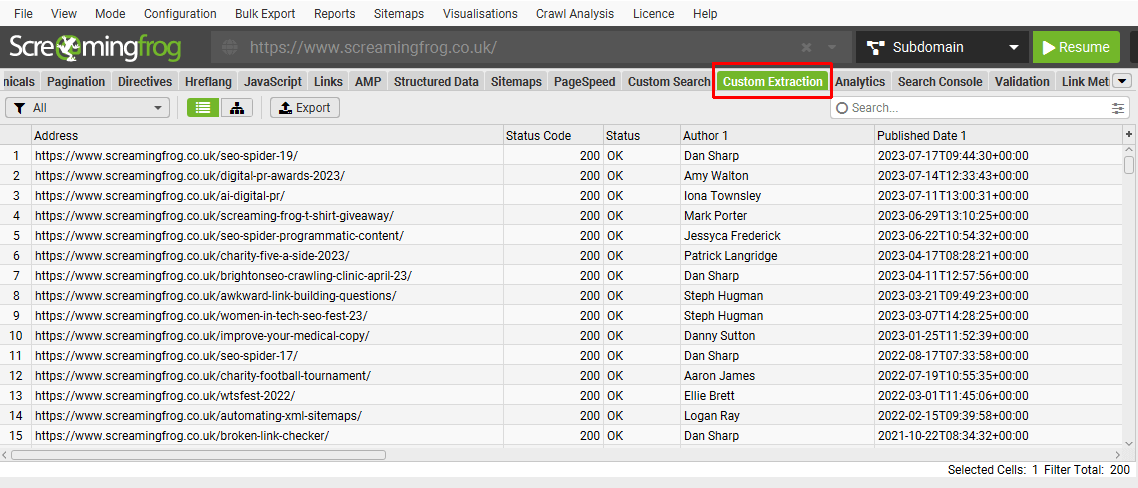
Please read our SEO Spider web scraping guide for a full tutorial on how to use custom extraction. For examples of custom extraction expressions, please see our XPath Examples and Regex Examples.
Regex Troubleshooting
- The SEO Spider does not pre process HTML before running regexes. Please bear in mind however that the HTML you see in a browser when viewing source maybe different to what the SEO Spider sees. This can be caused by the web site returning different content based on User-Agent or Cookies, or if the pages content is generated using JavaScript and you are not using JavaScript rendering.
- More details on the regex engine used by the SEO Spider can be found here.
- The regex engine is configured such that the dot character matches newlines.
- Regular Expressions, depending on how they are crafted, and the HTML they are run against, can be slow. This will have the affect of slowing the crawl down.




