How to Scrape Google Search Features Using XPath
Patrick Langridge
Posted 3 September, 2019 by Patrick Langridge in SEO
How to Scrape Google Search Features Using XPath
Google’s search engine results pages (SERPs) have changed a great deal over the last 10 years, with more and more data and information being pulled directly into the results pages themselves. Google search features are a regular occurrence on most SERPs nowadays, some of most common features being featured snippets (aka ‘position zero’), knowledge panels and related questions (aka ‘people also ask’). Data suggests that some features such as related questions may feature on nearly 90% of SERPs today – a huge increase over the last few years.
Understanding these features can be powerful for SEO. Reverse engineering why certain features appear for particular query types and analysing the data or text included in said features can help inform us in making optimisation decisions. With organic CTR seemingly on the decline, optimising for Google search features is more important than ever, to ensure content is as visible as it possibly can be to search users.
This guide runs through the process of gathering search feature data from the SERPs, to help scale your analysis and optimisation efforts. I’ll demonstrate how to scrape data from the SERPs using the Screaming Frog SEO Spider using XPath, and show just how easy it is to grab a load of relevant and useful data very quickly. This guide focuses on featured snippets and related questions specifically, but the principles remain the same for scraping other features too.
TL;DR
If you’re already an XPath and scraping expert and are just here for the syntax and data type to setup your extraction (perhaps you saw me eloquently explain the process at SEOCamp Paris or Pubcon Las Vegas this year!), here you go (spoiler alert for everyone else!) –
Featured snippet XPath syntax
(//span[@class='S3Uucc'])[1](//span[@class="e24Kjd"])[1]//ul[@class="i8Z77e"]/li//ol[@class="X5LH0c"]/li//table//tr(//div[@class="xpdopen"]//a/@href)[2](//img[@id="dimg_7"]//@title)Related questions XPath syntax
(//g-accordion-expander//h3)[1](//g-accordion-expander//h3)[2](//g-accordion-expander//h3)[3](//g-accordion-expander//h3)[4]//g-accordion-expander//span[@class="e24Kjd"]//g-accordion-expander//h3//g-accordion-expander//div[@class="r"]//a/@hrefYou can also get this list in our accompanying Google doc. Back to our regularly scheduled programming for the rest of you…follow these steps to start scraping featured snippets and related questions!
1) Preparation
To get started, you’ll need to download and install the SEO Spider software and have a licence to access the custom extraction feature necessary for scraping. I’d also recommend our web scraping and data extraction guide as a useful bit of light reading, just to cover the basics of what we’re getting up to here.
2) Gather keyword data
Next you’ll need to find relevant keywords where featured snippets and / or related questions are showing in the SERPs. Most well-known SEO intelligence tools have functionality to filter keywords you rank for (or want to rank for) and where these features show, or you might have your own rank monitoring systems to help. Failing that, simply run a few searches of important and relevant keywords to look for yourself, or grab query data from Google Search Console. Wherever you get your keyword data from, if you have a lot of data and are looking to prune and prioritise your keywords, I’d advise the following –
3) Create a Google search query URL
We’re going to be crawling Google search query URLs, so need to feed the SEO Spider a URL to crawl using the keyword data gathered. This can either be done in Excel using find and replace and the ‘CONCATENATE’ formula to change the list of keywords into a single URL string (replace word spaces with + symbol, select your Google of choice, then CONCATENATE the cells to create an unbroken string), or, you can simply paste your original list of keywords into this handy Google doc with formula included (please make a copy of the doc first).

At the end of the process you should have a list of Google search query URLs which look something like this –
https://www.google.co.uk/search?q=keyword+one
https://www.google.co.uk/search?q=keyword+two
https://www.google.co.uk/search?q=keyword+three
https://www.google.co.uk/search?q=keyword+four
https://www.google.co.uk/search?q=keyword+five etc.
4) Configure the SEO Spider
Experienced SEO Spider users will know that our tool has a multitude of configuration options to help you gather the important data you need. Crawling Google search query URLs requires a few configurations to work. Within the menu you need to configure as follows –
These config options ensure that the SEO Spider can access the features and also not trigger a captcha by crawling too fast. Once you’ve setup this config I’d recommend saving it as a custom configuration which you can load up again in future.
5) Setup your extraction
Next you need to tell the SEO spider what to extract. For this, go into the ‘Configuration’ menu and select ‘Custom’ and ‘Extraction’ –

You should then see a screen like this –

From the ‘Inactive’ drop down menu you need to select ‘XPath’. From the new dropdown which appears on the right hand side, you need to select the type of data you’re looking to extract. This will depend on what data you’re looking to extract from the search results (full list of XPath syntax and data types listed below), so let’s use the example of related questions –
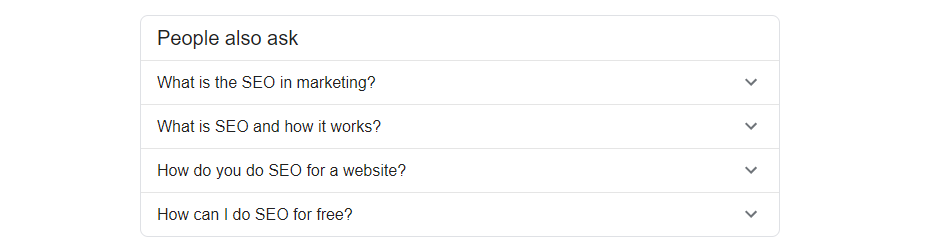
The above screenshot shows the related questions showing for the search query ‘seo’ in the UK. Let’s say we wanted to know what related questions were showing for the query, to ensure we had content and a page which targeted and answered these questions. If Google thinks they are relevant to the original query, at the very least we should consider that for analysis and potentially for optimisation. In this example we simply want the text of the questions themselves, to help inform us from a content perspective.
Typically 4 related questions show for a particular query, and these 4 questions have a separate XPath syntax –
- Question 1 –
(//g-accordion-expander//h3)[1] - Question 2 –
(//g-accordion-expander//h3)[2] - Question 3 –
(//g-accordion-expander//h3)[3] - Question 4 –
(//g-accordion-expander//h3)[4]
To find the correct XPath syntax for your desired element, our web scraping guide can help, but we have a full list of the important ones at the end of this article!
Once you’ve input your syntax, you can also rename the extraction fields to correspond to each extraction (Question 1, Question 2 etc.). For this particular extraction we want the text of the questions themselves, so need to select ‘Extract Text’ in the data type dropdown menu. You should have a screen something like this –

If you do, you’re almost there!
6) Crawl in list mode
For this task you need to use the SEO Spider in List Mode. In the menu go Mode > List. Next, return to your list of created Google search query URL strings and copy all URLs. Return to the SEO Spider, hit the ‘Upload’ button and then ‘Paste’. Your list of search query URLs should appear in the window –
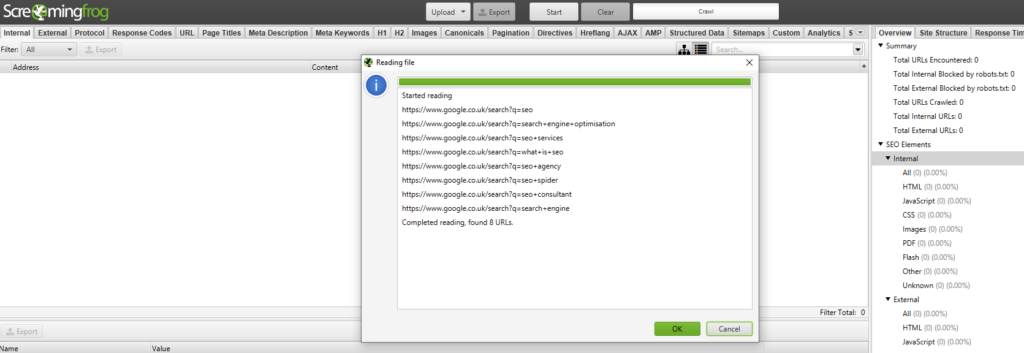
Hit ‘OK’ and your crawl will begin.
7) Analyse your results
To see your extraction you need to navigate to the ‘Custom’ tab in the SEO Spider, and select the ‘Extraction’ filter. Here you should start to see your extraction rolling in. When complete, you should have a nifty looking screen like this –
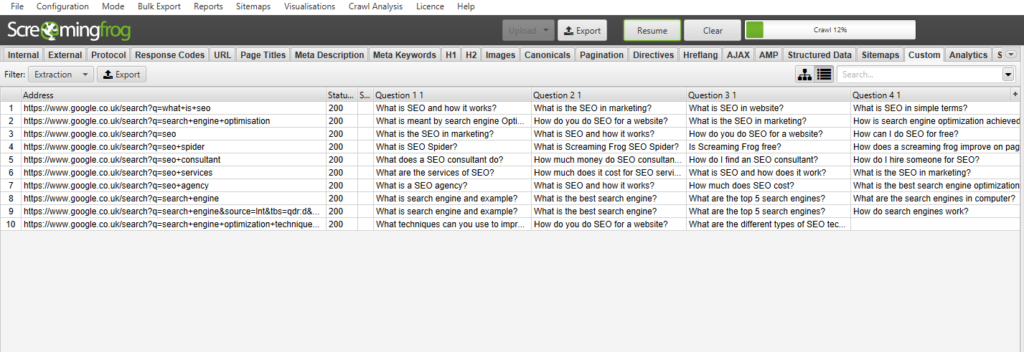
You can see your search query and the four related questions appearing in the SERPs being pulled in alongside it. When complete you can export the data and match up your keywords to your pages, and start to analyse the data and optimise to target the relevant questions.
8) Full list of XPath syntax
As promised, we’ve done a lot of the heavy lifting and have a list of XPath syntax to extract various featured snippet and related question elements from the SERPs –
Featured snippet XPath syntax
(//span[@class='S3Uucc'])[1](//span[@class="e24Kjd"])[1]//ul[@class="i8Z77e"]/li//ol[@class="X5LH0c"]/li//table//tr(//div[@class="xpdopen"]//a/@href)[2](//img[@id="dimg_7"]//@title)Related questions XPath syntax
(//g-accordion-expander//h3)[1](//g-accordion-expander//h3)[2](//g-accordion-expander//h3)[3](//g-accordion-expander//h3)[4]//g-accordion-expander//span[@class="e24Kjd"]//g-accordion-expander//h3//g-accordion-expander//div[@class="r"]//a/@hrefWe’ve also included them in our accompanying Google doc for ease.
Conclusion
Hopefully our guide has been useful and can set you on your way to extract all sorts of useful and relevant data from the search results. Let me know how you get on, and if you have any other nifty XPath tips and tricks, please comment below!






This is an Amazing post Patrick!
Why no mention of Proxies and VPNs? Scraping Google isn’t the best idea if one doesn’t know what he does. I’d at least put a disclaimer to that post.
Also, anything on scraping Google For Jobs?
Thanks!
Thanks Jean-Christophe!
Fair point on scraping Google, though I did cover this in the config section in terms of setting certain crawl limits – it’s nothing that all rank tracking tools do either!
Like the idea of looking at Jobs, I’ll see what I can do…
☝️ @Jean yep the first thing I was thinking too, would be very useful to have a section to expand on this. I haven’t worked extensively with Google SERP scraping, but even doing manual incog spot checks a bit quick can trigger the anti-scraping captcha or the 4XX errors.
In Canada, I crawled Google For Jobs 3-pack (I had to adapt the Xpath becaus google.ca isn’t exactly the same as google.co.uk).
You can extract the job title, the employer and the Website where you’ll find the job. This can help getting some rankings.
For the gjobs title I call the div with the class BjJfJf gsrt cPd5d (sorry SF firewall blocks the code, so I’ll only give the class here). Click on my name to see the post. (sorry for the self promotion, I am just doing this since I can’t put code here.)
To get the gjobs employer, I use the div with the class gyaQGc
For the gjobs website source I call the second div with the class LqUjCc
You can also extract the function value instead of the inner HTML to find out if the Google For Jobs box gets out.
To do this, use the count() function.
And using Xpath call the div that contains the class bkWMgd and that contains a subdiv contains the class BjJfJf gsrt cPd5d
This will give you a 1 if it gets out or a 0 if not.
Awesome, thanks JC! Might have to do a follow-up post at some point for Jobs and other features too :)
Thanks for the article. It was very useful. I tried it the first time. I really like.
Sweet! Glad it worked nicely :)
Is this configuration to crawl more than the first 4 related questions, as once you click on the query it will keep on expanding? I’ve seen some python solutions but perhaps this is out of scope?
Hey John – the config doesn’t crawl more than the standard 4 questions. Do share if you have a python solution, that would be cool to see!
Hey Patrick~ Here’s one I wrote! https://evolving-curiosity.com/using-python-to-scrape-beyond-google-initial-people-also-ask-questions/ ~ Cheers!
Thanks Garrett!
Hey Patrick,
is it possible to export the title and description of a normal search result with that?
I want to monitor whether google uses the title and/or the description which is defined or generates a description from the content.
Cheers,
Jonas
Hey Jonas,
This should do all the page titles –
//div[3]/div/div/div/div/div/a/h3/div
Descriptions can be done individually, but I’m trying to find a solution to grab them all. Here’s for the 1st result anyway –
//div[2]/div/div/div[3]/div/div[1]/div/div/div/div
Let me know if that works!
Cheers,
Patrick
Title
//div[@class=”r”]//h3
URL link
//div[@class=”r”]//a/@href
That’s a great post !
I’ve just extracted all the search queries triggering featured snippets with Ahref, and I needed to know what typology of FS it was.
It helps a lot, thank you =)
Thanks Matthew, much appreciated!
Have you tried any of this on the latest Screaming Frog recently? I followed instructions to the letter and could never reproduce your results.
It’s not working for me either
Hi Eric,
Thanks for your message via support. I just wanted to reply here so others could see as well – Make sure you’re using the latest version of the SEO Spider, when performing the above.
It should then work!
Thanks,
Dan
Sorry, but this is not working. Can you please check this?
Should this also work to get links on SERPs? Any specific advice about doing this? :)
Many thanks,
J.
Pretty sure the Featured snippet XPath syntax for page title (Text) does not work. :/
If you noticed a user in this page’s analytics with some 1,000 sessions and some 1,000 corresponding pageviews, that was me. This tab was open for the past five months and I finally had time to sharpen the saw. Blessings from the USA to you and Dan!
Hey, Patrick!
Great article! Thank you!
I’m not a technical guy, but I need to scrape Facebook pages from 200websites. Can Screaming Frog help me with that? Could you give me more information? I will be thankful!
hey Patrick, I did everything as you showed here, but my screaming frog is returning 302 for all google search URLs. I checked them and they look ok.
if you get a 302 it means you have most likely triggered the captcha, you can check the redirect URL given in the crawl
Hi,
Great article as always. It would be better if there was a video. at least we could see how it’s done on the screen.
Interesting! I realized it’s easier to scrape other tld’s of Google DB. I tried scraping Google.com – but i’m receiving no response as a status. Any tips for scraping Google.com DB?
Just to add, scraping with Regex does work for me but its generating too many results.
Hey guys,
I’m trying to pull the links from the People Also Ask section on the SERPs, but can’t seem to get the formula to work. Can anybody help? :)
Thanks,
Marty
I tried to apply y’all the custom settings suggested here and tried to scrape the first PAA question. I got no results, although the SERP shows several results for People Also Ask.
Same for any kind of XPath I tried from this guide. Is there any missing info?
Hi Patrick,
With the incoming Core Web Vitals & Page Experience algorithm update due in a few months from now. I’m thinking ahead. Would your methodology above work for scraping the ‘fast page badge’ label? (That’s if Google decides to implement the fast page badge).
Info on the fast page label – https://blog.chromium.org/2020/08/highlighting-great-user-experiences-on.html#:~:text=Links%20to%20pages%20that%20have,have%20a%20particularly%20good%20experience.
Thanks,
Chris
This does not work anymore as of August 2021.
I use this Xpath syntax for Google PAA and it’s working, only gives back only the first 3 answers, no matter how I set it:
//div[@class=”iDjcJe IX9Lgd wwB5gf”]
Let me know if anyone finds a better syntax set up.
Found this other Xpath syntax configuration that seems to work for all questions:
//*[@aria-expanded]/div[2]/span
This is great thank you for sharing. Was curious if there was a way to pull the answer portion and not just the question?
I have tried following this guide but am not getting the results. Has the method to extract related questions from the SERP using SF changed since this page was published?
Any help will be much appreciated.
For those who are also stuck, I have figured it out how to get an XPath that works.
For each “People also ask” (PAA) accordion:
1) Load a Google SERP which features the PAA accordions
2) Go into ‘Inspect’ mode (F12)
3) Use the ‘Select Element’ tool
4) Hover over and click the PAA accordion you wish to extract – This will highlight the corresponding html in the inspect window
5) Go up a few levels in the html – as you go up the accordion should still be highlight in blue – go to the highest level before the highlighting disappears – this seems to start with Copy > Copy full XPath
7) Use this in the custom extraction in screaming frog as per this guide