Google Search Console robots.txt Tester Inconsistencies
Liam Sharp
Posted 28 September, 2017 by Liam Sharp in Screaming Frog SEO Spider
Google Search Console robots.txt Tester Inconsistencies
We’ve had a few customers notice that our robots.txt tester tool, in version 8.1 of the SEO Spider, gives different results than the robots.txt tester in Google Search Console .
This variation in behaviour is around the handling of non-ASCII characters, as highlighted below.
Giuseppe Pastore blogged about this issue back in 2016, but we wanted to perform our own tests using case variations and Googlebot itself, not just the robots.txt Tester.
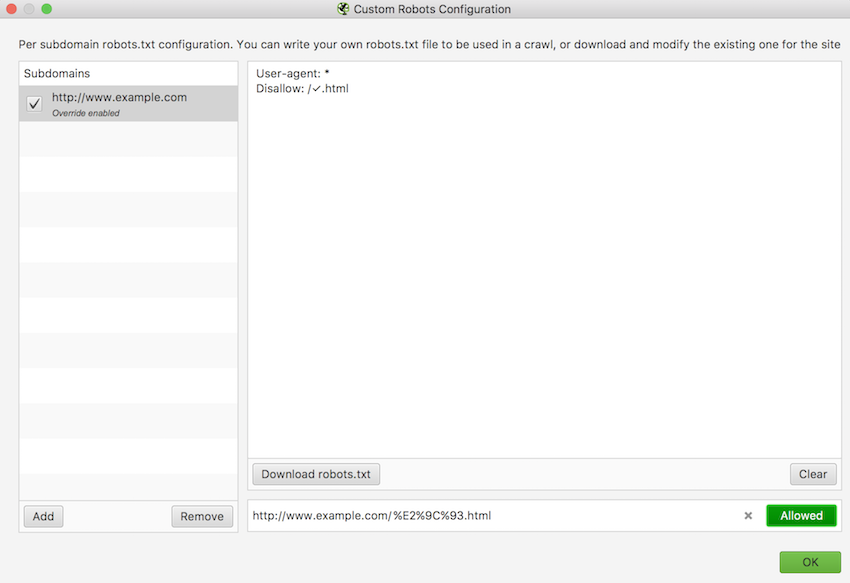
The example URL http://www.example.com/✓.html contains a check mark, which is a non-ASCII character. When an HTTP request is made for this URL it must be percent-encoded as http://www.example.com/%E2%9C%93.html. So if you want to prevent Googlebot from crawling this page on your site, what do you put in your robots.txt file?
The UTF-8 character?
Disallow: /✓.html
Or the percent encoded version?
Disallow: /%E2%9C%93.html
Looking at Google’s robots.txt reference, we see the following:
“Non-7-bit ASCII characters in a path may be included as UTF-8 characters or as percent-encoded UTF-8 encoded characters per RFC 3986.”
Which suggests that both methods should be valid.
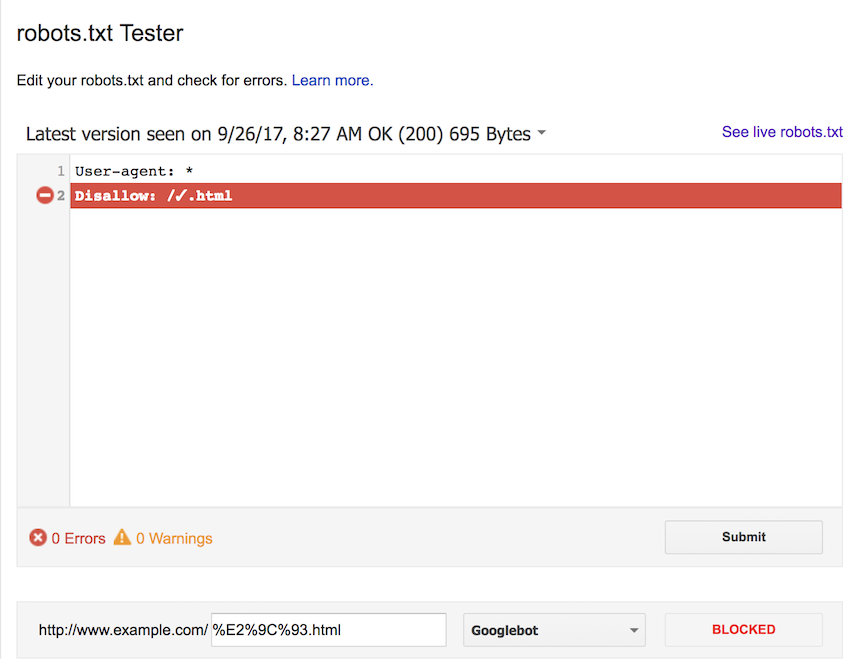
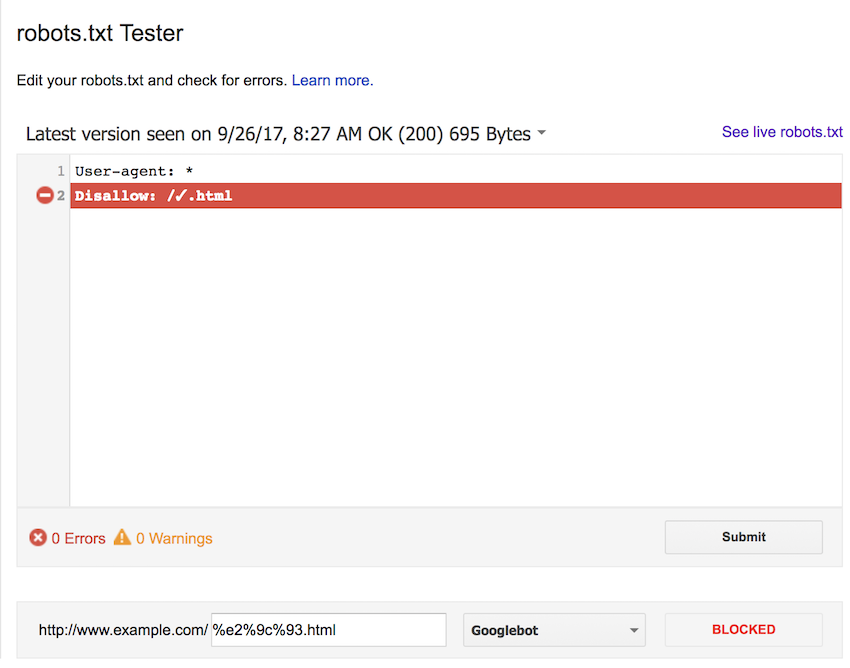
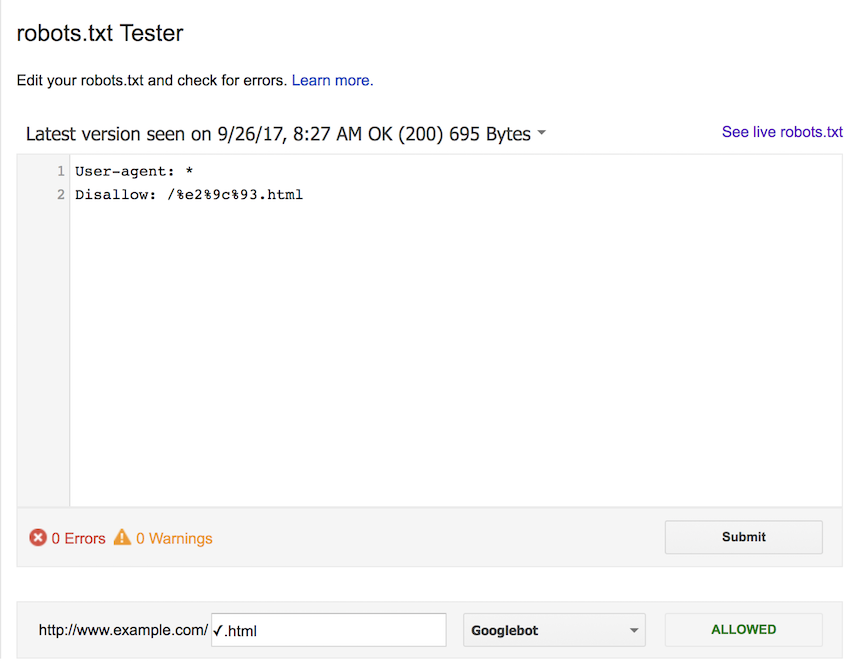
We first tested using the UTF-8 character in the robots.txt file. We checked this against the UTF-8 character, as well as both upper and lowercase percent-encoded versions (%E2%9C%93.html and %e2%9c%93.html).
As you can see in the screenshots below, the results are as expected and the rule blocks all 3 forms of the URL.
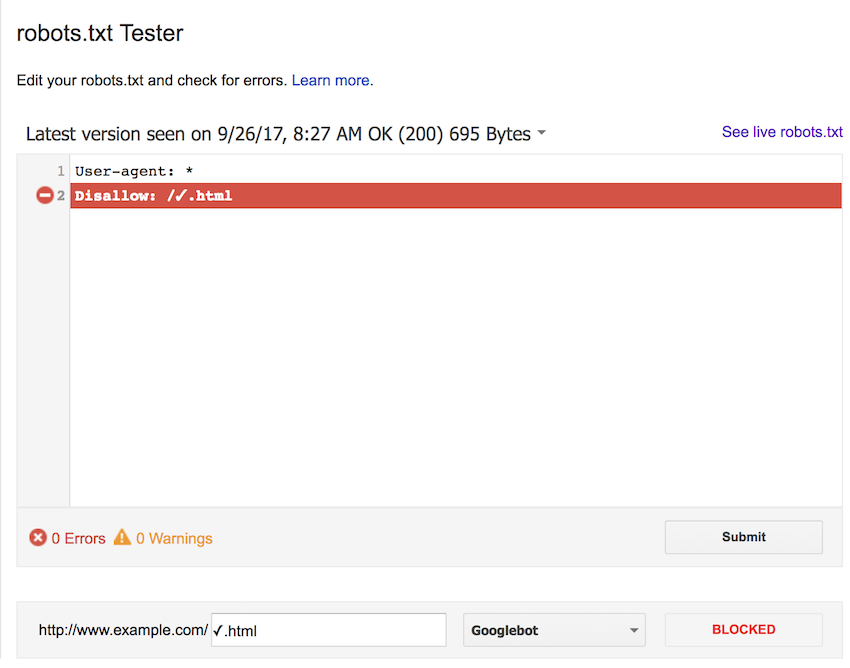
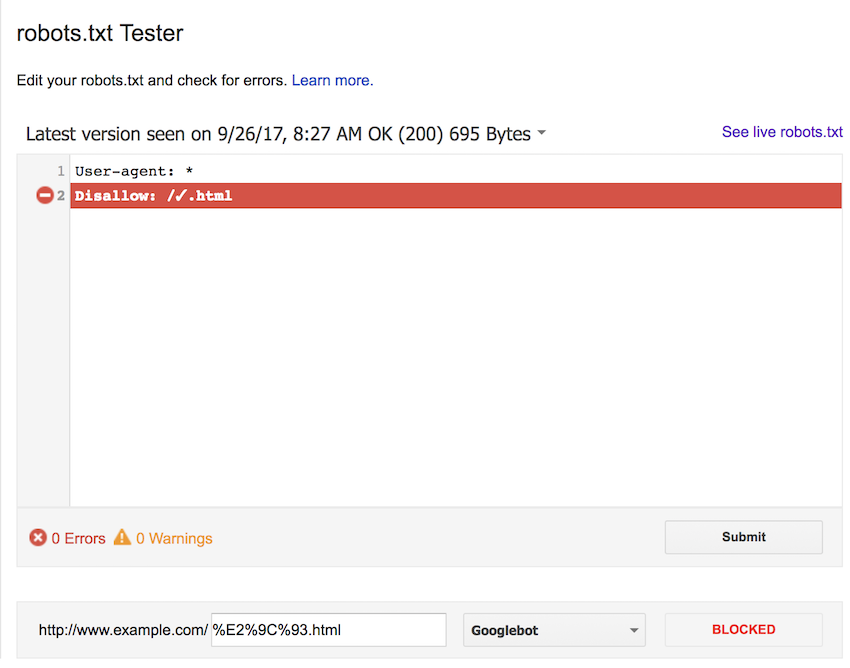
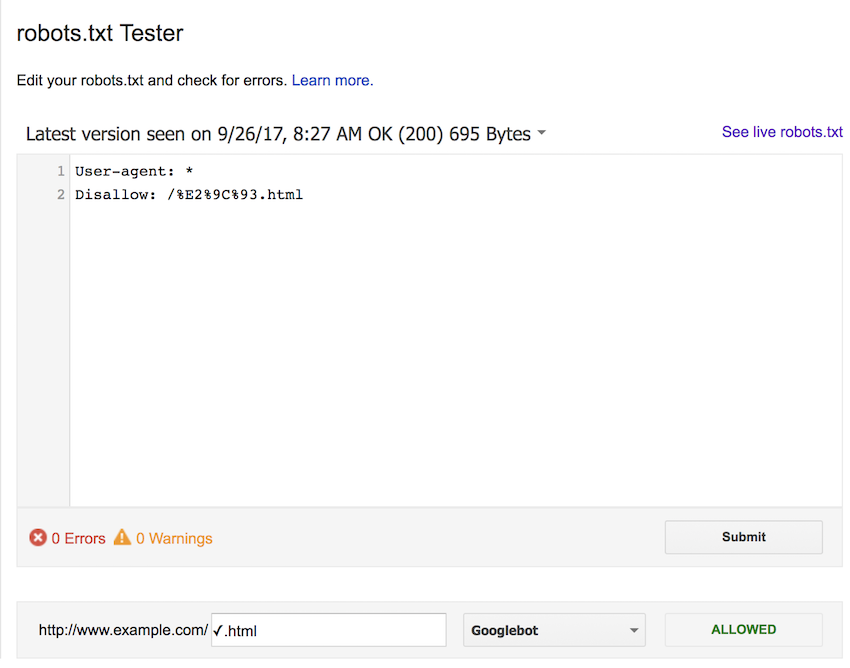
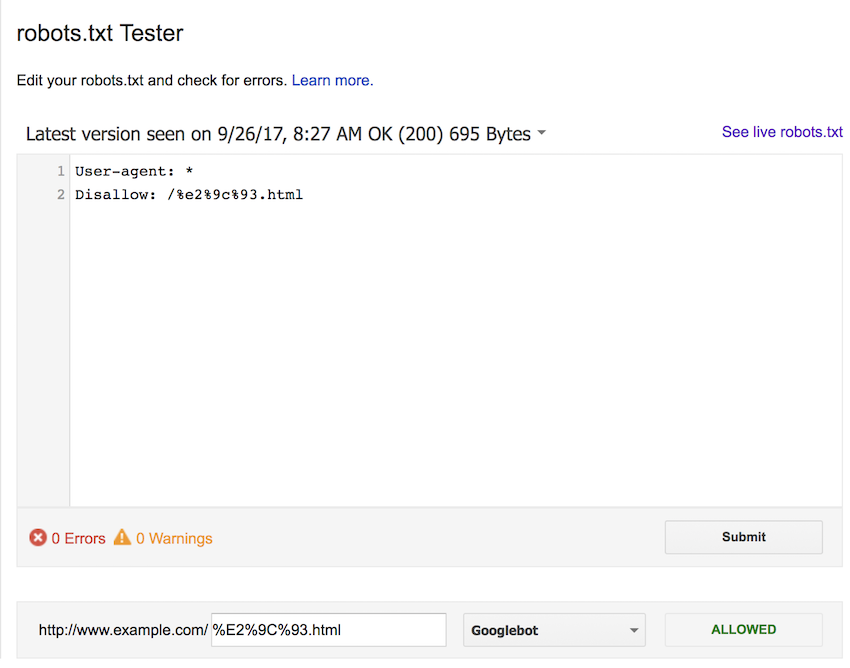
We then updated the rule to block using the uppercase percent-encoded form. The results here are not what we were expecting, the rule does not match in any of the cases.
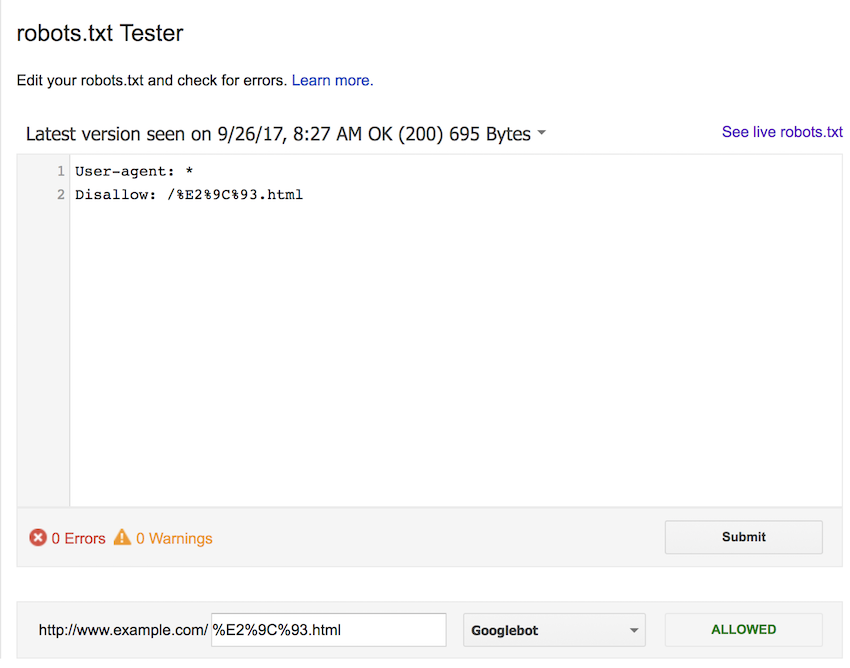
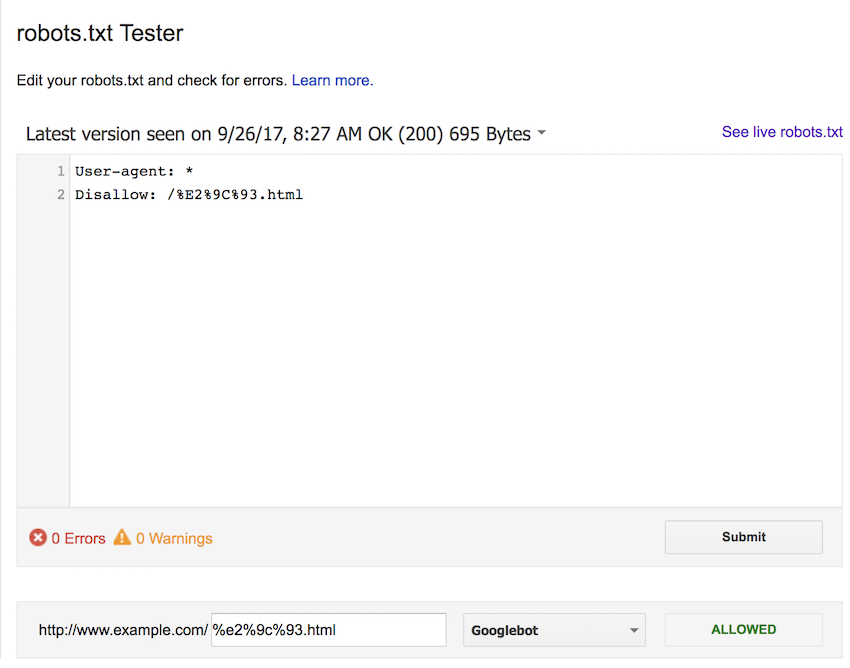
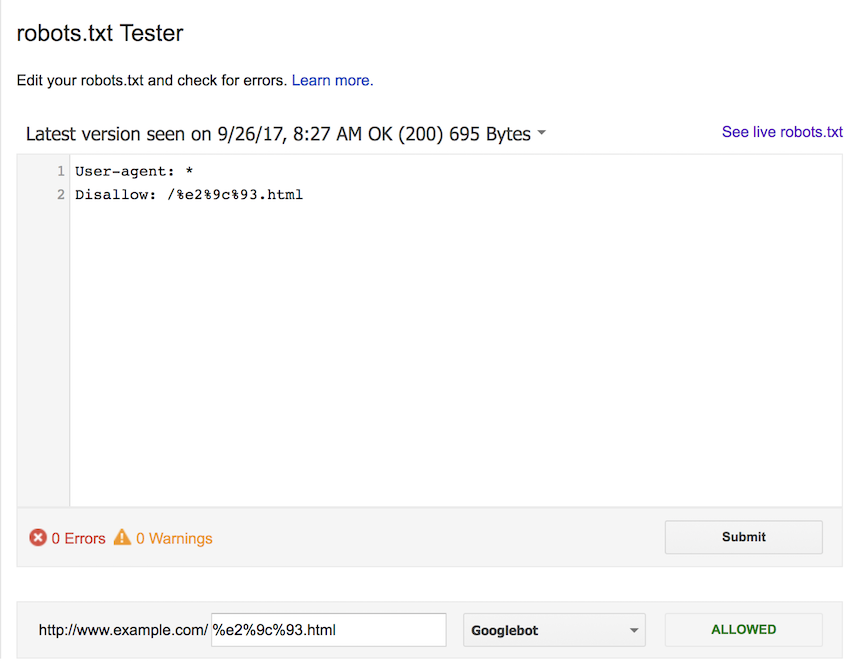
For completeness, we also tested using the lower case percent-encoded version of the URL. Again, we expected this to block each form of the URL, but all were allowed.
These results suggest that we should be using the raw UTF-8 characters in our robots.txt files, and not their percent-encoded equivalents.
Testing Googlebot Itself
The whole point of the robots.txt Tester is to check how Googlebot will interpret your robots.txt file when crawling your site. So we performed another test to see if Googlebot followed the same rules during regular crawling.
We first created the following 3 Disallows in our robots.txt file:
User-agent: *
Disallow: /lower_case_%e2%9c%93_page.php
Disallow: /upper_case_%E2%9C%93_page.php
Disallow: /utf8_✓_page.php
We then created a seed page with a link to each of these pages as well as another page, ‘normal.php’, which is not blocked in any way. Each of the 4 linked-to pages creates an entry in a log file so we know it’s been requested, along with all the details about the request so we can verify it’s actually from Googlebot.
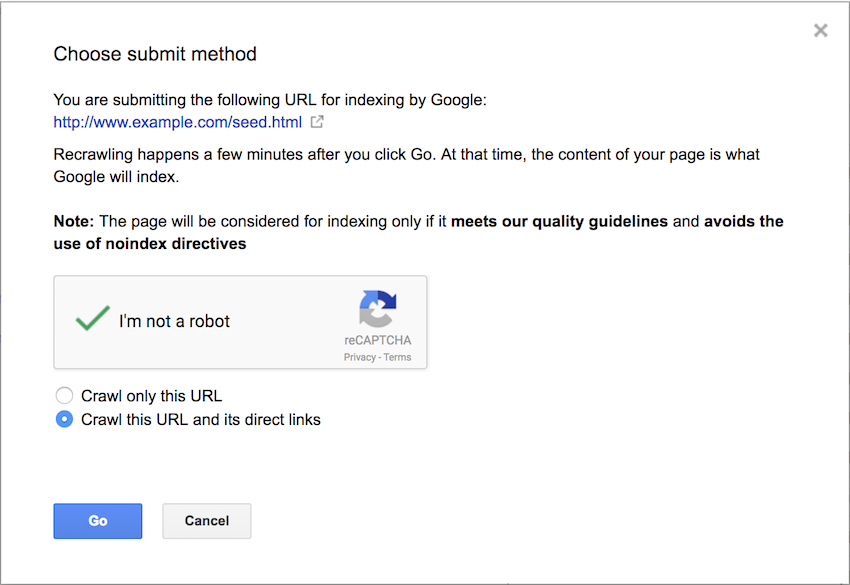
We submitted this seed page, containing the 4 links, to Google using the Fetch as Googlebot tool. We then requested it was indexed and its direct links crawled.
Very quickly we saw a request for the only page not disallowed in any way, normal.php. A week after running these tests we still had no logs of the other 3 pages being requested.
Conclusion
The robots.txt tester tool should not be relied upon, it follows different rules to Googlebot itself – Googlebot accepts the UTF-8, upper and lowercase percent-encoded forms of URLs in a robots.txt file.
The SEO Spider has a couple of issues that will be addressed in a future release. We currently only look at the percent-encoded form of a URL, we also need to use the non-encoded version. The SEO Spider uses a consistent uppercase form of percent-encoding, so we need to make this case insensitive when matching robots.txt rules. With these fixes in place the SEO Spider’s robots.txt tester tool will still produce different results to the GSC robots.txt Tester, but will be in line with our understanding of Googlebot itself.
If you have anymore questions about how to use the Screaming Frog SEO Spider, then please do get in touch with our support team.






What is the use of robots.txt. Please explain me clearly. What will happen if we don’t have robots.txt
Some good docs on this over at the Google Search Console help: https://support.google.com/webmasters/answer/6062608?hl=en
We have checked many times in 8.1 version. No issues found.
I recently tried this out and its great seeing the process explained here
Great explanation, it’s really very helpful.
Hello
I’ve found more inconsistencies:
* URL to blog: /blog/en/page/4
* Rule in robots,txt: Disallow: /blog/*/page/*$
Blocked by Search Console but not blocked in Screaming Frog
Hi Nico,
Thanks for reporting this, we’ll fix it up in a future release of the SEO Spider.
Cheers
Liam
It’s really, very helpful!
Liam the content is really helpful, but I have a query and I’ll be glad if you can answer it.
I have a Laravel website, and in Laravel the URLs are dynamic, so I want to create a sitemap accordingly, But I am confused either I should add images, CSS, javascript URLs or only internal URLs while creating a sitemap through screaming frog?
The website is quite big and has more than 6k URLS.
Hi Omaxe, could you email support@ with this query please? Cheers!
Hi Liam, Is this function available in free version Too? I have a website and want to put selected URLs only.
Thanks in Advance
The robots.txt tester is only available in the free version of the SEO Spider. If you have a list of URLs you want to check specifically, then using List Mode (free for up to 500 URLs) would be a good option, more details here: https://www.screamingfrog.co.uk/how-to-use-list-mode/