SEO Spider
How To Check For Duplicate Content
How To Find Duplicate Content
Duplicate content should be minimised across a website, as it can make it difficult for search engines to decide which version to rank for a query.
While a ‘duplicate content penalty’ is a myth in SEO, very similar content can cause crawling inefficiencies, dilute PageRank, and be a sign of content that could be consolidated, removed or improved.
It’s worth remembering that duplicate and similar content is a natural part of the web, which often isn’t a problem for search engines who will, by design, canonicalise URLs and filter them where appropriate. However, at scale it can be more problematic.
Preventing duplicate content puts you in control over what’s indexed and ranked – rather than leaving it to the search engines. You can limit crawl budget waste and consolidate indexing and link signals to help in ranking.
This tutorial walks you through how you can use the Screaming Frog SEO Spider to find both exact duplicate content, and near-duplicate content where some text matches between pages on a website.
Duplicate content identified by any tool, including the SEO Spider needs to be reviewed in context. Watch our video, or continue to read our guide below.

To get started, download the SEO Spider which is free for crawling up to 500 URLs. The first 2 steps are only available with a licence. If you’re a free user, then skip to number 3 in the guide.
1) Enable ‘Near Duplicates’ Via ‘Config > Content > Duplicates’
By default the SEO Spider will automatically identify exact duplicate pages. However, to identify ‘Near Duplicates’ the configuration must be enabled, which allows it to store the content of each page.
The SEO Spider will identify near duplicates with a 90% similarity match, which can be adjusted to find content with a lower similarity threshold.

The SEO Spider will also only check ‘Indexable’ pages for duplicates (for both exact and near-duplicates).
This means if you have two URLs that are the same, but one is canonicalised to the other (and therefore ‘non-indexable’), this won’t be reported – unless this option is disabled.
If you’re interested in finding crawl budget issues, then untick the ‘Only Check Indexable Pages For Duplicates’ option, as this can help find areas of potential crawl waste.
2) Adjust ‘Content Area’ For Analysis Via ‘Config > Content > Area’
You’re able to configure the content used for near-duplicate analysis. For a new crawl, we recommend using the default set-up and refining it later when the content used in the analysis can be seen, and considered.
The SEO Spider will automatically exclude both the nav and footer elements to focus on main body content. However, not every website is built using these HTML5 elements, so you’re able to refine the content area used for the analysis if required. You can choose to ‘include’ or ‘exclude’ HTML tags, classes and IDs in the analysis.
For example, the Screaming Frog website has a mobile menu outside the nav element, which is included within the content analysis by default. While this isn’t much of an issue, in this case, to help focus on the main body text of the page its class name ‘mobile-menu__dropdown’ can be input into the ‘Exclude Classes’ box.

This will exclude the menu from being included in the duplicate content analysis algorithm. More on this later.
3) Crawl The Website
Open up the SEO Spider, type or copy in the website you wish to crawl in the ‘Enter URL to spider’ box and hit ‘Start’.

Wait until the crawl finishes and reaches 100%, but you can also view some details in real-time.
4) View Duplicates In The ‘Content’ Tab
The Content tab has 2 filters related to duplicate content, ‘exact duplicates’ and ‘near duplicates’.

Only ‘exact duplicates’ is available to view in real-time during a crawl. ‘Near Duplicates’ require calculation at the end of the crawl via post ‘Crawl Analysis‘ for it to be populated with data.
The right hand ‘overview’ pane, displays a ‘(Crawl Analysis Required)’ message against filters that require post crawl analysis to be populated with data.

5) Click ‘Crawl Analysis > Start’ To Populate ‘Near Duplicates’ Filter
To populate the ‘Near Duplicates’ filter, the ‘Closest Similarity Match’ and ‘No. Near Duplicates’ columns, you just need to click a button at the end of the crawl.

However, if you have configured ‘Crawl Analysis’ previously, you may wish to double-check, under ‘Crawl Analysis > Configure’ that ‘Near Duplicates’ is ticked.
You can also untick other items that also require post crawl analysis to make this step quicker.

When crawl analysis has completed the ‘analysis’ progress bar will be at 100% and the filters will no longer have the ‘(Crawl Analysis Required)’ message.

You can now view the populated near-duplicate filter and columns.
6) View ‘Content’ Tab & ‘Exact’ & ‘Near’ Duplicates Filters
After performing post crawl analysis, the ‘Near Duplicates’ filter, the ‘Closest Similarity Match’ and ‘No. Near Duplicates’ columns will be populated. Only URLs with content over the selected similarity threshold will contain data, the others will remain blank. In this case, the Screaming Frog website has just two.

A crawl of a larger website, such as the BBC will reveal many more.

You’re able to filter by the following –
- Exact Duplicates – This filter will show pages that are identical to each other using the MD5 algorithm which calculates a ‘hash’ value for each page and can be seen in the ‘hash’ column. This check is performed against the full HTML of the page. It will show all pages with matching hash values that are exactly the same. Exact duplicate pages can lead to the splitting of PageRank signals and unpredictability in ranking. There should only be a single canonical version of a URL that exists and is linked to internally. Other versions should not be linked to, and they should be 301 redirected to the canonical version.
- Near Duplicates – This filter will show similar pages based upon the configured similarity threshold using the minhash algorithm. The threshold can be adjusted under ‘Config > Spider > Content’ and is set at 90% by default. The ‘Closest Similarity Match’ column displays the highest percentage of similarity to another page. The ‘No. Near Duplicates’ column displays the number of pages that are similar to the page based upon the similarity threshold. The algorithm is run against text on the page, rather than the full HTML like exact duplicates. The content used for this analysis can be configured under ‘Config > Content > Area’. Pages can have a 100% similarity, but only be a ‘near duplicate’ rather than exact duplicate. This is because exact duplicates are excluded as near duplicates, to avoid them being flagged twice. Similarity scores are also rounded, so 99.5% or higher will be displayed as 100%.
Near duplicate pages should be manually reviewed as there are many legitimate reasons for some pages to be very similar in content, such as variations of products that have search volume around their specific attribute.
However, URLs flagged as near-duplicates should be reviewed to consider whether they should exist as separate pages due to their unique value for the user, or if they should be removed, consolidated or improved to make the content more in-depth and unique.
Tip! Alongside identifying exact and near duplicates, the SEO Spider is able to identify semantically similar pages and potentially off-topic, low relevance content.
This functionality goes beyond matching text by utilising LLM embeddings that understand the underlying concepts and meaning of words. Read our tutorial on How to Identify Semantically Similar Pages & Outliers.
7) View Duplicate URLs Via The ‘Duplicate Details’ Tab
For ‘exact duplicates’, it’s easier to just view them in the top window by using the filter – as they are grouped together and share the same ‘hash’ value.

In the above screenshot, each URL has a corresponding exact duplicate due to a trailing slash and non-trailing slash version.
For ‘near duplicates’, click the ‘Duplicate Details’ tab at the bottom which populates the lower window pane with the ‘near duplicate address’ and similarity of each near-duplicate URL discovered.
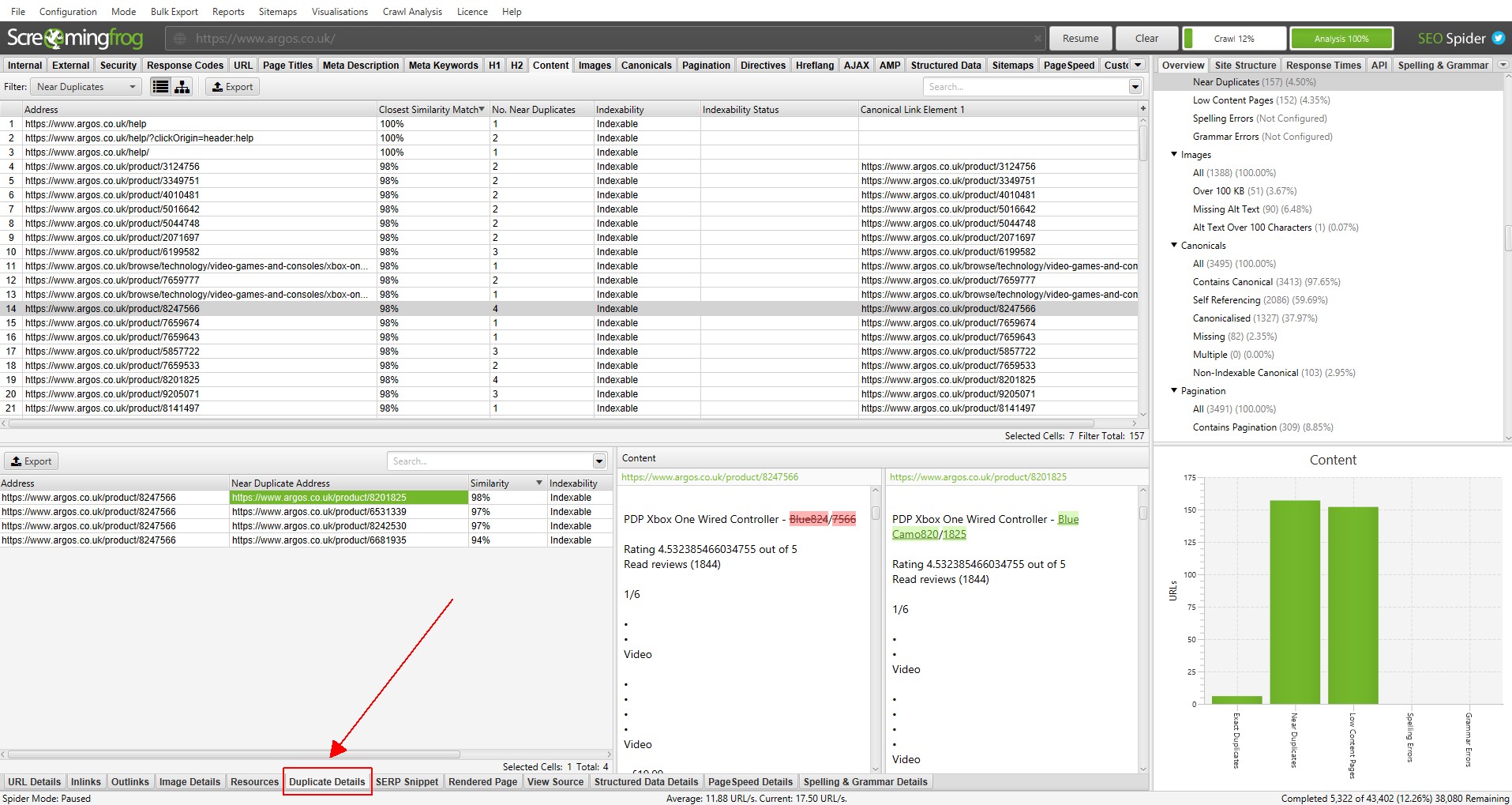
For example, if there are 4 near-duplicates discovered for a URL in the top window, these can all be viewed.

The right-hand side of the ‘Duplicate Details’ tab will display the near duplicate content discovered from the pages and highlight the differences between the pages when you click on each ‘near duplicate address’.

If there is any duplicate content in the duplicate details tab that you don’t wish to be part of the duplicate content analysis, exclude or include any HTML elements, classes or IDs (as highlighted in point 2), & re-run crawl analysis.
8) Bulk Export Duplicates
Both exact and near-duplicates can be exported in bulk via the ‘Bulk Export > Content > Exact Duplicates’ and ‘Near Duplicates’ exports.

Final Tip! Refine Similarity Threshold & Content Area, & Re-run Crawl Analysis
Post-crawl you are able to adjust both the near duplicate similarity threshold, and content area used for near-duplicate analysis.
You can then re-run crawl analysis again to find more or less similar content – without re-crawling the website.

As outlined earlier, the Screaming Frog website has a mobile menu outside the nav element, which is included within the content analysis by default. The mobile menu can be seen in the content preview of the ‘duplicate details’ tab.

By excluding the ‘mobile-menu__dropdown’ in the ‘Exclude Classes’ box under ‘Config > Content > Area’, the mobile menu is removed from the content preview and near-duplicate analysis.

This can really help when fine-tuning the identification of near-duplicate content to main content areas, without the need to re-crawl.
Summary
The guide above should illustrate how to use the SEO Spider as a duplicate content checker for your website. For the most accurate results, refine the content area for analysis and adjust the threshold for different groups of pages.
Please also read our Screaming Frog SEO Spider FAQs and full user guide for more information on the tool.
If you have any further queries, feedback or suggestions to improve the duplicate content tool in the SEO Spider then just get in touch via support.




