Advanced Screaming Frog Crawling Tips and Use Cases for Ecommerce Auditing
Maria Camanes
Posted 8 April, 2024 by Maria Camanes in Screaming Frog SEO Spider
Advanced Screaming Frog Crawling Tips and Use Cases for Ecommerce Auditing
Auditing ecommerce websites with seemingly infinite pages can be a real challenge. Luckily, the Screaming Frog SEO Spider tool can be a powerful ally for SEO professionals seeking to dig into all the nitty-gritty details of their websites. However, if you really want to make the most of this tool, you must go beyond the basics and explore more advanced techniques.
There’s already a great guide on how to crawl large sites with the spider which covers things such as memory vs database storage modes and memory allocation in great detail, so I won’t include any of these today.
In this article, we will delve into other advanced Screaming Frog crawling tips and explore how they can be applied specifically to ecommerce websites, unlocking new avenues for auditing this type of sites at scale.
This article is a guest contribution from Maria Camanes, Associate Director – Technical SEO at Builtvisible.
Limit Your Crawl
Eliminate Certain Types of URLs in Your Crawl
One of the first things you can do is limit your crawl to include only certain types of URLs. For example, if you are auditing only category pages on your site, you could exclude all the product pages, which usually would take up a lot of your crawl memory.
If all your products were placed within a /p/ folder, you could add this regex to the Screaming Frog ‘exclude’ feature to exclude these from the crawl:
https://www.example.com/p/*.

Similarly, if you just want to audit the commercial pages of your store, therefore excluding editorial content, you can do that with a regex similar to this:
https://www.example.com/blog/*.
Conducting a crawl without excluding your product attributes such as size, colour, brand, and so on, may lead to a crawl containing millions of URLs. To avoid this, you can eliminate all of the URL parameters. Whilst you could do this with the ‘exclude’ feature as shown above, if you want to exclude all parameters, there is a much better way to do that by clicking the ‘remove all’ checkbox under Configuration > URL Rewriting:


You can of course use regex to manually exclude certain parameters as well, or you can limit the number of query strings under Configuration > Spider > Limit Number of Query Strings.
These are just some examples, the combinations are endless; they will change from site to site and depending on what you are looking to include ion your audit.
Separate Your Site by Sections
Similarly, you could crawl your site in parts by only including URLs within a specific path. For example, you could run separate crawls for the /women/, /men/ and /kids/ categories of your online store by using the ‘include’ feature. The regex could look like this:
https://www.example.com/women/*
https://www.example.com/men/*
https://www.example.com/kids/*
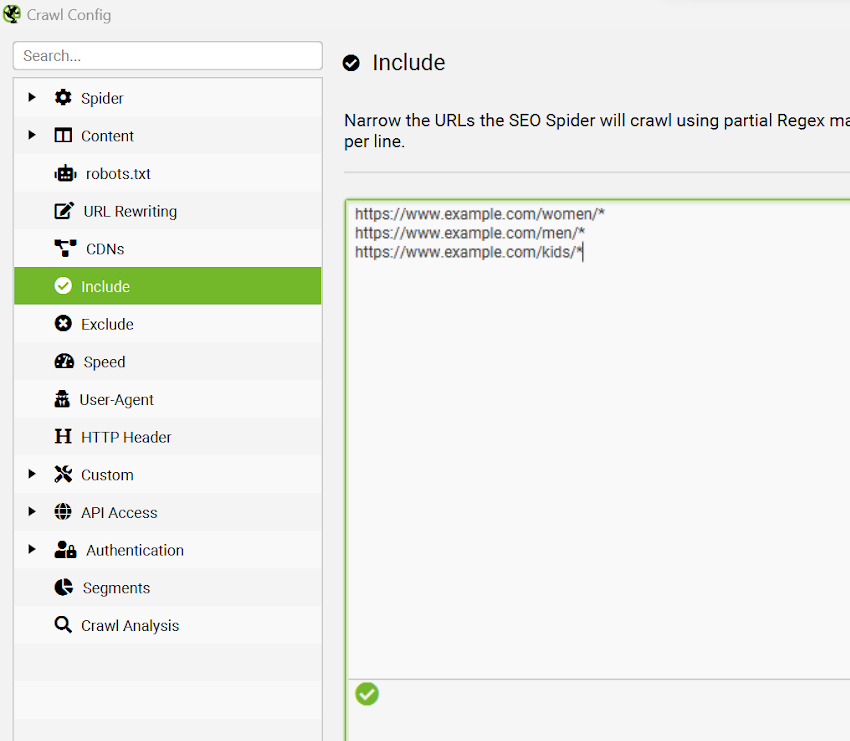
Besides department, you could also break down your site by categories too (e.g. /clothing/, /swimwear/, /accessories/ etc.).
Segment Your Crawl
Segments in Screaming Frog enable you to classify URLs on your site to recognise and oversee issues and opportunities associated with various templates, page types, or site sections more effectively. This can be particularly useful when auditing ecommerce websites, due to their typically large size.
In every tab, you will see a column labelled ‘Segments’ that displays coloured labels for each URL along with their respective segment. This data will also be included in any exports:
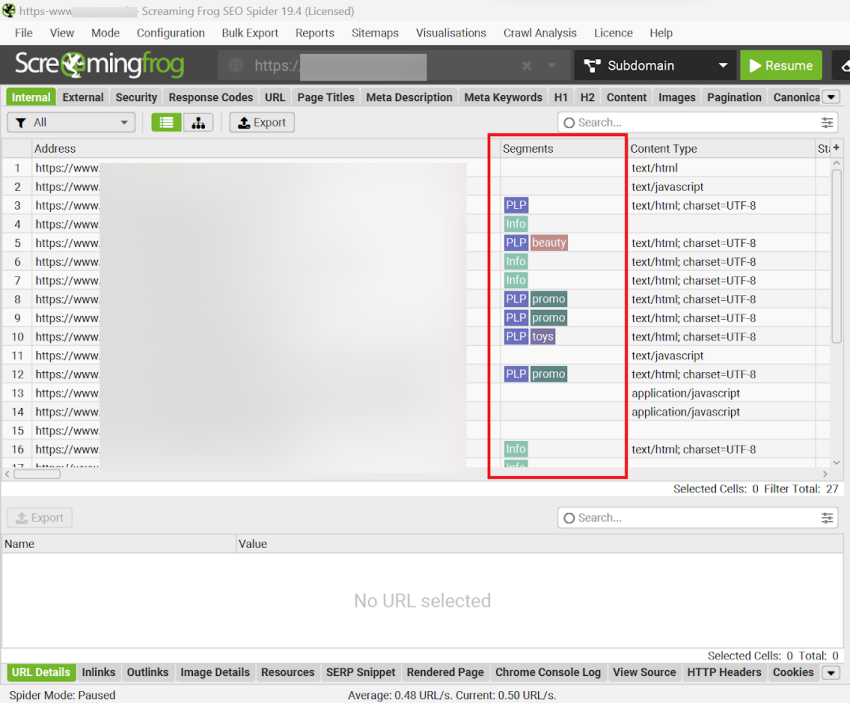
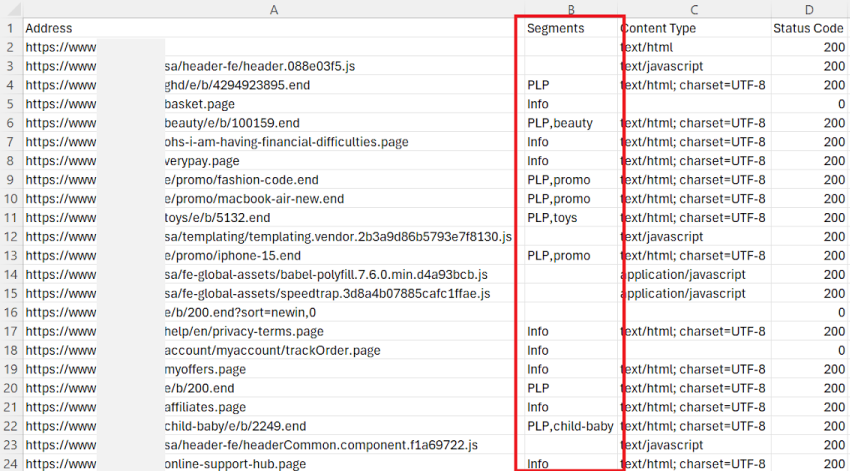
The ‘Issues’ tab on the right-hand side will also feature a segments bar, which allows you to easily identify the segments affected by each issue at a glance.
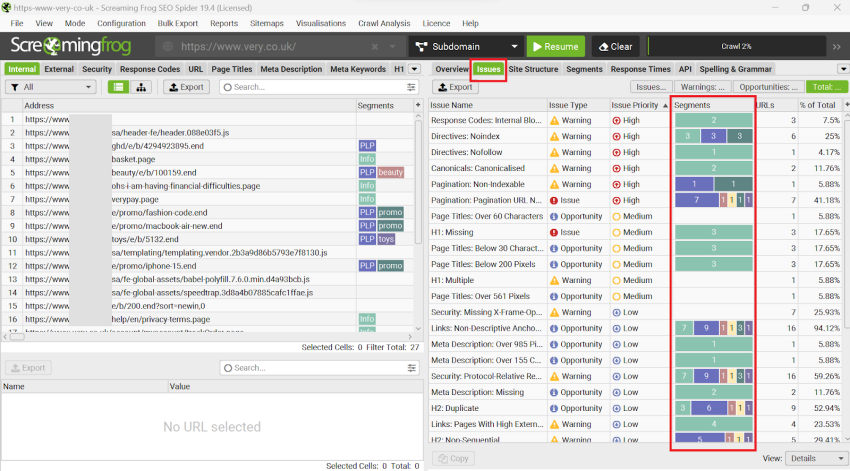
One of my favourite things you can do is auditing the site’s crawl depth by page type (segments). You can use the Segments tab ‘view’ filter to do this:
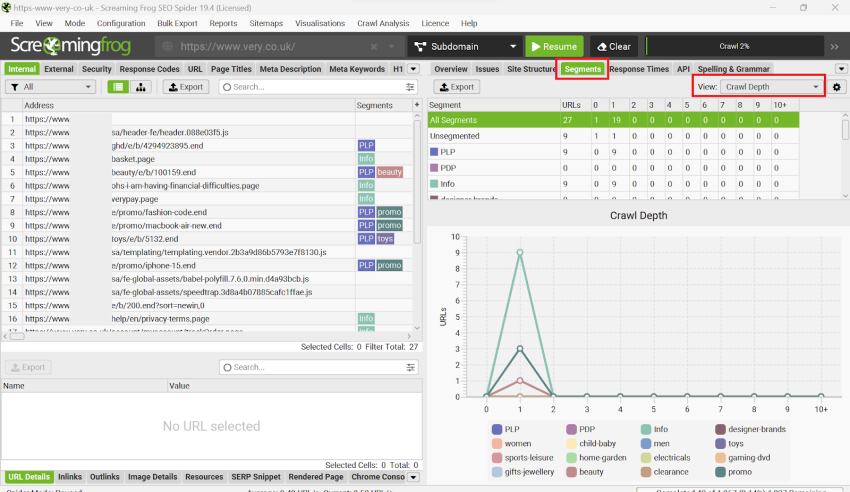
To find out how to set up segments on your crawls you can look at this video or read Screaming Frog’s configuration guide (see ‘Segments’ section) for more details.
Audit Your Site’s Current Retirement Strategy
There are multiple issues that can arise from a missing or wrongly implemented product retirement strategy, all of which will have a negative impact on the organic performance of your ecommerce store. Some of these are:
- Large quantities of 4xx caused by discontinued or temporarily available products
- High amount of broken links as a result of those 4xx, causing large amounts of link equity loss
- Empty or thin category pages with limited stock causing thin content issues
Besides their negative impact in rankings, all of these will also result in bad a user experience and have a negative impact on conversions, resulting in lost sales (for all channels!).
For those reasons, one of the things I do when auditing an ecommerce site is analysing whether they have an effective product retirement strategy in place. There are multiple ways in which you can use Screaming Frog to do this.
Find out of Stock Products With ‘Custom Extraction’
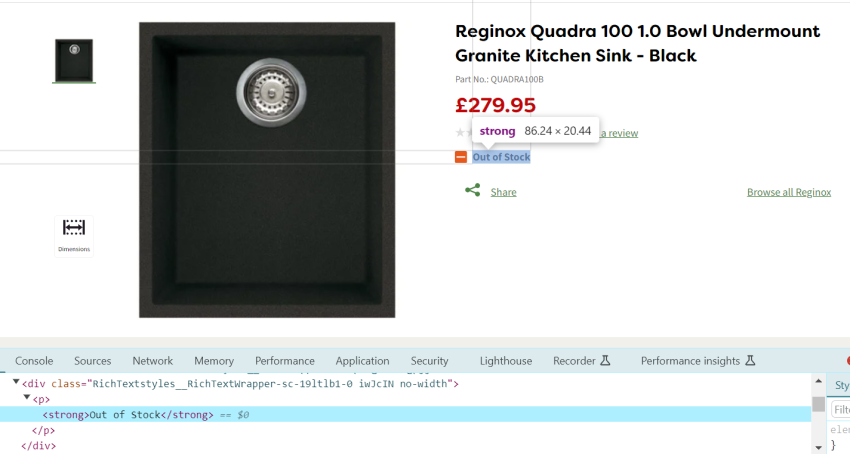
Products that are out of stock and return a 200 status code will be challenging to identify on a large scale; as they don’t return a 4xx status code, they won’t be detected through a regular crawl, so you’ll need to use Screaming Frog’s ‘Custom extraction’ feature.
Simply locate the ‘Out of stock’ identifier in the HTML of your product page template and paste it in the crawlers’ ‘Custom extraction’ function. This could typically be something like ‘Out of stock’ or ‘Currently unavailable’.
Here is an example, using this URL.
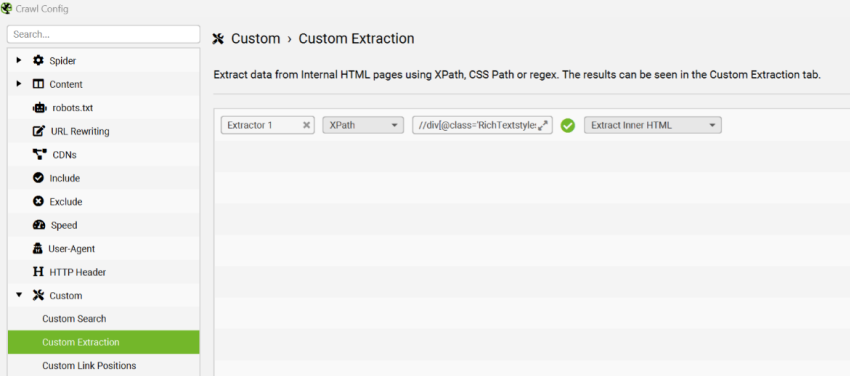
You can use the tool to fetch the contents of the stock status container by typing the below on the ‘custom extraction’ tool:
//div[@class='RichTextstyles__RichTextWrapper-sc-19ltlb1-0 iwJcIN no-width']
If you prefer, you can instead use the ‘Custom search’ feature to find URLs that contain the specified ‘out of stock’ string. I explain the process in more detail in this article.
Find Thin Product Listing Pages With Limited or No Stock
One of my favourite uses for this tool is pulling out the number of products across all category and subcategory pages of the site. This information can be used to decide which pages to eliminate or combine on your ecommerce site. For instance, if you have several category pages with fewer than a given number of products, and you’re competing with competitor pages that have hundreds of items listed, it’s unlikely that you’ll be able to outrank them. Furthermore, these pages can be considered thin content by search engines, which could potentially lead to algorithmic penalties for the site. In such situations, it might be best to either consolidate the page into its parent category, mark it as ‘noindex’ or combine small subcategories together.
You can utilise two methods to locate category pages with limited or no stock across your website.
Custom Extraction
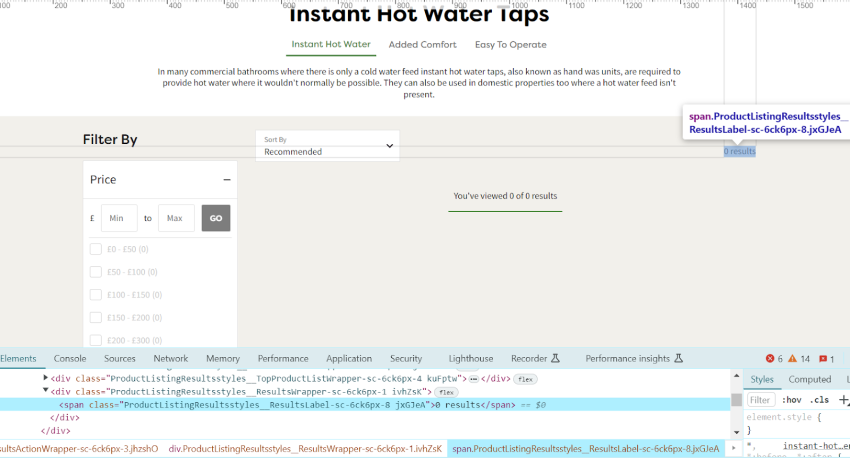
Using the custom extraction feature and taking this URL as an example, you’d type the below on the tool to fetch the contents of the ‘product count’ container:
//span[@class='ProductListingResultsstyles__ResultsLabel-sc-6ck6px-8 jxGJeA']
If you don’t want to crawl the whole site, remember that you can combine this feature with the ‘exclude’ and ‘include’ features explained earlier in this article to limit your crawl to category pages only.
When the crawl finishes, go to the ‘Custom’ tab at the top of the tool and you’ll see something like this:
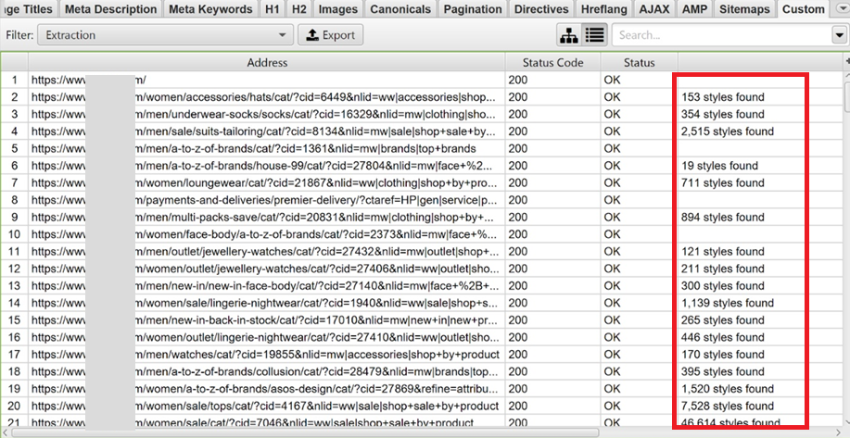
If your page doesn’t have a container with the number of products available, you can still count the number of elements (product cards) on a page:
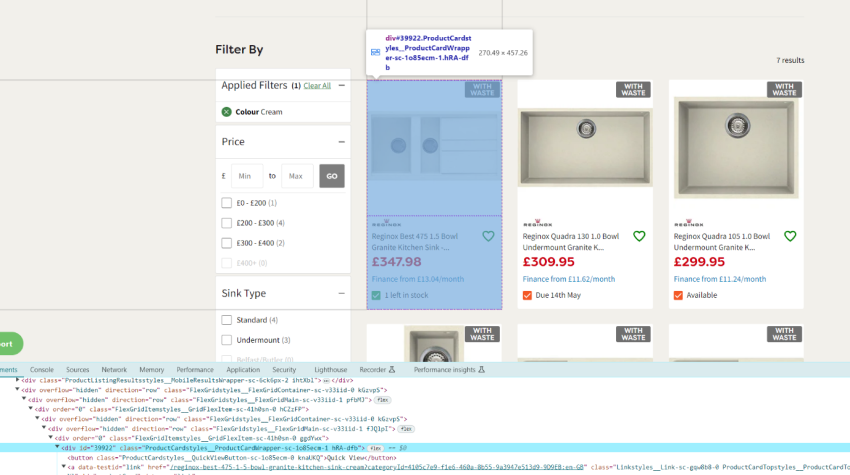
In some cases, when using this feature to pull out data from a website, the custom extraction data may be missing; if this happens, it’s quite likely that the product cards are not on the raw HTML of the site but handled using JavaScript, which is quite common to see. If this is the case, you’ll need to crawl in JavaScript rendering mode.
Custom Search
To do this with the ‘Custom search’ feature instead, you need to find the ‘no products’ identifier on your page template and paste it into the Screaming Frog’s feature, using the same approach explained above for finding discontinued products.
Using the above PLP as an example that would be ‘0 results’.
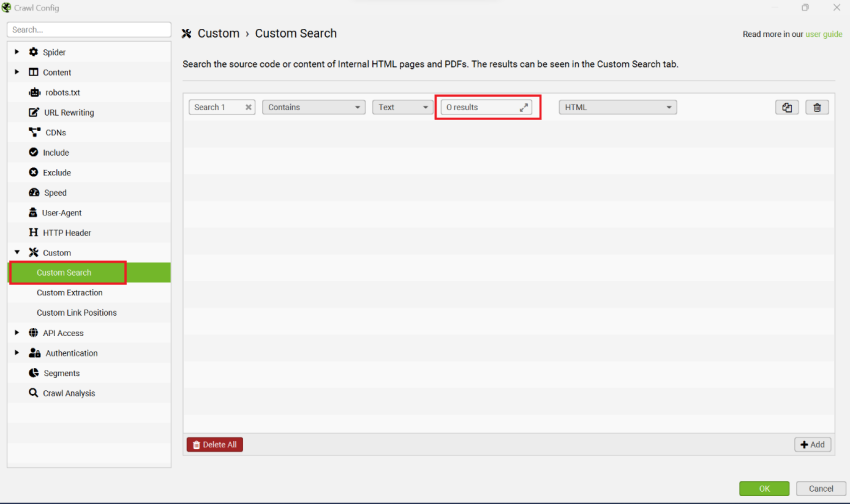
Bear in mind that this function is case sensitive.
Use the ‘Custom Extraction’ Tool to Extract Content Snippets
Besides the product count, there are many other elements of a page you can extract with this feature. For ecommerce sites in particular, one of the most common use cases would be extracting the content snippets of your category and subcategory pages so that you can find short snippets that might need to be optimised.
Taking this ASOS category page as an example, you’d be typing this on the ‘Custom extraction’ tool:
//*[contains(@class, "container_gW2ai")]
To fetch the contents of the snippet container.
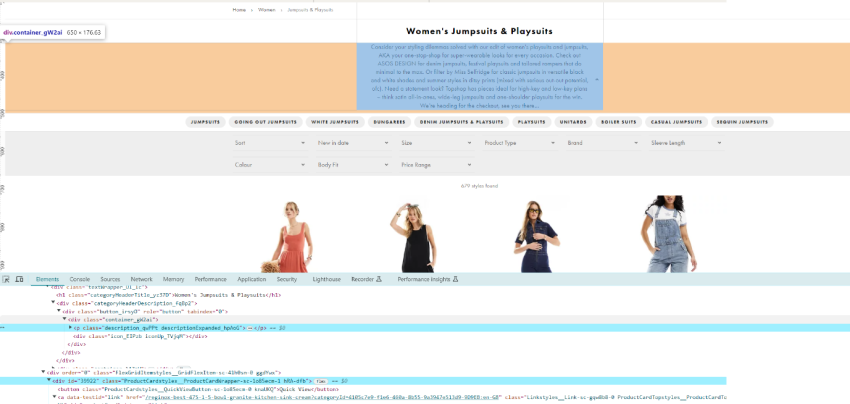
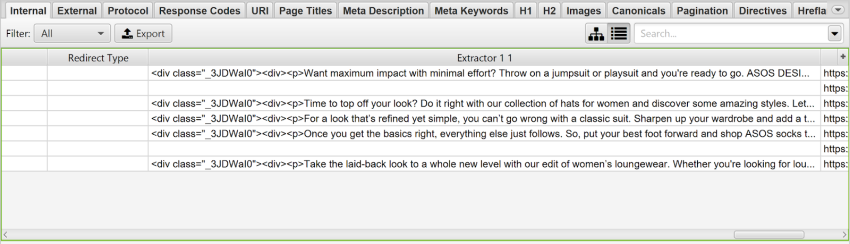
Then, when the crawl finishes and you export your results to Excel, you can remove any unnecessary code on the ‘Extractor’ cells with ‘find and replace’ and add this formula for word count:
=LEN(B3)-LEN(SUBSTITUTE(B3," ",""))+1
Find Products With No Reviews
There are plenty of other things you can do with this feature. For example, you could also pull out the number of reviews, to find products with a low number or no reviews. This can be useful when auditing your conversion rates across all product pages on your site. Adding this datapoint will allow you to identify products with low conversion rates which might benefit from having more customer reviews or a better rating.
This form of user-generated content (UGC) can be highly effective in addressing content uniqueness and freshness issues on a large scale. Additionally, reviews are a source of relevant content for your product pages, which will improve their keyword targeting and contribute to higher rankings for long-tail keywords. Finally, reviews can motivate visitors to complete a purchase – thereby boosting your conversion rates and revenue – and are seen as an endorsement of trust by Google.
Other Common Xpath Uses for Ecommerce Auditing
Before finishing, I wanted to share a list of useful page elements you can extract with XPath to then use in Screaming Frog’s ‘Custom extraction’ feature for ecommerce SEO auditing. These are:
- Extracting the price of every single product page on your website
- Finding product pages with offers or discounted price
- Getting all product descriptions across your site (to then get the word count with the ‘LEN’ formula in Excel).
- Extracting all links in a document (e.g. all products within a category page)
- Pulling out Structured data of all of your products, such as
- Average star rating
- Product image
- Product name
- Product ID
- Stock status
- Find pages with missing UA codes
The SEO Spider’s Visual Custom Extraction makes it very easy to put together Xpath or CSS path for different sites.
You can do all of this to scrape your competitors’ sites too when doing competitor analysis or to, for example, compare competitor prices to your own.
Final Thoughts
The Screaming Frog SEO Spider can be a powerful ally if you are trying to audit a big online store. Limiting your crawls to specific types of URLs, segmenting them to classify web pages or using the spider’s custom extraction feature to scrape data from your URLs will help you delve deep into the intricate specifics of your online shop, and quickly find low quality content (at scale!) negatively impacting your site’s organic performance.






Hi Maria,
thanks for this post. I use Screamingfrog every day. I love it!
Whoa, Maria, I appreciate you providing these very advanced Screaming Frog SEO Spider tactics! I’m new to SEO, so your post was really helpful in helping me figure out how to get the most out of this tool, particularly for auditing e-commerce websites.
It seems like a good idea to restrict the crawl to particular kinds of URLs so that you may concentrate on the important stuff, such as commercial or category pages, without being overtaken by unimportant information. To handle the site in more manageable chunks, it also makes a lot of sense to partition the crawl by sections or categories.
The custom extraction capability for locating out-of-stock items and thin content pages really piques my interest. It’s wonderful to know that even though some information might not be easily found in the HTML,