Is Bing Really Rendering & Indexing JavaScript?
Dan Sharp
Is Bing Really Rendering & Indexing JavaScript?
Historically all search engines were fairly blind to content created dynamically using JavaScript and would only crawl and index content within the initial HTML response.
But times have changed, and Google, in particular, renders web pages like a browser, processing JavaScript and enabling it to crawl and index content and links in the rendered HTML.
However, indexing of JavaScript is not nearly that simple. There’s a two-phase indexing process which makes it slower and less reliable, there’s more fragility due to the nature of JavaScript errors and resources required for rendering, and plenty of other nuances which make relying on a completely client-side JavaScript set-up keep you up at night, wondering if you’ll actually still be ranking tomorrow.
While Google deprecated the old AJAX crawling scheme, they have always recommended progressive enhancement and recently updated their recommendations at Google I/O to include dynamic rendering where server-side rendered content is shown to bots, rather than attempting a complete client-side approach.
Their tune has changed a little, due to the resource required and complications encountered indexing JavaScript content reliably at scale across the web.
But What About Bing?
Everyone forgets about Bing, which is fair enough. Bing also powers the Yahoo search results and their market share in early 2018 was around 14% in the UK, but a more significant 24% in the US (according to recent Statista data).
Over the years, we’d never really seen any evidence that Bing were able to actually process and index JavaScript. In Bing’s own Webmaster guidelines they still say –
“The technology used on your website can sometimes prevent Bingbot from being able to find your content. Rich media (Flash, JavaScript, etc.) can lead to Bing not being able to crawl through navigation, or not see content embedded in a webpage. To avoid any issue, you should consider implementing a down-level experience which includes the same content elements and links as your rich version does. This will allow anyone (Bingbot) without rich media enabled to see and interact with your website.”
Although in November 2014 when they introduced new mobile search bots, Lee Xiong from the ‘Bing Crawl Team’ discussed their advances in rendering –
“In all of these examples, the user agent strings containing “BingPreview” refer to crawlers that are capable of “rendering” the page, just like a user’s browser would. It is therefore paramount that you allow our crawlers to not only find the core content of the URLs themselves, but that you also allow them access to the necessary resources needed to load each page, that is, including any CSS, script, and image files.”
However, a series of JavaScript indexing tests last year by Bartosz Góralewicz showed that Bing were virtually JavaScript blind.

If you run some searches (alongside a site: query) in Bing for Bartosz’s JS test site, you can see that Bing is still not indexing any of the content today.
But Bing Said It Processes JavaScript
Last year at Pubcon Vegas (in November 2017), Fabrice Canel a Principal Program Manager at Bing (who is responsible for web crawling and indexing of the search engine) confirmed that Bing processes JavaScript.
As usual with anything Bing related, there was barely any discussion or coverage.
Internally we brushed this off at the time as the only evidence we had ever seen, was them making a complete mess of it when a client tested a client-side approach last year for an SPA, before moving to server-side rendering.
If you check the indexability of a well-known SPA, such as the official Angular.io website (https://angular.io/) in Bing, you’ll see problematic indexing issues (as highlighted previously by Tomek Rudzki in Onely’s excellent guide on JavaScript SEO).
The homepage doesn’t contain any real content in its initial HTML delivery and loads the page content via JavaScript. A site: query pulls back the homepage in 9th (which often sets alarm bells ringing), while an ‘angular.io’ search query highlights the lack of content in the snippet displayed, as well as ‘This website requires JavaScript’ twice.

If you search for content on the page which is loaded via JavaScript, Bing also doesn’t return any results, suggesting it simply hasn’t been seen and, or indexed.

So, where is the evidence of JavaScript indexing?
Show Me The Money
All research and tests we have seen internally to date seem to have concurred with the above, that Bing simply doesn’t process JavaScript. However, as we know with Google, they only render when they believe it’s necessary and have the resource, so perhaps Bing is similar and unsurprisingly, less advanced and consistent.
Over the past few months, we have started to see some real-world examples which may indicate that Bing is now starting to render and index JavaScript more regularly. Under some circumstances, for some websites, sometimes. Possibly. Let’s take a look.
A website we have been aware of and have been monitoring that relies purely on client-side rendering with React is Prose (https://prosehair.com/). If you check a site: query in Bing, you’ll see 11 URLs have been indexed (which doesn’t itself mean anything, as URLs can be indexed by sitemaps etc).
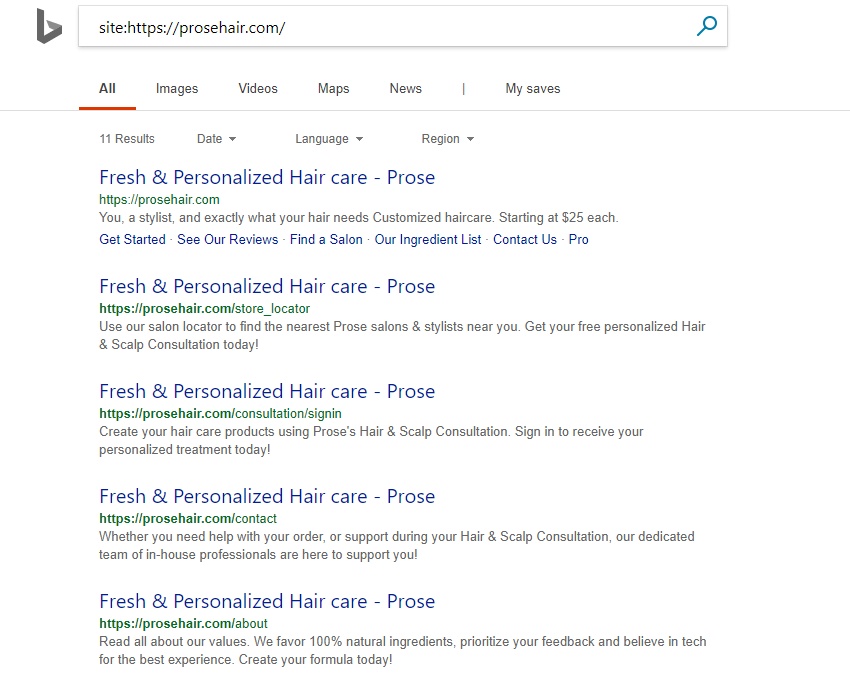
At first glance, you’ll see they all have the same page title (which is in the initial HTML response on every page) and typically you may assume this means Bing isn’t indexing the content in the rendered HTML, where there are unique.
However, if you look again, you’ll notice all the snippets are unique, and the initial HTML response (view source) doesn’t have meta descriptions or content.
If you run a search for content only loaded via JavaScript in the rendered HTML, Bing is also returning pages accurately.
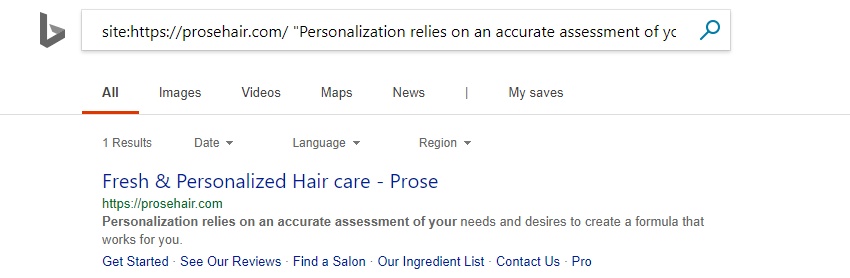
The interesting thing here is that Bing is using the static HTML title still in the SERPs.

The title is from the original HTML (which you can see from viewing the source) –

The page titles in the initial HTML are overriding the rendered, more unique and descriptive page titles in the SERPs (which you can see using ‘inspect element’ in Chrome).
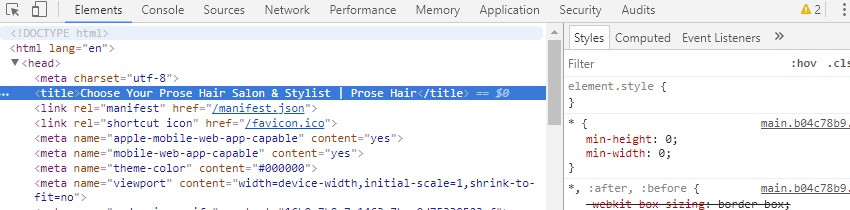
Bing is using the rendered HTML meta descriptions, where there aren’t any in the initial HTML response.
To verify the site wasn’t dynamically rendering to search bots, we spoofed the user-agent string, and we were able to check the fetched HTML in Google Search Console, not Bing Webmaster Tools (but presumably it would be spoofed there, too).
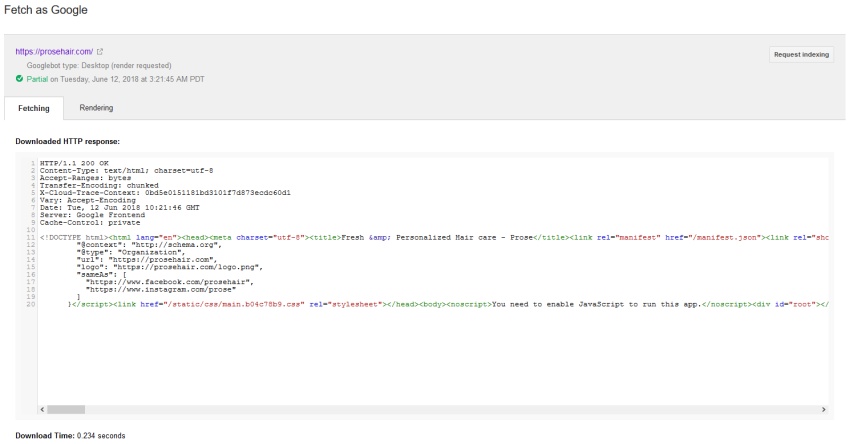
While Bing wouldn’t show a cache of the page at all, Google’s cache is as you would expect for a client-side JS site (showing the initial HTML, rather than the rendered HTML).
Another Example
Another client-side React site we have been monitoring is Shakr (https://www.shakr.com/), which looks like this with JavaScript disabled.
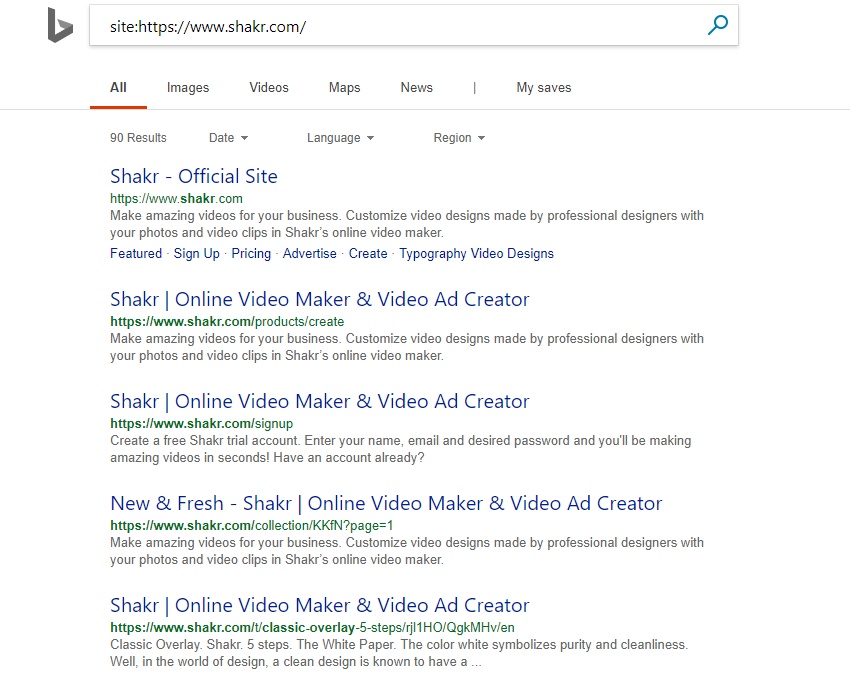
A site query in Bing shows 90 results that have been indexed.
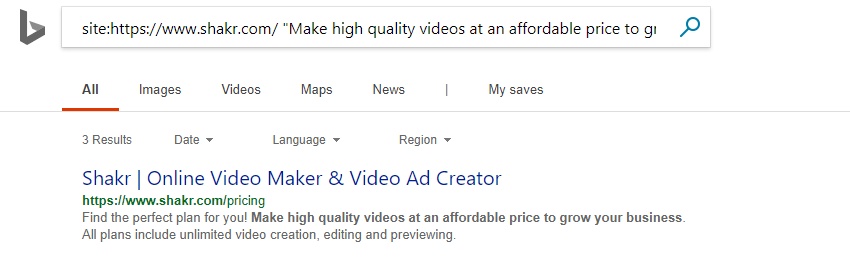
And content which is only available in the rendered HTML is being returned under search.
Although, again Bing is using the title element returned in the initial response, rather than the rendered HTML.
One More For Luck
Another website which loads all content using an external JS file is NS Tecnologia (http://nstecnologia.com.br/). Their initial HTML is literally 8 lines (a clean approach!) –

A site query pulls back their blog at the top results (which doesn’t rely on JS), which again, might make you assume the homepage hasn’t been indexed.
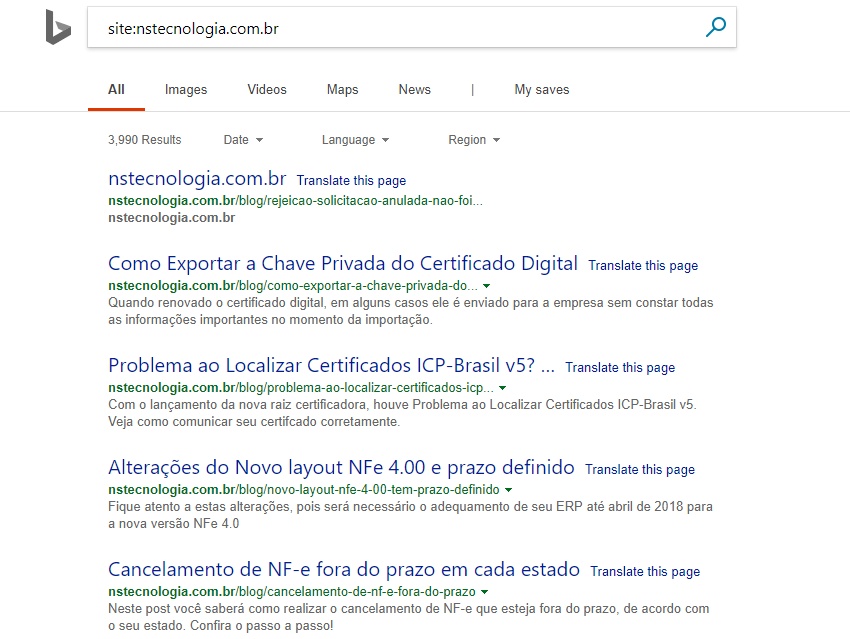
However, a URL query shows it is actually indexed – running searches for content from the page in the rendered HTML also returned the page.
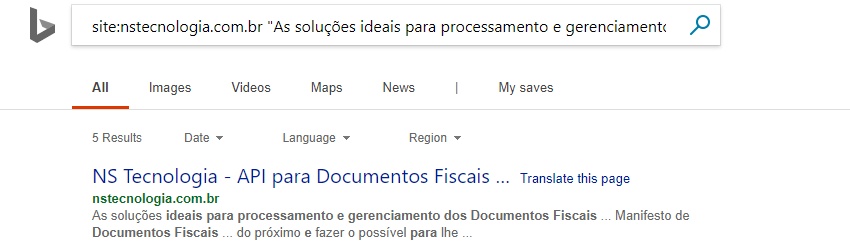
So, Bing does appear to be able to process the JavaScript file, and then crawl and index the content.
In Summary
There does appear to be more evidence that Bing is processing and indexing some JavaScript content. However, it was far from reliable.
We analysed only around twenty sites, and most of them didn’t show any signs of JavaScript being indexed. So, it’s fair to say the results are pretty mixed and you really shouldn’t rely on them indexing content by JavaScript. There weren’t any obvious patterns as to why some were indexed (frameworks, authority etc) and others were not, but the sample size was small and we may perform more tests.
The results also suggest that Bing may have a two-phase indexing process, much like Google. However, if Google renders a page for indexing, we generally find that Google then uses that rendered HTML version for indexing and scoring. Bing’s approach appears to be far more mixed, between content in the initial response, and rendered HTML, which makes it less convincing and reliable.
We know a lot now about Google’s WRS (Chrome 41), which was always present in log files. If Bing is accurately matching their user-agent strings to their WRS, then they might well be using IE11 (released in October 2013).
It’s worth noting, we have seen lots of sites being discussed and shared as client-side when in reality, they actually use the old AJAX crawling scheme or are dynamically serving pre-rendered content to search bots. As a caveat, we analysed the sites above as best we can, to ensure that they were being delivered entirely client-side, but it’s difficult to be 100% sure without having direct access to them.
Finally, it’s worth reiterating that if you care about SEO and sleeping at night, don’t rely on client-side rendering.
Have you seen more evidence of Bing processing and indexing JavaScript?






Nice observation Dan.
Great job Dan!
You have probably seen it, but to expand your knowledge I also recommend Wojtek Goralewicz article (rendering JS in Google): https://www.elephate.com/blog/javascript-seo-experiment/
Cheers, Semrevo! Yes, we know all of Bartosz’s excellent experiments (and mentioned the same test site in that piece, above, for testing with Bing).
It highlights the difficulty with test sites, his isn’t indexed by Bing, yet we prove they do and can index JavaScript (just not at scale, or reliably!).
Hi Dan,
This is a great post! Thanks for providing some tangible examples of test results. FYI – I wanted to tweet this out and the Twitter share button isn’t configured correctly :-) You might want to fix it – I tweeted it manually ;-)
Thanks, Dana! Yes, we’ve been meaning to fix those (it’s any with an ampersand that have the issue!).
Glad you found the Bing JS results useful.
Interesting post to get the discussion started with colleagues. More posts like these, Dan!
Thanks for this thought provoking article. There is not a lot of documentation that I’ve found on Bing – JS. This confirms some of my suspicions.
Would love to see an update on this article!