Duplicates
Dan Sharp
Posted 1 July, 2020 by Dan Sharp in
Duplicates
Configuration > Content > Duplicates
The SEO Spider is able to find exact duplicates where pages are identical to each other, and near duplicates where some content matches between different pages. Both of these can be viewed in the ‘Content’ tab and corresponding ‘Exact Duplicates’ and ‘Near Duplicates’ filters.

Exact duplicate pages are discovered by default. To check for ‘near duplicates’ the configuration must be enabled, so that it allows the SEO Spider to store the content of each page.

The SEO Spider will identify near duplicates with a 90% similarity match using a minhash algorithm, which can be adjusted to find content with a lower similarity threshold.
The SEO Spider will also only check ‘Indexable’ pages for duplicates (for both exact and near duplicates).
This means if you have two URLs that are the same, but one is canonicalised to the other (and therefore ‘non-indexable’), this won’t be reported – unless this option is disabled.
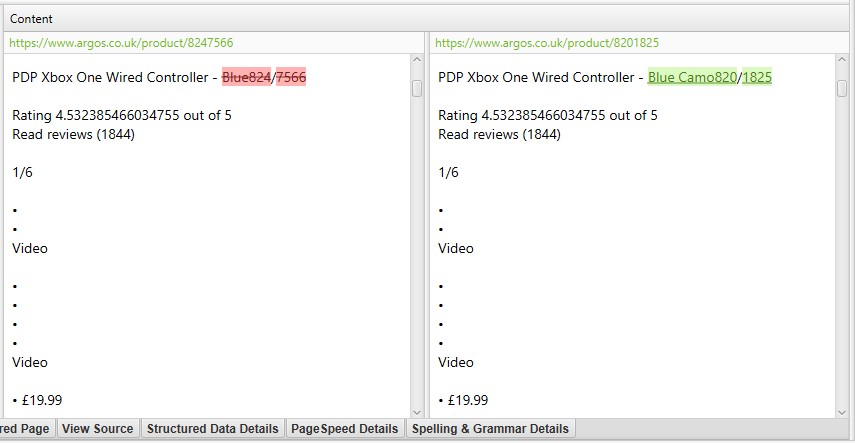
Near duplicates requires post crawl analysis to be populated, and more detail on the duplicates can be seen in the ‘Duplicate Details’ lower tab. This displays every near duplicate URL identified, and their similarity match.

Clicking on a ‘Near Duplicate Address’ in the ‘Duplicate Details’ tab will also display the near duplicate content discovered between the pages and highlight the differences.
The content area used for near duplicate analysis can be adjusted via ‘Configuration > Content > Area’. You’re able to add a list of HTML elements, classes or ID’s to exclude or include for the content used.
The near duplicate content threshold and content area used in the analysis can both be updated post crawl and crawl analysis can be re-run to refine the results, without the need for re-crawling.





