Google Search Console integration
Dan Sharp
Posted 13 October, 2016 by Dan Sharp in
Google Search Console integration
Configuration > API Access > Google Search Console
You can connect to the Google Search Analytics and URL Inspection APIs and pull in data directly during a crawl.
By default the SEO Spider will fetch impressions, clicks, CTR and position metrics from the Search Analytics API, so you can view your top performing pages when performing a technical or content audit.
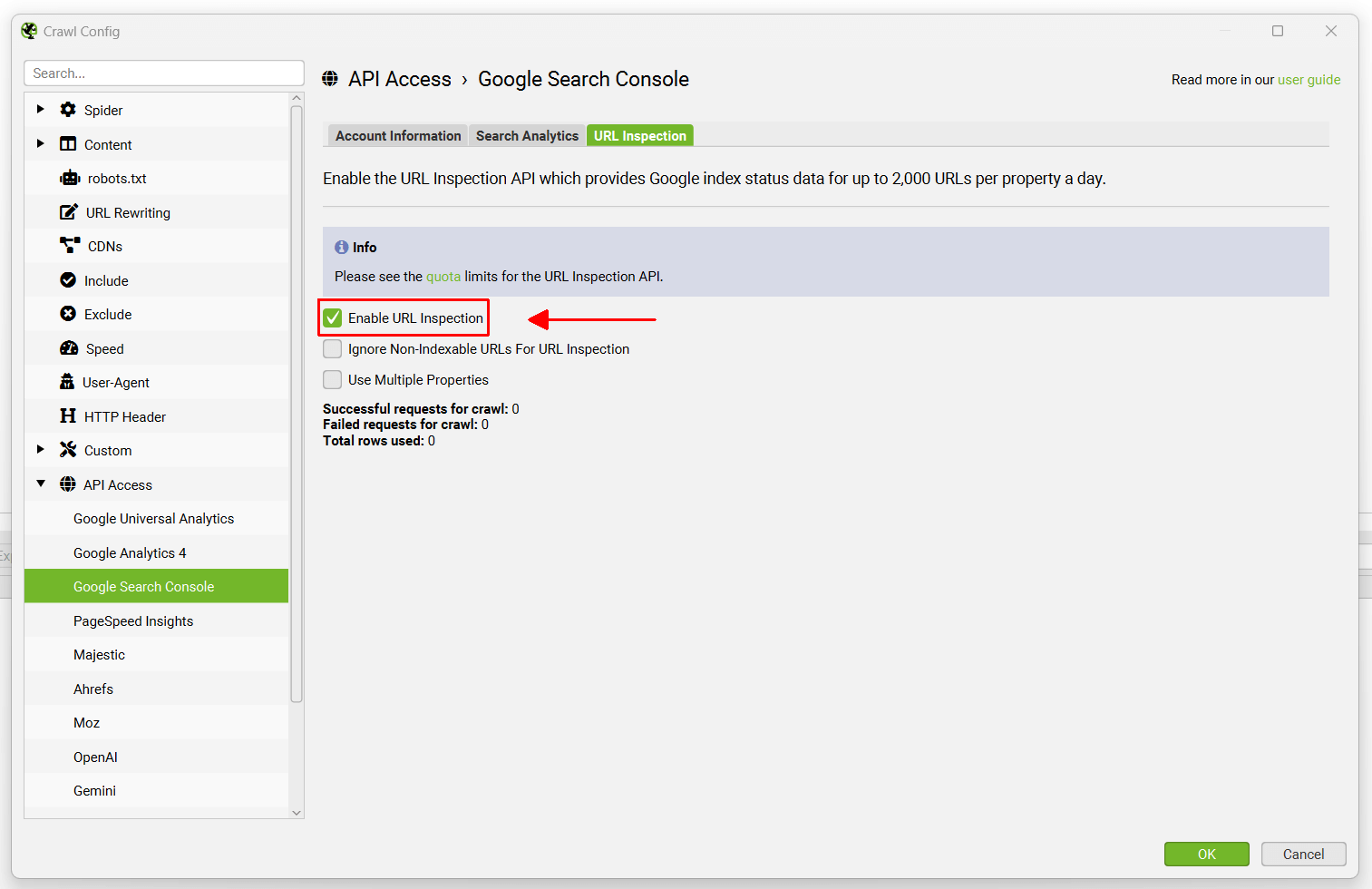
Optionally, you can also choose to ‘Enable URL Inspection’ alongside Search Analytics data, which provides Google index status data for up to 2,000 URLs per property a day. This includes whether the ‘URL is on Google’, or ‘URL is not on Google’ and coverage.
To set this up, go to ‘Configuration > API Access > Google Search Console’.

Connect to a Google account (which has access to the Search Console account you wish to query) by granting the ‘Screaming Frog SEO Spider’ app permission to access your account to retrieve the data. Google APIs use the OAuth 2.0 protocol for authentication and authorisation. The SEO Spider will remember any Google accounts you authorise within the list, so you can ‘connect’ quickly upon starting the application each time.
Once you have connected, you can choose the relevant website property.

By default the SEO Spider collects the following metrics for the last 30 days –
- Clicks
- Impressions
- CTR
- Position
Read more about the definition of each metric from Google.
If you click the ‘Search Analytics’ tab in the configuration, you can adjust the date range, dimensions and various other settings.

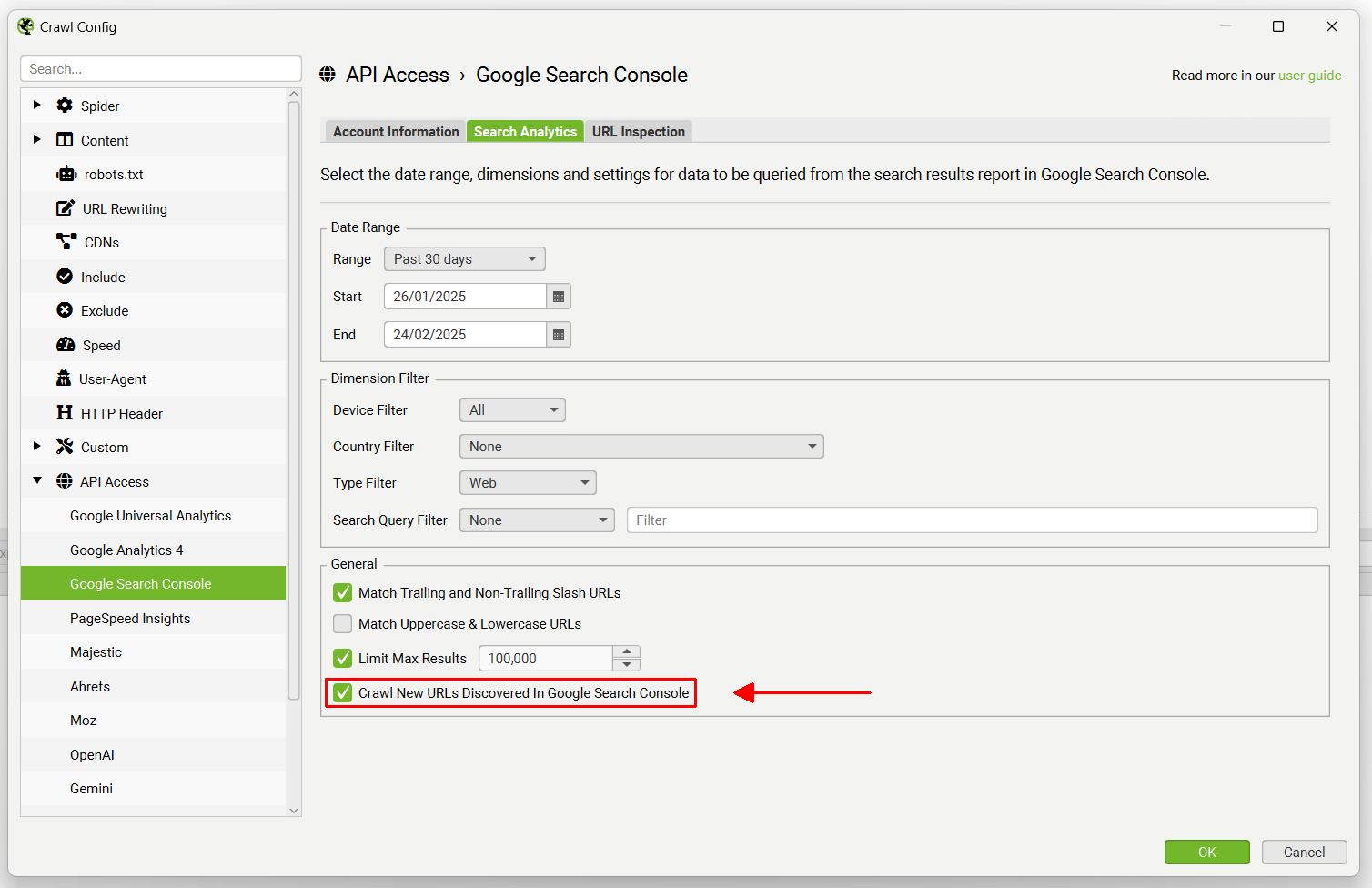
If you wish to crawl new URLs discovered from Google Search Console to find any potential orphan pages, remember to enable the configuration shown below.
Optionally, you can navigate to the ‘URL Inspection’ tab and ‘Enable URL Inspection’ to collect data about the indexed status of up to 2,000 URLs in the crawl.
The SEO Spider crawls breadth-first by default, meaning via crawl depth from the start page of the crawl. The first 2k HTML URLs discovered will be queried, so focus the crawl on specific sections, use the configration for include and exclude, or list mode to get the data on key URLs and templates you need.
The following configuration options are available –
- Ignore Non-Indexable URLs for URL Inspection – This means any URLs in the crawl that are classed as ‘Non-Indexable’, won’t be queried via the API. Only Indexable URLs will be queried, which can help save on your inspection quota if you’re confident on your sites set-up.
- Use Multiple Properties – If multiple properties are verified for the same domain the SEO Spider will automatically detect all relevant properties in the account, and use the most specific property to request data for the URL. This means it’s now possible to get far more than 2k URLs with URL Inspection API data in a single crawl, if there are multiple properties set up – without having to perform multiple crawls.
The URL Inspection API includes the following data.
- Summary – A top level verdict on whether the URL is indexed and eligible to display in the Google search results. ‘URL is on Google’ means the URL has been indexed, can appear in Google Search results, and no problems were found with any enhancements found in the page (rich results, mobile, AMP). ‘URL is on Google, but has Issues’ means it has been indexed and can appear in Google Search results, but there are some problems with mobile usability, AMP or Rich results that might mean it doesn’t appear in an optimal way. ‘URL is not on Google’ means it is not indexed by Google and won’t appear in the search results. This filter can include non-indexable URLs (such as those that are ‘noindex’) as well as Indexable URLs that are able to be indexed.
- Coverage – A short, descriptive reason for the status of the URL, explaining why the URL is or isn’t on Google.
- Last Crawl – The last time this page was crawled by Google, in your local time. All information shown in this tool is derived from this last crawled version.
- Crawled As – The user agent type used for the crawl (desktop or mobile).
- Crawl Allowed – Indicates whether your site allowed Google to crawl (visit) the page or blocked it with a robots.txt rule.
- Page Fetch – Whether or not Google could actually get the page from your server. If crawling is not allowed, this field will show a failure.
- Indexing Allowed – Whether or not your page explicitly disallowed indexing. If indexing is disallowed, the reason is explained, and the page won’t appear in Google Search results.
- User-Declared Canonical – If your page explicitly declares a canonical URL, it will be shown here.
- Google-Selected Canonical – The page that Google selected as the canonical (authoritative) URL, when it found similar or duplicate pages on your site.
- Mobile Usability – Whether the page is mobile friendly or not.
- Mobile Usability Issues – If the ‘page is not mobile friendly’, this column will display a list of mobile usability errors.
- AMP Results – A verdict on whether the AMP URL is valid, invalid or has warnings. ‘Valid’ means the AMP URL is valid and indexed. ‘Invalid’ means the AMP URL has an error that will prevent it from being indexed. ‘Valid with warnings’ means the AMP URL can be indexed, but there are some issues that might prevent it from getting full features, or it uses tags or attributes that are deprecated, and might become invalid in the future.
- AMP Issues – If the URL has AMP issues, this column will display a list of AMP errors.
- Rich Results – A verdict on whether Rich results found on the page are valid, invalid or has warnings. ‘Valid’ means rich results have been found and are eligible for search. ‘Invalid’ means one or more rich results on the page has an error that will prevent it from being eligible for search. ‘Valid with warnings’ means the rich results on the page are eligible for search, but there are some issues that might prevent it from getting full features.
- Rich Results Types – A comma separated list of all rich result enhancements discovered on the page.
- Rich Results Types Errors – A comma separated list of all rich result enhancements discovered with an error on the page. To export specific errors discovered, use the ‘Bulk Export > URL Inspection > Rich Results’ export.
- Rich Results Warnings – A comma separated list of all rich result enhancements discovered with a warning on the page. To export specific warnings discovered, use the ‘Bulk Export > URL Inspection > Rich Results’ export.
You can read more about the the indexed URL results from Google.
There are 11 filters under the ‘Search Console’ tab, which allow you to filter Google Search Console data from both APIs.
- Clicks Above 0 – This simply means the URL in question has 1 or more clicks.
- No Search Analytics Data – This means that the Search Analytics API didn’t return any data for the URLs in the crawl. So the URLs either didn’t receive any impressions, or perhaps the URLs in the crawl are just different to those in GSC for some reason.
- Non-Indexable with Search Analytics Data – URLs that are classed as non-indexable, but have Google Search Analytics data.
- Orphan URLs – URLs that have been discovered via Google Search Analytics, rather than internal links during a crawl. This filter requires ‘Crawl New URLs Discovered In Google Search Console’ to be enabled under the ‘General’ tab of the Google Search Console configuration window (Configuration > API Access > Google Search Console) and post ‘crawl analysis‘ to be populated. Please see our guide on how to find orphan pages.
- URL Is Not on Google – The URL is not indexed by Google and won’t appear in the search results. This filter can include non-indexable URLs (such as those that are ‘noindex’) as well as Indexable URLs that are able to be indexed. It’s a catch all filter for anything not on Google according to the API.
- Indexable URL Not Indexed – Indexable URLs found in the crawl that are not indexed by Google and won’t appear in the search results. This can include URLs that are unknown to Google, or those that have been discovered but not indexed, and more.
- URL is on Google, But Has Issues – The URL has been indexed and can appear in Google Search results, but there are some problems with mobile usability, AMP or Rich results that might mean it doesn’t appear in an optimal way.
- User-Declared Canonical Not Selected – Google has chosen to index a different URL to the one declared by the user in the HTML. Canonicals are hints, and sometimes Google does a great job of this, other times it’s less than ideal.
- Page Is Not Mobile Friendly – The page has issues on mobile devices.
- AMP URL Is Invalid – The AMP has an error that will prevent it from being indexed.
- Rich Result Invalid – The URL has an error with one or more rich result enhancements that will prevent the rich result from showing in the Google search results. To export specific errors discovered, use the ‘Bulk Export > URL Inspection > Rich Results’ export.
Please see our tutorial on ‘How To Automate The URL Inspection API‘.





