Majestic
Dan Sharp
Posted 18 July, 2017 by Dan Sharp in
Majestic
Configuration > API Access > Majestic
In order to use Majestic, you will need a subscription which allows you to pull data from their API. You then just need to navigate to ‘Configuration > API Access > Majestic’ and then click on the ‘generate an Open Apps access token’ link.

You will then be taken to Majestic, where you need to ‘grant’ access to the Screaming Frog SEO Spider.

You will then be given a unique access token from Majestic.

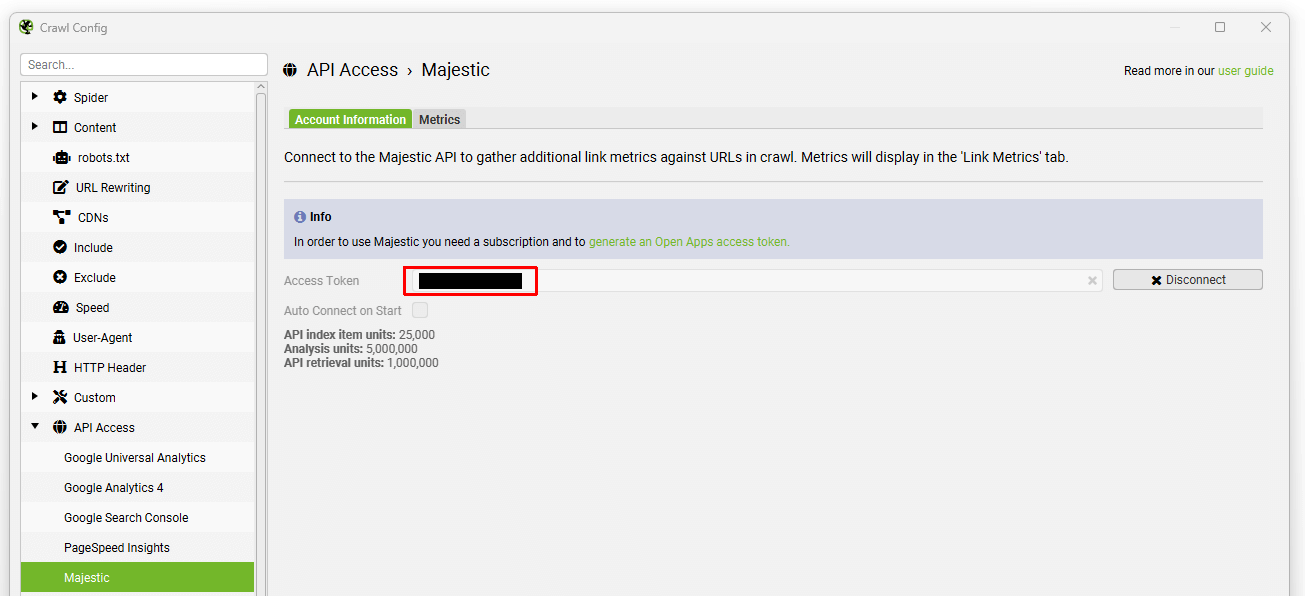
Copy and input this token into the API key box in the Majestic window, and click ‘connect’ –
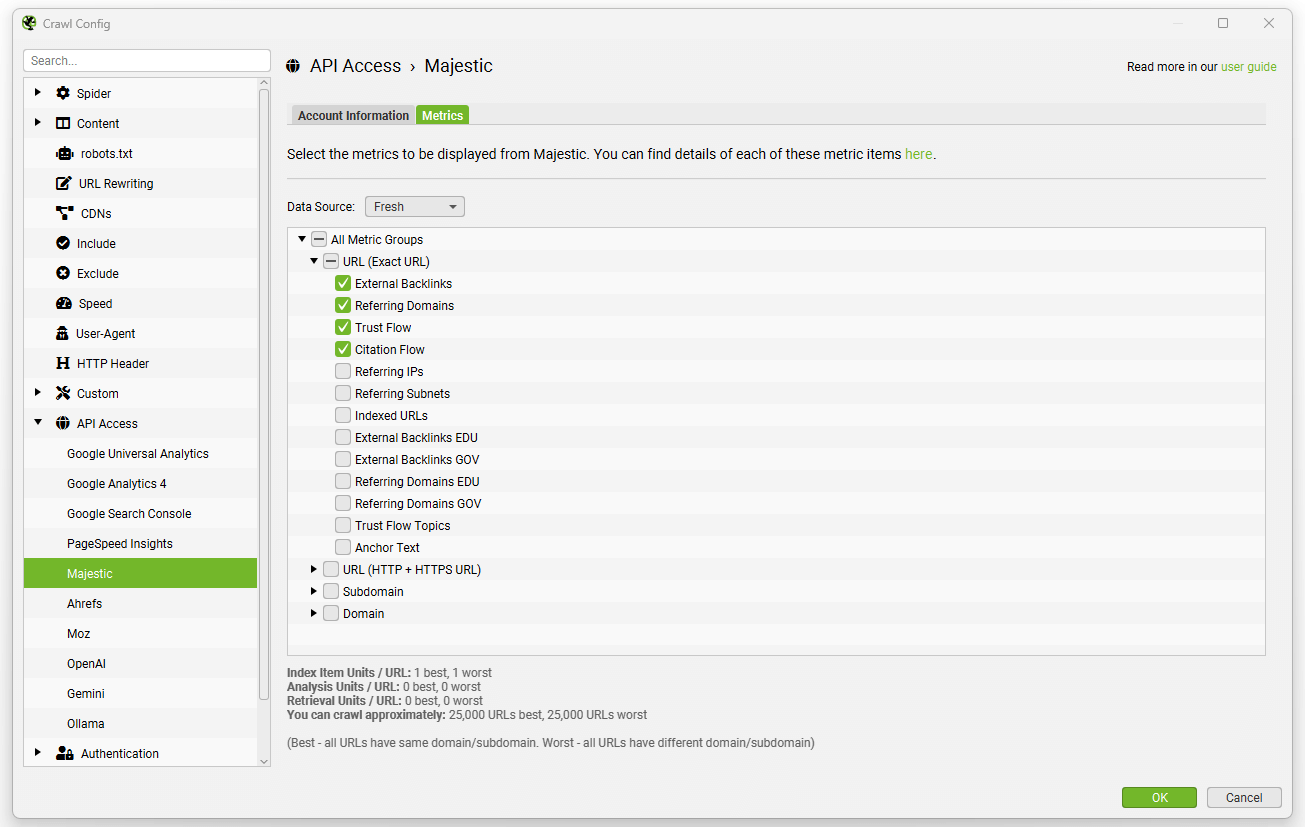
You can then select the data source (fresh or historic) and metrics, at either URL, subdomain or domain level.
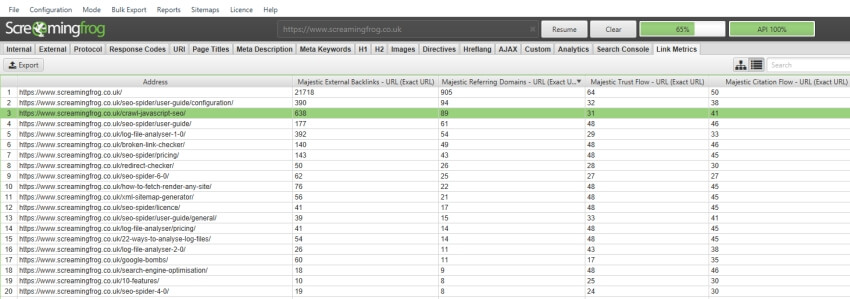
Then simply click ‘start’ to perform your crawl, and the data will be automatically pulled via their API, and can be viewed under the ‘link metrics’ and ‘internal’ tabs.