Screaming Frog SEO Spider Update – Version 2.20
Dan Sharp
Posted 15 July, 2013 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 2.20
I am delighted to announce version 2.20 of the Screaming Frog SEO spider.

We have been busy behind the scenes developing some very cool new features which we hope everyone will enjoy! As always, thank you to everyone for their fantastic feedback and suggestions, we still have plenty more to come. Version 2.20 now includes the following –
Redirect Chains Report
There is a new ‘reports’ menu in the top level navigation of the UI, which contains the redirect chains report. This report essentially maps out chains of redirects, the number of hops along the way and will identify the source, as well as if there is a loop. This is really useful as the latency for users can be longer with a chain, a little extra PageRank can dissipate in each hop and a large chain of 301s can be seen as a 404 by Google (Matt discussed this in a Google Webmaster Help video here).
Another very cool part of the redirect chain report is how it works for site migrations alongside the new ‘Always follow redirects‘ option (in the ‘advanced tab’ of the spider configuration). Now when you tick this box, the SEO spider will continue to crawl redirects even in list mode and ignore crawl depth.
Previously the SEO Spider would only crawl the first redirect and report the redirect URL target under the ‘Response Codes’ tab. However, as list mode is essentially working at a crawl depth of ‘0’, you wouldn’t see the status of the redirect target which, particularly on migrations is required when a large number of URLs are changed. Potentially a URL could 301, then 301 again and then 404. To find this previously, you had to upload each set of target URLs each time to analyse responses and the destination. Now, the SEO Spider will continue to crawl, until it has found the final target URL. For example, you can view redirect chains in a nice little report in list mode now.
{kind=link}
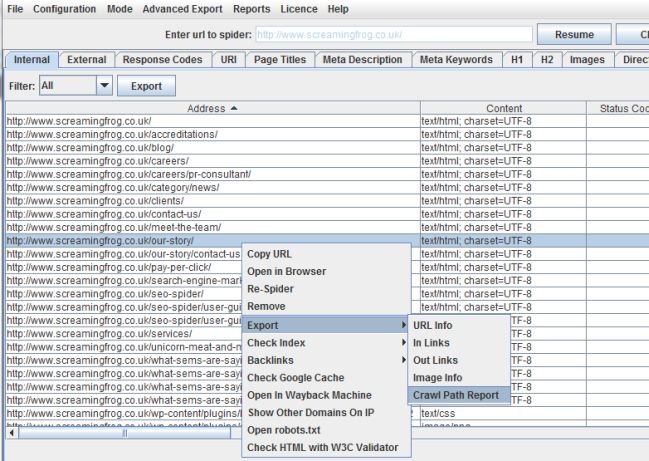
Crawl Path Report
Have you ever wanted to know how a URL was discovered? Obviously you can view ‘in links’ of a URL, but when there is a particularly deep page, or perhaps an infinite URLs issue caused by incorrect relative linking, it can be a pain to track down the originating source URL (Tip! – To find the source manually, sort URLs alphabetically and find the shortest URL in the sequence!). However, now on right click of a URL (under ‘export’), you can see how the spider discovered a URL and what crawl path it took from start to finish.
Respect noindex & Canonical
You now have the option to ‘respect’ noindex and canonical directives. If you tick this box under the advanced tab of the spider configuration, the SEO Spider will respect them. This means ‘noindex’ URLs will obviously still be crawled, but they will not appear in the interface (in any tab) and URLs which have been ‘canonicalised’ will also not appear either. This is useful when analysing duplicate page titles, or descriptions which have been fixed by using one of these directives above.
rel=“next” and rel=“prev”
The SEO Spider now collects these html link elements designed to indicate the relationship between URLs in a paginated series. rel=“next” and rel=“prev” can now be seen under the ‘directives’ tab.
Custom Filters Now Regex
Similar to our include, exclude and internal search function, the custom filters now support regex, rather than just query string. Oh and we have increased the number of filters from five to ten and included ‘occurrences’. So if you’re searching for an analytics UA ID or a particular phrase, the number of times it appears within the source code of a URL will be reported as well.
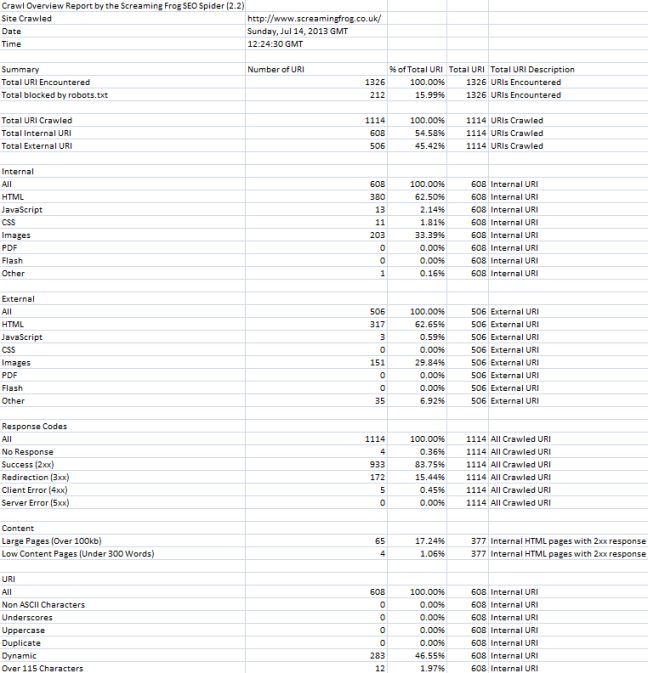
Crawl Overview Report
Under the new ‘reports’ menu discussed above, we have included a little ‘crawl overview report’. This does exactly what it says on the tin and provides an overview of the crawl, including total number of URLs encountered in the crawl, the total actually crawled, the content types, response codes etc with proportions. This will hopefully provide another quick easy way to analyse overall site health at a glance. Here’s a third of what the report looks like –
We have also changed the max page title length to 65 characters (although it seems now to be based on pixel image width), added a few more preset mobile user agents, fixed some bugs (such as large sitemaps being created over the 10Mb limit) and made other smaller tweaks along the way.
As always, we love any feedback and thank you again for all your support. Please do update your SEO Spider now to try out all the new features.
Small Update – Version 2.21 Released 20th October 2013
We have released a very small update to version 2.21 of the Screaming Frog SEO spider, which essentially fixes a few small bugs & updates a couple of features from feedback we received. These include –
- Individual cell selection, so contents can be individually copied and pasted.
- Now when you upload a list of URLs and use the ‘Always follow redirects‘ configuration, the resulting redirect chains report export will now include ALL URLs from the original upload, not just those that redirect. This should make it easier to audit URLs in a site migration by seeing them all in one place with a single report.
- There was a bug with relative URLs and the new respect canonical configuration which has been corrected.
- We have fixed a couple of smaller total & percentage calculations in the crawl overview report.
Small Update – Version 2.22 Released 3rd December 2013
We have just released another small update to version 2.22 of the Screaming Frog SEO spider. There’s a couple of tweaks, which include –
- We are now identified Apple developers! So hopefully Mac users will no longer receive a warning that we are ‘unidentified’ or the ‘file is damaged’ upon install.
- From feedback of individual cell and row selection in 2.21, we have improved this and introduced row numbers.
That’s it for now, if you spot any issues, please as always do let us know via our support. Thanks again for all the kind comments below, we are busy working on lots of new features for our next release!






Awesome update guys! Sounds like some really useful new features.
All great new features; every single one useful. Keep up the good work!
@Miguel @Bob – Thanks guys, really appreciated.
The only thing I’m sad about…
Is i’m about to walk into a meeting and I can’t play with this for a few hours. :)
Thanks!! The redirect loop/chain tool will let me do a project I’ve been having to do for a few months super easily!
heheh! Thanks Dan – The redirect chain report has been on the list for a little while, so it’s great to release it finally.
Guys… Thank you! Great new features in my absolute favorite tool. There is not a day where I don’t use Screaming Frog!
Hey, great new features – thanks for your good work !!!
Nice work! You just saved me hours with crawl paths and redirect chains.
Great to hear, thanks Dan.
Nice one! Whats the Max Memory Limit for crawling large sites?
Out of the box, the limit is 512MB. Though you can override that. The limit depends upon your OS. You can find what you need here: https://www.screamingfrog.co.uk/seo-spider/user-guide/general/ It’s a few headings after the video.
Thanks for helping to answer the query Travis.
@Sebastian – Thank you! As Travis already answered, we have a guide on increasing memory allocation over here – https://www.screamingfrog.co.uk/seo-spider/user-guide/general/#6 :-)
Great work, just the features I was hoping for…
awesome addition to the tool with the crawl path and redirect chains! thanks :)
The best crawler just got better. I always recommend Screaming Frog when the subject comes up. It’s worth every red cent.
Very nice work! Thanks :)
If i knew this a week ago… It saved me approx 2 days of work… Great Update by the way!
In the new crawl overview spreadsheet, the depth for clicks from the start URL seems useful.
Depth (Clicks from Start URL):
1 2 3 4 5 6+
However, the percentages are adding up to ~250%.
How do you arrive at the number of URI in this case?
Good spot. There is a bug on these numbers (including more than just html pages).
We are awaiting more bugs and feedback (there’s always some!) before updating a release with small fixes.
Cheers.
Great update Guys! Might have to purchase a full license now as seem to be using more and more.
Thanks for the update, especially the redirect path.
We’re using Screaming Frog to check our websites both on developpement and staging environnement. Because we have many subdomains and the staging environnent is password protected it’s sometimes painful to to type the same username/password for each subdomains.
Could you add a function, wich will be able to memorize the requested username and password and try it on any subdomains.
Hey François,
Good to hear you like the redirect chain report.
We can certainly add your suggestion to our ‘todo’ list, so there is an option to remember the username/password.
Thanks for the feedback.
Dan
Hey Dan,
Thanks for your reply.
I would like to be able to define a default username / password for a all subdomains under the same domain so the spider will try to authenticate using this default username/password.
Francois
Makes sense, thats for the feedback again.
Cheers.
Real exciting stuff in this update. Pagination directives, Redirect Chains…Oh My! Thank you for continuing to make a great product even better!
Niiice! Looking forward to play with the frog again :-)
Thanks for this will update my version now, then it is time to crawl thousands of pages =)
Fantastic update, loving the crawl path!
Well done guys
Great update. The redirect chain report is perfect for a task I was just assigned. This tool keeps getting better.
Can you please share a quick “how to read” the crawl path report. It seems intuitive enough but I want to make sure I’ve got it right before sharing with customers.
Hi Steve,
More info here – https://www.screamingfrog.co.uk/seo-spider/user-guide/general/#9
I hope that helps.
Cheers.
Dan
Can you make this software to crawl Javascript files, for external links or internal links. I hope you can include in 2.3 version.
Oh! That’s great news. Thanks for sharing SEO Search Engine Optimization spider update.
Really, an useful tool.
Definitely a great update indeed.
How about few more suggestions?
It would be great if you can fetch GA code from the page and mention whether it is missing or not. Also, the HTTP issues in a tree structure would help a lot. It helps in where the HTTP issue is generating from.
Hi Ricky,
Thanks for the suggestions, but these are already available –
You can use the custom source code search feature to analyse GA code – https://www.screamingfrog.co.uk/seo-spider/user-guide/configuration/#13
You can view in links to any URLs (whatever http you wish) using the advanced export menu – https://www.screamingfrog.co.uk/seo-spider/user-guide/general/#3
Cheers
Dan
Thank you so much for the update.
I am waiting a lot for path report and noindex features. Good job.
Great work guys. I love the new features, especially the overview report. I can’t wait for the next update – worth every cent!
Really informative. Thanks a lot.
Great Update!!
All these new features are great! my favorite is the redirect chain report but all the others are great too.
Thanks so much for the great work. You guys rock! (as always by the way)
Daniel
The new features look really good. Looking forward to trying out the crawl path report feature. Nice work.
Really great work guys. And also very informative . Actually I have been looking for this for a few days. Thanks again.
Great updates. These are going to save me a ton of time with site audits. Just tried the Overview report and there is so much useful information in here.
Thanks for the update team, tons of new & helpful features! Question, do you guys have plans on including a crawler that scans marketing tags (like Google Analytics, Adsense, KissMetrics, etc.) sometime in the near future? I found a pretty cool tool, Tag Inspector (http://www.taginspector.com) that does just that, but would love to see your tool also add this feature in future updates.
Thanks again for the great work!
Hey Jimmy,
Thanks! You can use the custom source code search function to find analytics code and more – https://www.screamingfrog.co.uk/seo-spider/user-guide/configuration/#13
We have thought about extending this feature to make it easier to search for specific marketing tags etc, but I can’t give a date when it might be available :-)
Thanks again for the feedback!
Thanks again to everyone for commenting and all the kind words.
Lots more to come!
Beautiful work. Really love how this program continues to go from strength to strength. Well done.
This software used to helpful for me and now upgraded version is awesome….it will rock in seo world.
This looks like a very good tool. I am new here so I wanted to see what other tools are out there in SEO.
I bet you did a lot of work on this tool. It looks very intuitive.
Great news. The only thing that I’d like to point out that you have not added the option to check if a specific page has been indexed by Google. :)
Wow, thanks for the update. I love Screaming Frog. :)
Hey, love Screaming Frog! I have a question about Custom Filters. Is there a way of exporting all filters without having to export each individually? It would be fantastic if it would export all custom filters, with perhaps a tab (Excel) for each Filter.
It would also be really helpful to be able to see what the actual Filter is from the Screaming Frog software. i.e. “Filter: Filter 1 [Export] could be something like “Filter: UA-123456789 [Export]
Thanks again for such an amazing contribution to the Internet Marketing world with this tool! :)
Hello thewebtheorist :-)
There’s no way of exporting all at once currently I am afraid, it has to be individually.
Thanks for the suggestions though, I agree seeing the contents of the filter would be useful as well.
Cheers.
Dan
Love the Screaming Frog, thanks for the update!
amazing update, I love the new features. Thanks a lot!
Thanks for new great features…They are really handy….
Awesome guys! I don’t know what I would do without Screaming Frog. Your ongoing dedication to improving an already stellar piece of SEO software is incredible.
Another great update to my most used tool.
I have a suggestion for a feature. It would be great if there was a way to crawl URLs, but ultimately exclude them from being included in final report.
Say if there is website that has hundreds of category ‘page=’ pages, with valid product pages being linked from them. I don’t actually need the ‘page=’ pages in the report, (as I will be excluding these from being indexed in Google) but I can’t exclude them from being crawled as then it would miss all the products pages linked from them.
This would decrease the size of the crawl, as I often have gigantic crawls of thousands, upon thousands of pages that often run out of the memory.
Awesome update guys! Really nice tool for SEOs :-)
Thanks for continuing to build this great tool – loving the idea of the redirect loop info and also the respecting noindex and canonical – makes the crawl even more accurate. Going to update my version now. :)
If I had to choose which feature to kill from this update, I would not know. Make as stable as Xenu and so it can crawl millions of pages on a website and not fall off – and it will be the single tool one will ever need.
Thanks for the latest update…Screaming Frog is a fantastic tool that has saved me countless man-hours. Much appreciated!
The Individual cell selection , while it may be useful, actually feels like a step backward. If i select a line in the first column, then scroll all the way to the far right column, I no longer have any idea which line I’m on.
Perhaps you could have the 1st colum where you can select the entire row, like excel.
Hey Max,
Thanks for the feedback. I agree, I think this can be improved.
The old click a cell which highlights the whole row was useful when you scroll to know exactly which line you’re looking at.
We will have a look at making this easier, but for now you can (you may already know) –
* When you click on a cell and want to scroll right, just hold down the click on the cell and drag right (which scrolls right and highlights the row).
Or
* Click on the cell and use the right arrow key, this scrolls right and keeps to the same row.
Cheers.
Dan
First of all thank you for your awesome tool. But I have to agree to Max Peters, the individual cell selection of version 2.21 fells like a step back.
The export to csv function didn’t work well for me because some characters created an unwanted line break in excel. This made it really hard to work with this data. But i found a workaround for this problem. I just copied and pasted everything out of Screaming Frog into Excel and then applied the style of excel to it. This put every piece of content in the right cell, no aditional fixes were needed.
Now since to new update this workaround isn’t working anymore. Maybe you figure something out to make this work again, or even fix/optimize the export to csv function. Until then i’ll have to downgrade to 2.20 again.
Hi SF,
ur update sounds cool … very cooL! Acutualy theres a problem with installing the new version. Downloading runs witout any problems, but while installation at mac 10.9 an error Message appears: “Screaming Frog SEO Spider.app” ist beschädigt und kann nicht geöffnet werden. Es empfiehlt sich, das Objekt in den Papierkorb zu bewegen.”
Its sounds like a damaged image?!
Quick Help would be nice,
thx
Max
Hey Max,
It’s Apples Gatekeeper requiring an ‘authorised developer’, more details here in the FAQ –
https://www.screamingfrog.co.uk/seo-spider/faq/#38
Cheers,
Dan
The update sound cool with bug fixes.
Any idea on support for Retina text on Mac?
Hi Conrad,
It’s something we’ve had feedback on recently, so will be looking into.
Thanks,
Dan
Getting this message under mavericks.
Finder[157]: JLRequestRuntimeInstall: CFMessagePortSendRequest: error -1
I have uninstalled and reinstalled and nothing. It will not launch.
I would appreciate any feedback or advice. Thx for your time.
Hi Nicholas,
This is not an error we’ve seen before.
So I just had a Google and this error appears to be related to the auto install of Java failing. I’d suggest you download and install Java 6 manually from Apple here and try again.
http://support.apple.com/kb/DL1572?viewlocale=en_US
Anymore problems, our support details are here –
https://www.screamingfrog.co.uk/seo-spider/support/
Cheers,
Dan
loving the idea of redirecting loop..thanks for the tool and the updates..fantastic post..Thank you…!!!
We use Screaming Frog extensively here at the office. Only question is are you going to provide support for Retina text on Mac? I’d like to see our results in full HD B)
Hey David,
It’s on our list, we have had a few people request this :-)
Cheers,
Dan
Thanks Dan for the reply. I’ll keep my eyes open for the update!
Big Fan of Screaming Flog…this is a must have SEO tool.
Loving the redirect chain report.
Thx for all that you do!
– Jason Hennessey
Does screaming frog analysis schema structure of blog ?
Hi George,
It doesn’t as yet, but we do have it on the ‘todo’.
You can use the custom filters to search for any Schema though :-)
Thanks,
Dan
Does SEO Spider have any automation capabilities? Like, I save my list of URLS to run, and it can run it each night at 10 and save out the reports separate for each URL; or even export as a sql file?
Or am I going to have to do something funky with Applescript and GUI automation?
Hi Vance,
Not yet I am afraid, but it is coming :-)
Thanks,
Dan
That would be interesting. Can you say more about when?
Im waiting on this too ;-) When do you guys think its ready for us?
Hi Paw,
I think you’ve seen this already, but details over here :-) –
https://www.screamingfrog.co.uk/seo-spider/user-guide/general/#scheduling
Cheers,
Dan
BIG shout out to Screaming Frog! I’ve been using your software for a while, but mainly internally. I WOW’d a prospect last week with a report I handed them thanks to data from SF, Moz and Link Assistant’s Rank Tracker, that they pulled the trigger to move forward with us! Your software is invaluable and looking for to more updates as you all evolve. That Retina display would be kick-ass as well from a comment above I saw!! – Patrick @ Whiteboard Creations
Loaded log on screen first in the list of URL’s to crawl, but the log on screen dialog box never comes up, page says unauthorized.
Hey Ted,
You’re commenting on a really old blog post now and I’ve just seen you’ve contacted support.
So, will be in touch via email.
Cheers,
Dan
Guys… Thank you! Great new features in my absolute favorite tool. There is not a day where I don’t use Screaming Frog!
Thanks for continuing to build this great tool – love it!
Thanks for another great update! Screaming Frog is my go-to tool – I use it daily and couldn’t work without it.