Screaming Frog SEO Spider Update – Version 16.6
Dan Sharp
Posted 3 February, 2022 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 16.6
We’re excited to release version 16.6 of the Screaming Frog SEO Spider codenamed ‘Romeo’.
We don’t usually shout about point releases as they do not contain ‘new’ features, they are for improvements to existing features, and bug fixes. However, this release includes an update that could be described as both a new feature, and an improvement on an existing integration.
As it’s quite a cool one, we wanted to provide a bit more detail. So, what’s new?
1) URL Inspection API Integration
Google announced the launch of the new Search Console URL Inspection API, which allows users to fetch current Google index data that you see in Search Console.
We have been busy updating the SEO Spider to support the new API into our existing Search Console integration, which already pulls data from the search analytics API.
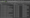
Now you’re able to connect to the URL Inspection API in the SEO Spider, and pull in data for up to 2k URLs per property a day alongside all the usual crawl data.
While 2k URLs a day is obviously low for large websites, it will help monitor key pages, debug sample templates and single pages. It’s also per property, so if you have lots of subdomains or subfolders verified, you can substantially increase that limit across the entire domain.
To connect, go to ‘Config > API Access > Google Search Console’, connect to your account, choose your property and then under the ‘URL Inspection’ tab, select ‘Enable URL Inspection’.

URL Inspection API data will then be populated in the ‘Search Console’ tab, alongside the usual Search Analytics data (impressions, clicks, etc). We’ve introduced some new filters to help you quickly identify potential issues.

Here’s a quick rundown of the meaning of each new filter –
- URL Is Not on Google – The URL is not indexed by Google and won’t appear in the search results. This filter can include non-indexable URLs (such as those that are ‘noindex’) as well as Indexable URLs that are able to be indexed. It’s a catch all filter for anything not on Google according to the API.
- Indexable URL Not Indexed – Indexable URLs found in the crawl that are not indexed by Google and won’t appear in the search results. This can include URLs that are unknown to Google, or those that have been discovered but not indexed, and more.
- URL is on Google, But Has Issues – The URL has been indexed and can appear in Google Search results, but there are some problems with mobile usability, AMP or Rich results that might mean it doesn’t appear in an optimal way.
- User-Declared Canonical Not Selected – Google has chosen to index a different URL to the one declared by the user in the HTML. Canonicals are hints, and sometimes Google does a great job of this, other times it’s less than ideal.
- Page Is Not Mobile Friendly – The page has issues on mobile devices.
- AMP URL Is Invalid – The AMP has an error that will prevent it from being indexed.
- Rich Result Invalid – The URL has an error with one or more rich result enhancements that will prevent the rich result from showing in the Google search results.
The API has slightly different naming in places to the interface, so we have tried to keep naming inline with the UI. You’re able to get crawl, indexing and validation data for mobile usability, AMP and rich results, such as:
- Presence on Google
- Coverage Status
- Last Crawl Date & Time
- Crawl As
- Crawl Allowed
- Page Fetch
- Indexing Allowed
- User-declared Canonical
- Google-selected Canonical
- Mobile Friendly Validation & Errors
- AMP Validation & Errors
- Rich Result Types, Validation, Errors & Warnings
By matching this data against live Screaming Frog crawl data, you can start to see some interesting insights.
For example, the ‘Indexable URL Not Indexed’ cuts through the clutter and shows any URLs that should be indexed, but aren’t. In the example below, our new case study isn’t indexed yet! If this was an important page, we may want to take action (submitting, improving linking etc).
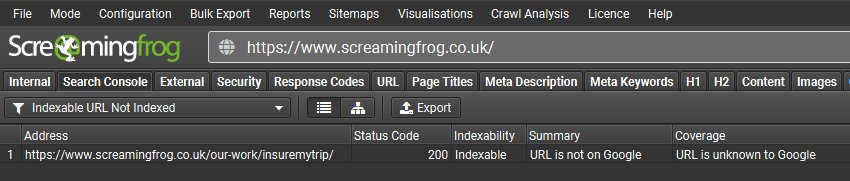
The new ‘User-Declared Canonical Not Selected’ filter is also super helpful to find out where Google is choosing a different canonical to the one you have stipulated.

It’s good to see Google has corrected our own issue in this case, as these paginated SEO Spider tutorial pages should really be self referencing canonicals.
You can also export the Google Rich Result types, errors and warnings via the ‘Bulk Export > URL Inspection > Rich Results’ menu.
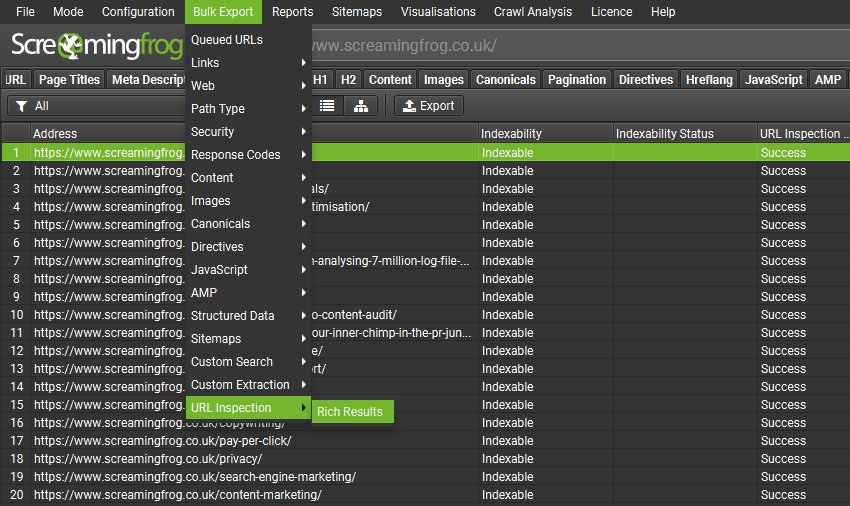
This includes every URL, whether it’s valid, or has errors and warnings, severity, type, name and item issue.
We’re excited to see how users might integrate this data, perhaps using scheduling, the CLI and automated Data Studio crawl reporting.
A big thank you to Daniel Waisberg, John Mueller and the Google Search Console team for helping to make this new API possible and available to all.
2) Other Updates
Version 16.6 also includes a number of smaller updates, security and bug fixes, outlined below.
- Update to log4j 2.17.1 to fix CVE-2021-44832.
- Keyboard shortcut to close crawl on Windows: Use command/ctrl + W to close projects, Remove command/ctrl + W and other shorts cuts for tabs.
- Remove GSC Type Filter ‘All’ and use ‘Web’ as default.
- Add clear button to Scheduling History dialog.
- Word Cloud Visualisation filtering out words incorrectly, it is now language aware.
- Add MISC linktype to Inlink Reports
- Fix PSI Core Web Vitals Assessment inconsistency with Google.
- Fix List Mode failing to read sitemaps with content type and file extension for PHP.
- Fix a stall in JavaScript crawls.
- Fix CSS Path extraction to maintain newlines and leading/trailing spaces.
- Fix regression with Burmese characters not showing on Windows.
- Fix Rendering Failed with certain URLs due to JS popup.
- Fix crash showing pop over in visualisations.
- Fix crash selecting option in Site Structure context menu.
- Fix crash in near duplicates.
- Fix crash copying cells to clipboard in Inlinks table.
- Fix crash in Link Score triggered by not storing canonicals.
- Fix crash in scheduling.
- Fix crash crawling when using AHREFS.
We hope the new update is useful.
Please be aware that this was built and released at pace, so it won’t be perfect. There’s challenges to fit all the data neatly into columns and not all data available from the Inspection API is included yet. With use and user feedback, the way we integrate the data to gain additional insights will be improved as well.
If you spot any issues, or would like to see additional data or reporting from the URL Inspection API – just let us know via support. We already have a few items planned, but wanted to get the basic feature including the most important items out there for users to enjoy quickly. Bells and whistles to follow.
Download version 16.6 Screaming Frog SEO Spider below and let us know what you think in the comments.
Small Update – Version 16.7 Released 2nd March 2022
We have just released a small update to version 16.7 of the SEO Spider. This release is mainly bug fixes and small improvements –
- URL inspection can now be resumed from a saved crawl.
- The automated Screaming Frog Data Studio Crawl Report now has a URL Inspection page.
- Added ‘Days Since Last Crawl’ column for the URL Inspection integration.
- Added URL Inspection data to the lower ‘URL Details’ tab.
- Translations are now available for the URL Inspection integration.
- Fixed a bug moving tabs and filters related to URL Inspection in scheduling.
- Renamed two ‘Search Console’ filters – ‘No Search Console Data’ to ‘No Search Analytics Data’ and ‘Non-Indexable with Search Console Data’ to ‘Non-Indexable with Search Analytics Data’ to be more specific regarding the API used.
- Fix crash loading scheduled tasks.
- Fix crash removing URLs.






Thank you for fulfilling my dreams!
Great way of utilising the URL inspection API! Looking forward to getting stuck in.
This is so useful. Love the filters. Great work as usual.
Wowww!!!!!
Outstanding! Just used this feature and it works as advertised, great work guys and much appreciated.
That was quick! and so useful, thank you
Thanks, Samuel! More to come.
I’m new to screaming frog tool and I’ve done a lot of search to find out if it supports internal links suggestion? I know its possible to see internal and external links, but is there any function to give admin potential keywords and links to add link to?
Добрый день. В россии много пользователей этой чудесной программы. когда будет русская версия?
Thanks for the suggestion. We’d love to support more languages, and it’s on the list!
Once again great job scream frog. I was struggling for a couple of days and now my problem is solved.
Well done guys!! We were expecting this update with craving!! :)
Previously, I was not aware about this tool’s quality features but when I start using it, I really loved it. Thanku so much fo this wonderful tool. Now Screaming Frog is in top in my favourite tools.
Works like a charm, thank you so much for this quick implementation of this Google API. :)
Cheers, Axel!
Thank you soo much for adding this API to your software. It really helpful for me.
Hi,
When I’m trying to connect to Google Search Console via API I get the following error: “You have no credits available for Google Search Console, no requents will be made”
Have anybody else experienced the same error, and any suggestions as to a possible fix in my end,
Hi Michael,
This is the message you’ll receive when you have burned through the 2,000 URLs per property per day quota.
You’ll need to wait for a day, or use a different property.
Cheers.
Dan
Thank you so much ScreamingFrog for helping us do better SEO! You rock! There are already many datastudio templates to copy and paste your Search Console tab, i am goint to test it asap :)
Hi Dan,
thanks for this great feature.
2 questions:
– What can I do when I get (API) errors at some URLs in my crawl? recrawl of the url won´t start API request again
– If I save and reopen my crawl all data of URL inspection API is gone. Is this a bug?
Hi Flo,
No worries, glad you’re enjoying. On your queries –
1) You should be able to right click and ‘respider’. This generally works, but there is a bug in this operation ‘sometimes’. We’ll have this fixed up for release next week (with some other improvements).
2) We don’t know about this one. Please can you send details through to support ([email protected])?
Cheers.
Dan
Hello Screamingfrog team,
just a question regarding the visualization and anchor text.
Would it be possible to have a feature that shows you for a specific anchor text all the internal linking + the linkscore? that would help to identify the volume of internal anchor text or missing opportunities. Thank you. Cheers. Dave
What an update! the implementation was very fast. Thank you Screaming Frog
With 16.7 I’m not able to render JS and as a result cannot store rendered HTML like in previous versions. I tried URLs from a variety of sites and everything times out.
Hi Krissy,
If you contact us via support – https://www.screamingfrog.co.uk/seo-spider/support/
We can help.
Cheers.
Dan
Thanks for the great article. You know if there a limit for crawling pages with the URL inspection tool? I tried to crawl a sitemap.xml. But Screaming Frog could not analyze the indexation status of all pages. I think there is a limit of 2000 pages or does it depend on the crawl budget of a website?
Hi Angela,
Yes, there’s a 2k URL limit. More here – https://www.screamingfrog.co.uk/how-to-automate-the-url-inspection-api/#limit
Cheers.
Dan
Amazing update. Thanks for making ScreamingFrog better and better :).
Hello
I write to you from Spain
I have started using your tool and it is helping me a lot.
But even with the free version I see that it is difficult to take advantage of it for non-professionals
I just started using the paid version of the tool and it’s helping me a lot on advanced SEO. And it’s great having this amazing update to easily determine page status and issues. Now, I don’t have to go through different platforms just to check my entire SEO checklist status.