Screaming Frog SEO Spider Update – Version 6.0
Dan Sharp
Posted 21 July, 2016 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 6.0
I’m excited to announce version 6.0 of the Screaming Frog SEO Spider, codenamed internally as ‘render-Rooney’.
Our team have been busy in development and have some very exciting new features ready to release in the latest update. This includes the following –
1) Rendered Crawling (JavaScript)
There were two things we set out to do at the start of the year. Firstly, understand exactly what the search engines are able to crawl and index. This is why we created the Screaming Frog Log File Analyser, as a crawler will only ever be a simulation of search bot behaviour.
Secondly, we wanted to crawl rendered pages and read the DOM. It’s been known for a long time that Googlebot acts more like a modern day browser, rendering content, crawling and indexing JavaScript and dynamically generated content rather well. The SEO Spider is now able to render and crawl web pages in a similar way.
You can choose whether to crawl the static HTML, obey the old AJAX crawling scheme or fully render web pages, meaning executing and crawling of JavaScript and dynamic content.

Google deprecated their old AJAX crawling scheme and we have seen JavaScript frameworks such as AngularJS (with links or utilising the HTML5 History API) crawled, indexed and ranking like a typical static HTML site. I highly recommend reading Adam Audette’s Googlebot JavaScript testing from last year if you’re not already familiar.
After much research and testing, we integrated the Chromium project library for our rendering engine to emulate Google as closely as possible. Some of you may remember the excellent ‘Googlebot is Chrome‘ post from Joshua G on Mike King’s blog back in 2011, which discusses Googlebot essentially being a headless browser.
The new rendering mode is really powerful, but there are a few things to remember –
- Typically crawling is slower even though it’s still multi-threaded, as the SEO Spider has to wait longer for the content to load and gather all the resources to be able to render a page. Our internal testing suggests Google wait approximately 5 seconds for a page to render, so this is the default AJAX timeout in the SEO Spider. Google may adjust this based upon server response and other signals, so you can configure this to your own requirements if a site is slower to load a page.
- The crawling experience is quite different as it can take time for anything to appear in the UI to start with, then all of a sudden lots of URLs appear together at once. This is due to the SEO Spider waiting for all the resources to be fetched to render a page before the data is displayed.
- To be able to render content properly, resources such as JavaScript and CSS should not be blocked from the SEO Spider. You can see URLs blocked by robots.txt (and the corresponding robots.txt disallow line) under ‘Response Codes > Blocked By Robots.txt’. You should also make sure that you crawl JS, CSS and external resources in the SEO Spider configuration.
It’s also important to note that as the SEO Spider renders content like a browser from your machine, so this can impact analytics and anything else that relies upon JavaScript.
By default the SEO Spider excludes executing of Google Analytics JavaScript tags within its engine, however, if a site is using other analytics solutions or JavaScript that shouldn’t be executed, remember to use the exclude feature.
2) Configurable Columns & Ordering
You’re now able to configure which columns are displayed in each tab of the SEO Spider (by clicking the ‘+’ in the top window pane).

You can also drag and drop the columns into any order and this will be remembered (even after a restart).
To revert back to the default columns and ordering, simply right click on the ‘+’ symbol and click ‘Reset Columns’ or click on ‘Configuration > User Interface > Reset Columns For All Tables’.
3) XML Sitemap & Sitemap Index Crawling
The SEO Spider already allows crawling of XML sitemaps in list mode, by uploading the .xml file (number 8 in the ‘10 features in the SEO Spider you should really know‘ post) which was always a little clunky to have to save it if it was already live (but handy when it wasn’t uploaded!).
So we’ve now introduced the ability to enter a sitemap URL to crawl it (‘List Mode > Download Sitemap’).

Previously if a site had multiple sitemaps, you’d have to upload and crawl them separately as well.
Now if you have a sitemap index file to manage multiple sitemaps, you can enter the sitemap index file URL and the SEO Spider will download all sitemaps and subsequent URLs within them!
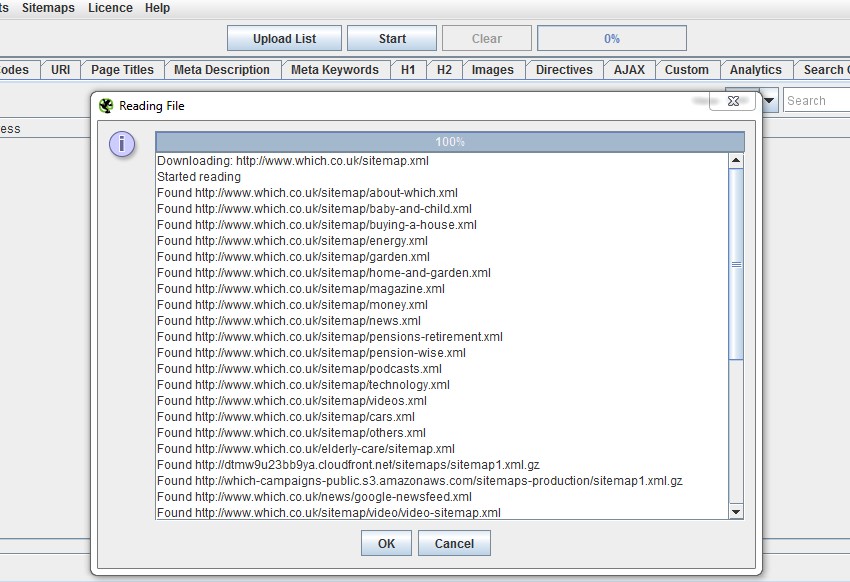
This should help save plenty of time!
4) Improved Custom Extraction – Multiple Values & Functions
We listened to feedback that users often wanted to extract multiple values, without having to use multiple extractors. For example, previously to collect 10 values, you’d need to use 10 extractors and index selectors ([1],[2] etc) with XPath.
We’ve changed this behaviour, so by default, a single extractor will collect all values found and report them via a single extractor for XPath, CSS Path and Regex. If you have 20 hreflang values, you can use a single extractor to collect them all and the SEO Spider will dynamically add additional columns for however many are required. You’ll still have 9 extractors left to play with as well. So a single XPath such as –

Will now collect all values discovered.
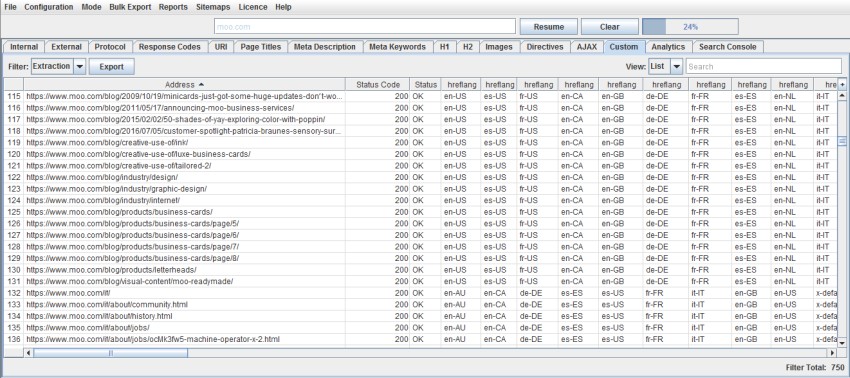
You can still choose to extract just the first instance by using an index selector as well. For example, if you just wanted to collect the first h3 on a page, you could use the following XPath –

Functions can also be used anywhere in XPath, but you can now use it on its own as well via the ‘function value’ dropdown. So if you wanted to count the number of links on a page, you might use the following XPath –

I’d recommend reading our updated guide to web scraping for more information.
5) rel=“next” and rel=“prev” Elements Now Crawled
The SEO Spider can now crawl rel=“next” and rel=“prev” elements whereas previously the tool merely reported them. Now if a URL has not already been discovered, the URL will be added to the queue and the URLs will be crawled if the configuration is enabled (‘Configuration > Spider > Basic Tab > Crawl Next/Prev’).
rel=“next” and rel=“prev” elements are not counted as ‘Inlinks’ (in the lower window tab) as they are not links in a traditional sense. Hence, if a URL does not have any ‘Inlinks’ in the crawl, it might well be due to discovery from a rel=“next” and rel=“prev” or a canonical. We recommend using the ‘Crawl Path Report‘ to show how the page was discovered, which will show the full path.
There’s also a new ‘respect next/prev’ configuration option (under ‘Configuration > Spider > Advanced tab’) which will hide any URLs with a ‘prev’ element, so they are not considered as duplicates of the first page in the series.
6) Updated SERP Snippet Emulator
Earlier this year in May Google increased the column width of the organic SERPs from 512px to 600px on desktop, which means titles and description snippets are longer. Google displays and truncates SERP snippets based on characters’ pixel width rather than number of characters, which can make it challenging to optimise.
Our previous research showed Google used to truncate page titles at around 482px on desktop. With the change, we have updated our research and logic in the SERP snippet emulator to match Google’s new truncation point before an ellipses (…), which for page titles on desktop is around 570px.
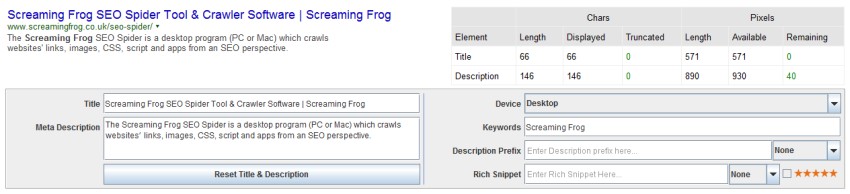
Our research shows that while the space for descriptions has also increased they are still being truncated far earlier at a similar point to the older 512px width SERP. The SERP snippet emulator will only bold keywords within the snippet description, not in the title, in the same way as the Google SERPs.
Please note – You may occasionally see our SERP snippet emulator be a word out in either direction compared to what you see in the Google SERP. There will always be some pixel differences, which mean that the pixel boundary might not be in the exact same spot that Google calculate 100% of the time.
We are still seeing Google play to different rules at times as well, where some snippets have a longer pixel cut off point, particularly for descriptions! The SERP snippet emulator is therefore not always exact, but a good rule of thumb.
Other Updates
We have also included some other smaller updates and bug fixes in version 6.0 of the Screaming Frog SEO Spider, which include the following –
- A new ‘Text Ratio’ column has been introduced in the internal tab which calculates the text to HTML ratio.
- Google updated their Search Analytics API, so the SEO Spider can now retrieve more than 5k rows of data from Search Console.
- There’s a new ‘search query filter’ for Search Console, which allows users to include or exclude keywords (under ‘Configuration > API Access > Google Search Console > Dimension tab’). This should be useful for excluding brand queries for example.
- There’s a new configuration to extract images from the IMG srcset attribute under ‘Configuration > Advanced’.
- The new Googlebot smartphone user-agent has been included.
- Updated our support for relative base tags.
- Removed the blank line at the start of Excel exports.
- Fixed a bug with word count which could make it less accurate.
- Fixed a bug with GSC CTR numbers.
I think that’s just about everything! As always, please do let us know if you have any problems or spot any bugs at all.
Thanks to everyone for all the support and continued feedback. Apologies for any features we couldn’t include in this update, we are already working on the next set of updates and there’s plenty more to come!
Now go and download version 6.0 of the SEO Spider!
Small Update – Version 6.1 Released 3rd August 2016
We have just released a small update to version 6.1 of the SEO Spider. This release includes –
- Java 8 update 66 is now required on all platforms, as this update fixes several bugs in Java.
- Reduced certificate verification to be more tolerant when crawling HTTPS sites.
- Fixed a crash when using the date range configuration for Google Analytics integration.
- Fixed an issue with the lower window pane obscuring the main data window for some users.
- Fixed a crash in custom extraction.
- Fixed an issue in JavaScript rendering mode with the JS navigator.userAgent not being set correctly, causing sites performing UA profiling in JavaScript to miss fire.
- Fixed crash when starting a crawl without a selection in the overview window.
- Fixed an issue with being too strict on parsing title tags. Google seem to use them regardless of valid HTML head elements.
- Fixed a crash for Windows XP/Vista/Server 2003/Linux 32 bit users, which are not supported for rendering mode.
Update – Version 6.2 Released 16th August 2016
We have just released a small update to version 6.2 of the SEO Spider. This release includes –
- Fix for several crashes.
- Fix for the broken unavailable_after in the directives filter.
- Fix double clicking .seospider files on OS X that didn’t load the crawl file.
- Multiple extractions instances are now grouped together.
- Export now respects column order and visibility preferences.






Wow, big changes. So amazing to see all these improvements to an already superb tool.
Gotta read up on JS crawling now, thanks for the reminder.
Keep up the good work!
Sebastian
(Btw, love the frog at the footer of your site)
Looks nice! :)
Nice one guys! Improved custom extraction sounds great. Really looking forward to giving this a test drive :)
Thanks for the updates
Thanks for this awesome update! I loved the download sitemaps feature.
Cheers mate!
Great! But please add the feature of keeping order and duplicate URLs at exporting, That would make the rutine easier for Excel-clumsy people like me :D
Hey Charlie,
You’ll be pleased to hear I just moved this into the priority queue for our next release :-)
Cheers.
Dan
Awesome! :D
wow, these are really big ones….appreciate it
How can an SEO not have Screaming Frog? Enough said ;)
Hey Dan,
as always a superb update. I especially like how you guys listen to the feedback of your users and customers. I see I should get far more into the custom extensions as they seem to be extremely powerful.
Thanks a lot. See you on Twitter. :-)
Best,
Sebastian
Hi Sebastian,
Thanks for the kind comments, awesome to hear you like the extraction update!
Chat soon about the football I am sure ;-)
Dan
Hi. Can you also add a custom collect of selected data. Example – what if i want go get Title+H1… or desc/keywords of 1 million pages? Now in will be file 10 Gig and i need very powerfull PC. But primitive utils that parse only title can do it better that frog.
I think it will be useful feature.
Hey Pavel,
Thanks for your feedback. Definitely something we have discussed previously.
What uses up most memory is link relationships though, a site may have 1m unique pages, but if you add up the unique link instances, it’s normally a huge number more.
We have some plans to improve in this area though :-)
Thanks again,
Dan
Thanks for update.
Could you add checkbox – save link relationships – on/off.
For big sites its big problem – to save/open giant files.
Very slow.
Fast parse and save only H1-Title or meta tags without link relationships as described Pavel above – very common task.
Hi Dan,
Thanks for the updates ! I love sceamingfrog. Great Free tool and even better when u buy it!
Thanks for this awesome update! Screaming Frog Rules! I can not imagine working without it.
Thanks for the updates
This was an update that I was really looking forward to. Sitemap feature is an excellent one. Also the update on SERP is much accurate than before. Can you consider calculating the back-links feature and Google PR ranking in your next release.
Love the new additions, thanks for updating
Hi Dan,
thanks for the awesome update. I have a small wish for one of the next releases: Could you consider to add all data variations to the configurable colums menu?
It would be awesome to control the colums for all possible data like H1-2 or H1-2 length, even if the colums are empty.
Thanks a lot!
Tim.
Hey Tim,
Thanks for your feedback.
We grouped them together as elements, as some of it is dynamic. I’ll bring this up for discussion, as I can see why this would be useful.
Cheers.
Dan
Hi Dan,
I second Tim’s point. This feature would be very useful. We export ScreamingFrog data to use as an input for various custom reporting at our agency. Having predictability of the columns the SF export report has would be very helpful!
Thank you,
Austin
You just made an indispensable tool even better. Brilliant. Thanks.
Guys, what an amazing update! Thanks for making the SEO Spider more and more awesome. I am especially excited about the Javascript crawling and the improved custom extraction.
“Fixed a bug with GSC CTR numbers.” Any more info on that bug?
One feature that I’m really missing: Saving multiple configs. This would be so helpful for crawling websites periodically, especially when using custom extractions.
Hey Jan,
The exact Github description we gave it was –
We show this to 2dp, but as its a percentage, we should show it to 4dp so it works well when exported, then it’s actually a percentage to 2dp, rather than a rounded percentage.
eg
7.54 we show as 0.08.
Lets show it as 0.0754.
So, essentially when users were exporting and converting the data, it would often mess up. So we’ve amended it :-)
Cheers.
Dan
Hi Dan,
OK, makes sense! Thanks for clearing it up. :)
– Jan
Great updates all around! My recommendation for the next version? UI Polish – I think it will help you selling.
Thanks Thomas, we are working on incorporating the framework required for multi language versions :-)
There are many improvements in this update, thank you very much!
Excellent update! Small features such as the XML (and Index XML!) are welcome for sitemap validation, ever found myself lost in the end between dozens of files named sitemap.xml ;-)
Thanks Samuel! I’ve been there too, downloading sitemap by sitemap, glad this has helped ;-)
This is probably the greatest thing that has happened all year. Thank you!
Cheers Steffan. It’s been a pretty crappy year, lets hope things get better soon :-)
Exciting additions. I’m looking forward to testing out all the new features.
Rendered Crawling (JavaScript)
Thank you! Perfect timing
Great update. Especially like Configurable Columns & Ordering – though it doesn’t seem like it’s possible to export with these options? I am getting raw data like before.
Thanks Ludvig! That didn’t quite make our release, but will be in the next one!
Cheers.
Dan
Great update, thanks! We’re using SF for years now and it belongs to the essential tools for any SEO consultant. Looking forward to test all new features.
I am so excited about this release. Thank you so much!
Screaming frog rocks, best free seo tool
Great update! Thanks.
Update excellent and really recommended
Thanks for great update. As we have evolved our site from traditional client side site to a AngularJS, we have had issue crawling, previously only 42 pages where found on our site http://www.paf.com but now thanks to the new JS rendering nearly 200 pages are reported. Big thanks!
One question thought, we have multi-language site using locale parameter. With old rendering system and cookie enabled the crawler managed to keep locale-parameter during crawling but we are seeing issue now with new JS rendering system and wonder if you are aware of this? For example we are getting meta titles and content from English site when crawling our Swedish site at https://www.paf.com?locale=sv_SE
Thanks!
Just a note, the language param value is stored in a cookie. For some reason the cookie is not stored/read by Screaming Frog when javascript rendering is enabled.
Thanks Jani and Mikael.
I understand you’ve sent through a support query on this one and you’re removing the UK IP filter for us to investigate.
We will be in touch anyway.
Cheers.
Dan
One of my favorite SEO tool. and best for analysis and i love to use sitemap feature.
Thank you heaps for consistently listening to client feedback, Dan! Screaming Frog has always and still continues to play a huge role in our SEO processes.
Thank you for upgrade. Sooo nice!
Hi, would be possible to change settings of crawling sitemap to add duplicate URLS? Because now it crawl each URL exactly once and it seems that there are any duplicate URLs. We have to use other software to identify, which URLs are duplicated and what is the number of all URLs in sitemap (including duplicated URLs).
This tool has been a life saver for developing Crowd Save. All errors/ issues trapped in one handy tool. 10/10
Hi,
I was just wondering if there is any trial or free version available as I would need to study the format before implementation.
Hi Riya,
Thanks for the comment.
Yes, the SEO Spider is free to download and use for crawling up to 500 URLs – https://www.screamingfrog.co.uk/seo-spider/
The advanced configuration and saving of crawls are only available in the paid licenced version, though.
Cheers.
Dan
Good day,
Thank you for sharing guyssss! It helps a lot I need this info, REALLY! This article is very helpful to a student like me. I’m a beginner in SEO.
Thanks again!
Dy
These are nice updates, i have to take advantages of these so that i can make good use of Screaming frog tool. Screaming Frog is really wonderful tool :)
Love the new features! Screaming Frog is one of our go-to tools that we use in analyzing websites. A must for SEO
I need to open a crawl from 2016 – crazy, I know. My current version of SF can’t do it.
Are there historical download files we can get at?
TIA,
Linda
Hey Linda,
You’re commenting on a post from 2016, which I usually just ‘spam’ :-)
I’d recommend emailing support and we can see what we can do – https://www.screamingfrog.co.uk/seo-spider/support/
Cheers
Dan