Screaming Frog SEO Spider Update – Version 7.0
Dan Sharp
Posted 12 December, 2016 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 7.0
I’m delighted to announce Screaming Frog SEO Spider version 7.0, codenamed internally as ‘Spiderman’.
Since the release of rendered crawling in version 6.0, our development team have been busy working on more new and exciting features. Let’s take a look at what’s new in 7.0.
1) ‘Fetch & Render’ (Rendered Screen Shots)
You can now view the rendered page the SEO Spider crawled in the new ‘Rendered Page’ tab which dynamically appears at the bottom of the user interface when crawling in JavaScript rendering mode. This populates the lower window pane when selecting URLs in the top window.

This feature is enabled by default when using the new JavaScript rendering functionality and allows you to set the AJAX timeout and viewport size to view and test various scenarios. With Google’s much discussed mobile first index, this allows you to set the user-agent and viewport as Googlebot Smartphone and see exactly how every page renders on mobile.

Viewing the rendered page is vital when analysing what a modern search bot is able to see and is particularly useful when performing a review in staging, where you can’t rely on Google’s own Fetch & Render in Search Console.
2) Blocked Resources
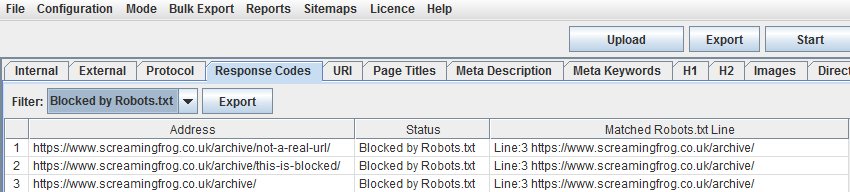
The SEO Spider now reports on blocked resources, which can be seen individually for each page within the ‘Rendered Page’ tab, adjacent to the rendered screen shots.

The blocked resources can also be seen under ‘Response Codes > Blocked Resource’ tab and filter. The pages this impacts and the individual blocked resources can also be exported in bulk via the ‘Bulk Export > Response Codes > Blocked Resource Inlinks’ report.

3) Custom robots.txt
You can download, edit and test a site’s robots.txt using the new custom robots.txt feature under ‘Configuration > robots.txt > Custom’. The new feature allows you to add multiple robots.txt at subdomain level, test directives in the SEO Spider and view URLs which are blocked or allowed.
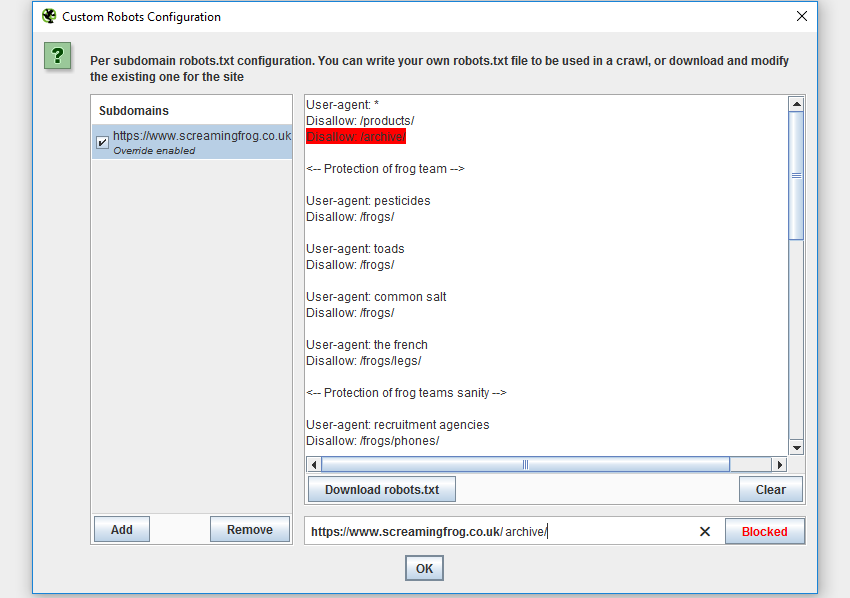
During a crawl you can filter blocked URLs based upon the custom robots.txt (‘Response Codes > Blocked by robots.txt’) and see the matches robots.txt directive line.
Custom robots.txt is a useful alternative if you’re uncomfortable using the regex exclude feature, or if you’d just prefer to use robots.txt directives to control a crawl.
The custom robots.txt uses the selected user-agent in the configuration and works well with the new fetch and render feature, where you can test how a web page might render with blocked resources.
We considered including a check for a double UTF-8 byte order mark (BOM), which can be a problem for Google. According to the spec, it invalidates the line – however, this will generally only ever be due to user error. We don’t have any problem parsing it and believe Google should really update their behaviour to make up for potential mistakes.
Please note – The changes you make to the robots.txt within the SEO Spider, do not impact your live robots.txt uploaded to your server. You can read more about testing robots.txt in our user guide.
4) hreflang Attributes
First of all, apologies, this one has been a long time coming. The SEO Spider now extracts, crawls and reports on hreflang attributes delivered by HTML link element and HTTP Header. They are also extracted from Sitemaps when crawled in list mode.
While users have historically used custom extraction to collect hreflang, by default these can now be viewed under the ‘hreflang’ tab, with filters for common issues.
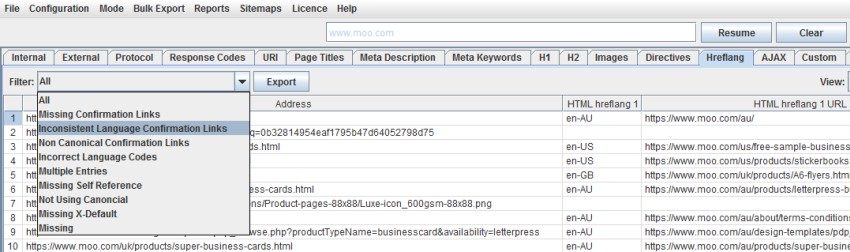
While hreflang is a fairly simple concept, there’s plenty of issues that can be encountered in the implementation. We believe this is the most comprehensive auditing for hreflang currently available anywhere and includes checks for missing confirmation links, inconsistent languages, incorrect language/regional codes, non-canonical confirmation links, multiple entries, missing self-reference, not using the canonical, missing the x-default, and missing hreflang completely.
Additionally, there are four new hreflang reports available to allow data to be exported in bulk (under the ‘reports’ top level menu) –
- Errors – This report shows any hreflang attributes which are not a 200 response (no response, blocked by robots.txt, 3XX, 4XX or 5XX responses) or are unlinked on the site.
- Missing Confirmation Links – This report shows the page missing a confirmation link, and which page requires it.
- Inconsistent Language Confirmation Links – This report shows confirmation pages which use different language codes to the same page.
- Non Canonical Confirmation Links – This report shows the confirmation links which are to non canonical URLs.
This feature can be fairly resource-intensive on large sites, so extraction and crawling are entirely configurable under ‘Configuration > Spider’.
5) rel=”next” and rel=”prev” Errors
This report highlights errors and issues with rel=”next” and rel=”prev” attributes, which are of course used to indicate paginated content.
The report will show any rel=”next” and rel=”prev” URLs which have a no response, blocked by robots.txt, 3XX redirect, 4XX, or 5XX error (anything other than a 200 ‘OK’ response).
This report also provides data on any URLs which are discovered only via a rel=”next” and rel=”prev” attribute and are not linked-to from the site (in the ‘unlinked’ column when ‘true’).
6) Maintain List Order Export
One of our most requested features has been the ability to maintain the order of URLs when uploaded in list mode, so users can then export the data in the same order and easily match it up against the original data.
Unfortunately, it’s not as simple as keeping the order within the interface, as the SEO Spider performs some normalisation under the covers and removes duplicates, which meant it made more sense to produce a way to export data in the original order.
Hence, we have introduced a new ‘export’ button which appears next to the ‘upload’ and ‘start’ buttons at the top of the user interface (when in list mode) which produces an export with data in the same order as it was uploaded.
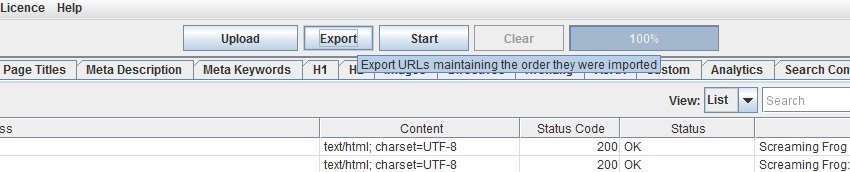
The data in the export will be in the same order and include all of the exact URLs in the original upload, including duplicates or any fix-ups performed.
7) Web Forms Authentication (Crawl Behind A Login)
The SEO Spider has supported basic and digest standards-based authentication for some time, which enables users to crawl staging and development sites. However, there are other web forms and areas which require you to log in with cookies which have been inaccessible, until now.
We have introduced a new ‘authentication’ configuration (under ‘Configuration > Authentication), which allows users to log in to any web form within the SEO Spider Chromium browser, and then crawl it.
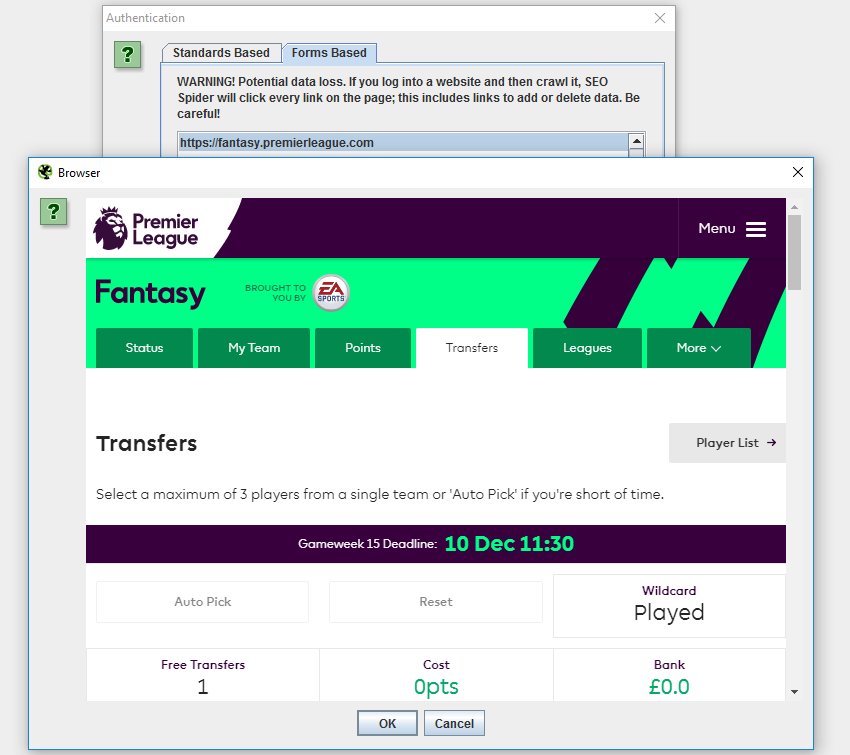
This means virtually all password-protected areas, intranets and anything which requires a web form login can now be crawled.
Please note – This feature is extremely powerful and often areas behind logins will contain links to actions which a user doesn’t want to press (for example ‘delete’). The SEO Spider will obviously crawl every link, so please use responsibly, and not on your precious fantasy football team. With great power comes great responsibility(!).
You can block the SEO Spider from crawling links or areas by using the exclude or custom robots.txt.
Other Updates
We have also included some other smaller updates and bug fixes in version 7.0 of the Screaming Frog SEO Spider, which include the following –
- All images now appear under the ‘Images’ tab. Previously the SEO Spider would only show ‘internal’ images from the same subdomain under the ‘images’ tab. All other images would appear under the ‘external’ tab. We’ve changed this behaviour as it was outdated, so now all images appear under ‘images’ regardless.
- The URL rewriting ‘remove parameters’ input is now a blank field (similar to ‘include‘ and ‘exclude‘ configurations), which allows users to bulk upload parameters one per line, rather than manually inputting and entering each separate parameter.
- The SEO Spider will now find the page title element anywhere in the HTML (not just the HEAD), like Googlebot. Not that we recommend having it anywhere else!
- Introduced tri-state row sorting, allowing users to clear a sort and revert back to crawl order.
- The maximum XML sitemap size has been increased to 50MB from 10MB, in line with Sitemaps.org updated protocol.
- Fixed a crash in custom extraction!
- Fixed a crash when using the date range Google Analytics configuration.
- Fixed exports ignoring column order and visibility.
- Fixed cookies set via JavaScript not working in rendered mode.
- Fixed issue where SERP title and description widths were different for master view and SERP Snippet table on Windows for Thai language.
We hope you like the update! Please do let us know if you experience any problems, or discover any bugs at all.
Thanks to everyone as usual for all the feedback and suggestions for improving the Screaming Frog SEO Spider.
Now go and download version 7.0 of the SEO Spider!
Small Update – Version 7.1 Released 15th December 2016
We have just released a small update to version 7.1 of the SEO Spider. This release includes –
- Fix crash on startup for users of OSX 10.8 and below.
- Show decoded versions of hreflang URLs in the UI.
- Fix issue with connecting to a SSLv3 only web servers.
- Handle standards based authentication when performing forms based authentication.
- Handle popup windows when peforming forms based authenticaion.
- Fix typo in hreflang filter.
Small Update – Version 7.2 Released 30th January 2017
We have just released a small update to version 7.2 of the SEO Spider. This release includes –
- Prevent printing when using JavaScript rendering.
- Prevent playing of audio when using JavaScript rendering.
- Basic High DPI support for Linux (Configuration > User Interface > ‘Enable GTK Windows Look and Feel’).
- Fix issue with SERP panel truncating.
- Fix crash in hreflang processing.
- Fix unable to start on 32-bit Linux.
- Fix crash in tree view when moving columns.
- Fix hreflang ‘missing confirmation links’ filter not checking external URLs.
- Fix status code of ‘illegal cookie’.
- Fix crash when going to ‘Configuration > API Access > Google Analytics’.
- Fix crash when sorting on the redirect column.
- Fix crash in custom extraction.
- Fix ‘Enable Rendered Page Screen Shots’ setting not saving.
- Fix ‘Inconsistent Language Confirmation Links’ report, reporting the wrong ‘Actual Language’.
- Fix: NullPointerException when saving a crawl.






Number 7 is incredible. Can’t wait to try that out :)
Thanks for the update, Dan!
Cheers Glen, much appreciated!
Dan
Nice, good work! Now I only wait for the schedule feature with export function
This makes me extremely happy. Amazing work Dan & team, keep it up.
Oh my. This is a very, very, very interesting update to the frog. Awesome sauce. Now let’s give it a go.
This update is absolutely awesome! Thank you so much. The Fetch & Render helps a lot when looking for bad mobile pages and the hreflang saves me tons of time!
Absolutely amazing release. What a pleasant surprise to begin my workday with an excellent update to SF.
I am very appreciative of your hreflang extraction upgrade! And the custom robots.txt! Just fantastic work, Dan and team. Time and time again you astound me with your upgrades, willingness to hear user feedback and integrate our ideas into future releases. You make my work so much more enjoyable and easy. <3
Hi Nicholas,
Thanks for the awesome comment, really delighted to hear the release helps out! We’ve had so much amazing user feedback over the past 6 years, we’d be insane not to listen.
You know where we are with any further feedback anyway. More to come, too!
Cheers.
Dan
This update broke my activation. My licence is no longer working.
Hey Ben,
That’s not really possible, so I recommend having a read of the reasons why a licence might be invalid –
https://www.screamingfrog.co.uk/seo-spider/faq/#why-is-my-licence-key-saying-its-invalid
You can contact support https://www.screamingfrog.co.uk/seo-spider/support/ if you’re still having issues.
Thanks,
Dan
Screaming Frog 7.0 improvements are just great!
Many thanks for the update! :D
Wow. These updates are great!
And even with the price increase, Screaming Frog is still easily the best value SEO tool around.
Only issue I have at the moment is with the way Screaming Frog displays on my laptop’s QHD display – everything is microscopic! I can change the screen resolution to make things readable but most programs automatically adapt for QHD displays. Will there be a fix for this anytime soon?
I also have an idea for a future release, but I’ll send an email about that :)
Hey David,
Thanks for your comments, awesome to hear.
Actually, we do have a fix for the super small fonts on high res monitors – https://www.screamingfrog.co.uk/seo-spider/faq/#why-are-the-fonts-so-small-on-my-high-res-display
Hopefully that helps! Love to hear any ideas, please do pop through to us at [email protected] anytime.
Cheers.
Dan
‘Crawl Behind A Login’ is absolutely great!!
Congrats! This is amazing! Great work!
Hi, cool news, in my opinion the frog is one of the best tools to analyze, thanks for the great product and good luck to you!!!
Major step up, Dan. Very impressed with the ability to now fetch and render all within the one screen. hreflang will also prove to be really useful for us.
Fetch and render in Screaming Frog! Yay! Keep up the amazing work!
Great work! Blocked Resources and Maintain List Order Export – that’s I’ve been waiting for.
What is “Missing Confirmation Links” I try to google it but still got no idea
Thanks in advance for answer
Hey Adam,
Google describe it in their hreflang guidelines here – https://support.google.com/webmasters/answer/189077?hl=en
“Missing confirmation links: If page A links to page B, page B must link back to page A. If this is not the case for all pages that use hreflang annotations, those annotations may be ignored or not interpreted correctly.”
Hope that helps.
Dan
Thanks! Now i see what seems to be issue – for ‘SC’ “/développeurs/” is not the same as ‘/d%C3%A9veloppeurs/”
Great update!
Update: Now I see that that wasnt the problem, Checked on ‘home pages’ ( links: “/” “/de/” etc ), can send you example na prv
Hey Adam,
Are you able to pop through an example to us via [email protected]?
We’ve just fixed an encoding bug in hreflang, which might be related.
Cheers.
Dan
That’s a nice early Christmas present! :)
You could top it by telling me if it is somehow possible to have Screaming Frog log into Google My Business. Specifically, I’d like to custom extract some data from the Google My Business Insights (via List Mode). Sadly, Google redirects the crawler (even after changing the identification) and crawling the list is then not possible.
This is such an awesome update, ‘Crawl Behind A Login’ is absolutely perfect!
Hi,
Your tool works great to find broken links & duplicate pages. It helps to find out several bugs & issues in website!
This is a really great update – ‘Web Forms Authentication’ is purely magic!
Hi Dan, and thanks for an awesome product and customer service.
Seeing as Google offers websites to implement Hreflang tagging in one of two ways (HTML or in Sitemap.xml), it would be an awesome future release feature (if possible) to be able to enter multiple market/language specific sitemap.xml-files into Screaming Frog and have it validate the “handshakes” between those sitemap-files. This is a really tedious task to perform manually and one that would be perfect for SF. Multiple CMS’, such as Magento for instance, has the ability to generate separate storeview sitemap-files, only listing that perticular storeview’s URLs and it’s own Hreflang-references – so to validate only one file won’t feedback any “handshakes” even if they do exist.
Anyway, thanks for your awesome work – keep it up!
/Staffan R.
Hey Staffan,
Love the idea and the feedback.
We do have full hreflang sitemap support on our ‘todo’ list and I have just added a note to our queue about your suggestion.
Thanks again,
Dan
The tool is awesome and superb. Now able to fetch and render simultaneously!
Hi,
You mentioned the improvements on the hreflang elements. I remember asking one of your team whether a hreflang .xml sitemap creation feature would be in future versions and they confirmed it’s in the roadmap.
Just wondered if this is still the case?
Thanks
Lloyd
Hi Lloyd,
Improved XML Sitemap hreflang auditing, and generation are both on the roadmap.
I can’t give you any dates on release, but they are in the prioritised list which is based on user feedback like this.
Thanks for mentioning again!
Cheers.
Dan
Thanks for the update Dan.
There is still no comprehensive hreflang XML sitemap generation tool on the market, so this would definitely put Screaming Frog in an even stronger position.
Whilst there is still a debate whether using hreflang XML sitemaps are as effective as having the hreflang code inline on the specified pages, hopefully Google will continue to improve how well they interpret hreflang XML sitemaps as they are often the lower maintenance option for hreflang management.
Thanks again
Lloyd
Hi Lloyd.
Appreciate the feedback, hreflang in XML sitemaps is a big pain point it seems at the moment.
We will do our best to help!
Cheers.
Dan
Very nice update, packed with great new features and improvements. Keep up the awesome work guys!
Feature 6 and 7 are incredible. Export in the same order will be a huge time saver when I recrawl on a working document where I also end up forgetting that last URL and adding it to the crawl and then messing with Excel in my custom report , no more! Feature #7 would be our secret weapon for all the SEOs doing QA, let’s evangelize the tool for QA people too! :-)
Cheers to a *great* update!
Hi Samuel,
Awesome to hear! We had SO many requests for the maintain list order feature. More than JavaScript crawling etc, the ‘little things’ can make a big difference on the day to day stuff we do.
We put together a little guide on the web form login, hope you find it useful! – https://www.screamingfrog.co.uk/crawling-password-protected-websites/
Cheers.
Dan
Please implement schedule feature with export function, and it will be completed tool
This is currently lined up for our next release. :-)
The tool is not loading any more. Just stopped this morning and I cannot get it working.
Hi Olesia,
Sorry to hear you’re experiencing problems. Would you be able to pop through the details to us at support? https://www.screamingfrog.co.uk/seo-spider/support/
It would be useful to know exactly what happens and your OS.
Cheers.
Dan
Solved by reinstalling myself, Thus, chose not to create the ticket. The problem has never returned since then :)
Great update, I’m looking forward to trying out these new features. Thanks for all the great work you are doing, this tool is amazing!
I finally have a way to win my Fantasy league, thank you
LOL :-)
Great update, thanks!
Only just got started with this tool, but it’s fantastic! Can’t believe I been missing this until now.
Awesome SEO tool, and this update is well awaited. Some really neat features here guys. Cheers.
Hi there! my tools is keep on crashing, any idea what would be the caused? I already uninstalled and install.
Hi WAM,
Please just contact us via support with details on your OS and when you experience the crash please (logs files always useful too, under ‘help > debug > save logs’) – https://www.screamingfrog.co.uk/seo-spider/support/
Cheers.
Dan
Great news. thanks for keeping us updated
The last update looked really good, I admit that I haven’t fulfill the full potential of this tool yet but I can tell you that it is the tool I use the most out of all of the tools I use to spec my site. I will definitely use the Hreflang feature as I am about implement several languages. Thanks for the good work you are putting into this. Simply Amazing.
Excellent work as always and really useful fixes (especially crashes in extractions) :) I also have to admit (as the user above) that i’m not using the frog on full power, but i count on the tool more and more every single day.
The new update is working well, great work. I was having random SC crashes 20 – 30 mins into the crawl previous on one of the sites I crawl weekly. Running fine since installing 7.2.
Thanks
Great update, thanks!
Awesome update! Screaming Frog is a great SEO tool. Highly recommended!
Version 7 looks awesome.
Great update. Thanks you guys, really appreciate all the great work you are doing.
What I can say.. excellent work as always. High 5!
De todas las que he probado por ahora es la más fiable
Man you are awesome!!
Very much looking forward to version 8, great work on version 7.
This software is fantastic, I wouldn’t do without it! A+++
Awesome tool screamingfrog, going to recommend to everyone. Really like the look of the updates.
Hi. Can you please add export urls multiple sitemap index right after loading?
Example – 300 sitemaps * 50K urls – SF can download it, but maybe nou enought memory to parse and crash. But anyway i want to save list of this 1.5M urls and to divide into several pieces.
Nice program, this will go well with the other SEO apps we use. What I find particularly pleasing is the high speed parsing, finding links and problems.
Great update. Ps. Would have been nice if one could circumvent blocked content.
Thanks, Andreas!
You can do that already, by ignoring robots.txt, or using the new custom robots.txt feature above.
Cheers.
Dan
Hi Dan, The “rel=next/prev error report” feature is a gem. Trying the free version now and exploring the functionalities. I am definitely going to purchase the full version in a few days.
Please can you add feature:
In mode list or sitemap.xml show what urls is blocked in robots.txt first (Process them first. Now blocked urls are processed in the general order).
Great update! Well done as always!
I do everything on mobile, including managing my blog so I would appreciate if I see such great tool on mobile interface.
Weldone for the great work you are doing.
awesome upgrade! Super fast and accurate. everyone should have.
Great update. Screamingfrog is a awesome tool!
Great update. Thanks you guys, really appreciate all the great work you are doing.
Great update. Screamingfrog is a awesome tool!
The best SEO tool ever! It was the first tool I bought when I became freelance since then I use it on daily basis! The new UI made it so nice and welcomy :)
If ones being scanned by this “Screaming Frog SEO Spider/6.2”, how does one determine the source IP doing the scanning?
Hey Gene,
You can look in your logs :-)
Thanks,
Dan
Once again very nice stuff, beautifully written. Thanks for sharing. I have got a lot of help from your articles. Thanks alot.
This tool is incredible :) For me the best crawler on the market :)
Hi Dan,
Great article!
I’m very interested in the hreflang attributes as I’m running an international site.
Do you have any examples with sites that have aced hreflang tags and confirmation links?
I would be a great help:-)
Thanks!
Magnificent tool for all SEO’s, especially if you need to create technical site audit. With Screaming Frog work with 404, crawl budget etc. is very easy :)
I’ve been using Screamingfrog paid version for some time and I really like how much time it saves me… I would say it gives much more comparing the money I pay for it – a lot of useful functionalities!
I am using screaming frog from couple of years, I’ve tried some other softwares, still Screaming Frog is my choice number 1!
Great article! Thank you!