Using Screaming Frog to Improve Programmatic SEO Content
Jessyca Frederick
Posted 22 June, 2023 by Jessyca Frederick in SEO
Using Screaming Frog to Improve Programmatic SEO Content
All anyone wants to talk about in SEO these days is AI, ChatGPT, and Generative Search. For marketers, the utility of these disruptive tools all rely on the same premise: I can do 100x or a 1000x more than I could when it was just me.
Years of programmatic content successes and failures tell us that you shouldn’t just run full speed ahead without considering whether all of that automatically-generated content is a good idea. There are pitfalls to letting the computers do their thing — not just the well-known hallucinations common to Large Language Models (LLM), but also that these tools which lack context and understanding can create problems.
This guide can’t tell you if using these tools to create massive amounts of content is a good idea for your website, but it can help you assess the quality of campaigns you have already launched, as well as how to check new campaigns before they launch.
This article is a guest contribution from Jessyca Frederick.
What is Programmatic SEO?
As with all things SEO, it depends. In this case it mostly depends on who you ask (recently discussed in an enlightening podcast from Majestic SEO titled “Programmatic SEO”).
For most of us, Programmatic SEO is the practice of using code to combine content with the purpose of scaling long-tail content, and hopefully traffic, in a cost-effective way.
Easy to understand examples include:
- The Best 10 Sushi Bars near Downtown Boston at Yelp where they’ve combined their restaurant ratings with the type of food they serve and their location.
- Things to Do in Chicago with Kids at TripAdvisor where they’ve combined their experience ratings, data about kid-friendly activities, and their location.
- 2023 Virginia conforming and FHA loan limits by county at Bankrate is an example of the super long tail which loads a unique page for FHA data for this year, for each state
What Can Go Wrong With Programmatic Content?
There are so many things that can go wrong when you rely on code to create pages for you. The root causes are the same: your code lacks the context it needs to know if it should create a particular page of content at a particular URL and there are too many pages to check manually for quality. Here are four common issues to consider.
Code Errors
Perhaps at a fundamental level, even before we think about content quality at the page level, we need to be concerned with generating actual errors. These errors show up in two common ways: PHP errors printed to the screen and asset-related errors printed to the browser’s developer console (missing resources, JavaScript errors, Content Security Policy issues, etc.).
In many environments error messages are suppressed so that users don’t have a bad experience and the search engines don’t see your mistakes as easily. Even still, things like Soft 404s and 50x errors are common for many websites, and especially so for programmatically-generated pages.
How to Detect What’s Missing
One of life’s great truths is that you can’t prove something doesn’t exist. Likewise, it’s quite difficult to use a crawler to find things that don’t exist (in some places). Related to finding printed errors is the need to detect errors in the form of content that didn’t load but should have.
Imagine a scenario where you have some spectacular script running on your server which goes out and builds unique content based on your data, and then stores it somewhere (like your database). Your script is written in such a way that it skips writing to the database when it can’t build some piece of content (incomplete records, missing records, etc.). Then your programmatic template tries to load your unique content and it can’t find it. Most likely you direct the template to write nothing so as not to alert the user to the missing data.
Except how would you crawl for that? You can’t. Unless you use a super simple trick. In your code, either in the original script or in the template (in your staging or local environment), don’t skip failed/blank content snippets. Instead, use a unique dummy phrase which you can easily search for as the default value. Something as simple as “Lorem ipsum” will do.
Then, configure the SEO Spider to search for “Lorem ipsum” and, voila, you now know every piece of content that failed to build or load.
Thin Content
Thin content lacks substance and fails to answer a query that might have led a user to the page in the first place. One kind of thin content is a “stub page” where high-quality content is expected to live someday but hasn’t been produced yet.
Thin content is very common in ecommerce. Typically it presents itself as a category page where sometimes there is inventory and sometimes there isn’t.
For an informational site which builds content clusters to attain topical authority, this might be a future support page linked from a pillar page. Very often this is to demonstrate that a site knows a thing exists, but that they don’t have anything to say about it yet. Maybe even as a test to see if there’s any potential traffic for the keyword.
It’s also not uncommon for thin content to be a problem on affiliate websites which might list a product on their site but only include the information provided in the merchant’s datafeed — widely available to thousands of other websites — without adding any new information to help a consumer understand why they should or shouldn’t buy it.
Duplicate Content
Duplicate content is a term that strikes fear into the hearts of fledgling SEOs and seasoned experts alike. Aside from possible consideration as spam by search engines, it causes problems with keyword cannibalization — where you divide the potential ability of content to rank across multiple pages, therefore diluting the value of all the pages.
A great example of this is in product comparisons. On my site, I offer head-to-head comparisons for similar wine clubs. The page template interprets the URL to pull in content from the database and content blurbs I’ve written specifically to support these comparison pages.

If you were to start your journey on my website on the Nakedwines.com review, you could link to the comparison page where Nakedwines.com is first. The reverse is true for the Winc review. This method makes for a relevant and topical user experience, but these pages are essentially the same, and this is not good for search engine optimization.
Excessive (And Problematic) Internal Linking
How you link between the pages on your site has always been a critical component of SEO. Its prominence in SEO media waxes and wanes as a topic of concern for site owners, but at one point it became so popular to manipulate that the term “link sculpting” was all the rage.
Smart site owners pay very close attention to how the pages on their site link together, as both quality and quantity of links need to be considered in these strategies. Here’s an example of how it can go bad.
I recently launched a new section of my site featuring reviews of wines I’ve tasted. I launched with approximately 40 wines. Each wine had metadata like: winery, wine region, wine color, grapes, and tasting notes.
At launch, each place I displayed a particular wine (like the Red Wine Reviews page), I also generated links to some or all of the terms from that metadata. Similar to what is pictured here.
These 40 wines, with their programmatically-created category pages based on metadata, added 300 pages and 7k new internal links to my 700 page site.
One could argue this new content meaningfully changed what my site is about, and in this case, not in a way conducive to increasing revenue.
This change in meaning wasn’t what I intended, so I went back and reduced the number of unique tasting notes so there would be fewer pages created (and therefore internal links). I still use all of the terms in the review itself, just not in the part that programmatically generates links.

The above is an example of programmatically-generated and user-friendly links which caused excessive internal linking for the available content and importance on the site.
It’s worth noting how easy it is to do this when tinkering with programmatic content for SEO purposes. This is not the first time I’ve made such a mistake, and the first time was much worse. There are currently 3.5k pages on my site (canonicalized and noindexed) which were automatically generated by combining a location with the same sort of metadata used in the above example. Those pages have 176k internal links! These pages have promise when I fix the user experience and the datastreams that generate them (and pruning some of those links).
How to Use the Screaming Frog SEO Spider to Find Programmatic Content Problems
My web crawler of choice is the Screaming Frog SEO Spider. It is a superb tool for finding detailed information scattered about your site, and therefore is the perfect tool for discovering problems created by programmatic content campaigns.
The techniques I’m about to discuss explain how to use Screaming Frog to find these kinds of programmatic content mistakes so you can resolve them — ideally before you launch them out to production (like I did before I started using Screaming Frog).
After the content about how to use Screaming Frog reports to get at problems caused by programmatic content, I provide steps to configure your Spider to get all of this data into your reports.
How to Detect PHP Errors Using Screaming Frog
After a particular programmatic content launch, I started seeing Crawl Report messages showing up in Google Search Console that indicated something was wrong. Since Google doesn’t crawl every page very often, especially new content, I needed to figure out how widespread the problem really was.
Aside: this was about the time I realized I should crawl my local machine with error suppression turned off before I push to staging/production. More experienced and methodical teams may already do this, but for code cowboys like me, it’s a good idea to implement this QA step.
One of the Screaming Frog SEO Spider’s most useful features is Custom Search. With this tool you can find anything you want in the HTML or text of a website. I hand code a lot of PHP, so I configured my spider to look for “PHP” in the text of my website (i.e. the bits that are printed out to the screen, vs those that are the HTML itself). Here’s how that renders in the crawl report:

How to Detect Thin Content Using Screaming Frog
There are two easy methods you can use to identify pages with thin content in Screaming Frog. Both are easily accessed via the Content tab. This report page shows all kinds of easily-tabulated or inferred data about the content area on your pages.
The easiest method of finding thin pages in Screaming Frog is to navigate to the Content tab in your report and filter the results to see Low Content Pages. By default, this will return all pages with less than 200 words. The threshold can be configured to suit your needs.
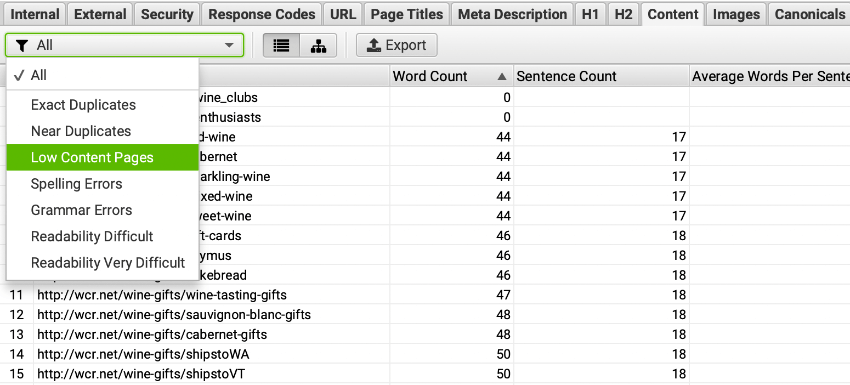
You could also just sort by Word Count and see which ones are too low.
How to Detect Duplicate Content Using Screaming Frog
As you can see in the previous graphic, there are also Content report filters for Exact Duplicates and Near Duplicates. Read more about Duplicates in the SEO Spider.
In the case of my new wine reviews section, I have a lot of duplicate and near duplicate content. The “No. Near Duplicates” column shows me how many pages are too similar to each URL. The first column shows the worst offender.
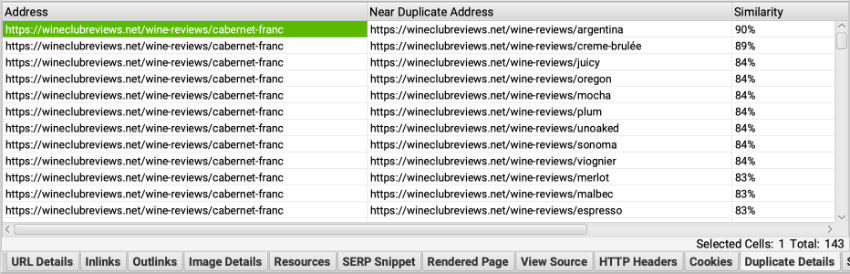
If I click on a URL and select the Duplicate Details lower tab, I can see all of the duplicate pages and their similarity matches.
Clicking on one of the URLs in the above panel shows me the duplication.
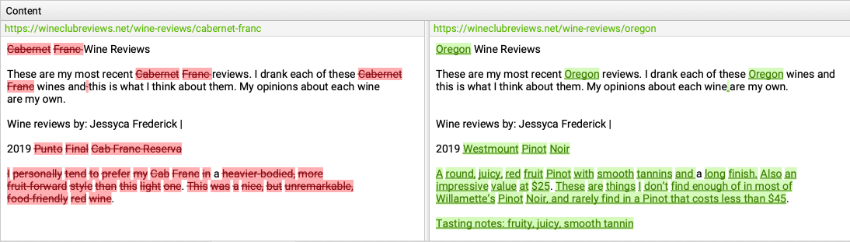
The red/green parts are what’s different, but you can see my programmatic content at work. I pushed these to production because I was interested in gauging potential traffic to this content before I spent precious time making each page unique.
Bonus Duplication Checking
You can use Screaming Frog crawl reports to identify pages with duplicate Page Titles, H1s, and H2s, too. This feature can be leveraged to see if your programmatic pages are creating repetitive on-page issues.
How to Detect Excessive or Problematic Internal Linking in the SEO Spider
The first part of finding problematic links is to understand where to look and how to refine your report view so it’s telling you what you want to know.
To see all of your internal links, visit the Internal upper tab, select all, and then in the lower tab section, view the Inlinks tab.
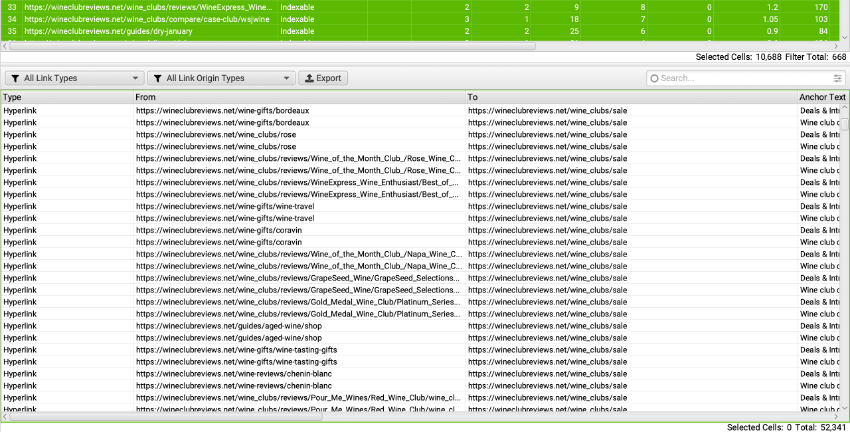
You can see in the upper right portion of the screenshot that I have limited which links are shown by those identified in the “Content” portion of the page, and that there are 11,232 internal links in my content across my 668 page website.
After careful pruning, the 210 wine review pages now have 1k links. If I look at the upper tab called Links and filter by URLs with wine-reviews in them, I can see a good distribution of links with a clear emphasis on the most important pages (for Topical Authority).
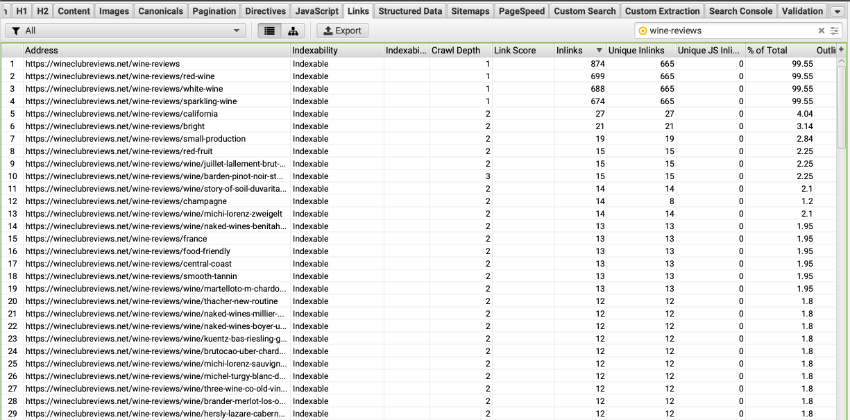
Note: if you use a lot of in-page linking (like a table of contents), you may want to change your SEO Spider configuration by unchecking Crawl Fragment Identifiers.
Bonus Step
I also like to use the Crawl Visualization tools after I create a mountain of programmatic pages to make sure I planned (and implemented) the structure correctly.
To access this beautiful diagram, go to Visualizations > Force-directed Directory Tree Diagram. You should see nice tight clusters. If you don’t, something’s probably amiss.
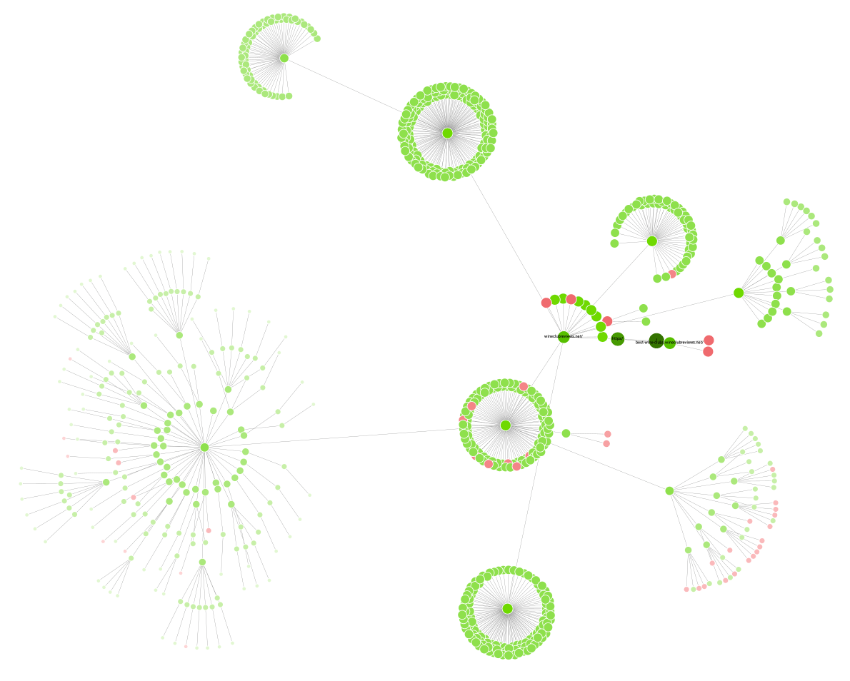
This is the diagram from my most recent crawl. The two topmost clusters are my wine-reviews and wine-reviews/wine directories. Nice and tight!
SEO Spider Configuration for Programmatic Content QA
Before you dig into an existing crawl to look for problems with programmatic content, you should know your existing configuration was probably missing a few bits. Here are the pre-crawl configuration edits I recommend.
Configuration for Error-Checking
Menu: Configuration > Custom > Search
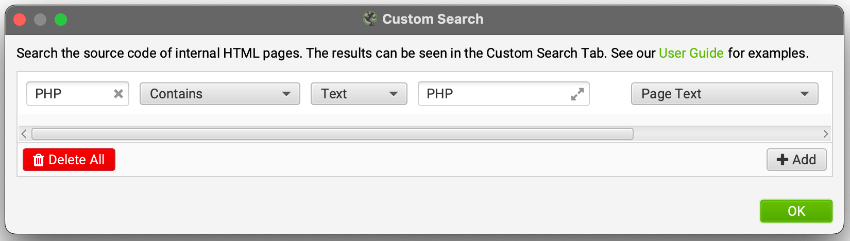
Sometimes PHP errors aren’t printed to the screen and are buried in the HTML — like if you load an undefined PHP variable into a <script></script> block, but it can’t find the PHP variable. It won’t break your page display in the browser, but that error is probably breaking something somewhere.
In those cases you also want to search the HTML. Screaming Frog lets you search a specific portion of your pages instead of the whole page, if you know where the errors are on the page but you need to identify all of the pages that have the errors.
Configuration for All Content
Before you get into specifics about how much content is enough, you’ll first want to define where on your pages your content is and isn’t located.
Menu: Configuration > Content
Rather than rely on the out-of-the-box configuration, I customize my configurations to exclude global navigation from “Content.”
On my site, those blocks are <nav> and <footer> blocks. I don’t use <aside> much, but it might also be an area to exclude on your site. Maybe your code is clean enough that you can simply include <article>.
Or, you can customize it to include/exclude certain blocks that aren’t standard semantic HTML elements. It’s quite powerful.
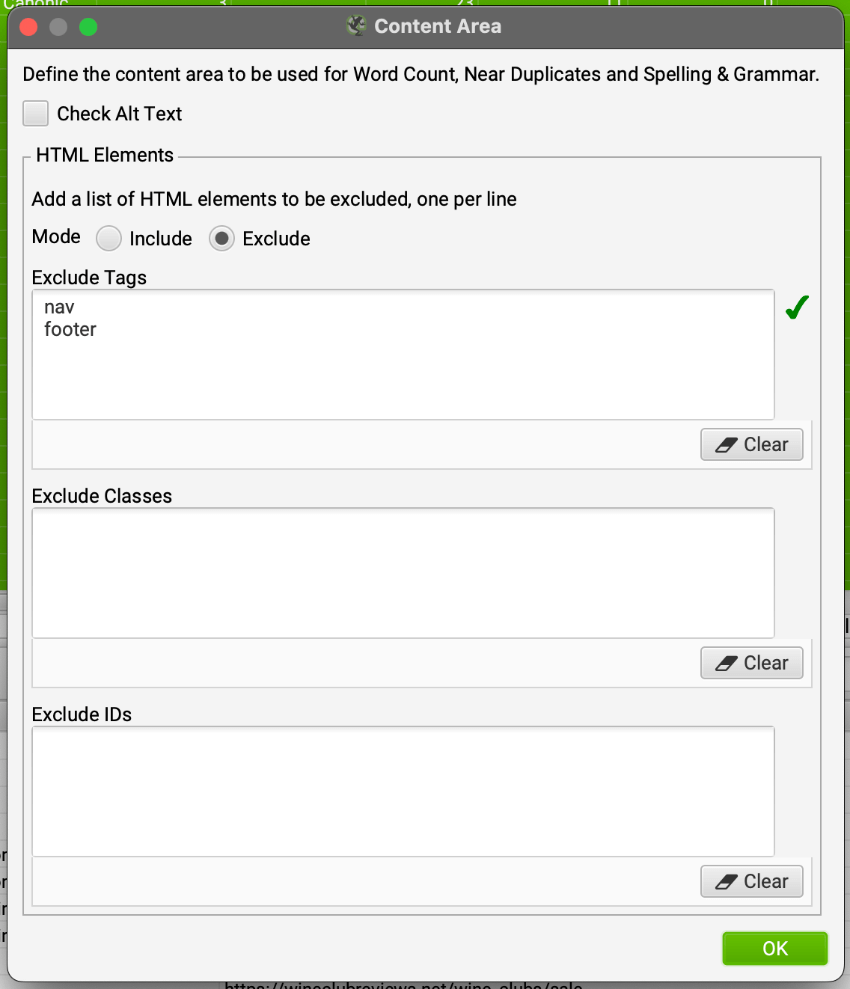
Configuration for Thin Content
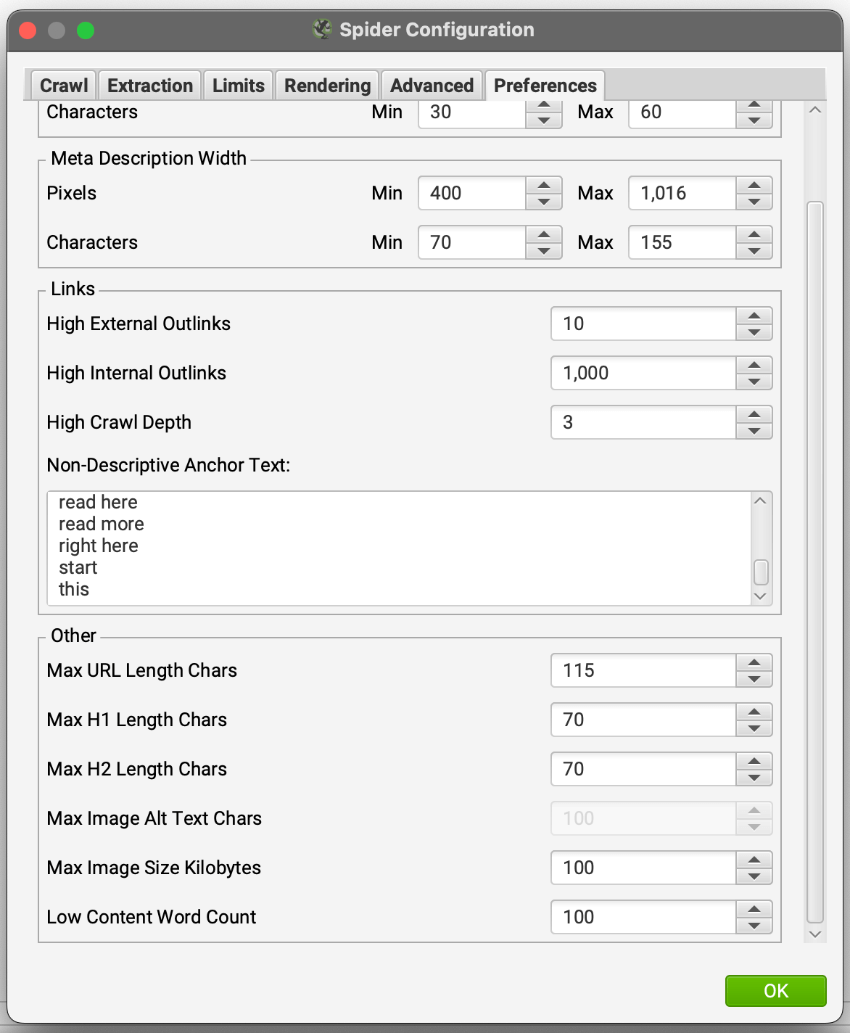
Menu: Configuration > Spider > Preferences tab
Scroll all the way down to the bottom and set your threshold for Low Content Word Count.
By default this is set to 0, but that’s not super helpful.
There is no “right word count” but under 100 words is probably a good indication of thin content.
Configuration for Duplicate Content
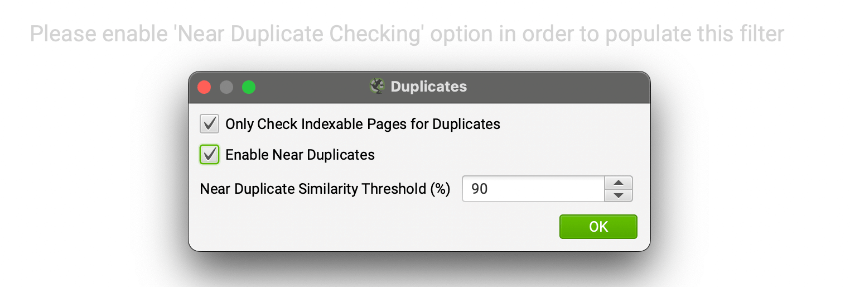
Menu: Configuration > Content > Duplicates
Check “Enable Near Duplicates” and choose a threshold for how similar pages should be before they raise this flag. The default is 90% and that’s adequate for checking for near duplicates.
If you want to find content that’s “too similar,” set it to 50%.
Note: after your crawl is complete you’ll need to run a Crawl Analysis to run this check.






The article raises important considerations regarding the use of programmatic SEO and AI-driven tools in content generation. It highlights the potential pitfalls that can arise when relying solely on code to create large volumes of content.
I appreciate the practical advice provided, particularly the suggestion of using a unique dummy phrase to identify content that failed to load or was incomplete. This approach demonstrates a proactive mindset towards identifying and rectifying errors in programmatic content.
By being mindful of the potential issues discussed in the article, marketers can make informed decisions about implementing programmatic SEO and ensure that the content produced aligns with their goals and provides value to users.
Zgadzam się! Bardzo wartościowy tekst. Idealna lektura w czasach, w których z każdej strony słyszymy o sztucznej inteligencji.