SEO Spider
How to Identify Semantically Similar Pages & Outliers
Introduction
The SEO Spider allows you to analyse the semantic similarity of pages in a crawl to help identify duplicate content and detect potentially off-topic, less relevant content on a site.
This functionality goes beyond matching text (as seen in our duplicate content detection) by utilising LLM embeddings that understand the underlying concepts and meaning of words on a page.
Utilising vector embeddings makes it possible to:
- Identify Duplicate & Similar Content – Find exact and near duplicate pages that might be overlapping in theme, covering the same subject multiple times, causing cannibalisation or just crawling and indexing inefficiencies.
- Detect Off-Topic Low Relevance Content – Discover pages that deviate from the average content theme or focus across the website.
- Visualise Content Clusters – View patterns and relationships in your website’s content, where semantically similar content is clustered and outliers are isolated.
These features require a paid licence for the software.
This tutorial walks you through how to connect to AI providers for vector embeddings, enable semantic similarity analysis and find semantically similar pages and low-relevance content.
1) Select An AI Provider for Embeddings
To perform semantic content analysis, you will need to connect to an AI provider API to generate vector embeddings of crawled page content.
Select from OpenAI, Gemini & Ollama via ‘Config > API Access > AI’.
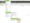
Ensure you have set up an account and have an API key, as outlined in the guides above.
2) Add Embeddings Prompt From Library
When you have selected your AI provider, navigate to the ‘Prompt Configuration’, select ‘Add from Library’ and choose the relevant preset for embeddings.
The Gemini embeddings and API are recommended and used in our example. For Gemini, select ‘Extract Semantic Embeddings from Page’, which will be added as a prompt.

The ‘Extract Semantic Embeddings from Page’ prompt specifically uses the ‘SEMANTIC_SIMILARITY’ task type, which suits this analysis.

The prompt will be displayed, with an error message that ‘Store HTML‘ must also be configured. More on this shortly.
3) Connect To the API
Before enabling the Store HTML setting, remember to ‘Connect’ to the API under ‘Account Information’.

This means when you start the crawl, embeddings will be generated and displayed in the AI tab.
4) Select ‘Store HTML’ & ‘Store Rendered HTML’
Click ‘Config > Spider > Extraction’ and enable ‘Store HTML’ and ‘Store Rendered HTML’ so page text is stored and used for vector embeddings.

The raw HTML page text will be used for crawls in text-only mode, while the rendered HTML page text will be used in JavaScript rendering mode.
5) Enable Embeddings Functionality
Navigate to the embeddings configuration via ‘Config > Content > Embeddings’ and ‘Enable Embedding functionality’.
The prompt set up should automatically be displayed in the embedding prompt dropdown. You can select multiple API providers, and use the dropdown to switch between them.
Enable ‘Semantic Similarity’ and ‘Low Relevance’ to populate the relevant columns and filters in the Content tab.

6) Crawl the Website
Enter the website you wish to crawl in the ‘Enter URL to spider’ box and hit ‘Start’.
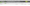
Wait until the crawl and API progress bar reaches 100%.
7) Run Crawl Analysis
To populate the ‘Semantically Similar’ and ‘Low Relevance Content’ filters in the Content tab (and associated columns), you need to perform crawl analysis when the crawl has completed.
There is an icon and message displayed next to filters that require crawl analysis displayed in the right-hand Overview tab.

To run crawl analysis, just click ‘Crawl Analysis > Start’ in the top menu.

The crawl analysis progress bar will appear in the top right hand corner, and when it reaches 100%, it’s time to analyse the data.

You are able to select to run this automatically at the end of the crawl to avoid this step in the future via ‘Crawl Analysis > Configure’ and selecting ‘Auto-Analyse at End of Crawl’.
8) View Semantically Similar & Low Relevance Filters
Click on the ‘Content’ tab and view the ‘Semantically Similar’ and ‘Low Relevance Content’ filters which will now be populated.
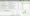
The two issues are as described in our right-hand Issues tab and in our issues library.
Semantically Similar
The ‘Semantically Similar’ filter displays the closest semantically similar address for each URL, as well as a semantic similarity score and number of URLs that are semantically similar.
High semantic similarity can be completely normal, but it can also indicate duplicate or overlapping content that should be reviewed.

Semantic similarity scores range from 0 – 1. The higher the score, the more similar the page is to its nearest neighbour displayed in the closest semantically similar address column.
Pages scoring above 0.95 are considered semantically similar by default. This threshold can be adjusted in the embedding config.
Read more details on the ‘Semantically Similar‘ issue in our issues library.
Low Relevance Content
The ‘Low Relevance Content’ filter shows pages that are potentially less relevant or off-topic compared to the general content theme of the website.
Low semantic similarity to the overall site focus might indicate irrelevant pages or those that do not fit generally what is written about.

Low Relevance Content pages are calculated by averaging the embeddings of all crawled pages to identify the ‘centroid’, then measuring the semantic distance to the centroid. The ‘Semantic Relevance Score’ column displays the similarity of a page to the centroid.
The threshold can be adjusted via ‘Config > Content > Embeddings’ and is set at 0.4 by default. The less semantically similar a page is to average content written on the site, the lower the ‘Semantic Relevance Score’ will be.
Read more details on the ‘Low Relevance Content‘ issue in our issues library.
The algorithms for both issues above are run against text on the page based on the content area.
9) View Duplicate Details Tab
When there are a number of URLs that are semantically similar to a URL, the lower ‘Duplicate Details’ tab and ‘Semantic Similarity’ filter will list all URLs that are semantically similar.

The right-hand side of the tab displays the text analysed, so it’s easy to review why they are classified as similar.
10) Bulk Export Semantically Similar
‘Semantically Similar’ URLs can be exported in bulk via the ‘Bulk Export > Content > Semantically Similar’ export.

This will include the closest semantically similar address and any others above the threshold.
11) View Semantic Content Cluster Diagram
The Content Cluster Diagram available under ‘Visualisations’ menu is a two-dimensional visualisation of URLs from the crawl, plotted and clustered from embeddings data.
It can be used to identify patterns and relationships in your website’s content, where semantically similar content is clustered together. A different colour is given to each semantic cluster.
The diagram can display up to 10,000 pages at a time. The closer the nodes are together, the more semantically similar they are to each other.
The example diagram above highlights the semantic relationship of an animal website.
Tiger populations are tightly grouped together, with the nearest neighbour, the Liger hybrid between the Tiger and the Lion, and then other big cats such as Leopards, Jaguars, and Cheetahs as the next neighbours and so on.
The diagrams can visualise the scale of clusters of content on a site, or identify potential topical clusters that are semantically related – yet might be distantly integrated for the user.

Low-relevance content and outliers can be easily identified as isolated nodes on the edges of the diagram.

The cog allows you to adjust the sampling, dimension reduction, number of clusters and colour schemes used. You can select to use ‘segments‘ as clustering node colour scheme if you have segmented your crawl.

This can be helpful to spot when two semantically similar pages are in different segments, which could be considered for internal linking to each other.
In the case of the above, the two pages that cover the same subject are in different sections of the website – tutorials and our issues library, and should refer to each other with internal links.
You’re also able to right-click and ‘Show Inlinks’ or outlinks within the Content Cluster Diagram.

As well as viewing all internal links to a page, you can also select to ‘Show Inlinks Within Cluster’, to see if a page is benefiting from links from semantically similar pages.

This can be a useful way to visually identify internal link opportunities or gaps in internal linking based upon semantics.
David Gossage has an excellent guide on How to Interpret the Content Clustering Visualisation.
Tips For Improving Results
There are various things you can do to improve the results of using vector embeddings for semantic content analysis.
Refine Your Content Area Settings
Embeddings will only be as good as the content provided during their generation. If the content provided to the LLM is messy, then the embeddings and results from the analysis will be less useful.
To view the content provided to generate embedding for URLs, use the lower ‘View Source’ tab and ‘Visible Content’ filter.

You’re able to configure the content used via ‘Config > Content > Area’.
The SEO Spider will exclude nav and footer elements to focus on main body content. However, not every website is built using these HTML5 elements, so you’re able to refine the content area used for the analysis. You can choose to ‘include’ or ‘exclude’ HTML tags, classes, and IDs from the analysis.

So consider removing boilerplate text, which is the same across pages – such as cookie content text, additional menu items, business addresses and phone numbers, etc. Focus on the main unique content of each page.
The Screaming Frog site for example has an additional secondary nav on issues pages, as well as ‘download’ modal windows that repeat the same text across the site.

When present, they can make pages seem more similar if used to generate embeddings. Updating the content area settings to remove the relevant div classes improves the content provided.

This will exclude the menu and other duplicated items from being included in the embeddings generation for better results.
Gemini RPM
If you’re using Gemini for embeddings, then the free tier is extremely limited.
Their default embeddings model is limited to 100 requests per minute (RPM), but in practice appears to error over 20 RPM (doh, Google!). You may see an error like the below.

The tier 1 paid account increases this significantly up to 3,000 RPM.
In the Advanced tab, you can adjust the maximum requests per minute for different models. If you’re a paid user, double check your rate limits in AI Studio, and increase the embeddings RPM.

Improve Speed, Without Losing Accuracy
Research by Dejan SEO showed that you can reduce the dimensions of vector embeddings from 1,024 to 256 dims, and not sacrifice accuracy, while improving speed and reducing size significantly.
It’s possible to truncate dimensions for embeddings by clicking the cog next to mode name to add a parameter.

Click ‘Add Parameter’ and input the dimension name, value and adjust to ‘Number’ from ‘String’. For OpenAI, the dimensions parameter is ‘dimensions’.

For Gemini, the parameter to set dimension is ‘outputDimensionality’.

These changes will be more noticeable on less powerful machines, but will make crawl analysis and the content cluster visualisation quicker, and reduce the size of crawls.
With limited testing, we have seen crawl analysis improve by 30% and t-SNE dimension reduction by 55%.
‘Limit Page Content’ for Large Pages
Review Indexable HTML pages under the ‘AI’ tab for any missing an embedding (there should be a long number within the relevant embedding column) with an error in the ‘Prompt Request Status’:
Error: Bad Request. "This model's maximum context length is 8192 tokens, however you requested 11679 tokens (11679 in your prompt; 0 for the completion). Please reduce your prompt; or completion length."
These will typically be large content pages, which exceed the context token length of the AI providers model.

This can be debugged by pausing the crawl, and clicking ‘Config > API Access > AI > AI Provider’ and on the ‘Prompt Configuration’ clicking the ‘test’ button.

Enter the URL of the page missing an embedding and read the response from the AI provider.

This will confirm if the error is related to the size of the context length token limit.
Close the test window, click the ‘Advanced’ tab and enable ‘Limit Page Content’, which will limit the content in the prompt to 5,000 characters. This can be adjusted based on the model.

Returning to the test tab confirms that this change now generates an embedding.

With this adjustment, go back to the AI tab and right click and ‘Request API Data’ for the AI provider in bulk for any URLs missing embedding data.

This will re-request data for just those URLs so they can be included in the analysis.
Using In Combination With Exact & Near Duplicate Detection
The SEO Spider is able to find exact and near duplicate content using more traditional text matching on a page, using MD5 and minhash algorithms.
This detection does not aim to understand language, and relies on word matching and order. Therefore this does not find semantically similar pages, that use different words to describe similar things.

While the semantic similarity functionality will find exact and near duplicates that will appear in these filters, it will also find far more complex matches.
Both perform similar jobs, but in different ways, and can produce quite different results – which is why it’s often useful to use in combination.
The results from the duplicate content checks are typically ‘obvious’ higher priority duplicates, as they are word matching. Another benefit is they do not require the use of embedding and API tokens.
Other Uses for Embeddings
The semantic similarity analysis can be used for more than just detecting near duplicates and low-relevance content as well, such as:
- Improving Internal Linking – The lower ‘Duplicate Details’ tab, and ‘Semantic Similarity’ filter can be used to improve internal linking between semantically similar content.
- URL Mapping for Redirects – Crawl old and new websites together and adjust the semantic similarity threshold to get a list of the closest semantically similar URLs for redirects.
- Semantic Similarity Analysis of any Element – Select ‘page titles’ instead of ‘page text’ for the embeddings, and run a semantically similar analysis to find near duplicate titles instead.
And lots more!
Limitations of Embeddings
It would be remiss not to outline the limitations of embeddings and the use in the tool. While deep reading, we recommend:
- Is Cosine-Similarity of Embeddings Really About Similarity?
- Problems With Evaluation of Word Embeddings Using Word Similarity Tasks
While both OpenAI embeddings and Gemini Embeddings are recommended to be used in the way that they are, typically datasets need grooming and tweaking, then various techniques are applied to explore the datasets to work out how to present a result.
We have a one size fits all approach, due to the nature of our software.
While the results may not be perfect or reliable in all scenarios, empirically the results have proved to be useful across a range of websites.
Data should never be followed blindly, human interpretation and analysis will always be required.
Debugging
If none of the features that rely on embeddings are working, there might be an issue with generating them via your chosen AI provider.
The first step is to check embeddings have been created, under the ‘AI’ tab. There should be a long number in the embedding column. The ‘Prompt Request Status’ should also say ‘Success’.

If the embedding column is blank, then no embedding has been created – and the features that rely on it will not work.
This can be debugged by clicking ‘Config > API Access > AI > AI Provider’ and on the ‘Prompt Configuration’ clicking the ‘test’ button.
Enter the URL of the page missing an embedding and read the response from the AI provider.
This will confirm the specific error. The above is an example error for a large page over the token size limit, but often errors for all pages will be related to account credits etc.
A successful request should look like this –
Summary
The guide above should illustrate how to use the SEO Spider to find duplicate and semantically similar pages in a crawl.
For the best results, refine the content area used for embeddings and adjust the threshold for different sites or groups of pages.
Please also read our Screaming Frog SEO Spider FAQs and full user guide for more information on the tool. Get in touch with our support with any queries.




