What I Learnt from Analysing 7 Million Log File Events
Roman Adamita
Posted 10 January, 2022 by Roman Adamita in Screaming Frog Log File Analyser
What I Learnt from Analysing 7 Million Log File Events
Table of Contents
- What You’ll Learn From My Research
- How Often Is Googlebot Crawling the robots.txt File?
- Is There a Way to See in Log Files Where Googlebot Is Coming From?
- How Many Different IP Addresses Does Googlebot Have?
- Which Pages Are Googlebot Crawling More Often?
- Are 404 Status Code Pages Crawled More Than Three Times?
- How Long Does Googlebot Crawl a 301-Redirect For?
- How Often Does Googlebot Crawl Paginated Pages?
- Should Higher Traffic Pages Be Crawled More by Googlebot?
- Is It Important to Have a Lot of Products in a Category to Get More Attention From Googlebot?
- How Important Is Page Speed in the Context of Crawling Events?
- Does Rebooting Your Machine Make Your Log File Analysis Faster?
- Last Words
It’s been almost three years since I started to work intensely on log file analysis for SEO purposes, and to make the analysis simple, I decided on the Screaming Frog Log File Analyser as my tool of choice.
Because I faced so many cases where I should have known better, I decided to start noting down everything I learnt in the last ten months when working on a project. This project involved looking at server log files and then optimising the crawl budget based on findings.
This article is a guest contribution from Roman Adamita former Director of SEO at BoostRoas.
This blog post is not about an SEO case study, but more of a research and learnings piece based on my experience of over 7.2 million user agent events, which is he has followed up with more insights on his blog.
The only user agent I tracked during this research is Googlebot’s, which had 124 different user agents and several thousand real IP addresses.
The website I was analysing is an eCommerce site, which has over 100,000 indexed pages, and by delving into and understanding the website’s log files, I found a lot of opportunities to optimise the crawl budget and positively impact the revenue of the brand.
If you’re not already familiar with server log files, the below resources are a great starting point to gain a better understanding of how they work, and how they can be leveraged for SEO insight.
- What Is A Server Log File? by Ian Lurie
- The Ultimate Guide to Log File Analysis for SEO by Daniel Butler
You can also find lots of additional information in Screaming Frog’s Log File Analyser user guide.
What You’ll Learn From My Research
Some of the insights I gained from this task include:
- How often is Googlebot crawling the robots.txt file?
- Is there a way to see in the log files where Googlebot is coming from?
- How many different IP addresses does Googlebot have?
- Which Pages Are Googlebot Crawling More Often?
- Are 404 status code pages crawled more than three times?
- How many times does Googlebot crawl a 301-redirect?
- How often does Googlebot crawl paginated pages?
- Should higher traffic pages be crawled more by Googlebot?
- Is it important to have a lot of products in a category to get more attention from Googlebot?
- How important is page speed in the context of crawling events?
- Does rebooting your machine make your log file analysis faster?
How Often Is Googlebot Crawling the robots.txt File?
This is one of the most challenging parts of log file analysis, as there’s no exact number of times that Googlebot will crawl your robots.txt. But in this website’s case, Googlebot crawled the robots.txt file between 6 to 60 times per day. In 10 months, Googlebot crawled the robots.txt file over 24 thousand times – which breaks down as around 2,400 times per month.
The most common IP addresses to crawl the robots.txt file were:
- 66.249.76.106 (ISP: Google – United States)
- 66.249.76.97 (ISP: Google – United States)
It’s important to remember that this website has almost 100,000 indexed pages. In some cases, such as if the website is small, the robots.txt will be crawled at a much lower rate.
Don’t forget that Googlebot uses robots.txt to know which pages should or shouldn’t be crawled, so it’s important to ensure it’s reachable to Googlebot.
Is There a Way to See in Log Files Where Googlebot Is Coming From?
The short answer is yes.

Within log files you can see the referrer, which tells us that Googlebot found our site while crawling another.
You won’t see every backlink in this list, but there’s a chance you can catch some weird things that other tools may miss, such as your website’s IP address being indexable. In our case, the website had eight indexable IP addresses. If the original website has 100K indexed pages, then it makes 800K duplicate pages because of these IP-based domains.
As SEOs, we must inform developers about instances like this, and the developers will usually prevent those IP addresses from being crawlable.
Not every website will have the same problem, but it’s still something you must be aware of.
How Many Different IP Addresses Does Googlebot Have?
If we consider that there might be some bots that can impersonate even Googlebot, it might be good to start with how many real user agents of Googlebot I had to face in this period of 10 months.

There’s about 124 different user agents with a total of 7,231,982 events from Googlebot. This year, Google published their IP addresses of Googlebot as a way to identify if it’s legitimately them or not. Over the period of 10 months of log file analysis, I faced thousands of different IP addresses.
What can you do with these thousands of IP addresses?
- Use them to verify if the Googlebot’s IP is real or not
- You can check which country Googlebot is crawling your website from
- It becomes easier to filter server-side by IP address to find Googlebot verified logs
All the verifiable IP addresses start with “66.249…”, and if you want to see the IPs I exported from 2 user agents of Googlebot, here’s the list of them.
If you use AWS and want to verify Googlebot, you can use a filter and match those IP addresses. Usually, it’s not an SEO job; you can ask the developer.
The Screaming Frog Log File Analyser also allows you to verify all major search engine bots right within the tool:

Which Pages Are Googlebot Crawling More Often?
It’s no surprise that, yes, in our case the homepage was the most crawled page, as it should be.
But you might be surprised to hear the rest of the most crawled pages:
- Image* – which is an icon that is used on almost every page.
- Robots.txt file
- Header Image – the brand used it on mobile devices at the top of the homepage.
- Error page – if your website automatically redirects a 404 page to the same “Error Page”, I suggest you solve it. In these instances, finding which page is 404’ing will be very difficult, but we solved this problem by leaving 404 pages on the same URL that was removed.
*These images are uploaded under the root domain. The brand uses a CDN, so the images that have particular URL addresses are not included in these log files.
Are 404 Status Code Pages Crawled More Than Three Times?
As far as I see, 404 pages can be crawled unlimited times.
Why might this be the case?
- There are still websites that refer to that old page – the best practice here is to contact the website owner and let them know about the replaced page.
- It’s internally linked and hasn’t yet been replaced – even if you redirected that old page, you must remove the links to it from every page.
- It’s included in a static XML sitemap – ideally a sitemap is updated dynamically so that pages are automatically added and removed.
- Div style background URLs won’t update themselves – it’s best to check the source code to ensure there are no broken images.
How Long Does Googlebot Crawl a 301-Redirect For?
When John Mueller said that you must keep 301-redirect for at least one year, he was right, as was Matt Cutts at the time.
For this question, in my experience, hundreds of 301-redirected pages were crawled for over nine months.
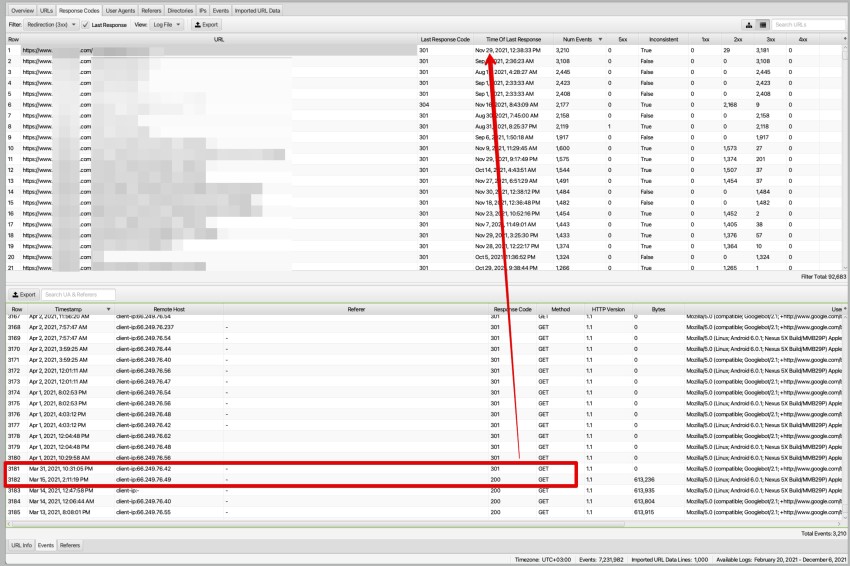
One of the reasons is that those old pages (which now are redirected) are internally linked. Some of them have fewer crawl events because Googlebot started to understand which one is the new page.
Some of them had external links that couldn’t be updated, so there was little to do but wait for Google to recognise the new links.
I had some other cases where Googlebot crawled dozens of pages that were over 3 years old and returned a 404-response code. This is not unusual for large sites, and it’s not necessary to take any action. You won’t lose any value from the crawl budget for your website, and it’s not necessary to 301-redirect every single 404 page. Just make sure that the old page wasn’t bringing any value for users at the time.
How Often Does Googlebot Crawl Paginated Pages?
It’s almost impossible to say an exact number for this question, but on average when looking at events for the second page, I can say that it’s between 1 week to 1 month. Googlebot usually uses the pagination series for understanding the relationship between categories.
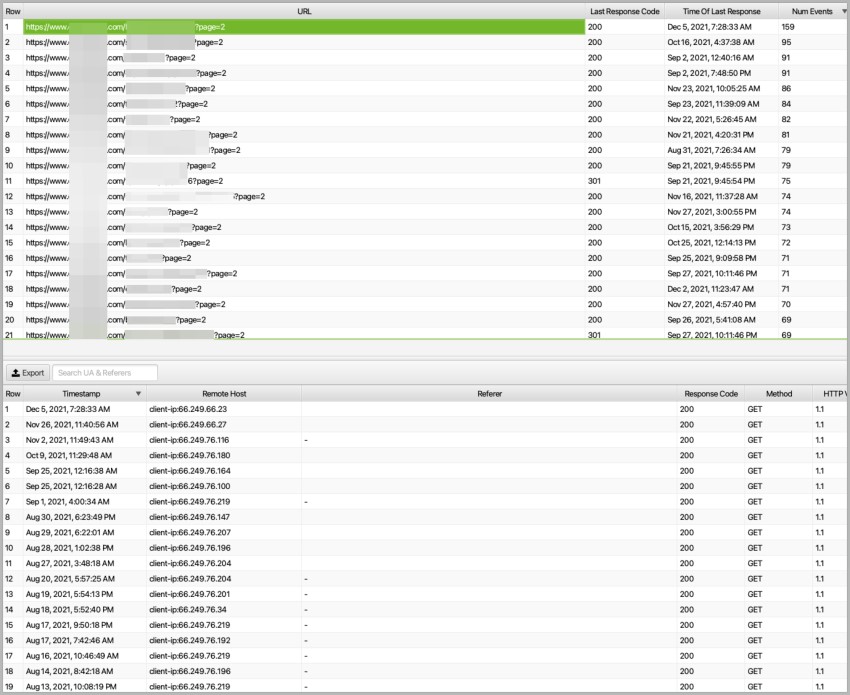
In this case, we made pagination pages as a carousel. It works using JavaScript, and Googlebot can see every pagination page link in any of them. But when it comes to crawling other paginations, it becomes tough to reach them since they often not as well linked to.
One thing to remember is, your website will never appear in the top ten of the search results with the second page of a category. But in any case, for the sake of “best practice”, you can keep indexable pagination pages or whatever structure you use for levelling the depth of categories.
Should Higher Traffic Pages Be Crawled More by Googlebot?
The short answer to this question is yes and no.
One of my learnings from this project’s log file analysis is that it doesn’t matter how many clicks a page gets. It’s more important to ensure that those pages are reachable, fast, and provide the intent that users are looking for.
So why is the answer also yes, then? Because there’s a homepage that has the most clicks and events. The homepage should have the most events, but not necessarily the most clicks. So, in this case, this is a typical result.
The most crawled pages by user clicks in the last ten months:
- Homepage (Level 1) – over 60,000 events and 2,640,000 clicks.
- Main Category (linked on every page – Level 2) – 4,260 events and over 8,200 clicks.
- Brand Category (linked in faceted navigation of a sub-category – Level 4) – 3,400 events and over 5,000 clicks.
- Sub-Category (linked in the main category – Level 3) – over 3,300 events and 4,300 clicks.
- Chocolate Product (linked in the sub-category and brand category – Level 5) – over 3,200 events and 2,400 clicks.
The most clicked top 5 pages and how many events they have:
- Homepage
- Catalogue (linked on every page – Level 2) – 612 events and over 479,000 clicks.
- Seasonal Sub-Category (linked in a Level 3 sub-category – Level 4) – 415 events and over 129,000 clicks.
- Sub-Category (linked in the main category – Level 3) – 478 events and over 119,000 clicks.
- Deals & Sales (linked on every page – Level 2) – over 1,600 events and 79,000 clicks.
Level – A definition of how many steps away from the homepage, referred to within the Screaming Frog Spider Tool as Crawl Depth.
Based on my findings, I feel that it’s not a “crawling signal” if a page getting a lot of clicks. As you can see above, the most crawled versus the most clicked pages are different from each other (excluding the homepage).
Is It Important to Have a Lot of Products in a Category to Get More Attention From Googlebot?
No. Even if they have 0 products in some of the categories, Googlebot will crawl it as much as other pages. In this case, I saw a lot of categories that had a meagre amount of products, but they were crawled periodically. It might be because of reasons such as the following:
- Since those categories don’t return a 304 status code (not modified), Googlebot is trying to see if there’s any update in the product listing.
- It’s included in the XML sitemap, and Googlebot loves to crawl this file very often. Some of the URLs which are included in the XML sitemap are not linked internally because the brand usually hides the categories that have no products in them.
- These categories are linked on every page due to the header or footer menu. I would suggest everyone checks all links that are included on every page of the website.
How Important Is Page Speed in the Context of Crawling Events?
I asked my colleague Adem for his opinion on how important page speed is as metric in the context of crawling events, since he is experienced when it comes page speed optimisation. He said that the Largest Contentful Paint (LCP) is the one we must care about more than other Core Web Vitals metrics.
Well, I believe him. Not because he’s my colleague, but because his approach on page speed is intense. In his experience, almost all the page speed metrics affect themselves. If the Time to First Byte (TTFB) metric is bad, then the First Contentful Paint (FCP) is too. If the FCP metric is bad, optimising any parts of the website will greatly affect the Largest Contentful Paint metric. That’s why the LCP metric is the most challenging one, and that’s why we still don’t have the FCP metric in Google Search Console.
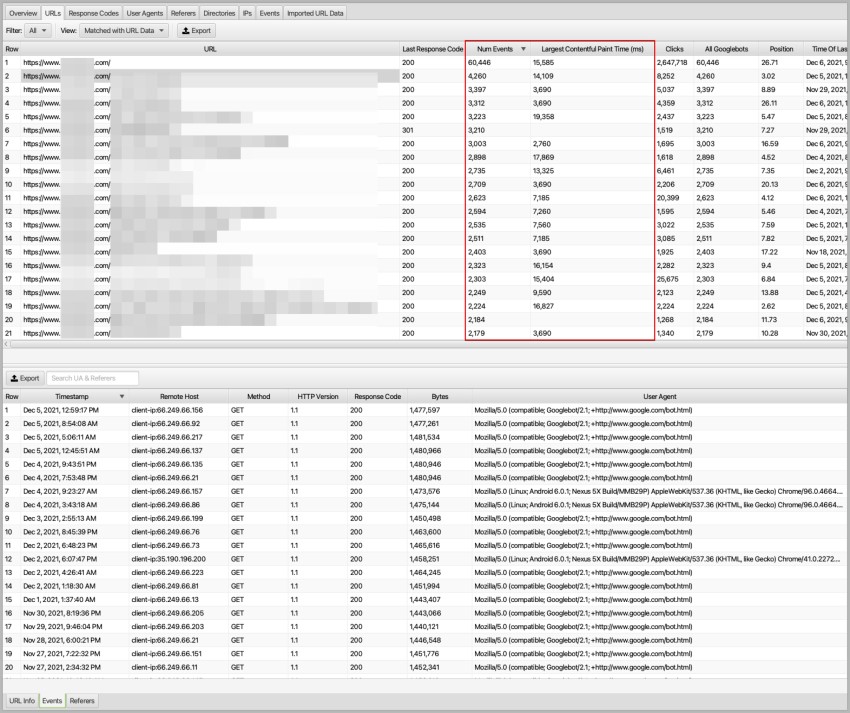
I compared how LCP affects Googlebot’s crawl events, and here’s what I learned:
- Googlebot will crawl those pages anyway, if it has a low score of LCP or not.
- The most crawled five pages have between 4 and 19 seconds of LCP load.
- In some cases, Googlebot tried to crawl the pages with a lousy LCP score more often.
- Pages with better LCP scores have more user clicks than others with bad scores.
- If a page is interactive for the users, it doesn’t matter what the metrics say. Users are the ones who choose where to spend time.
Does Rebooting Your Machine Make Your Log File Analysis Faster?
Yes. Do it often. Your CPU will thank you whenever you do log file analysis.
Last Words
Finally, it would be a crime if I didn’t mention the references I used heavily during this project:
- Log File Analysis Guide by Ruth Everett
- 22 Ways to Analyse Log Files by Dan Sharp






Hey Roman
Thanks for these insights
I was wondering if you noticed a progressive or immediate stop in crawls to 410 pages. As I saw on my own analysis thanks to Log File Analyzer and as you mentioned in the article, Google keeps on crawling 404. However, I wondered if the specific 410 code was a good means to actually stop the flow. I’m waiting for feedbacks before deciding to implement that function in the backoffice.
Best regards,
oh man – thanks for sharing this insights, roman
as if the timing couldn’t be better, the part about “Crawl Paginated Pages” in particular just got me extremely far and made my day.
thanks a lot! a great and successful 2022 to you
michael
Really so much actionable stuff here! Serioous lover this piece. I did the largest data study on what speed factor affects ranking the most– five years ago. So, yea it’s changed, but actually TTFB was always way more important than others at that time. We looked at ranking for 80,000 pages. One reason is it’s easier to measure properly, even today, as to how it effects UX vs. Largest Contentful Paint (LCP).
Some very detailed results here Roman, thanks for sharing. Particularly interesting to hear that 404 pages could potentially be crawled an unlimited amount of times, I would have assumed that Google would give up after a short while.
This is wonderful! Thank you so much for sharing, Roman. Agree that “Largest Contentful Paint (LCP) is the one we must care about more than other Core Web Vitals metrics.”!
Wow that was good. All our crawling knowledge is based on various assumptions, statements by people at Google, personal experiences in some of these, but this is a good collection of observations, from a large data set. Although I am also curious how Googlebot behaves on very small websites and those with a small amount of traffic.
Some great insights in this post. The research about how often Is Googlebot Crawling the robots.txt File was an eye-opener especially because we often find websites don’t list the XML sitemaps in there as they should.
One additional, very interesting metric is how long it takes for Google to crawl an entirely new website, without any backlinks.
It’s been some time, since I’ve seen it firsthand – before the end of last year, that is. With an established site, Google is quite fast and efficient to crawl whole websites. Never had an issue with getting changes crawled and indexed almost instantly, even without a manual request in Search Console.
However, it’s a completely different thing with a new website (no surprise here). Most sources say it usually takes up to 4 weeks.
In my case, it took Google 8 weeks to fully crawl a new website with 200 pages, after submitting a sitemap and requesting an indexation of the category pages with links to almost all pages. 2 to 10 pages were getting crawled and indexed each day, which matched the data in Search Console (where the coverage data is only updated every 3 to 4 days).
When requesting page indexations in the Search Console manually, there was a limit on how many pages can be indexed, which was below the request-limit. Each page over that limit (I estimate it was 5 pages per day) was crawled, but not indexed. This was also shown in Search Console. John Mueller once said, this is typically due to thin content on the page. However, in my case, it looked like a limitation on crawling and indexation budget on Googles side. Because when I stopped manually submitting pages, those pages in limbo were also indexed shortly after the rest.
I was honestly surprised at how slow it was. Bing crawled the entire website in less than 1 week.
Great research and analysis Roman.
What brought you to this conclusion for pagination?:
‘Googlebot usually uses the pagination series for understanding the relationship between categories.’
Thanks Roman, great work! The part about 404 was particularly interesting for me – excellent research:)
Hi, Such an informative write up. I liked the way of telling, and explaining the things to your users. Nice info! Thanks a lot for sharing it, that’s truly has added a lot to our knowledge about this topic. Have a more successful day. Amazing write-up, always find something interesting.
Hi Roman,
Thanks a lot for the insights. It’s to rare that log files are mentioned.
So all SEOs and technicians unite to keep making websites perfectly crawlable and even the page for google bots. They will be thankful :-)
Cheers,
Matthias
Interesting Post. I recently did many Redirects and gave the new ones a canonical URL.
Hope this helps to see it move earlier… What do you think?
Great insights, Roman. I wonder what impact this has on Google caching? I have noticed that it is taking a long time for Google to cache new domains/pages in their index of late.
Hello, thank you for this great article. I work a lot with Screaming frog and will now use the log file analysis more.
Greetings Max
Great Article. Screaming frog is soo powerful. Log file analysis may give us a lot of specific data. But i’m really impressed how big this tool is. Im learning screaming frog for a long time but still many things can surprise me. Your product is definitely the best.
Greetings, Hubert.
It seems that the crawling of 404 is not so simple. I have noticed many times that googlebot is trying to crawl URLs that have long been removed from the site as a result of a redesign. There are no links to them, neither external nor internal, and of course they are not in the sitemap. The source is most likely some internal index of Google itself.
Would be great to see this updated for 2024 to see if anything has changed in the past 2 years.