How To Use Wireshark With The SEO Spider
Dan Sharp
How To Use Wireshark With The SEO Spider
Here at Screaming Frog we occasionally get support queries from users of the SEO Spider reporting issues such as recording the wrong response code, or perhaps reporting a page to have no title or headings, when they are there when viewed in a browser. We often get asked if it’s bug in the software, but sometimes sites just respond differently depending on User-Agent, whether cookies are accepted, or if the server is under load for example.
Would it not be great if there was an easy way to independently verify what was being reported by the SEO Spider?
Well, actually there is. Enter Wireshark the worlds leading network protocol analyser. It captures and logs network traffic, allowing you to inspect packets sent and received by your computer. It’s available, for free, on all major operating systems and I wanted to put a guide together to show SEOs how Wireshark can be extremely useful verifying data (and a lot more!).
To show how to use Wireshark, I have created a page here that will not include a page title element if the requesting User-Agent contains the word ‘Spider’. The demo page doesn’t contain any links, but if you were doing this on a real site it would be worth limiting the crawl to just a single URL to minimise the amount of traffic generated (Configuration -> Spider and set ‘Limit Search Total’ to ‘1’ in the Limits tab).
Now start up Wireshark and choose Capture-> Start from the menu:

Switch back to the SEO Spider and start the crawl of the page. Once this is complete, switch back to Wireshark and choose Capture-> Stop.

In the filter input box at the top, type “http” and press enter.

This will filter out a lot of the traffic, ideally leaving you only with the HTTP traffic generated by the SEO Spider. Other browser sessions with active content or applications such as Dropbox will also generate HTTP traffic that may also be shown. You should be able to see a row in the master view with an ‘Info’ column containing:
GET /demo/missing_page_title/ HTTP/1.1
This is the request sent by the SEO Spider, you can inspect the contents of this by clicking the row and then expanding the “Hypertext Transfer Protocol” section in the details view:
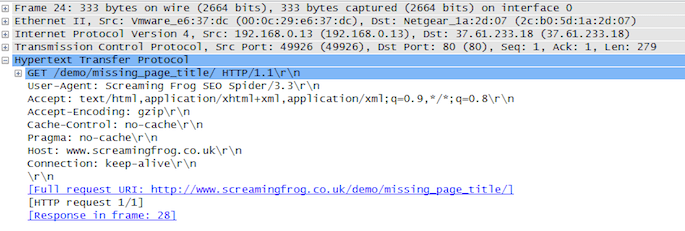
Here we can view the HTTP request headers sent by the SEO Spider. Now, switch back to the main ‘master view’ again and within the next few packets, depending on what other HTTP traffic was captured, you’ll be able to see a packet with Info:
HTTP/1.1 200 OK (text/html)
This is the HTTP response. Again clicking on it allows us to view in more detail:
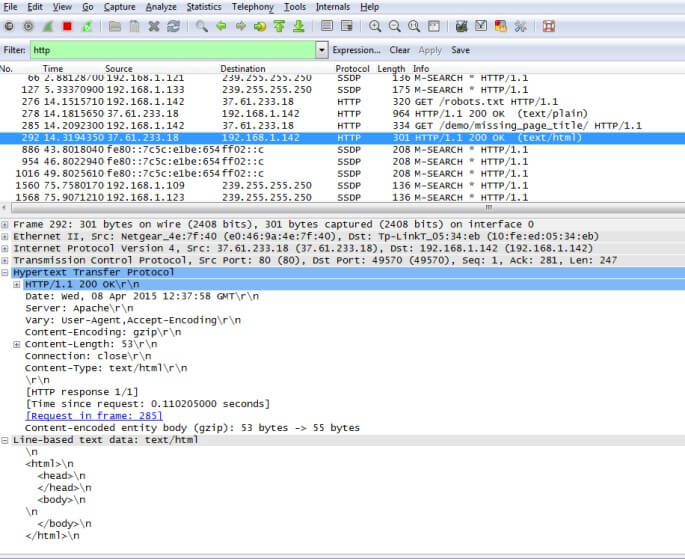
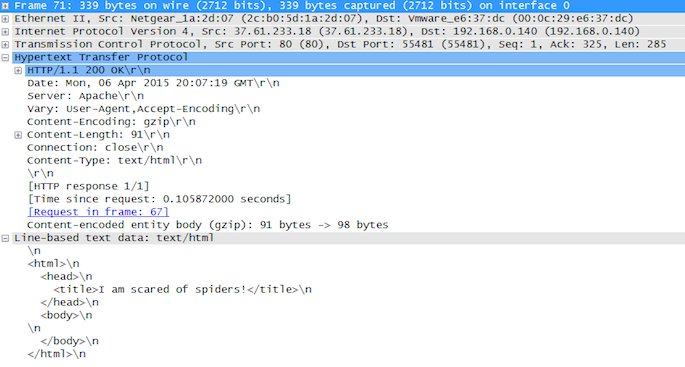
Here we can see the complete HTML returned under ‘Line-based text data: text/html’, and clearly see that it’s missing a page title.
If we now repeat the process by changing the User-Agent configured in the SEO Spider (Configuration-> User Agent) to GoogleBot regular.
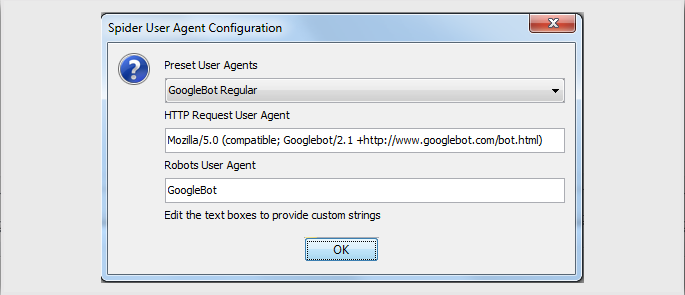
Then re-run the capture, we can see the updated request:
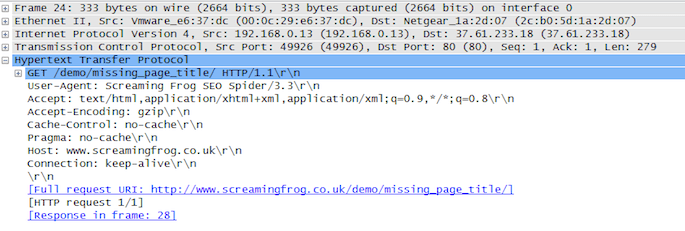
And the corresponding response, now including the page title “I am scared of spiders!”.
There are other tools such as Web Sniffer that allow you to switch User-Agent and view the raw HTML returned, but they don’t capture exactly what’s happening like Wireshark which allows you to sniff any tool you might be using or building yourself.
Hopefully this post has been a useful insight into the role Wireshark can play in an SEO’s toolkit.






I hadn’t even thought of using Wireshark with Screamingfrog. That, sir, is nothing less than spiffy.
That’s a really powerful tool, to debug network protocol implementations, examine problems and inspect network protocol internals.
This is an excellent solutions. I experienced this issue on a single occasion and reported errors that wasn’t there (my fault) – but this is great.
That’s awesome! never thought of such a possibility even though I use both the tools for different obvious purposes! Good way to test the network protocols and the raw HTML returned.. cheers for sharing this..
I’ve hands on session last week and found out that the filter tool and some other features is what I’m looking for. Thanks.
excellent article!!!
I use Screaming Frog every single day, and i must say its the best seo tool on the market today, but wire-shark i have never used before, it looks like i need to give it a try
I must agree, screaming frog is much better than A1 sitemap.
Thank you for such a good explanation!
Your seo spider – facilitated life. I will use it also in the future! :)
Hi all,
Can somebody help me to make this work on Mac OS using wireshark 3.2.2. When I follow the steps I always see two errors when stopping the capture:
“Unexpected error from select: Interrupted system call.” and “Error by extcap pipe: ** (process:2185): WARNING **: Missing parameter: –remote-host”
I haven’t adapted the setup yet, but maybe this needs some adaptions before the first capture. Any hints are much appreciated.
Best regards,
Manuel
Hi Manuel,
We’d need more detail on this one :-)
Are you able to email [email protected] with all the details and we can take a look?
Cheers.
Dan
@Manuel T. Have you fixed this issue on your side? I’m getting quite similar issue with newer version on Mac OS. Thanks!