Reports
si digital
Posted 27 November, 2015 by si digital in
Reports
There’s a variety of reports which can be accessed via the ‘reports’ top level navigation. These include as follows below.
Crawl Overview Report
This report provides a summary of the crawl, including data such as, the number of URLs encountered, those blocked by robots.txt, the number crawled, the content type, response codes etc. It provides a top level summary of the numbers within each of the tabs and respective filters.
The ‘total URI description’ provides information on what the ‘Total URI’ column number is for each individual line to (try and) avoid any confusion.
All Redirects, Redirect Chains & Redirect & Canonical Chains Reports
These reports detail redirects discovered on the website and the source URLs they are found on.

The ‘All Redirects’ report shows all singular redirects and chains discovered, ‘Redirect Chains’ reports redirects with 2+ redirects in a chain, and ‘Redirect & Canonical Chains’ shows any 2+ redirects or canonicals in a chain.
The ‘redirect chains’ and ‘redirect & canonical chains’ reports map out chains of redirects and canonicals, the number of hops along the way and will identify the source, as well as if there is a loop. In Spider mode (Mode > Spider) these reports will show all redirects, from a single hop upwards. It will communicate the ‘number of redirects’ in a column and the ‘type of chain’ identified, whether it’s an HTTP Redirect, JavaScript Redirect, Canonical etc. It also flags redirect loops. If the reports is empty, it means you have no loops or redirect chains that can be shortened.
The ‘redirects’, ‘redirect chains’ and ‘redirect & canonical chains’ reports can also all be used in list mode (Mode > List). They will show a line for every URL supplied in the list. By ticking the ‘Always follow redirects‘ and ‘always follow canonicals‘ options the SEO Spider will continue to crawl redirects and canonicals in list mode and ignore crawl depth, meaning it will report back upon all hops until the final destination. Please see our guide on auditing redirects in a site migration.
Please note – If you only perform a partial crawl, or some URLs are blocked via robots.txt, you may not receive all response codes for URLs in this report.
Canonicals Reports
The ‘Canonical Chains’ and ‘Non-Indexable Canonicals’ reports highlight errors and issues with canonical link elements or HTTP canonicals implementation within the crawl. Please read How To Audit Canonicals for our step-by-step guide.
The ‘Canonical Chains’ report highlight any URLs that have a 2+ canonicals in a chain. This is where a URL has a canonical URL to a different location (and is ‘canonicalised’), which then has a canonical URL to another URL again (a chain of canonicals).
The ‘Non-Indexable Canonicals’ report highlights errors and issues with canonicals. In particular, this report will show any canonicals which have a no response, are blocked by robots.txt, 3XX redirect, 4XX or 5XX error (anything other than a 200 ‘OK’ response).
This report also provides data on any URLs which are discovered only via a canonical and are not linked to from the site (in the ‘unlinked’ column when ‘true’).
Pagination Reports
The ‘Non-200 Pagination URLs’ and ‘Unlinked Pagination URLs’ reports highlight errors and issues with rel=”next” and rel=”prev” attributes, which are of course used to indicate paginated content. Please read How To Audit rel=”next” and rel=”prev” Pagination Attributes for our step-by-step guide.
The ‘Non-200 Pagination URLs’ report will show any rel=”next” and rel=”prev” URLs which have a no response, blocked by robots.txt, 3XX redirect, 4XX, or 5XX error (anything other than a 200 ‘OK’ response).
The ‘Unlinked Pagination URLs’ report provides data on any URLs which are discovered only via a rel=”next” and rel=”prev” attribute and are not linked-to from the site (in the ‘unlinked’ column when ‘true’).
Hreflang Reports
The Hreflang reports relate to the implementation of hreflang discovered on the website. Please read How To Audit Hreflang for our step-by-step guide.
There are 7 hreflang reports which allow data to be exported in bulk, which include the following –
- All Hreflang URLs – This is a 1:1 report of all URLs & hreflang URLs including region and language values discovered in a crawl.
- Non-200 Hreflang URLs – This report shows any URLs in hreflang annotations which are not a 200 response (no response, blocked by robots.txt, 3XX, 4XX or 5XX responses).
- Unlinked Hreflang URLs – This report shows any hreflang URLs which are not linked to via a hyperlink on the site.
- Missing Confirmation Links – This report shows the page missing a confirmation link, and which page is not confirming.
- Inconsistent Language Confirmation Links – This report shows confirmation pages which use different language codes to the same page.
- Non Canonical Confirmation Links – This report shows the confirmation links which are to non canonical URLs.
- Noindex Confirmation Links – This report shows the confirmation links which are to noindex URLs.
Insecure Content Report
The insecure content report will show any secure (HTTPS) URLs which have insecure elements on them, such as internal HTTP links, images, JS, CSS, SWF or external images on a CDN, social profiles etc. When you’re migrating a website to secure (HTTPS) from non secure (HTTP), it can be difficult to pick up all insecure elements and this can lead to warnings in a browser –
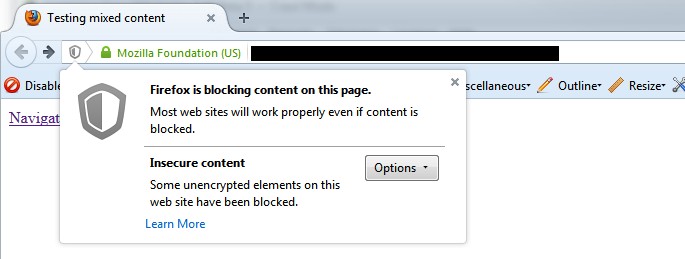
Here’s a quick example of how a report might look (with insecure images in this case) –

SERP Summary Report
This report allows you to quickly export URLs, page titles and meta descriptions with their respective character lengths and pixel widths.
This report can also be used for a template to re-upload back into the SEO Spider in ‘SERP’ mode.
Orphan Pages Report
The orphan pages report provides a list of URLs collected from the Google Analytics API, Google Search Console (Search Analytics API) and XML Sitemap that were not matched against URLs discovered within the crawl.
This report will be blank, unless you have connected to Google Analytics, Search Console or configured to crawl an XML Sitemap and pull in data during a crawl.
You can see orphan page URLs directly in the SEO Spider as well, but it does require the correct configuration. We recommend reading our guide on how to find orphan pages.
The orphan pages report ‘source’ column shows exactly the source the URL was discovered, but not matched against a URL in the crawl. These include –
- GA – The URL was discovered via the Google Analytics API.
- GSC – The URL was discovered in Google Search Console, by the Search Analytics API.
- Sitemap – The URL was discovered via the XML Sitemap.
- GA & GSC & Sitemap – The URL was discovered in Google Analytics, Google Search Console & the XML Sitemap.
This report can include any URLs returned by Google Analytics for the query you select in your Google Analytics configuration. Hence, this can include logged in areas, or shopping cart URLs, so often the most useful data for SEOs is returned by querying the landing page path dimension and ‘organic traffic’ segment. This can then help identify –
- Orphan Pages – These are pages that are not linked to internally on the website, but do exist. These might just be old pages, those missed in an old site migration or pages just found externally (via external links, or referring sites). This report allows you to browse through the list and see which are relevant and potentially upload via list mode.
- Errors – The report can include 404 errors, which sometimes include the referring website within the URL as well (you will need the ‘all traffic’ segment for these). This can be useful for chasing up websites to correct external links, or just 301 redirecting the URL which errors, to the correct page! This report can also include URLs which might be canonicalised or blocked by robots.txt, but are actually still indexed and delivering some traffic.
- GA or GSC URL Matching Problems – If data isn’t matching against URLs in a crawl, you can check to see what URLs are being returned via the GA or GSC API. This might highlight any issues with the particular Google Analytics view, such as filters on URLs, such as ‘extended URL’ hacks etc. For the SEO Spider to return data against URLs in the crawl, the URLs need to match up. So changing to a ‘raw’ GA view, which hasn’t been touched in anyway, might help.
Structured Data Reports
The ‘Validation Errors & Warnings Summary’ report aggregates structured data to unique validation errors and warnings discovered (rather than reporting every instance) and shows the number of URLs affected by each issue, with a sample URL with the specific issue. An example report can be seen below.
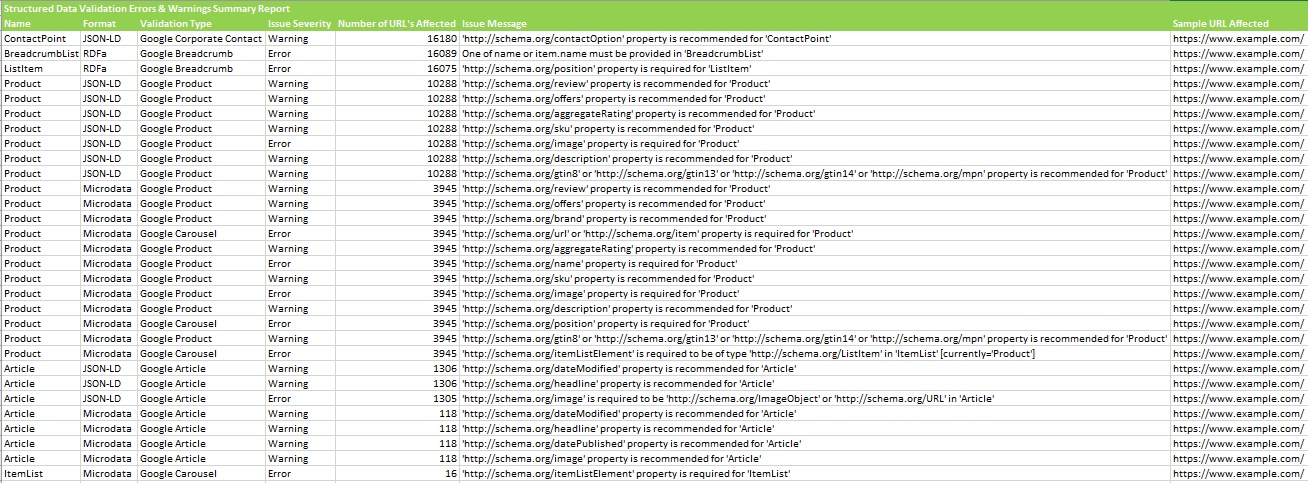
The ‘Validation Errors & Warnings’ report shows every structured data validation error and warning at URL level, including the URL, the property name (Organization etc), format (JSON-LD etc), issue severity (error or warning), validation type (Google Product etc) and issue message (/review property is required etc).
The ‘Google Rich Results Features Summary’ report aggregates by Google Rich Results Features detected across a crawl, and shows the number of URLs that have each feature.
The ‘Google Rich Results Features’ report maps every URL against every available feature, and shows which ones have been detected for each URL.
PageSpeed Reports
The PageSpeed reports relate to the filters outlined in the PageSpeed tab, which covers the meaning of each. These reports provide a way to export the pages and their specific resources with speed opportunities or diagnostics.
They require the PageSpeed Insights integration to be set-up and connected.
The ‘PageSpeed Opportunities Summary’ report summaries all the unique opportunities discovered across the site, the number of URLs it affects, and the average and total potential saving in size and milliseconds to help prioritise them at scale.
The ‘CSS Coverage Summary’ report highlights how much of each CSS file is unused across a crawl, and the potential savings that could be made by removing unused code that is loading across the site.
The ‘JavaScript Coverage Summary’ report highlights how much of each JS file is unused across a crawl, and the potential savings that could be made by removing unused code that is loading across the site.
HTTP Header Summary Report
This shows an aggregated view of all HTTP response headers discovered during a crawl. It shows every unique HTTP response header and the number of unique URLs that responded with the header.
‘HTTP Headers‘ must be enabled to be extracted via ‘Config > Spider > Extraction’ for this to be populated.
More granular details of the URLs and headers can be seen in the lower window ‘HTTP Headers’ tab, and via the ‘Bulk Export > Web > All HTTP Headers’ export.
Alternatively, HTTP headers can be queried in the Internal tab, where they are appended in separate unique columns.
Cookie Summary Report
This shows an aggregated view of unique cookies discovered during a crawl, considering their name, domain, expiry, secure and HttpOnly values. The number of URLs each unique cookie was issued on will also be displayed. The cookie value itself is discounted in this aggregation (as they are unique!).
‘Cookies‘ must be enabled to be extracted via ‘Config > Spider > Extraction’ for this to be populated. JavaScript rendering mode will also need to be configured to get an accurate view of cookies which are loaded on the page using JavaScript or pixel image tags.
This aggregated report is extremely helpful for GDPR. More granular details of the URLs and cookies found on them can be seen in the lower window ‘Cookies’ tab, and via the ‘Bulk Export > Web > All Cookies’ export.
Crawl Path Report
This report is not under the ‘reports’ drop down in the top level menu, it’s available upon right-click of a URL in the top window pane and then the ‘export’ option. For example –
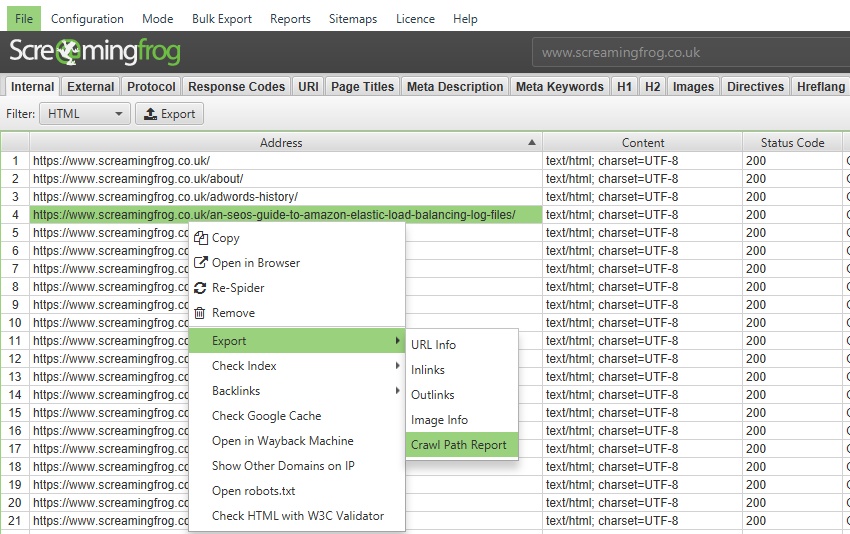
This report shows you the shortest path the SEO Spider crawled to discover the URL which can be really useful for deep pages, rather than viewing ‘inlinks’ of lots of URLs to discover the original source URL (for example, for infinite URLs caused by a calendar).
The crawl path report should be read from bottom to top. The first URL at the bottom of the ‘source’ column is the very first URL crawled (with a ‘0’ level). The ‘destination’ shows which URLs were crawled next, and these make up the following ‘source’ URLs for the next level (1) and so on, upwards.
The final ‘destination’ URL at the very top of the report will be the URL of the crawl path report.




