Screaming Frog SEO Spider Update – Version 2.40
Dan Sharp
Posted 15 May, 2014 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 2.40
I am excited to announce version 2.40 of the Screaming Frog SEO spider, codenamed internally as ‘Duck Cam’. Thanks again to everyone for their continued feedback, suggestions and support.
Let’s get straight to it, the updated version includes the following new features –
1) SERP Snippets Now Editable
First of all, the SERP snippet tool we released in our previous version has been updated extensively to include a variety of new features. The tool now allows you to preview SERP snippets by device type (whether it’s desktop, tablet or mobile) which all have their own respective pixel limits for snippets. You can also bold keywords, add rich snippets or description prefixes like a date to see how the page may appear in Google.
You can read more about this update and changes to pixel width and SERP snippets in Google in our new blog post.

The largest update is that the tool now allows you to edit page titles and meta descriptions directly in the SEO Spider as well. This subsequently updates the SERP snippet preview and the table calculations letting you know the number of pixels you have before a word is truncated. It also updates the text in the SEO Spider itself and will be remembered automatically, unless you click the ‘reset title and description’ button. You can make as many edits to page titles and descriptions and they will all be remembered.
This means you can also export the changes you have made in the SEO Spider and send them over to your developer or client to update in their CMS. This feature means you don’t have to try and guesstimate pixel widths in Excel (or elsewhere!) and should provide greater control over your search snippets. You can quickly filter for page titles or descriptions which are over pixel width limits, view the truncations and SERP snippets in the tool, make any necessary edits and then export them. (Please remember, just because a word is truncated it does not mean it’s not counted algorithmically by Google).
2) SERP Mode For Uploading Page Titles & Descriptions
You can now switch to ‘SERP mode’ and upload page titles and meta descriptions directly into the SEO Spider to calculate pixel widths. There is no crawling involved in this mode, so they do not need to be live on a website.

This means you can export page titles and descriptions from the SEO Spider, make bulk edits in Excel (if that’s your preference, rather than in the tool itself) and then upload them back into the tool to understand how they may appear in Google’s SERPs.
Under ‘reports’, we have a new ‘SERP Summary’ report which is in the format required to re-upload page titles and descriptions. We simply require three headers for ‘URL’, ‘Title’ and ‘Description’.
The tool will then upload these into the SEO Spider and run the calculations without any crawling.
3) Crawl Overview Right Hand Window Pane
We received a lot of positive response to our crawl overview report when it was released last year. However, we felt that it was a little hidden away, so we have introduced a new right hand window which includes the crawl overview report as default. This overview pane updates alongside the crawl, which means you can see which tabs and filters are populated at a glance during the crawl and their respective percentages.
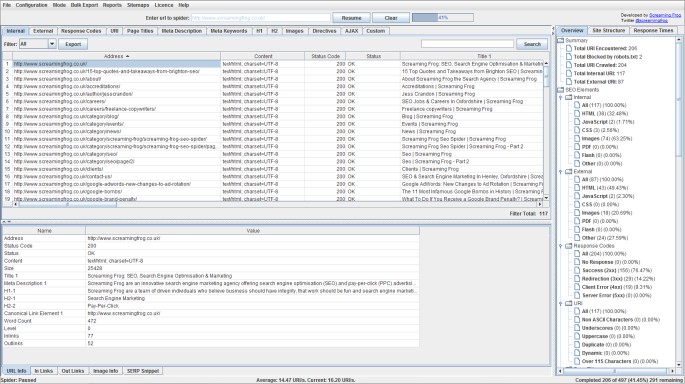
This means you don’t need to click on the tabs and filters to uncover issues, you can just browse and click on these directly as they arise. The ‘Site structure’ tab provides more detail on the depth and most linked to pages without needing to export the ‘crawl overview’ report or sort the data. The ‘response times’ tab provides a quick overview of response time from the SEO Spider requests. This new window pane will be updated further in the next few weeks.
You can choose to hide this window, if you prefer the older format.
4) Ajax Crawling #!
Some of you may remember an older version of the SEO Spider which had an iteration of Ajax crawling, which was removed in a later version. We have redeveloped this feature so the SEO Spider can now crawl Ajax as per Google’s Ajax crawling scheme also sometimes (annoyingly) referred to as hashbang URLs (#!).
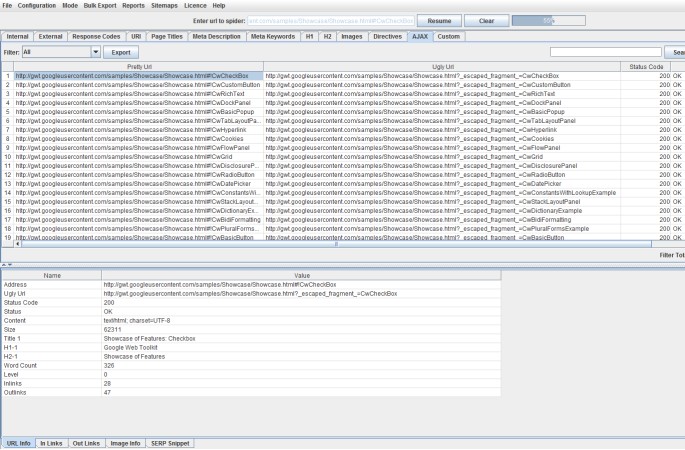
There is also an Ajax tab in the UI, which shows both the ugly and pretty URLs, with filters for hash fragments. Some pages may not use hash fragments (such as a homepage), so the ‘fragment’ meta tag can be used to recognise an Ajax page. In the same way as Google, the SEO Spider will then fetch the ugly version of the URL.
5) Canonical Errors Report
Under the ‘reports‘ menu, we have introduced a ‘canonical errors’ report which includes any canonicals which have no response, are a 3XX redirect or a 4XX or 5XX error.
This report also provides data on any URLs which are discovered only via a canonical and are not linked to from the site (so not html anchors to the URL). This report will hopefully help save time, so canonicals don’t have to be audited separately via list mode.
Other Smaller Updates
We have also made a large number of other updates, these include the following –
- A ‘crawl canonicals‘ configuration option (which is ticked by default) has been included, so the user can decide whether they want to actually crawl canonicals or just reference them.
- Added new Googlebot for Smartphones user-agent and retired the Googlebot-Mobile for Smartphones UA. Thanks to Glenn Gabe for the reminder.
- The ‘Advanced Export’ has been renamed to ‘Bulk Export‘. ‘XML Sitemap‘ has been moved under a ‘Sitemaps’ specific navigation item.
- Added a new ‘No Canonical’ filter to the directives tab which helps view any html pages or PDFs without a canonical.
- Improved performance of .xlsx file writing to be close to .csv and .xls
- ‘Meta data’ has been renamed to ‘Meta Robots’.
- The SEO Spider now always supplies the Accept-Encoding header to work around several sites that are 404 or 301’ing based on it not being there (even though it’s not actually a requirement…).
- Allow user to cancel when uploading in list mode.
- Provide feedback in stages when reading a file in list mode.
- Max out Excel lines per sheet limits for each format (65,536 for xls, and 1,048,576 for xlsx).
- The lower window ‘URL info’ tab now contains much more data collected about the URL.
- ‘All links’ in the ‘Advanced Export’ has been renamed to ‘All In Links’ to provide further clarity.
- The UI has been lightened and there’s a little more padding now.
- Fixed a bug where empty alt tags were not being picked up as ‘missing’. Thanks to the quite brilliant Ian Macfarlane for reporting it.
- Fixed a bug upon some URLs erroring upon upload in list mode. Thanks again to Fili for that one.
- Fixed a bug in the custom filter export due to the file name including a colon as default. Oops!
- Fixed a bug with images disappearing in the lower window pane, when clicking through URLs.
I believe that’s everything! I really hope you like all the new features and improvements listed above. We still have so much planned and in our development queue, so there is plenty more to come as well.
As always, thank you all for your on-going support and feedback. Please do let us know about any bugs, issues or if there are any other features you’d like to see in the tool. Thanks all.






Pure awesomeness. Love the new features as I work a lot with writing and updating pages for clients.
Again, awesome work.
Magnifico – that SERP snippet editor is just marvellous, amazing as always guys and thank you!
Great update guys, the new editable SERPs Snippets is really great!
@Per, Ruth & Justin,
Thanks for the kind comments all, much appreciated.
Very cool to hear you like the snippet editor!
Dan
1. Could you offer guidance, perhaps a video tutorial, on how to use Screaming Frog to migrate a static html site into WordPress?
2. Do you need the paid subscription of Screaming Frog to gain the new features?
Hi Jeannie,
1) You can use the SEO Spider to crawl a static html site to gather URLs (alongside other sources, such as analytics landing pages, WMT link data etc) to then help put together a list of URLs to redirect for your site migration. The video guide we have on the SEO Spider page (https://www.screamingfrog.co.uk/seo-spider/) will show you how to crawl a site and gather the URLs.
For the rest of the actual migration, there are some good guides out there already – http://www.smashingmagazine.com/2013/05/15/migrate-existing-website-to-wordpress/. I hope this helps!
2) No, all the new features are in the free lite version.
Thanks!
Dan
This update looks awesome! Can’t wait try it. Thanks again for providing such a great tool!
Great job!
Any chance that you include the (host)name of the crawled website by default in the file exports? Maybe with the current date in front as well? Would love to see this in one of the next updates.
However: Great job!
Thanks Stephan!
Yeah we have that on the ‘todo’ list, agree it would be useful!
Cheers for the feedback.
Dan
Seeing many transitions in this new update, great! Well, I have also heard that Google is coming with “Penguin 3” in few weeks. If this is true then definitely “SERP” is affected. What you say?
Hi Sohil,
Thanks and yup – We have been expecting a Penguin update for sometime.
This means sites with low quality unnatural link profiles will get hit & those which have cleaned up have a chance to recover.
Cheers.
Dan
thanks for this (again).
will you be writing a case study about how offering a free seo tool has helped you rank for many seo-related terms?
Hi Chris,
No problem at all, hope you like it.
No, we won’t be writing a case study on this in particular.
But you’re right, I do think it’s a good example of how offering something of real value can get your brand talked about & hence perform well organically.
Cheers.
Dan
Great new features! SF is my top go-to diagnostic source for the audit work I do (my main business service). Keep up the great work !
Thanks Alan!
Nice one Dan, particularly pleased with the Ajax crawling – will be putting it through its paces today.
Thanks dude.
Found a small bug in AJAX crawling that you may not notice. Will have a fix up for early next week.
Hope you like it anyway!
Dan
“The SEO Spider now always supplies the Accept-Encoding header to work around several sites that are 404 or 301’ing based on it not being there (even though it’s not actually a requirement…).”
Can this be an option? Googlebot doesn’t supply this header, so to diagnose specific crawl problems it’s nice to be able to copy the bot (I recently saw a site which was serving Application/JSON content type when this header wasn’t specifying – browsers worked, bots choked.
Hey Fakename :-)
We could make this configurable.
That said, every scenario I’ve seen Googlebot dealt with this without any issue (interesting example above tho!).
Thanks for the feedback, will give some thought.
Dan
Update – We just did a quick test again and Googlebot does provide the Accept-Encoding header anyway with the same value as us. Feel free to drop an email to support@ if you have any other examples which differ.
Mega update Dan (and team!) – a big +1 for the “Crawl Overview Right Hand Window Pane” addition – just a note you need to drag this out from the right (or at least I did as it was hidden), in case ppl miss it. Perhaps show by default?
Thanks Depesh!
It *should* be open as default the first time of installing & opening. I will take a look though, thanks for mentioning.
Your preferences on whether it’s open or closed (you can use the little arrows to collapse or expand it) & window size etc is now all remembered & will default to your preference upon opening each time etc too.
Cheers.
How about making Screaming Frog SEO Spider an online tool. That would be great!
i like the new features :)
These new features are very useful! Thanks ScreamingFrog Team!
Can’t Thank you enough for the work you are providing. This updates are awesome.
I work with Screaming Frog daily and I really appreciate all the time and effort you put in keeping the tool up to date. Great new futures! Thanks guys!
Best SEO tool, really appreciate your work with it!
Staffan, Mohammed, Maurizio, Angelos, Werner & Tommy,
Thank you all for your comments!
The team and I are delighted you like the update, more to come.
Dan
Thank you for this wonderful tool!
Thank you so much for this!
everything is awsssssuuum!
Max out Excel lines per sheet limits for each format (65,536 for xls, and 1,048,576 for xlsx)
This was so helpful! Cheers
love the snippet but the ability to copy and paste in/out of the title/desc fields would be nice
Just found a piece of code blocking a client site by using this software…..great. I can read code but would not have checked every page. Looking at the other features now. Thanks team, I will look at paid version now. Would be interested in some pretty reports but I am a female so that is expected. Great work guys.
News update with the Ajex crawling. However I have a site that uses Ajax, but all the content is simply on the home page and the hashes act more like hash anchors. However its like screaming frog is assuming its using Ajax as outlined in Google guidelines – Its guessing the escaped fragment URLS when they dont actually exist. Yuop can see here: http://cinestyle.com.au/
Thanks Max.
We are doing exactly as Google do here. There isn’t any assuming going on, you opt into the AJAX crawling (See “Opting into the AJAX crawling scheme) on
https://developers.google.com/webmasters/ajax-crawling/docs/specification) by providing these urls (#!).
The section “Existing uses of #! section of https://developers.google.com/webmasters/ajax-crawling/docs/specification
covers what should be done if you want to opt out etc.
Thanks,
Dan
Wow These new features are very useful! I and the best is that it’s all free, Thanks ScreamingFrog Team! keep up the good work..
Love the new features…I work daily with SF and I really appreciate all the effort you put in this tool. Keep up guys….
Where exactly is the download link? I always have trouble finding it in your version update posts.
Hi Kyle,
You can just download it via the usual download buttons on the SEO Spider page which are updated when we publish the release blog post – https://www.screamingfrog.co.uk/seo-spider/
The SEO Spider also has an auto check for updates anyway, so it will alert you to download a new version when you start it.
Cheers.
Dan
It’s safe to say, I’m in love with Screaming Frog! I can’t tell you how much I appreciate these new updates.
I’m using OS X Yosemite beta – therefore I can’t run the latest version of Screaming Frog since Java 7 won’t install.
Do you have a page on your site where I can download an older version – 2.40 – of Screaming Frog? URL?
Hey Charley,
This should help –
https://www.java.com/en/download/help/mac_10_10.xml
Alternatively, you can revert to 2.4 here –
https://www.screamingfrog.co.uk/seo-spider/faq/#45
Cheers,
Dan
Simply Awesome! Great Work Guys!
Is there anyway to export the site structure at all?
Hi Daniel,
You can’t export yet unfortunately, it’s on our todo.
You can however highlight the table data, copy (control + c) and paste it though.
The graphs would have to be screenshots.
Cheers.
Dan
Hi everyone,
Just recently gave this tool a shot. I’m already loving it and considering the license.
Would pretty much appreciate some feedback on a concern I have.
After a site crawl, Screaming Frog is showing me some truncated page titles that indeed exceed the 512px mark. But, when I do the site:search on Google for that exact same URL the title is shorter and not truncated. Curiously, on the page itself (after checking the source code) the title is in fact as Screaming Frog extracted.
How is this happening?! I would like to present to my superiors the number of truncated Titles for this website but the SERP Snippet is not showing me exactly the same as Google’s site:search.
Thanks
Hi Pedro,
Thanks for the comment. You’re commenting on a post from back in May last year. So, I’d recommend reading – https://www.screamingfrog.co.uk/page-title-meta-description-lengths-by-pixel-width/ & https://www.screamingfrog.co.uk/an-update-on-pixel-width-in-google-serp-snippets/ for a bit of background, if you haven’t already.
Essentially, the SERP Snippet emulator is not exact and Google can do whatever they like at anytime.
In your case, it sounds like Google are actually not using the page title in the source code to construct the title you see in the Google SERPs. This is pretty common when it’s much larger than it should be, they will just rewrite it (http://searchengineland.com/advanced-seo-learning-experiments-using-googles-title-tag-changes-example-189850) and use whatever they like (which you might not!). Obviously we can’t copy that, that’s logic they have internally only ;-)
Google is less likely to rewite your title when it’s shorter & more relevant. So it sounds like you have some work to do!
I’d recommend using an info: command on a URL to check it’s SERP snippet, as I’ve found it to be a little more reliable.
Cheers.
Dan
Hey guys
Screaming Frog has always been a great application. Been using it for years with helping out clients with On Page SEO Audits and stuff.
Keep up the good work!
I’m missing the hability to edit snippets on 8.1. Was this removed or moved somewhere else?!
Hi Thiago,
This hasn’t changed, it’s exactly the same :)
There’s a SERP Snippet tab at the bottom.
Thanks,
Dan