Screaming Frog SEO Spider Update – Version 12.0
Dan Sharp
Posted 22 October, 2019 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 12.0
We are delighted to announce the release of Screaming Frog SEO Spider version 12.0, codenamed internally as ‘Element 115’.
In version 11 we introduced structured data validation, the first for any crawler. For version 12, we’ve listened to user feedback and improved upon existing features, as well as introduced some exciting new ones. Let’s take a look.
1) PageSpeed Insights Integration – Lighthouse Metrics, Opportunities & CrUX Data
You’re now able to gain valuable insights about page speed during a crawl. We’ve introduced a new ‘PageSpeed’ tab and integrated the PSI API which uses Lighthouse, and allows you to pull in Chrome User Experience Report (CrUX) data and Lighthouse metrics, as well as analyse speed opportunities and diagnostics at scale.

The field data from CrUX is super useful for capturing real-world user performance, while Lighthouse lab data is excellent for debugging speed related issues and exploring the opportunities available. The great thing about the API is that you don’t need to use JavaScript rendering, all the heavy lifting is done off box.
You’re able to choose and configure over 75 metrics, opportunities and diagnostics (under ‘Config > API Access > PageSpeed Insights > Metrics’) to help analyse and make smarter decisions related to page speed.

(The irony of releasing pagespeed auditing, and then including a gif in the blog post.)
In the PageSpeed tab, you’re able to view metrics such as performance score, TTFB, first contentful paint, speed index, time to interactive, as well as total requests, page size, counts for resources and potential savings in size and time – and much, much more.
There are 19 filters for opportunities and diagnostics to help identify potential speed improvements from Lighthouse.

Click on a URL in the top window and then the ‘PageSpeed Details’ tab at the bottom, the lower window populates with metrics for that URL, and orders opportunities by those that will make the most impact at page level based upon Lighthouse savings.
By clicking on an opportunity in the lower left-hand window panel, the right-hand window panel then displays more information on the issue, such as the specific resources with potential savings.
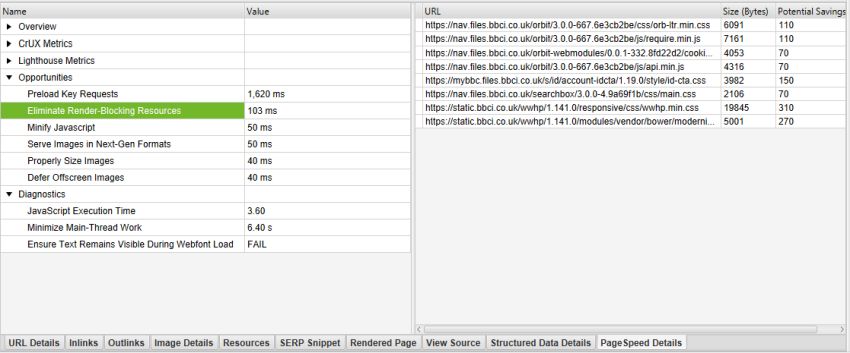
As you would expect, all of the data can be exported in bulk via ‘Reports‘ in the top-level menu.
There’s also a very cool ‘PageSpeed Opportunities Summary’ report, which summaries all the opportunities discovered across the site, the number of URLs it affects, and the average and total potential saving in size and milliseconds to help prioritise them at scale, too.
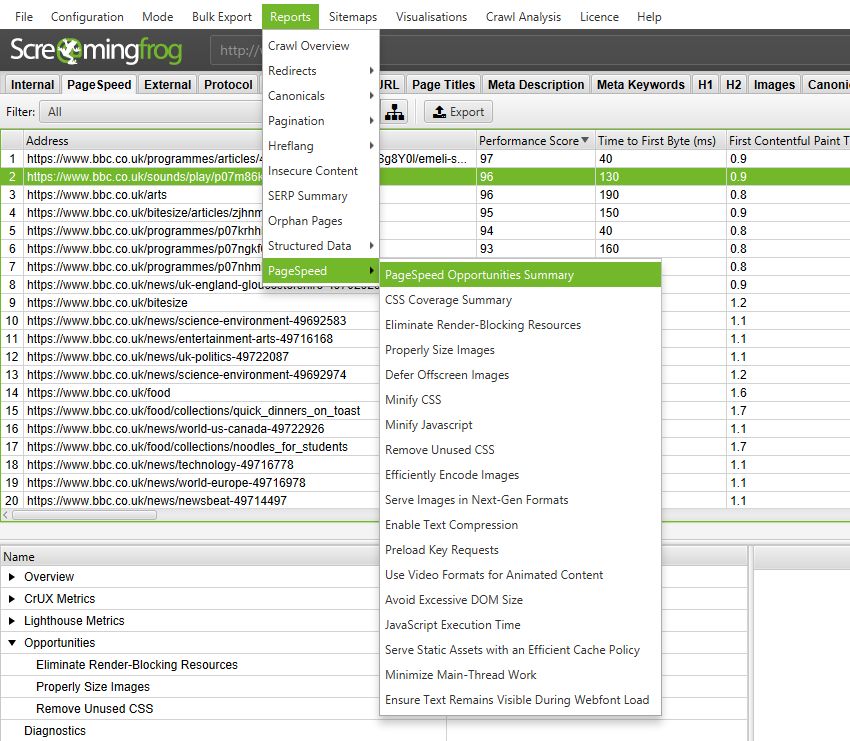
As well as bulk exports for each opportunity, there’s a CSS coverage report which highlights how much of each CSS file is unused across a crawl and the potential savings.
Please note, using the PageSpeed Insights API (like the interface) can affect analytics currently. Google are aware of the issue and we have included an FAQ on how to set-up an exclude filter to prevent it from inflating analytics data.
2) Database Storage Crawl Auto Saving & Rapid Opening
Last year we introduced database storage mode, which allows users to choose to save all data to disk in a database rather than just keep it in RAM, which enables the SEO Spider to crawl very large websites.
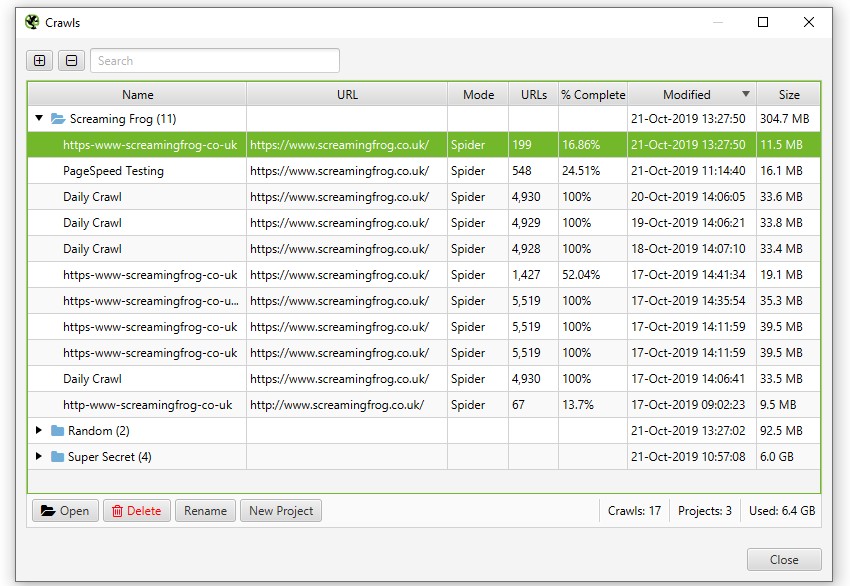
Based upon user feedback, we’ve improved the experience further. In database storage mode, you no longer need to save crawls (as an .seospider file), they will automatically be saved in the database and can be accessed and opened via the ‘File > Crawls…’ top-level menu.

The ‘Crawls’ menu displays an overview of stored crawls, allows you to open them, rename, organise into project folders, duplicate, export, or delete in bulk.
The main benefit of this switch is that re-opening the database files is significantly quicker than opening an .seospider crawl file in database storage mode. You won’t need to load in .seospider files anymore, which previously could take some time for very large crawls. Database opening is significantly quicker, often instant.
You also don’t need to save anymore, crawls will automatically be committed to the database. But it does mean you will need to delete crawls you don’t want to keep from time to time (this can be done in bulk).
You can export the database crawls to share with colleagues, or if you’d prefer export as an .seospider file for anyone using memory storage mode still. You can obviously also still open .seospider files in database storage mode as well, which will take time to convert to a database (in the same way as version 11) before they are compiled and available to re-open each time almost instantly.
Export and import options are available under the ‘File’ menu in database storage mode.
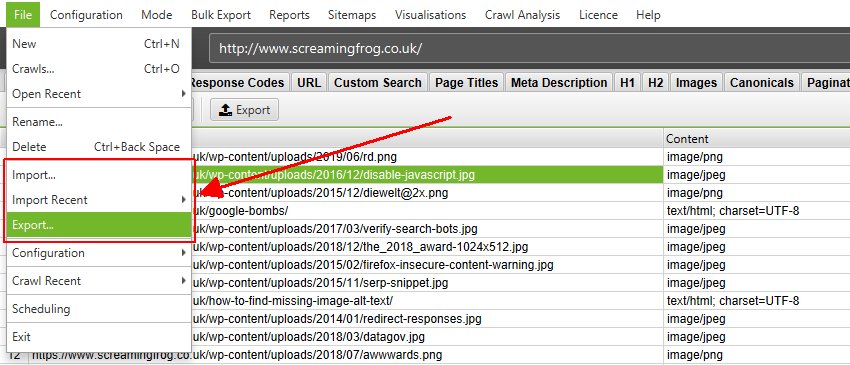
To avoid accidentally wiping crawls every time you ‘clear’ or start a new crawl from an existing crawl, or close the program – the crawl is stored. This leads us nicely onto the next enhancement.
3) Resume Previously Lost or Crashed Crawls
Due to the feature above, you’re now able to resume from an otherwise ‘lost’ crawl in database storage mode.
Do any other @screamingfrog users frequently shut down their machine at the end of the day and then remember they had a monster crawl running. Twice this week :(
— will king (@kingwill829) August 30, 2019
Previously if Windows had kindly decided to perform an update and restart your machine mid crawl, there was a power-cut, software crash, or you just forgot you were running a week-long crawl and switched off your machine, the crawl would sadly be lost forever.
The difference between me and AI is that AI wouldn't be stupid enough to close a two day crawl that is 92% complete on @screamingfrog pic.twitter.com/BRsnqFhQYs
— Steph Whatley (@SEOStephW) October 7, 2019
We’ve all been there and we didn’t feel this was user error, we could do better! So if any of the above happens, you should now be able to just open it back up via the ‘File > Crawls’ menu and resume the crawl.
Unfortunately this can’t be completely guaranteed, but it will provide a very robust safety net as the crawl is always stored, and generally retrievable – even when pulling the plug directly from a machine mid-crawl.
4) Configurable Tabs
You can now select precisely what tabs are displayed and how they are ordered in the GUI. Goodbye forever meta keywords.
The tabs can be dragged and moved in order, and they can be configured via the down arrow icon to the right-hand side of the top-level tabs menu.
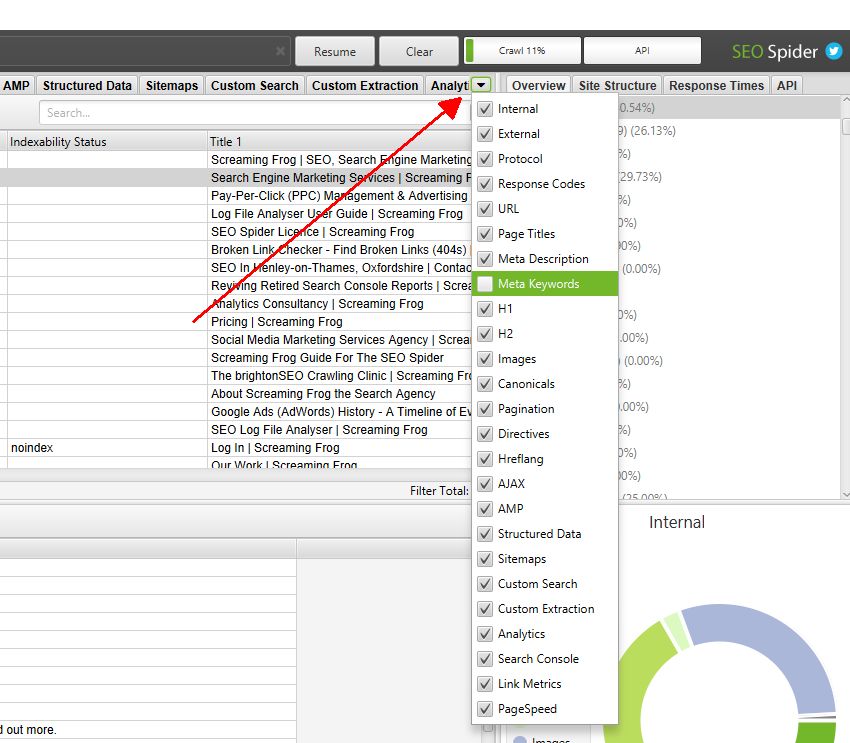
This only affects how they are displayed in the GUI, not whether the data is stored. However…
5) Configurable Page Elements
You can de-select specific page elements from being crawled and stored completely to help save memory. These options are available under ‘Config > Spider > Extraction’. For example, if you wanted to stop storing meta keywords the configuration could be disabled.
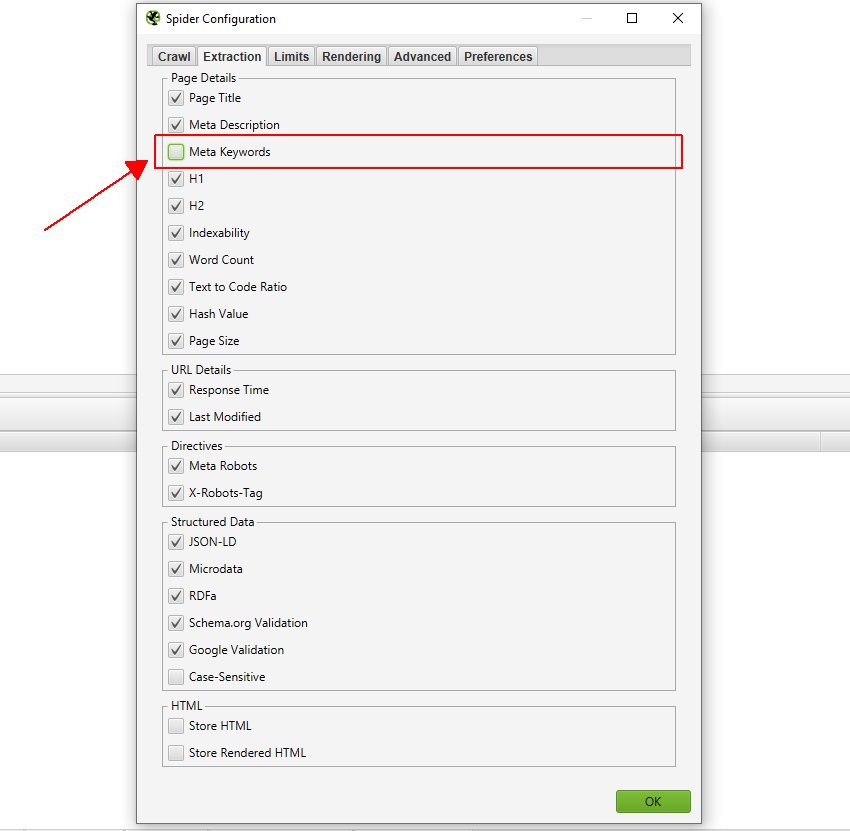
This allows users to run a ‘bare bones’ crawl when required.
6) Configurable Link Elements For Focused Auditing In List Mode
You can now choose whether to specifically store and crawl link elements as well (under ‘Config > Spider > Crawl’).
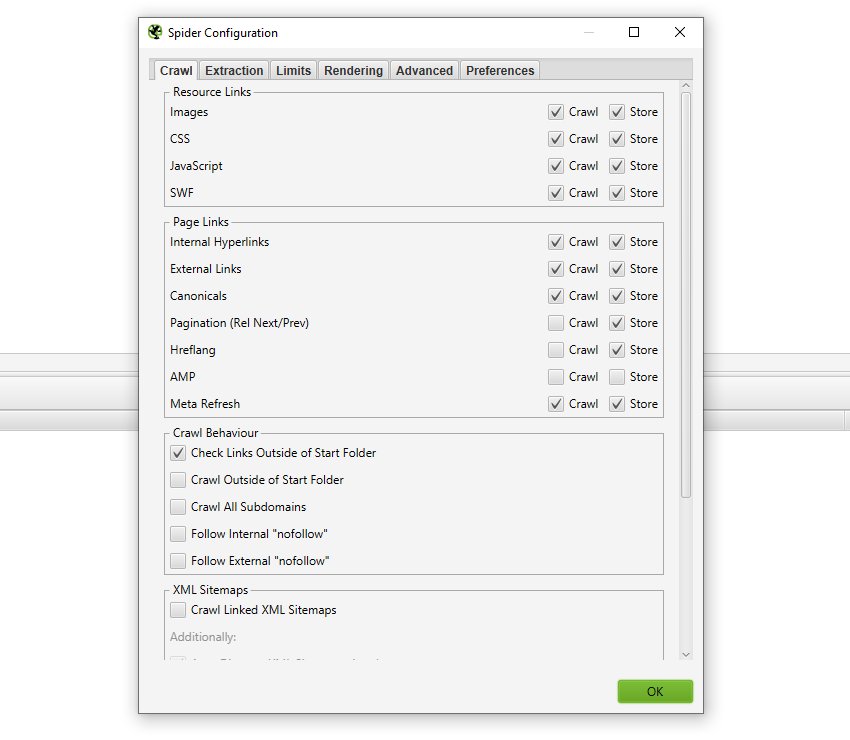
This enables the SEO Spider to be infinitely more flexible, particularly with the new configurable ‘Internal hyperlinks’ configuration option. This becomes really powerful in list mode in particular, which might not be immediately clear why at face value.
However, if you deselect ‘Crawl’ and ‘Store’ options for all ‘Resource Links’ and ‘Page Links’, switch to list mode, go to ‘Config > Spider > Limits’ and remove the crawl depth that gets applied in list mode, you can then choose to audit any link element you wish alongside the URLs you upload.
For example, you can supply a list of URLs in list mode, and only crawl them and their hreflang links only.
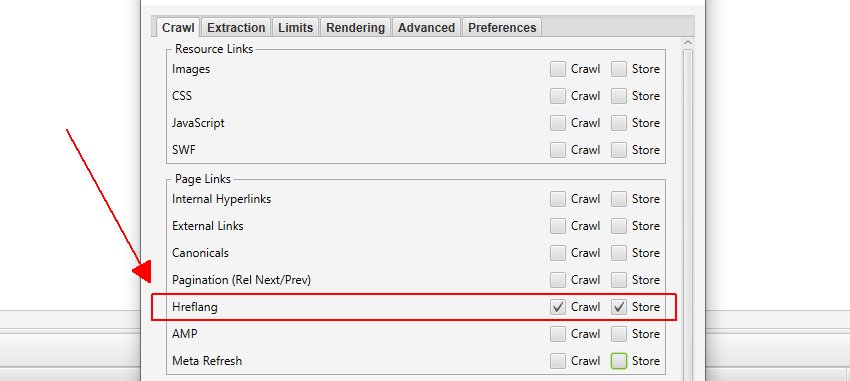
Or you could supply a list of URLs and audit their AMP versions only. You could upload a list of URLs, and just audit the images on them. You could upload a list of URLs and only crawl the external links on them for broken link building. You get the picture.
Previously this level of control and focus just wasn’t available, as removing the crawl depth in list mode would mean internal links would also be crawled.
This advanced configurability allows for laser focused auditing of precisely the link elements you require saving time and effort.
7) More Extractors!
You wanted more extractors, so you can now configure up to 100 in custom extraction. Just click ‘Add’ each time you need another extractor.
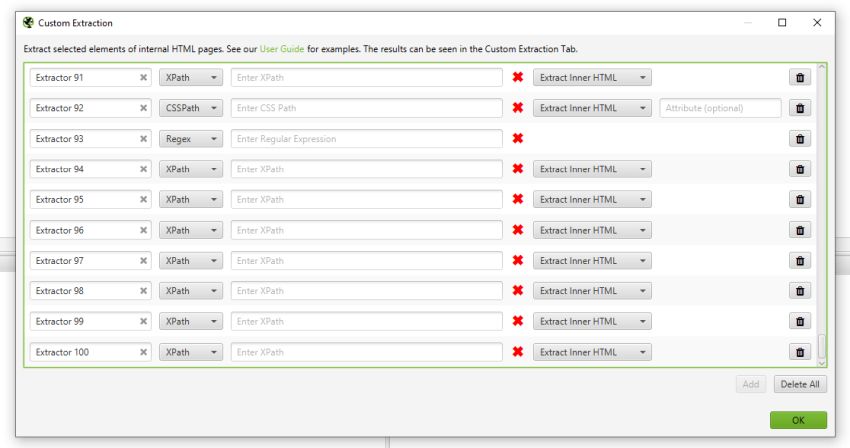
Custom extraction also now has its own tab for more granular filtering, which leads us onto the next point.
8) Custom Search Improvements
Custom Search has been separated from extraction into its own tab, and you can now have up to 100 search filters.
A dedicated tab allows the SEO Spider to display all filter data together, so you can combine filters and export combined.
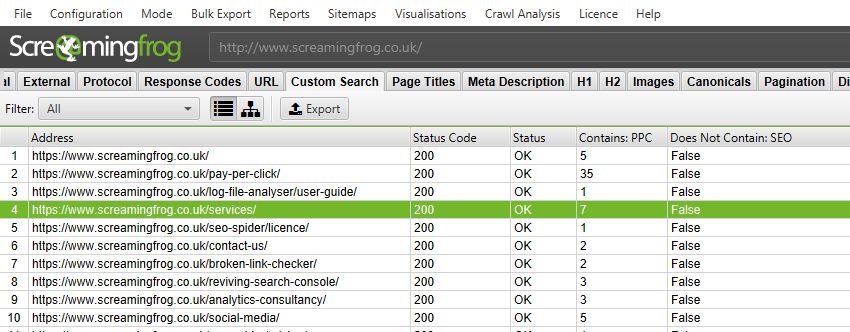
We have more plans for this feature in the future, too.
9) Redirect Chain Report Improvements
Based upon user feedback, we’ve split up the ‘Redirect & Canonical Chains’ report into three.
You can now choose to export ‘All Redirects’ (1:1 redirects and chains together), ‘Redirect Chains’ (just redirects with 2+ redirects) and ‘Redirect & Canonical Chains’ (2+ redirects, or canonicals in a chain).
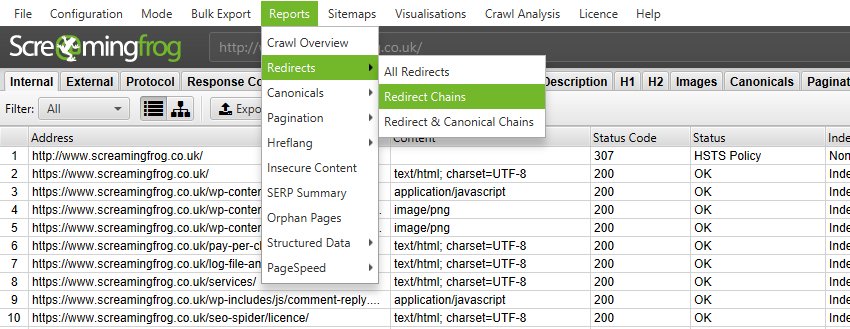
All of these will work in list mode when auditing redirects. This should cover different scenarios when a variety of data combined or separated can be useful.
Other Updates
Version 12.0 also includes a number of smaller updates and bug fixes, outlined below.
- There’s a new ‘Link Attributes’ column for inlinks and outlinks. This will detail whether a link has a nofollow, sponsored or ugc value. ‘Follow Internal Nofollow‘ and ‘Follow External Nofollow‘ configuration options will apply to links which have sponsored or ugc, similar to a normal nofollow link.
- The SEO Spider will pick up the new max-snippet, max-video-preview and max-image-preview directives and there are filters for these within the ‘Directives‘ tab. We plan to add support for data-nosnippet at a later date, however this can be analysed using custom extraction for now.
- We’re committed to making the tool as reliable as possible and encouraging user reporting. So we’ve introduced in-app crash reporting, so you don’t even need to bring up your own email client or download the logs manually to send them to us. Our support team may get back to you if we require more information.
- The crawl name is now displayed in the title bar of the application. If you haven’t named the crawl (or saved a name for the .seospider crawl file), then we will use a smart name based upon your crawl. This should help when comparing two crawls in separate windows.
- Structured data validation has been updated to use Schema.org 3.9 and now supports FAQ, How To, Job Training and Movie Google features. We’ve also updated nearly a dozen features with changing required and recommended properties.
- ga:users metric has now been added to the Google Analytics integration.
- ‘Download XML Sitemap’ and ‘Download XML Sitemap Index’ options in list mode, have been combined into a single ‘Download XML Sitemap’ option.
- The exclude configuration now applies when in list mode, and to robots.txt files.
- Scroll bars have now been removed from rendered page screenshots.
- Our SERP snippet emulator has been updated with Google’s latest changes to larger font on desktop, which has resulted in less characters being displayed before truncation in the SERPs. The ‘Over 65 Characters’ default filter for page titles has been amended to 60. This can of course be adjusted under ‘Config > Preferences’.
- We’ve significantly sped up robots.txt parsing.
- Custom extraction has been improved to use less memory.
- We’ve added support for x-gzip content encoding, and content type ‘application/gzip’ for sitemap crawling.
- We removed the descriptive export name text from the first row of all exports as it was annoying.
That’s everything. If you experience any problems with the new version, then please do just let us know via our support and we’ll help as quickly as possible.
Thank you to everyone for all their feature requests, feedback, and bug reports. We appreciate each and every one of them.
Now, go and download version 12.0 of the Screaming Frog SEO Spider and let us know what you think!
Small Update – Version 12.1 Released 25th October 2019
We have just released a small update to version 12.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Fix bug preventing saving of .seospider files when PSI is enabled.
- Fix crash in database mode when crawling URLs with more than 2,000 characters.
- Fix crash when taking screenshots using JavaScript rendering.
- Fix issue with Majestic with not requesting data after a clear/pause.
- Fix ‘inlinks’ tab flickering during crawl if a URL is selected.
- Fix crash re-spidering a URL.
- Fix crash editing text input fields with special characters.
- Fix crash when renaming a crawl in database mode.
Small Update – Version 12.2 Released 1st November 2019
We have just released a small update to version 12.2 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Improved performance of opening database crawls.
- Aggregate Rating and Review Snippet property names updated.
- Fix regression in parsing of XML sitemaps missing opening XML declarations.
- Fix issue loading saved list mode crawl opens in Spider mode.
- Remove API error pop-ups. The number of errors can still be seen in the API tab, but better reporting to come.
- Fix crash sorting tables in some situations.
- Fix crash displaying GSC configuration.
- Fix crash changing custom filters in paused crawl.
- Fix issue with PageSpeed details saying ‘not connected’, when you are.
- Fix crash taking screenshots during JavaScript rendering.
- Fix crash when renaming a database crawl with multiple SEO Spider instances open.
- Fix crash starting a crawl with an invalid URL for some locales.
- Fix crash showing PSI data
- Fix crash caused by illegal cookie names when using JavaScript rendering.
Small Update – Version 12.3 Released 28th November 2019
We have just released a small update to version 12.3 of the SEO Spider. This release is mainly bug fixes and small improvements –
- You can now use a URL regular expression to highlight nodes in tree and FDD visualisations i.e. show all nodes that contain foo/bar.
- PageSpeed Insights now show errors against URLs including error message details from the API.
- A (right click) re-spider of a URL will now re-request PSI data when connected to the API.
- Improve robustness of recovering crawls when OS is shutdown during running crawl.
- Fix major slow down of JavaScript crawls experienced by some macOS users.
- Fix windows installer to not allow install when the SEO Spider is running.
- Fix crash when editing database storage location.
- Fix crash using file dialogs experienced by some macOS users.
- Fix crash when sorting columns.
- Fix crash when clearing data.
- Fix crash when searching.
- Fix crash undoing changes in text areas.
- Fix crash adjusting sliders in visualisations.
- Fix crash removing/re-spidering duplicates titles/meta descritions after editing in SERP View.
- Fix crash in AHREFs API.
- Fix crash in SERP Panel.
- Fix crash viewing structured data.
Small Update – Version 12.4 Released 18th December 2019
We have just released a small update to version 12.4 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Remove checks from deprecated Google Features.
- Respect sort and search when exporting.
- Improved config selection in scheduler UI.
- Allow users without crontab entries to schedule crawls on Ubuntu.
- Speed up table scrolling when using PSI.
- Fix crash when sorting, searching and clearing table views.
- Fix crash editing scheduled tasks.
- Fix crash when dragging and dropping.
- Fix crash editing internal URL config.
- Fix crash editing speed config.
- Fix crash when editing custom extractions then resuming a paused crawl.
- Fix freeze when performing crawl analysis.
- Fix issues with GA properties with + signs not parsed on a Mac.
- Fix crash when invalid path is used for database directory.
- Fix crash when plugging in and out multiple screens on macOS.
- Fix issue with exporting inlinks being empty sometimes.
- Fix issue on Windows with not being able to export the current crawl.
- Fix crash on macOS caused by using accessibility features.
- Fix issue where scroll bar stops working in the main table views.
- Fix crash exporting .xlsx files.
- Fix issue with word cloud using title tags from svg tags.
Small Update – Version 12.5 Released 28th January 2020
We have just released a small update to version 12.5 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Update Googlebot User Agent strings to include latest Chrome version.
- Report 200 ‘OK’ URLs that are redirected by PSI in the PSI Error Column.
- Update Structured Data validation to account for Google Receipe changes.
- Fix bug in PSI causing it to request too fast when faced with slow responeses from the API.
- Fix broken visualisations export when it contains diacritical characters.
- Fix issue loading in a crawl with PSI data in database mode.
- Fix issue with column ordering is not persisted.
- Fix crash due to corrupt configuration file.
- Fix crash when running out of disk space in a database crawl.
- Fix crash pasting in robots.txt files.
- Fix crash switching mode when no tabs are selected.
- Fix crash in speed configuration UI.
- Fix crash when sorting/searching tables.
- Fix crash in PSI when server response is slow.
- Fix crash removing/re-spidering URLs.
Small Update – Version 12.6 Released 3rd February 2020
We have just released a small update to version 12.6 of the SEO Spider with new data now available from the Ahrefs API. The release includes –
- Keywords, traffic and value data, which is now available courtesy of the Ahrefs API. This can be configured under ‘Config > API Access > Ahrefs > Metrics’. This data can be selected for the URL, subdomain and root domain.






Really nice update. Glad to see that! :)
PageSpeed Insights and Redirect Chains – great that it was introduced. It will speed up and automate work very much. Good job!
Screaming Frog is the best, thank you for the great updates.
The long awaited autosave! You guys just made my day!
Damn that’s a great update, awesome work guys!
Amazing features have arrived. We were waiting to update. It’s finally here.
Great news! The autosave feature will really help for those times it crashes or Windows 10 decides to do a Windows update. The next feature I’d love to see is comparisons between two different crawls for the same site.
That’s the coolest update ever :)
Well done team! Some significant enhancements in this version which all look really interesting and useful!
Phenomenal update, it’s like Christmas in October!!
Nice update! Would love to see some improvement of the CLI version of screamingfrog as well.
Best and most valuable seo tool in town!
Thanks, Simon!
Any particular improvements you’d like to see to the CLI?
Cheers.
Dan
Well done! Thanks mates!
Massive update, lots of great things to discover. Keep up the phenomenal work!
OMG .. PageSpeed Insights Integration is amazing ….
thank you
thank you
thank you
Glad to know, now we can resume crawl as required! :)
Oh yes! Thanks for these new features!
Love this update! Such nice new features, great improvement!
Cracking update – The PageSpeed Insights API integration will save me so much time… can ditch my custom sheets now. Brilliant job guys.
3) Resume Previously Lost or Crashed Crawls
i love this feature!!
Really great update, thanks a lot, guys! Love the PSI integration and the update with Schema 3.9 :) God bless you!
Very nice update, guys especially on the page speed. I wanted to know if this option can be used simultaneously with WPRocket, Autoptimize and Power CSS? Also, will Screaming Frog help me out with soft 404 google indexing errors?
I must say, some great improvements here. For me, by far, is the auto saving of the crawls. This will make things much easier in many situations!
suggestion for next blog post: “how to creat api for pagespeed on screaming frog, step by step”
Just go to https://developers.google.com/speed/docs/insights/v5/get-started and press button “Get a Key” (note: you should be logged in your Google account).
Hi John,
We have a guide here – https://www.screamingfrog.co.uk/seo-spider/user-guide/configuration/#pagespeed-insights-integration
Actually, it’s a slightly different way of doing it than Bohdana’s method, but both work nicely! (Thanks Bohdana!).
Cheers.
Dan
Lovely, a lot of things I didn’t even know I wanted!
PageSpeed is also highly interesting, which Lighthouse version is it using? Just a quick warning: unused CSS and JS is not fully accurate till you have tried to activate all events on a page. Chrome allows you to record the unused CSS and JS in the coverage tool (chrome dev -> more tools) while you try to activate all potential actions.
Good update!
Hope to see next update (random order):
1. When we select few rows (may be few cells from rows) – wanna see number of selected rows near Filter Total (Excel-alike)
2. Most of scrollable tables should have numbering column
3. Automate bulk after-all-crawl-and-analysis export with something, implemented like Crawl Analysis, where we could select reports to export. Or even combine it with general idea of Layout templates implemented under File->Confuration->SaveAs. Later we could select Set of reports for export.
4. Indicate somehow Zero lines in exportable report (0)
5. Add column tag summary, like H1:1;H2:3…H6:0.
6. In custom search add ability to count search term
7. In the overview tab (right hand) add a little button before Overview tab – Hide/Unhide all to unclutter too mach opened and actioinaly unused bullets.
7a. Pro option – let user change order of blocks on the right hand window
8. Add option to export In fact ready-to-use images/charts with reports [option for image size is also good idea]. I mean Images/Chart we see in the right hand overview window..
9. Add option to manually specify common prefix to all exportable reports in current crawl. In tabs – additional button near filter – Export with prefix
10. Add option to select and copy to buffer all table, or selected collumns – now it is sorting when press on column header – impossible to select column or few. U will need to use SHIFT+arrows to select column cells.
10a – I think this is a bug: U can select cells by using SHIFT+arrows and Frog will select cell by cell instead of process it like table’s rows and columns. Here an example: http://prntscr.com/pnaz99
10б – When during crawling click to sort by some column – it continue to sort after each and every new URL crawled till the end. And it can’t be stoped. It EAT memory and CPU. Some option is needed. May be ability to sort by numbering column. Or just not continue sorting after initial one.
11. Conditional formatting of cell’s background/font color in the tables (like in Excel) would be fantastic
12. Images section: with Alt attribute there are two stories – MISSING attribute and EMPTY text. Hope to see both stories.
13. When we add Custom Filter – Let us give filter a descriptive name and select what we will see as a result – some custom TEXT or Number of Occurencies of search term AND add CHECK BOX to append as a Custom column (Header is Filter name) to the aplicable table [Dropdown]. Instead of dropdown in filter settings may be add to the list of Columns to Show/Hide [now it is “+” icon next to the most right visible column header]. We use it to find iframes, analytics code, code snippets… and add it to internal HTML reports.
14. To redirects: add column to indicate if any External domain involved or it is just internal hops.
(Example for column flag: IEE – start link Internal url then redirects to External url … hops … last point is External. so Internal-External-External (IEE). And so on…)
15. Ability to apply/re-apply custom filter AFTER crawl (if HTML stored).
Hope i’m not the only one vote for these options )
Hi Kirill,
This is an awesome list, thank you so much for taking the time to write them all out.
I just wanted to reply to each of them, so you know where we are and what’s on the list –
1. This is on the list!
2. This is on the list!
3. We’ve got something like this on the list. You can do it now via scheduling, but I think we can do a better job here.
4. We plan on trying to get anything that’s in a report only into the GUI. Or at least as you say, show whether there’s anything in it better.
5. Cool idea, will consider for the dev list.
6. This is available now. If you run a contains for say ‘SEO’, it comes back with the number in the column :-)
7. Good idea. You can expand or condense each element via the down arrows, but be cool to do this in bulk.
7a. I like this too. You can actually do this now – If you change the order of the tabs at the top (or remove those you don’t want). The right hand window will copy it :-)
8. This is on the list!
9. Cool idea, will consider for the dev list.
10. Cool idea, will consider for the dev list.
10a – That might be a bug. Shift should highlight blocks, control should highlight individual cells. Which seems to be the case for me, so will see if I can work out what’s happening here.
10б – If you click to sort twice more, it will stop. It sorts twice alphabetically for example for the Address column, and the 3rd time it goes back to the usual crawl order state.
11. Cool idea, will consider for the dev list.
12. This is on the list!
13. Check out the new custom search report, I think it does what you want. Let me know if not :-)
14. Makes sense, would be easy to include for us.
15. This is on the list (for custom search and extraction :-)
Thanks again for all the feedback, much appreciated.
Dan
Good to know that we’re on the same page, Dan!
#13 :) It’s not
Imagine you perform search for long code-snippet in HTML code – you will get Ugly Column header in the report like “Custom filter: LONG-UGLY-BS-HEADER-SCROLL-TILL-MORNING-TO-THE-NEXT-COLUMN”
That’s why suggestion was to let user define Future column’s Header (default if not specified by user)
next: Look on current Custom report’s columns: Which of them is really useful?
May be i’m completely wrong …
Are we perform search only in HTML? If So… we will see URLs in this report IF and ONLY IF the Satus code is 200 and Status code is OK.
next part was about: If user will be able to choose what will appear (Occurrences or specified TEXT) – it will be more flexible. Some time we want to mark the fact, that search term is there and mark it all in the same key. Hope you got the point.
and finally: Imagine now you have only useful columns (#filers +1 URL). And there other tabs like Internal HTML, External HTML (I named them aplicable tables in my #13 suggestion), where user would like to see filter result as additional columns.
So you will need just repeat what you previousely done with GA data – merge custom and aplicable tables by URL as a KEY.
In case of Occurrence option fill empty cell with 0 or leave it blank. If user specified TEXT options – then fill with specified TEXT (may be with another specified TEXT for NOT FOUND case. Of cause we do that only for Status-code-200 URLs in aplicable tables.
Also i mentioned about adding Custom Columns to the dropdown menu related to aplicable tables to include or not Custom filter’s columns.
Not quite sure if my explanations are clear enough.
Kirill
Hi Kirill,
Thanks for the following up, that’s a cracking explanation and provides more clarity definitely.
I’ll add this conversation to the custom search enhancements item we have in our queue, so we can review properly.
We’ve got things like configurability around being able to search in all HTML, just rendered text, or particular HTML elements etc as well.
Appreciate your thoughts – super helpful!
Cheers.
Dan
PageSpeed – finally!!! :)
PageSpeed Insights Integration and Auto Saving sounds delicious!
Great update and great new features :D Will be great for our projects the new possibilities you offer! Thanks!
Thanks, super!
12.0 Crashed lack of memory in memory mode – message after restart http://prntscr.com/po2g1f
Pause on high memory usage was ON.
GSC+GA ON. Ajax rendering ON. Approx 700k was crawled out of 1.8m in queue. :((
5 custom filters, no HTML store
Please double check accurate memory allocation pre-calculation for pause warning.
Cheers, Kirill. If you’re able to send your logs though to [email protected] we can nail down whether there was a spike, and for what reason.
Have you thought about using database storage mode?
It can crawl significantly more, and if there is a problem, you won’t lose your crawl.
Thanks,
Dan
Woaw ! ..
beautiful update!
For the moment, I do not have any more crashes during the crawl of medium / big site :CrossedFinger:
Thank you !
Hello, there is a problem.
Why is the problem caused?
—
Reason: java.io.IOException: Server returned HTTP response code: 500 for URL:
Hi Ahmet,
Have a read of this FAQ I put together for this error in PSI API – https://www.screamingfrog.co.uk/seo-spider/faq/#why-do-i-receive-an-external-api-error-request-failure-pop-up-for-pagespeed-insights
Cheers.
Dan
Hi, Is that PSI score for desktop or mobile? If I send mobil user agent, then can I assume that it is mobile score?
It looks like desktop, I am just confused.
Thanks
Hi Hulya,
Take a look at the second screenshot in this post, where we show the configuration options for PSI.
At the top, you can switch device between desktop and mobile.
This is under ‘Config > API Access > PageSpeed Insights > Metrics’.
Cheers.
Dan
Well done team screaming frog. It is a great update.!
Great work with really useful implementations on v12.0 – thanks!
Hi, Dan
I use now external SSD – will see how it will eat big site
btw: I paused crawl, and sorted by timeout status – to mark 150 URLs for re-spider.
And it removing it almost an hour already… and continue sorting after each URL removed
anyway – it so so slow… Expected removing for re-spider will takes few seconds.
here is screenshot – http://prntscr.com/ppvngl
May be on small sites its OK, but for big DB – it takes very long time
Please optimize algorithm )
Hi Kirill,
Any chance you could pop this through to us with your logs via [email protected]?
We’ll give it a test our end, but be useful to see your logs as well.
Cheers.
Dan
and more:
would be nice if SF will remember status of crawling.
I paused crawl to remove URL from several section for re-spidering and it started to crawl right after removing first.
I wanted to remove more for respider and then continue to crawl.
Now i have to click Pause after each pack of URLs marked for re-spider….
Cheers, Kirill – we’ve got this one on the list, as it re-spiders the URLs selected, and continues crawling URLs in the queue currently.
Nice work. :)
That’s a lot of boxes to untick/tick though. Could we have an ‘uncheck all’ box on spider configuration?
Really cool update :)
Hi everybody,
I am wondering where the coloumn H1-2 has gone? Is it only me missing it? Would be happy to receive some feedback :-)
Hey Louise,
It’s still there, but it only appears if you have multiple h1s.
So it sounds like you just have a single h1 on that crawl (congrats ;-)
Cheers.
Dan
Yeah thank you for the quick reply :-) I will forward the praise.
Hey, Dan!
Any chance in the next quick update: highlight raw where cursor is located and stick line number column?
Today after main crawl i retrieved API data for PageSpeed -> paused to continue later. Switched off notebook. Later open previously paused crawl and see only zero in the overview window and all tables related (data in Internal tab and PageSpeed tab in bottom window is OK). Also there were no Resume button, Only Start..
Hi Kirill,
We’ve got that one on the list! I can’t say for sure it will be in the next one, but it’s been raised to review for it.
On the API for PageSpeed – You should be able to resume the crawl, but at the moment we don’t let the user know that they were connected to an API. So you can reconnect, and the resume should mean the API is queried again and continues requesting data. But we have some improvements planned here. Not being able to resume, and having zero data in the overview window sounds like a bug, and it’s not one we know about. If you could send on through to us via support ([email protected]) with your logs (Help > Debug > Save Logs) we’d love to take a look.
Cheers.
Dan
Update, finally waited!
PageSpeed cool and structured data validation – cool!
Thanks
Hi very good updates! I have a scrapping problem (in 12.2) which was not present in version 9. Custom extraction xpath with parameter does not give any data for ” //*[@id=”tads”]/ol/li[1]/div[2] ” while in version 9. it was working propely. Is it a bug? Or should I change the paramater which I copied directly from chrome?
Thanks
Hi Krisztian,
You’ll need to pop through the example URL to us at support –
https://www.screamingfrog.co.uk/seo-spider/support/
Cheers.
Dan
Hi, Dan!
Any chance to add Yandex API? [ Yandex has version API compatible with Google Analytics Core Reporting API (v3) ]
Thanks in advance )
Hi Kirill,
Thanks for the suggestion! We’ve got this one on the ‘todo’ list :-)
Cheers.
Dan
Hey, Dan!
Bag: Open Saved Crawl (Disk Storage) with few custom search filters results. Add another custom search filter. Press OK. It will clear all current search results in overview window. Unexpected…
To restore custom filters results U need to reopen saved Crawl.
.
Hi Kirill,
I am just going to test this one, thanks for mentioning!
Cheers.
Dan
This update is epic! Being able to just crawl and store aspects like hreflang from a list of URLs is so useful (especially for me right now with an existing audit). So impressed with each update, keep them coming :)
Hi Michelle,
Thank you! Really pleased you’re enjoying the granular control over auditing in list mode, it’s really powerful (and was much needed).
Cheers.
Dan
best tool ever
thank you very much
Really good update, thanks guys.
I notice that the maximum page title limit has changed from 65 to 60. Is there a reason / have you read something somewhere from Google pros?
Great update.
Now I have my SEO power, 10x
Thanks a lot
And see you soon ScreamingFrog
Federico
Very good tool
Does your program scan svg-graphics?
Оn the page mql5.com/en/signals/561919 I want to parse this value:
http://i.piccy.info/i9/3c84ccd6b0057370f9dc919132f03285/1575534068/20628/1350956/05_12.png
This is svg graphics.
If I press F12 in the browser, it shows this:
http://i.piccy.info/i9/93cf851e7d3ef3e5351d2831ccbd8ef8/1575534295/59757/1350956/05_122.png
What XPath request should I ask?
Hi Danminin,
Pop us an email via support (https://www.screamingfrog.co.uk/seo-spider/support/) and we can help.
Cheers.
Dan
Good day!
Tell me how to exclude pagination from reports, an example:
/feedbacks/?PAGEN_1=3
/feedbacks/?PAGEN_1=2
or
/boksy/?PAGEN_1=4
/catalog/boksy/?PAGEN_1=3
1) If I block in “Excludes”, then it is possible that the spider will not scan all the goods in this section
2) And if I remove these pages /?PAGEN_1=2 – this is a very long time
Hi Insomnia,
If you need to crawl paginated pages to discover products, then there might not be another way around it I am afraid.
If you exclude them, then products in the section won’t be discovered etc.
You could exclude them if products can be found elsewhere (for example, via XML Sitemaps, or GSC/GA integration etc).
Feel free to get in touch with our support with the specific site details if you’d like us to take a closer look.
Cheers.
Dan
Perhaps then for the field “Enter a regular expression to filter the results” it will be possible to use negation (NOT or !)
This tool helps me a lot. THANKS
Very cool and excellent update..
Hey
12gb with 8gb for ScreamingFrog 12.3 in database storage mode, external SSD via usb 3.0
1) store html source is switched off but for 880 K url database size is over 40Gb. May be SF actually store html in db..?… What else it may be?
2) border 12% of crawl analysis cannot be passed for 48 hours of processing.
3) i mentioned that earlier but it is still faster to perform full recrawl even for big site than opt remove urls from existing crawl. Something is wrong in algorithm.. And more – i recrawled 40gb scan (because of #2). Instead of removing urls after scan i added them to exclude during scan. DB size of new scan became 45.8Gb
4) after removing 250K urls from crawl – folder size of db remains the same all the time.
.
is that known bugs?
Thanks in advance
Hi Kirill,
Sorry, do you mind sending these through to support please? I read your comment, then forgot to respond – so apologies!
Just to answer now –
1) Internal linking is a major factor in size. So if there’s lots of sitewide linking, or if there’s hreflang, you’re using JS rendering etc. If you want to share the site via support, we can tell you why.
2) There is a bug in link score currently. Stop the crawl analysis, untick link score from the options, and start it again – it should now complete quite quickly!
3) We will have another look at ‘remove’ URLs for large crawls.
4) I think you’d need to share logs with us for the crawls ([email protected]) and so we can find out a bit more.
Cheers,
Dan
Really thanks for fixing all the bugs in the previous version.
It would be useful, in next release, to have the possibility to send the .xlsx exports directly via email (as an attachment) when a scheduled crawl is finished.
What do you think about?
Great Job! My best crawler!
I always think it’s impossible… but version by version you keep getting better. Looking forward to 13.0. Thanks for making our job easier!
Nice work!
I love to work on Screamingfrog, but I would love that you launch more products related to SEO.
Appreciate your work guys! I use screaming from on daily basis at my SEO Agency BrandRise. It’s actually cool that it spits out all those important data. And ofcourse it’s one time paid tool. It was good version. Appreciate recent update to v13 Screaming Frog seo crawler.
Best regards
BrandRise SEO agency from Toruń Poland
Screaming Frog is the best crawler ever :D i’m using this everytime i have new website to work on
Best program for audit
Best program ever
One of the coolest update ever :) Great to hear, that Screaming Frog advances. My favourite tool.