Screaming Frog SEO Spider Update – Version 9.0
Dan Sharp
Posted 26 February, 2018 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 9.0
I’m delighted to announce the release of Screaming Frog SEO Spider 9.0, codenamed internally as ‘8-year Monkey’.
Our team have been busy in development working on exciting new features. In our last update, we released a new user interface, in this release we have a new and extremely powerful hybrid storage engine. Here’s what’s new.
1) Configurable Database Storage (Scale)
The SEO Spider has traditionally used RAM to store data, which has enabled it to have some amazing advantages; helping to make it lightning fast, super flexible, and providing real-time data and reporting, filtering, sorting and search, during crawls.
However, storing data in memory also has downsides, notably crawling at scale. This is why version 9.0 now allows users to choose to save to disk in a database, which enables the SEO Spider to crawl at truly unprecedented scale for any desktop application while retaining the same, familiar real-time reporting and usability.
The default crawl limit is now set at 5 million URLs in the SEO Spider, but it isn’t a hard limit, the SEO Spider is capable of crawling significantly more (with the right hardware). Here are 10 million URLs crawled, of 26 million (with 15 million sat in the queue) for example.

We have a hate for pagination, so we made sure the SEO Spider is powerful enough to allow users to view data seamlessly still. For example, you can scroll through 8 million page titles, as if it was 800.

The reporting and filters are all instant as well, although sorting and searching at huge scale will take some time.

It’s important to remember that crawling remains a memory intensive process regardless of how data is stored. If data isn’t stored in RAM, then plenty of disk space will be required, with adequate RAM and ideally SSDs. So fairly powerful machines are still required, otherwise crawl speeds will be slower compared to RAM, as the bottleneck becomes the writing speed to disk. SSDs allow the SEO Spider to crawl at close to RAM speed and read the data instantly, even at huge scale.
By default, the SEO Spider will store data in RAM (‘memory storage mode’), but users can select to save to disk instead by choosing ‘database storage mode’, within the interface (via ‘Configuration > System > Storage), based upon their machine specifications and crawl requirements.
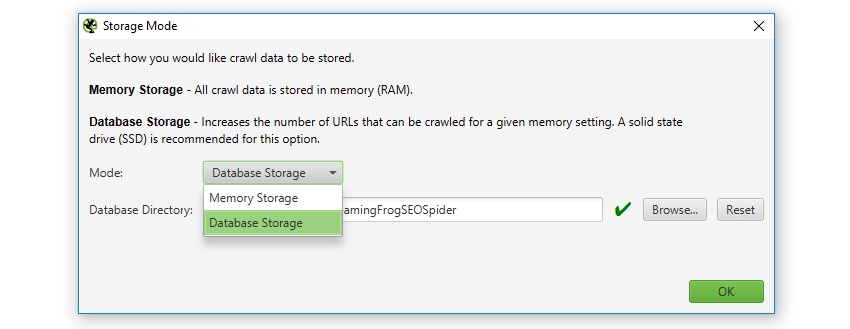
Users without an SSD, or are low on disk space and have lots of RAM, may prefer to continue to crawl in memory storage mode. While other users with SSDs might have a preference to just crawl using ‘database storage mode’ by default. The configurable storage allows users to dictate their experience, as both storage modes have advantages and disadvantages, depending on machine specifications and scenario.
Please see our guide on how to crawl very large websites for more detail on both storage modes.
The saved crawl format (.seospider files) are the same in both storage modes, so you are able to start a crawl in RAM, save, and resume the crawl at scale while saving to disk (and vice versa).
2) In-App Memory Allocation
First of all, apologies for making everyone manually edit a .ini file to increase memory allocation for the last 8-years. You’re now able to set memory allocation within the application itself, which is a little more user-friendly. This can be set under ‘Configuration > System > Memory’. The SEO Spider will even communicate your physical memory installed on the system, and allow you to configure it quickly.
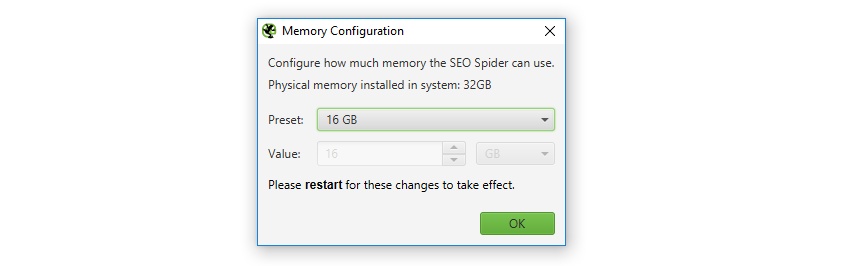
Increasing memory allocation will enable the SEO Spider to crawl more URLs, particularly when in RAM storage mode, but also when storing to database. The memory acts like a cache when saving to disk, which allows the SEO Spider to perform quicker actions and crawl more URLs.
3) Store & View HTML & Rendered HTML
You can now choose to store both the raw HTML and rendered HTML to inspect the DOM (when in JavaScript rendering mode) and view them in the lower window ‘view source’ tab.
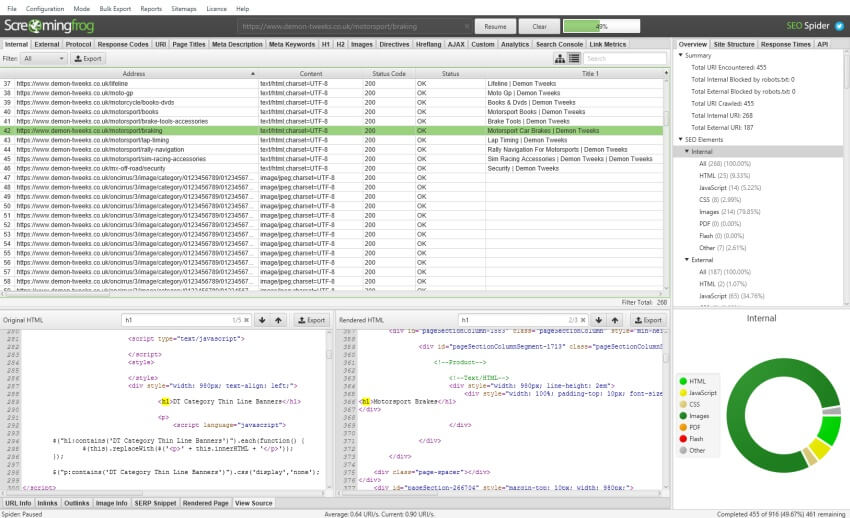
This is super useful for a variety of scenarios, such as debugging the differences between what is seen in a browser and in the SEO Spider (you shouldn’t need to use WireShark anymore), or just when analysing how JavaScript has been rendered, and whether certain elements are within the code.
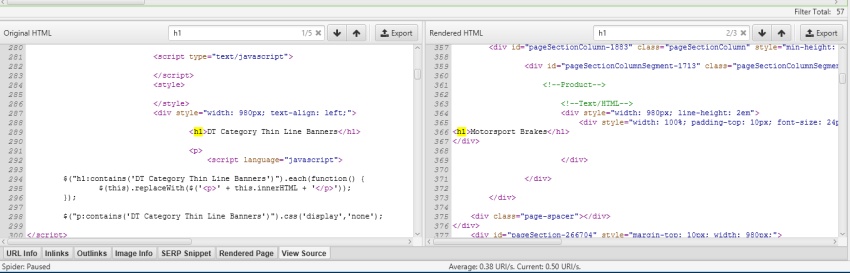
You can view the original HTML and rendered HTML at the same time, to compare the differences, which can be particularly useful when elements are dynamically constructed by JavaScript.
You can turn this feature on under ‘Configuration > Spider > Advanced’ and ticking the appropriate ‘Store HTML’ & ‘Store Rendered HTML’ options, and also export all the HTML code by using the ‘Bulk Export > All Page Source’ top-level menu.
We have some additional features planned here, to help users identify the differences between the static and rendered HTML.
4) Custom HTTP Headers
The SEO Spider already provided the ability to configure user-agent and Accept-Language headers, but now users are able to completely customise the HTTP header request.
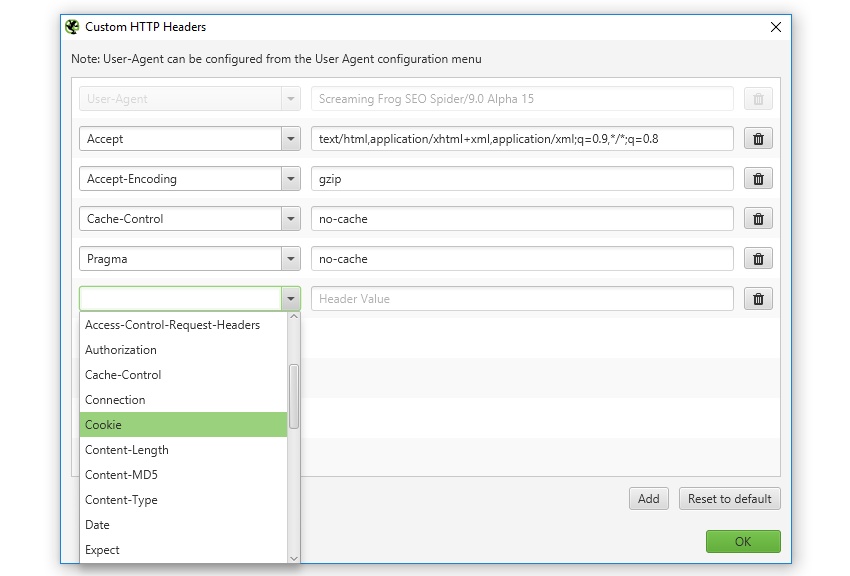
This means you’re able to set anything from the accept-encoding, cookie, referer, or just supplying any unique header name. This can be useful when simulating the use of cookies, cache control logic, testing behaviour of a referer, or other troubleshooting.
5) XML Sitemap Improvements
You’re now able to create XML Sitemaps with any response code, rather than just 200 ‘OK’ status pages. This allows flexibility to quickly create sitemaps for a variety of scenarios, such as for pages that don’t yet exist, that 301 to new URLs and you wish to force Google to re-crawl, or are a 404/410 and you want to remove quickly from the index.
If you have hreflang on the website set-up correctly, then you can also select to include hreflang within the XML Sitemap.
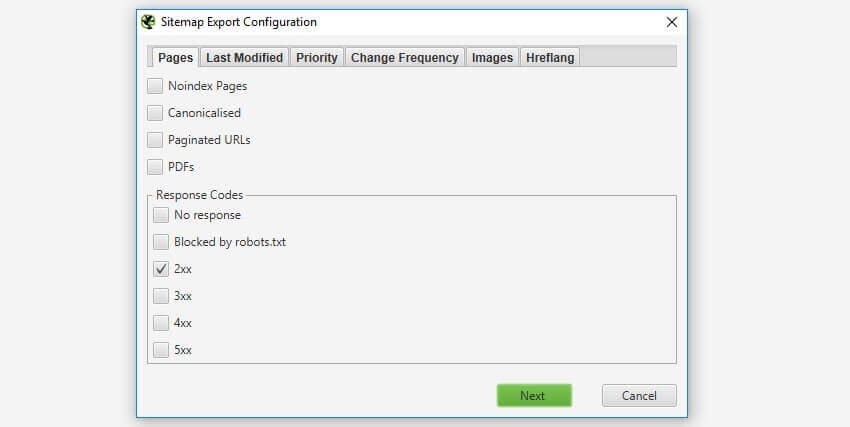
Please note – The SEO Spider can only create XML Sitemaps with hreflang if they are already present currently (as attributes or via the HTTP header). More to come here.
6) Granular Search Functionality
Previously when you performed a search in the SEO Spider it would search across all columns, which wasn’t configurable. The SEO Spider will now search against just the address (URL) column by default, and you’re able to select which columns to run the regex search against.
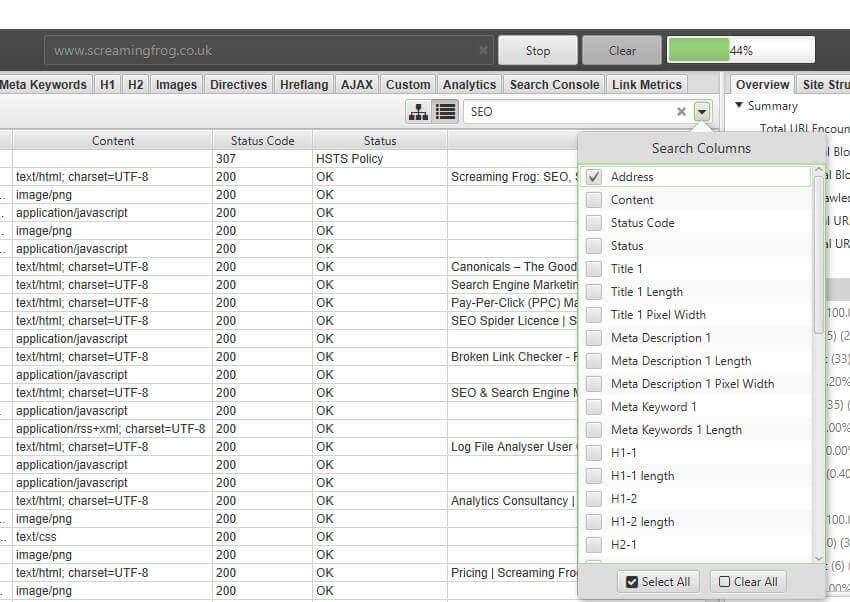
This obviously makes the search functionality quicker, and more useful.
7) Updated SERP Snippet Emulator
Google increased the average length of SERP snippets significantly in November last year, where they jumped from around 156 characters to over 300. Based upon our research, the default max description length filters have been increased to 320 characters and 1,866 pixels on desktop within the SEO Spider.
The lower window SERP snippet preview has also been updated to reflect this change, so you can view how your page might appear in Google.
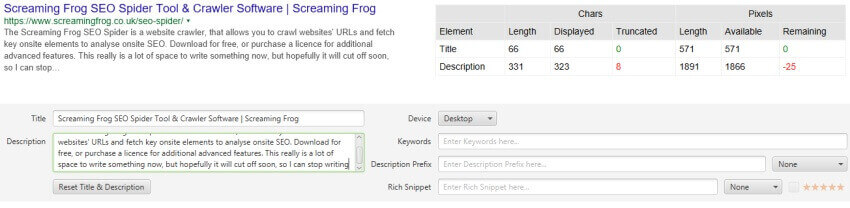
It’s worth remembering that this is for desktop. Mobile search snippets also increased, but from our research, are quite a bit smaller – approx. 1,535px for descriptions, which is generally below 230 characters. So, if a lot of your traffic and conversions are via mobile, you may wish to update your max description preferences under ‘Config > Spider > Preferences’. You can switch ‘device’ type within the SERP snippet emulator to view how these appear different to desktop.
As outlined previously, the SERP snippet emulator might still be occasionally a word out in either direction compared to what you see in the Google SERP due to exact pixel sizes and boundaries. Google also sometimes cut descriptions off much earlier (particularly for video), so please use just as an approximate guide.
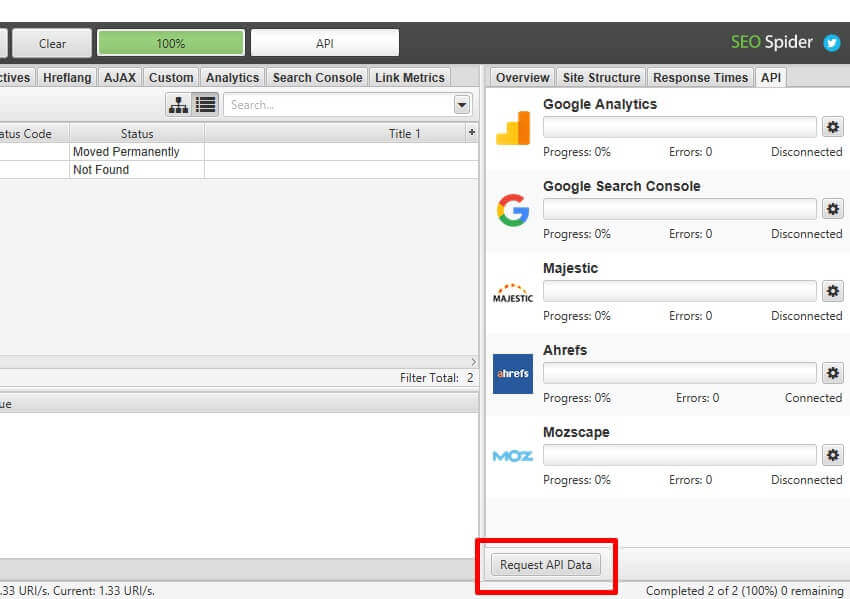
8) Post Crawl API Requests
Finally, if you forget to connect to Google Analytics, Google Search Console, Majestic, Ahrefs or Moz after you’ve started a crawl, or realise at the very end of a crawl, you can now connect to their API and ‘request API data’, without re-crawling all the URLs.
Other Updates
Version 9.0 also includes a number of smaller updates and bug fixes, outlined below.
- While we have introduced the new database storage mode to improve scalability, regular memory storage performance has also been significantly improved. The SEO Spider uses less memory, which will enable users to crawl more URLs than previous iterations of the SEO Spider.
- The ‘exclude‘ configuration now works instantly, as it is applied to URLs already waiting in the queue. Previously the exclude would only work on new URLs discovered, and rather than those already found and waiting in the queue. This meant you could apply an exclude, and it would be some time before the SEO Spider stopped crawling URLs that matched your exclude regex. Not anymore.
- The ‘inlinks’ and ‘outlinks’ tabs (and exports) now include all sources of a URL, not just links (HTML anchor elements) as the source. Previously if a URL was discovered only via a canonical, hreflang, or rel next/prev attribute, the ‘inlinks’ tab would be blank and users would have to rely on the ‘crawl path report’, or various error reports to confirm the source of the crawled URL. Now these are included within ‘inlinks’ and ‘outlinks’ and the ‘type’ defines the source element (ahref, HTML canonical etc).
- In line with Google’s plan to stop using the old AJAX crawling scheme (and rendering the #! URL directly), we have adjusted the default rendering to text only. You can switch between text only, old AJAX crawling scheme and JavaScript rendering.
- You can now choose to ‘cancel’ either loading in a crawl, exporting data or running a search or sort.
- We’ve added some rather lovely line numbers to the custom robots.txt feature.
- To match Google’s rendering characteristics, we now allow blob URLs during JS rendering crawl.
- We renamed the old ‘GA & GSC Not Matched’ report to the ‘Orphan Pages‘ report, so it’s a bit more obvious.
- URL Rewriting now applies to list mode input.
- There’s now a handy ‘strip all parameters’ option within URL Rewriting for ease.
- We have introduced numerous JavaScript rendering stability improvements.
- The Chromium version used for rendering is now reported in the ‘Help > Debug’ dialog.
- List mode now supports .gz file uploads.
- The SEO Spider now includes Java 8 update 161, with several bug fixes.
- Fix: The SEO Spider would incorrectly crawl all ‘outlinks’ from JavaScript redirect pages, or pages with a meta refresh with ‘Always Follow Redirects’ ticked under the advanced configuration. Thanks to our friend Fili Weise on spotting that one!
- Fix: Ahrefs integration requesting domain and subdomain data multiple times.
- Fix: Ahrefs integration not requesting information for HTTP and HTTPS on (sub)domain level.
- Fix: The crawl path report was missing some link types, which has now been corrected.
- Fix: Incorrect robots.txt behaviour for rules ending *$.
- Fix: Auth Browser cookie expiration date invalid for non UK locales.
That’s everything for now. This is a big release and one which we are proud of internally, as it’s new ground for what’s achievable for a desktop application. It makes crawling at scale more accessible for the SEO community, and we hope you all like it.
As always, if you experience any problems with our latest update, then do let us know via support and we will help and resolve any issues.
We’re now starting work on version 10, where some long standing feature requests will be included. Thanks to everyone for all their patience, feedback, suggestions and continued support of Screaming Frog, it’s really appreciated.
Now, please go and download version 9.0 of the Screaming Frog SEO Spider and let us know your thoughts.
Small Update – Version 9.1 Released 8th March 2018
We have just released a small update to version 9.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Monitor disk usage on user configured database directory, rather than home directory. Thanks to Mike King, for that one!
- Stop monitoring disk usage in Memory Storage Mode.
- Make sitemap reading support utf-16.
- Fix crash using Google Analytics in Database Storage mode.
- Fix issue with depth stats not displaying when loading in a saved crawl.
- Fix crash when viewing Inlinks in the lower window pane.
- Fix crash in Custom Extraction when using xPath.
- Fix crash when embedded browser initialisation fails.
- Fix crash importing crawl in Database Storage Mode.
- Fix crash when sorting/searching main master view.
- Fix crash when editing custom robots.txt.
- Fix jerky scrolling in View Source tab.
- Fix crash when searching in View Source tab.
Small Update – Version 9.2 Released 27th March 2018
We have just released a small update to version 9.2 of the SEO Spider. Similar to 9.1, this release addresses bugs and includes some small improvements as well.
- Speed up XML Sitemap generation exports.
- Add ability to cancel XML Sitemap exports.
- Add an option to start without initialising the Embedded Browser (Configuration->System->Embedded Browser). This is for users that can’t update their security settings, and don’t require JavaScript crawling.
- Increase custom extraction max length to 32,000 characters.
- Prevent users from setting database directory to read-only locations.
- Fix switching to tree view with a search in place shows “Searching” dialog, forever, and ever.
- Fix incorrect inlink count after re-spider.
- Fix crash when performing a search.
- Fix project saved failed for list mode crawl with hreflang data.
- Fix crash when re-spidering in list mode.
- Fix crash in ‘Bulk Export > All Page Source’ export.
- Fix webpage cut off in screenshots.
- Fix search in tree view, while crawling doesn’t keep up to date.
- Fix tree view export missing address column.
- Fix hreflang XML sitemaps missing namespace.
- Fix needless namespaces from XML sitemaps.
- Fix blocked by Cross-Origin Resource Sharing policy incorrectly reported during JavaScript rendering.
- Fix crash loading in large crawl in database mode.
Small Update – Version 9.3 Released 29th May 2018
We have just released a small update to version 9.3 of the SEO Spider. Similar to 9.1 and 9.2, this release addresses bugs and includes some small improvements as well.
- Update SERP snippet pixel widths.
- Update to Java 1.8 update 171.
- Shortcuts not created for user account when installing as admin on Windows.
- Can’t continue with Majestic if you load a saved crawl.
- Removed URL reappears after crawl save/load.
- Inlinks vanish after a re-spider.
- External inlinks counts never updated.
- HTTP Canonicals wrong when target url contains a comma.
- Exporting ‘Directives > Next/Prev’ fails due to forward slash in default file name.
- Crash when editing SERP description using Database Storage Mode.
- Crash in AHREFs when crawling with no credits.
- Crash on startup caused by user installed java libraries.
- Crash removing URLs in tree view.
- Crash crawling pages with utf-7 charset.
- Crash using Datebase Storage Mode in a Turkish Locale.
- Loading of corrupt .seospider file causes crash in Database Storage Mode.
- Missing dependencies when initializing embedded browser on ubuntu 18.04.
Small Update – Version 9.4 Released 7th June 2018
We have just released a small update to version 9.4 of the SEO Spider.
- Revert Java back to 1.8 update 161, due to a crash when calculating font widths for SERP calculations.
- Fix issue with over writing content types during JavaScript rendering.
- Fix crash when taking screenshots during JavaScript rendering.






Unable to do anything without it crashing on Windows XP unfortunately. Always seems to be the case with any big update. Hope to see a fix in a patch.
Hey Adam,
If you can pop through your logs to us ([email protected]) we can take a look :-)
Logs are located here – C:\Users\\.ScreamingFrogSEOSpider\trace.txt
Cheers.
Dan
Not a problem at all, have sent those through just now (didn’t see this response till just now). Thank you!
Yeah, and it doesn’t wanna run on Windows 3.1 neither ;-)
I don’t think it’s too much of an ask for it to work on Windows XP. They have always been good at getting it fixed up every other time.
It runs fine on Mac OS Puma ;)
Something is wrong with the comment dates. I feel like saying, “What year is it?”
Windows XP is dead man, get a pirated copy of windows 10
Excited to see this finally arrive! Some really cool features in there, can’t wait to play with the stored HTML.
I love your team so much right now!!!
Looks like a great update – fast and seamless interaction – thank you!
Hi team, do you have a link to roll back to the previous version please? I’m on Lite and I don’t have enough space or ram to run anything on the new version, just keep getting “free up space” error, regardless of new storage and ram settings. I have 2 gb left and no capacity to delete anything else. Please help!
Hey Lisa,
Yeah, absolutely. You can amend the download URL string to download version 8.3 again.
Example for the PC – https://download.screamingfrog.co.uk/products/seo-spider/ScreamingFrogSEOSpider-8.3.exe
In DB storage we give a warning and stop crawling when you have 5GB of disk space left. We shouldn’t do this in RAM storage mode (which is a bug and will be fixed up in 9.1).
Cheers.
Dan
Thanks so much Dan!!
Hey Dan,
Seems that on Linux (Ubuntu) version I’m still getting the warning with 20.4 GB free disk space.
Would you drop me a link to 8.3 version for Ubuntu, please?
Thanks,
Rad
Ah, that’s allright, found it :)
https://download.screamingfrog.co.uk/products/seo-spider/screamingfrogseospider_8.3_all.deb
Hey Rad,
We throw up a warning if you have less than 5gb of disk space left, as crawls can be large.
We have a couple of bugs here though, one that the warning happens in memory mode (when it shouldn’t as you’re just using RAM), and the other than it checks the default drive (rather than a chosen drive).
If your issue isn’t one of the above, if you could pop through your logs to us ([email protected]) I’d appreciate it :-)
Cheers.
Dan
Amazing update! This is super work and perfect timing for us.
We’re halfway through crawling a 20m page website and running out of RAM rapidly (256GB available).
Knocked it out the park with this update Dan – looking forward to trying to break it =D Custom HTTP headers is a massive help!
Cheers, Michael!
Amazing update!
Well Done!
Wow I love those new features! Great!!!
Like it! You develop really client-oriented product. Please, keep good work!
Nicely done.
Hey Screaming Frog Team! This is wonderful update, especially with RAM where a lot of people were having issues. Many thanks for the greatest SEO tool!
Great update. Tons of new stuff! Is there any feature requests/plans for the next update to include the ability to truly ignore canonical urls (or at least filter them out) of results?
Hi Roland,
Have you tried the ‘respect canonicals’ option, under ‘Configuration > Spider > Advanced;?
Essentially, it will remove canonicalised URLs from the interface (like they would be from an index).
If this doesn’t do what you wanted, I’d be interested in hearing more on what you hoped to see.
Cheers.
Dan
Fantastic release. So many of these items have been on my wishlist for ages. Well done SF team.
Hello dan, Really its amazing tool. Thank you for sharing with us.
Love it! Now we can crawl trillion pages sites)
Muhahaha ;-)
I use the program long, the new version looks better.
Hey, thanks for update. Amazing thing !
Awesome! Thanks, guys :)
Hi dear Screaming Frog Team,
since the new update my crawl needs extremly long to save. It used to take up to max. 5 minutes and now needs about 30-40 minutes for about 14K Queries. The file size also changed from previously about 230MB to now 1,4 GB. Is there any explanation to this or do I have to change something in the settings?
Best,
Suzy
Hi Suzy,
Just to mention, the estimated save time isn’t particularly accurate (so you may find it’s quicker than it says).
To keep memory overhead as low as possible when writing out we take longer, and write out larger files than 8.3. However, they should compress down well, though!
We might be able to bring the time down a little as well.
Cheers.
Dan
I agree with Suzy. It takes forever. I just saved a crawl (25k pages) that used to take a few min, now it just took me 40 min. Even creating a sitemap takes longer, and I still have not been able to get an images sitemap to process. It will just hang my entire system, I let it run overnight and it said it was going to take more than 180 days! I thought that wasn’t correct so I let it run overnight with no progress at all. I could not cancel it, in fact my whole computer was locked up so I had to reboot.
I thought maybe there was something wrong with my saved crawl file, so I recrawled , re-saved the crawl (40 min) and built a regular sitemap, but when I tried to do an images sitemap it is telling me currently that it will take more than 1000 days, increasing by 2 or 3 days per second!
I’m super frustrated with this version
Hi Mike,
Sorry to hear you’re frustrated. It’s a big, big update, so there will always be some bugs and issues along the way.
What I can say is, we always investigate any problems and fix all bugs that come in. Often very quickly.
So what we need from you is quite simple – An email through to [email protected] with the details, we can then look into it, and sort out any problems. In the meantime, you can revert to 8.3 if you’d prefer for now (links above in the comments).
Cheers.
Dan
Great work, great and useful improvements.
Great!
I would say this is something what from point of view of big services will save a lot of troubles with data sampling, and from other side should also save memory resources on not best performing machines.
Good work and sure You can make it even better with community feedback ;)
Always the first seo tool
Thanks
Great work Guys,
Just upgraded and the speed improvement is very noticeable.
Regards,
Luis
Well done team, amazing update.
Excellent update – crawling 15 million pages no longer needs 32Gb+ RAM and the granular search functionality is a great feature. Not sure how you can improve for version 10 :)
Dear Team,
Thanks for amazing update and new features. Unfortunately, point 3 seems not be working for me, I am able to see the Original Html but not the rendered one.
Any ideas why?
Thanks in advance for your help.
Hey Andrius,
Thank you! For rendered HTML to work, we need to be able to render the page. So you’ll need JavaScript rendering on (Config > Spider > Rendering) :-)
Then you should be able to see HTML, and the DOM!
Cheers,
Dan
I have tried to download the windows 9.1 update put at the end I get an error message ? Am I the only one with this update challenge ?
In the past most all update have been flawless. Could not find a faq for help.
thank you ,
william savage
Hey William,
What’s the error? Pop it through to us ([email protected]) and we can advise!
Cheers
Dan
Thanks for the amazing update and new features. Just upgraded and the speed improvement is very noticeable.
Regards,
Luci
Another great update. New sitemaps improvements are really awesome. Seems like Screaming Frog is ever more powerful than it was.
Thanks for the amazing update and new features. Just upgraded and the speed improvement is very noticeable.
Regards,
Cheerons
Very good update Dan
What I’d really love to see in one of the next updates is the ability to upload/paste an identifier along with the urls which is also passed on to its decendants, maybe separated by a tab before/behind the url.
The reason? It’s simple: Matching is pain in Excel, if you don’t know where it originates from.
Trailing slashes are added in Sceaming Frog by default, which might not be the case for the source URL in the sheet.
Of course there are search and find functions to address that issue somehow. But that makes me need to process and/or correct my source sheet, otherwise I cannot have a perfect and simple matching.
Furthermore, if following redirects, the 200 OK final URL could have a different domain, subdomain and path or querystring attached to it. In those cases I need to multi-match serveral sheets, just to attach the final URL as a column to the source sheet.
For those cases I already wrote a PHP script, because it is too much of an arduous task to do so, so I make sure I only paste final URLs to Screaming Frog for easy processing.
Bonus: Optionally follow Meta Refresh, possibly JS Redirects would be awesome, too.
Cheers, Patrick
Hi Patrick,
Thanks for the feedback. Just to reply to your feedback and points, as some we already do and perhaps you didn’t know.
First of all, love the idea of being able to upload an identifier (a label) to a URL. We’ve been thinking of cool ways you could use this to segment data.
On trailing slashes – The SEO Spider adds a trailing slash to the host (www.example.com to http://www.example.com/) as they are one and the same. It won’t do that for a path, i.e http://www.example/page as obviously that’s technically seen as a different URL. That’s not the case for a host.
With regards to following redirects and chains – I am not sure if you use this already https://www.screamingfrog.co.uk/audit-redirects/, but we are working on some improvements to the report, including a fixed final destination column :-)
For meta refreshes and JS redirects – These get followed and reported on already (in JavaScript rendering mode for JS) :-)
Cheers for your thoughts!
Dan
Thanks for your quick reply, Dan.
Glad the Website is up and running again world-wide… must have been a Friday the 13th thing.
Yes, the audit is very helpful, and I didn’t realize it already contains meta refreshes and now also JS redirects, so thank you bunches for the reminder. I used chrome headless for a while to retrieve the final URL from any input, as it can be executed multithreaded via PHP CLI as well. A fixed position for the final URL column will be much appreciated :-)
For basic URL processing I just went to my own custom solution, because the data I handle is unfortunately often not “normalized” in a way that it should be. I wish there was one tool to do it all, but there isn’t yet. I think Screaming Frog can be the one though.
Here’s my issue: I litereally receive URLs in the format of random. To give you a glimpse, it is always something like this, and more: http://url.tld; url.tld; http://www.url.tld/
The problem with this is that I have to pre-process it somehow, as Screaming Frog will only accept the first URL out of the 3 examples. And I cannot simply put a training slash on all of them, or put a scheme (protocol://) in front of it, as it would break others. Stripping everything down to root domain name, without www. wouldn’t work as well, as this can cause issues as well. Random example: steuerlex[dot]de (doesn’t resolve) vs.. www[dot]steuerlex[dot]de (resolves).
So my smart query for the latter is basically [ if 2nd lvl doesn’t resolve && 3rd level ‘www’ + 2nd lvl does resolve ] continue with www; else status definitely 0;
Maybe something similar could be implemented as a smart way of trying to recover an URL as well, which is otherwise falsely deleted or considered as dead, but it was just a formatting error, or the way it resolves (www != non-www) was changed later on.
Looking forward to the labels when they come!
Patrick
Hi Patrick,
Thanks for explaining your use case, and I can see why you’d need to pre-process the URL list you get given!
It’s a complicated one, and probably one that will always need some manual validation to an extent.
Thanks for your comments and patience on Twitter as well re: Securi btw, good to hear it’s resolving again in Asia (it’s been a bit of a nightmare)!
Cheers.
Dan
I have try this update…. Screaming Frog is the best.
Thanks a lot, thanks a lot
Mike Moore
Finally, if you forget to connect to Google Analytics, Google Search Console, Majestic, Ahrefs or Moz …
New feature to try.
thank you so much!
Mirco S.
excellent update
with this new version it improves the quality of our services.
thanks for the effort!!!
Andrew M.
Hi Dan, web scraping sometimes demands information beyond the content. A recent request to me demanded the calculated DOM height. I am not sure how to go about this other than evaluating JS, e.g. document.getElementsByTagName(‘body’)[0].offsetHeight. When JS rendering is activated, would it be possible to enable JS evaluation to the Custom Extraction section or create an entire new panel for such purposes? There are likely to be many many other use-cases where it could be applied to. Right now I am stuck with chrome headless and puppeteer to retrieve the info.
-Patrick
I have used Deepcrawl for most of my technical SEO work. It is a great tool, but I really want to test out Screaming Frog. From what I see is that it looks like it focuses on parts that I use the most and cuts out all the fat, like migrations etc.
Nice Program saved my life in SEO :)