Screaming Frog SEO Spider Update – Version 22.0
Dan Sharp
Posted 10 June, 2025 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 22.0
We’re delighted to announce Screaming Frog SEO Spider version 22.0, codenamed internally as ‘knee-deep’.
This release includes updates based upon user feedback, as well as exciting new features built upon the foundations introduced in our previous release.
So, let’s take a look at what’s new.
1) Semantic Similarity Analysis
You can now analyse the semantic similarity of pages in a crawl to help detect duplicate, similar and potentially off-topic, less relevant content on a site.

This goes beyond matching text on a page found in our duplicate content detection, by utilising LLM embeddings, which capture the semantic meaning and relationship of words.
This makes it possible to identify similar pages with different phrases but overlapping themes, covering the same subject multiple times, which can cause cannibalisation or inefficiencies in crawling and indexing.
If you’re not familiar with embeddings, then check out Mike King’s piece on Vector Embeddings is All You Need. Many SEOs have been inspired to experiment and build various tools with these concepts.
Using our existing AI provider integrations via ‘Config > API Access > AI’ (including OpenAI, Gemini & Ollama) you can capture vector embeddings of pages.

You can now enable their use in the SEO Spider via ‘Config > Content > Embeddings’ for semantic content analysis, semantic search and visualisations.

When the crawl has completed and crawl analysis has been performed, the ‘Semantically Similar’ and ‘Low Relevance Content’ filters will be populated in the Content tab.
Please refer to our user guide on configuring embeddings.
Semantically Similar Pages
The Content tab and ‘Semantically Similar‘ filter will show the closest semantically similar address for each URL, as well as a semantic similarity score and number of URLs that are semantically similar.
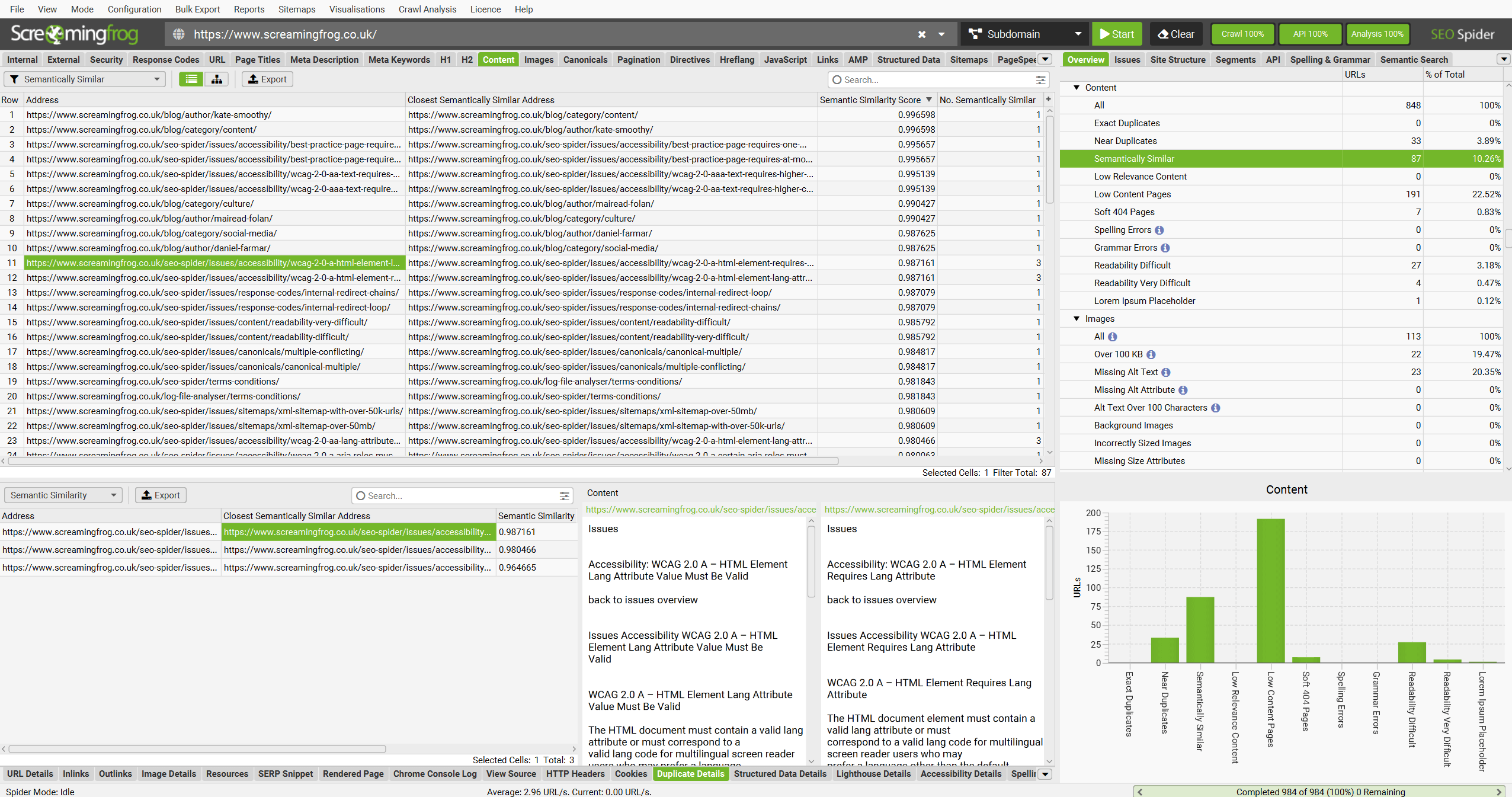
The lower ‘Duplicate Details’ tab and ‘Semantic Similarity’ filter will show all semantically similar URLs, as well as the content analysed.
Semantic similarity scores range from 0 – 1. The higher the score, the higher the similarity to the closest semantically similar address.
Pages scoring above 0.95 are considered semantically similar by default. The semantic similarity threshold can be adjusted via ‘Config > Content > Embeddings’ down to as low as 0.5.
Low Relevance Content
Vector embeddings can also be used to detect pages that are potentially off-topic compared to the overall content theme by averaging the embeddings of all crawled pages to identify the ‘centroid’.
Measuring the deviation of page embeddings from a site embedding is something that was hinted at within the Google leak, and SEOs have been playing with this concept to find outliers.
Outliers are those furthest from the average, and might indicate low relevance, ‘more off-topic’ content than is published elsewhere on the site.
Pages below the threshold can be seen under the ‘Content’ tab and ‘Low Relevance Content’ filter.

For our site this suggests blog content around the Olympic torch coming to Henley, a recent post on returning to work after maternity and our login page as outliers compared to the rest of the more technical SEO focused content on the site.
While we’re not going to remove these pages, it’s fair to suggest that the content of these pages deviates from the usual focus of the site.
Read our full tutorial on How to Identify Semantically Similar Pages & Outliers.
The semantic similarity analysis can be used for more than just detecting near duplicates and low relevance content as well, such as:
- Improving Internal Linking – The lower ‘Duplicate Details’ tab, and ‘Semantic Similarity’ filter can be used to improve internal linking between semantically similar content.
- URL Mapping for Redirects – Crawl old and new websites together and get a list of closest semantically similar URLs based upon the page text for redirects.
- Semantic Similarity Analysis of any Element – Select ‘page titles’ instead of ‘page text’ for the embeddings, and run a semantically similar analysis to find near duplicate titles instead etc.
We’re excited to see the different use-cases and ways this new functionality is used, which will in-turn inspire the evolution within the tool.
2) Semantic Content Cluster Visualisation
The Content Cluster Diagram is available via ‘Visualisations > Content Cluster Diagram’. It’s a two-dimensional visualisation of URLs from your crawl, plotted and clustered from embeddings data.
It can be used to identify patterns and relationships in your website’s content, where semantically similar content are clustered together.
The example diagram above highlights the semantic relationship of an animal website. It’s fascinating to see how semantics mimic animal taxonomy –
Tiger populations tightly grouped together, with the nearest neighbour the Liger hybrid inbetween the Tiger and the Lion, and then other big cats such as Leopards, Jaguars, Cheetahs as the next neighbours and so on.
The diagrams can be useful to visualise the scale of clusters of content across a site or identify potential topical clusters that are semantically related yet might be distantly integrated for the user.
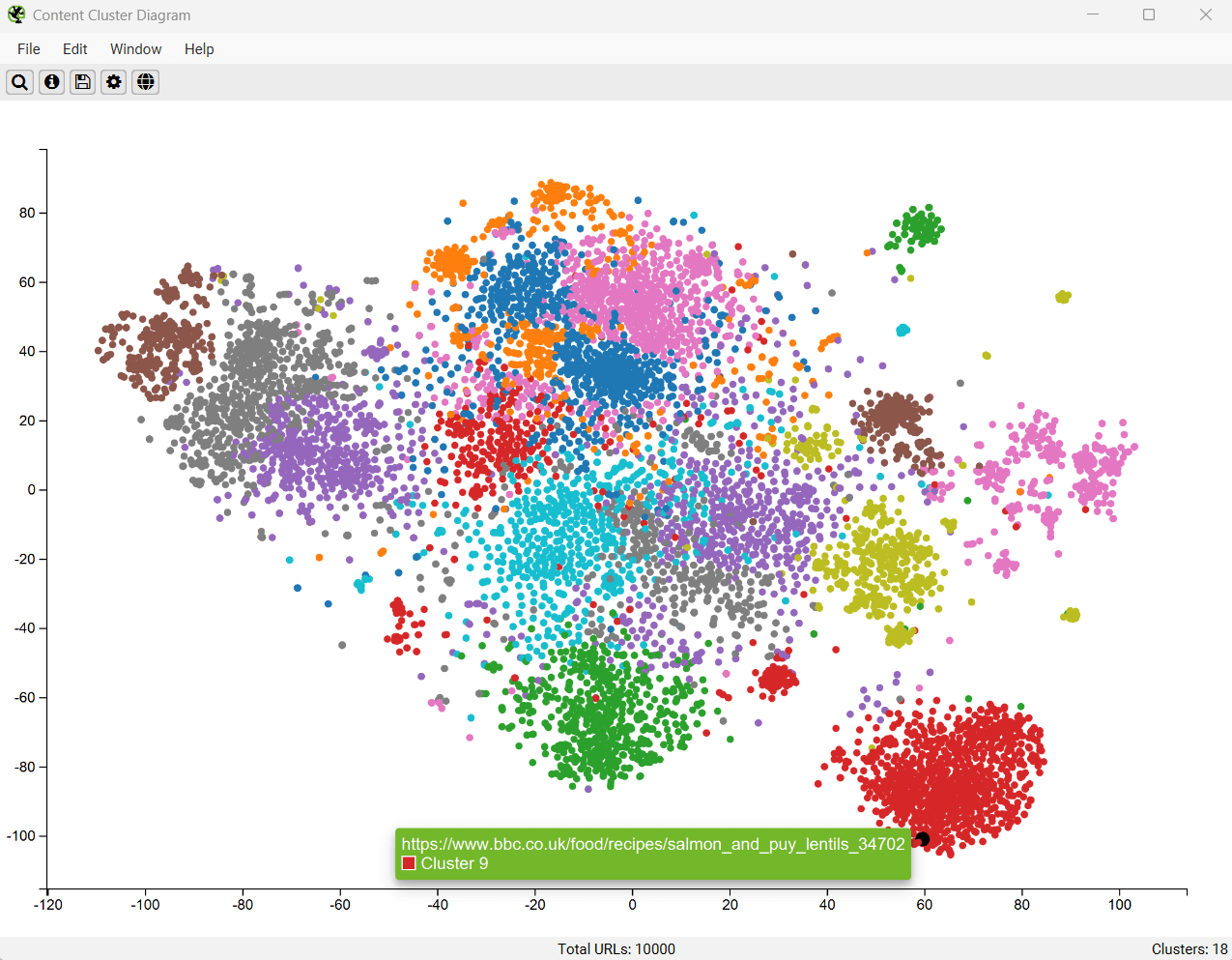
In the diagram above, you can easily see the scale of different sections, such as recipes on the BBC.
You can also spot outliers that are isolated from other nodes on the edges of the diagram, such as those mentioned on our site earlier.
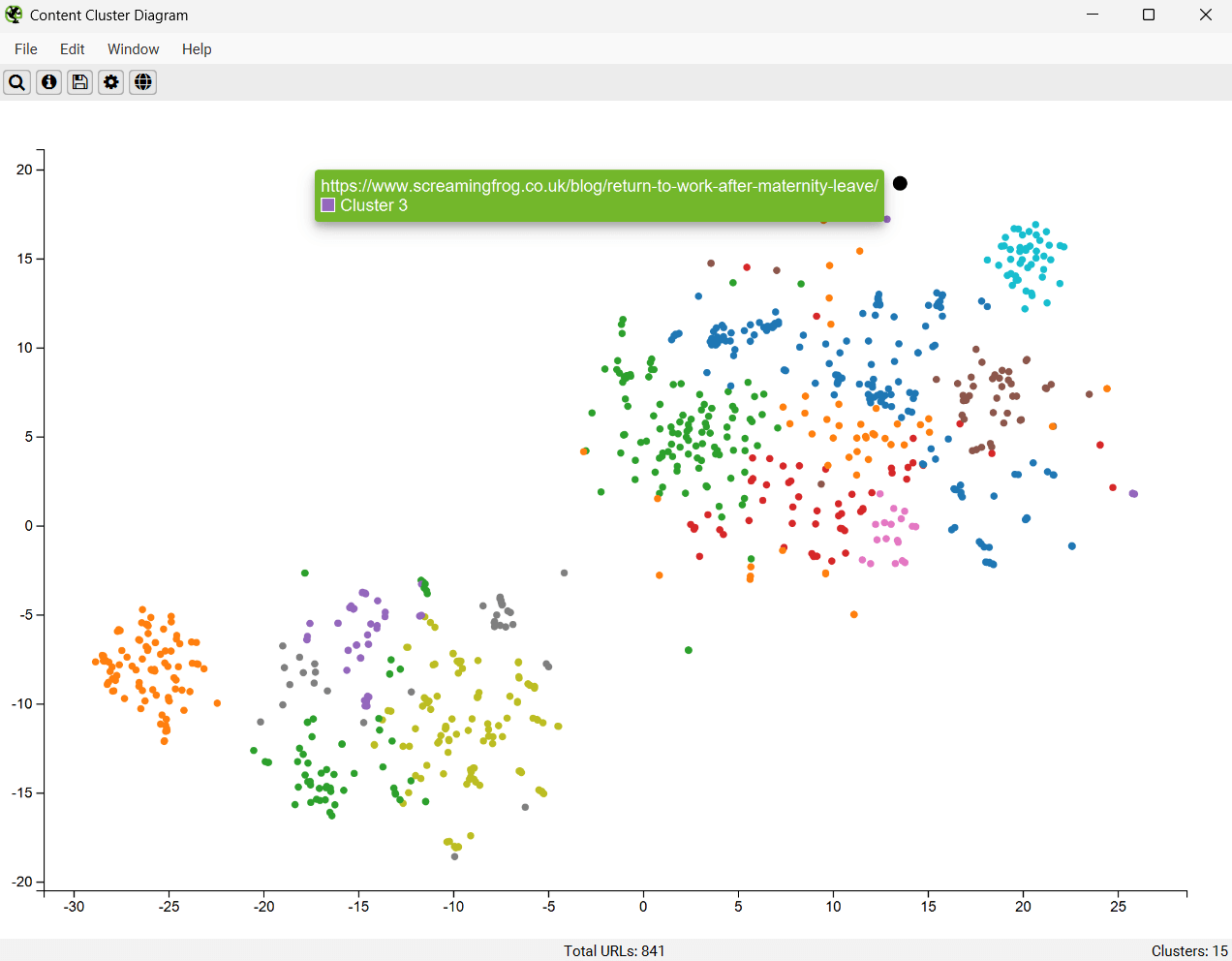
The cog allows you to adjust the sampling, dimension reduction, clustering and colour schemes used. The content cluster diagram also works alongside segments, so you can visualise content in one specific area or section of a site.
We have plans to compliment these diagrams with crawl data for more insights.
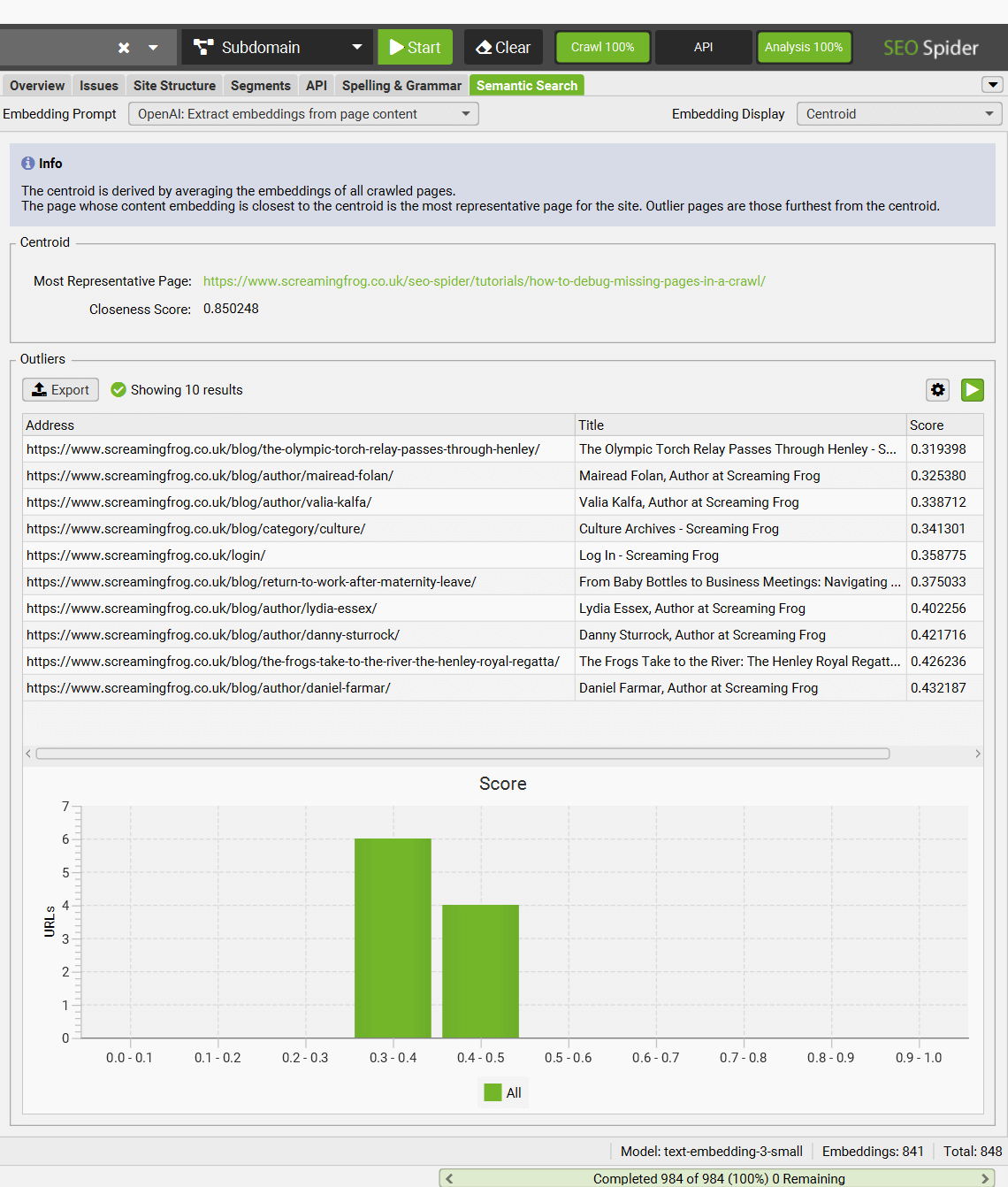
3) Semantic Search
There’s a new right-hand ‘Semantic Search’ tab, which allows you to enter a search query and see the most relevant pages in a crawl.
This functionality vectorises the search query and calculates the cosine similarity between the query and pages in a crawl using vector embeddings rather than keywords.
It can help quantify the relevance of content to a query for all pages in a crawl, and is more akin to how modern search engines and LLMs return content today, rather than more simplistic keyword presence and matching within text.
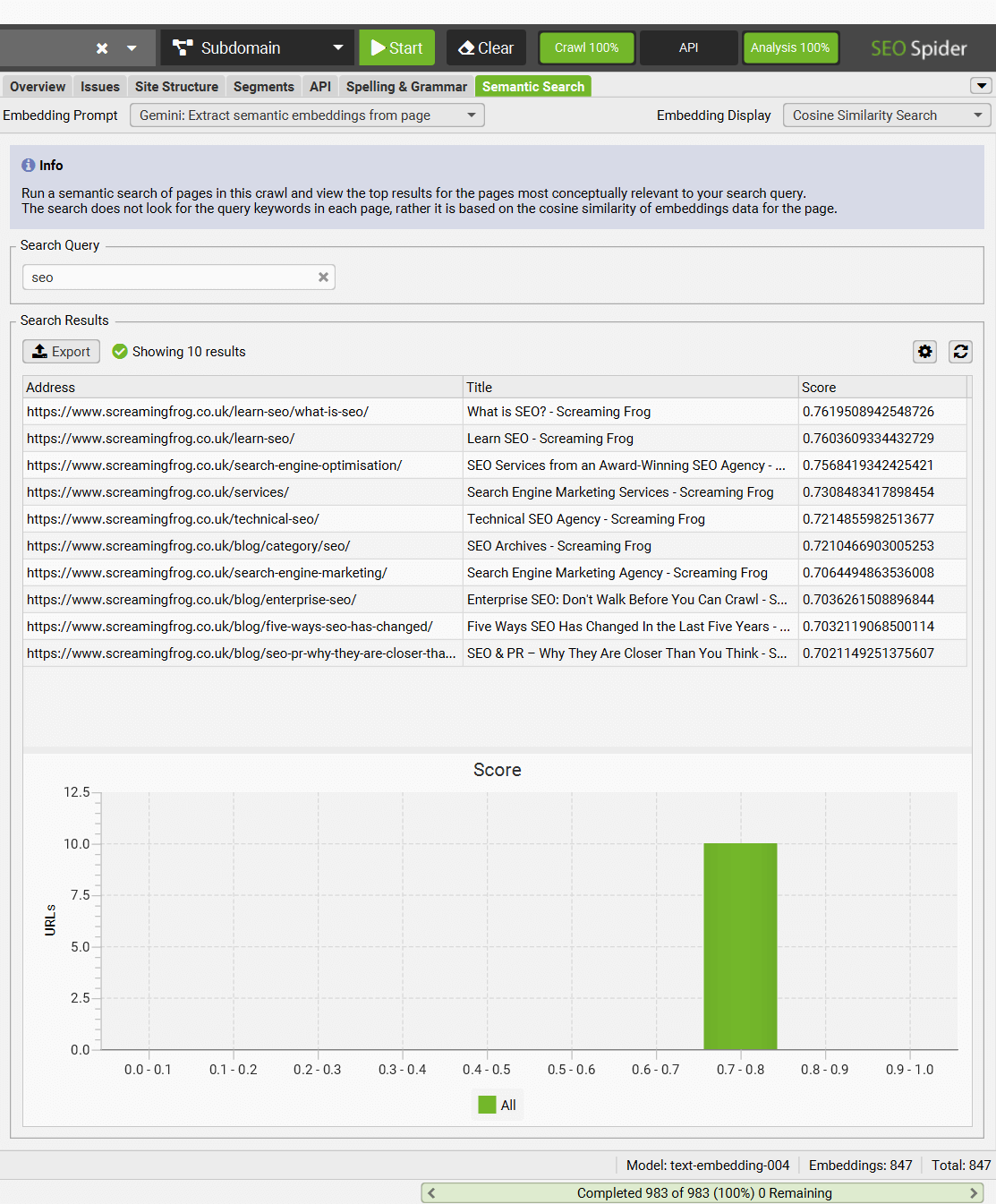
This functionality can be used to find relevant pages for keyword mapping, related pages for internal linking, or competitor analysis against keywords as examples.
The ‘Embedding Display’ filter can be adjusted to ‘Centroid’, to see more details about outliers found on the website and the ‘most representative page’, that is closest to the average embedding across the whole site.
If you’ve pulled embeddings from a variety of LLMs you can adjust the filter at the top to view the different results.
Similar to the other features launched, it’s obvious how this feature could be extended in the tool in future updates.
4) AI Integration Improvements
We’ve introduced a variety of improvements for our AI integration to make it even more advanced, flexible and to help reduce waste of credits and queries. This includes:
Multiple Prompt Targets
You can now click the cog against a prompt and write a more advanced prompt, including multiple prompt target elements.

Run Prompts For Specific Segments & Issues
You’re able to choose to run AI prompts against URLs that match a specific segment. This means you can set up segments for different scenarios you wish AI prompts to be run against, and not waste credits.
In the advanced prompt, you can choose to ‘Match on Segment’.

Alongside this, you’re now able to segment based upon ‘Issues’.
For example, this means you can create image alt text only for image URLs in the segment with the issue ‘Missing Alt Text’, rather than every image.
Reference URL Details
URL Details data can now be selected to be used in AI prompts for further flexibility.

Custom Endpoint
You can now customise the OpenAI endpoint, which allows users to enable private LLM APIs and other AI providers that use the same structure.
For example, you can use DeepSeek, Microsoft Copilot, or Grok by customising the endpoint and using the relevant API key.

You can also customise the model parameters, headers, and limit page content length to reduce token exceeded errors on long content pages.
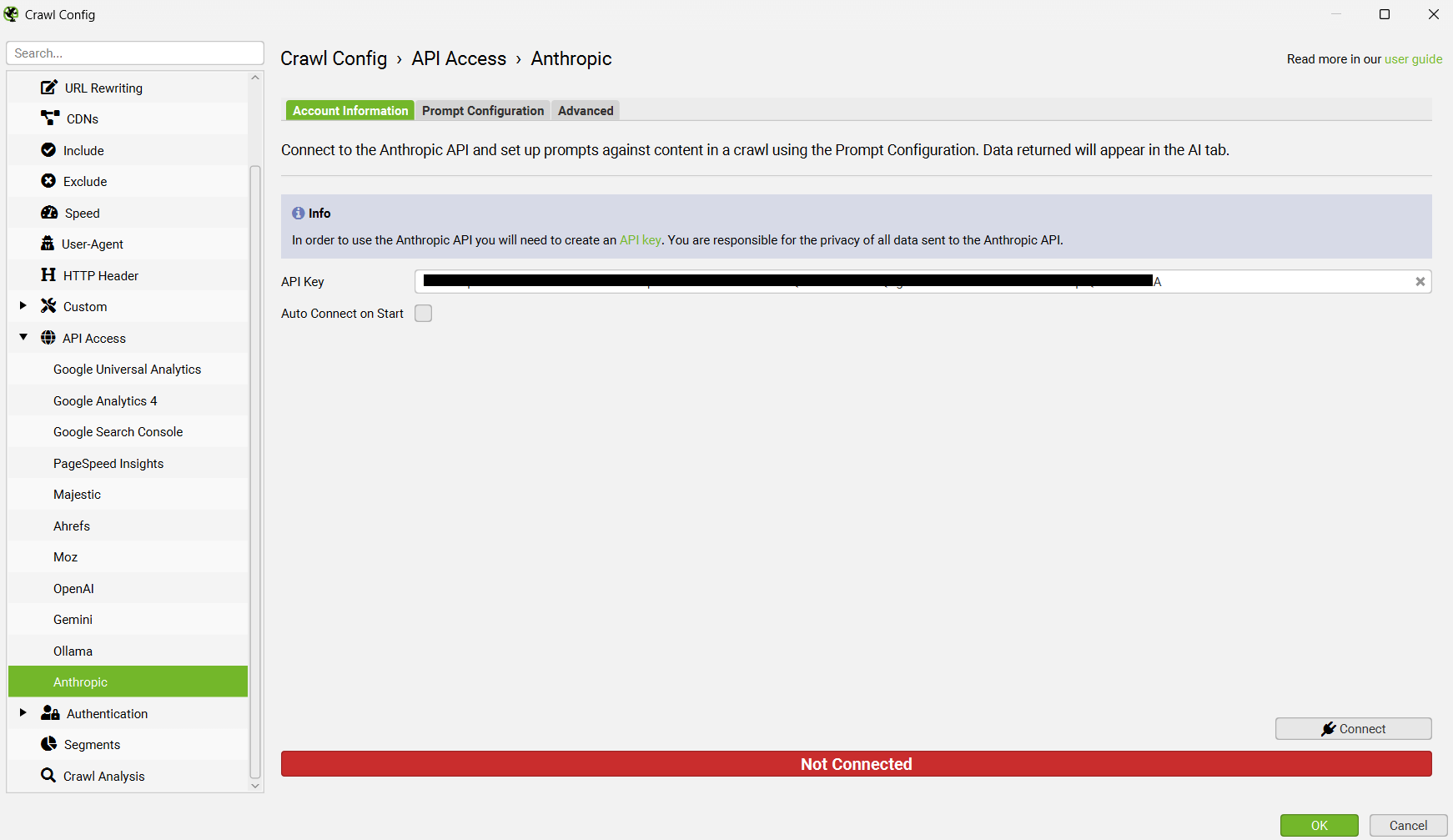
Anthropic Integration
Similar to the integrations of OpenAI, Gemini and Ollama, you can now integrate with Anthropic (aka ‘Claude’) via ‘Config > API Access’ to run AI prompts while crawling.
Generate Images & Text Speech
We had some fun and integrated image and text speech generation for OpenAI and Gemini. As an example, this can be used to crawl blog posts, and create a hero image for each of them.
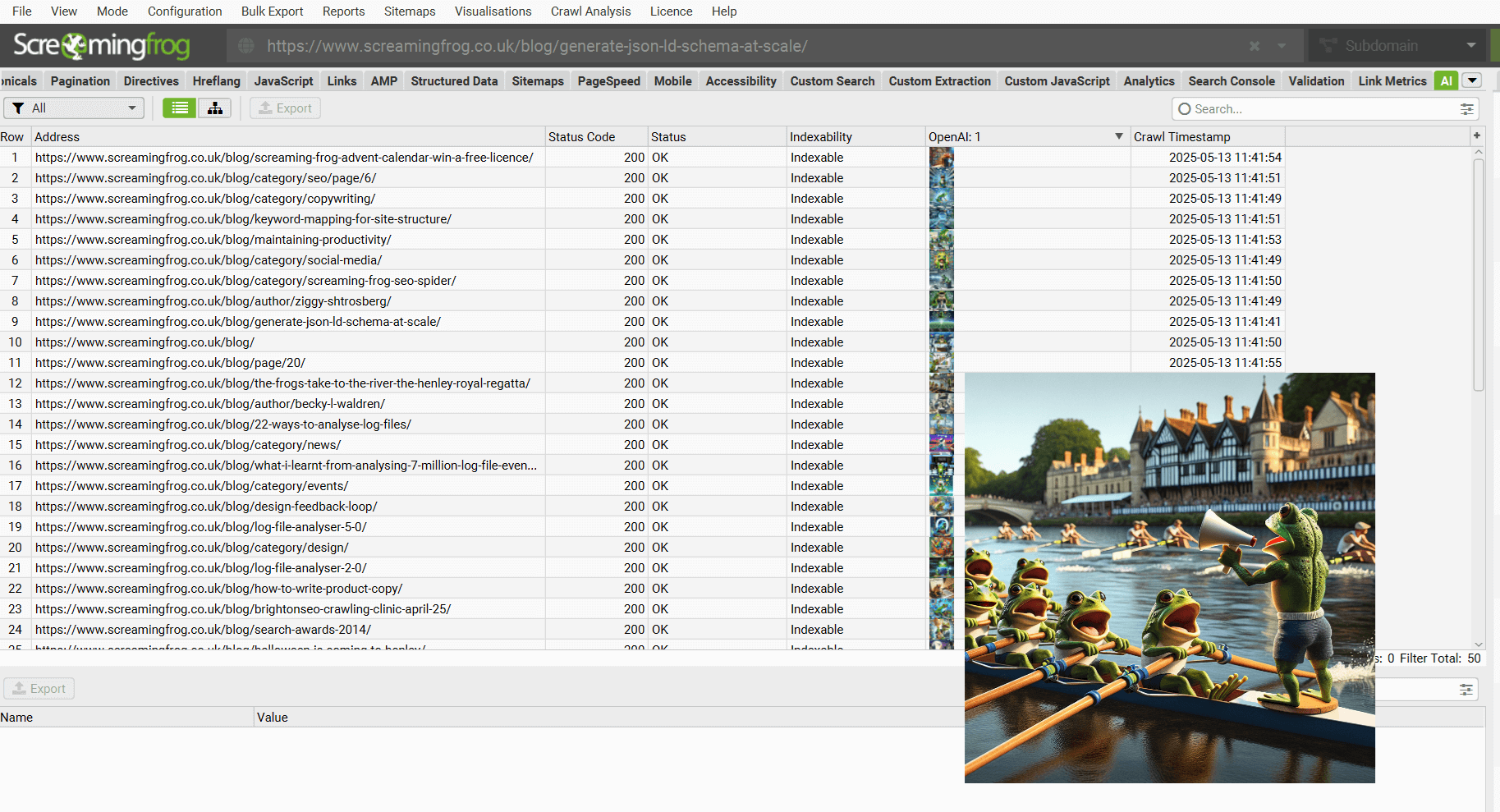
The SEO Spider will show an image or sound preview in the UI, which you can expand, or listen to.
Read our full tutorial on How To Crawl With AI Prompts.
5) Advanced Column Configurator
In the same way you can customise tabs, you can now configure columns with an advanced configurator that allows them to be selected, hidden and adjusted in order in bulk.
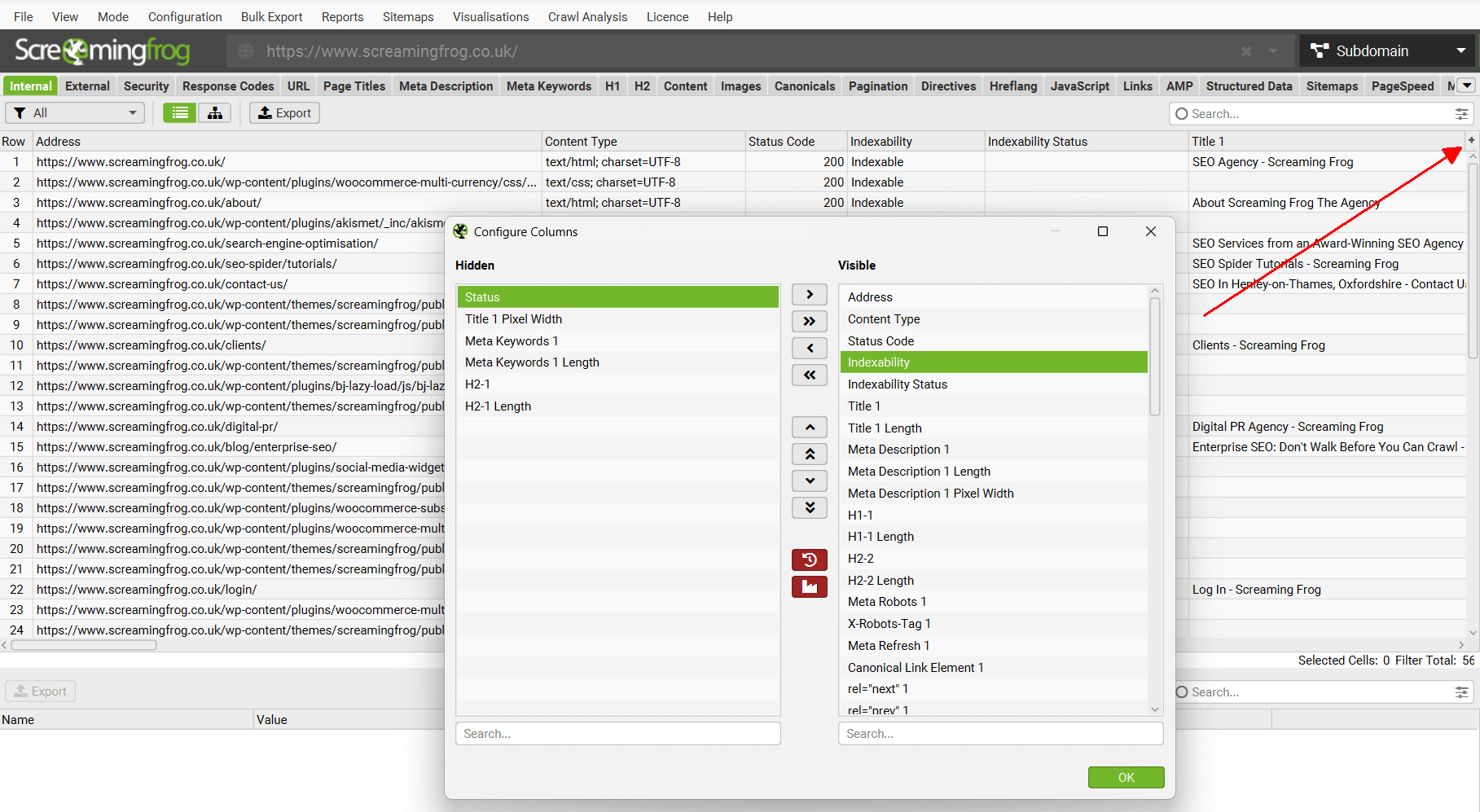
This should make customising columns less painful.
6) Custom Multi-Export
There’s a new ‘Multi Export’ option under the ‘Bulk Export’ menu. This allows you to select any tab, bulk export or report to export in a single click.
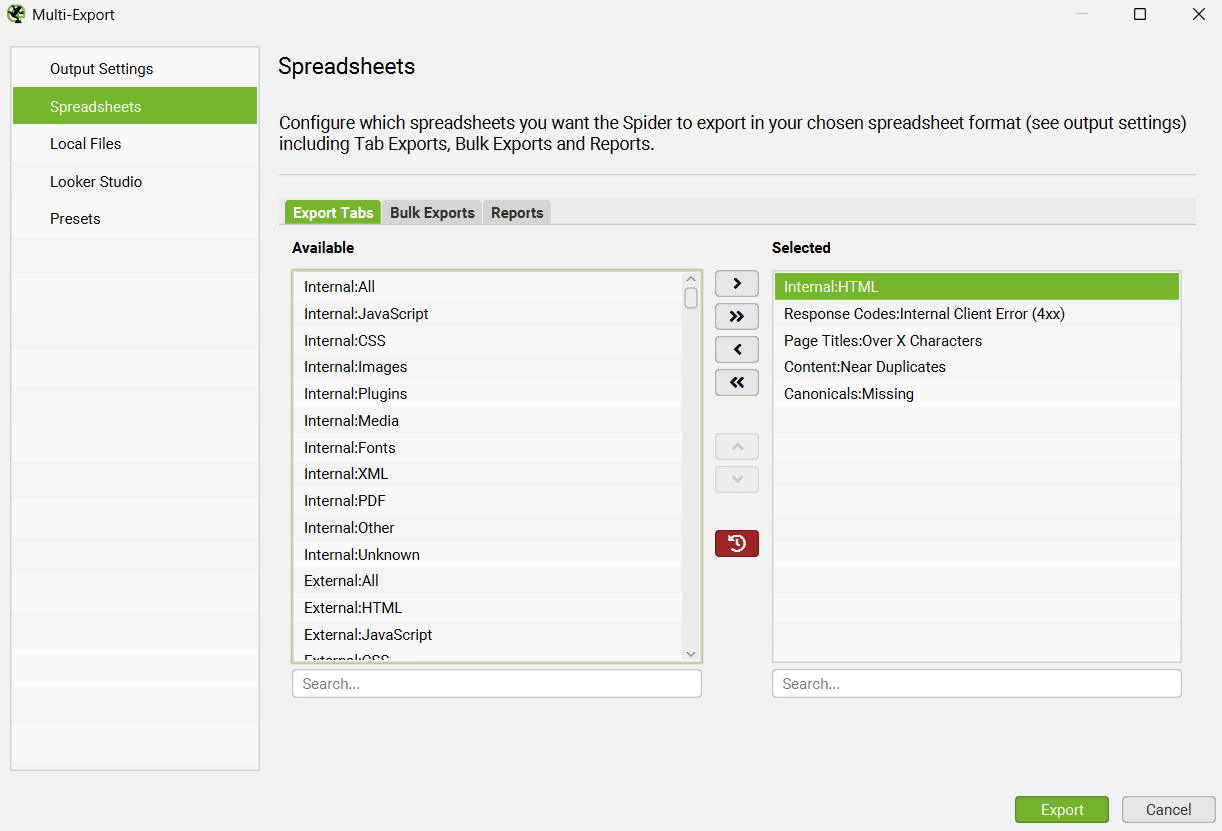
If there’s a common set of reports you use for crawls, or have specific exports for some websites, then you can save them as presets and use them when needed both manually in the UI, or in scheduling and the CLI.
This new functionality also enables you to run the Export for Looker Studio from a manual crawl, rather than only from within scheduling.
7) Export to Multiple Tabs In Single Sheet/Workbook
When you bulk export multiple exports manually or from within scheduling, you can now select to ‘consolidate spreadsheets’.
Rather than export each tab, bulk export or report as a separate file, it will export everything to multiple individual tabs within the same single Google Sheet or Workbook.
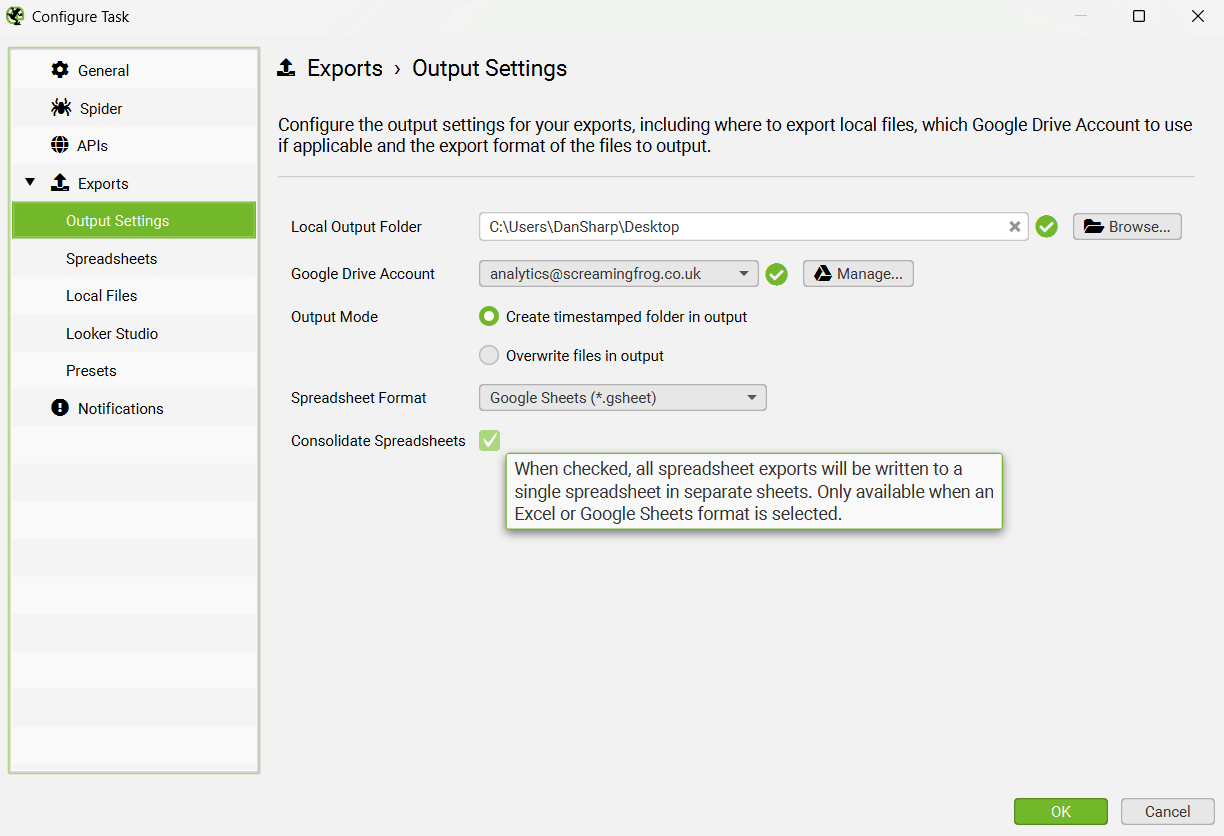
This is available for both Google Sheets and Excel.
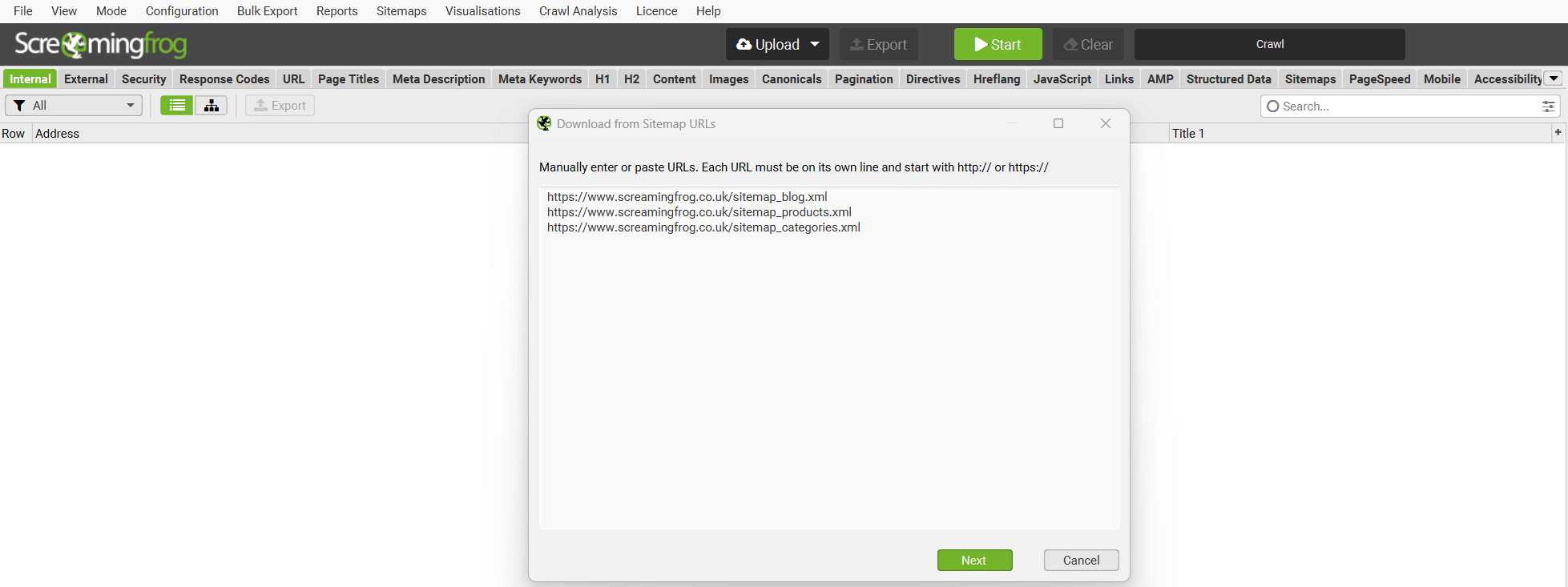
8) Download Multiple XML Sitemaps
In list mode you can now upload multiple XML Sitemaps, instead of relying on a Sitemap Index file.
9) Download from Google Sheets
In list mode, you can select the source as a Google Sheet address. Any URLs within the Google Sheet will be uploaded and crawled.
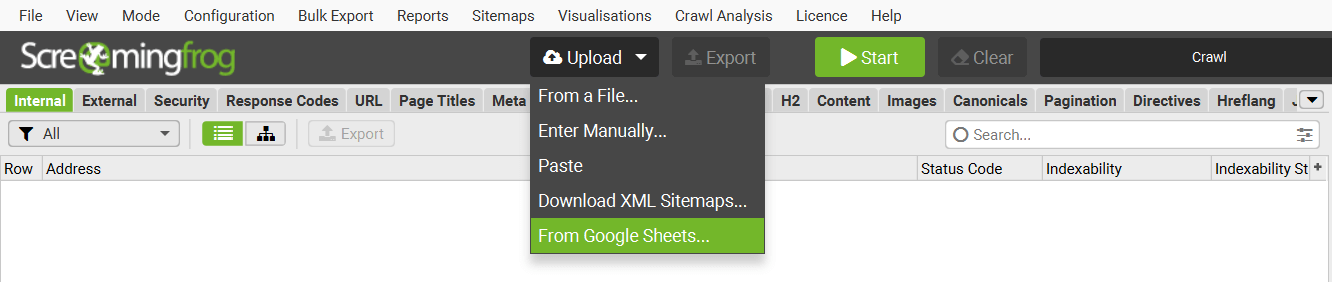
You’re able to input your Google Drive details so the SEO Spider can access private Google Sheets.
This feature has exciting automation potential, as you can dictate the URLs to be crawled using Google Sheets (and associated add-ons and app scripts).
This is also available in scheduling and the CLI.
10) Fetch API Data Without Crawling or Re-Crawling
There’s a new ‘APIs’ mode (‘Mode > APIs’), which allows you to upload URLs and pull data from any APIs – without any crawling involved for speed.
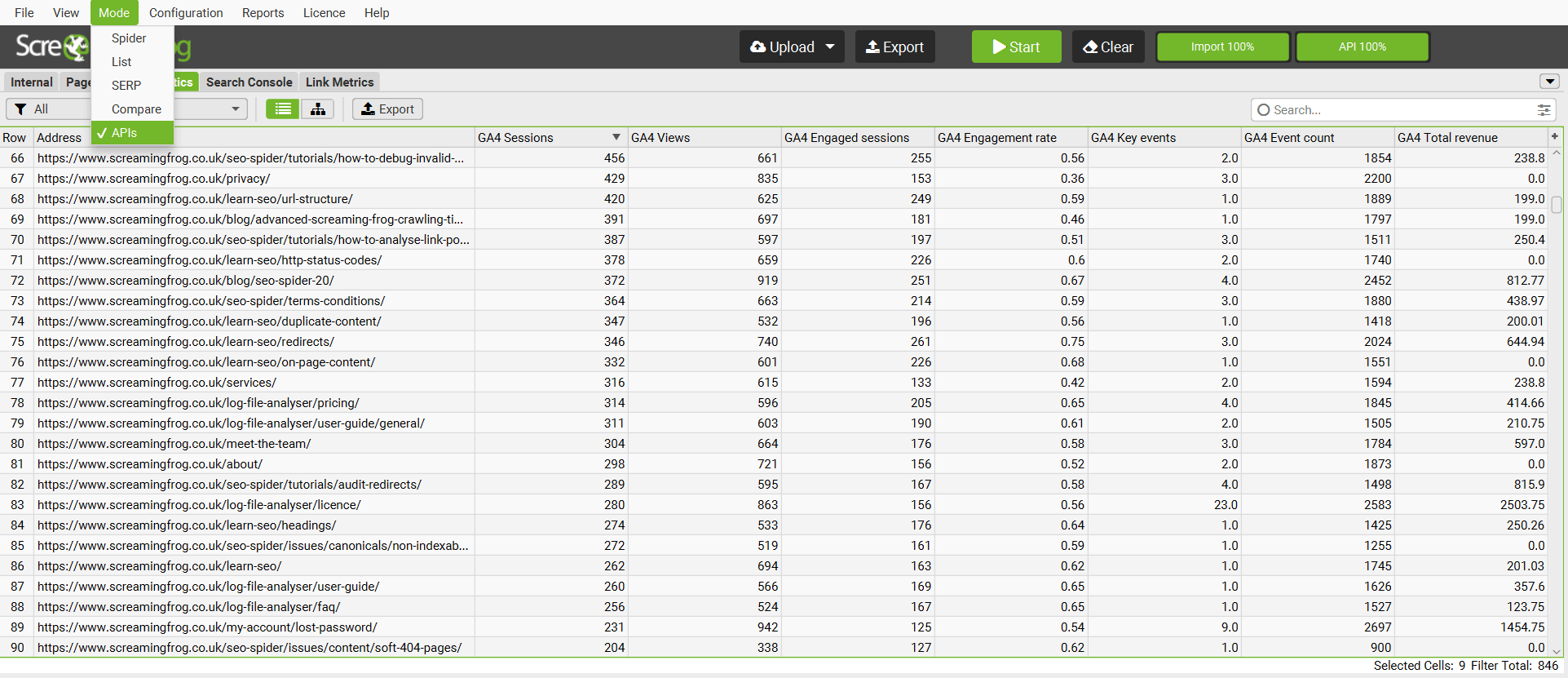
Additionally, there’s been more API improvements:
- The ‘Request API Data’ button in the right-hand APIs tab is now enabled anytime you pause a crawl with a connected API, not just at the end of a completed crawl. Pressing it will resume the API requests (but not the crawl) effectively allowing you to sync all the API data for the URLs you have crawled so far.
- If you modify GA4/GSC config, a dialog will appear before the config window closes asking if you want to remove all existing data and request and apply the new data. Previously if you connected to GA4/GSC, you couldn’t remove the data or re-fetch it. Now you can.
- You can now right click any URL and request data for any of the connected APIs (apart from GA4/GSC). If the crawl already has existing data, this data will be replaced by the new request. These requests will take priority over any other requests in the queue which means they should show up in the table straight away for the user to see. This works for when you are either paused or crawling.
Other Updates
Version 22.0 also includes a number of smaller updates and bug fixes.
- There’s a new ‘Save’ icon next to AI prompts and custom JavaScript snippets which allow you to quickly save them to the library.
- All visualisations now have the option to open in an external browser, which can improve performance at scale.
- Holding ‘control + shift + C’ together will now bring up a configuration diff window to quickly spot any differences between the current config and the default.
- The Moz API has now been updated to v.3. Metrics such as link propensity, spam score and brand authority are now available alongside DA, PA and link numbers.
- You can now select to pull Trust Flow Topics via the Majestic API integration.
That’s everything for version 22.0! After writing this post, we quickly realised there was enough features for two new releases. So if you stayed until the end, thank you!
Thanks to everyone for their continued support, feature requests and feedback. Please let us know if you experience any issues with this latest update via our support.
Small Update – Version 22.1 Released 18th June 2025
We have just released a small update to version 22.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Added custom endpoint functionality to the Ollama integration (to match functionality in OpenAI and Gemini).
- Improved error icons to show tooltip when clicked on.
- Fixed issue exporting to Google Sheets in non-English languages.
- Added Dimension Reduction Presets for Embeddings.
- Added response codes to ‘Missing Confirmation Links’ Report.
- Fixed issue with stall on start up for some Windows users.
- Fixed issue with missing columns in the new advanced column chooser.
- Fixed various unique crashes.
Small Update – Version 22.2 Released 2nd July 2025
We have just released a small update to version 22.2 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Added a configurable minimum score threshold for Semantic Search results.
- Added ‘Bulk Export’ for ‘URL Inspection’ options in APIs Mode.
- Added ‘Command+F’ shortcut to focus the search box in the crawls dialog.
- ‘Export > Output Settings > Output Mode’ setting now remembers state, which was confusing users.
- Fixed ‘Show Issue in Rendered HTML’ which wasn’t working reliably.
- Fixed issue with ‘Overwrite Files’ in output settings causing tabs to be deleted in Google Sheets.
- Fixed issue with ‘Bulk Export > JavaScript > Contains JavaScript Links’ returning no URLs.
- Fixed issue with audio being played after using Visual Custom Extraction for some sites.
- Added Passage Embeddings Snippet to Custom JS System Library. Thanks to Noah Learner!
- Added Indexing Insight Custom JS Snippet To Custom JS ‘System’ Library. Thanks to Adam Gent!
- Fixed various unique crashes.






Great, look forward to downloading the new updated SF and trying it out :)
Great, that was nearly four months ago and all adds up. It is not anymore about keywords but more about their semantics and the tool is a Swiss knife.
Oh wow. I would love to cancel all my appointments today and test everything in peace.
Great additions! The multiple sitemap upload and multiple tabs in a single sheet features will be incredibly useful. Semantic sections will be also exciting.
What’s really exciting are the developments towards AI integration. Features that allow for competitor/market analysis and provide URL performance recommendations will elevate Screaming Frog significantly.
My only extra note is that the Looker Studio integration could be easier and more flexible.
Version 22.0 appears so good. I look forward to future updates that include a feature to delay the rendering of JavaScript pages (apart from AJAX delay). This would be beneficial, as JS redirects often fail to be captured effectively.
Wow, what an incredible update!
The semantic similarity analysis using LLM embeddings is a game-changer – finally going beyond basic text matching to identify content cannibalization and topical gaps. The content cluster visualization looks absolutely fascinating, especially seeing how it mimics natural taxonomies.
Really excited about the AI integration improvements too – being able to run prompts against specific segments and issues will save so many credits, and the Anthropic/Claude integration opens up even more possibilities. The Google Sheets integration for URL lists is brilliant for automation workflows.
The semantic search functionality essentially brings modern search engine logic right into the crawl analysis – this is exactly what we need for better keyword mapping and internal linking strategies.
Screaming Frog continues to stay ahead of the curve with these ML/AI integrations. Can’t wait to dive into the semantic outlier detection for content audits!
Now eagerly waiting for siteFocus and siteRadius! ;)
Thanks for pushing the boundaries of what’s possible in technical SEO tools!
What an INCREDIBLE update! The integration with embeddings and semantic analysis was exactly what was missing to transform Screaming Frog into a true SEO intelligence hub. Excited to test the clusters and vector search — this is a game-changer for those working with audits and information architecture!
I’ve always been amazed by how small, but mighty, the Screaming Frog team is. Updates like this set the bar high for other industry tools and I am always appreciative of the constant evolution and development that this team does without charging astronomical fees for such a powerful tool. Also, great customer support – Dan, do you ever sleep? :) Keep up the great work, Screaming Frog team!
i suggest a feature to convert images > 100kb in webp and awif format . it would useful for page speed optimization.
Congratulations, beyond awesome. Absolutely cracking update—a quantum leap!
SEO folks who’ve wanted to help marketing teams to learn about embeddings/vectorization, to understand semantic similarity, to finally have concrete means w the potential to alter their thinking. It’s one thing to get these analyses, it’s another to help the decision makers to grasp the significance.
Hats off to the team: you’ve not only elevated tool capabilities, it feels like wizardry. Proper legends; from being the most useful tool to being utterly indispensable.
Super duper excited to test out the semantic analysis, cosine similarity right into the tool. Thanks for dropping this insane update!!! Yay!
Amazing update! You’ve put a couple of my Python scripts into a (welcomed) early retirement.
Incredible update! It helps democratize the use of Vector Embeddings and perform semantic analysis.
The Semantic Similarity feature will take this tool to the next level, especially by helping with content analysis like Screaming Frog does. It’s now becoming a holistic SEO tool.
But there’s still an important part missing: off-page SEO. If you can improve integration with Ahrefs or Moz to get referring domains for specific URLs, that would be very useful. Another great feature would be to fetch brand mentions directly from search results.
Also, adding Bing Webmaster Tools integration would be helpful too. Last but not least is Determining referral traffic from Google Analytics. This can be super helpful to understand which URLs are driving traffic from AI tools.
Fantastic work, Screaming Frog. Just what the industry was looking for!
Amazing work! Screaming From shows again what the winning formula is – speed. Massive update, I tested it and I love it. Really well done.
Great update and absolutely stunning work as always. The bulk-export functionality is so incredibly comfortable! Thank you!
The v22.0 update is insane. The new AI features and the Google Drive integration for automating crawls are going to save me hours of work. Updating right now!
Sounds like an amazing update… The only problem is that after installing this update, Screaming Frog immediately crashes. I had to revert back to 21.4 – hope the team can get a quick fix out to address this issue.
Pop us an email ([email protected]), we’ve got a beta for you to use.
Cheers.
Dan
Same issue – Windows 11
Same and sent lots of crash reports. Cannot do a default run even (no APIs / no customizations / just enter URL and hit the go button).
Windows 11 as well.
Same here, it never happened before with any other update. I can barely launch the software and it freezes before I can click on anything.
Hi Guys,
Just pop us an email on [email protected], as we have a beta that will work as expected.
Cheers
Dan
I have an issue here. In this article, a link was given to what I thought was a new animal, the Liger. Come to find out it was a link to a video intended to make me laugh. But the issue is that as soon as that short video ended, YouTube showed me the Cheech and Chong up in smoke car scene. Then I was laughing so hard that I could not even recall what a vector embedding is.
On a more serious note, I’m very interested in the cluster diagramming. I’d like to suggest a follow up blog article that gives some example actions that would be taken on that data, ideally using a real website as a test.
Also I just noticed in the prompt library you have search intent evaluation. This is great but it does seem to exclude one of the standard 3 intents based on the image shown. Will this prompt be expanded in the future?
Thanks for this incredible update! Using AI with Claude and setting up custom prompts to gather crawl data is a great way to boost our analysis of large sites. What I love most is how the semantic search basically brings Google’s own understanding right into our audits. This is exactly the direction the industry needed to move in. Brilliant work, team!
Does anyone know the system requirements for version 22? Version 21 runs fine for now, but when I try to upgrade it says it won’t. Does anyone have an idea of what’s changed? Thanks!
Hi Kevin,
No changes that would make that happen. What OS are you running?
If you’re on a Mac, please ensure you’ve installed the correct version – https://www.screamingfrog.co.uk/seo-spider/faq/#what-version-of-the-seo-spider-to-i-need-for-my-mac
Cheers
Dan
I’m on Windows 11 Enterprise version number 10.0.22631 Build 22631. Sorry. I just saw this.
Hi Kevin,
Give 22.1 a try (available now), if that doesn’t work, do contact us via support – https://www.screamingfrog.co.uk/seo-spider/support/
Cheers
Dan
I just opened it up and and several of us noticed 22 started working. 22.1 doesn’t and I’m getting a certificate error even after going through troubleshooting. Thinking it may just take a couple days for the network on our end to accept things. Thank you!
Wow, what a powerhouse update! The new semantic similarity analysis and content clustering features are incredibly exciting — it’s amazing to see how far SEO tools have come with LLM integrations. The ability to detect low-relevance content and visualize semantic relationships is going to be a game-changer for content audits and strategy. Also loving the thoughtful touches like advanced prompt targeting and multi-export improvements. Big kudos to the Screaming Frog team — version 22.0 is knee-deep in innovation!
Great update! Really looking forward to downloading the new version of SF and giving all the new features a spin — especially the semantic similarity analysis and content clusters. Huge step forward, well done team!
Extremely powerful and great combination of features, big launch by screaming frog, thanks guys.
That looks amazing!
Great update — kudos to the team!
With the new updates and AI features, it’s been getting better and better every day. I’ll try out the features one by one. Thank you.
This is such a great update. I am really enjoying the new features and a lot of functionality will save me and my team hours (if not days) in various projects. Great stuff!
This is an increadible update. I tested the semantic content analysis and I find it useful. But I can´t see if there is a possibility to export to a sheet or excel file the result of the content cluster diagram. How can I see in a file what cluster the each URL belongs?
Me encantan las nueva mejoras , ya lo he actualizado y lo estoy probando la integración con IA y la similitud semántica :-)
Gracias
I had a crash issue as well with the newest version. Just would not respond
Hi Frederik,
Please do send in your logs ([email protected]), so we can help.
Dan
Hi team,
Just a quick note to say thanks for this fantastic update. The semantic similrity feature is a real step forward, and the content cluster visualization is already proving super useful for our website’s audits.
Great work !
Adrien
Screaming Frog just keeps getting better and better!
I am currently using Screaming Frog, and I must say that version 22 has been a game-changer in many respects. However, I’m encountering an issue with bulk exports when segments are applied. While the bulk export functionality works as expected without segments, it fails to do so when a segment is active. Unfortunately, this issue persists even after updating to version 22.2.
This is one of the most needed updates in SEO, huge kudos to the Screaming Frog team! I used the cluster map feature and, although it took me a bit of time to fully grasp concepts like relevance and cosine similarity, it turned out to be incredibly helpful. I managed to identify and clean up over 150 outdated blog posts that were not only irrelevant but were actually hurting the topical authority of the website.
Thanks for the Bugfixes and updates of this great Crawling Software! Couldn’t imagine my SEO Workflows without it.
Cool that you fixed the error icons tooltip, that helps to add more clarity. Also cool that you fixed the issue in the Google Sheets export, really helpful because most auf my SEO-Audits are in German.
Congrats! A great update – now I just need a spare 50 hours to test all this stuff :)
Thank you for your work! We also use the app on a daily basis!
Such a strong release. Semantic similarity + content clustering is exactly what we needed to level up internal linking and trim bloat. Love where this is going.
SF just keeps getting better and better! thank you Kuba
Best & big update :)
This version 22.0 update is a game-changer, thank you Screaming Frog team! The inclusion of semantic similarity analysis, powered by LLM embeddings, takes content audits to a whole new level. It’s awesome to finally identify conceptually overlapping pages, even when phrasing differs, no more sneaky cannibalization or missed consolidation opportunities. Hats off to the team, this isn’t just an update; it’s a leap forward for SEO pros everywhere.
Ever since the 22.2 update my Screaming Frog has a buggy menu and shows the context menu options (the menu that opens after clicking on one of the main menu points) would appear hanging loosely on the very left of the screen next to the program itself. Makes navigating through the option really bothersome (especially with a maxed window since the menu options disappear then into the outer screen space). If I happen to drag the programm to my main screen (laptop), it usually works properly there. Tried reinstalling two times, one of which I switched back to 18.0, but still the same issues and every time on secondary monitors that are plugged in over hdmi. Would wanna go back to 22.0 but don’t have a backup unfortunately
Hi MedienT,
You won’t be shocked by my reply. Please email us at support – https://www.screamingfrog.co.uk/seo-spider/support/
Thanks!
Dan
So happy about this extensive update! Semantic Search is my favorite! Thank you guys :))
This update feels like a game‑changer for technical SEOs and content strategists. The new semantic similarity and content clustering features finally make it realistic to diagnose content cannibalization, topical gaps, and low‑relevance pages directly inside a crawler instead of stitching everything together in external BI tools.