Screaming Frog SEO Spider Update – Version 10.0
Dan Sharp
Posted 19 September, 2018 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 10.0
We are delighted to announce the release of Screaming Frog SEO Spider version 10.0, codenamed internally as ‘Liger‘.
In our last release, we announced an extremely powerful hybrid storage engine, and in this update, we have lots of very exciting new features driven entirely by user requests and feedback. So, let’s get straight to them.
1) Scheduling
You can now schedule crawls to run automatically within the SEO Spider, as a one off, or at chosen intervals.

You’re able to pre-select the mode (spider, or list), saved configuration, as well as APIs (Google Analytics, Search Console, Majestic, Ahrefs, Moz) to pull in any data for the scheduled crawl.

You can also automatically save the crawl file and export any of the tabs, filters, bulk exports, reports or XML Sitemaps to a chosen location.

This should be super useful for anyone that runs regular crawls, has clients that only allow crawling at certain less-than-convenient ‘but, I’ll be in bed!’ off-peak times, uses crawl data for their own automatic reporting, or have a developer that needs a broken links report sent to them every Tuesday by 7 am.
The keen-eyed among you may have noticed that the SEO Spider will run in headless mode (meaning without an interface) when scheduled to export data – which leads us to our next point.
2) Full Command Line Interface & –Headless Mode
You’re now able to operate the SEO Spider entirely via command line. This includes launching, full configuration, saving and exporting of almost any data and reporting.
It behaves like a typical console application, and you can use –help to view the full arguments available.
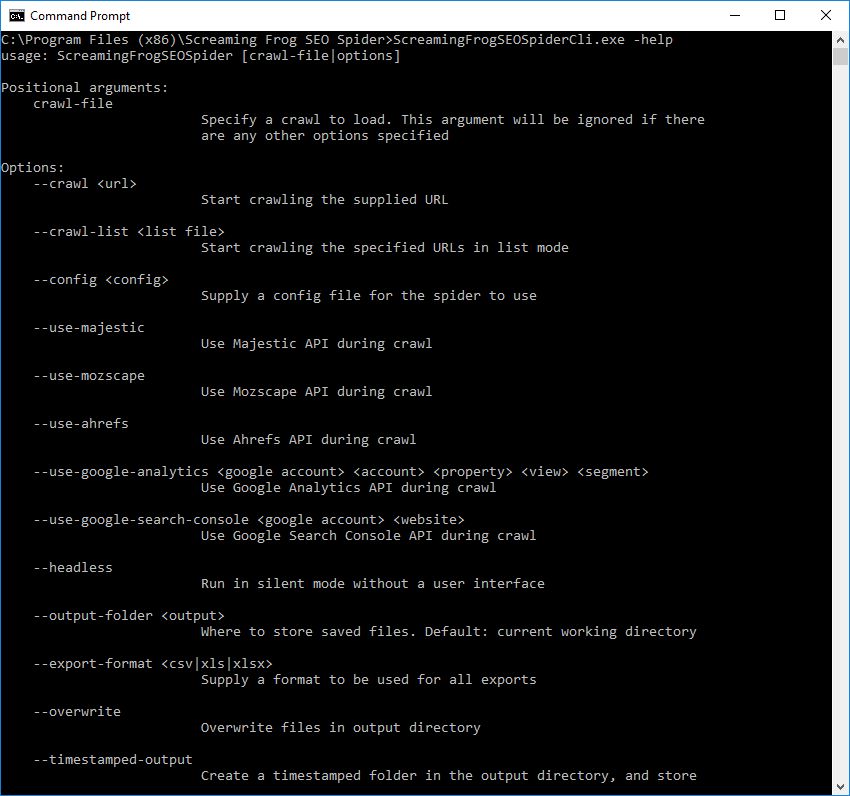
You can read the full list of commands that can be supplied and how to use the command line in our updated user guide. This also allows running the SEO Spider completely headless, so you won’t even need to look at the user interface if that’s your preference (how rude!).
We believe this can be an extremely powerful feature, and we’re excited about the new and unique ways users will utilise this ability within their own tech stacks.
3) Indexability & Indexability Status
This is not the third biggest feature in this release, but it’s important to understand the concept of indexability we have introduced into the SEO Spider, as it’s integrated into many old and new features and data.
Every URL is now classified as either ‘Indexable‘ or ‘Non-Indexable‘.
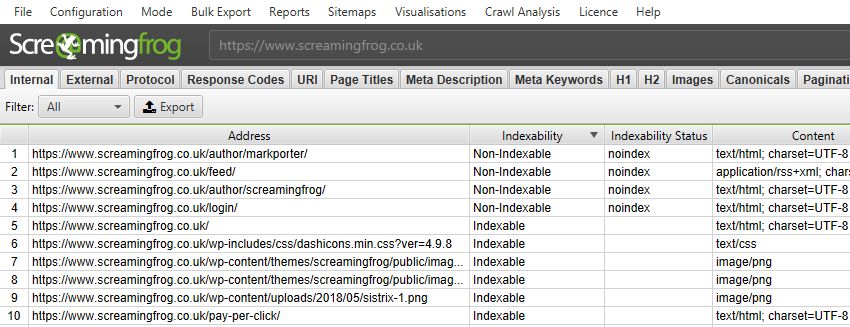
These two phrases are now commonplace within SEO, but they don’t have an exact definition. For the SEO Spider, an ‘Indexable’ URL means a page that can be crawled, responds with a ‘200’ status code and is permitted to be indexed.
This might differ a little from the search engines, which will index URLs which can’t be crawled and content that can’t be seen (such as those blocked by robots.txt) if they have links pointing to them. The reason for this is for simplicity, it helps to bucket and organise URLs into two distinct groups of interest.
Each URL will also have an indexability status associated with it for quick reference. This provides a reason why a URL is ‘non-indexable’, for example, if it’s a ‘Client Error’, ‘Blocked by Robots.txt, ‘noindex’, ‘Canonicalised’ or something else (and perhaps a combination of those).
This was introduced to make auditing more efficient. It makes it easier when you export data from the internal tab, to quickly identify which URLs are canonicalised for example, rather than having to run a formula in a spreadsheet. It makes it easier at a glance to review whether a URL is indexable when reviewing page titles, rather than scanning columns for canonicals, directives etc. It also allows the SEO Spider to use a single filter, or two columns to communicate a potential issue, rather than six or seven.
4) XML Sitemap Crawl Integration
It’s always been possible to crawl XML Sitemaps directly within the SEO Spider (in list mode), however, you’re now able to crawl and integrate them as part of a site crawl.
You can select to crawl XML Sitemaps under ‘Configuration > Spider’, and the SEO Spider will auto-discover them from robots.txt entry, or the location can be supplied.
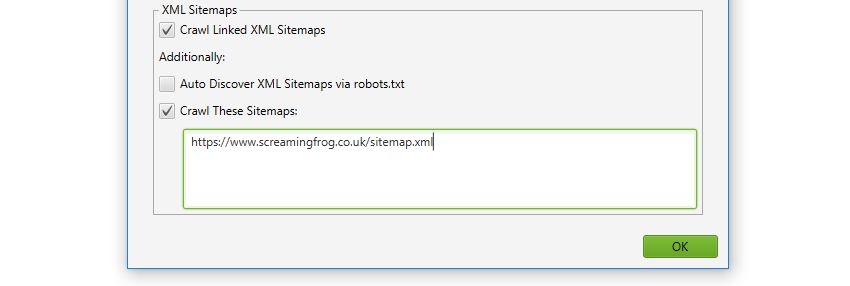
The new Sitemaps tab and filters allow you to quickly analyse common issues with your XML Sitemap, such as URLs not in the sitemap, orphan pages, non-indexable URLs and more.
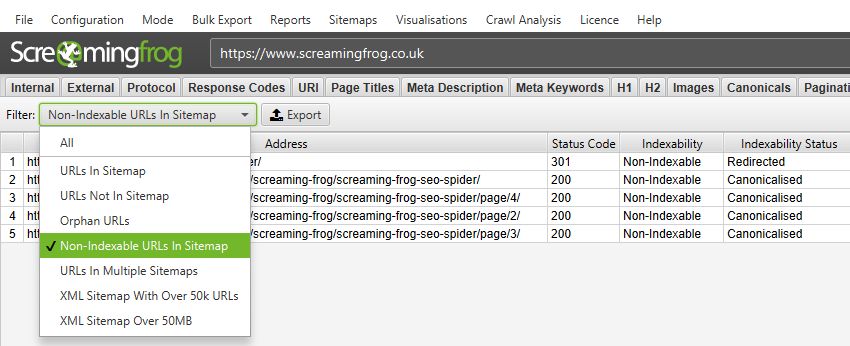
You can also now supply the XML Sitemap location into the URL bar at the top, and the SEO Spider will crawl that directly, too (instead of switching to list mode).
5) Internal Link Score
A useful way to evaluate and improve internal linking is to calculate internal PageRank of URLs, to help get a clearer understanding about which pages might be seen as more authoritative by the search engines.
The SEO Spider already reports on a number of useful metrics to analyse internal linking, such as crawl depth, the number of inlinks and outlinks, the number of unique inlinks and outlinks, and the percentage of overall URLs that link to a particular URL. To aid this further, we have now introduced an advanced ‘link score’ metric, which calculates the relative value of a page based upon its internal links.
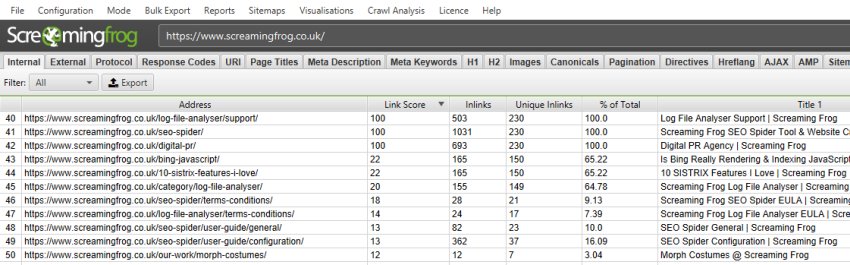
This uses a relative 0-100 point scale from least to most value for simplicity, which allows you to determine where internal linking might be improved.
The link score metric algorithm takes into consideration redirects, canonicals, nofollow and much more, which we will go into more detail in another post.
This is a relative mathematical calculation, which can only be performed at the end of a crawl when all URLs are known. Previously, every calculation within the SEO Spider has been performed at run-time during a crawl, which leads us on to the next feature.
6) Post Crawl Analysis
The SEO Spider is now able to perform further analysis at the end of a crawl (or when it’s stopped) for more data and insight. This includes the new ‘Link Score’ metric and a number of other new filters that have been introduced.
Crawl analysis can be automatically performed at the end of a crawl, or it can be run manually by the user. This can be viewed under ‘Crawl Analysis > Configure’ and the crawl analysis can be started by selecting ‘Crawl Analysis > Start’. When the analysis is running, the SEO Spider can continue to be used as normal.
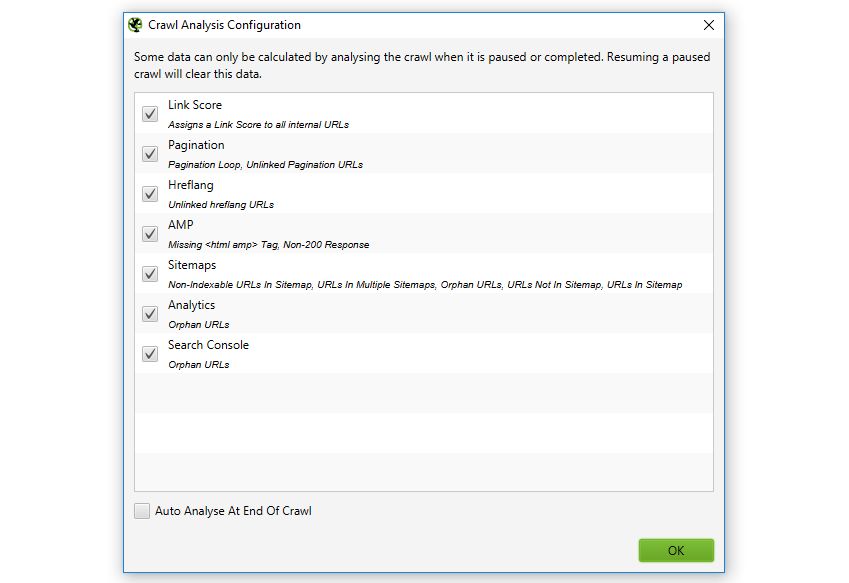
When the crawl analysis has finished, the empty filters which are marked with ‘Crawl Analysis Required’, will be populated with data.
Most of these items were already available via reports, but this new feature brings them into the interface to make them more visible, too.
7) Visualisations
We have a confession. We have always loved the idea of crawl visualisations, but have always had a problem with them – they were rarely actionable. They too frequently don’t help diagnose actual problems, hide data, and often don’t reflect the real world view of a crawl either. Although, they have always looked pretty, and some SEOs are able to read them like a piece of abstract art. That said, the actual concept is fun and exciting, and due to overwhelming popular demand, we went to the drawing board.
Portent originally introduced the concept of force-directed diagrams to the SEO industry, and a few providers already provide various useful site visualisations (and kudos to them), but we don’t believe any of them were perfect, and we wanted to see if we could challenge our own assumptions of their limits.
We wanted to build a better way of visually understanding a site, its architecture, internal link structure and issues. We wanted to make them scalable, and we didn’t want to have to hide data from users to make them work.
So, we have introduced two types of diagrams, and two different perspectives on viewing a site, each with their own benefits that we believe provide more actionable data, and insight.
These include two crawl visualisations, and two directory tree visualisations.

Crawl Visualisations
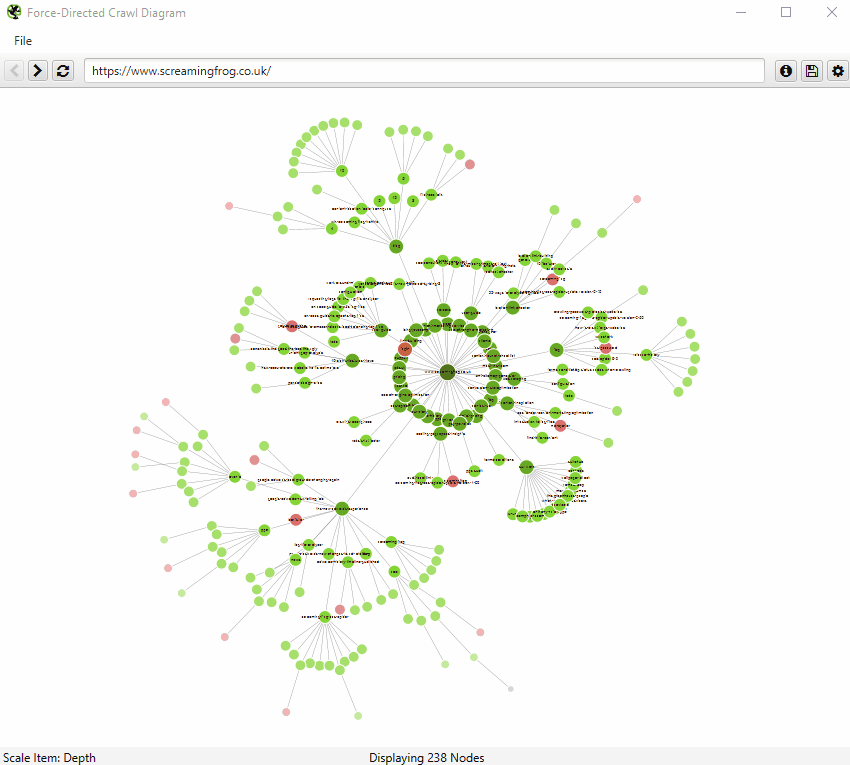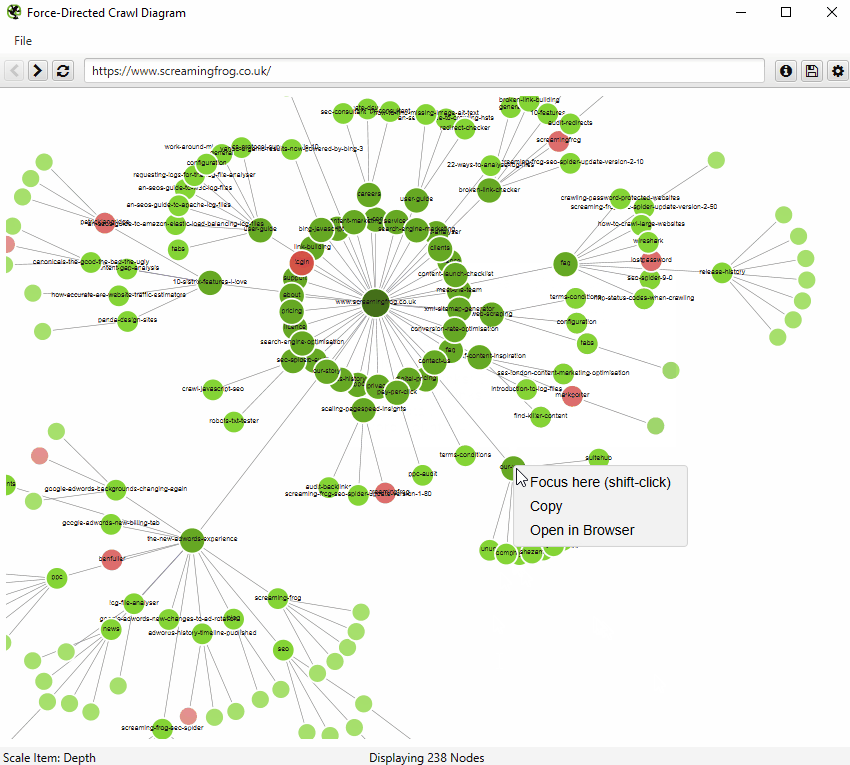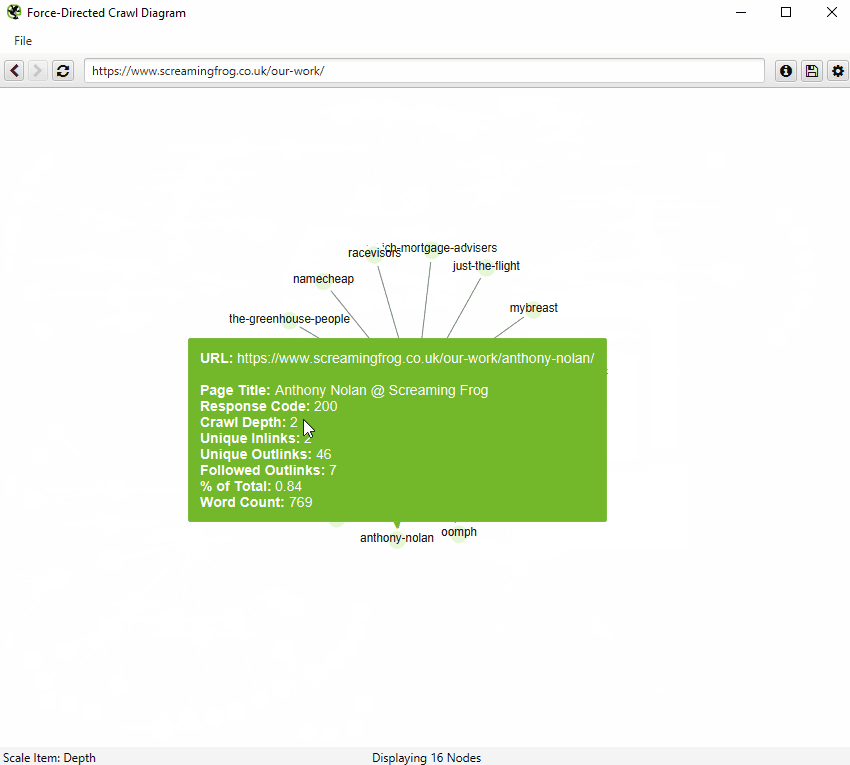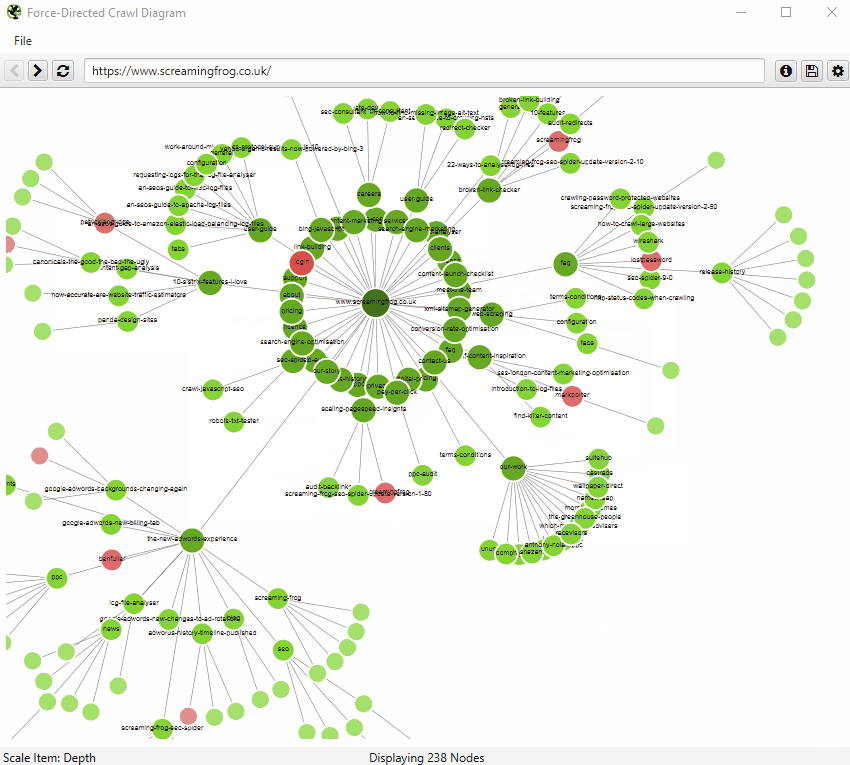
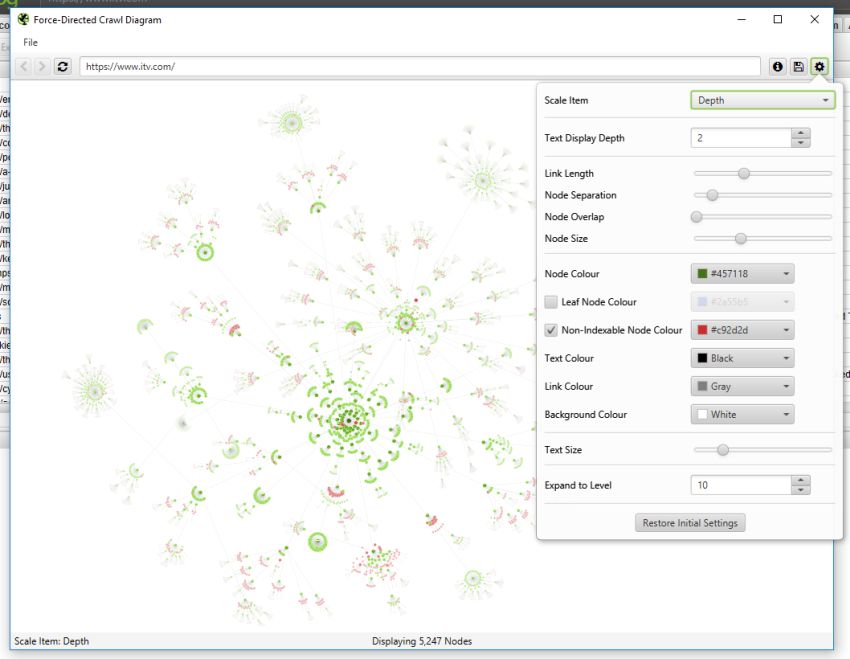
The force-directed crawl diagram and crawl graph visualisations are useful for analysis of internal linking, as they provide a view of how the SEO Spider has crawled the site, by shortest path to a page. Here’s how our own website can be seen with our force-directed crawl diagram.
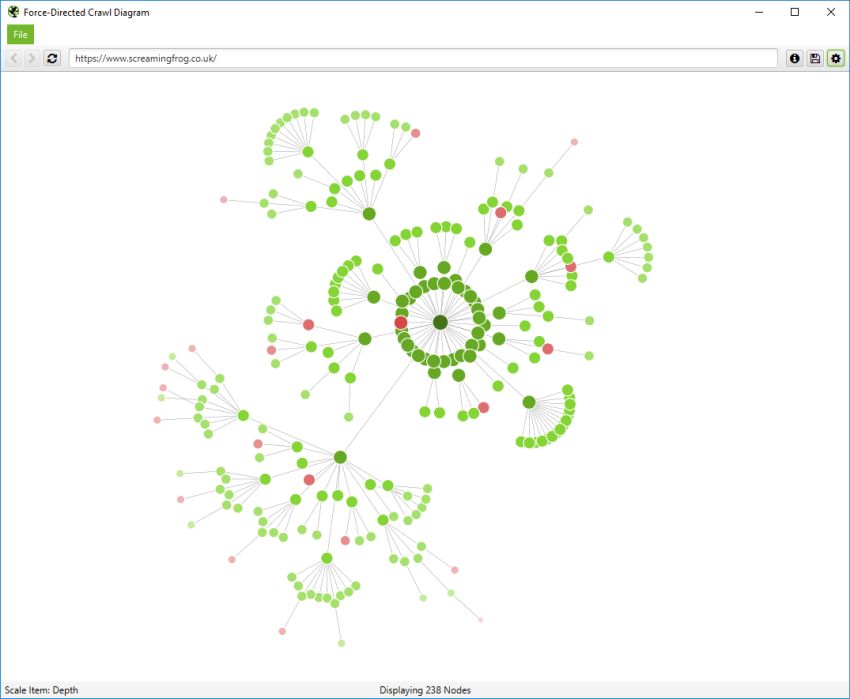
Indexable pages are represented by the green nodes, the darkest, largest circle in the middle is the start URL (the homepage), and those surrounding it are the next level deep, and they get further away, smaller and lighter with increasing crawl depth (like a heatmap).
One of the problems with crawl visualisations is scale. They are really memory intensive and the force-directed crawl diagram visualisations do not scale very well due to the amounts of data. The browser will start to grind to a halt at anything above 10k URLs, unless interactivity and other bells and whistles were removed, which would be a shame, as that’s part of their appeal. However, it’s sites on a larger scale that need visualisations the most, to really understand them.
So, as site architecture doesn’t start and end at the homepage, our visualisations can be viewed from any URL.
The visualisation will show up to 10k URLs in the browser, but allow you to right-click and ‘focus’ to expand on particular areas of a site to show more URLs in that section (up to another 10k URLs at a time). You can use the browser as navigation, typing in a URL directly and moving forwards and backwards with ease.
You can also right-click on any URL in a crawl, and open up a visualisation from that point as a visual URL explorer.
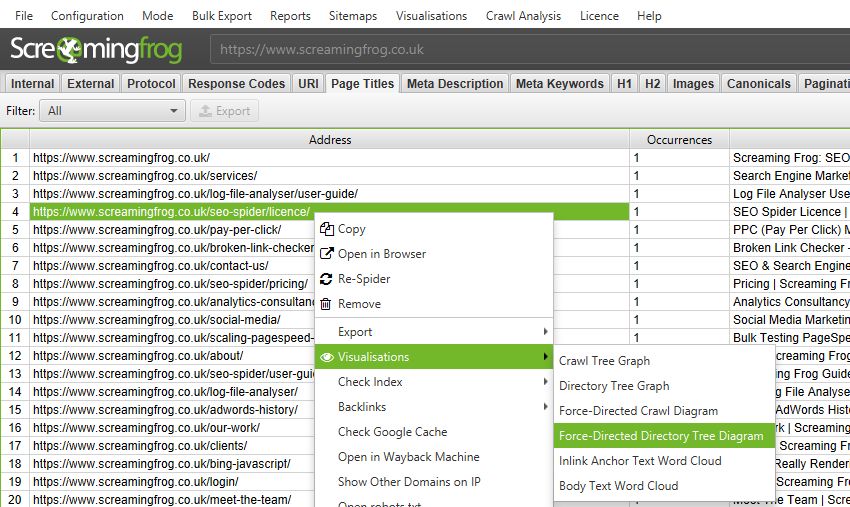
When a visualisation has reached the 10k URL limit, it lets you know when a particular node has children that are being truncated (due to size limits), by colouring the nodes grey. You can then right click and ‘explore’ to see the children. This way, every URL in a crawl can be visualised.
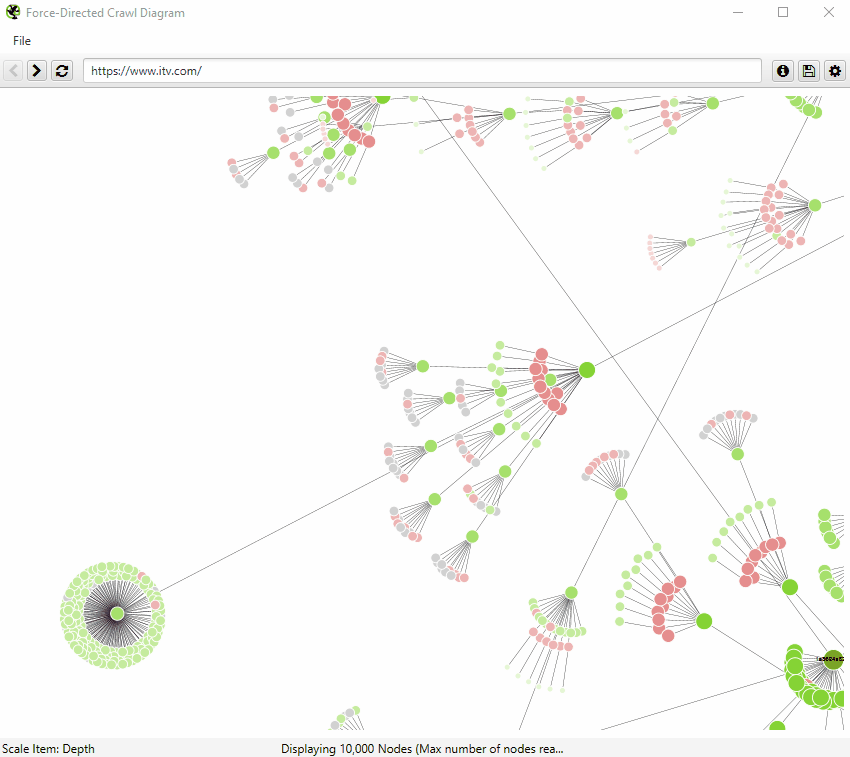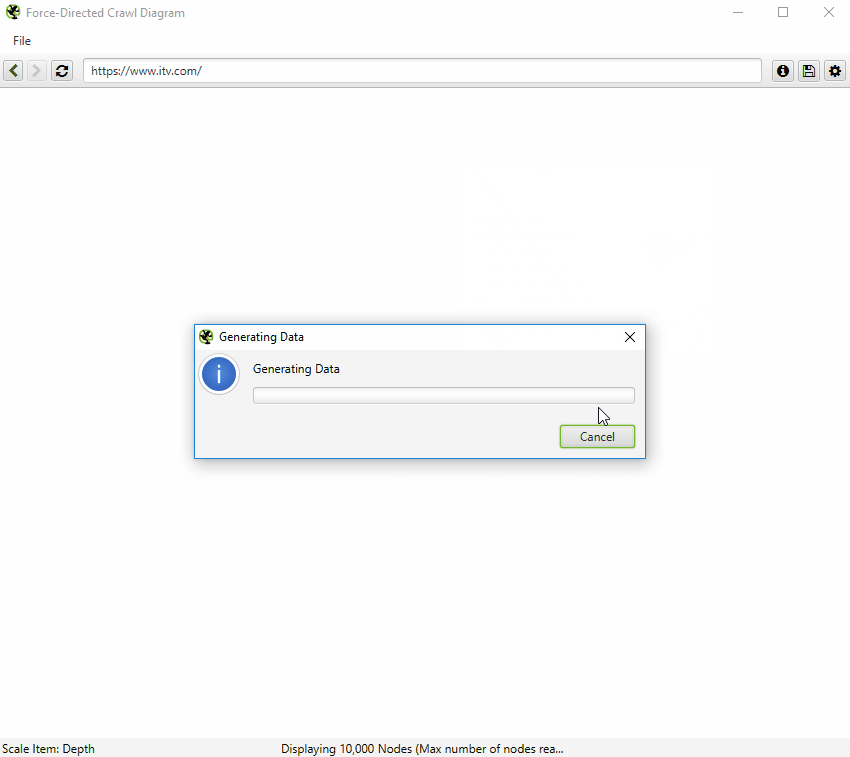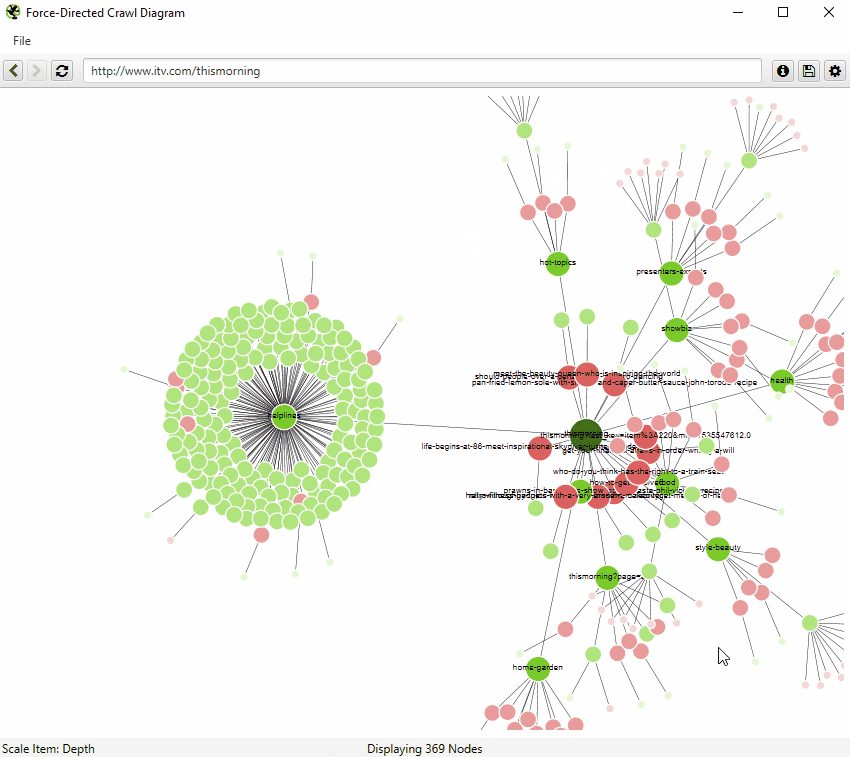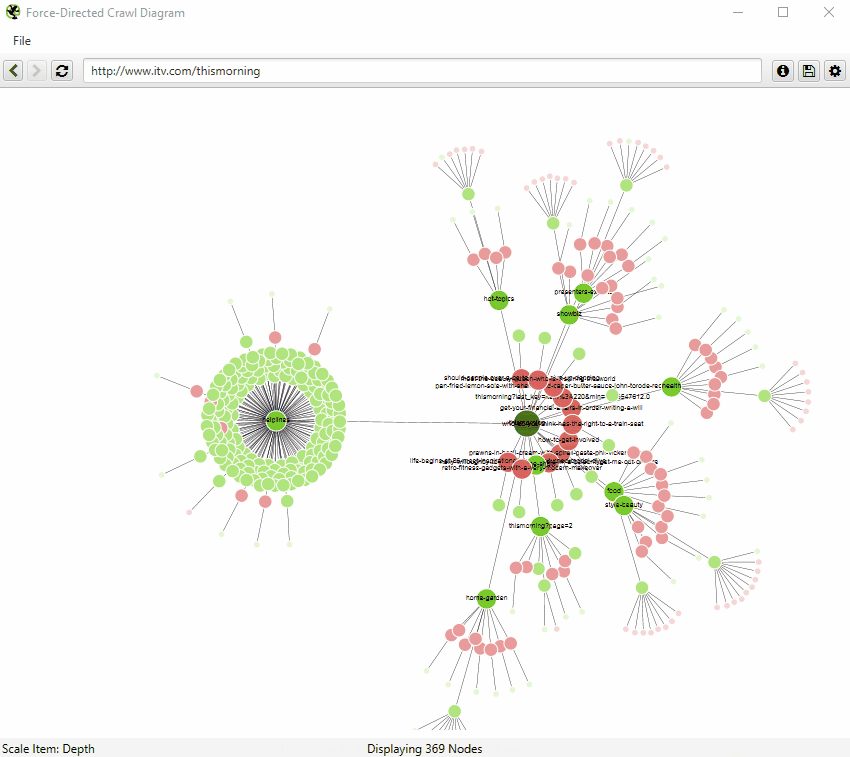
The pastel red highlights URLs are non-indexable, which makes it quite easy to spot problematic areas of a website. There are valid reasons for non-indexable pages, but visualising their proportion and where they are, can be useful in quickly identifying areas of interest to investigate further.
We also took the force-directed diagrams a few steps further, to allow a user to completely configure them visually, in size of nodes, overlap, separation, colour, link length and when to display text.
After all, they are arguably more like works of art.

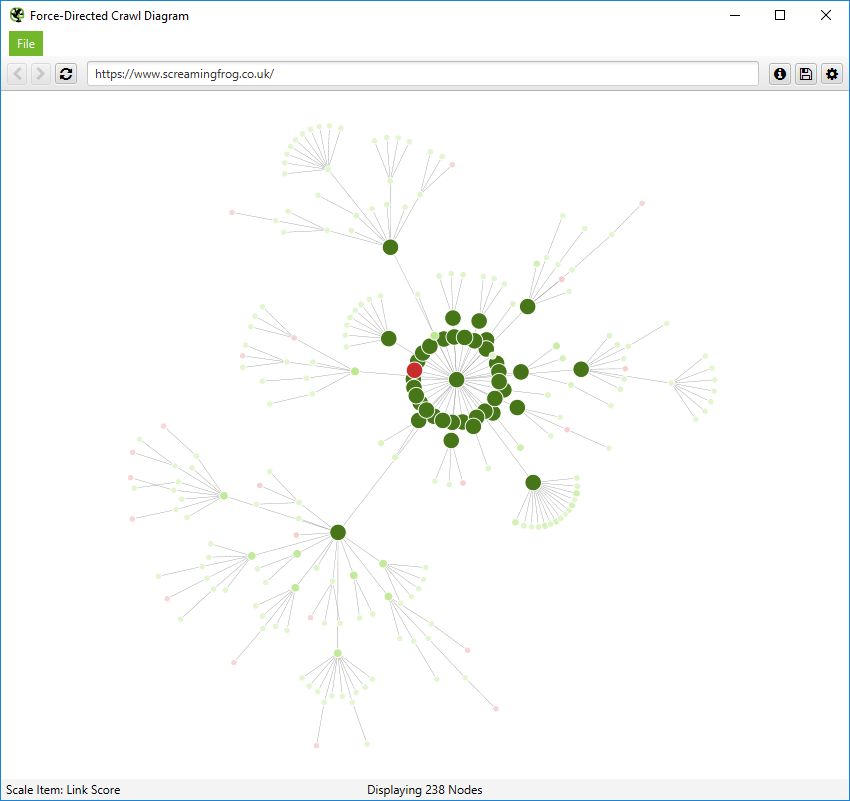
More significantly, you also have the ability to scale visualisations by other metrics to provide greater insight, such as unique inlinks, word count, GA Sessions, GSC Clicks, Link Score, Moz Page Authority and more.
The size and colour of nodes will scale based upon these metrics, which can help visualise many different things alongside internal linking, such as sections of a site which might have thin content.
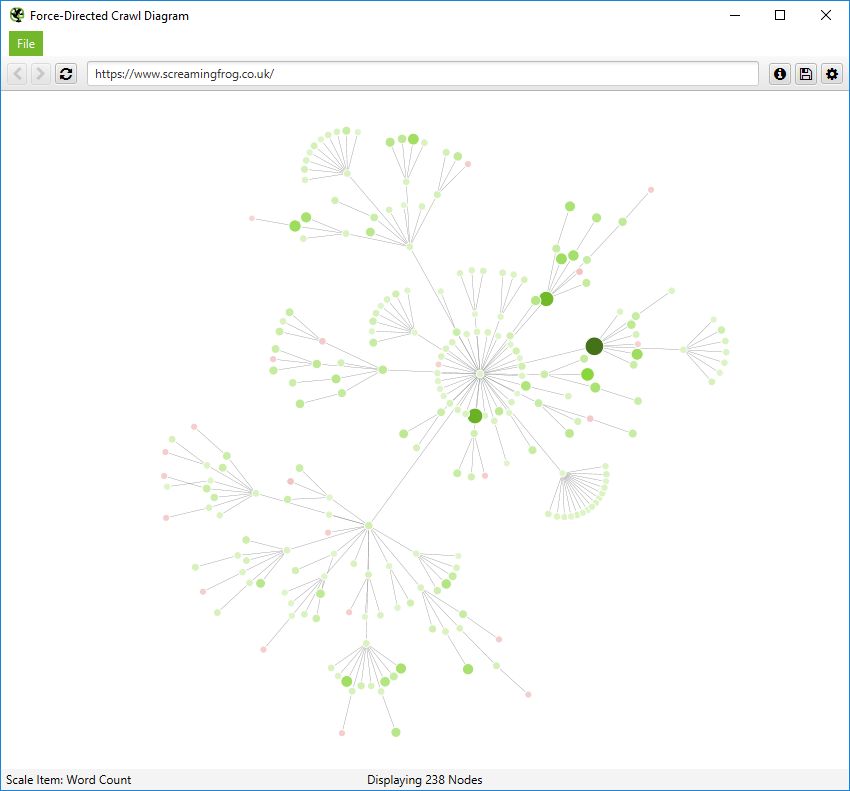
Or highest value by link score.
It can be hard to quickly see pages in a force-directed diagram, as beautiful as they are. So you can also view internal linking in a more simplistic crawl tree graph, which can be configured to display left to right, or top to bottom (or bottom to top, if you’re slightly weird).
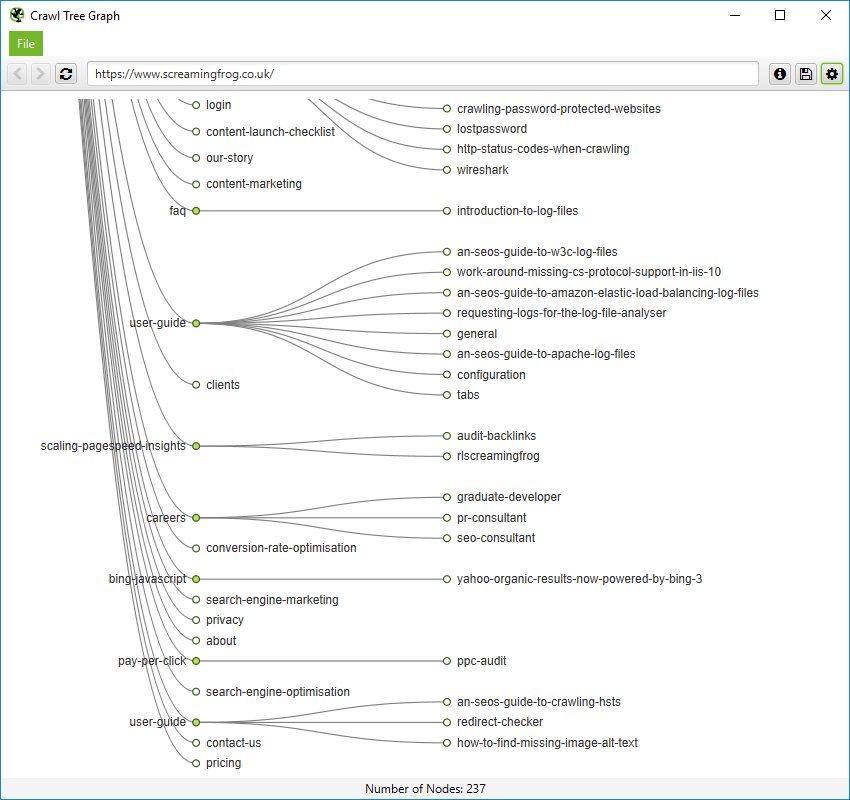
You can right click and ‘focus’ on particular areas of the site. You can also expand or collapse up to a particular crawl depth, and adjust the level and node spacing, to get it just right.
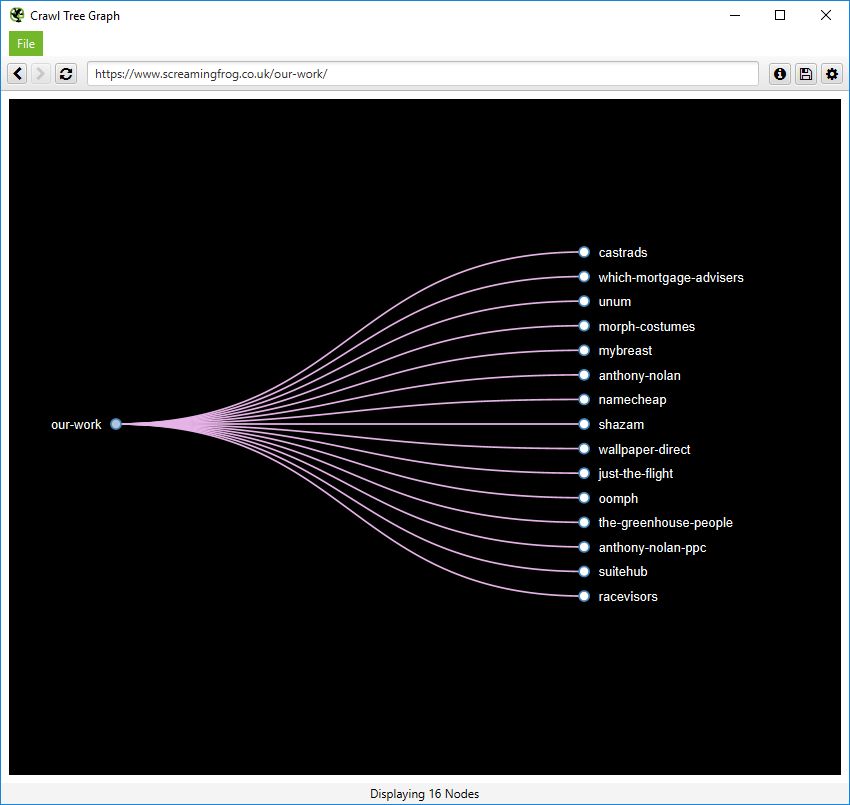
Like the force-directed diagrams, all the colours can also be adjusted for fun (or if you have to be boring and use brand colours).
Directory Tree Visualisations
The ‘Directory Tree’ view in the SEO Spider has been a favourite of users for a long time, and we wanted to introduce this into our visualisations.
The key differentiator is that it helps to understand a site’s URL architecture, and the way it’s organised, as opposed to internal linking of the crawl visualisations. This can be useful, as these groupings often share the same page templates, and SEO issues (but not always).
The force-directed directory tree diagram is unique to the SEO Spider and you can see it’s very different for a crawl of our site than the previous crawl diagram and easier to visualise potential problems.
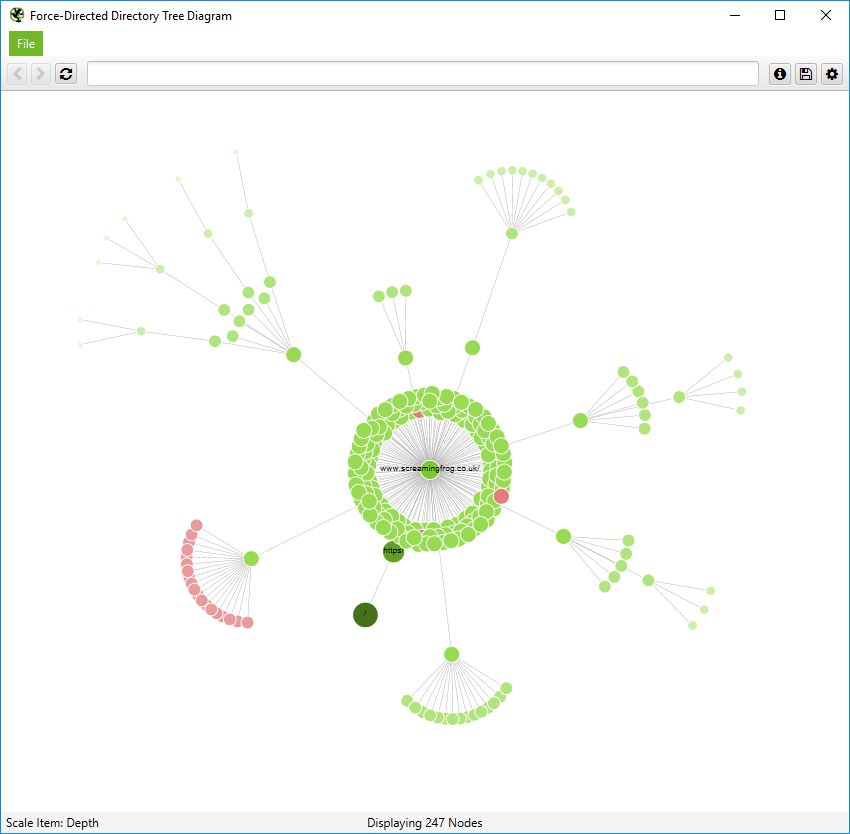
Notice how the non-indexable red nodes are organised together, as they have the same template, whereas in the crawl diagram they are distributed throughout. This view often makes it easier to see patterns.
This can also be viewed in a simplistic directory tree graph format, too. These graphs are interactive and here’s a zoomed in, top-down view of a section of our website.

While the SEO Spider’s visualisations don’t solve all the problems mentioned at the outset of this feature, they are a step in the right direction to making them more insightful, a truer representation of a site, and ultimately, useful.
We believe there might be a sweet spot middle ground between the crawl and directory tree visualisations, but that’s work in progress. If there are any further scale metrics you’d like to see introduced into these visualisations, then do let us know.
Anchor & Body Text Word Clouds
Due to our visualisation integration, you can also visualise all internal anchors to a URL, and the body text of a page.
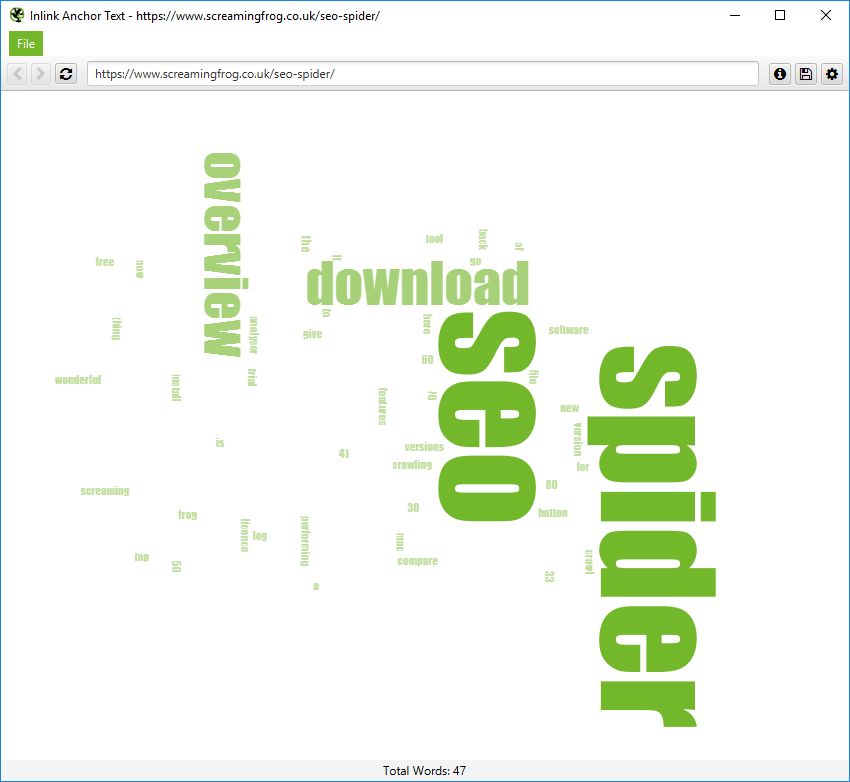
These options are available via right-clicking a URL and choosing ‘Visualisations’.
8) AMP Crawling & Validation
You can now automatically extract and crawl accelerated mobile pages (AMP), analyse and validate them.
You can quickly identify various common AMP issues via the new AMP tab and filters, such as errors, missing canonicals or non-confirming links with the desktop version.
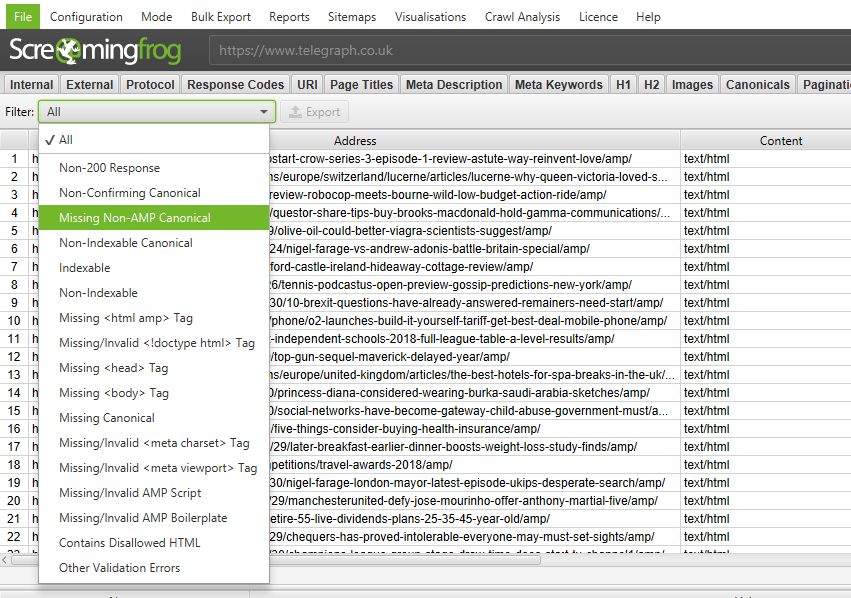
The AMP Validator has also been integrated into the SEO Spider, so you can crawl and identify any validation issues at scale. This includes the exact checks from the AMP Validator, for all required HTML as per the specification, and disallowed HTML.
9) Canonicals & Pagination Tabs & Filters
Canonicals and pagination were previously included under the directives tab. However, neither are directives and while they are useful to view in combination with each other, we felt they were deserving of their own tabs, with their own set of finely tuned filters, to help identify issues faster.
So, both have their own new tabs with updated and more granular filters. This also helps expose data that was only previously available within reports, directly into the interface. For example, the new canonicals tab now includes a ‘Non-Indexable Canonical’ filter which could only be seen previously by reviewing response codes, or viewing ‘Reports > Non-Indexable Canonicals’.
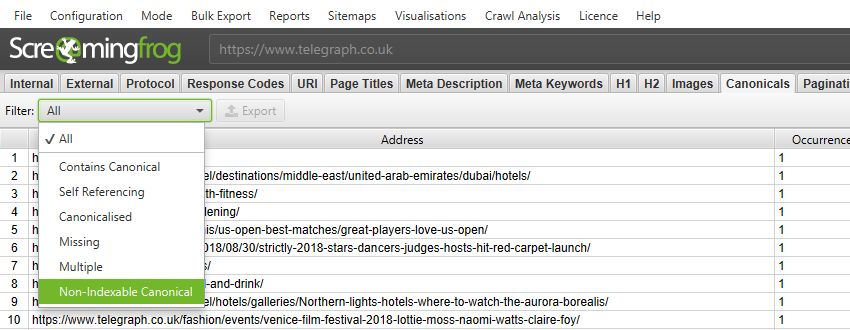
Pagination is something websites get wrong an awful lot, it’s nearly at hreflang levels. So, there’s now a bunch of useful ways to filter paginated pages under the pagination tab to identify common issues, such as non-indexable paginated pages, loops, or sequence errors.
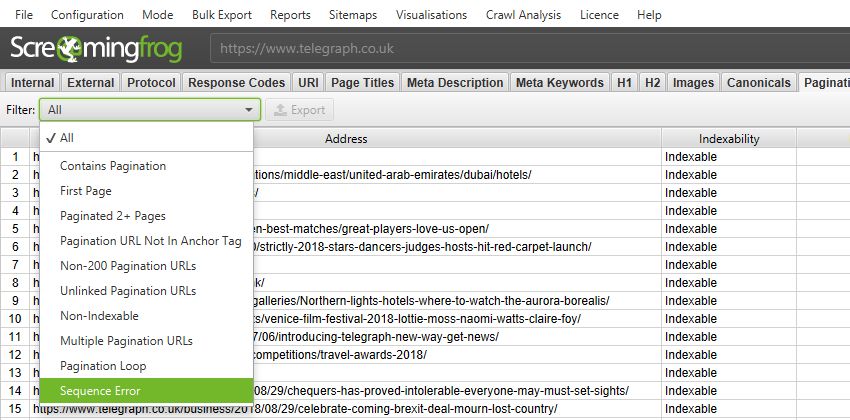
The more comprehensive filters should help make identifying and fixing common pagination errors much more efficient.
10) Improved Redirect & Canonical Chain Reports
The SEO Spider now reports on canonical chains and ‘mixed chains’, which can be found in the renamed ‘Redirect & Canonical Chains’ report.
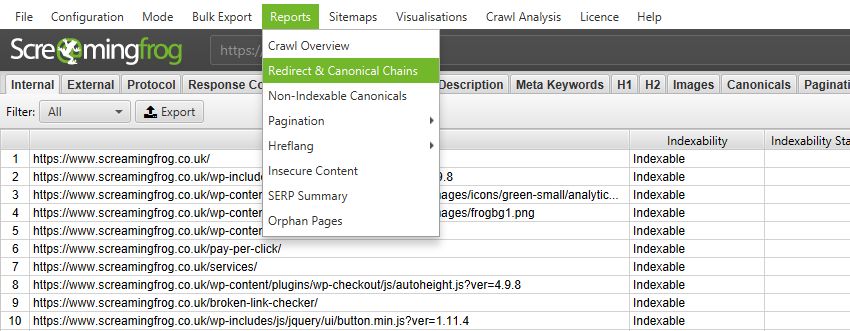
For example, the SEO Spider now has the ability to report on mixed chain scenarios such as, redirect to a URL which is canonicalised to another URL, which has a meta refresh to another URL, which then JavaScript redirects back to the start URL. It will identify this entire chain, and report on it.
The updated report has also been updated to have fixed position columns for the start URL, and final URL in the chain, and reports on the indexability and indexability status of the final URL to make auditing more efficient to see if a redirect chain ends up at a ‘noindex’ or ‘error’ page etc. The full hops in the chain are still reported as previously, but in varying columns afterwards.
This means auditing redirects is significantly more efficient, as you can quickly identify the start and end URLs, and discover the chain type, the number of redirects and the indexability of the final target URL immediately. There’s also flags for chains where there is a loop, or have a temporary redirect somewhere in the chain.
There simply isn’t a better tool anywhere for auditing redirects at scale, and while a feature like visualisations might receive all the hype, this is significantly more useful for technical SEOs in the trenches every single day. Please read our updated guide on auditing redirects in a site migration.
Other Updates
Version 10.0 also includes a number of smaller updates and bug fixes, outlined below.
- You’re now able to automatically load new URLs discovered via Google Analytics and Google Search Console, into a crawl. Previously new URLs discovered were only available via the orphan pages report, this now configurable. This option can be found under ‘API Access > GA/GSC > General’.
- ‘Non-200 Hreflang URLs’ have now been moved into a filter under the ‘Hreflang tab.
- You can disable respecting HSTS Policy under the advanced configuration (to retrieve true redirect status codes easier, rather than an internal 307) .
- The ‘Canonical Errors’ report has been renamed to ‘Non-Indexable Canonicals’ and is available under reports in the top level menu.
- The ‘rel=”next” and rel=”prev” Errors’ report has been adjusted to ‘Pagination’ > ‘Non-200 Pagination URLs’ and ‘Unlinked Pagination URLs’ reports.
- Hard disk space has been reduced by around 30% for crawls in database storage mode.
- Re-spidering of URLs in bulk on larger crawls is faster and more reliable.
- There are new ‘bulk exports’ for Sitemaps and AMP as you would expect.
- The main URL address bar at the top is now much wider.
- Donut charts and right click highlighting colours have been updated.
- There’s a new ‘Always Follow Canonicals‘ configuration item for list mode auditing.
- The 32k character limit for custom extraction has been removed.
- ‘rel=”next” and rel=”prev” are now available in the ‘Internal’ tab.
- ‘Max Redirects To Follow’ configuration has been moved under the ‘Limits’ tab.
- There’s now a ‘resources’ lower window tab, which includes (you guessed it), resources.
- The Google Search Console integration website profiles list is now searchable.
- The include and exclude configuration, now have a ‘test’ tab to help test your regex pre a crawl.
- There’s a new splash screen on start-up.
- There’s a bunch of new right click options for popular checks with other tools such as PageSpeed Insights, the Mobile Testing Tool etc.
That’s everything. If you made it this far and are still reading, thank you for caring. Thank you to everyone for the many feature requests and feedback, which have helped the SEO Spider improve so much over the past 8 years.
If you experience any problems with the new version, then please do just let us know via support and we can help.
Now, go and download version 10.0 of the Screaming Frog SEO Spider.
Small Update – Version 10.1 Released 21st September 2018
We have just released a small update to version 10.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Fix issue with no URLs displaying in the UI when ‘Respect Next/Prev’ is ticked.
- Stop visualisations popping to the front after displaying pop-ups in the main UI.
- Allow configuration dialogs to be resized for users on smaller screens.
- Update include & exclude test tabs to show the encoded URL that the regular expressions are run against.
- Fix a crash when accessing GA/GSC via the scheduling UI.
- Fix crash when running crawl analysis with no results.
- Make tree graph and force-directed diagram fonts configurable.
- Fix issue with bold and italic buttons not resetting to default on graph config panels.
Small Update – Version 10.2 Released 3rd October 2018
We have just released a small update to version 10.2 of the SEO Spider. This release is mainly bug fixes and small improvements –
- –headless can now be run on Ubuntu under Windows.
- Added configuration option “Respect Self Referencing Meta Refresh” (Configuration > Spider > Advanced). Lots of websites have self-referencing meta refereshes, which can be classed as ‘non-indexable’, and this can now simply be switched off.
- URLs added to the crawl via GA/GSC now got through URL rewriting and exclude configuration.
- Various scheduling fixes.
- The embedded browser now runs in a sandbox.
- The Force-Directed Diagram directory tree now considers non-trailing slash URLs as potential directories, and doesn’t duplicate where appropriate.
- Fix bug with ‘Custom > Extraction’ filter missing columns when run headless.
- Fix issue preventing crawls saving with more than 32k of custom extraction data.
- Fix issue with ‘Link Score’ not being saved/restored.
- Fix crash when accessing the Forms Based Authentiction.
- Fix crash when uploading duplicate SERP URLs.
- Fix crashes introduced by update to macOS 10.14 Mojave.
Small Update – Version 10.3 Released 24th October 2018
We have just released a small update to version 10.3 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Custom search now works over multiple lines.
- Introduced a ‘Contains Hreflang’ filter, inline with other tabs and elements (Canonicals, Pagination etc).
- Renamed hreflang ‘Incorrect Language Codes’ filter, to ‘Incorrect Language & Region Codes’.
- Reworked GSC account selection to improve usability.
- URLs discovered via sitemaps now go via URL rewriting.
- Be more tolerant of XML Sitemap/Sitemap index files missing the XML declaration (Google process them, so the SEO Spider now does, too).
- Include the protocol in ‘Orphan Pages’ report for GSC & XML Sitemaps URLs.
- Warn on startup if network debugging is on. This slows crawls down, and should not be enabled unless requested by our support.
- Fix “Maximum call stack size exceeded” with visualisations.
- Fix crash writing ‘Reports > Overview’.
- Fix error exporting ‘Hreflang:Inconsistent Language Confirmation Links’ from command line.
- Fix crash when running Crawl Analysis.
- Fix crash triggered by pages with invalid charset names.
- Fix scheduler issue with Hebrew text.
- Fix crash crawling AMP URLs.
- Fix macOS issue where scheduling failed if the LaunchAgents folder didn’t exist.
- Fix anti aliasing issue in Ubuntu.
Small Update – Version 10.4 Released 6th November 2018
We have just released a small update to version 10.4 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Fix slow down of database crawls (when crawling and saving).
- Fix crash in SERP generation.
- Stop including URLs without crawl depth, in crawl depth statistics.
- Update Crawl Depth chart label to 10+.
- Fix indexability classification bug.
- Fix custom search to be case insensitive for both ‘Contains’ and ‘Does Not Contain’.
- Fix typo in GA Page Views Per Session GA metrics.
- Fix crash when hovering over doughnut charts.






I think you are one of the companies that pays the most attention to the community and its opinion. Keep making the best crawler :)
Thanks, Georgi! We do, it’s been a community driven product for years. We just (try) and build what everyone needs.
Hope you like it!
Dan & team, there are some incredible updates here.
Particularly excited for #3 and being able to see indexable pages at a glance.
These updates are one of the many reasons I’m happy to pay year after year. Thanks for what you bring to this space!
Hey Glenn,
Really appreciate the kind words.
Good to hear you like indexability as well – a small feature, but it does make spotting potential issues so much simpler!
Cheers.
Dan
Great new features! Looking forward to playing around with the visualization additions! Keep up the great work!
Guys you killed it with this update! The visualizations are amazing and oh so helpful! I use other tools that do this — 2 actually, but you blow them both away. When I do audits, this is one tool I rely on so thank you for making it amazing. The whole update is awesome. Keep up the great work!
Thanks, Jill.
Other tools had already done visualisations. So when we took this on, we had to raise the bar, or there wasn’t really much point! Glad you like them :-)
Website Auditor has done it right, but you blew it away … love the crawl tree graph. Thank you for easily seen non-indexable pages and improved redirect/canonical chain.
Yes. I also tried Website Auditor. I think this update looks much better.
This is an amazing update. Love the XML sitemaps showing non indexable content in addition to the redirect/canonical chain report!
Congratulations on the new release, it’s full of new goodies to try out. The link score is great for prioritizing to-do’s and sorting in Excel.
I’m also keen to try out the command line feature. Is it possible to run it globally via bash for Windows? Or can I only use the command prompt version on Windows?
Cheers, Martijn.
On the query – We’ll say no for now, as there’s a couple of issues there. But potentially in the future :-)
Really nice to see you guys keeping up with the competition and constantly adding more and better features. I really love the visualizations and a much needed update if you ask me. Really looking forward to getting under the hood of this again and having a tinker.
As always, another amazing update to an already amazing tool. I’m sure with some of these changes this will bring back a few SEO’s who had moved on.
Hope the next update brings some new page speed analysis features!
This is amazing work. If there’s a tool SEOs can’t live without – this is it.
Dan, thanks for integrating customer feedback so seriously. I <3 these updates like you wouldn't believe.
Pairing the 1) Scheduling + 10) Improved Redirect & Canonical Chain Reports will save me hours for migrations.
3) Indexability + Indexability Status: So much easier than the formulas I was using!
7) Visualisations: Glad you improved on these! I've always found Tree Graphs were more useful than the Force-Directed Graphs too. I <3 Tree Graphs because I can usually pivot them with "metrics that matter" like URL count (source, destination), GA, GSC, and backlinks. I'd love to see when those are automatically integrated.
P.S. Disabling HSTS Policy is small, but greatly appreciated!
Thanks, Thanh!
My personal fav feature is the improved redirect chains report as well. We may integrate GA/GSC data into fixed columns (like sessions and clicks), to help prioritise which redirects to fix first, too.
Awesome to hear this helps make your work life a bit more efficient anyway.
Keep up the good work guys! I can honestly say Screaming Frog is the best technical SEO tool around and it just keeps on getting better.
This update has cemented Screaming Frog as my #1 SEO tool! I don’t know how people can do any SEO without this tool, thanks so much for adding all the new features, especially the indexability check and the internal link score.
As always from you guys: Amazing work! The visual reporting options… Damn… This version is a MAJOR step. Thanks guys!
Thanks, mate – appreciated.
Major change this is Great Thanks
Wow – this is an amazing release. Saw a screenshot of the crawl map on Twitter and thought you were just playing catchup, but you’re blowing others out of the water!
Hi Joseph,
Thank you! I can see on face value why it might appear that way initially. But as you say, the idea was to take them to the next level – scalable, with true data integrity and new ideas to visualise architecture (like the ‘directory tree’ view, which hasn’t been seen anywhere else before). Really awesome to hear you like anyway.
Cheers.
Dan
That indexability status simply brilliant.
Screaming Frog was still one of my top tool for SEO … but now for big website with Full Command Line Interface and for sure “Headless Mode”, it’s a reral gift and THE best one! Thansk for several updates, you’ve reach also some part of dataviz, and this is really awesome ;-)
If you are looking for me, I will be at my desk playing with Comand Line & Screaming Frog =)
This is great. It was already one of my favorite tools and now with these new features is unbeatable. Good job guys, really impressive
Wow, this is such an impressive release. I love the post-crawl analysis, the link score, the new sitemap tab, the visualisation features…all of it! Amazing! Great work.
Thanks again for this fantastic tool & these updates. I’ve just [very briefly] introduced some intern/students to both screaming frog & the concepts behind anchor text+ internal linking.
Having the new visualisations along with your other ‘minor tweaks’ will make it that much easier for them to understand & then audit their work more effectivly. Brilliant!
Very good the new diagrams.
Thanks!!!
Great update! Compliments.
It would be interesting the possibility to send the .xlsx export (Internal) directly via email when a scheduled crawl is finished.
I was just thinking about how to do command line access and and getting ready to send in a feature request, and you’ve not only added everything I wanted, but done it better than I had hoped. We often have situations where we have a client with a network of many sites (the most recent one was 85) and we might want to spider them all individually and then run some processing codes on the reports that result. The ability to script that end-to-end is game changing. Thank you so much!
Wow that an impressive update. I waited a long time for the cli function, finally I can completely integrate the frog into my systems and start with a script.
A couple of items
1. When playing with the visualization settings and panning/moving/zooming I’ve “lost” the visualization with no choice than to close it open it again. Having a way to recenter the display on the visualization would be helpful.
2. I really like the new indexability dimension, is there any report for it, or is the internal_report the only place to get that info currently?
3. Will visualizations be added to the scheduling exports?
4. The new scheduling feature and mass exports is awesome, but is there a way to quickly export all reports for the current crawl?
Thanks for releasing an update that makes my work faster and more productive.
Hey Christopher,
Appreciate the feedback. Just to reply to your thoughts individually –
1) Agreed.
2) It’s only available in the ‘internal’ tab (and other tabs) at the moment. But we could quickly add this as a bulk export or report. We did also consider including something in the right hand overview window for indexable and non-indexable URLs. Will give this more thought.
3) Just to confirm, you’d like to see the SVG file exported of the various visualisations? I guess the difficulty for them sometimes is that they require a little configuration (but not always).
4) There isn’t an ‘export all’ type option, but we do plan on adding this feature, it’s been on the ‘todo’ for a while.
Cheers for your thoughts.
Dan
You deliver more than expected to all of us.
It will be hard to find something to request now
I’m happy to give you some money for your work…
Merci
Amazing update! Love this tool even more. The data vislualizations are F****** amazing! Keep up the great work team Screaming Frog
Awesome, the visualisations are exactly what I need right now.
Needed to step through an audit with a couple of non technical stakeholders, and this will help tremendously.
I’d love to see one feature in the future, which is to upload the visualizations to the cloud, so that I could explore them from my local computer.
The thing is, my SF is running on a VPS machine, which is great for crawling, but not so great when I try work with the visualizations on the remote desktop – the refresh rate is pretty low, and the overall experience is quite difficult.
I’d love to be able to send the map to the cloud and get an URL that I could open in my local browser to investigate using the full power of my local computer.
Overall though, a great update.
You are really fantastic! Every time you can improve an already excellent tool. The latest updates left me speechless, especially those related to Visualizations. It will be much easier to show and explain the site structure to customers. :-)
wow, great update! :) thanks
Wow the data vislualizations are amazing! That an impressive update
very good update
thanks
Love the data visualisation features!
Absolutely smashed it out the park with this update. Look forward to testing the scheduling options, headless mode and how these can be put into a dashboard for comparisons.
Stellar work.
Great updates and tremendous post. Screaming Frog remains one of the best tools out there. I’ve used it for years and will continue to do so. The Post Crawl Analysis is a nice touch. Well done. Keep up the great work folks!
There has to be an element of selflessness to build this version, of the ilk who created the ancient Roman & Florentine marble sculptures that are tediously flawless even where no one will ever look. Thank you Dan & crew.
Woow! Seems like you integrated Gephi for visualisation – now I don’t have to do that manually anymore. :)
Thank you very much, it’s an impressive feature list of the new release and I guess it will be helpful to many of us our here.
Keep up the good work!
Those visualisations look sweet as, can’t wait to dive in!
Wow. So much value in all of those additions. Thank you, Screaming Frog team! Going to get stuck in testing the “internal link score” metric.
What an awesome update. You guys are always quick to respond to any issues that I have. I skimmed through the features, but the visualization features stood out to me, so I tried them. I really want to really know Screaming Frog. Can you point me in the right direction on how to do this? I’ve started reading your documentation, but I just wanted to know if you would recommend any other methods to learn your software. Thanks for providing such a great piece of SEO software.
Hey Tom,
Thank you! I recommend having a read of our user guide, which should cover most things fairly well – https://www.screamingfrog.co.uk/seo-spider/user-guide/
We have lots of ‘how to guides’ there as well, like https://www.screamingfrog.co.uk/how-to-audit-validate-amp/, https://www.screamingfrog.co.uk/how-to-audit-xml-sitemaps/, https://www.screamingfrog.co.uk/how-to-audit-hreflang/ etc, which can walk you through common items, too.
Plus, if you haven’t seen it, the SEER guide is very cool – https://www.seerinteractive.com/blog/screaming-frog-guide/
Cheers
Dan
I love these diagrams. It just make things more clearly.
Cheers guys! keep up the. good work.
Fantastic update! i really love the data visualisation features! Thumbs up
Diagrams are impressive, thanks for the great update! :)
Thanks for the update… :)
I can’t understand “non indexable” issue because I’m crawling a site in which every URL has a self-referential canonical, 200OK and it’s not blocked by robots but still appears as a Non-Indexable. What am I missing?
Hi Fani,
What does it say as the reason (in the indexability status column next to it)?
Thanks,
Dan
Great update, i will definitely test all changes :)
Another great update, very impressive! I really love the diagrams. Screaming Frog Team, thank you for the incredible update!
This is some of the stuff that I honestly have been missing, and some of the stuff that I exclusively used website auditor for, now there’s even more stuff to do with the grand ol’ spider. Keep up the good work guys and gals.
With great crawling power comes great responsibilities.
Crawl Visualisations looks really great. This extensive feature will certainly help many people. Me too ;)
Great update ! I will try the Data vizualization soon, thanks !
Love how you relentlessly keep fixing pesky bugs on a regular basis even for seemingly small things such as typos
Any update about Structured data tag in this Version. Like Google job Search, Events
We have this on the list :-)
It’s coming.
Do you plan to opensource a community version of Screaming Frog?
We have no plans to OpenSource the SEO Spider.
Cheers.
Dan
Nice update, guys! We love data visualization
I have been using Screaming From from 5 years and still love this tool. They provide free information where other tools are more interested in your money. Thank you Screaming Frog.
Nice work on the tree diagram. Just tested that today !
I was used to use visualized data like these for my clients with other software. Now I have everything needed here.
Great article. I loved the visuals.
Great new features! Looking forward to playing around with the visualization additions! Keep up the great work!