Screaming Frog SEO Spider Update – Version 13.0
Dan Sharp
Posted 1 July, 2020 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 13.0
We are excited to announce the release of Screaming Frog SEO Spider version 13.0, codenamed internally as ‘Lockdown’.
We’ve been busy developing exciting new features, and despite the obvious change in priorities for everyone right now, we want to continue to release updates as normal that help users in the work they do.
Let’s take a look at what’s new.
1) Near Duplicate Content
You can now discover near-duplicate pages, not just exact duplicates. We’ve introduced a new ‘Content‘ tab, which includes filters for both ‘Near Duplicates’ and ‘Exact Duplicates’.

While there isn’t a duplicate content penalty, having similar pages can cause cannibalisation issues and crawling and indexing inefficiencies. Very similar pages should be minimised and high similarity could be a sign of low-quality pages, which haven’t received much love – or just shouldn’t be separate pages in the first place.
For ‘Near Duplicates’, the SEO Spider will show you the closest similarity match %, as well as the number of near-duplicates for each URL. The ‘Exact Duplicates’ filter uses the same algorithmic check for identifying identical pages that was previously named ‘Duplicate’ under the ‘URL’ tab.
The new ‘Near Duplicates’ detection uses a minhash algorithm, which allows you to configure a near-duplicate similarity threshold, which is set at 90% by default. This can be configured via ‘Config > Content > Duplicates’.

Semantic elements such as the nav and footer are automatically excluded from the content analysis, but you can refine it further by excluding or including HTML elements, classes and IDs. This can help focus the analysis on the main content area, avoiding known boilerplate text. It can also be used to provide a more accurate word count.

Near duplicates requires post crawl analysis to be populated, and more detail on the duplicates can be seen in the new ‘Duplicate Details’ lower tab. This displays every near-duplicate URL identified, and their similarity match.
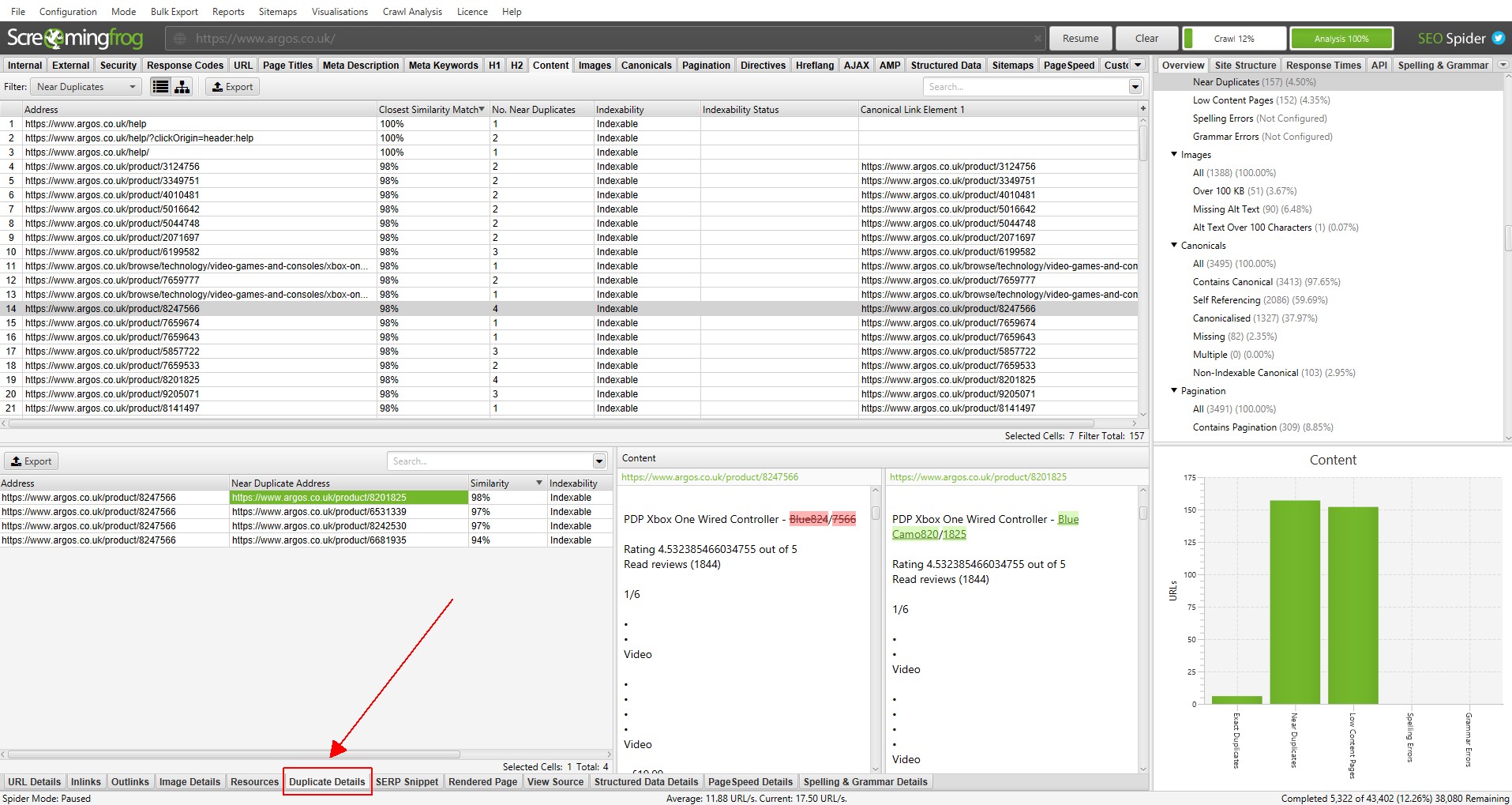
Clicking on a ‘Near Duplicate Address’ in the ‘Duplicate Details’ tab will display the near duplicate content discovered between the pages, and perform a diff to highlight the differences.
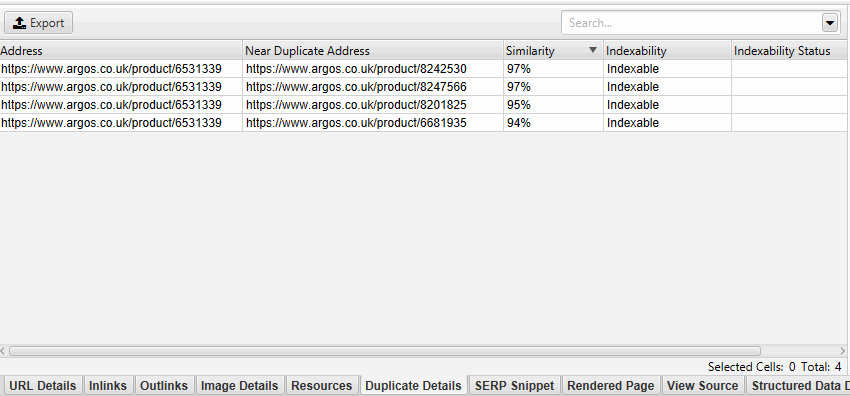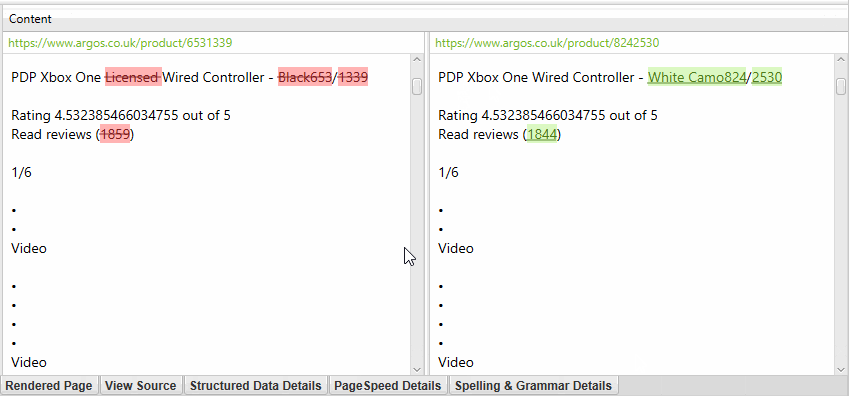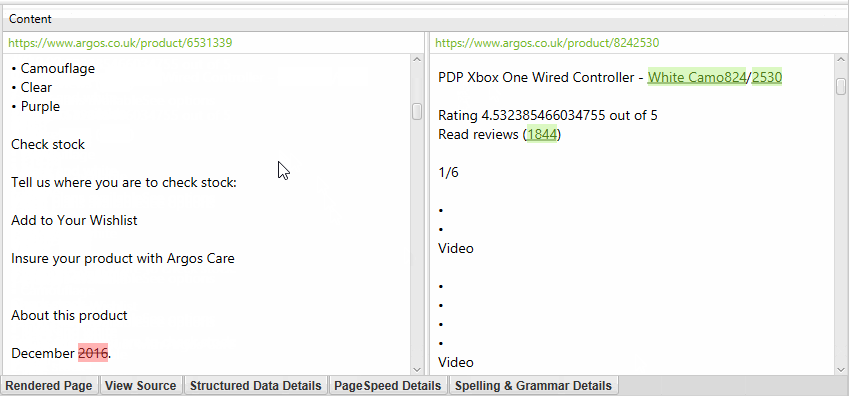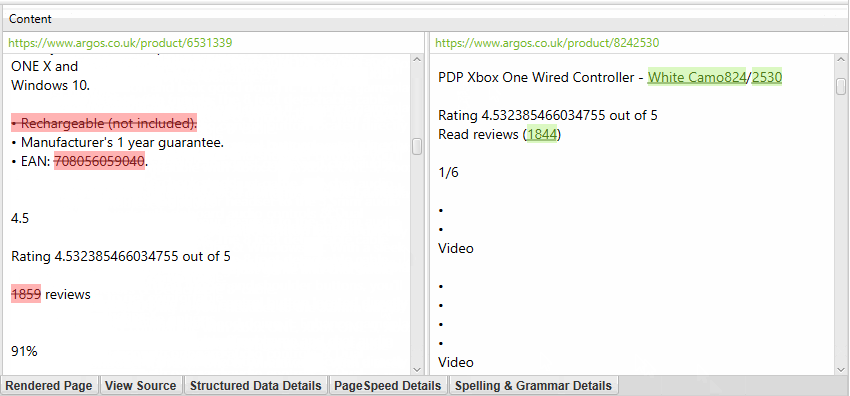
The near-duplicate content threshold and content area used in the analysis can both be updated post-crawl, and crawl analysis can be re-run to refine the results, without the need for re-crawling.
The ‘Content’ tab also includes a ‘Low Content Pages’ filter, which identifies pages with less than 200 words using the improved word count. This can be adjusted to your preferences under ‘Config > Spider > Preferences’ as there obviously isn’t a one-size-fits-all measure for minimum word count in SEO.
Read our ‘How To Check For Duplicate Content‘ tutorial for more.
2) Spelling & Grammar
If you’ve found yourself with extra time under lockdown, then we know just the way you can spend it (sorry).
You’re now also able to perform a spelling and grammar check during a crawl. The new ‘Content’ tab has filters for ‘Spelling Errors’ and ‘Grammar Errors’ and displays counts for each page crawled.
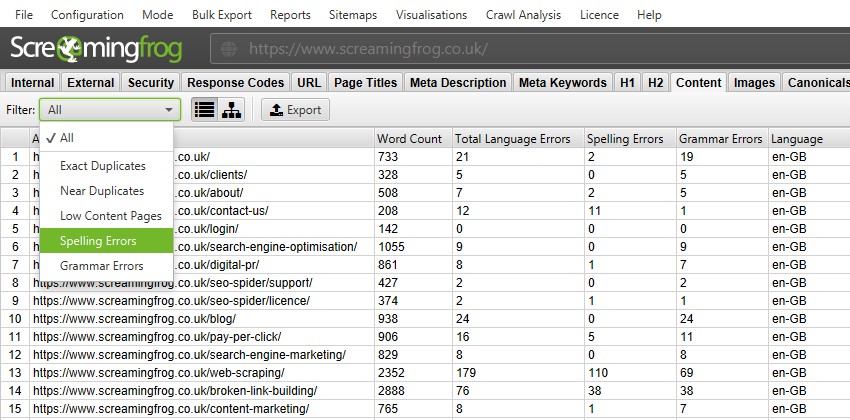
You can enable spelling and grammar checks via ‘Config > Content > Spelling & Grammar‘.
While this is a little different from our usual very ‘SEO-focused’ features, a large part of our roles are about improving websites for users. Google’s own search quality evaluator guidelines outline spelling and grammar errors numerous times as one of the characteristics of low-quality pages (if you need convincing!).
The lower window ‘Spelling & Grammar Details’ tab shows you the error, type (spelling or grammar), detail, and provides a suggestion to correct the issue.
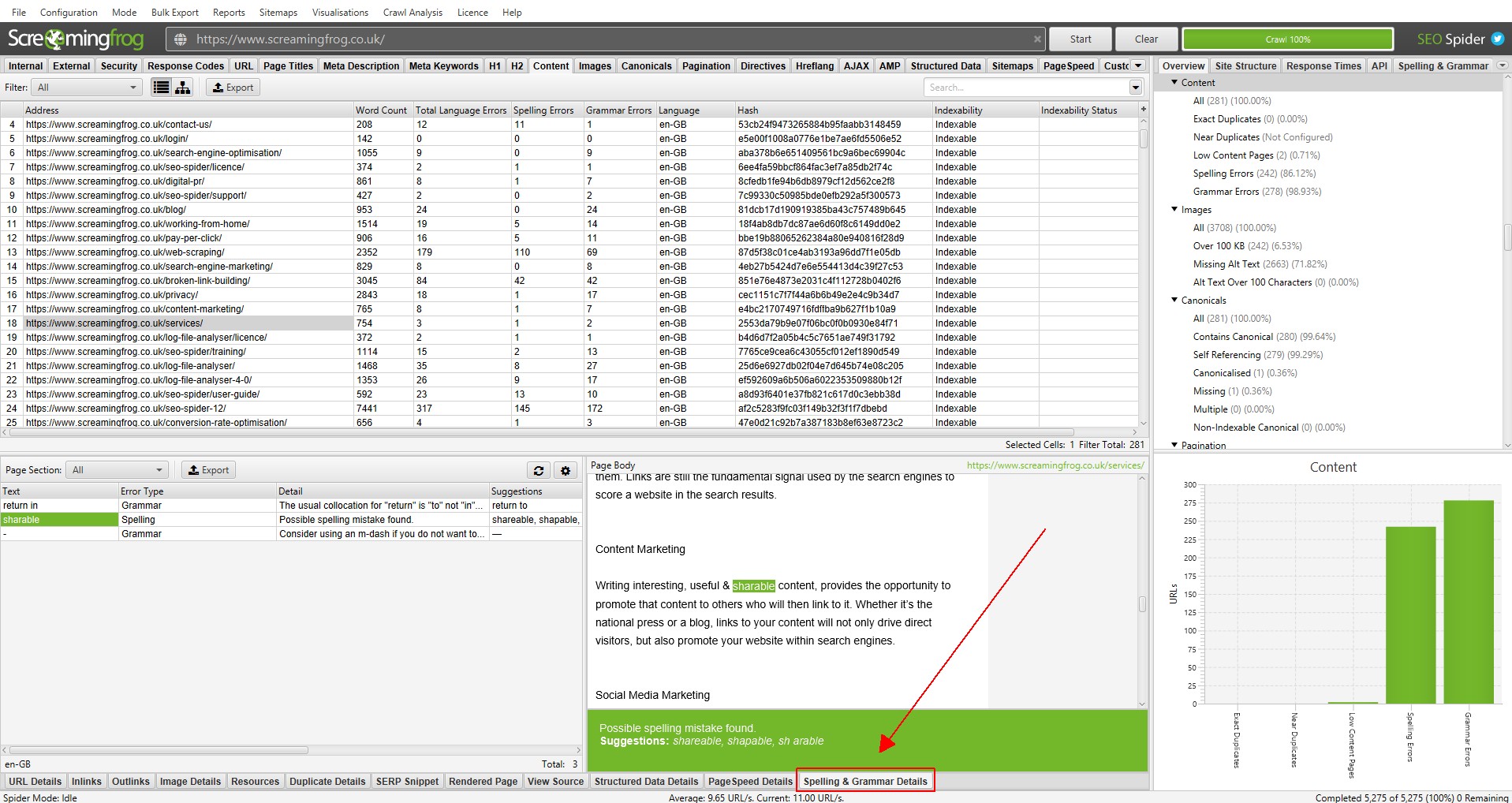
The right-hand-side of the details tab also shows you a visual of the text from the page and errors identified.
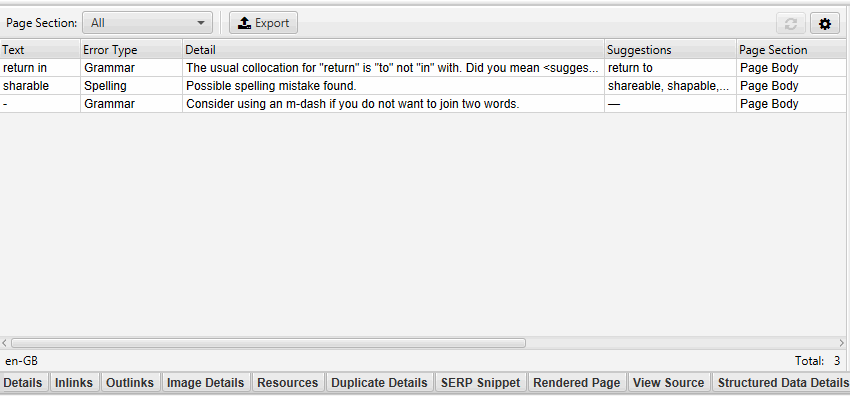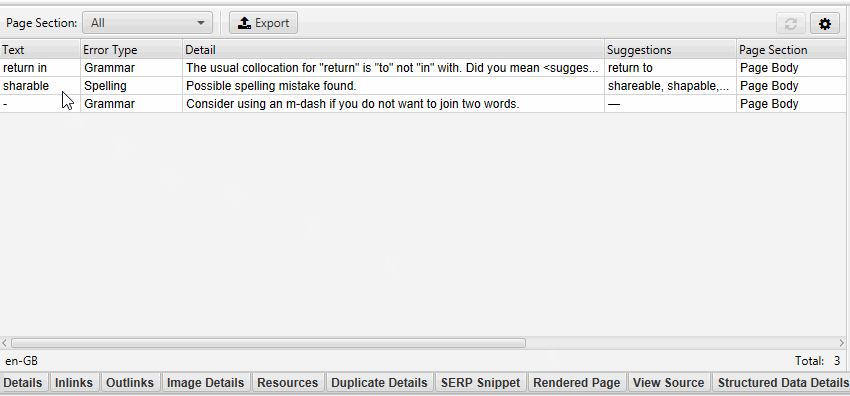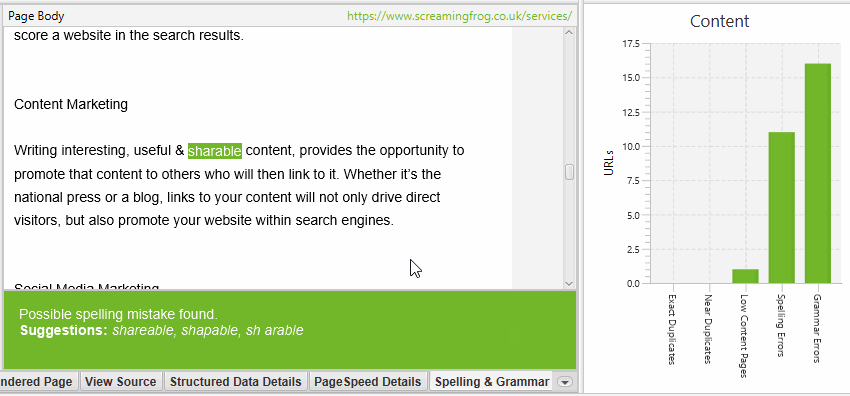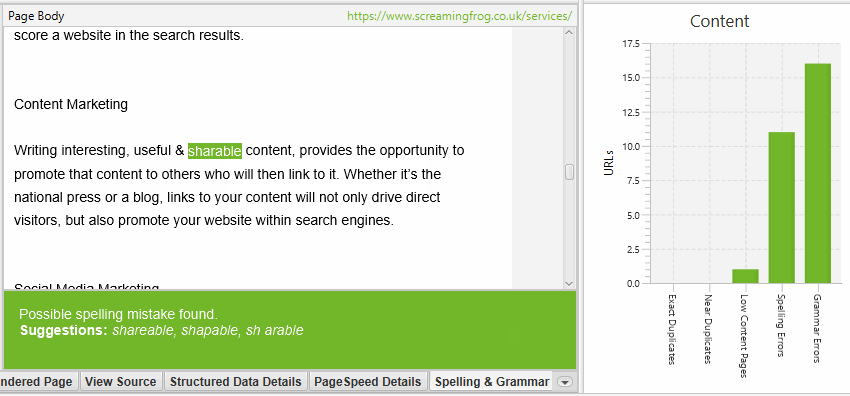
The right-hand pane ‘Spelling & Grammar’ tab displays the top 100 unique errors discovered and the number of URLs it affects. This can be helpful for finding errors across templates, and for building your dictionary or ignore list.
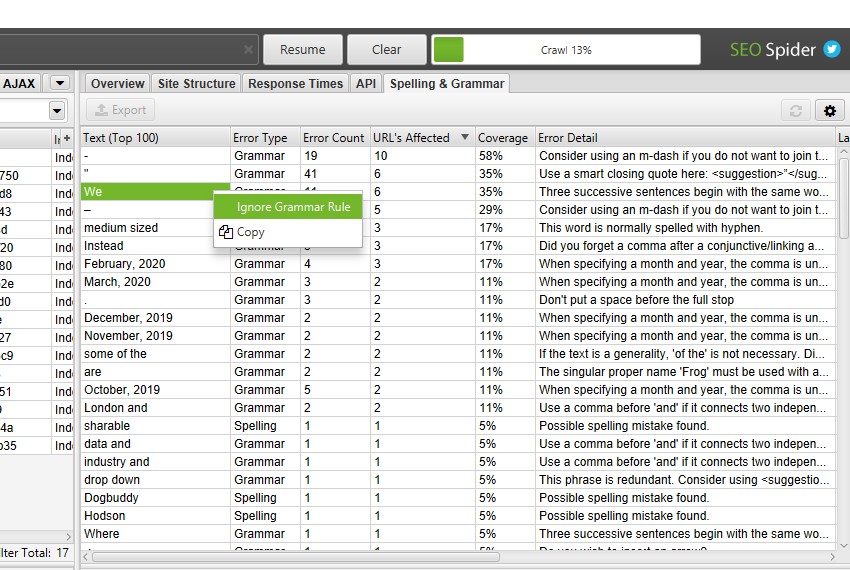
The new spelling and grammar feature will auto-identify the language used on a page (via the HTML language attribute), but also allow you to manually select language where required. It supports 39 languages, including English (UK, USA, Aus etc), German, French, Dutch, Spanish, Italian, Danish, Swedish, Japanese, Russian, Arabic and more.
You’re able to ignore words for a crawl, add to a dictionary (which is remembered across crawls), disable grammar rules and exclude or include content in specific HTML elements, classes or IDs for spelling and grammar checks.
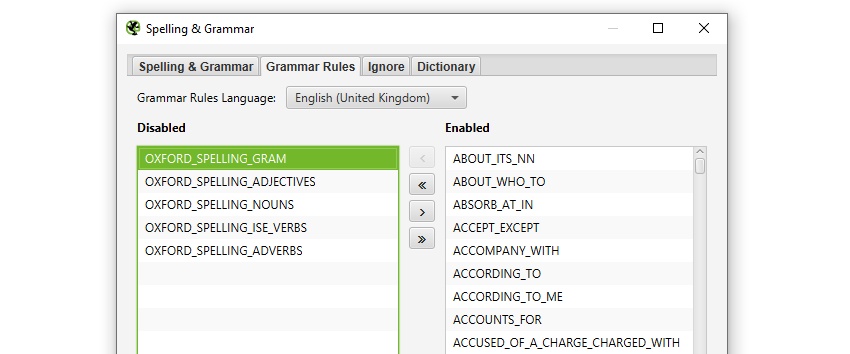
You’re also able to ‘update’ the spelling and grammar check to reflect changes to your dictionary, ignore list or grammar rules without re-crawling the URLs.
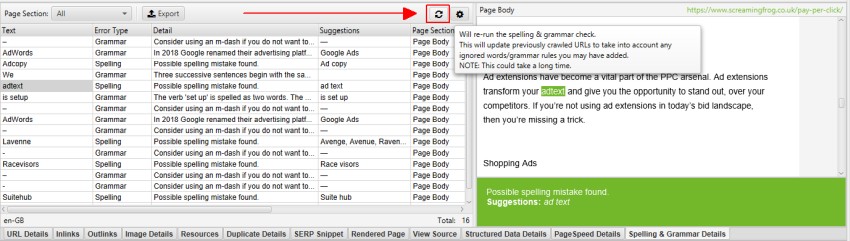
As you would expect, you can export all the data via the ‘Bulk Export > Content’ menu.
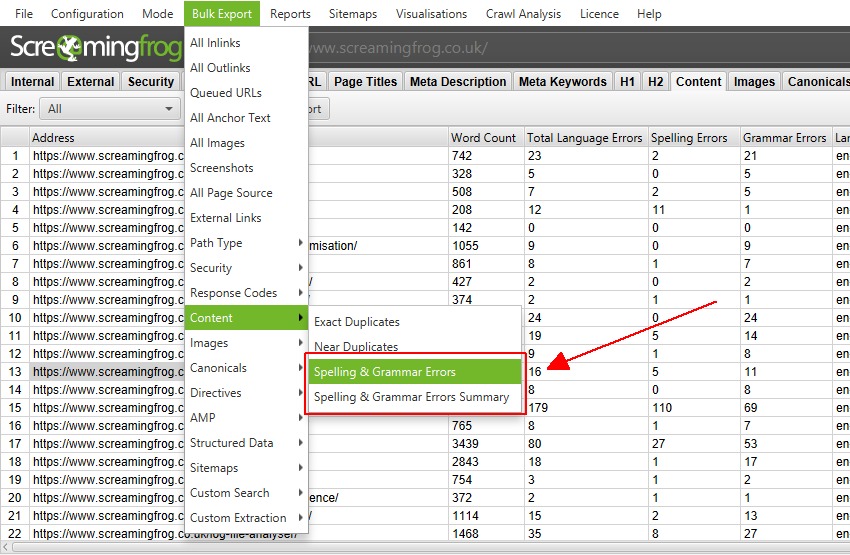
Please don’t send us any ‘broken spelling/grammar’ link building emails. Check out our ‘Spell & Grammar Check Your Website‘ tutorial.
3) Improved Link Data – Link Position, Path Type & Target
Some of our most requested features have been around link data. You want more, to be able to make better decisions. We’ve listened, and the SEO Spider now records some new attributes for every link.
Link Position
You’re now able to see the ‘link position’ of every link in a crawl – such as whether it’s in the navigation, content of the page, sidebar or footer for example. The classification is performed by using each link’s ‘link path’ (as an XPath) and known semantic substrings, which can be seen in the ‘inlinks’ and ‘outlinks’ tabs.
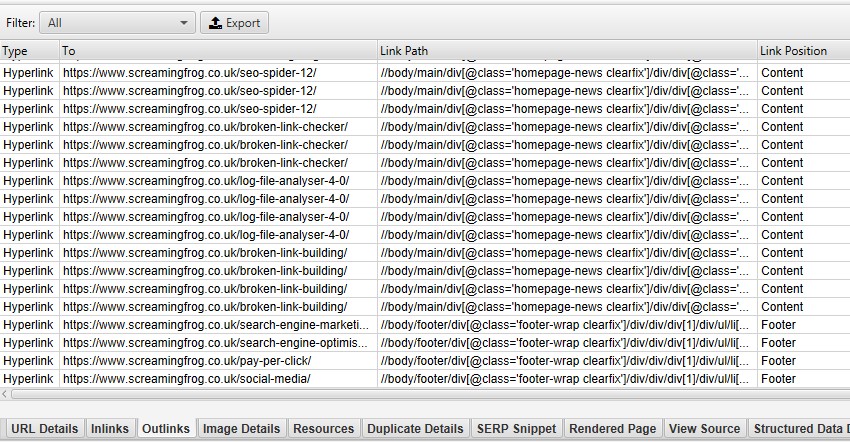
If your website uses semantic HTML5 elements (or well-named non-semantic elements, such as div id=”nav”), the SEO Spider will be able to automatically determine different parts of a web page and the links within them.
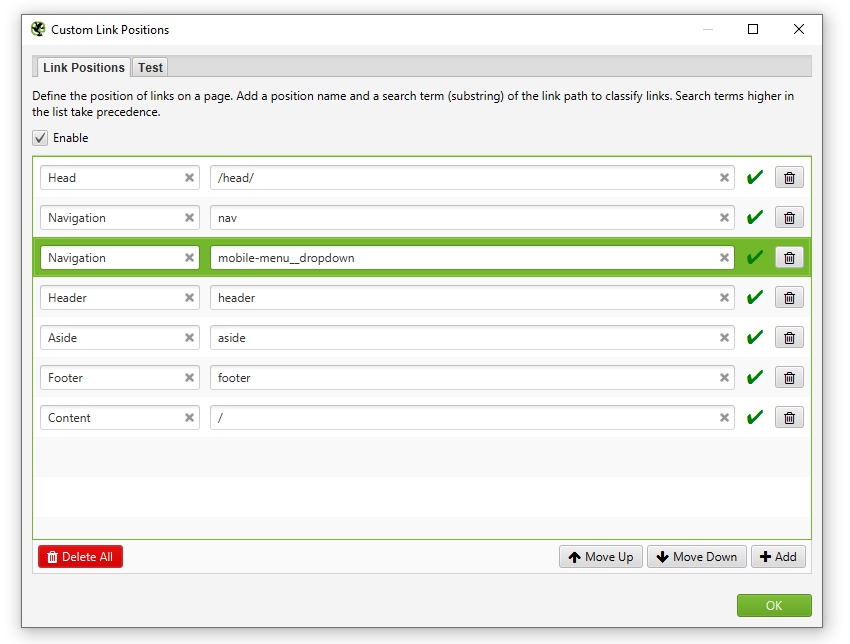
But not every website is built in this way, so you’re able to configure the link position classification under ‘Config > Custom > Link Positions‘. This allows you to use a substring of the link path, to classify it as you wish.
For example, we have mobile menu links outside the nav element that are determined to be in ‘content’ links. This is incorrect, as they are just an additional sitewide navigation on mobile.
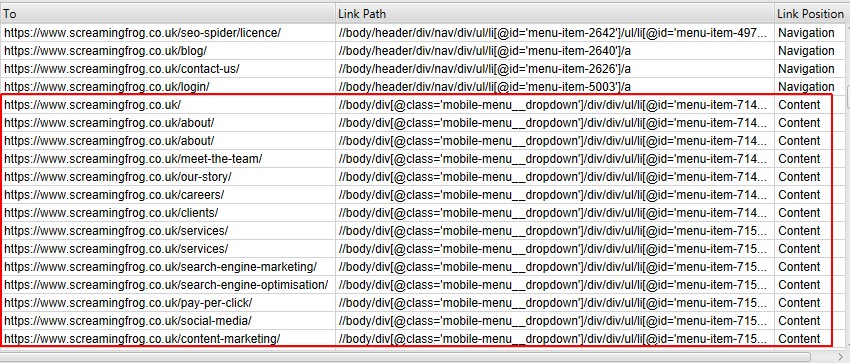
The ‘mobile-menu__dropdown’ class name (which is in the link path as shown above) can be used to define its correct link position using the Link Positions feature.
These links will then be correctly attributed as a sitewide navigation link.
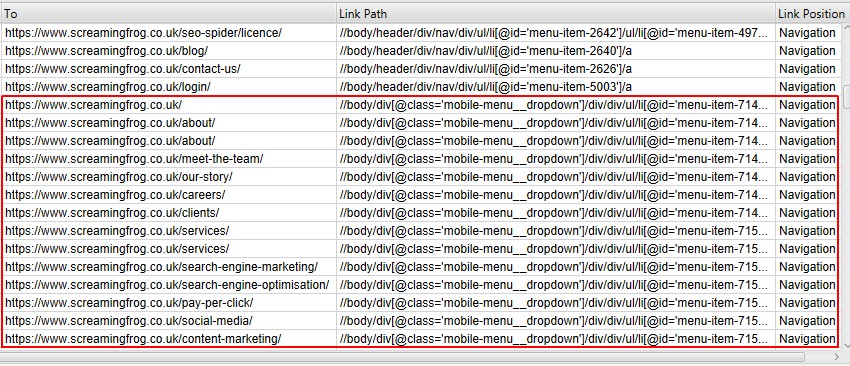
This can help identify ‘inlinks’ to a page that are only from in-body content, for example, ignoring any links in the main navigation, or footer for better internal link analysis.
Path Type
The ‘path type’ of a link is also recorded (absolute, path-relative, protocol-relative or root-relative), which can be seen in inlinks, outlinks and all bulk exports.
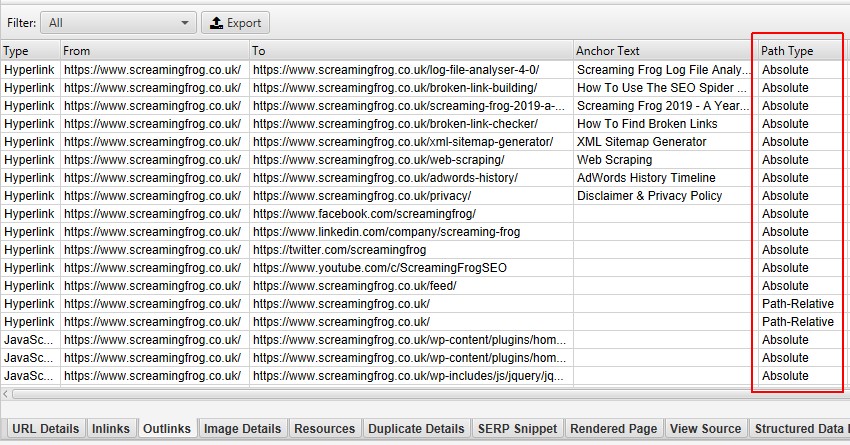
This can help identify links which should be absolute, as there are some integrity, security and performance issues with relative linking under some circumstances.
Target Attribute
Additionally, we now show the ‘target’ attribute for every link, to help identify links which use ‘_blank’ to open in a new tab.
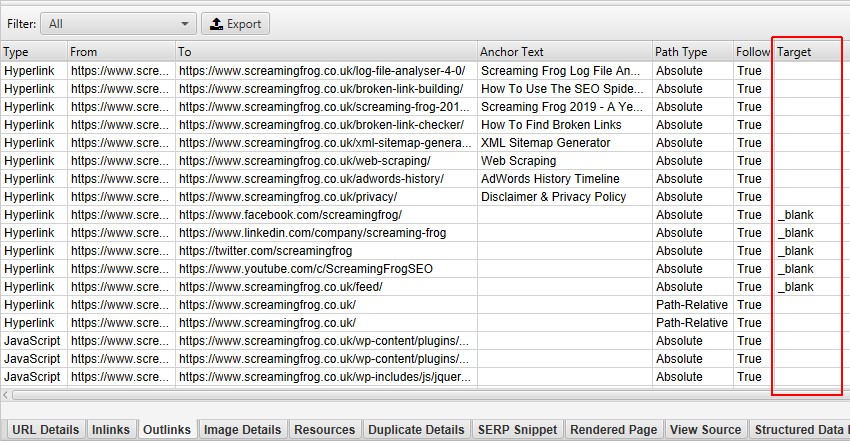
This is helpful when analysing usability, but also performance and security – which brings us onto the next feature.
4) Security Checks
The ‘Protocol’ tab has been renamed to ‘Security‘ and more up to date security-related checks and filters have been introduced.
While the SEO Spider was already able to identify HTTP URLs, mixed content and other insecure elements, exposing them within filters helps you spot them more easily.
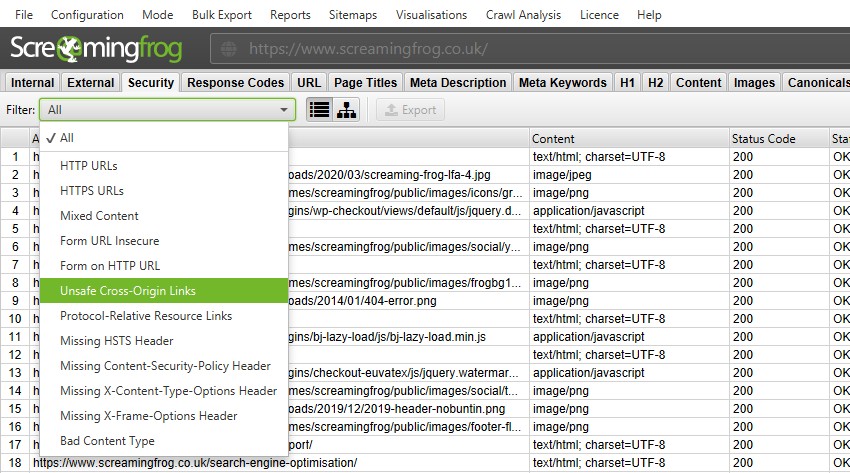
You’re able to quickly find mixed content, issues with insecure forms, unsafe cross-origin links, protocol-relative resource links, missing security headers and more.
The old insecure content report remains as well, as this checks all elements (canonicals, hreflang etc) for insecure elements and is helpful for HTTPS migrations.
The new security checks introduced are focused on the most common issues related to SEO, web performance and security, but this functionality might be extended to cover additional security checks based upon user feedback.
5) Improved UX Bits
We’ve found some new users could get confused between the ‘Enter URL to spider’ bar at the top, and the ‘search’ bar on the side. The size of the ‘search’ bar had grown, and the main URL bar was possibly a little too subtle.

So we have adjusted sizing, colour, text and included an icon to make it clearer where to put your URL.

If that doesn’t work, then we’ve got another concept ready and waiting for trial.
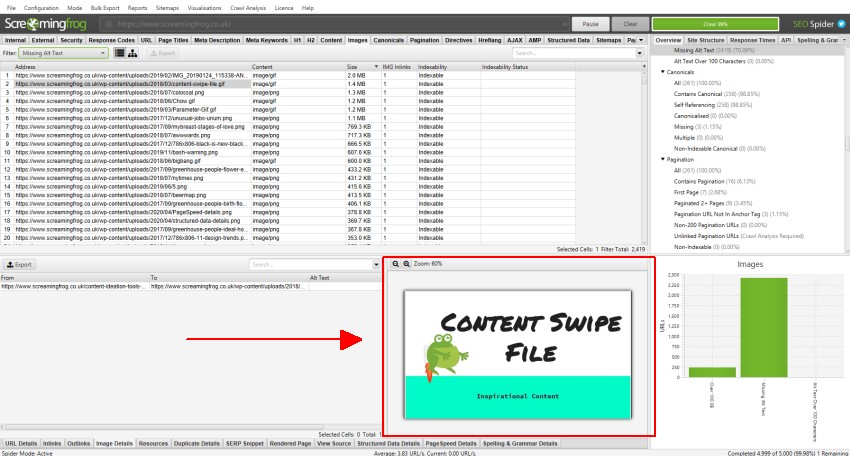
The ‘Image Details’ tab now displays a preview of the image, alongside its associated alt text. This makes image auditing much easier!
You can highlight cells in the higher and lower windows, and the SEO Spider will display a ‘Selected Cells’ count.
The lower windows now have filters and a search, to help find URLs and data more efficiently.
Site visualisations now have an improved zoom, and the tree graph nodes spacing can be much closer together to view a site in its entirety. So pretty.
Oh, and in the ‘View Source’ tab, you can now click ‘Show Differences’ and it will perform a diff between the raw and rendered HTML.
Other Updates
Version 13.0 also includes a number of smaller updates and bug fixes, outlined below.
- The PageSpeed Insights API integration has been updated with the new Core Web Vitals metrics (Largest Contentful Paint, First Input Delay and Cumulative Layout Shift). ‘Total Blocking Time’ Lighthouse metric and ‘Remove Unused JavaScript’ opportunity are also now available. Additionally, we’ve introduced a new ‘JavaScript Coverage Summary’ report under ‘Reports > PageSpeed’, which highlights how much of each JavaScript file is unused across a crawl and the potential savings.
- Following the Log File Analyser version 4.0, the SEO Spider has been updated to Java 11. This means it can only be used on 64-bit machines.
- iFrames can now be stored and crawled (under ‘Config > Spider > Crawl’).
- Fragments are no longer crawled by default in JavaScript rendering mode. There’s a new ‘Crawl Fragment Identifiers’ configuration under ‘Config > Spider > Advanced’ that allows you to crawl URLs with fragments in any rendering mode.
- A tonne of Google features for structured data validation have been updated. We’ve added support for COVID-19 Announcements and Image Licence features. Occupation has been renamed to Estimated Salary and two deprecated features, Place Action and Social Profile, have been removed.
- All Hreflang ‘confirmation links’ named filters have been updated to ‘return links’, as this seems to be the common naming used by Google (and who are we to argue?). Check out our How To Audit Hreflang guide for more detail.
- Two ‘AMP’ filters have been updated, ‘Non-Confirming Canonical’ has been renamed to ‘Missing Non-AMP Return Link’, and ‘Missing Non-AMP Canonical’ has been renamed to ‘Missing Canonical to Non-AMP’ to make them as clear as possible. Check out our How To Audit & validate AMP guide for more detail.
- The ‘Memory’ configuration has been renamed to ‘Memory Allocation’, while ‘Storage’ has been renamed to ‘Storage Mode’ to avoid them getting mixed up. These are both available under ‘Config > System’.
- Custom Search results now get appended to the Internal tab when used.
- The Forms Based Authentication browser now shows you the URL you’re viewing to make it easier to spot sneaky redirects.
- Deprecated APIs have been removed for the Ahrefs integration.
That’s everything. If you experience any problems, then please do just let us know via our support and we’ll help as quickly as possible.
Thank you to everyone for all their feature requests, feedback, and bug reports. Apologies for anyone disappointed we didn’t get to the feature they wanted this time. We prioritise based upon user feedback (and a little internal steer) and we hope to get to them all eventually.
Now, go and download version 13.0 of the Screaming Frog SEO Spider and let us know what you think!
Small Update – Version 13.1 Released 15th July 2020
We have just released a small update to version 13.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- We’ve introduced two new reports for Google Rich Result features discovered in a crawl under ‘Reports > Structured Data’. There’s a summary of features and number of URLs they affect, and a granular export of every rich result feature detected.
- Fix issue preventing start-up running on macOS Big Sur Beta
- Fix issue with users unable to open .dmg on macOS Sierra (10.12).
- Fix issue with Windows users not being able to run when they have Java 8 installed.
- Fix TLS handshake issue connecting to some GoDaddy websites using Windows.
- Fix crash in PSI.
- Fix crash exporting the Overview Report.
- Fix scaling issues on Windows using multiple monitors, different scaling factors etc.
- Fix encoding issues around URLs with Arabic text.
- Fix issue when amending the ‘Content Area’.
- Fix several crashes running Spelling & Grammar.
- Fix several issues around custom extraction and XPaths.
- Fix sitemap export display issue using Turkish locale.
Small Update – Version 13.2 Released 4th August 2020
We have just released a small update to version 13.2 of the SEO Spider. This release is mainly bug fixes and small improvements –
- We first released custom search back in 2011 and it was in need of an upgrade. So we’ve updated functionality to allow you to search within specific elements, entire tracking tags and more. Check out our custom search tutorial.
- Sped up near duplicate crawl analysis.
- Google Rich Results Features Summary export has been ordered by number of URLs.
- Fix bug with Near Duplicates Filter not being populated when importing a .seospider crawl.
- Fix several crashes in the UI.
- Fix PSI CrUX data incorrectly labelled as sec.
- Fix spell checker incorrectly checking some script content.
- Fix crash showing near duplicates details panel.
- Fix issue preventing users with dual stack networks to crawl on windows.
- Fix crash using Wacom tablet on Windows 10.
- Fix spellchecker filters missing when reloading a crawl.
- Fix crash on macOS around multiple screens.
- Fix crash viewing gif in the image details tab.
- Fix crash canceling during database crawl load.






Wow
That’s a fantastic update
The link position will be extremely useful for internal pagerank analysis through the cautious surfer model
The near duplicate content analysis will be a great help
and all the other evolutions are also very helpful
Definitely the n°1 SEO Tool as far as on-site structural optimization is concerned
Thanks, Nicolas – Awesome to hear!
Awesome work! Very Useful
The “content” tab is going to be helpful for large website. SF version 13.0 IS AWSOME
Nice.
My favorite number 13. New features are nice.
Thank you.
Cmon there are more Polish users than danish and you didnt include PL language… cmon guys…
Yeah, we did. Polish language is supported in Spelling & Grammar :-)
‘Config > Content > Spelling & Grammar’ and you’ll see it in the ‘language’ list.
Awesome work. The near duplicate content tab is simply amazing. I can’t believe how good this tool is getting with each update. Quick question, duplicates were using the MD5 algorithm to compute the hash value of the page. Any info on how you compute the near duplicate score?
Cheers, Jean-Christophe!
Yeah, it’s MD5 algorithm for the hash value and exact duplicates. We’re using minhash for near duplicates, which allows us to calculate similarity.
Lots of new information. This should take me a while to learn and improve my website, thank you :)
Once again, thanks for providing us SEO specialists with such a robust, multipurpose tool like Screaming Frog. Duplication checks, spelling checks, and security checks are things we were analysing, but can now do so natively with your software. Looking forward to trying it out!
Thanks, Aron!
really looking forward to an update.
thank you that despite the pandemic, you continue to develop the product
This update is NOT less than amazing, especially the “near-duplicate content” feature. Totally love it.
Cheers, Ziv! It’s a powerful feature that one, as you can adjust settings post-crawl, then re-run crawl analysis to refine it too.
This is brilliant work. Pagespeed insights now in SF.
Love the new version. Lot more features for the affordable price.
Looking forward to see more in future. Keep it going.
Thank you for another great Version. The continuous progress of Screaming Frog makes work and identifying new possibilities, chances and potentials a blast. It’s definitely worth the money. Keep up the good work!
WOW .. just WOW
Honestly, the best SEO software around and it keeps getting better and better.
Thanks, Saijo! That’s really kind. Glad you like it!
This update is marvellous! I’m glad I got to know about the tool during the lockdown. Screaming Frog was recommended to me about a week ago on Reddit. To be honest, it makes SEO quite easier.
Bravo pour cette version 13 !
Je m’empresse de mettre à jour pour tester tout ceci.
Hi
This is all interesting, but the most important thing has not been done – where is the integration of the list of proxies, both ordinary and with authorization ???
Apologies, Andre! We do prioritise based upon feedback, and that didn’t quite make the cut. It’s on the ‘todo’ list, though.
One again, you’ve made my day! This update is very cool. The new duplicate and spelling/grammar options are very usefull to have, target info on links is also a time saver. Didn’t test all the new stuff yet but I had to say it : MANY THANKS to all the SF team! Keep it up :p
Ah, thanks Brice!
Duplicate content is going to be an instant loved feature among SEOs. Hope it get better and more accurate
Wowww!!! That’s amazing!
Out of curiosity: the switch from Java 8 to 11 lead to some memory management improvement with big crawls? Thank you, guys!
There shouldn’t be a lot of difference really. If you’re not already using database storage mode, then I highly recommend it.
Database storage mode with 4GB of RAM allocated can tackle most sites sub 2m URLs these days.
the program crashes when I do a page group respider in a large project
Hi Gnome,
Please can you pop your log files through? Help > Debug > Save Logs, to support@screamingfrog.co.uk.
Cheers.
Dan
The CTR + V key combination often doesn’t work.
In addition, the buttons for minimizing the window, full screen and off are not good visible.
In general, it looks so strange now.
See: https://freeimage.host/i/screaming-frog.dHH6tn
Pop us an email and we can help – support@screamingfrog.co.uk
Cheers.
Dan
An option that has been long overdue, thank you for putting it in place. Otherwise we would like to use several proxies sometimes. Is it possible to set it up?
Hi, where is a button “Pause on High Memory Used “?
We removed that, as we found so many users would simply click ‘resume’ and then experience a crash :-)
So this now means you need to save, increase memory (use db storage) to continue.
Cheers.
Dan
REALLY disappointed, I bought the license to have a look at the near duplicates and the software freezes at 76% of the crawl analysis. Tried with different computers and connections, same issue… I’d appreciate if you could have a look on this issue more deeply
Hi Marine,
Sorry to hear you’re disappointed. For larger crawls, crawl analysis for near duplicates can take a bit longer.
You had waited 25mins to get to 75%, so you had under 10mins left to wait.
When you emailed us about this yesterday, we replied to say we are working to make it faster. But this isn’t something we can do in a day unfortunately, as there’s more involved to speed up minhash.
We’ll be in touch when we do, and if you pop an email reply I can see if I can run it for you. I’ve actually just sent it to you now.
Cheers.
Dan
Good job on supporting only 64-bit machines. I can’t install the new update only because my PC is a few years old and I have 32-bit Windows installed… really good job guys!
Hi Krzysiek,
You’ll find that most modern technology and frameworks are stopping support of 32-bit machines.
You can still use version 12.6, which works with 32-bit machines. Just we can’t support them for the new features we want to build.
Cheers.
Dan
please provide me with link of version 12.6, which works with 32-bit machines
Thanks for the update, Love the new Duplicate Content option and Spelling checker.
But will be nice if you guys can add an option where the user can save the layout tab arrangement. Now every time I add a new site, I have to make that change again and again.
Very time consuming :(
Hi Tanvir,
Good to hear you’re enjoying.
What do you mean by layout tab arrangement? If you remove tabs (right click, close), or move their position (drag), they are remembered – even after closing the tool.
Are you saying you’d like a different tab arrangement per crawl and it to be saved as part of the configuration?
Thanks,
Dan
such a very nice updates it will really helpful for us but I have a request kindly allow to use in 32-bit windows.
Thanks in Advance
Hi Anurodh,
Little FAQ on 32-bit Windows – https://www.screamingfrog.co.uk/seo-spider/faq/#what-operating-systems-does-the-seo-spider-run-on
Cheers.
Dan
Many thanks for the update and the documentation!
Lot of work to be done! Thank you :)
Fantastic! It would also be nice to highlight the page/code differences between text-HTML and web pages rendered with Javascript.
Nice Update! It makes my work more easier.
Thank you Screaming Frog.
Awesome update. This is going to be extremely helpful.
Long life to Screaming Frog, that tool I use every day.
Is version 12.6 the only one that runs on 32-bit computers? Is there no higher version than this?
Hi Toy Shop Employee,
Correct! We only support 64 bit OS from version 13. We supported 32-bit for as long as we could.
Thanks,
Dan