Screaming Frog SEO Spider Update – Version 14.0
Dan Sharp
Posted 23 November, 2020 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 14.0
We are pleased to launch Screaming Frog SEO Spider version 14.0, codenamed internally as ‘megalomaniac’.
Since the release of version 13 in July, we’ve been busy working on the next round of features for version 14, based upon user feedback and as always, a little internal steer.
Let’s talk about what’s new in this release.
1) Dark Mode
While arguably not the most significant feature in this release, it is used throughout the screenshots – so it makes sense to talk about first. You can now switch to dark mode, via ‘Config > User Interface > Theme > Dark’.

Not only will this help reduce eye strain for those that work in low light (everyone living in the UK right now), it also looks super cool – and is speculated (by me now) to increase your technical SEO skills significantly.
The non-eye-strained among you may notice we’ve also tweaked some other styling elements and graphs, such as those in the right-hand overview and site structure tabs.
2) Google Sheets Export
You’re now able to export directly to Google Sheets.

You can add multiple Google accounts and connect to any, quickly, to save your crawl data which will appear in Google Drive within a ‘Screaming Frog SEO Spider’ folder, and be accessible via Sheets.

Many of you will already be aware that Google Sheets isn’t really built for scale and has a 5m cell limit. This sounds like a lot, but when you have 55 columns by default in the Internal tab (which can easily triple depending on your config), it means you can only export around 90k rows (55 x 90,000 = 4,950,000 cells).
If you need to export more, use a different export format that’s built for the size (or reduce your number of columns). We had started work on writing to multiple sheets, but really, Sheets shouldn’t be used in that way.
This has also been integrated into scheduling and the command line. This means you can schedule a crawl, which automatically exports any tabs, filters, exports or reports to a Sheet within Google Drive.
You’re able to choose to create a timestamped folder in Google Drive, or overwrite an existing file.
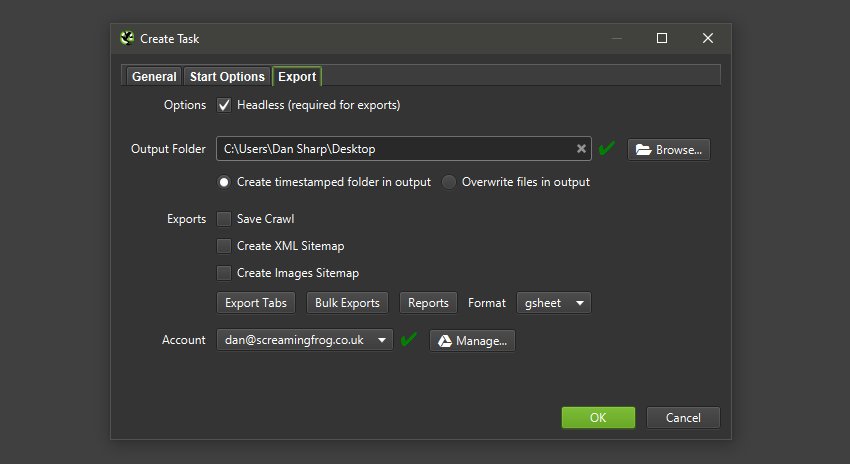
This should be helpful when sharing data in teams, with clients, or for Google Data Studio reporting.
3) HTTP Headers
You can now store, view and query full HTTP headers. This can be useful when analysing various scenarios which are not covered by the default headers extracted, such as details of caching status, set-cookie, content-language, feature policies, security headers etc.
You can choose to extract them via ‘Config > Spider > Extraction’ and selecting ‘HTTP Headers’. The request and response headers will then be shown in full in the lower window ‘HTTP Headers’ tab.
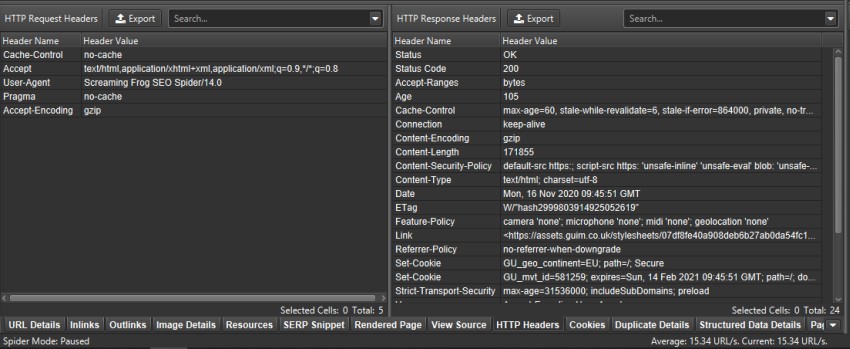
The HTTP response headers also get appended as columns in the Internal tab, so they can be viewed, queried and exported alongside all the usual crawl data.
Headers can also be exported in bulk via ‘Bulk Export > Web > All HTTP Headers’.
4) Cookies
You can now also store cookies from across a crawl. You can choose to extract them via ‘Config > Spider > Extraction’ and selecting ‘Cookies’. These will then be shown in full in the lower window Cookies tab.
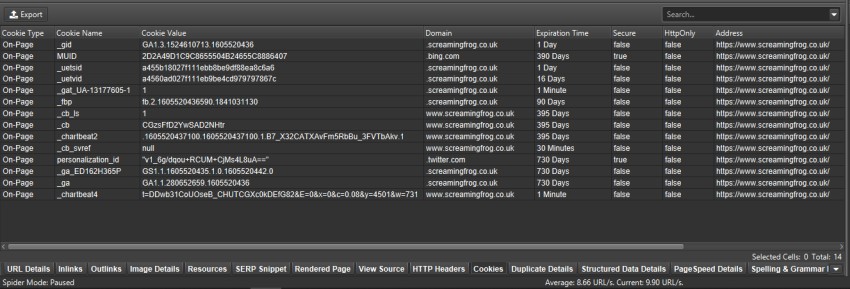
You’ll need to use JavaScript rendering mode to get an accurate view of cookies, which are loaded on the page using JavaScript or pixel image tags.
The SEO Spider will collect cookie name, value, domain (first or third party), expiry as well as attributes such as secure and HttpOnly.
This data can then be analysed in aggregate to help with cookie audits, such as those for GDPR via ‘Reports > Cookies > Cookie Summary’.
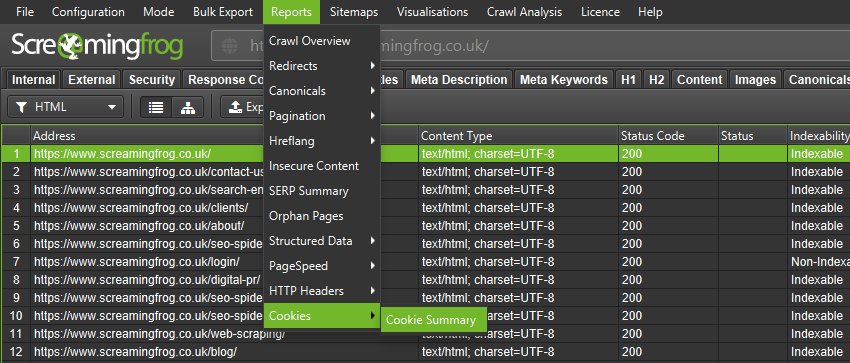
You can also highlight multiple URLs at a time to analyse in bulk, or export via the ‘Bulk Export > Web > All Cookies’.
Please note – When you choose to store cookies, the auto exclusion performed by the SEO Spider for Google Analytics tracking tags is disabled to provide an accurate view of all cookies issued.
This means it will affect your analytics reporting, unless you choose to exclude any tracking scripts from firing by using the Exclude configuration (‘Config > Exclude’) or filter out the ‘Screaming Frog SEO Spider’ user-agent similar to excluding PSI in this FAQ.
5) Aggregated Site Structure
The SEO Spider now displays the number of URLs discovered in each directory when in directory tree view (which you can access via the tree icon next to ‘Export’ in the top tabs).
This helps better understand the size and architecture of a website, and some users find it more logical to use than traditional list view.
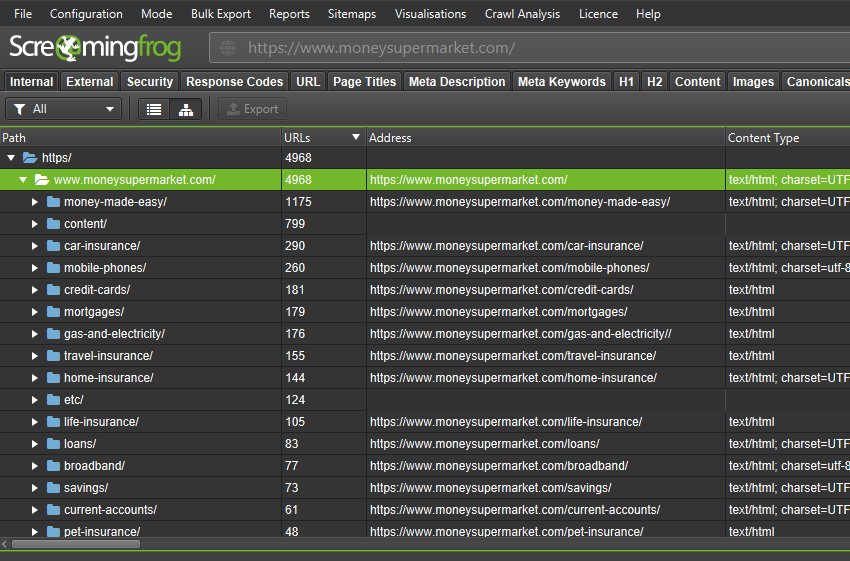
Alongside this update, we’ve improved the right-hand ‘Site Structure’ tab to show an aggregated directory tree view of the website. This helps quickly visualise the structure of a website, and identify where issues are at a glance, such as indexability of different paths.
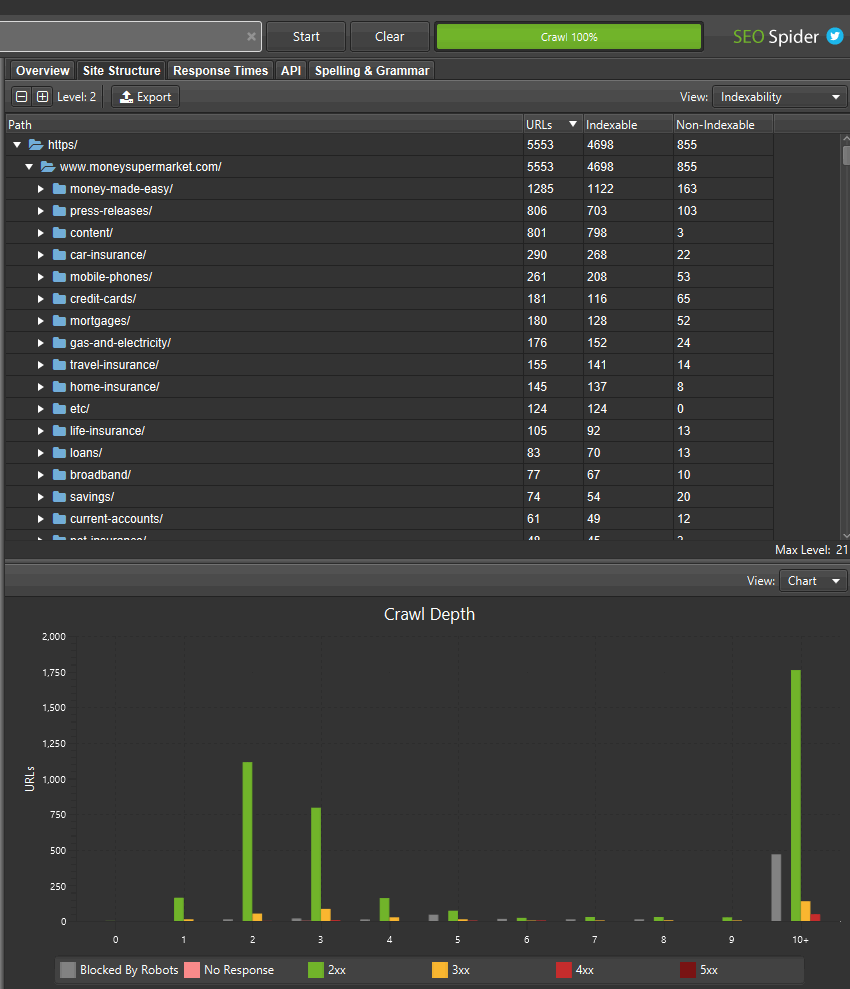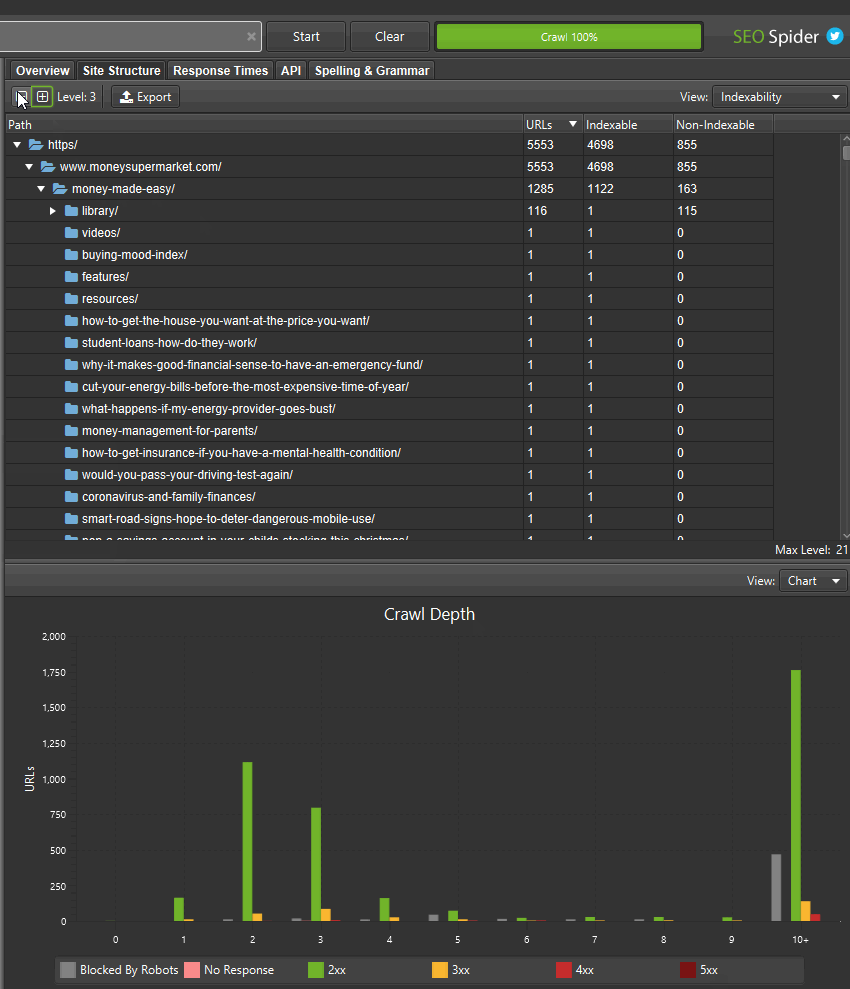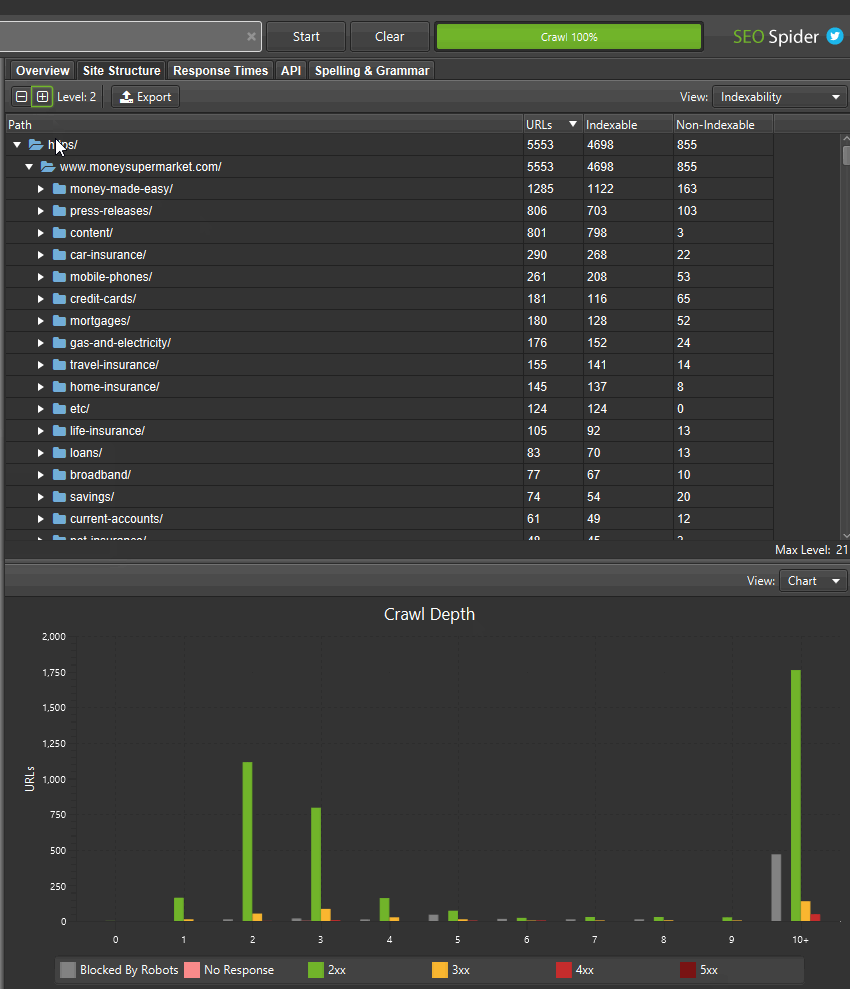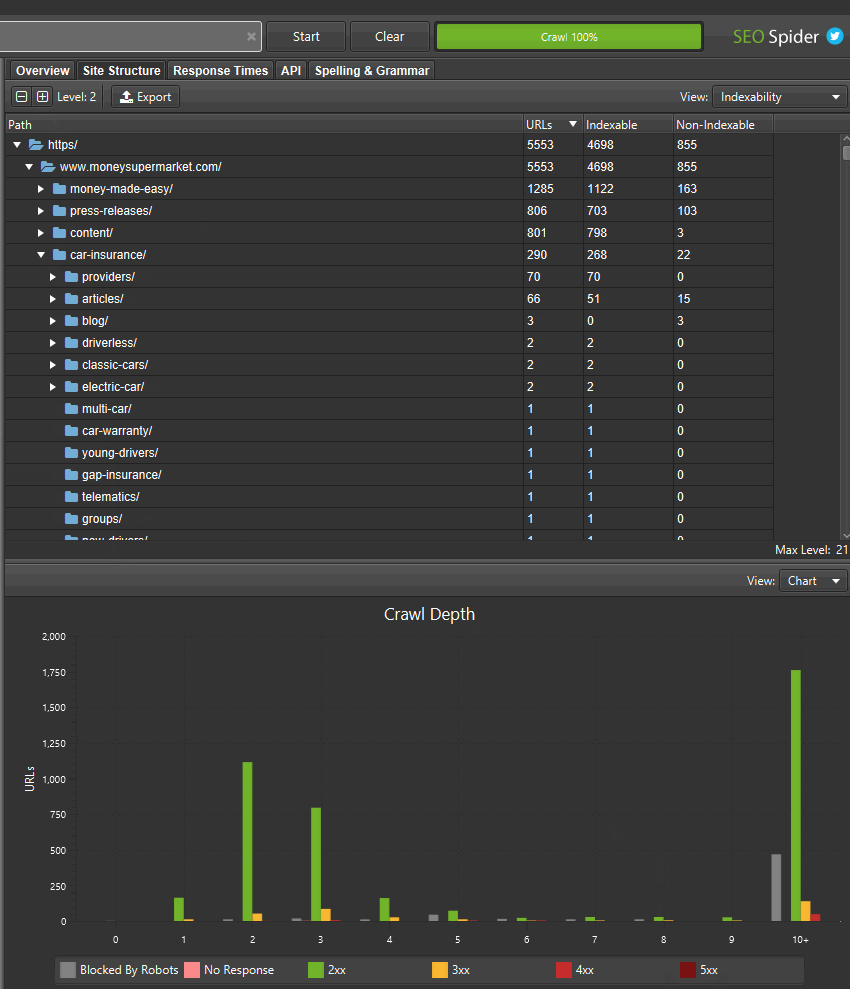
If you’ve found areas of a site with non-indexable URLs, you can switch the ‘view’ to analyse the ‘indexability status’ of those different path segments to see the reasons why they are considered as non-indexable.
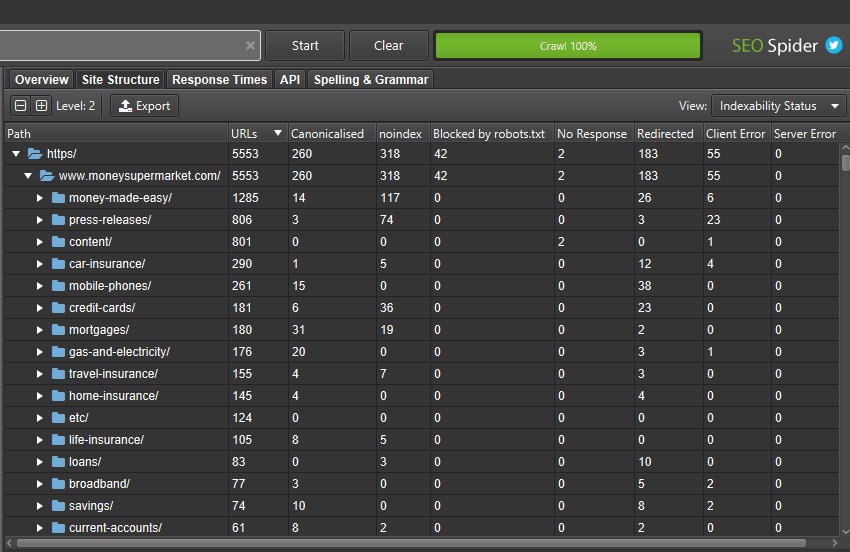
You can also toggle the view to crawl depth across directories to help identify any internal linking issues to areas of the site, and more.
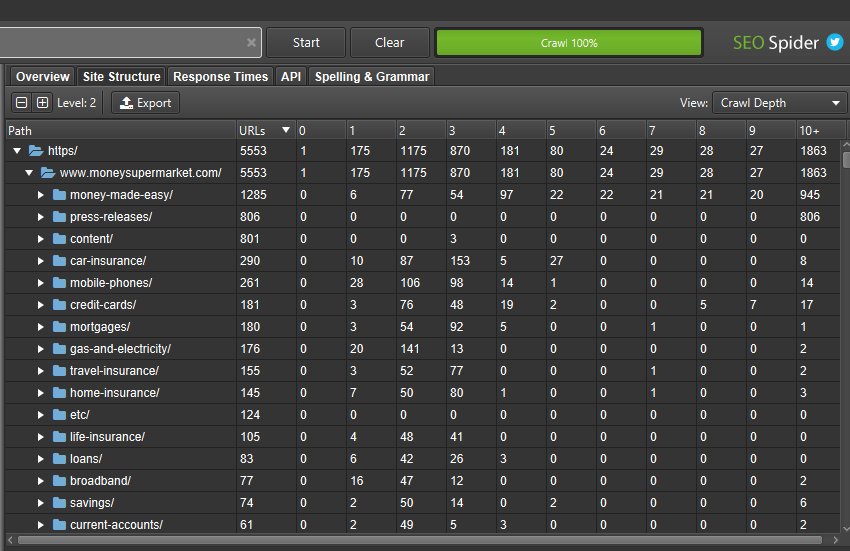
This wider aggregated view of a website should help you visualise the architecture, and make better decisions for different sections and segments.
6) New Configuration Options
We’ve introduced two new significant configuration options – ‘Ignore Non-Indexable URLs for On-Page Filters’ and ‘Ignore Paginated URLs for Duplicate Filters’.
These are both enabled by default via ‘Config > Spider > Advanced’, and will mean non-indexable pages won’t be flagged in appropriate on-page filters for page titles, meta descriptions, or headings.
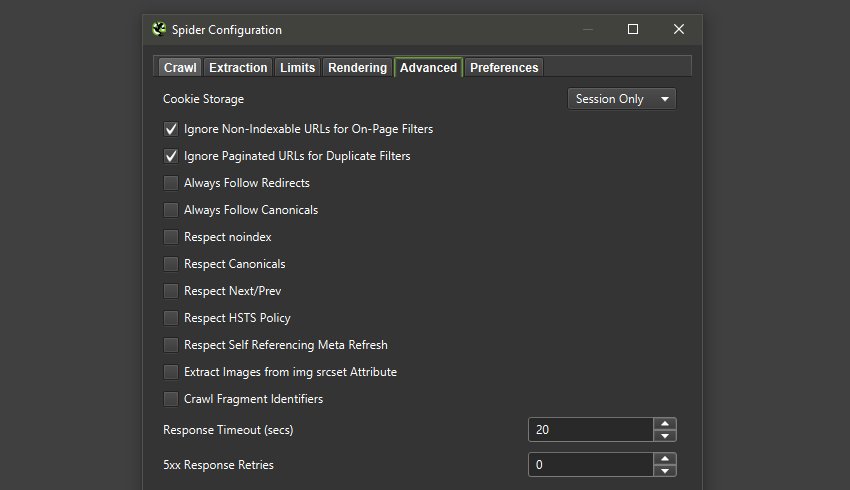
This means URLs won’t be considered as ‘Duplicate’, or ‘Over X Characters’ or ‘Below X Characters’ if for example they are noindex, and hence non-indexable. Paginated pages won’t be flagged for duplicates either.
If you’re crawling a staging website which has noindex across all pages, remember to disable these options.
These options are a little different to the ‘respect‘ configuration options, which remove non-indexable URLs from appearing at all. Non-indexable URLs will still appear in the interface, they just won’t be flagged for relevant issues.
Other Updates
Version 14.0 also includes a number of smaller updates and bug fixes, outlined below.
- There’s now a new filter for ‘Missing Alt Attribute’ under the ‘Images’ tab. Previously missing and empty alt attributes would appear under the singular ‘Missing Alt Text’ filter. However, it can be useful to separate these, as decorative images should have empty alt text (alt=””), rather than leaving out the alt attribute which can cause issues in screen readers. Please see our How To Find Missing Image Alt Text & Attributes tutorial.
- Headless Chrome used in JavaScript rendering has been updated to keep up with evergreen Googlebot.
- ‘Accept Cookies’ has been adjusted to ‘Cookie Storage‘, with three options – Session Only, Persistent and Do Not Store. The default is ‘Session Only’, which mimics Googlebot’s stateless behaviour.
- The ‘URL’ tab has new filters available around common issues including Multiple Slashes (//), Repetitive Path, Contains Space and URLs that might be part of an Internal Search.
- The ‘Security‘ tab now has a filter for ‘Missing Secure Referrer-Policy Header’.
- There’s now a ‘HTTP Version’ column in the Internal and Security tabs, which shows which version the crawl was completed under. This is in preparation for supporting HTTP/2 crawling inline with Googlebot.
- You’re now able to right click and ‘close’ or drag and move the order of lower window tabs, in a similar way to the top tabs.
- Non-Indexable URLs are now not included in the ‘URLs not in Sitemap’ filter, as we presume they are non-indexable correctly and therefore shouldn’t be flagged. Please see our tutorial on ‘How To Audit XML Sitemaps‘ for more.
- Google rich result feature validation has been updated inline with the ever-changing documentation.
- The ‘Google Rich Result Feature Summary’ report available via ‘Reports‘ in the top-level menu, has been updated to include a ‘% eligible’ for rich results, based upon errors discovered. This report also includes the total and unique number of errors and warnings discovered for each Rich Result Feature as an overview.
That’s everything for now, and we’ve already started work on features for version 15. If you experience any issues, please let us know via support and we’ll help.
Thank you to everyone for all their feature requests, feedback, and continued support.
Now, go and download version 14.0 of the Screaming Frog SEO Spider and let us know what you think!
Small Update – Version 14.1 Released 7th December 2021
We have just released a small update to version 14.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Fix ‘Application Not Responding’ issue which affected a small number of users on Windows.
- Maintain Google Sheets ID when overwriting.
- Improved messaging in Force-Directed Crawl Diagram scaling configuration, when scaling on items that are not enabled (GA etc).
- Removed .xml URLs from appearing in the ‘Non-Indexable URLs in Sitemap’ filter.
- Increase the size of Custom Extraction text pop-out.
- Allow file name based on browse selection in location chooser.
- Add AMP HTML column to internal tab.
- Fix crash in JavaScript crawling.
- Fix crash when selecting ‘View in Internal Tab Tree View’ in the the Site Structure tab.
- Fix crash in image preview details window.
Small Update – Version 14.2 Released 16th February 2021
We have just released a small update to version 14.2 of the SEO Spider. This release includes a couple of cool new features, alongside lots of small bug fixes.
Core Web Vitals Assessment
We’ve introduced a ‘Core Web Vitals Assessment’ column in the PageSpeed tab with a ‘Pass’ or ‘Fail’ using field data collected via the PageSpeed Insights API for Largest Contentful Paint, First Input Delay and Cumulative Layout Shift.
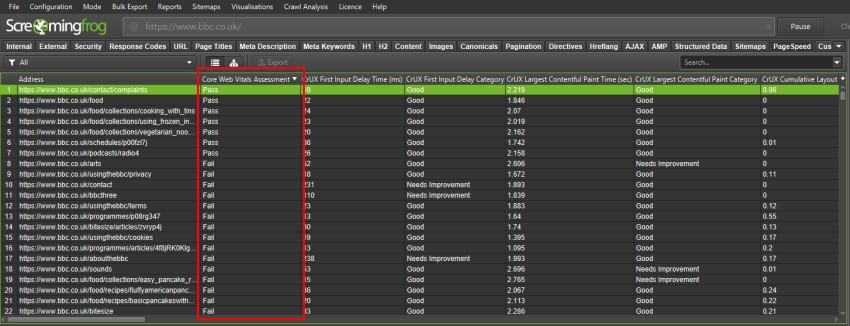
For a page to ‘pass’ the Core Web Vital Assessment it must be considered ‘Good’ in all three metrics, based upon Google’s various thresholds for each. If there’s no data for the URL, then this will be left blank.
This should help identify problematic sections and URLs more efficiently. Please see our tutorial on How To Audit Core Web Vitals.
Broken Bookmarks (or ‘Jump Links’)
Bookmarks are a useful way to link users to a specific part of a webpage using named anchors on a link, also referred to as ‘jump links’ or ‘anchor links’. However, they frequently become broken over time – even for Googlers.
https://twitter.com/JohnMu/status/1351146583828672514
To help with this problem, there’s now a check in the SEO Spider which crawls URLs with fragment identifiers and verifies that an accurate ID exists within the HTML of the page for the bookmark.
You can enable ‘Crawl Fragment Identifiers’ under ‘Config > Spider > Advanced’, and then view any broken bookmarks under the URL tab and new ‘Broken Bookmark’ filter.
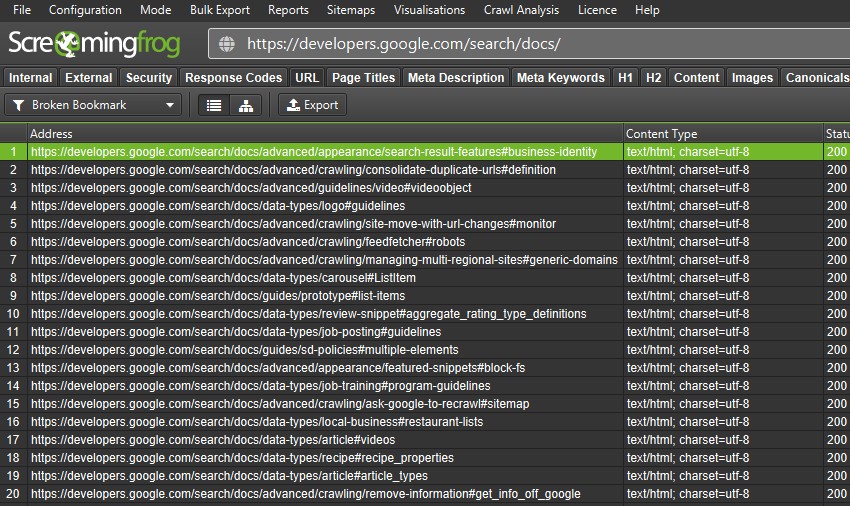
You can view the source pages these are on by using the ‘inlinks’ tab, and export in bulk via a right click ‘Export > Inlinks’. Please see our tutorial on How To Find Broken Bookmark & Jump Links.
14.2 also includes the following smaller updates and bug fixes.
- Improve labeling in all HTTP headers report.
- Update some column names to make more consistent – For those that have scripts that work from column naming, these include – Using capital case for ‘Length’ in h1 and h2 columns, and pluralising ‘Meta Keywords’ columns from singular to match the tab.
- Update link score graph calculations to exclude self referencing links via canoncials and redirects.
- Make srcset attributes parsing more robust.
- Update misleading message in visualisations around respecting canonicals.
- Treat HTTP response headers as case insensitive.
- Relax Job Posting value property type checking.
- Fix issue where right click ‘Export > Inlinks’ sometimes doesn’t export all the links.
- Fix freeze on M1 mac during crawl.
- Fix issue with Burmese text not displayed correctly.
- Fix issue where Hebrew text can’t be input into text fields.
- Fix issue with ‘Visualisations > Inlink Achor Text Word Cloud’ opening two windows.
- Fix issue with Forms Based Auth unlock icon not displaying.
- Fix issue with Forms Based Auth failing for sites with invalid certificates.
- Fix issue with Overview Report showing incorrect site URL in some situations.
- Fix issue with Chromium asking for webcam access.
- Fix issue on macOS where launching via a .seospider/.dbseospider file doesn’t always load the file.
- Fix issue with Image Preview incorrectly showing 404.
- Fix issue with PSI CrUX data being duplicated in Origin.
- Fix various crashes in JavaScript crawling.
- Fix crash parsing some formats of HTML.
- Fix crash when re-spidering.
- Fix crash performing JavaScript crawl with empty user agent.
- Fix crash selecting URL in master view when all tabs in details view are disabled/hidden.
- Fix crash in JavaScript crawling when web server sends invalid UTF-8 characters.
- Fix crash in Overview tab.
Small Update – Version 14.3 Released 17th March 2021
We have just released a small update to version 14.3 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Add Anchor Text Alt Text & Link Path to ‘Redirect’ reports.
- Show the display URL for duplicate content reports rather than the URL encoded URL.
- Update right click ‘History >’ checks to be HTTPS.
- Fix issue with Image Details tab failing to show images if page links to itself as an image.
- Fix issue with some text labels being truncated.
- Fix issue where API settings can’t be viewed whilst crawling.
- Fix issue with GA E-commerce metrics not showing when reloading a DB crawl.
- Fix issue with ‘Crawls’ UI not sorting on modified date.
- Fix PageSpeed CrUX discrepancies between master and details view.
- Fix crash showing authentication Browser.
- Fix crash in visualisations.
- Fix crash removing URLs.
- Fix crash after editing SERP panel.
- Fix odd colouring on fonts on macOS.
- Fix crash during JavaScript crawling.
- Fix crash viewing PageSpeed details tab.
- Fix crash using Wacom tablet on Windows.






These are great changes!
Exporting to google sheets will significantly improve the comfort of working on a project by several people at once.
Thanks to header support I can get rid of several plugins in my browser:
And have you planned to support the command line for the dbstorage version in version 15.0?
Hey Rafal,
Great to hear they are helpful.
On the CLI and database storage, you can switch to that already –
https://www.screamingfrog.co.uk/seo-spider/user-guide/general/#command-line-interface-set-up
Check out the ‘Choosing Storage Mode’ section.
Cheers.
Dan
So much work to help us better understand the structure of a website.
And the new feature to store cookies and helps us audit for compliance is a must have feature… No need of an external tool now!
Screaming Frog makes my daily work much easier – with the quick overview of title tags, internal linking and the clear technical presentation of the websites. And now this new development step. Thank you for your good work!
All great additions. I can’t help but be the most excited about dark mode… .
Hi, is it possible, that you integrate the most common regex expressions to the search field?
I find myself always feelin like “Dear regex god, please show me only entries, which do NOT have the words “huge seo success” in it.
I guess I am not the only one for this.
Best,
Martin
Cheers for the suggestion, Martin.
Yeah, we plan on giving the search function a bit of an overhaul. It’s on the list :-)
I would love to see the export to google sheets in scheduling to a selected folder in drive. This would make connecting crawls to Google Data Studio 90% automated. Not sure how you would show previous crawls if overwritten though to show graphs of all the work I’m doing :).
That was my first question too:)
I will do this with setting “overwrite files in output” and removing data from actual sheet into other sheet with this GSheets addon: https://gsuite.google.com/marketplace/app/archive_data/187729264527
Good suggestion! We can potentially do that, at the moment we just export to the ‘Screaming Frog SEO Spider’ folder.
You can either overwrite, or create a timestamped folder.
We’re waiting on more feedback from users on what they want, and we’ll update further.
Dan
The method i mentioned will not work – this addon acts only inside of the same document between different tabs. I see now just a single way to create Data Studio reports fully automatically – two conditions must be fulfilled for this:
1. Exported data must be appended to the same Google Sheet,
2. Appended data must be written with a timestamp
Until you add this function, i’ll write a helper Google App script :)
I would love to use Google drive for crawling save without make a Google cloud account. Can may be possible this? of course this one you suggest is very good “I would love to see the export to google sheets in scheduling to a selected folder in drive”. Thank you.
Great software
Great features indeed! However, I’d still want to see easier filtering. Don’t get me wrong SF is a great tool but the fact that I have to learn regex to filter things out is a bummer to me.
We use SF for its great features which help us root problems faster why not search and filter faster as well? Especially now that you support Google sheets we should be able to extract what we nees in specific rather than export and then filter.
Sitebulb is already there, and yet SF is better by far.
Cheers for the thoughts, Stelios. Agree with you, we have this on the ‘todo’ for development.
The dark mode is super cool!
We love it! Without a doubt one of the most excellent SEO tools anywhere in the world.
The dark mode is super cool!
This is really cool news. Thanks a lot. We use Screaming Frog via a root server. The schedulable execution with the new Google Sheet allows many new ideas. Automatic Google presentations, task collection for URls, DataStudio and certainly much more. I am looking forward to the implementation.
please update table template for data studio for version 14. new app looks cool❤
Thank you for bringing the dark mode on to Screaming Frog. It really helps with all the hours staring into the good data you provide!
Hi there, I just loved the dark mode of your software. I often work at night so it’s so much pleasurable to be able to use the dark version. My eyes don’t get too tired. It looks like you read my mind. Thanks for that
Cheers
Hey!
Very good update with many new usefull features. Nice work!
for me:
1) 14.0 crashes on EVERY crawl overview report saving (no matter excel, csv). Program saving report and just closing. Over reports are OK. (Both Diskstorage and Memory).
2) Program stop responding very often while crawling. So need to close process in task manager and restart SF to continue crawl. 13.2 worked perfectly with no such trouble at all. Windows 7 Pro, Diskstorage mode + external SSD via USB 2.0 now + memory 6-8GB. Problem is not related to the size of crawl and may stop responding at the very begining or later on. In fact need to continue follow and check all time.
3) When Restart (resume) after crash i see, that chart and table of crawl depth is nulled.
http://prntscr.com/vtv10b
http://prntscr.com/vtv3fp
And Summary at the top of the right window is populated with wrong numbers (it was the problem in 13.2 too).
http://prntscr.com/vtuxwk
Is it nown bugs or any quick advice?
Thanks in advance
Hi Kirill,
Thank you, glad you like the update. On each of your issues –
1 & 2) Please can you send over your logs? Help > Debug > Save Logs https://www.screamingfrog.co.uk/seo-spider/support/
3) Will see if we can replicate here, but it would be good to sort the crash out for you.
4) Are you able to save over your saved crawl file with this data? It doesn’t make sense that total URLs encountered is lower than ‘Response Codes > All’. We’ve not seen this before!
Cheers.
Dan
Hello, Dan!
I was already worried about my comment, as it disappeared a few minutes after publication.
It seems that the situation with Not Responds is not just for me. See the comment below from Stefani.
In a situation like Stefani, I close the application and then restart the SF and continue the interrupted scan as I am working in the save-to-disk mode. If I work in RAM mode, it will not be possible to complete the crawling at all.
” 4) Are you able to save over your saved crawl file with this data? It doesn’t make sense that total URLs encountered is lower than ‘Response Codes > All’. – Yes, the file is saved and the scanning depth data shows ridiculous numbers for the number of URLs encountered. Well, at least the report is saved, albeit with errors )
Hi Kirill,
Comments go into moderation and I have to approve each one.
If you pop us an email, we’ve worked out what Stefani’s issue is and have given her a beta :-) So if you have the same issue, it’s fixed.
On 4) Apologies, I meant ‘are you able to send over your saved crawl file with this data?’.
When you email us via support, send over the crawl so we can take a look at that specific issue where the numbers don’t match up.
Cheers.
Dan
Hi,
Since the new version, Screaming Frog can’t seem to complete the crawl of my website. Never had this issue before. It gets between 10 and 25% of the way and then freezes (and says Not Responding). Any advice?
Hi Stefani,
Yes, please send us the details – https://www.screamingfrog.co.uk/seo-spider/support/
Cheers
Dan
Great new features, exporting in Google Sheets will make my daily tasks way faster. No doubt this is one of the greatest tools for SEO!
I love the Dark Mode. Great Software!!
When will the optimized version of Screaming Frog for M1 chip come out? and know it can run on Rosetta2?
Hey, Dan!
Thanks for 14.1 fix Not Reponding issue!
Crawled a site and found an issue as i think: jpeg with non ASCII file name has 200 status but in the bottom tab Image Details it shows unable to display Image with 404 error Reason. I think some bug out there. Crawled with java, ignore robots.txt (for info)
Image Details bottom tab screenshot: http://prntscr.com/vy8svd
URL details bottom tab screenshot: http://prntscr.com/vy8v0r
Cheers, Kirill – Glad that fixed it.
The image preview issue appears to be a Window specific, as it works on MacOS. Thanks for letting us know, we’ll fix up.
Dan
The Google Sheets is the master stroke, This feature added tremendous value to the product. What other feature are coming soon? Sorry to ask silly question but is anything we can automate from the tool?
Hey, Dan!
Strange Structured Data validation error result in 14.1
http://prntscr.com/vyse7o
Last breadcrumb has no link to click (empty @id) and it looks “name” of the last item went to first element of the list basing of the base href of the page
Just my guess
Hi Kirill,
Please can you send through any possible bugs or specifics like this to [email protected]?
We have a team inbox where we can look into specific scenarios. It also means you can share URLs in the email (rather than an image of a URL which I always dread ;-)).
We can then reply in detail to issues, and keep you updated with any fixes as necessary.
Thanks,
Dan
The best technical software for SEO ever. You do a very good job!
Hi! Just wanted to know where the “Directives” dropdown went to after the update? I can’t seem to find it now in v14. It was after Pagination and before Hreflang. Thanks!
It’s still there, but you can right click on tabs and ‘close’, so it sounds like that’s perhaps what you have done.
You can use the ‘+’ picker to the right hand side of all the top tabs to add it back, or go to ‘Config > User Interface > Reset Tabs’ and it will reappear.
Cheers.
Dan
Hi there, Just want to thank you guys for screaming frog. Despite its name being really catchy the software works great for me. Without any doubts one of the “must have” program for me! Cheers
Chris
Hey, i just love this dark mode! It’s very helpful with crawling sites in dark basement :) Still using your tool and still be pleased of it!
Great new features ! however still missing the multiple proxy option…
Next – built-in VPN please :)
Screaming Frog is always a big help for me since the start of my online journey ,well i didn’t know more about this until now thanks for this fantastic update.
Thank you for this incredible update.
The new option to export to google sheets, I think it is very useful, I will use it together with my team.
Congratulations on your work
unfortunately, application crashes on the Apple M1 CPU, stops responding :(
Hi Mike,
Pop us an email ([email protected]), it should be fine – https://www.screamingfrog.co.uk/seo-spider/faq/#does-the-seo-spider-work-on-the-new-m1-macs
Cheers,
Dan
Screaming Frog one of the best SEO Tools! It helps me to rank the websites of my customers much better! Title Tags, Internal Links, Redirects…. i love it! Thanks you for your good work!
Without this program, SEO work cannot be done. Thank you to everyone who contributed.
Hi Screaming Frog,
Yvette from Norway here. I am new to your site. Would very much learn to use your tool and build SEO reports. Thinking about client reports with nice visual results from analyzing a website. Is this something should use the data from Screaming Frog to make, or is there a template or other tools for this?
Love the dark mode.
Thanks for keeping us with the latest update. I am using this tool over the last few years and just one word “Awesome”.
I think there must be an option for fetching all the reports in one single go like customize the report.
Thanks,
Can i crawl a localhost website with screaming frog?
I have recently approached this program but I still get great satisfaction. Thanks
Thanks for this informative and valuable update. I have been using this tool since last few years and it has been an awesome experience. However, I wish there must be an option for fetching all the reports in a go like the tailor-made report.
Whenever I try to download the SEO Spider, all the text is jumbled together and unreadable. If I highlight the text and copy + paste, then I can see the actual English text. Not sure what is going on with that…
Hi Haydon,
This FAQ should help – https://www.screamingfrog.co.uk/seo-spider/faq/#why-is-the-gui-text-garbled
Cheers,
Dan
Yeah…dark mode finally :D I was looking forward those new configuration options. Great features.
In some tutorials, writers referring to “internal_html.xlsx/csv”.
How can i export this report from SF?
That’s really nice! Just wanted to say thanks for another excellent update, it’s always good to see improvements to the tool. Keep it up, now yours is the best SEO spider!
PS: love the dark mode.
Thanks
I love screaming frog, great update.
Does SF already supports apple M1 Processors?
Hi Luca,
It does, more here – https://www.screamingfrog.co.uk/seo-spider/faq/#does-the-seo-spider-work-on-the-new-m1-macs
Cheers
Dan
Amazing update indeed. Screaming Frog SEO Spider is a solid crawler with a lot of options. I often use it for technical SEO audits, checks, and QA. Was using its free version when I was new to the SEO game. Recently upgraded to a premium one. Must say it is worth it. Can’t wait to try the dark theme ;)
Great new features, but while Exporting file bit slower the app
Amazing features, dark mode is really great
It may not be a very key issue, but the implementation of the dark mode has made working on Screaming Frog very pleasant and comfortable. After switching to the dark mode, I can’t imagine going back to the previous mode. You’ve done a great job on this. Besides, functionality. I am impressed with how quickly and dynamically this tool is developing. I do not hide that one of my favorites.
Thanks for keeping us with the newest update. i’m using this tool over the previous couple of years and only one word “Awesome”.
Love this dark mode! It’s very helpful with crawling sites in dark basement.
Thanks for this fantastic update.
Great SEO software and happy with the improvements. One of the seo tools that still has an reasonable subscription price while offering the full package.
I cannot get the program to even open on Windows 10. It worked several months ago but now the program won’t even open. I click the icon to launch and it simply never launches and eventually Windows asks if I want to keep waiting on the program to load. Disappointing for sure. I’ve even uninstalled and reinstalled an older version and nothing works. Any advice?
Hi Brent,
You’re leaving a comment on a post that’s over a year old and isn’t even the latest version, rather than just asking us via support?
So, my advice would be – Contact us via support for help! Or comments like this will often be completely missed.
Cheers.
Dan
The most important seo tool!
Absolutely one of the best SEO-Tools with brilliant Features. Happy with the dark mode! Thank you!
Screaming frog is such a great tool for an SEO Specialist to use
One word Comment for Screaming Frog Tool is Excellent !! I am using last 4 years…
A basic and the best SEO-tool that we use daily in our agency. Thanks for bring it! ❤
Screaming Frog is in my “TOP 5” list of the best SEO-Tools. I luv the dark mode!!!!
Finally dark mode!! Screaming frog one of the best SEO-Tools ATM :D
Thanks for sharing this content.Its a great SEO tool with brilliant features and thanks for keeping us with the newest update.You have done a superior work.
Been using your software ever since Dan first introduced it.
Many thanks
Ben
Screaming Frog is the best SEO-Tools with brilliant features. Good work!
I appreciate the update! This tool has been incredible over the years.
A feature to generate all reports in one go with customization would be a fantastic addition.
Thank you!
Thanks for the updates! I’ve been using this tool for years, and it’s awesome. A customizable report option would be great. Keep up the great work!