Screaming Frog SEO Spider Update – Version 16.0
Dan Sharp
Posted 22 September, 2021 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 16.0
We’re excited to announce Screaming Frog SEO Spider version 16.0, codenamed internally as ‘marshmallow’.
Since the launch of crawl comparison in version 15, we’ve been busy working on the next round of prioritised features and enhancements.
Here’s what’s new in our latest update.
1) Improved JavaScript Crawling
5 years ago we launched JavaScript rendering, as the first crawler in the industry to render web pages, using Chromium (before headless Chrome existed) to crawl content and links populated client-side using JavaScript.
As Google, technology and our understanding as an industry has evolved, we’ve updated our integration with headless Chrome to improve efficiency, mimic the crawl behaviour of Google closer, and alert users to more common JavaScript-related issues.
JavaScript Tab & Filters
The old ‘AJAX’ tab, has been updated to ‘JavaScript’, and it now contains a comprehensive list of filters around common issues related to auditing websites using client-side JavaScript.

This will only populate in JavaScript rendering mode, which can be enabled via ‘Config > Spider > Rendering’.
Crawl Original & Rendered HTML
One of the fundamental changes in this update is that the SEO Spider will now crawl both the original and rendered HTML to identify pages that have content or links only available client-side and report other key differences.
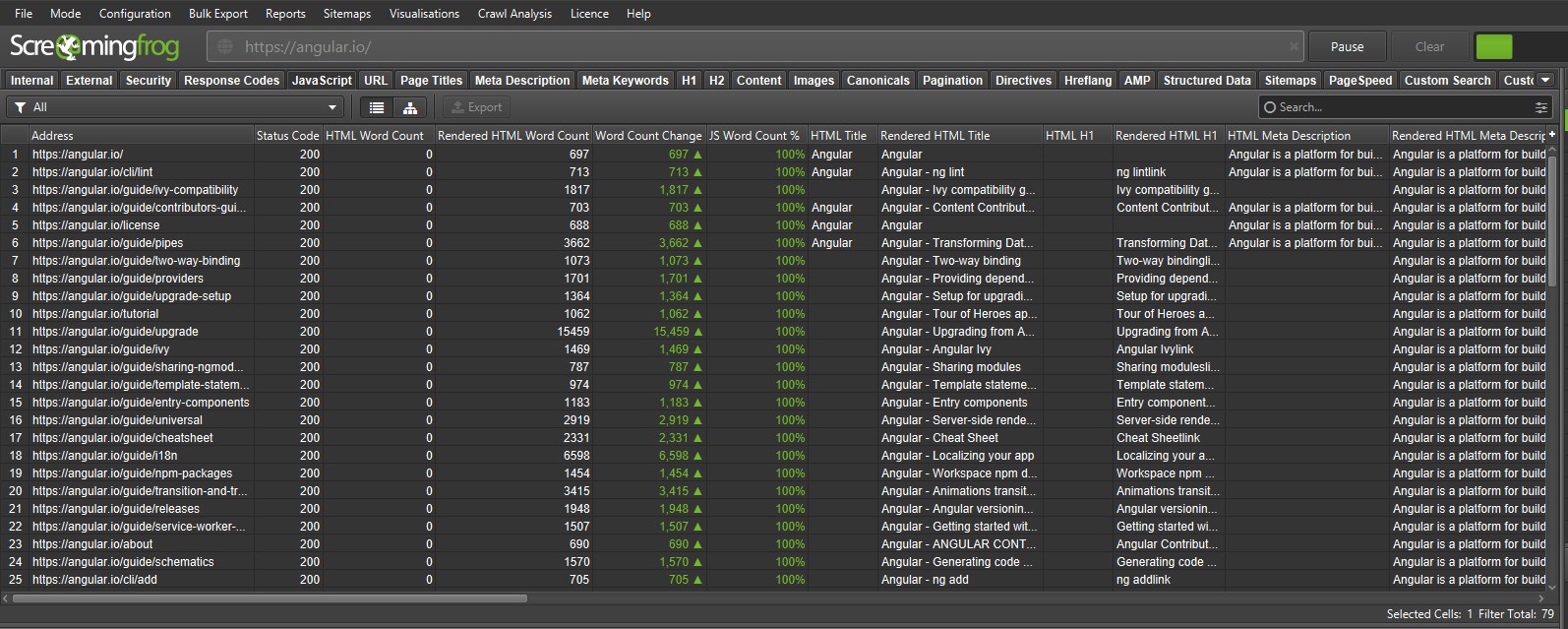
This is more in line with how Google crawls and can help identify JavaScript dependencies, as well as other issues that can occur with this two-phase approach.
Identify JavaScript Content & Links
You’re able to clearly see which pages have JavaScript content only available in the rendered HTML post JavaScript execution.
For example, our homepage apparently has 4 additional words in the rendered HTML, which was new to us.

By storing the HTML and using the lower window ‘View Source’ tab, you can also switch the filter to ‘Visible Text’ and tick ‘Show Differences’, to highlight which text is being populated by JavaScript in the rendered HTML.
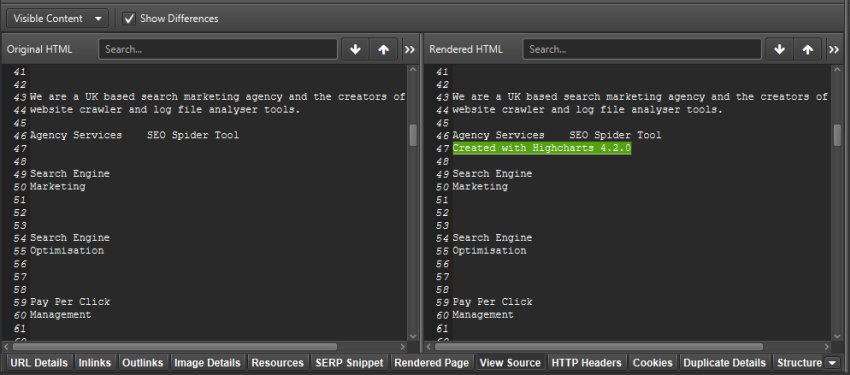
Aha! There are the 4 words. Thanks, Highcharts.
Pages that have JavaScript links are reported and the counts are shown in columns within the tab.
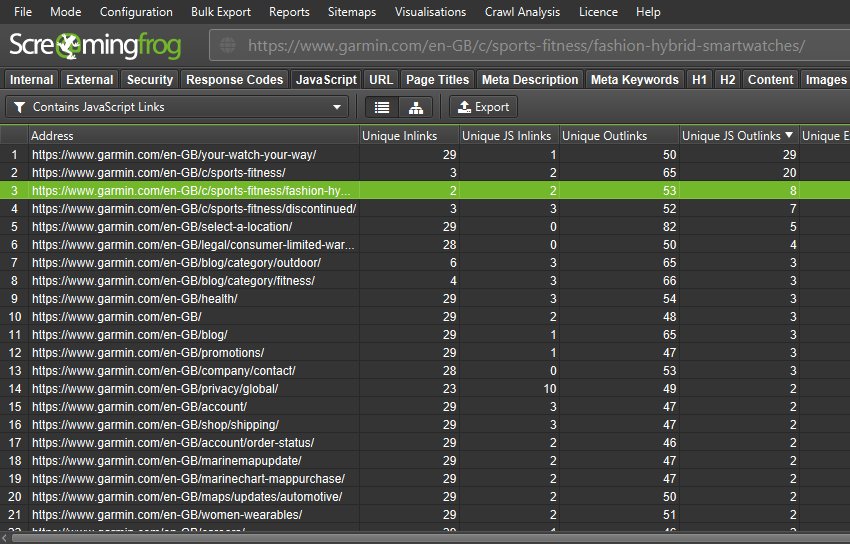
There’s a new ‘link origin’ column and filter in the lower window ‘Outlinks’ (and inlinks) tab to help you find exactly which links are only in the rendered HTML of a page due to JavaScript. For example, products loaded on a category page using JavaScript will only be in the ‘rendered HTML’.
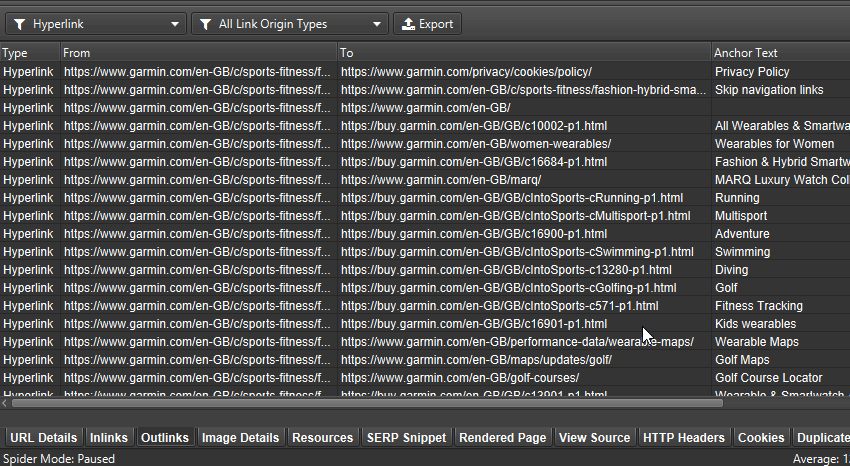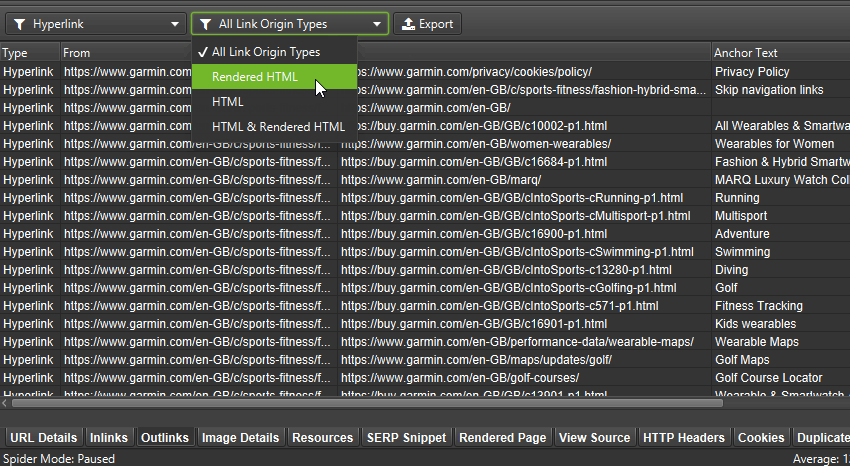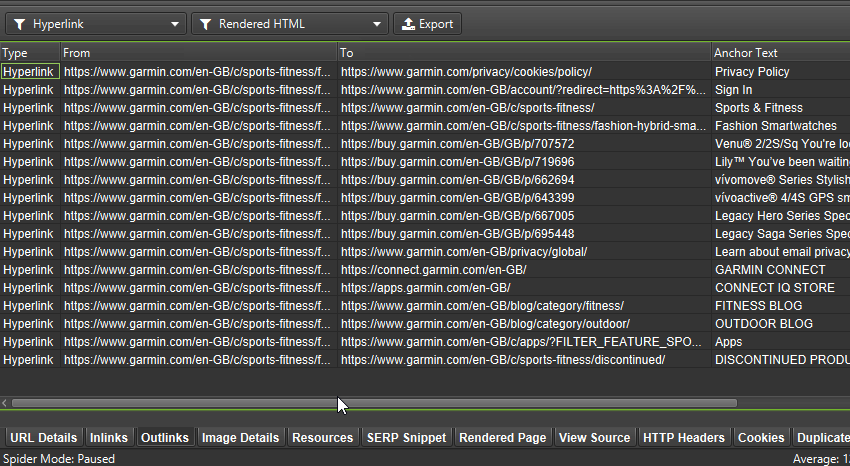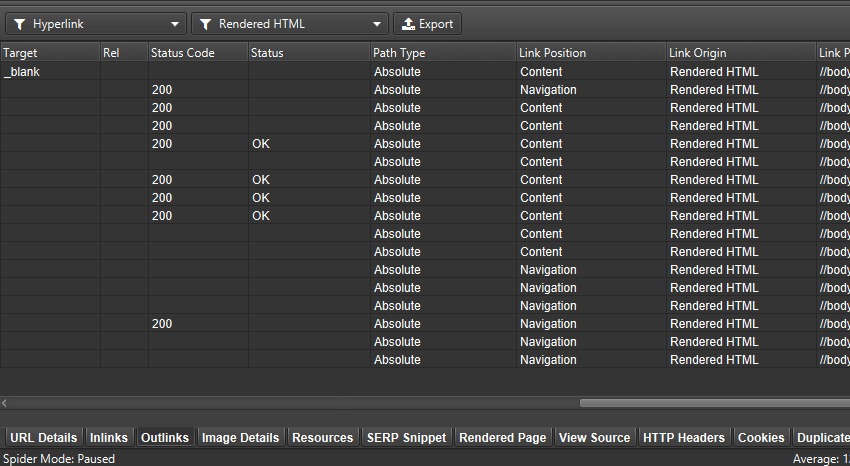
You can bulk export all links that rely on JavaScript via ‘Bulk Export > JavaScript > Contains JavaScript Links’.
Compare HTML Vs Rendered HTML
The updated tab will tell you if page titles, descriptions, headings, meta robots or canonicals depend upon or have been updated by JavaScript. Both the original and rendered HTML versions can be viewed simultaneously.
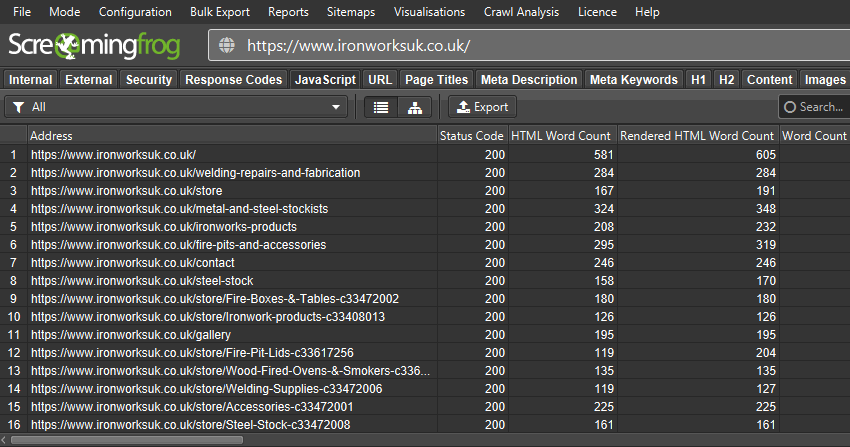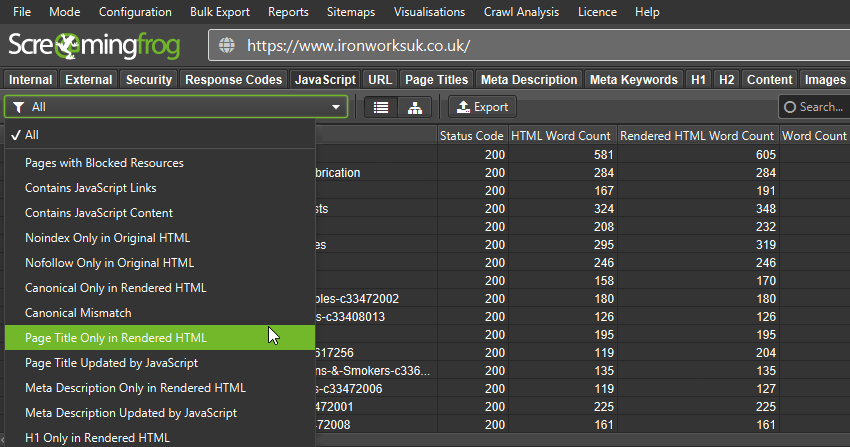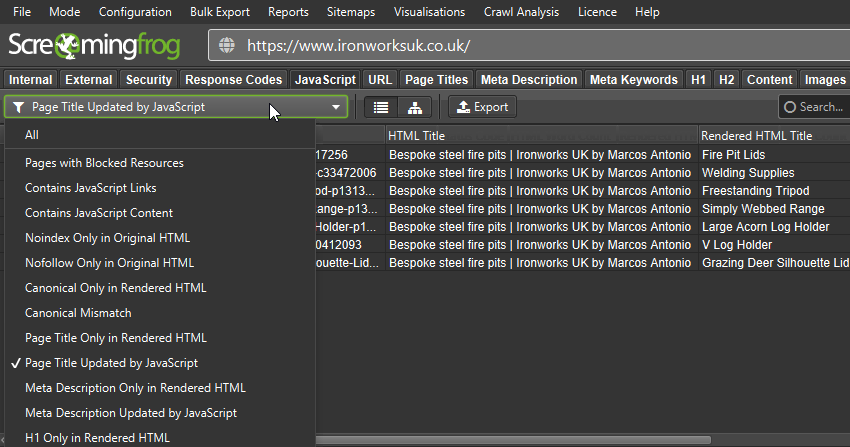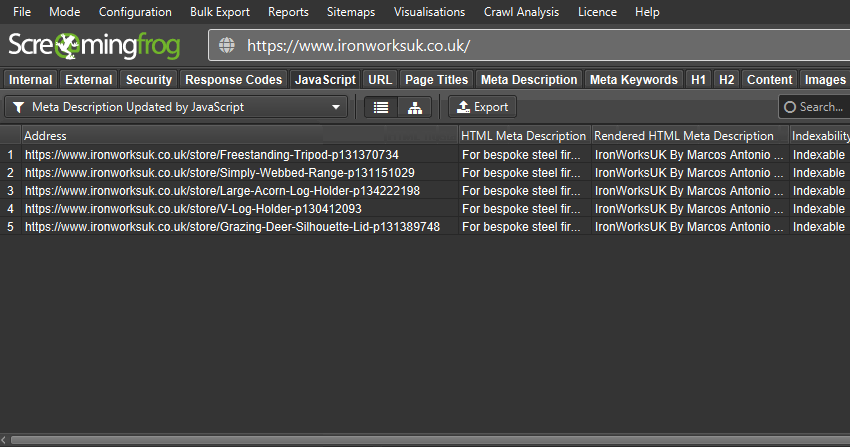
This can be useful when determining whether all elements are only in the rendered HTML, or if JavaScript is used on selective elements.
The two-phase approach of crawling the raw and rendered HTML can help pick up on easy to miss problematic scenarios, such as the original HTML having a noindex meta tag, but the rendered HTML not having one.
Previously by just crawling the rendered HTML the page would be deemed as indexable when in reality Google will see the noindex in the original HTML first, and subsequently skip rendering, meaning the removal of the noindex won’t be seen and the page won’t be indexed.
Shadow DOM & iFrames
Another enhancement we’ve wanted to make is to improve our rendering to better match Google’s own behaviour. Giacomo Zecchini’s recent ‘Challenges of building a search engine like web rendering service‘ talk at SMX Advanced provides an excellent summary of some of the challenges and edge cases.
Google is able to flatten and index Shadow DOM content, and will inline iframes into a div in the rendered HTML of a parent page, under specific conditions (some of which I shared in a tweet).
After research and testing, both of these are now supported in the SEO Spider, as we try to mimic Google’s web rendering service as closely as possible.
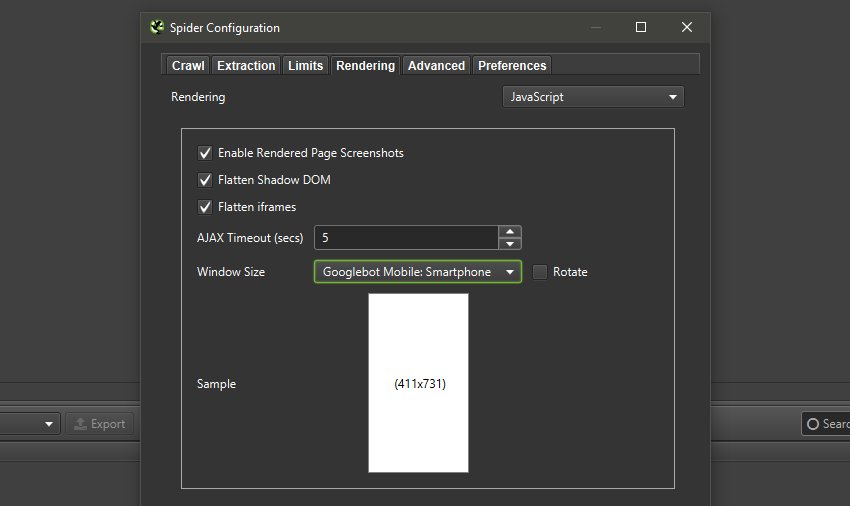
They are enabled by default, but can be disabled when required via ‘Config > Spider > Rendering’. There are further improvements we’d like to make in this area, and if you spot any interesting edge cases then drop us an email.
2) Automated Crawl Reports For Data Studio
Data Studio is commonly the tool of choice for SEO reporting today, whether that’s for your own reports, clients or the boss. To help automate this process to include crawl report data, we’ve introduced a new Data Studio friendly custom crawl overview export available in scheduling.
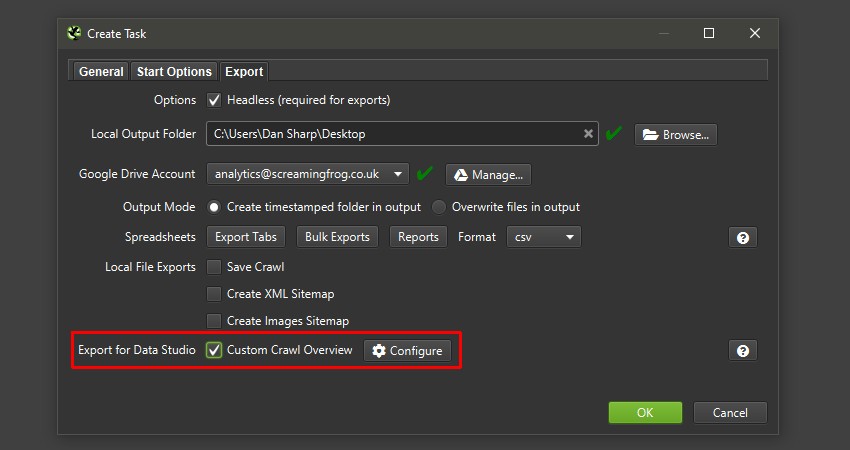
This has been purpose-built to allow users to select crawl overview data to be exported as a single summary row to Google Sheets. It will automatically append new scheduled exports to a new row in the same sheet in a time series.
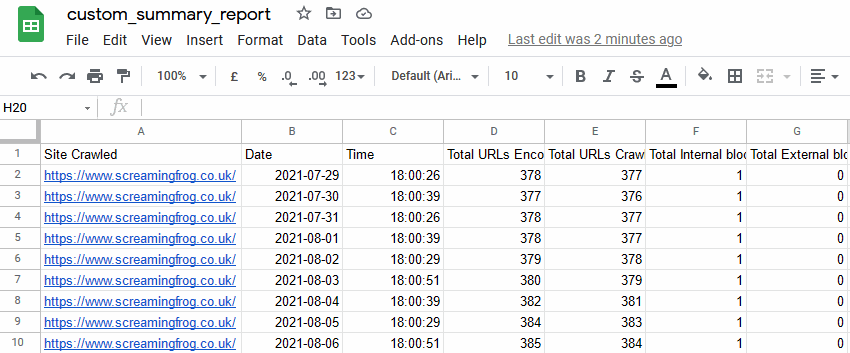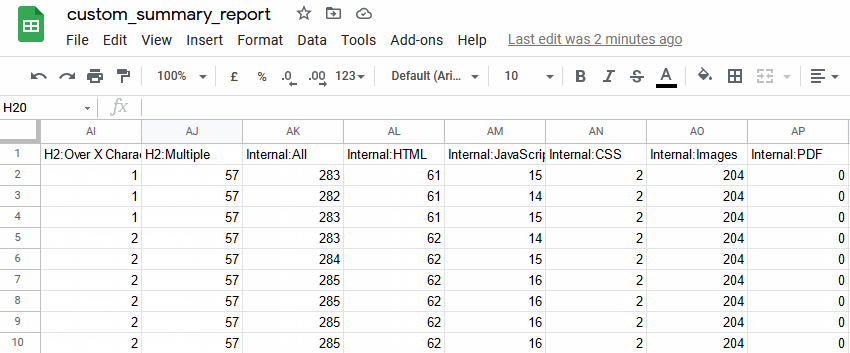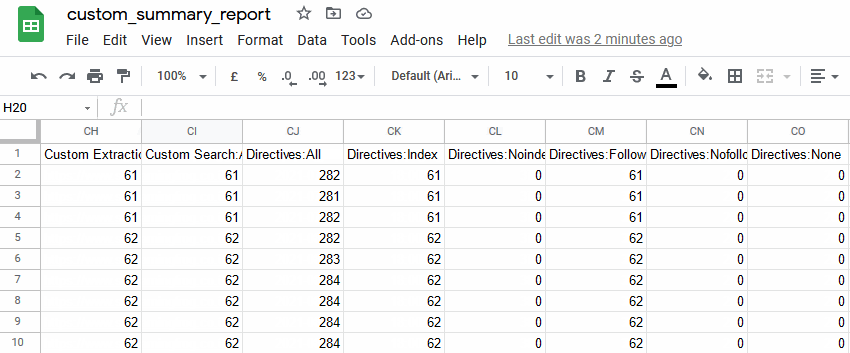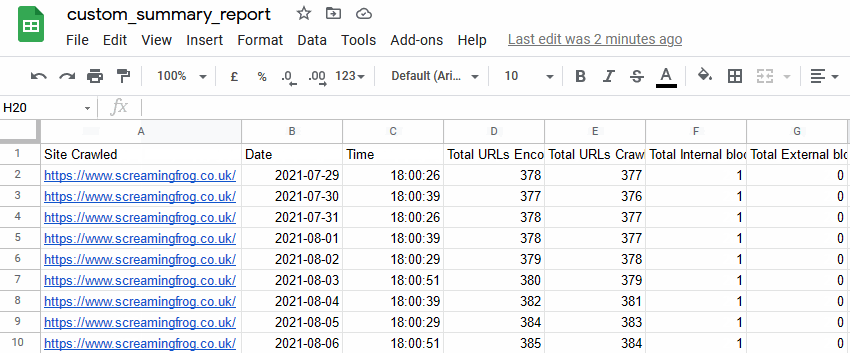
The new crawl overview summary in Google Sheets can then be connected to Data Studio to be used for a fully automated Google Data Studio crawl report. You’re able to copy our very own Screaming Frog Data Studio crawl report template, or create your own better versions!
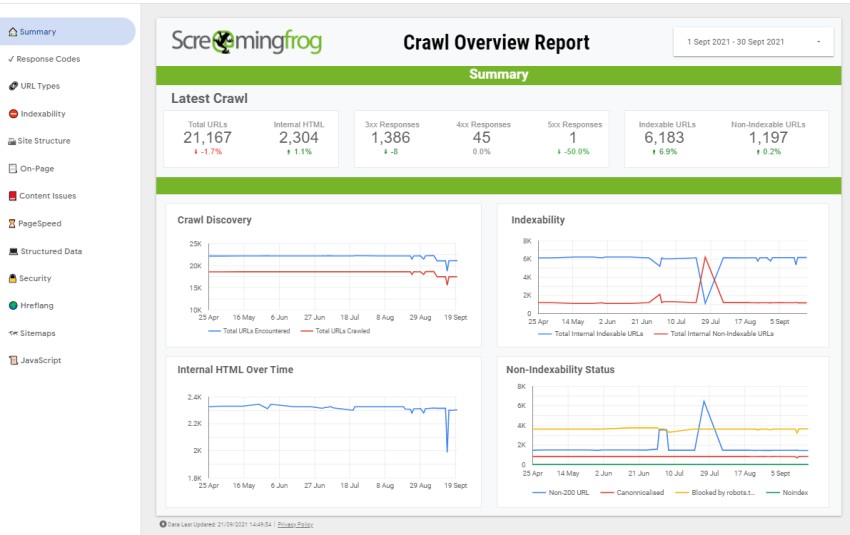
This allows you or a team to monitor site health and be alerted to issues without having to even open the app. It also allows you to share progress with non-technical stakeholders visually.
Please read our tutorial on ‘How To Automate Crawl Reports In Data Studio‘ to set this up.
We’re excited to see alternative Screaming Frog Data Studio report templates, so if you’re a Data Studio whizz and have one you’d like to share with the community, let us know and we will include it in our tutorial.
3) Advanced Search & Filtering
The inbuilt search function has been improved, it defaults to regular text search but allows you to switch to regex, choose from a variety of predefined filters (including a ‘does not match regex’) and combine rules (and/or).
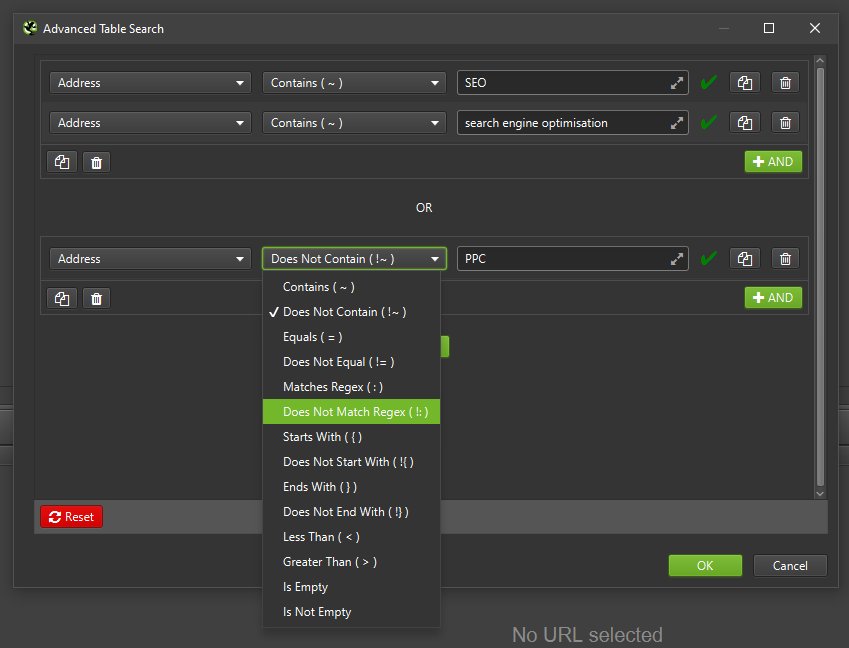
The search bar displays the syntax used by the search and filter system, so this can be formulated by power users to build common searches and filters quickly, without having to click the buttons to run searches.

The syntax can just be pasted or written directly into the search box to run searches.
4) Translated UI
Alongside English, the GUI is now available in Spanish, German, French and Italian to further support our global users. It will detect the language used on your machine on startup, and default to using it.
Language can also be set within the tool via ‘Config > System > Language’.
A big shoutout and thank you to the awesome MJ Cachón, Riccardo Mares, Jens Umland and Benjamin Thiers at Digimood for their time and amazing help with the translations. We truly appreciate it. You all rock.
Technical SEO jargon alongside the complexity and subtleties in language makes translations difficult, and while we’ve worked hard to get this right with amazing native speaking SEOs, you’re welcome to drop us an email if you have any suggestions to improve further.
We may support additional languages in the future as well.
Other Updates
Version 16.0 also includes a number of smaller updates and bug fixes, outlined below.
- The PageSpeed Insights integration has been updated to include ‘Image Elements Do Not Have Explicit Width & Height’ and ‘Avoid Large Layout Shifts’ diagnostics, which can both improve CLS. ‘Avoid Serving Legacy JavaScript’ opportunity has also been included.
- ‘Total Internal Indexable URLs’ and ‘Total Internal Non-Indexable URLs’ have been added to the ‘Overview’ tab and report.
- You’re now able to open saved crawls via the command line and export any data and reports.
- The include and exclude have both been changed to partial regex matching by default. This means you can just type in ‘blog’ rather than say .*blog.* etc.
- The HTTP refresh header is now supported and reported!
- Scheduling now includes a ‘Duplicate’ option to improve efficiency. This is super useful for custom Data Studio exports, where it saves time selecting the same metrics for each scheduled crawl.
- Alternative images in the picture element are now supported when the ‘Extract Images from srcset Attribute’ config is enabled. A bug where alternative images could be flagged with missing alt text has been fixed.
- The Google Analytics integration now has a search function to help find properties.
- The ‘Max Links per URL to Crawl’ limit has been increased to 50k.
- The default ‘Max Redirects to Follow’ limit has been adjusted to 10, inline with Googlebot before it shows a redirect error.
- PSI requests are now x5 times faster, as we realised Google increased their quotas!
- Updated a tonne of Google rich result feature changes for structured data validation.
- Improved forms based authentication further to work in more scenarios.
- Fix macOS launcher to trigger Rosetta install automatically when required.
- Ate plenty of bugs.
That’s everything! As always, thanks to everyone for their continued feedback, suggestions and support. If you have any problems with the latest version, do just let us know via support and we will help.
Now, download version 16.0 of the Screaming Frog SEO Spider and let us know what you think in the comments.
Small Update – Version 16.1 Released 27th September 2021
We have just released a small update to version 16.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Updated some Spanish translations based on feedback.
- Updated SERP Snippet preview to be more in sync with current SERPs.
- Fix issue preventing the Custom Crawl Overview report for Data Studio working in languages other than English.
- Fix crash resuming crawls with saved Internal URL configuration.
- Fix crash caused by highlighting a selection then clicking another cell in both list and tree views.
- Fix crash duplicating a scheduled crawl.
- Fix crash during JavaScript crawl.
Small Update – Version 16.2 Released 18th October 2021
We have just released a small update to version 16.2 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Fix issue with corrupt fonts for some users.
- Fix bug in the UI that allowed you to schedule a crawl without a crawl seed in Spider Mode.
- Fix stall opening saved crawls.
- Fix issues with upgrades of database crawls using excessive disk space.
- Fix issue with exported HTML visualisations missing pop up help.
- Fix issue with PSI going too fast.
- Fix issue with Chromium requesting webcam access.
- Fix crash when cancelling an export.
- Fix crash during JavaScript crawling.
- Fix crash accessing visualisations configuration using languages other then English.
Small Update – Version 16.3 Released 4th November 2021
We have just released a small update to version 16.3 of the SEO Spider. This release is mainly bug fixes and small improvements –
- The Google Search Console integration now has new filters for search type (Discover, Google News, Web etc) and supports regex as per the recent Search Analytics API update.
- Fix issue with Shopify and CloudFront sites loading in Forms Based authentication browser.
- Fix issue with cookies not being displayed in some cases.
- Give unique names to Google Rich Features and Google Rich Features Summary report file names.
- Set timestamp on URLs loaded as part of JavaScript rendering.
- Fix crash running on macOS Monetery.
- Fix right click focus in visualisations.
- Fix crash in Spelling and Grammar UI.
- Fix crash when exporting invalid custom extraction tabs on the CLI.
- Fix crash when flattening shadow DOM.
- Fix crash generating a crawl diff.
- Fix crash when the Chromium can’t be initialised.
Small Update – Version 16.4 Released 14th December 2021
We have just released a small update to version 16.4 of the SEO Spider. This release includes a security patch, as well as bug fixes and small improvements –
Small Update – Version 16.5 Released 21st December 2021
We have just released a small update to version 16.5 of the SEO Spider. This release includes a security patch, as well as bug fixes and small improvements –
- Update to Apache log4j 2.17.0 to fix CVE-2021-45046 and CVE-2021-45105.
- Show more detailed crawl analysis progress in the bottom status bar when active.
- Fix JavaScript rendering issues with POST data.
- Improve Google Sheets exporting when Google responds with 403s and 502s.
- Be more tolerant of leading/trailing spaces for all tab and filter names when using the CLI.
- Add auto naming for GSC accounts, to avoid tasks clashing.
- Fix crash running link score on crawls with URLs that have a status of “Rendering Failed”.
Small Update – Version 16.6 Released 3rd February 2022
We have just released a small update to version 16.6 of the SEO Spider, which includes URL Inspection API integration. Please read our version 16.6 release notes.
Small Update – Version 16.7 Released 2nd March 2022
We have just released a small update to version 16.7 of the SEO Spider. Please read our version 16.7 release notes.






Outstanding work SF team. I shall crawl a JS heavy site later today to test out the new functionality.
Hi Dan, what is the syntax for opening a crawl file with the CLI? Checked in the User Guide and imagine as this is a new release it will be updated soon, but I’m too impatient to wait to try it out! Loving the feature by the way, I can’t state how much this helps our internal automation efforts.
Hello mate,
It’s been too long, how are you? Hope you’re doing well?
Yeah, I am just going through the user guides right now trying to update them all with the latest updates.
Little tip on getting the arguments early, use –
ScreamingFrogSEOSpiderCli.exe –help
This is more up to date than me ;-)
You can use –
–load-crawl “C:\Users\Your Name\Wherever\crawlfilename.seospider”
It has to either be a .seospider or .dbseospider crawl file currently, rather than one just in the database (via ‘File > Crawl’). That’s next on the list!
Shout if any probs!
Cheers.
Dan
Very well thanks! Hope you are doing well also. Ah yep I made the rookie mistake of forgetting –help! Amazing thank you, as always this tool is next level. Have a great day, hopefully meet up soon, I need to visit henley more.
Thanks!
Morning,
I downloaded the macOS version but the tabs contain unintelligible characters.
Will it be modified?
Morning / Afternoon Michele,
Please can you give this a go? https://www.screamingfrog.co.uk/seo-spider/faq/#why-is-the-gui-text-garbled
Essentially it’s due to a fonts issue.
Cheers.
Dan
For some reason, after updating I can’s seem to crawl more than the homepage URL no matter what site I try it on. And I can’t for the life of me figure out why.
FYI this is referring to Javascript rendering, as text mode works fine
Hi Patrick,
Please send it through to us and we can help!
https://www.screamingfrog.co.uk/seo-spider/support/
Cheers,
Dan
nice update, thanks
Good Morning,
I just downloaded the latest version on macOS and I’m experiencing problems with the autentication for password protected websites. Instead of the login page, I only get to an error page.
Is there already a solution to fix this?
Hi Marie,
Sending us an email with the details will help ([email protected]) :-)
https://www.screamingfrog.co.uk/seo-spider/support/
Thanks,
Dan
Hi,
wow thanks for the permanent development. I like the UI in English language. Is there any way that the UI is in one language and the export language is in another?
Greetings
Hi Tom,
Good to hear! No, it all works in the single language you select.
Thanks,
Dan
Hi! Good news! Thanks for update!
I have a problem with SF: when I’m parsing my website for near 5% of pages I get “Error parsing HTML”. What does it mean?
All pages of my website have a same markup.
Hi,
Please send an email with your support query and we can help ([email protected]).
https://www.screamingfrog.co.uk/seo-spider/support/
Thanks,
Dan
Great stuff, especially the new Raw vs rendered HTML comparison feature.
One thing though, naming something “Contains JavaScript Links” is misleading. A real JavaScript link cannot be detected by any crawlers, I am assuming you mean a link that only shows up with JS rendering? Just conscious on how this may cause less technical SEOs to believe that this is the way to find JS links….
Hi George,
Thanks for your thoughts and I can see where you’re coming from (I could ask ‘What do you mean by a ‘real JavaScript link’?’ for example :-))
You can find our definition here – https://www.screamingfrog.co.uk/seo-spider/user-guide/tabs/#javascript
Contains JavaScript Links – Pages that contain hyperlinks that are only discovered in the rendered HTML after JavaScript execution. These hyperlinks are not in the raw HTML.
Will keep an eye out for any confusion.
Cheers.
Dan
Hey! thanks for the update❤
Please show me an example of a Chrome UX spreadsheet for Google Data Studio communication
where can I find? 3) Advanced Search & Filtering
Hi Ronald,
The top right hand corner of the master window, or lower window.
Little screenshot in the user guide here – https://www.screamingfrog.co.uk/seo-spider/user-guide/general/#search-function
Cheers.
Dan
Thank you very much, I had not seen that functionality.
Although it is a very complete program, I have only used the basic functions.
Please show me an example of a Google Data Studio communication Chrome UX spreadsheet.
Hi Joseph,
If you’re referring to the core web vital information, we pull that through with the Chrome UX connector. More details here:
https://web.dev/chrome-ux-report-data-studio-dashboard/
Thanks,
Richard
Hi, I can’t run the .exe file of version 16.0., I keep getting a note – “error launching installer”. This doesn’t happen if I want to reinstall earlier versions.
Any idea why this is so? I am using windows.
Hi Ivan,
That error is usually because you have the app open.
So close the app. Then install the new version.
Hope that helps!
Cheers.
Dan
After upgrade to 16.0 it’s allways crashing on MacOS after i start the new crawl.
Hi TJ,
Please can you try resetting your config (File > Config > Clear Default Config), as that should help.
There’s a crash in 16, when using an old include. We’ll have a fix for it released tomorrow.
Cheers.
Dan
Hi guys —
has this been released? On my new Mac with an M1 chip the Frog keeps crashing every time I even try to start it up.
Hi Daniel,
Yes, 16.1 is released.
Hopefully how you get support is clear enough if you need help still? [email protected]
Thanks,
Dan
Just wanted to thank you for the update guys, the new advanced search functionality has been really useful so far.
Love love love this update! Quick Q: with the Google Data Studio Report, if you wanted to export a manual crawl (not connected to a scheduled), what would be the workflow for getting the right data out of crawl and into a Google Sheet?
Hi Kris,
Good to hear! The GDS integration is via scheduling only I am afraid.
We may offer this export in manual crawls or other means in the future.
Thanks,
Dan
I have just upgraded to version 16.1 now it works ok BUT some text is scrambled i.e
the text below the opening screen
and the search box where you type the url also the start scan button and another button is not in English.
also everything alongtheu top and bottom of the dashboard also sometimes there is a java? alert box with foreign text looks like korean.
Is this a know problem. The app can still be used but when typing in the url to search it is not in English it is either garbled or Korean ?
Hi John,
Sounds like this one – https://www.screamingfrog.co.uk/seo-spider/faq/#why-is-the-gui-text-garbled
Drop us a message via support if you need help.
Cheers.
Dan
Thank you very much I am reading the article you linked me to and will try the suggestions.
Thank you so much!. Followed your advice everything back and running as normal with five minutes. Checked Font Book App no problems, followed picture guide HELP->DEBUG->OPTIONS Clicked on the parts where arrows pointed to because the text was garbled. then quit Screaming Frog and then reopened and like magic everything is now normal.
Amazing updates. loved the new filter within custom extraction and search. Kudos to the team!!
Nice update, thank you for all thoses details
Hi everyone,
It’s a really nice update. Filters were always something I needed.
Among many other uses, I use Screaming Frog to check a batch of pages’ PageSpeed data regularly. After the update, PageSpeed API starts to return 500 after around 500 URLs. I noticed that SF sends API requests much faster than before, after the update. I think this causes to hit the limit for requests per seconds. I hope you can fix this soon, it’s a pain to check for thousands of pages now.
Cheers
Hi Mert,
Cheers for the kind comments!
Yeah unfortunately, Google don’t like it anywhere close to their advertised speed limit it seems… we’re chatting to them about it.
We’ve lowered it again. If you’d like the beta with the slowed down requests, pop us a message via support.
Cheers.
Dan
The best tool ever. I started using it for product mapping in order to redirect a large number of old addresses to new ones in stores where, for example, there was an engine change. It works great.
Amazing features as always! Is there currently a way to create custom groupings in SF to compare different sections of your site to each other (ex: category vs product pages). If not, is it by chance in the works? ;-)
Why Small Update – Version 16.6 missing in this page https://www.screamingfrog.co.uk/seo-spider/release-history/ ?
I’ve started using v16.7 on Linux Parrot OS. It’s fantastic and it works perfectly! Thanks :)
Great update. The new tools and filters surrounding javascript rendering are a huge help for websites built on React.