Screaming Frog SEO Spider Update – Version 18.0
Dan Sharp
Posted 5 December, 2022 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 18.0
We’re excited to announce Screaming Frog SEO Spider version 18.0, codenamed internally as ‘Willow’.
We’ve been busy working on one major feature we wanted to release pre to the Christmas holidays, and a variety of smaller, yet much-requested features and improvements.
Let’s take a look at what’s new in our latest update.
1) GA4 Integration
It’s taken a little while, but like most SEOs, we’ve finally come to terms that we’ll have to actually switch to GA4. You’re now able to (begrudgingly) connect to GA4 and pull in analytics data in a crawl via their new API.
Connect via ‘Config > API Access > GA4’, select from 65 available metrics, and adjust the date and dimensions.

Similar to the existing UA integration, data will quickly appear under the ‘Analytics’ and Internal tabs when you start crawling in real-time.

You can apply ‘filter’ dimensions like in the GA UI, including first user, or session channel grouping with dimension values, such as ‘organic search’ to refine to a specific channel.
If there are any other dimensions or filters you’d like to see supported, then do let us know.
2) Parse PDFs
PDFs are not the sexiest thing in the world, but due to the number of corporates and educational institutions that have requested this over the years, we felt compelled to provide support parsing them. The SEO Spider will now crawl PDFs, discover links within them and show the document title as the page title.
This means users can check to see whether links within PDFs are functioning as expected and issues like broken links will be reported in the usual way in the Response Codes tab. The outlinks tab will be populated, and include details such as response codes, anchor text and even what page of the PDF a link is on.

You can also choose to ‘Extract PDF Properties’ and ‘Store PDF’ under ‘Config > Spider > Extraction’ and the PDF subject, author, created and modified dates, page count and word count will be stored.
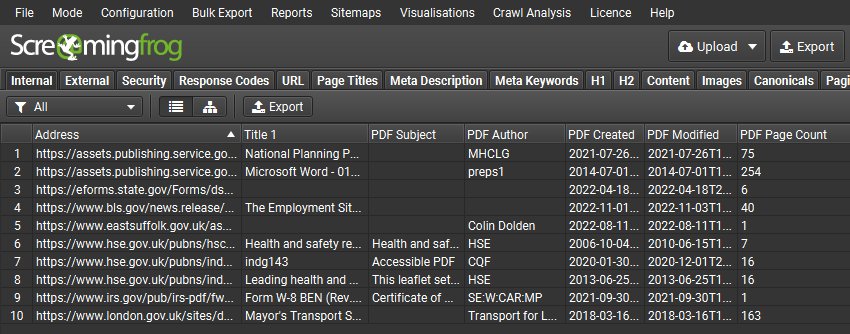
PDFs can be bulk saved and exported via ‘Bulk Export > Web > All PDF Documents’.
If you’re interested in how search engines crawl and index PDFs, check out a couple of tweets where we shared some insights from internal experiments for both Google and Bing.
3) Validation Tab
There’s a new Validation tab, which performs some basic best practice validations that can impact crawlers when crawling and indexing. This isn’t W3C HTML validation which is a little too strict, the aim of this tab is to identify issues that can impact search bots from being able to parse and understand a page reliably.
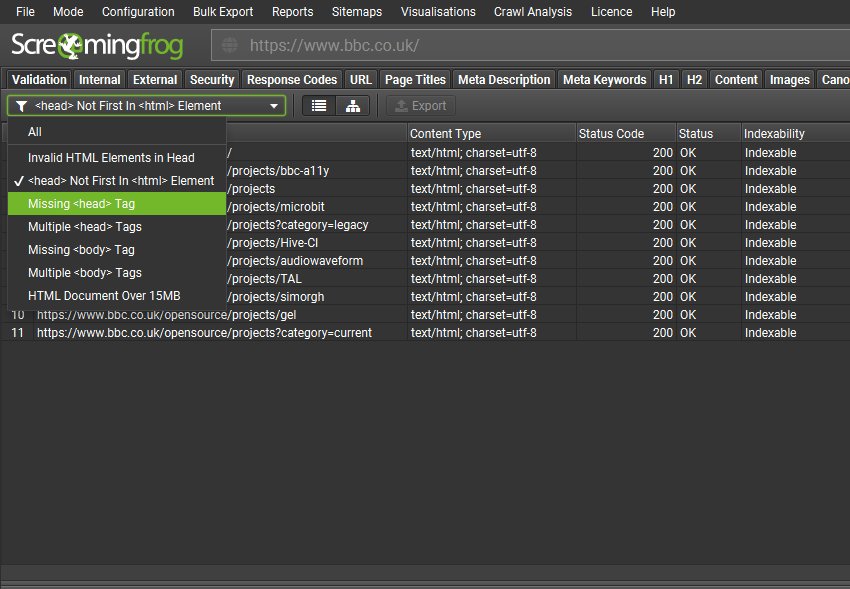
Most SEOs know about invalid HTML elements in the head causing it to close early, but there are other interesting fix-ups and quirks that both browsers like Chrome (and subsequently) Google do if it sees a non-head element prior to the head in the HTML (it creates its own blank head), or if there are multiple, or missing HTML elements etc.
The new filters include –
- Invalid HTML Elements In <head> – Pages with invalid HTML elements within the <head>. When an invalid element is used in the <head>, Google assumes the end of the <head> element and ignores any elements that appear after the invalid element. This means critical <head> elements that appear after the invalid element will not be seen. The <head> element as per the HTML standard is reserved for title, meta, link, script, style, base, noscript and template elements only.
- <head> Not First In <html> Element – Pages with an HTML element that proceed the <head> element in the HTML. The <head> should be the first element in the <html> element. Browsers and Googlebot will automatically generate a <head> element if it’s not first in the HTML. While ideally <head> elements would be in the <head>, if a valid <head> element is first in the <html> it will be considered as part of the generated <head>. However, if non <head> elements such as <p>, <body>, <img> etc are used before the intended <head> element and its metadata, then Google assumes the end of the <head> element. This means the intended <head> element and its metadata may only be seen in the <body> and ignored.
- Missing <head> Tag – Pages missing a <head> element within the HTML. The <head> element is a container for metadata about the page, that’s placed between the <html> and <body> tag. Metadata is used to define the page title, character set, styles, scripts, viewport and other data that are critical to the page. Browsers and Googlebot will automatically generate a <head> element if it’s omitted in the markup, however it may not contain meaningful metadata for the page and this should not be relied upon.
- Multiple <head> Tags – Pages with multiple <head> elements in the HTML. There should only be one <head> element in the HTML which contains all critical metadata for the document. Browsers and Googlebot will combine metadata from subsequent <head> elements if they are both before the <body>, however, this should not be relied upon and is open to potential mix-ups. Any <head> tags after the <body> starts will be ignored.
- Missing <body> Tag – Pages missing a <body> element within the HTML. The <body> element contains all the content of a page, including links, headings, paragraphs, images and more. There should be one <body> element in the HTML of the page. Browsers and Googlebot will automatically generate a <body> element if it’s omitted in the markup, however, this should not be relied upon.
- Multiple <body> Tags – Pages with multiple <body> elements in the HTML. There should only be one <body> element in the HTML which contains all content for the document. Browsers and Googlebot will try to combine content from subsequent <body> elements, however, this should not be relied upon and is open to potential mix-ups.
- HTML Document Over 15MB – Pages which are over 15MB in document size. This is important as Googlebot limit their crawling and indexing to the first 15MB of an HTML file or supported text-based file. This size does not include resources referenced in the HTML such as images, videos, CSS, and JavaScript that are fetched separately. Google only considers the first 15MB of the file for indexing and stops crawling afterwards. The file size limit is applied on the uncompressed data. The median size of an HTML file is about 30 kilobytes (KB), so pages are highly unlikely to reach this limit.
We plan on extending our validation checks and filters over time.
4) In-App Updates
Every time we release an update there will always be one or two users that remind us that they have to painstakingly visit our website, and click a button to download and install the new version.
WHY do we have to put them through this torture?
The simple answer is that historically we’ve thought it wasn’t a big deal and it’s a bit of a boring enhancement to prioritise over so many other super cool features we could build. With that said, we do listen to our users, so we went ahead and prioritised the boring-but-useful feature.
You will now be alerted in-app when there’s a new version available, which will have already silently downloaded in the background. You can then install in a few clicks.
We’re planning on switching our installer, so the number of clicks required to install and auto-restart will be implemented soon, too. We can barely contain our excitement.
5) Authentication for Scheduling / CLI
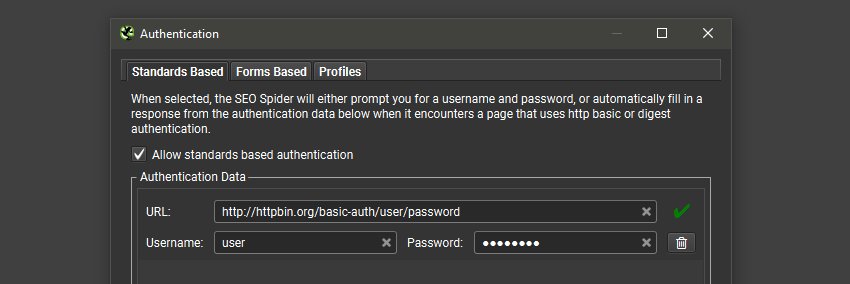
Previously, the only way to authenticate via scheduling or the CLI was to supply an ‘Authorization’ HTTP header with a username and password via the HTTP header config, which worked for standards based authentication – rather than web forms.
We’ve now made this much simpler, and not just for basic or digest authentication, but web form authentication as well. In ‘Config > Authentication’, you can now provide the username and password for any standards based authentication, which will be remembered so you only need to provide it once.
You can also login as usual via ‘Forms Based’ authentication and the cookies will be stored.
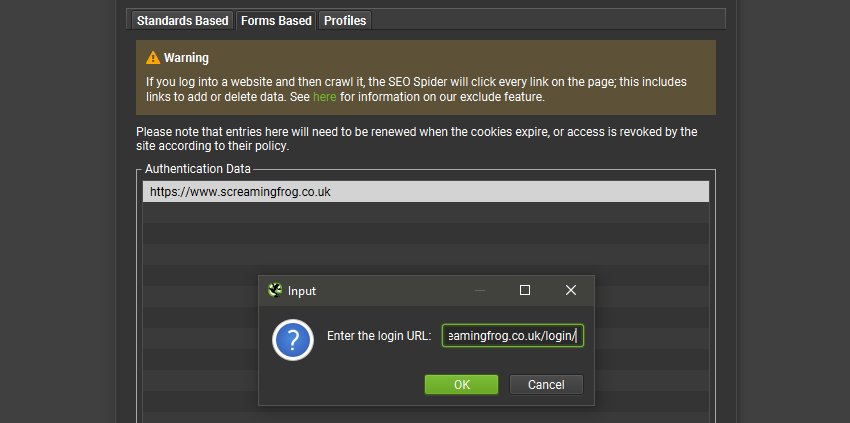
When you have provided the relevant details or logged in, you can visit the new ‘Profiles’ tab, and export a new .seospiderauthconfig file.
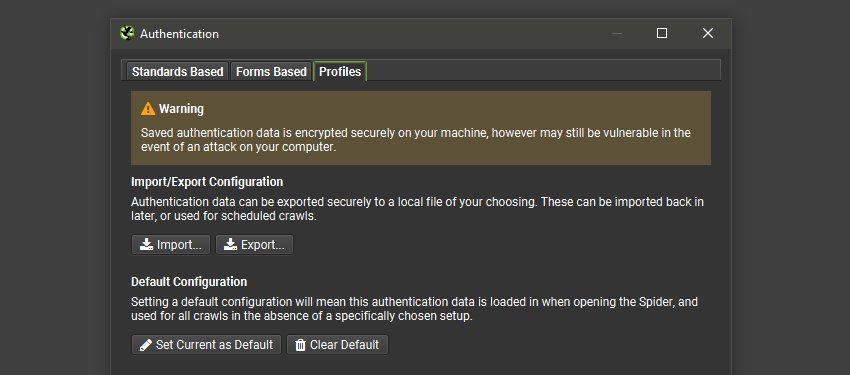
This file which has saved authentication for both standards and forms based authentication can then be supplied in scheduling, or the CLI.
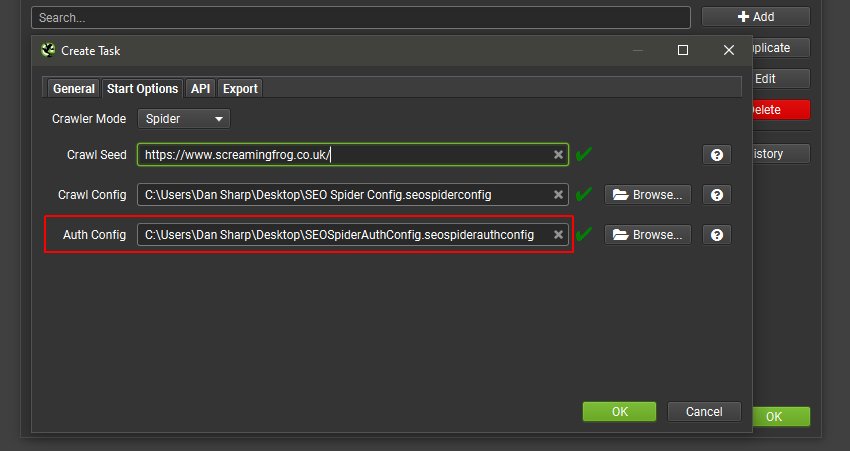
This means for scheduled or automated crawls the SEO Spider can login to not just standards based authentication, but web forms where feasible as well.
6) New Filters & Issues
There’s a variety of new filters and issues available across existing tabs that help better filter data, or communicate issues discovered.
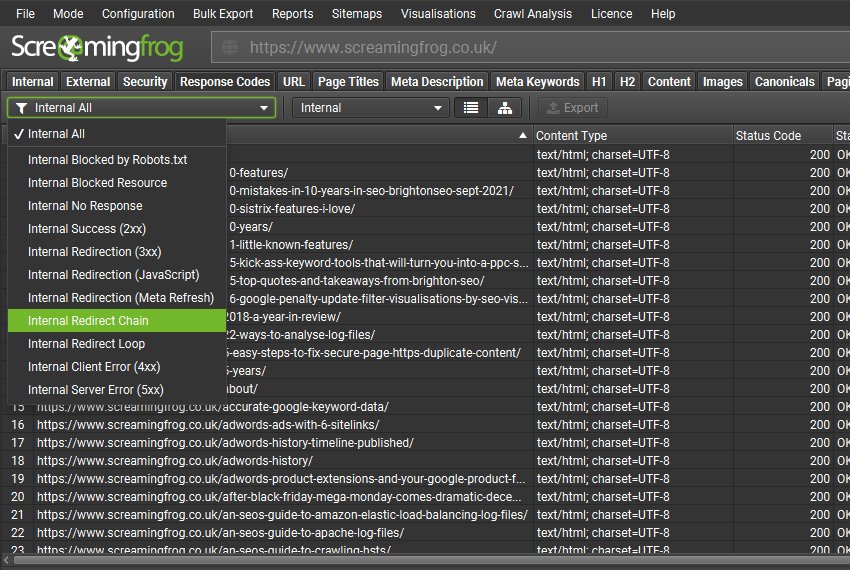
Many of these were already available either via another filter, or from an existing report like ‘Redirect Chains’. However, they now have their own dedicated filter and issue in the UI, to help raise awareness. These include –
- ‘Response Codes > Redirect Chains’ – Internal URLs that redirect to another URL, which also then redirects. This can occur multiple times in a row, each redirect is referred to as a ‘hop’. Full redirect chains can be viewed and exported via ‘Reports > Redirects > Redirect Chains’.
- ‘Response Codes > Redirect Loop’ – Internal URLs that redirect to another URL, which also then redirects. This can occur multiple times in a row, each redirect is referred to as a ‘hop’. This filter will only populate if a URL redirects to a previous URL within the redirect chain. Redirect chains with a loop can be viewed and exported via ‘Reports > Redirects > Redirect Chains’ with the ‘Loop’ column filtered to ‘True’.
- ‘Images > Background Images’ – CSS background and dynamically loaded images discovered across the website, which should be used for non-critical and decorative purposes. Background images are not typically indexed by Google and browsers do not provide alt attributes or text on background images to assistive technology.
- ‘Canonicals > Multiple Conflicting’ – Pages with multiple canonicals set for a URL that have different URLs specified (via either multiple link elements, HTTP header, or both combined). This can lead to unpredictability, as there should only be a single canonical URL set by a single implementation (link element, or HTTP header) for a page.
- ‘Canonicals > Canonical Is Relative’ – Pages that have a relative rather than absolute rel=”canonical” link tag. While the tag, like many HTML tags, accepts both relative and absolute URLs, it’s easy to make subtle mistakes with relative paths that could cause indexing-related issues.
- ‘Canonicals > Unlinked’ – URLs that are only discoverable via rel=”canonical” and are not linked-to via hyperlinks on the website. This might be a sign of a problem with internal linking, or the URLs contained in the canonical.
- ‘Links > Non-Indexable Page Inlinks Only’ – Indexable pages that are only linked-to from pages that are non-indexable, which includes noindex, canonicalised or robots.txt disallowed pages. Pages with noindex and links from them will initially be crawled, but noindex pages will be removed from the index and be crawled less over time. Links from these pages may also be crawled less and it has been debated by Googlers whether links will continue to be counted at all. Links from canonicalised pages can be crawled initially, but PageRank may not flow as expected if indexing and link signals are passed to another page as indicated in the canonical. This may impact discovery and ranking. Robots.txt pages can’t be crawled, so links from these pages will not be seen.
7) Flesch Readability Scores
Flesch readability scores are now calculated and included within the ‘Content‘ tab with new filters for ‘Readability Difficult’ and Readability Very Difficult’.
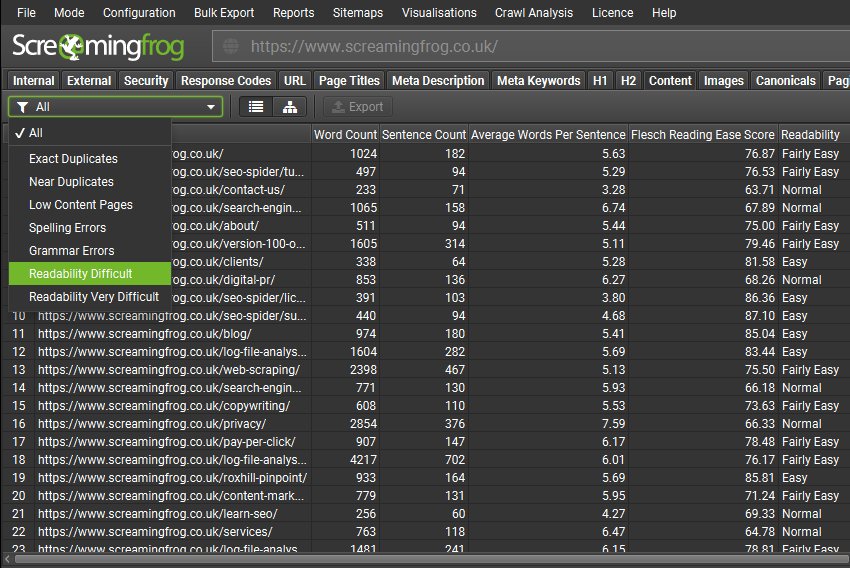
Please note, the readability scores are suited for English language, and we may provide support to additional languages or alternative readability scores for other languages in the future.
Readability scores can be disabled under ‘Config > Spider > Extraction’.
Other Updates
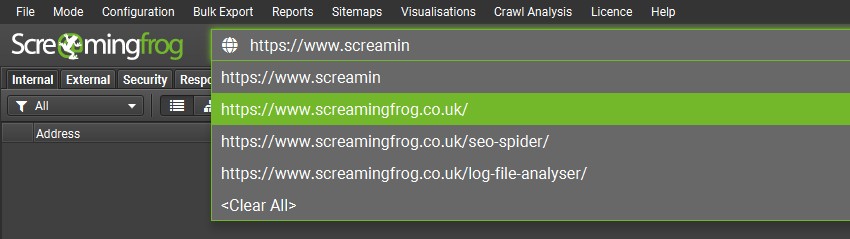
Auto Complete URL Bar
The URL bar will now show suggested URLs to enter as you type based upon previous URL bar history, which a user can quickly select to help save precious seconds.
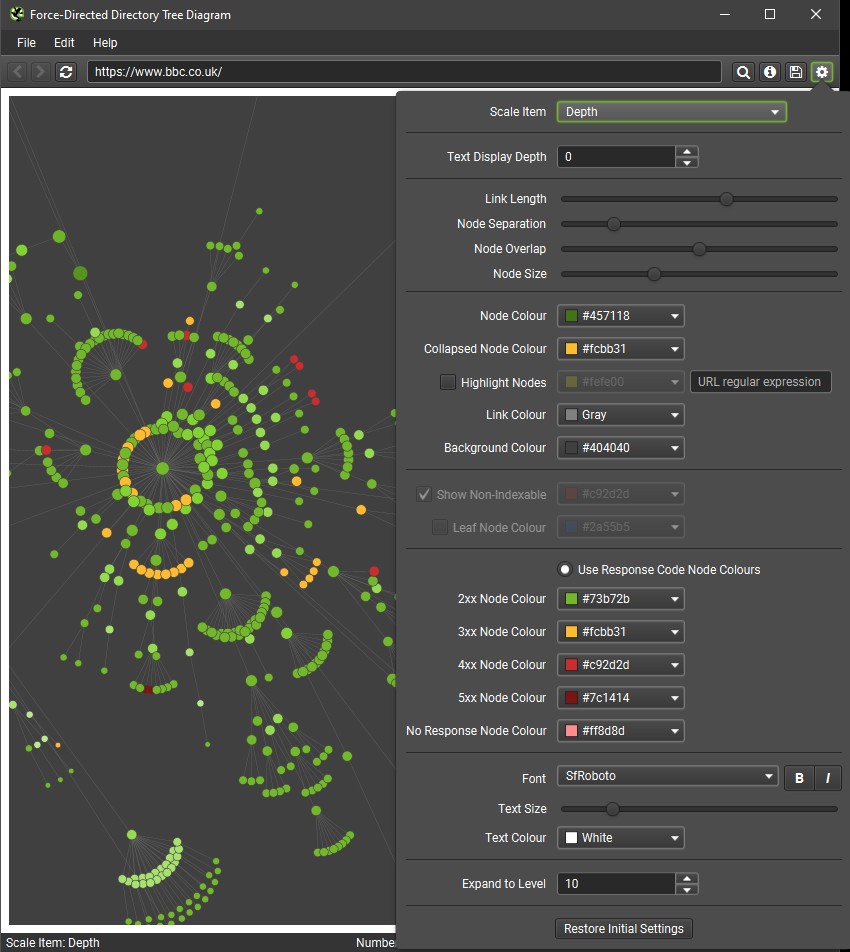
Response Code Colours for Visualisations
You’re now able to select to ‘Use Response Code Node Colours’ in crawl visualisations.
This means nodes for no responses, 2XX, 3XX, 4XX and 5XX buckets will be coloured individually, to help users spot issues related to responses more effectively.
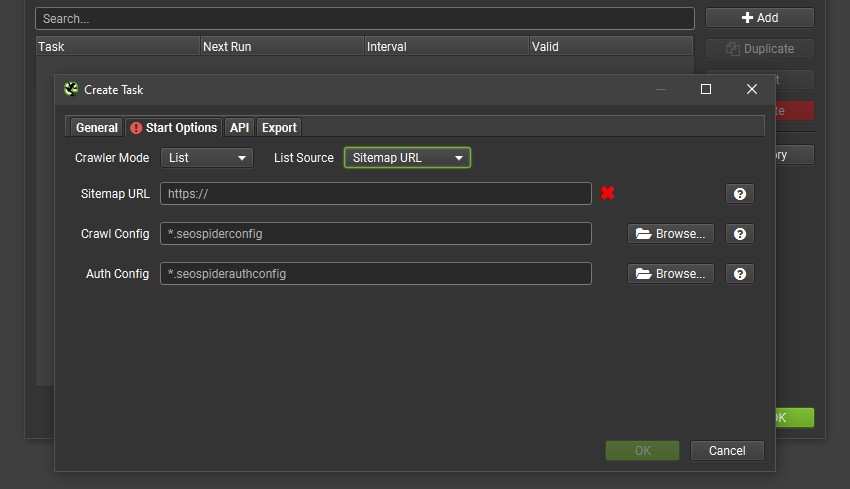
XML Sitemap Source In Scheduling
You can now choose an XML Sitemap URL as the source in scheduling and via the CL in list mode like the regular UI.
Version 18.0 also includes a number of smaller updates and bug fixes.
- 3 million Google rich result feature updates for structured data validation.
- The Apache-Common-Text file has been updated > 1.10.0 for vulnerability CVE-2022-42889.
Thanks again to everyone for their continued support, feature requests and feedback. Please let us know if you experience any issues with version 18.0 of the SEO Spider via our support.
Small Update – Version 18.1 Released 14th December 2022
We have just released a small update to version 18.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Added Education QA & Audit Google features.
- Add support for video/mp4 mimetype.
- SERP exports now import and export in users langauge.
- Index out of bounds shown for URLs with invalid php tags.
- Fix issue with JavaScript Rendering on Fedora triggering keyring dialog.
- Fix issue with some exported PDFs not opening.
- Fix ::before being shown in headings.
- Fix various crashes, including PDFs links with spaces and newlines, auto saving of config and more.
Small Update – Version 18.2 Released 13th February 2023
We have just released a small update to version 18.2 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Add quotas to GA4 UI.
- Renable spell check for Apple Silicon macs for some languages that were previously disabled.
- Allow scheduled crawls to run forever and run on battery.
- Update structured data with recent smaller changes to standard.
- Fix GA4 issues with not retriving more than 10k results.
- Fix issue exporting to Google Sheets when overwriting and the sheet has been removed/replaced.
- Fix various issues with HTML validation.
- Fix font issues affecting some customers on Windows.
- Fix occasional issue with connecting to Google Services.
- Fix PDF link extraction only use absolute URLs.
- Fix URL encoding issue preventing some pages loading in JavaScript rendering.
- Fix issues with blank cells in Excel not being regarded as black by the ISBLANK funtion.
- Fix broken icon in ‘Spider > Configuration > Advanced’.
- Fix missing translations for all languages.
- Fix issue with sorting readability column.
- Fix issue with exporting issues reports.
- Fix parsing issues caused by pseduo-elements.
- Fix crash / pop up of developer tools dialog connecting to GA4 on macOS.
- Fix crash sorting scheduler UI.
Small Update – Version 18.3 Released 8th March 2023
We have just released a small update to version 18.3 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Auto retry on various timeout types when writing to Google Sheets.
- Improve performance of the ‘Link Analysis’ phase of ‘Crawl Analysis’.
- Update JavaScript mime type for ‘Security > Bad Content Type’ validation.
- Switched GA4 to use ‘LandingPagePlusQueryString’ rather than ‘Landing Page’ as the dimension, as Google changed behaviour.
- Fix crash connecting to AHREFs with an invalid key.
- Fix crash loading graphs.
- Fix crash cancelling export of XML sitesmaps.
- Fix issue with display of GA4 API usage stats.
- Fix crash removing URL.
- Fix crash editing scheduled task.
- Fix issue with rendering failed due to OPTIONS request.
Small Update – Version 18.4 Released 16th March 2023
We have just released a small update to version 18.4 of the SEO Spider. This release contains a single update –
- Fix the PSI integration, after the API was updated with breaking changes without any advance warning. The PSI release notes have now been helpfully updated, a couple of days after the change.
Apologies to everyone for two releases in such quick succession.
Small Update – Version 18.5 Released 26th April 2023
We have just released a small update to version 18.5 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Fix issue with GSC account verification in scheduling
- Fix JS rendering issue around PDFs.
- Fix crawl path report to work with orphaned URLs.
- Fix ‘Security > Bad Content Type’ filter to only check know file extensions.
- Fix issue with invalid GSC data when loading old crawls/config.
- Fix issue showing Directory Tree Graph in non English languages.
- Fix robots.txt to parse all text content types.
- Fix crash loading in PSI data from old crawls.
- Fix crash parsing structure data.
- Fix crash editing scheduled tasks on Windows.






great update mate
Amazing! I really love Site Graph, the update I prefer. Fantastic!
Thanks for the in-app updates; indeed a boring but-useful feature!
Another phenomenal update to my favorite SEO app, thanks Screaming Frog Team!!
Spectacular. GA4 has finally been hooked.
This is a significant update, and users have expected all the features mentioned above for a long time. I know Screaming Frog is mainly dedicated to finding technical problems with a particular website, which is not so important to you guys for reporting purposes. But all SEO companies nowadays mostly use it for their client websites, and they often have to tell their clients what they have found and what they want to fix. But your external reporting system is not standardized. I know you have a reporting system using Data Studio, but it is not up-to-date. Especially in the last two updates, you have added various functionalities, but using those functionalities, our findings are not reflected in the Data Studio report system.
Also, another expected feature is to calculate the difference in traffic, sessions, impressions and clicks between two time periods using a search console and analytics data. I hope you plan to add these features in the next update to enrich your software.
great update thanks. The best seo tool!
I love the hilarious nuggets: “3 million Google rich result feature updates for structured data validation.” and “…install and auto-restart will be implemented soon, too. We can barely contain our excitement.”
Thank you for this update. Screaming Frog is one of my favourite seo tools :)
Thanks for adding more features, like PDF extraction.
Really love your tool!
I am hooked to it;)
Cheers from de Betuwe
great update thanks.
No words! Another excellent update with important improvements that will undoubtedly help me understand a little better everything that happens on my website. Thanks!
Wow, thanx for ga4 integration! Great update!
Great update, as usual, but it’s getting a little bit too complicated with even more tabs like “Validation”. I love to have more data to work with, but maybe in the next version it’s good idea to do some UX work on those tabs(don’t cut them, just reorganise them).
I hope you can use the feedback :)
No that you point it, it was a big deal to download the updates, but I really welcome the auto-update feature. Thank you all for saving my time! :)
Thanks for updates
Great update to ga4 integration & Validation Tab
Yay – we can finally start to pull in GA4 for some of our clients. We’re still running GA3 and GA4 together on some sites, but anxious to see what all can be pulled now in the GA4 release.
Well done guys!
Many nice features. Looking forward to dig into this.
But all old crawls are gone after backup. The “crawls” option in File-menu is gone.
Hi Ture,
I replied to you on support. I suspect you may have uninstalled before installing, but do reply to our ticket.
You can get back the crawls menu by switching to database storage mode (Config > System > Storage Mode).
Cheers.
Dan
Please, set the “order” and “width” of the columns can be saved in the “Default Configuration”
SEO Spider’s been a great friend through the years. Thank you! But for the latest versions I really would appreciate if I could stop it from following links in PDF files. I don’t need this all the time and it’s making a lot of extra work. Perhaps a config box I could uncheck?
Hi Frank,
Cheers for the kind comments!
We could add an option to make this configurable, thanks for the suggestion.
In the meantime, you can always block PDFs from being crawled? (‘Config > Exclude’).
Cheers.
Dan
Thank you very much for the GA4 integration – just in time!
I have one question: When I try to crawl a Javascript Website (configuration Spider > Rendering: JS) and I want to include just one website directory (include > “website/.*”) it doesn’t work. Anybody any idea what I am doing wrong?
Hi Enna,
Good to hear! Yeah, the include impacts rendering as well.
So all resources need to be accessible to be able to render the page. So make sure you include resources in the include, as well as the page URL paths you want to crawl.
Then it will be able to render the page, and crawl the pages you want.
Cheers.
Dan
I see!! Thank you!
hi, guys! I like screaming frog, many years used.
I have a two ideas:
1) Extraction or Search data after crawling.
Example, i crawled 100k page, saving html soerce code but forgot to add data extraction fields and now I have to crawled the web site all over again :(
You can add functionality in Crawl Analysis
https://prnt.sc/9ho9Vekzh5Ky.
A lot of time will be saved
2) Hot add new pages without updating the data table https://prnt.sc/t4xfDujz26Ej.
Example, the first session scanned 10k pages, but needed to add 5k more to the current crawling as if to continue scanning…
Hi Oleg,
Thanks for the suggestions – we’ve got both of these already on our ‘todo’, so I’ll add in votes for you. This helps us prioritise what to work on next!
Cheers.
Dan
Cheers for the new update mate, I really like the pdf extraction feature. Amazing SEO tool tho!
I am always a fan of screaming frog such a nice crawler that can massively help with SEO work. I just face one problem when I crawled a website that has Yoast plugin it provides an issue of duplicate titles I don’t know how is this an error as one is site title and the other is of yoast as yoast basically replaces the web page title with the Yoast title. Is it any issue I should fix?
Thanks, Farhan!
Sounds like multiple titles. Pop through the URL example to us via support if you’d like us to comment – https://www.screamingfrog.co.uk/seo-spider/support/
Cheers.
Dan
Sure, I will!
Absolutely loving the Flesch Readability Scores. Which additional languages will you prioritise for the near future?
Great update, thanks! One of the best SEO tools!
What an impressive update. Especially the Flesch Readability Score possibility is awesome. The “Code Colours for Visualisations” will also be quite useful for the next projects. Especially for big e-commerce sites, very helpful for site audits. Thanks to the Screamingfrog team for regularly updating this powerful tool.
A really great SEO tool, thanks for the update. Very helpful and on point.
woooooooooooow!!!
Great update, thanks!
One of the best SEO tools!
Thanks for sharing and for the great update!
We love using Screaming Frog!
Espectacular como siempre! Gran trabajo!
Still waiting for that sound alert for when the software ends crawling :P
thanks!!
Thanks Guys ! I had an issues when exporting a big e-commerce site structure and it has been fixed in the 18.4 beta 1. Hat off to the support crew (I’ve been in contact with Richard, Aaron, and Liam so far) for the amazing service they’re providing !
I love the thought and effort put into the maintenance of this crucial app. Thank you for the updates!
Our site is very small but thanks to the fact that the tool offers a FREE version, we are able to check it all. Thank you
Nice features. Thanks for the cool updates.
Thank you so much for the latest version updates to Screaming Frog!
As a user of the software, I really appreciate the continued improvements and new features that you’ve added.
Hello Screaming Frog team,
Can you please add option to set the amount of the pages that are included in the sitemap? Sometimes we are working with the new client on post production and we need to show them how sitemap works and it will be great is there a option to set for example 25k URLs in sitemap.
I would like to express my concerns regarding the frequency of bug-fix updates from your company. As a crucial resource for many SEO professionals, it is disheartening to see that 59.52% or 60% of all updates, according to your release history (https://www.screamingfrog.co.uk/seo-spider/release-history/), are dedicated to addressing bugs rather than introducing new features.
It appears that there may be issues with your software development lifecycle, particularly in the areas of regression testing and end-to-end automation testing, which should identify the issues pre-release so your development team can resolve these bugs before new updates are released to the public. I suggest reevaluating your development process and considering a more measured approach to releasing updates.
By taking the necessary time to ensure the quality and reliability of your tool, you can greatly improve the user experience for your community of devoted customers.
Hi Daine,
Thanks for your comment.
It’s actually due to the SEO Spider being such a crucial resource for many SEOs that we focus so much around stability and providing bug fix releases as quickly as possible.
It’s a shame that releasing fixes quickly for users is looked upon negatively, although I realise updating can be a pain at times. We’ve recently added an auto update feature to reduce the inconvenience of applying an update.
It’s far from a sign of issues with our dev lifecycle, I’d be far more concerned by those that don’t have regular releases… ;-)
We have exhaustive testing in place already, but as is the nature with software – there will always be some bugs.
We just squash these far more openly, and quickly than the majority of software companies. That’s partly what has helped us provide such a great user experience and build a devoted community of SEOs.
Cheers.
Dan
A great tool you have made!
Are you thinking of adding Serpstat API in the future?
Great tool and great update ! Keep up the great work .
Great update. Thanks for the extra validation filters and, of course, the GA4 integration (goodbye UA!). Also finding that updating the software is a lot better now you’ve added it in-app versus the website download.
Great update, Dan!
Exciting news about Screaming Frog SEO Spider version 18.0! The GA4 integration (goodbye UA!) and PDF crawling capabilities are impressive additions. The new Validation tab helps ensure proper indexing, and the in-app updates save time. The simplified authentication for scheduling and CLI is a welcome improvement. Overall, fantastic work!
Cheers,
Great update! The GA4 and the validation tab are impressive additions
Absolutely love it! Use it daily for my projects and I feel like can’t live without it. Sometimes when crawling I experience crashes, but that’s from my old pc. When I replaced it, everything came into place :)
Great update, thanks!
Super, merci pour la MAJ ! Tool toujours au top !