Screaming Frog SEO Spider Update – Version 3.0
Dan Sharp
Posted 11 February, 2015 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 3.0
I’m delighted to announce version 3.0 of the Screaming Frog SEO Spider, named internally as ‘walkies’.
This update includes a new way of analysing a crawl, additional sitemap features and insecure content reporting, which will help with all those HTTPS migrations! As always thanks to everyone for their continued support, feedback and suggestions for the tool.
So, let’s get straight to it. The new features in version 3.0 of the tool include the following –
1) Tree View
You can now switch from the usual ‘list view’ of a crawl, to a more traditional directory ‘tree view’ format, while still mantaining the granular detail of each URL crawled you see in the standard list view.

This additional view will hopefully help provide an alternative perspective when analysing a website’s architecture.
The SEO Spider doesn’t crawl this way natively, so switching to ‘tree view’ from ‘list view’ will take a little time to build, & you may see a progress bar on larger crawls for instance. This has been requested as a feature for quite sometime, so thanks to all for their feedback.
2) Insecure Content Report
We have introduced a ‘protocol’ tab, to allow you to easily filter and analyse by secure and non secure URLs at a glance (as well as other protocols potentially in the future). As an extension to this, there’s also a new ‘insecure content’ report which will show any HTTPS URLs which have insecure elements on them. It’s very easy to miss some insecure content, which often only get picked up on go live in a browser.

So if you’re working on HTTP to HTTPS migrations, this should be particularly useful. This report will identify any secure pages, which link out to insecure content, such as internal HTTP links, images, JS, CSS, external CDN’s, social profiles etc.

Here’s a quick example of how a report might look (with insecure images in this case) –

Please note, this report will only pick up on items we crawl, rather than everything rendered in a browser.
3) Image Sitemaps & Updated XML Sitemap Features
You can now add images to your XML sitemap or create an image sitemap file.
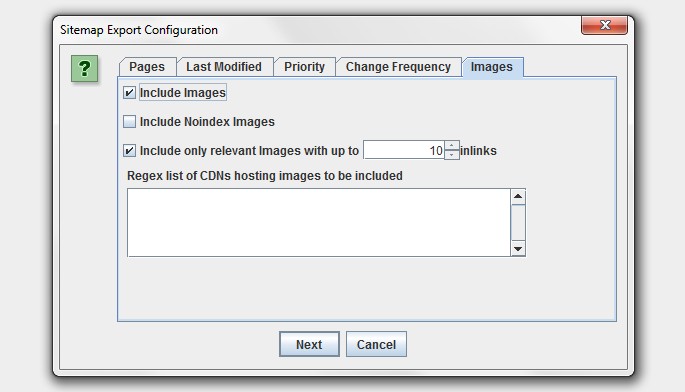
As shown in the screenshot above, you now have the ability to include images which appear under the ‘internal’ tab from a normal crawl, or images which sit on a CDN (and appear under the ‘external’ tab).
Typically you don’t want to include images like logos in an image sitemap, so you can also choose to only include images with a certain number of source attribute references. To help with this, we have introduced a new column in the ‘images’ tab which shows how many times an image is referenced (IMG Inlinks).
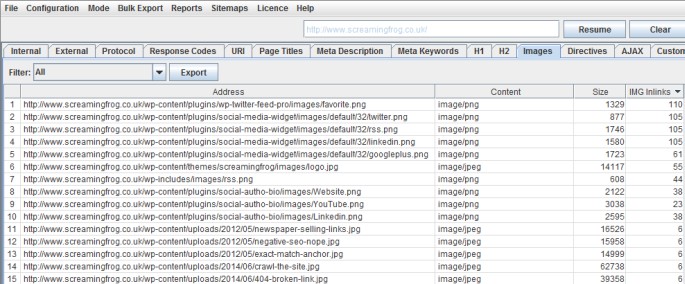
This is a nice easy way to exclude logos or social media icons, which are often linked to sitewide for example. You can also right-click and ‘remove’ any images or URLs you don’t want to include obviously too! The ‘IMG Inlinks’ is also very useful when viewing images with missing alt text, as you may wish to ignore social profiles without them etc.
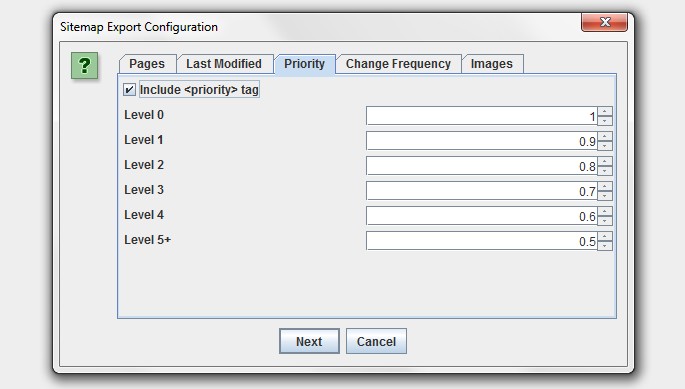
There’s now also plenty more options when generating an XML sitemap. You can choose whether to include ‘noindex’, canonicalised, paginated or PDFs in the sitemap for example. Plus you now also have greater control over the lastmod, priority and change frequency.
4) Paste URLs In List Mode
To help save time, you can now paste URLs directly into the SEO Spider in ‘list’ mode, or enter URLs manually (into a window) and upload a file like normal.
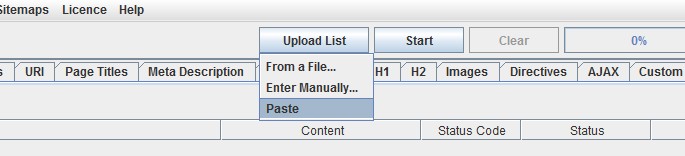
Hopefully these additional options will be useful and help save time, particularly when you don’t want to save a file first to upload.
5) Improved Bulk Exporting
We plan on making the exporting function entirely customisable, but for now bulk exporting has been improved so you can export all inlinks (or ‘source’ links) to the custom filter and directives, such as ‘noindex’ or ‘canonicalised’ pages if you wish to analyse crawl efficiency for example.
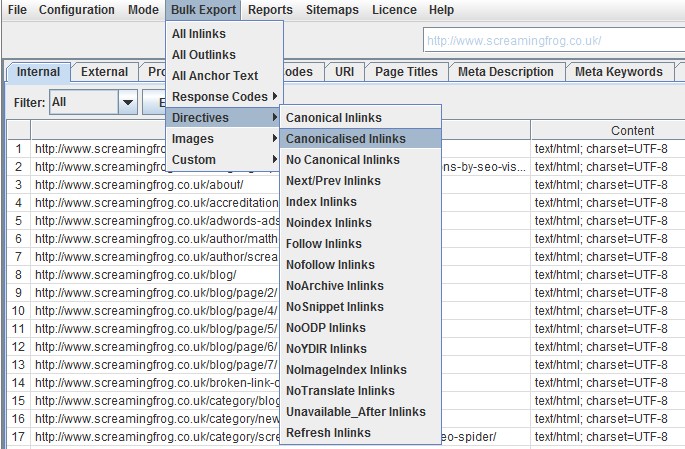
Thanks to the awesome Aleyda for this suggestion.
6) Windows Look & Feel
There’s a new ‘user interface’ configuration for Windows only, that allows users to enable ‘Windows look and feel’. This will then adhere to the scaling settings a user has, which can be useful for some newer systems with very high resolutions.
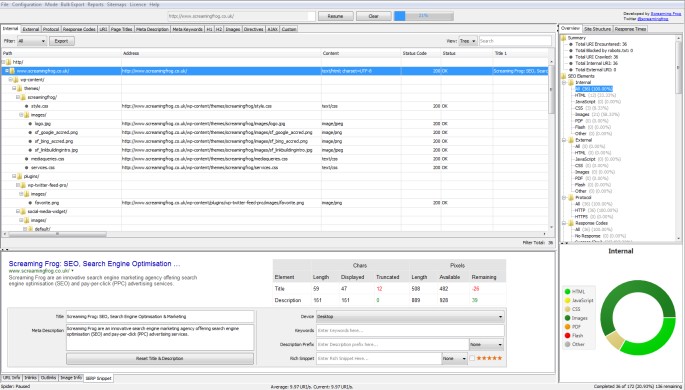
It’s also rather colourful in ‘tree view’.
Other Updates
We have also performed other updates in the version 3.0 of the Screaming Frog SEO Spider, which include the following –
- You can now view the ‘Last-Modified’ header response within a column in the ‘Internal’ tab. This can be helpful for tracking down new, old, or pages within a certain date range. ‘Response time’ of URLs has also been moved into the internal tab as well (which used to just be in the ‘Response Codes’ tab, thanks to RaphSEO for that one).
- The parser has been updated so it’s less strict about the validity of HTML mark-up. For example, in the past if you had invalid HTML mark-up in the HEAD, page titles, meta descriptions or word count may not always be collected. Now the SEO Spider will simply ignore it and collect the content of elements regardless.
- There’s now a ‘mobile-friendly’ entry in the description prefix dropdown menu of the SERP panel. From our testing, these are not used within the description truncation calculations by Google (so you have the same amount of space for characters as pre there introduction).
- We now read the contents of robots.txt files only if the response code is 200 OK. Previously we read the contents irrespective of the response code.
- Loading of large crawl files has been optimised, so this should be much quicker.
- We now remove ‘tabs’ from links, just like Google do (again, as per internal testing). So if a link on a page contains the tab character, it will be removed.
- We have formatted numbers displayed in filter total and progress at the bottom. This is useful when crawling at scale! For example, you will see 500,000 rather than 500000.
- The number of rows in the filter drop down have been increased, so users don’t have to scroll.
- The default response timeout has been increased from 10 secs to 20 secs, as there appears to be plenty of slow responding websites still out there unfortunately!
- The lower window pane cells are now individually selectable, like the main window pane.
- The ‘search’ button next to the search field has been removed, as it was fairly redundant as you can just press ‘Enter’ to search.
- There’s been a few updates and improvements to the GUI that you may notice.
- (Updated) – The ‘Overview Report’ now also contains the data you can see in the right hand window pane ‘Response Times’ tab. Thanks to Nate Plaunt and I believe a couple of others who also made the suggestion (apologies for forgetting anyone).
We have also fixed a number of reported bugs, which include –
- Fixed a bug with ‘Depth Stats’, where the percentage didn’t always add up to 100%.
- Fixed a bug when crawling from the domain root (without www.) and the ‘crawl all subdomains’ configuration ticked, which caused all external domains to be treated as internal.
- Fixed a bug with inconsistent URL encoding. The UI now always shows the non URL encoded version of a URL. If a URL is linked to both encoded and unencoded, we’ll now only show the URL once.
- Fixed a crash in Configuration->URL Rewriting->Regex Replace, as reported by a couple of users.
- Fixed a crash for a bound checking issue, as reported by Ahmed Khalifa.
- Fixed a bug where unchecking the ‘Check External’ tickbox still checks external links, that are not HTML anchors (so still checks images, CSS etc).
- Fixed a bug where the leading international character was stripped out from SERP title preview.
- Fixed a bug when crawling links which contained a new line. Google removes and ignores them, so we do now as well.
- Fixed a bug where AJAX URLs are UTF-16 encoded using a BOM. We now derive encoding from a BOM, if it’s present.
Hopefully that covers everything! We hope the new features are helpful and we expect our next update to be significantly larger. If you have any problems with the latest release, do just pop through the details to support, and as always, we welcome any feedback or suggestions.
You can download the SEO Spider 3.0 now. Thanks to everyone for their awesome support.
Small Update – Version 3.1 Released 24th February 2015
We have just released another small update to version 3.1 of the Screaming Frog SEO Spider. There’s a couple of tweaks and some bug fixes from the update, which include –
- The insecure content report has been improved to also include canonicals. So if you have a secure HTTPS URL, with an insecure HTTP canonical, these will be identified within the ‘insecure content’ report now, as well.
- Increased the size of the URL input field by 100px in Spider mode.
- Fixed a bug with ‘Respect Canonicals’ option, not respecting HTTP Header Canonicals.
- Fixed a bug with ‘Crawl Canonicals’ not crawling HTTP Header Canonicals.
- Fixed a crash on Windows, when users try to use the ‘Windows look and feel’, but have an older version of Java, without JavaFX.
- Fixed a bug where we were not respecting ‘nofollow’ directives in the X-Robots-Tag Header, as reported by Merlinox.
- Fixed a bug with the Sitemaps file writing ‘priorities’ attribute with a comma, rather than a full stop, due to user locale.
- Updated the progress percentage & average response time to format according to default locale.
- Fixed a crash caused by parsing pages with an embed tag containing an invalid src attribute, eg embed src=”about:blank”.
Small Update – Version 3.2 Released 4th March 2015
We have just released another small update to version 3.2 of the Screaming Frog SEO Spider. Again, this is just a smaller update with feedback from users and includes –
- Updated the insecure content report to report insecure HTTP content on HTTPS URLs more accurately.
- Fixed a bug causing a crash during a right click ‘re-spider’ of URLs reported by a few users.
- Fixed slow loading of CSV files.
- Fixed a bug reported with double URL encoding.
Small Update – Version 3.3 Released 23rd March 2015
We have just released another small update to version 3.3 of the Screaming Frog SEO Spider. Similar to the above, this is just a small release with a few updates, which include –
- Fixed a relative link bug for URLs.
- Updated the right click options for ‘Show Other Domains On This IP’, ‘Check Index > Yahoo’ and OSE to a new address.
- CSV files now don’t include a BOM (Byte Order Mark). This was needed before we had excel export integration. It causes problems with some tools parsing the CSV files, so has been removed, as suggested by Kevin Ellen.
- Fixed a couple of crashes when using the right click option.
- Fixed a bug where images only linked to via an HREF were not included in a sitemap.
- Fixed a bug effecting users of 8u31 & JDK 7u75 and above trying to connect to SSLv3 web servers.
- Fixed a bug with handling of mixed encoded links.
You can download the SEO Spider 3.3 now.
Thanks to everyone for all their comments on the latest version and feeback as always.






Thanks Screaming Frog for those amazing new features ! I particularly like the new tree view, really usefull :)
Amazing – loving the copy paste! Such a time saver
Really agree. This will save quite a bit of time in the future. Nice work Screaming Frog!
Tree view and new bulk export are superb. Thank you.
Great to see the new features and bug fixes.
Yeah, I really love the path export. Can’t wait to play with the excel data ;-)
Nice, image sitemap stuff too :) looks good!
Hey, looks super cool folks. Can’t wait to have a play with this. :)
Thanks for the update Dan. Love the new tree view – really handy!
Old crawls from version 2.55 produce an error (ClassCastException) when loaded with 3.0!
Hi Reinhard,
Old crawls should be fine, hence – Are you able to share an example with us at all?
Perhaps if you could pop over an old crawl via a Dropbox link for us to download (just to our support) so we can take a look? https://www.screamingfrog.co.uk/seo-spider/support/
Cheers.
Dan
Nice update. While I realize that are command line scheduling capabilities, it would be more ideal if this was built into the Spider Frog GUI. It also seems that functionality in its current state will just will run reports, but nothing else. Would enjoy the ability to have this schedule and to conditionally email and/or ftp reports (i.e. error reports) at a certain threshold. Can this be a feature request? Also, I am wondering if instead of many steps to generate all the various exports/reports if there is a possibility of having one master reporting column perhaps a rollover nav item that lists all the possible exports/reports. This way, you could select all reports or uncheck specific reports you didn’t want ion one fell swoop. It would seem to save time IMHO. Thanks!
Hi Bill,
Thanks for your thoughts and feedback.
A proper scheduling feature will be in our next version (with ability to auto email etc).
Good question regarding the exports and reports – We plan on adding the ability to export everything in one go. But also, the ‘reports’ section has been discussed internally, as it’s so easy to miss. Plus, having to export ‘redirect chains’ to find out if there are any for example, is a pain. So, we are considering a few ways to improve this definitely ;-)
Appreciate all the feedback.
Cheers.
Dan
Fantastic. Can’t wait. Thanks Dan! p.s. If you aren’t doing so already, you might want to consider a group of beta testers as well for new enhancements…
Would be cool if you could also provide intraday scheduling as well (hourly?) so it could be almost like real-time. Also, I am wondering if a feature to be able to perhaps highlight “what’s changed” in many of the tag attributes since the previous scan could be useful – especially if it was logged with a date/time. (i.e. you could see when the in-house development team actually implemented any changes…) Lastly, might be interesting if there would be a way to visually see what has changed as well (ala archive.org). From a disk space perspective, it would be a challenge to archive screenshots of some or all of the page(s) – especially if underlying spider code changes were made, but visually nothing changed. However, it might be useful if you could get a report that could be shared with internal teams that show the visual before and after of a site/page as well as the underlying changes of the spider attributes. Thx!
Hi Bill,
Apologies, nearly missed this. Thanks for all the suggestions, much appreciated. All good ideas, both scheduling and comparison of crawls are on our list.
Archiving screenshots wouldn’t be a problem either (I believe there’s a few tools which already do that) and I like the before and after visual too.
Cheers.
Dan
Great! Awesome! Such a super new features! Tree listing is very useful right now for me!) Thank you!)
Really loving the Tree View – that’s brilliant. Have to say best $100 spent yearly!
Is there anyway (in future) to enable export in Tree View?
Hey Jinnat,
Thanks for the kind comments.
This is one we discussed internally, as we were not convinced how useful the export of tree view is when you get it in a spread sheet.
While the ‘export’ button will just perform an export like you see in ‘list view’, to get the ‘tree view’ data, you can highlight all the data in the top window, copy and paste it into Excel tho! ;-)
Cheers.
Dan
The tree view can be an excellent way to better understand a site’s URL structure and it would be a great visual aid to help understand a variety of patterns and issues. However it is data overload at the moment, especially for large sites. Have you given further thought to enhancing the functionality here?
For example:
-the ability to close all subdirectory folders that are greater than 2 backslashes deep would
-breaking the paths down into columns, or showing the number of subdirectories would be helpful
-being able to easily generate a visual sitemap would be helpful
-being able to download a spreadsheet would be extremely useful for those who can’t break down this stuff down in Excel themselves from a regular download.
Hey Reid,
Thanks for the feedback. We have indeed discussed improving the functionality of the tree view and we’ve had quite a few requests about being able to export this view etc.
You can already choose to close all subdirectories up to a level – If you right click on key type symbol in the ‘path’ column next to a subfolder, you can choose to ‘expand’ and ‘collapse’ levels and say, only show a max level of ‘2’ etc.
I like the idea of showing the number of subdirectories and generating a visual sitemap. The visual sitemap feature we’ve had on our radar for a while, it would be cool to consider various views, subdirectory structure, but also internal links and depth etc.
Thanks for the suggestions, lots to come!
Cheers.
Dan
Hey guys,
Using Test-to-Column within Excel (Data Tab) you can easily create this kind of tree format from a basic list of exported URLs based on the folder structure. just use the forward slash as the delimiter vs. the basic comma.
Can’t thank you guys enough for the update. Image sitemaps were needed :) Keep up the great work!
Very good work!
Especially like new sitemap.xml options and tree view.
Thanks for your hard work Screaming Frog!
Now this is an update and a half ;) Hoping it will export the tree view, that will be amazing
Thanks Daniel.
Check out my reply to Jinnat above regarding exporting the ‘tree view’.
Cheers.
I noticed that, apologies.
One thing that would be good though, have excluded defaults for WordPress/Joomla etc
You know like URLS will wp-login.php, wp-admin it would be great to just tick some boxes to block those from a crawl
I know you can exclude this manually but for some reason, it still picks them up
Love it Dan, love it. Can’t live without Screaming Frog. What was life before Screaming Frog ? Thanks for an amazing product.
What is the “tab character” in links you mention above…do you mean the # or ?
Hi Rick,
I mean a link containing a tab character, e.g.:
a href=”http://www.foo.com/beforetab\taftertab/page.html” rel=”nofollow”>link with tab< Cheers. Dan
Great new updates – the tiered view looks particularly useful.
One thing I miss on your spider is the ability to exclude pages in the search. I can type in “/blog” and see all of the URLs containing that string but I’m unable to exclude “/blog” without exporting to Excel. These aren’t pages I’d want to exclude before a crawl. I often want to do the same with title tags.
Cheers,
Alex.
Thanks Alex.
Good shout, it is something we’ve had on the list for a while. We will get to it, definitely very useful.
Cheers.
Amazing update Dan. Happy to see the introduction of the “tree view” aka. site architecture! :)
cheers!
Thanks Samuel and everyone else for the awesome comments and feedback.
Lots more to come!
Great! Awesome! Love the new features! Tree view is very useful
Love the new tree view and capturing .pdf as part of xml sitemap..Awesome work!
Art
You are truly amazing guys.
You already have this great product but with every update you just add more features. Esp. tree view seems great for analysis.
Keep up the good work!
Thanks for the update :)
Great and useful updates, thanks for all guys!
Just want to say that this looks amazing! The ‘Tree View’ is perfect as that is what is featured in DeepCrawl. Understanding what is contained on a directly level is absolute perfection.
The new features are excellent. The tree view is really useful and the protocol tab will be of great use checking http -> https
Awesome update! I think it has become much clearer with the tree view.
Awesome update, very useful! thanks
This tool is absolutely brilliant. It helps us very quickly to run audits better than before. Love it.
It just keeps getting better and better….
Just bought the license. For me the best spider ! Really helpful. Many thanks.
The feature we would love to see you add is Configuration > Link Filter, which would allow us to either include or exclude links that occur within a certain RegEx expression. So, for example, I could key in exclusion filters on .*? in order to not count footer links, or, alternatively, I could decide to only have Screaming Frog look at links in the main body section of a page by adding an include filter like this: .*?. The important thing about this feature is that you would still crawl the entire site, even excluded or non-included links, but after the crawl is done, you would not show or report on links excluded via this filter. The use case here is let’s say I want to know how many internal inbound links I have to page XYZ that ARE NOT in either the top nav of the site or the footer links. Right now, there doesn’t seem to be a way to isolate the crawl results in this fashion with respect to certain parts of the page. I do know that I can exclude links from being crawled, but that’s not what we need: crawl everything but give us some control on what internal links are reported back once the crawl is finished. This would be hugely valuable to help SEO folks better understand the internal linking on a site within the body section of web pages, without counting top nav, etc. links. Thanks.
I see the HTML in my regex examples was stripped out, but hopefully you get the idea without it.
Hi Ken,
Thanks for the feedback, I like the idea and can see why this would be useful.
We have something similar to this on the development list, as it’s been suggested in the past (it may have been you, we have it in our records).
Cheers.
Dan
I second this recommendation! It’d be great to know how well internal links are working when footer, sidebar, and main nav links are excluded.
I was wondering if this was ever implemented? It would be a very useful and powerful when doing internal linking audits and structuring new sites.
A video sitemap creation would be nice to have.
Very helpful thanks for the update!
Thanks for the next update. Very helpful for me.
Awesome update, very useful! thanks
Will have to check out the tree view now
I am having issues with the OX version 3.3. I can’t crawl any websites because I get a connection timeout. I’ve uninstalled and reinstalled the spider. I’ve checked my java for updates. I’ve restarted my computer…. nothing. Help anyone?
Hi Nathan,
We have an FAQ over here which should help – https://www.screamingfrog.co.uk/seo-spider/faq/#39
If it doesn’t pop through your details to support and we can – https://www.screamingfrog.co.uk/seo-spider/support/
Cheers.
Dan
Hi Nathan. I am having the exact same problem and the FAQ have not help me.
Did you make it work?
Hi Chris,
As above, you can just pop through to support if the FAQ doesn’t help – https://www.screamingfrog.co.uk/seo-spider/support/
Cheers.
Dan
This tools keeps getting better and better and it’s my number one tool for doing SEO audits on both my own and my clients site.
thank you for update
hi,
I also use the latest version of this tool and It’s awesome. This one reduce my load from my shoulders.
Thanks
Hi all! recently I downloaded the 3.2v of this awesome tool…everything is working fine, however I have noticed that the images tab is always empty…..any clue about this issue?
Thanks heaps
Hi Javier,
Thanks for the kind comments.
You’ll probably find the images don’t appear under the ‘Images’ tab when they are on a CDN or another subdomain. You can still view them and the alt text under the ‘external’ tab though.
More info over here – https://www.screamingfrog.co.uk/seo-spider/faq/#38
Cheers.
Dan
Hands down the best tool for SEO, thanks SF!
Love the new features. Still one of the best tools out there for online marketers and web admins.
Hell yeah! Amazing new features! Thanx!
I have already updated my SEO spider to version 3.0. Got lot of awesome features.
Thanks
SF not working on Java version 8u45 any fix? thanks!
Hey Ed,
Version 8 Update 45 is fine. Sounds like it might be corrupt, try unintalling & reinstalling fresh – https://java.com/en/download/manual.jsp
Any further problems, just pop through to us – https://www.screamingfrog.co.uk/seo-spider/support/
Thanks,
Dan
I used the removal tool to remove older versions and reinstalled u45. Seems to be working now. Thanks!
Thanks for latest version with amazing features, that’s really helpful to fix up technical issues. Keep up the great work!
It looks like you guys fixed a lot of bugs with this program. I am excited
This is brilliant! hands down, cant wait for the next one!
this is really great app…thanks
Great update! Tree view is perfect
your comment “Please note, this report will only pick up on items we crawl, rather than everything rendered in a browser.” regarding the https report, is there anything in particular that I should be looking out for?
Hi Paul,
There might be some things we don’t crawl that you embed etc (such as videos etc) depending on how they are integrated.
So the report only looks at items we crawl, which might not cover every scenario.
Cheers.
Dan
I like all the updates and all the support that you guys give. A lot of improvements since the beginning.
Very helpful thanks for the update! :)
Hi,
We’ve just tried your tool and we have to say that is a very useful SEO tool. We’ll tell you more details ;) Congratulations!
Thanks!
Hi,
Thanks for a very useful tool, we are using it almost every day :)
Silneo Crew.
Loving the regular updates, it’s my most often used tool :)
Yesterday itself, I extracted the SEO elements of 2 websites and I was appreciated by mine head authorities but I did not tell them this TOOL secret. I told them, I extracted SEO elements of each page manually. Love this tool :)
Thanks guys, great tool and guides. I must use it at least every other day. More than any other.
Very useful tool for SEO service and I love the list mode and tree view. This tool works for me like a butter. Good work keep up
Great post with useful information for an excellent SEO tool. Thanks!