SEO Spider Companion Tools, Aka ‘The Magnificent Seven’
Richard Lawther
Posted 8 February, 2019 by Richard Lawther in SEO
SEO Spider Companion Tools, Aka ‘The Magnificent Seven’
From crawl completion notifications to automated reportig: this post may not have Billy the Kid or Butch Cassidy, instead, here are a few of my most useful tools to combine with the SEO Spider, (just as excitin).
We SEOs are extremely lucky—not just because we’re working in such an engaging and collaborative industry, but we have access to a plethora of online resources, conferences and SEO-based tools to lend a hand with almost any task you could think up.
My favourite of which is, of course, the SEO Spider—after all, following Minesweeper Outlook, it’s likely the most used program on my work PC. However, a great programme can only be made even more useful when combined with a gang of other fantastic tools to enhance, compliment or adapt the already vast and growing feature set.
While it isn’t quite the ragtag group from John Sturges’ 1960 cult classic, I’ve compiled the Magnificent Seven(ish) SEO tools I find useful to use in conjunction with the SEO Spider:
Debugging in Chrome Developer Tools
Chrome is the definitive king of browsers, and arguably one of the most installed programs on the planet. What’s more, it’s got a full suite of free developer tools built straight in—to load it up, just right-click on any page and hit inspect. Among many aspects, this is particularly handy to confirm or debunk what might be happening in your crawl versus what you see in a browser.
For instance, while the Spider does check response headers during a crawl, maybe you just want to dig a bit deeper and view it as a whole? Well, just go to the Network tab, select a request and open the Headers sub-tab for all the juicy details:

Perhaps you’ve loaded a crawl that’s only returning one or two results and you think JavaScript might be the issue? Well, just hit the three dots (highlighted above) in the top right corner, then click settings > debugger > disable JavaScript and refresh your page to see how it looks:

Or maybe you just want to compare your nice browser-rendered HTML to that served back to the Spider? Just open the Spider and enable ‘JavaScript Rendering’ & ‘Store Rendered HTML’ in the configuration options (Configuration > Spider > Rendering/Advanced), then run your crawl. Once complete, you can view the rendered HTML in the bottom ‘View Source’ tab and compare with the rendered HTML in the ‘elements’ tab of Chrome.

There are honestly far too many options in the Chrome developer toolset to list here, but it’s certainly worth getting your head around.
Page Validation with a Right-Click
Okay, I’m cheating a bit here as this isn’t one tool, rather a collection of several, but have you ever tried right-clicking a URL within the Spider? Well, if not, I’d recommend giving it a go—on top of some handy exports like the crawl path report and visualisations, there’s a ton of options to open that URL into several individual analysis & validation apps:
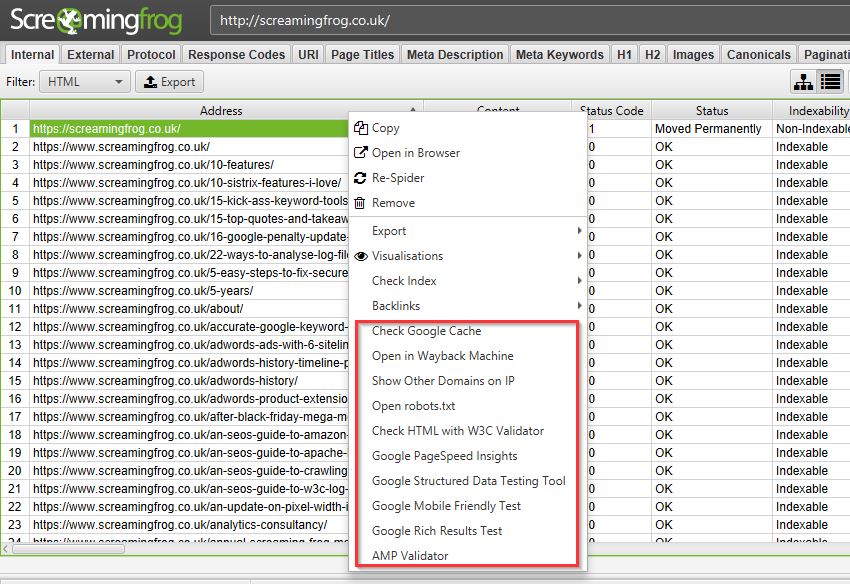
- Google Cache – See how Google is caching and storing your pages’ HTML.
- Wayback Machine – Compare URL changes over time.
- Other Domains on IP – See all domains registered to that IP Address.
- Open Robots.txt – Look at a site’s Robots.
- HTML Validation with W3C – Double-check all HTML is valid.
- PageSpeed Insights – Any areas to improve site speed?
- Structured Data Tester – Check all on-page structured data.
- Mobile-Friendly Tester – Are your pages mobile-friendly?
- Rich Results Tester – Is the page eligible for rich results?
- AMP Validator – Official AMP project validation test.
User Data and Link Metrics via API Access
We SEOs can’t get enough data, it’s genuinely all we crave – whether that’s from user testing, keyword tracking or session information, we want it all and we want it now! After all, creating the perfect website for bots is one thing, but ultimately the aim of almost every site is to get more users to view and convert on the domain, so we need to view it from as many angles as possible.
Starting with users, there’s practically no better insight into user behaviour than the raw data provided by both Google Search Console (GSC) and Google Analytics (GA), both of which help us make informed, data-driven decisions and recommendations.
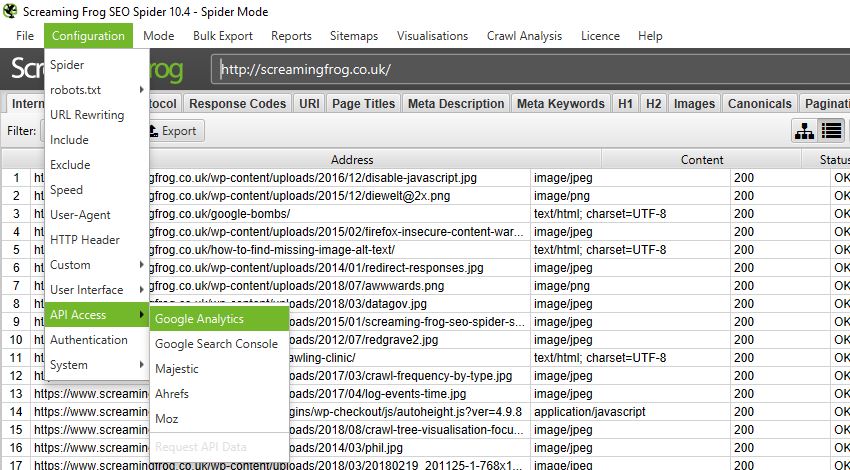
What’s great about this is you can easily integrate any GA or GSC data straight into your crawl via the API Access menu so it’s front and centre when reviewing any changes to your pages. Just head on over to Configuration > API Access > [your service of choice], connect to your account, configure your settings and you’re good to go.
Another crucial area in SERP rankings is the perceived authority of each page in the eyes of search engines – a major aspect of which, is (of course), links., links and more links. Any SEO will know you can’t spend more than 5 minutes at BrightonSEO before someone brings up the subject of links, it’s like the lifeblood of our industry. Whether their importance is dying out or not there’s no denying that they currently still hold much value within our perceptions of Google’s algorithm.

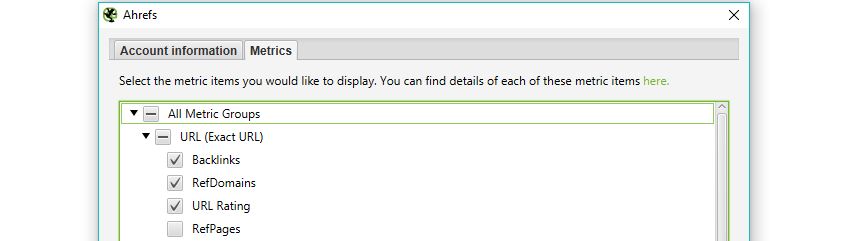
Well, alongside the previous user data you can also use the API Access menu to connect with some of the biggest tools in the industry such as Moz, Ahrefs or Majestic, to analyse your backlink profile for every URL pulled in a crawl.
For all the gory details on API Access check out the following page (scroll down for other connections): https://www.screamingfrog.co.uk/seo-spider/user-guide/configuration/#google-analytics-integration
Understanding Bot Behaviour with the Log File Analyzer
An often-overlooked exercise, nothing gives us quite the insight into how bots are interacting through a site than directly from the server logs. The trouble is, these files can be messy and hard to analyse on their own, which is where our very own Log File Analyzer (LFA) comes into play, (they didn’t force me to add this one in, promise!).
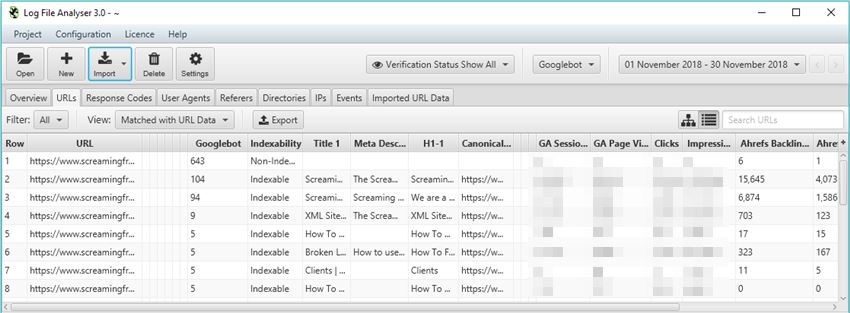
I’ll leave @ScreamingFrog to go into all the gritty details on why this tool is so useful, but my personal favourite aspect is the ‘Import URL data’ tab on the far right. This little gem will effectively match any spreadsheet containing URL information with the bot data on those URLs.

So, you can run a crawl in the Spider while connected to GA, GSC and a backlink app of your choice, pulling the respective data from each URL alongside the original crawl information. Then, export this into a spreadsheet before importing into the LFA to get a report combining metadata, session data, backlink data and bot data all in one comprehensive summary, aka the holy quadrilogy of technical SEO statistics.
While the LFA is a paid tool, there’s a free version if you want to give it a go.
One of my favourite reports from the Spider is the simple but useful ‘Crawl Overview’ export (Reports > Crawl Overview), and if you mix this with the scheduling feature, you’re able to create a simple crawl report every day, week, month or year. This allows you to monitor and for any drastic changes to the domain and alerting to anything which might be cause for concern between crawls.
However, in its native form it’s not the easiest to compare between dates, which is where Google Sheets & Data Studio can come in to lend a hand. After a bit of setup, you can easily copy over the crawl overview into your master G-Sheet each time your scheduled crawl completes, then Data Studio will automatically update, letting you spend more time analysing changes and less time searching for them.
This will require some fiddling to set up; however, at the end of this section I’ve included links to an example G-Sheet and Data Studio report that you’re welcome to copy. Essentially, you need a G-Sheet with date entries in one column and unique headings from the crawl overview report (or another) in the remaining columns:

Once that’s sorted, take your crawl overview report and copy out all the data in the ‘Number of URI’ column (column B), being sure to copy from the ‘Total URI Encountered’ until the end of the column.
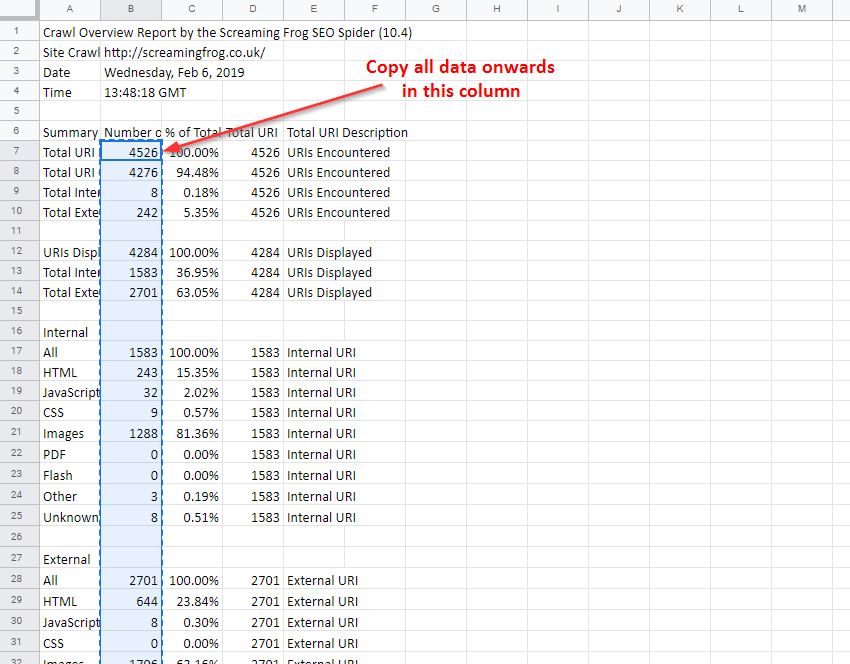
Open your master G-Sheet and create a new date entry in column A (add this in a format of YYYYMMDD). Then in the adjacent cell, Right-click > ‘Paste special’ > ‘Paste transposed’ (Data Studio prefers this to long-form data):
If done correctly with several entries of data, you should have something like this:

Once the data is in a G-Sheet, uploading this to Data Studio is simple, just create a new report > add data source > connect to G-Sheets > [your master sheet] > [sheet page] and make sure all the heading entries are set as a metric (blue) while the date is set as a dimension (green), like this:
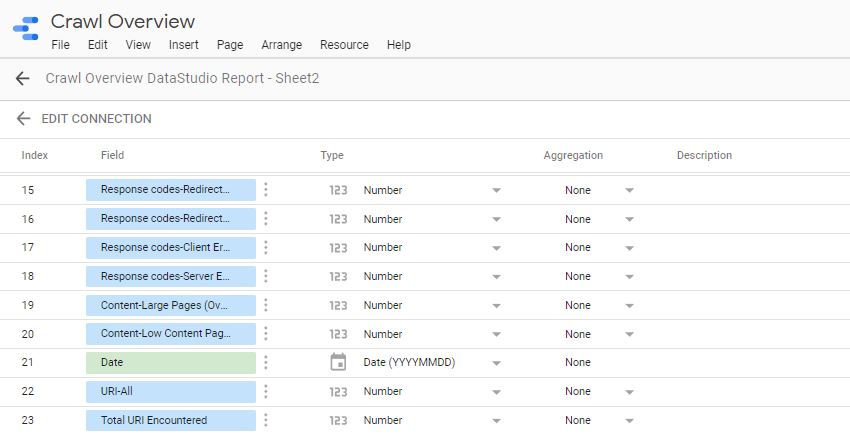
You can then build out a report to display your crawl data in whatever format you like. This can include scorecards and tables for individual time periods, or trend graphs to compare crawl stats over the date range provided, (you’re very own Search Console Coverage report).
Here’s an overview report I quickly put together as an example. You can obviously do something much more comprehensive than this should you wish, or perhaps take this concept and combine it with even more reports and exports from the Spider.
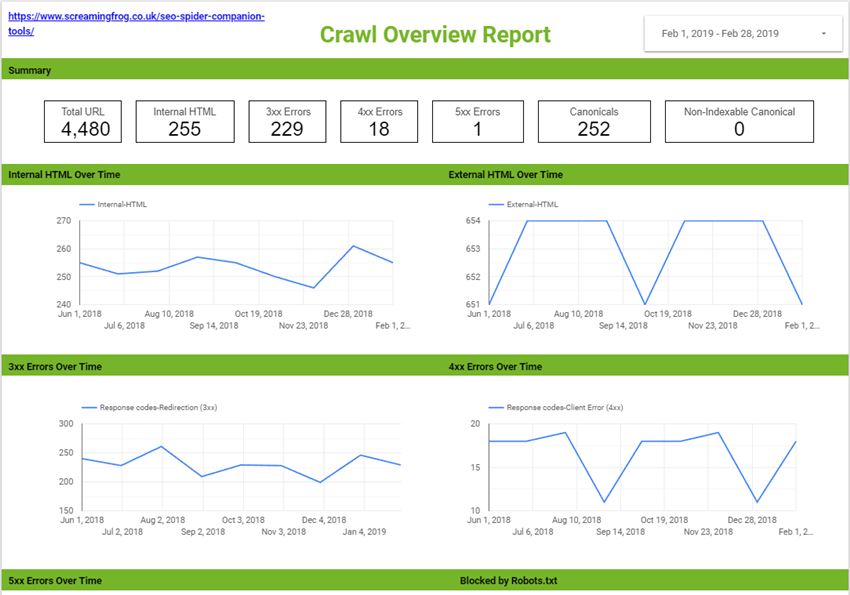
If you’d like a copy of both my G-Sheet and Data Studio report, feel free to take them from here:
Master Crawl Overview G-Sheet: https://docs.google.com/spreadsheets/d/1FnfN8VxlWrCYuo2gcSj0qJoOSbIfj7bT9ZJgr2pQcs4/edit?usp=sharing
Crawl Overview Data Studio Report: https://datastudio.google.com/open/1Luv7dBnkqyRj11vLEb9lwI8LfAd0b9Bm
Note: if you take a copy some of the dimension formats may change within DataStudio (breaking the graphs), so it’s worth checking the date dimension is still set to ‘Date (YYYMMDD)’
Building Functions & Strings with XPath Helper & Regex Search
The Spider is capable of doing some very cool stuff with the extraction feature, a lot of which is listed in our guide to web scraping and extraction. The trouble with much of this is it will require you to build your own XPath or regex string to lift your intended information.
While simply right-clicking > Copy XPath within the inspect window will usually do enough to scrape, by it’s not always going to cut it for some types of data. This is where two chrome extensions, XPath Helper & Regex- Search come in useful.
Unfortunately, these won’t automatically build any strings or functions, but, if you combine them with a cheat sheet and some trial and error you can easily build one out in Chrome before copying into the Spider to bulk across all your pages.
For example, say I wanted to get all the dates and author information of every article on our blog subfolder (https://www.screamingfrog.co.uk/blog/).
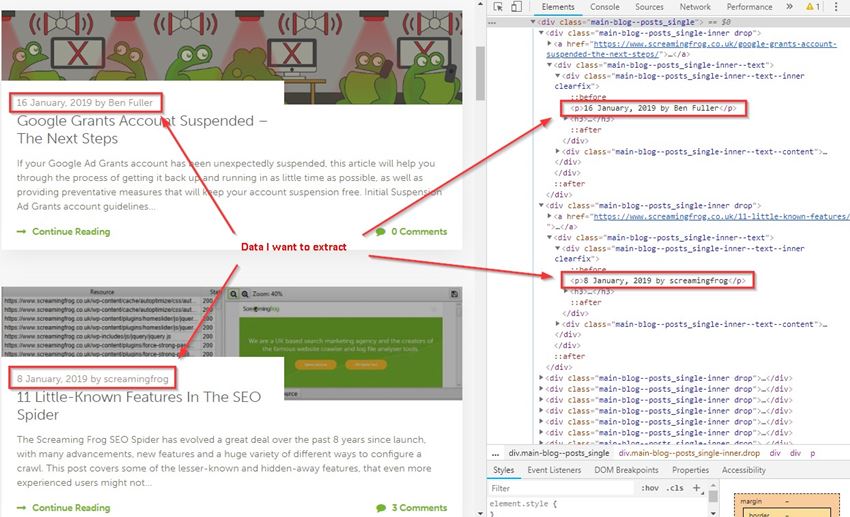
If you simply right clicked on one of the highlighted elements in the inspect window and hit Copy > Copy XPath, you would be given something like:
/html/body/div[4]/div/div[1]/div/div[1]/div/div[1]/p
While this does the trick, it will only pull the single instance copied (‘16 January, 2019 by Ben Fuller’). Instead, we want all the dates and authors from the /blog subfolder.
By looking at what elements the reference is sitting in we can slowly build out an XPath function directly in XPath Helper and see what it highlights in Chrome. For instance, we can see it sits in a class of ‘main-blog–posts_single-inner–text–inner clearfix’, so pop that as a function into XPath Helper:
//div[@class="main-blog--posts_single-inner--text--inner clearfix"]
XPath Helper will then highlight the matching results in Chrome:
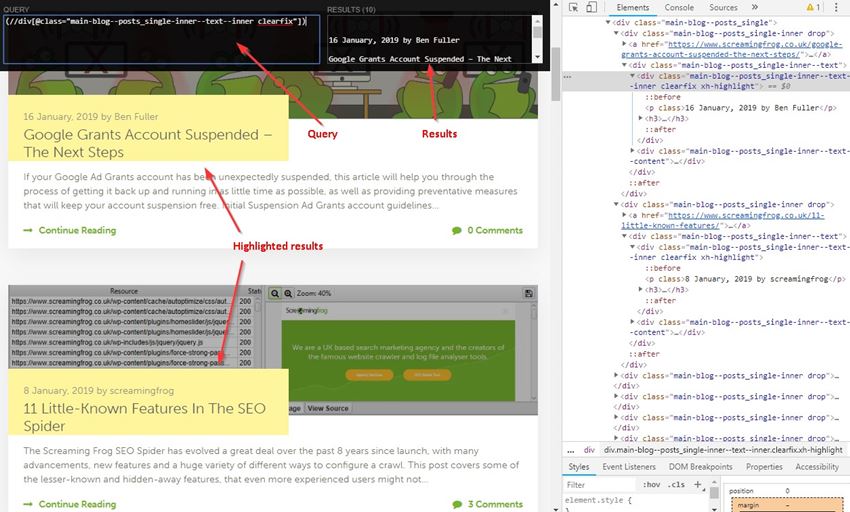
Close, but this is also pulling the post titles, so not quite what we’re after. It looks like the date and author names are sitting in a sub <p> tag so let’s add that into our function:
(//div[@class="main-blog--posts_single-inner--text--inner clearfix"])/p
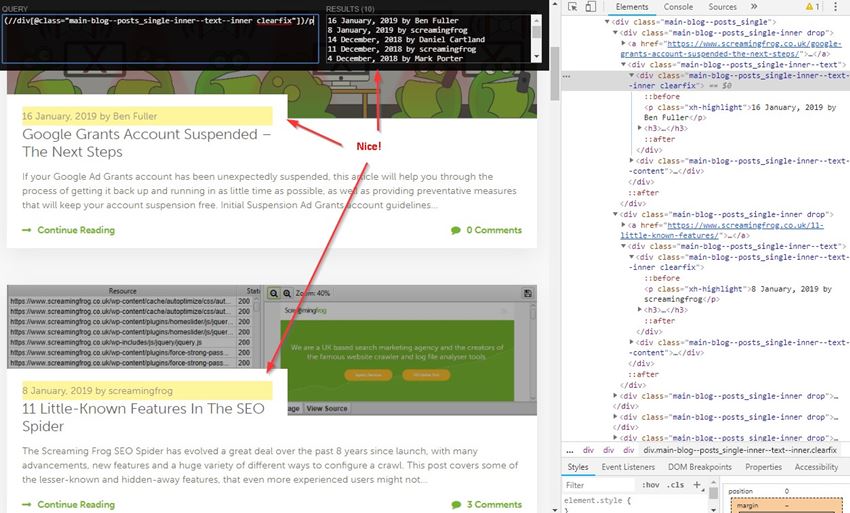
Bingo! Stick that in the custom extraction feature of the Spider (Configuration > Custom > Extraction), upload your list of pages, and watch the results pour in!
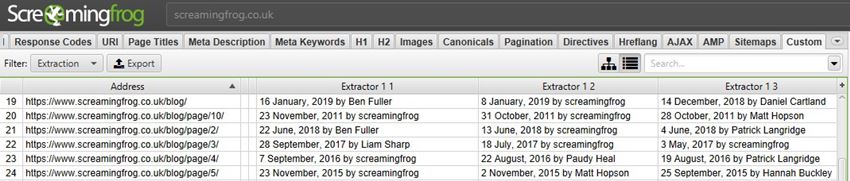
Regex Search works much in the same way: simply start writing your string, hit next and you can visually see what it’s matching as you’re going. Once you got it, whack it in the Spider, upload your URLs then sit back and relax.
Notifications & Auto Mailing Exports with Zapier
Zapier brings together all kinds of web apps, letting them communicate and work with one another when they might not otherwise be able to. It works by having an action in one app set as a trigger and another app set to perform an action as a result.
To make things even better, it works natively with a ton of applications such as G-Suite, Dropbox, Slack, and Trello. Unfortunately, as the Spider is a desktop app, we can’t directly connect it with Zapier. However, with a bit of tinkering, we can still make use of its functionality to provide email notifications or auto mailing reports/exports to yourself and a list of predetermined contacts whenever a scheduled crawl completes.
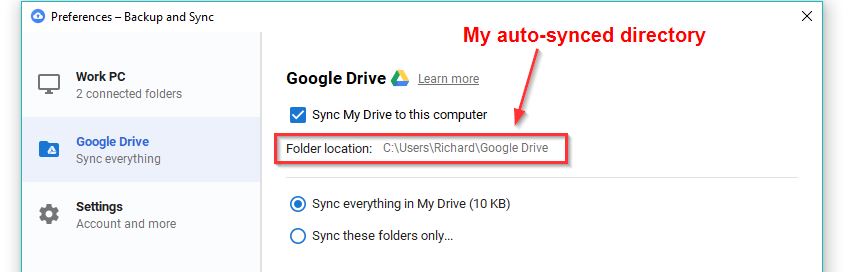
All you need is to have your machine or server set up with an auto cloud sync directory such as those on ‘Dropbox’, ‘OneDrive’ or ‘Google Backup & Sync’. Inside this directory, create a folder to save all your crawl exports & reports. In this instance, I’m using G-drive, but others should work just as well.
You’ll need to set a scheduled crawl in the Spider (file > Schedule) to export any tabs, bulk exports or reports into a timestamped folder within this auto-synced directory:
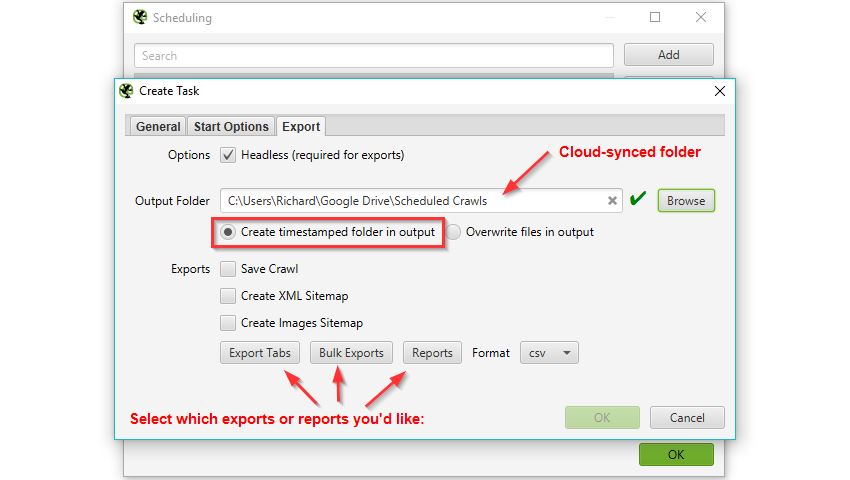
Log into or create an account for Zapier and make a new ‘zap’ to email yourself or a list of contacts whenever a new folder is generated within the synced directory you selected in the previous step. You’ll have to provide Zapier access to both your G-Drive & Gmail for this to work (do so at your own risk).
My zap looks something like this:
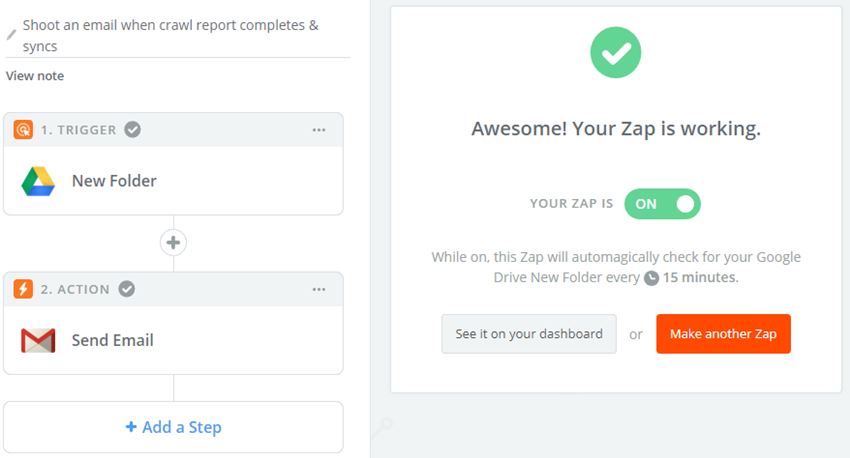
The above Zap will trigger when a new folder is added to /Scheduled Crawls/ in my G-Drive account. It will then send out an email from my Gmail to myself and any other contacts, notifying them and attaching a direct link to the newly added folder and Spider exports.
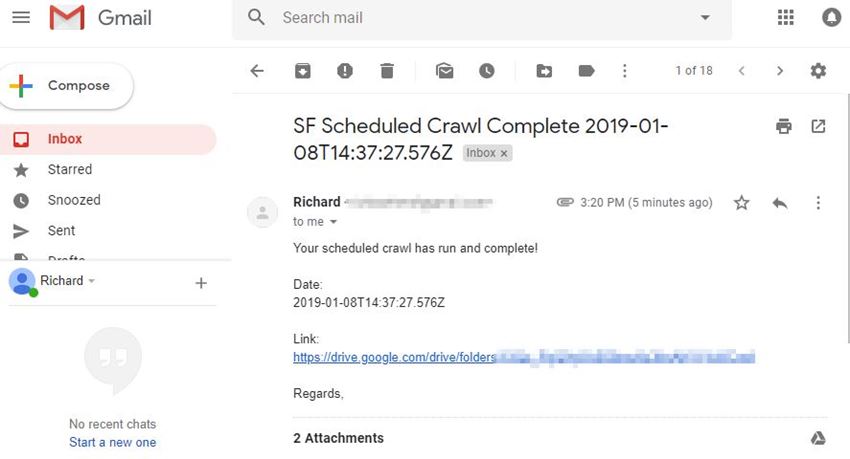
I’d like to note here that if running a large crawl or directly saving the crawl file to G-drive, you’ll need enough storage to upload (so I’d stick to exports). You’ll also have to wait until the sync is completed from your desktop to the cloud before the zap will trigger, and it checks this action on a cycle of 15 minutes, so might not be instantaneous.
Alternatively, do the same thing on IFTTT (If This Then That) but set it so a new G-drive file will ping your phone, turn your smart light a hue of lime green or just play this sound at full volume on your smart speaker. We really are living in the future now!
Conclusion
There you have it, the Magnificent Seven(ish) tools to try using with the SEO Spider, combined to form the deadliest gang in the west web. Hopefully, you find some of these useful, but I’d love to hear if you have any other suggestions to add to the list.






Thanks for the in-depth and very generous blog post Richard. It’s fun to still be learning new ways of using Screaming Frog after 6 or so years using it.
I’m going to have a play around with crawl scheduling / G-Sheets / GDS combo to see if it can provide any value above our GSC-powered reporting for some of our larger client websites.
Muito obrigado pelo conteúdo!
Como sempre, Screaming Frog está ajudando o trabalho de todos os SEO do mundo inteiro!
A Vossa ferrameta nos ajuda todos os dias em nossos trabalhos, usar no DataStudio não sabiamos como otimizar de tal forma, vai reduzir 70% do trabalho em auditorias documentadas no dataStudio…. obrigado, obrigado e obrigado novamente!
obrigado desde o Brasil!
Thank you very much for the content!
As always, Screaming Frog is helping the work of all SEO worldwide!
Your data tool helps us every day in our work, using DataStudio did not know how to optimize in such a way, it will reduce 70% of the work in documented audits in dataStudio …. thanks, thanks and thanks again!
Thank you from Brazil!
Thanks for this guide.
You can not imagine how helpful it is to use ScreamingFrog with your advice.
Thanks a lot Richard, Thanks a lot and see you soon man.
Federico @moonmarketing
I never knew how much Screaming Frog is actually capable of doing, defo downloading the log analyzer right now.
Great post, Thanks! Though did the upgrade to v11.0 break the Google Sheets layout? Looks like the paste transpose doesn’t line up with the columns in the Gsheets file anymore. :-(
Rich has updated the template for Gsheets for the Data Studio report now.
Cheers.
Dan
This is great Richard. Looking forward to hooking in Ahrefs and GSC to our Screaming Frog account and setting up some automated crawls > reports with Data Studio. A little bit of leg work required, but the end result will be well worth it.
please update table template for data studio for version 14. new app looks cool❤