Screaming Frog SEO Spider Update – Version 4.0
Dan Sharp
Posted 7 July, 2015 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 4.0
I’m really pleased to announce version 4.0 of the Screaming Frog SEO Spider, codenamed internally as ‘Ella’.
We have been busy in development working on some significant improvements to the SEO Spider due for release later this year, which include a number of powerful new features we’ve wanted to release for a very longtime. Rather than wait, we decided to release some of these features now, with much more on the way.
Therefore, version 4.0 has two new big features in the release, and here’s the full details –
1) Google Analytics Integration
You can now connect to the Google Analytics API and pull in data directly during a crawl.

To get a better understanding of a website’s organic performance, it’s often useful to map on-page elements with user data and SEOs have for a long-time combined crawl data with Google Analytics in Excel, particularly for Panda and content audits. GA data is seamlessly fetched and matched to URLs in real time as you crawl, so you often see data start appearing immediately, which we hope makes the process more efficient.
The SEO Spider not only fetches user and session metrics, but it can also collect goal conversions and ecommerce (transactions and revenue) data for landing pages, so you can view your top performing pages when performing a technical or content audit.
If you’re running an Adwords campaign, you can also pull in impressions, clicks, cost and conversion data and we will match your destination URLs against the site crawl, too. You can also collect other metrics of interest, such as Adsense data (Ad impressions, clicks revenue etc), site speed or social activity and interactions.
To set this up, start the SEO Spider and go to ‘Configuration > API Access > Google Analytics’.

Then you just need to connect to a Google account (which has access to the Analytics account you wish to query) by granting the ‘Screaming Frog SEO Spider’ app permission to access your account to retreive the data. Google APIs use the OAuth 2.0 protocol for authentication and authorisation.

Once you have connected, you can choose the relevant Analytics account, property, view, segment and date range!
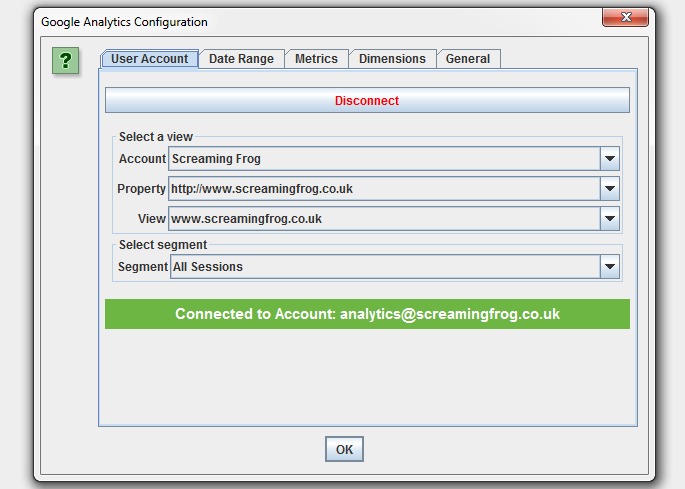
Then simply select the metrics that you wish to fetch. The SEO Spider currently allow you to select up to 20, which we might extend further. If you keep the number of metrics to 10 or below with a single dimension (as a rough guide), then it will generally be a single API query per 10k URLs, which makes it super quick –
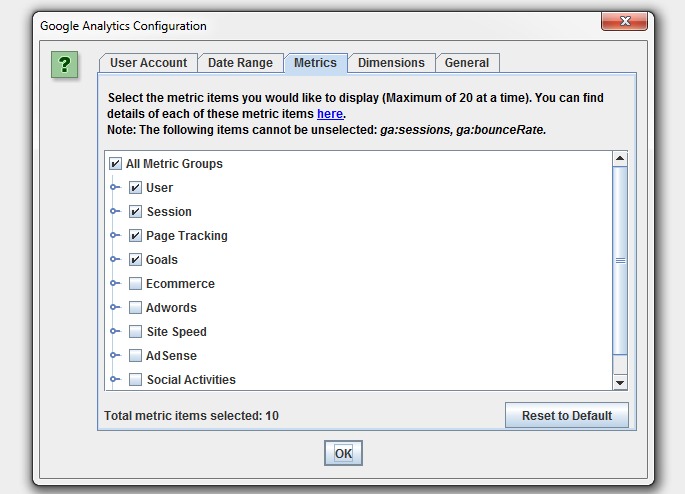
You can also set the dimension of each individual metric, as you may wish to collect data against page path and, or landing page for example.
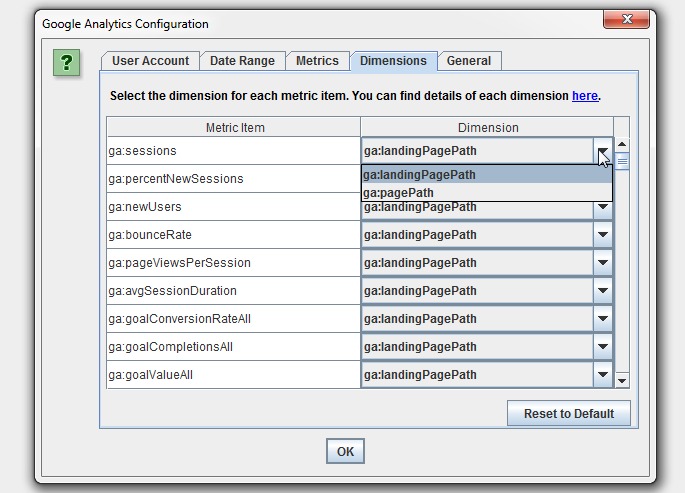
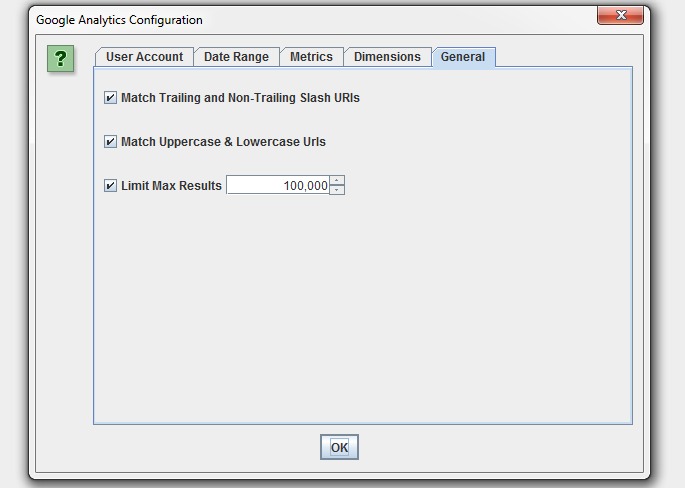
There are circumstances where URLs in Google Analytics might not match URLs in a crawl, so we have a couple of common scenarios covered in our configuration, such as matching trailing and non-trailing slash URLs and case sensitivity (upper and lowercase characters in URLs).
If you have millions of URLs in GA, you can also choose to limit the number of URLs to query, which is by default ordered by sessions to return the top performing page data.
When you hit ‘start’ to crawl, the Google Analytics data will then be fetched and display in respective columns within the ‘Internal’ and ‘Analytics’ tabs. There’s a separate ‘Analytics’ progress bar in the top right and when this has reached 100%, crawl data will start appearing against URLs. Fetching the data from the API is independent of the crawl, and it doesn’t slow down crawl speed itself.
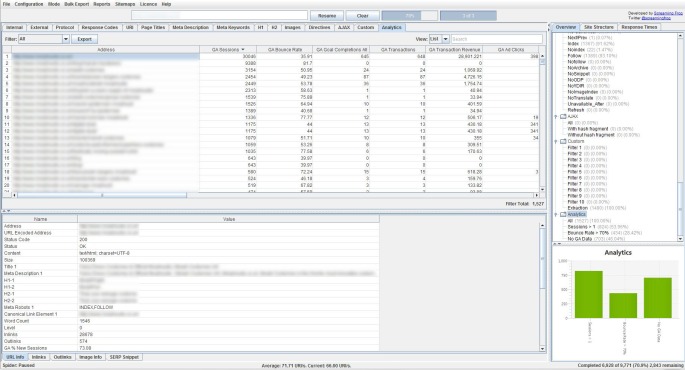
There are 3 filters currently under the ‘Analytics’ tab, which allow you to filter by ‘Sessions Above 0’, ‘Bounce Rate Above 70%’ and ‘No GA Data’. ‘No GA Data’ means that for the metrics and dimensions queried, the Google API didn’t return any data for the URLs in the crawl. So the URLs either didn’t receive any visits (sorry, ‘sessions’), or perhaps the URLs in the crawl are just different to those in GA for some reason.
For our site, we can see there is ‘no GA data’ for blog category pages and a few old blog posts, as you would expect really (the query was landing page, rather than page). Remember, you may see pages appear here which are ‘noindex’ or ‘canonicalised’, unless you have ‘respect noindex‘ and ‘respect canonicals‘ ticked in the advanced configuration tab.
Please note – If GA data does not get pulled into the SEO Spider as you expected, then analyse the URLs in GA under ‘Behaviour > Site Content > All Pages’ and ‘Behaviour > Site Content > Landing Pages’ depending on your query.
If they don’t match URLs in the crawl, then GA data won’t able to be matched up and appear in the SEO Spider. We recommend checking your default Google Analytics view settings (such as ‘default page’) and filters which all impact how URLs are displayed and hence matched against a crawl. If you want URLs to match up, you can often make the required amends within Google Analytics.
This is just our first iteration and we have some more advanced crawling, matching, canonicalisation and aggregation planned which will help in more complicated scenarios and provide further insights.
Enjoy!
2) Custom Extraction
The new ‘custom extraction’ feature allows you to collect any data from the HTML of a URL. As many of you will know, our original intention was always to extend the existing ‘custom search’ feature, into ‘custom extraction’, which has been one of the most popular requests we have received.
If you’re familiar with scraping using import XML and Xpath, SeoTools for Excel, Scraper for Chrome or our friends at URL Profiler, then you’ll be at home using Xpath & CSS Path selectors and using the custom extraction feature.
You’ll find the new feature under ‘Configuration > Custom’.
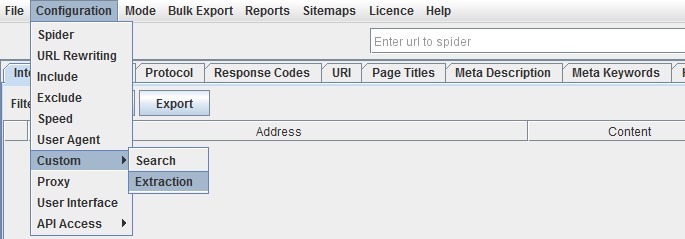
‘Search’ is of course the usual custom source code search feature you should be familiar with –
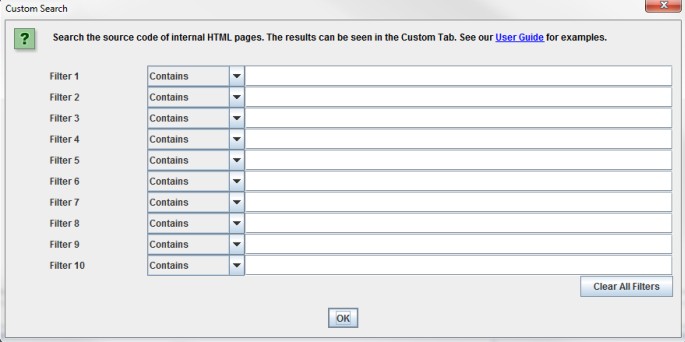
‘Extraction’ is similar to the custom search feature, you have 10 fields which allow you to extract anything from the HTML of a web page by using either Xpath, CSS Path or failing those, regex. You can include the attribute as usual in XPath and for CSS Path an optional attribute field will appear after selection.
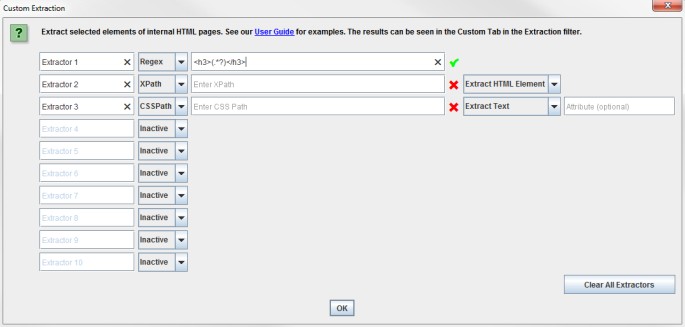
When using XPath or CSS Path to collect HTML, you can choose what to extract:
- Extract HTML Element: The selected element in full and the HTML content inside.
- Extract Inner HTML: The HTML content inside of the selected element. If the selected element contains other HTML elements, they will be included.
- Extract Text: The text content of the selected element, and the text content of any sub elements (essentially the HTML stripped entirely!).
You’ll get a lovely tick next to your regex, Xpath or CSS Path if it’s valid syntax. If you’ve made a mistake, a red cross will remain in place!
This will allow you to collect any data that we don’t currently as default or anything unique and specific to the work you’re performing. For example, Google Analytics IDs, schema, social meta tags (Open Graph Tags & Twitter cards), mobile annotations, hreflang values, as well as simple things like price of products, discount rates, stock availability etc. Let’s have a look at collecting some of these, with specific examples below.
Authors & Comments
Lets say I wanted to know the authors of every blog post on the site and the number of comments each have received. All I need to do is open up a blog post in Chrome, right click and ‘inspect element’ on the data I want to collect and right click again on the relevant HTML and copy the relevant CSS path or XPath. If you use Firebug in Firefox, then you can do the same there, too.
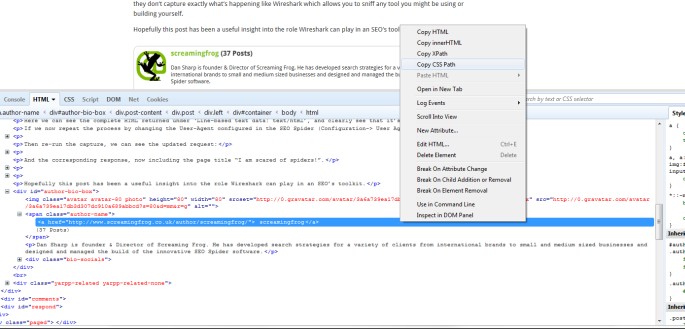
I can also name the ‘extractors’, which correspond to the column names in the SEO Spider. In this example, I’ve used a CSS Path and XPath for the fun of it.

The author names and number of comments extracted then shows up under the ‘extraction’ filter in the ‘custom’ tab, as well as the ‘internal’ tab allowing you to export everything collected all together into Excel.
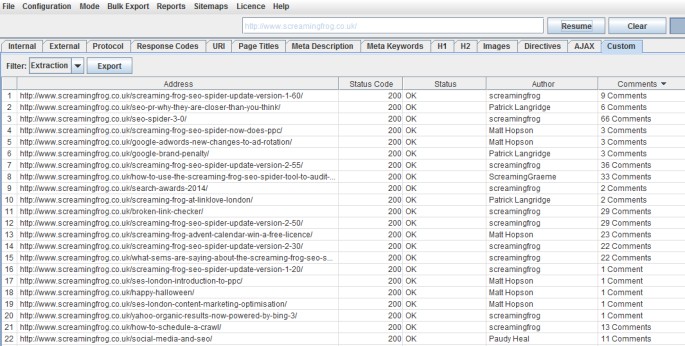
Google Analytics ID
Traditionally the custom search feature has been really useful to ensure tracking tags are present on a page, but perhaps sometimes you may wish to pull the specific UA ID. Let’s use regex for this one, it would be –
["'](UA-.*?)["']

And the data extracted is as you would expect –
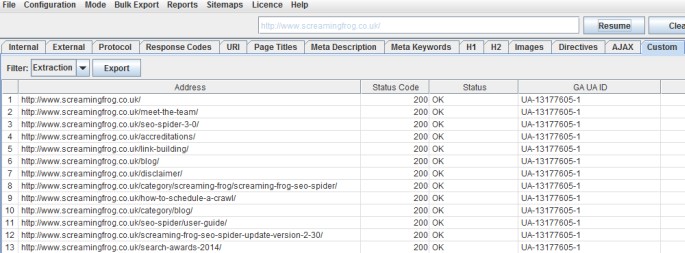
Additional Headings
As default, the SEO Spider only collects h1s and h2s. However, perhaps you would like to collect h3s as well. Regex should generally be your last resort, for collecting items which CSS Path or XPath can’t – such as HTML comments or inline JavaScript . However, as an example, a quick regex for this one might be –
<h3>(.*?)</h3>

The Xpath would just be –
//h3
Alongside the ‘Extract Text’ option. The first h3s returned are as follows –
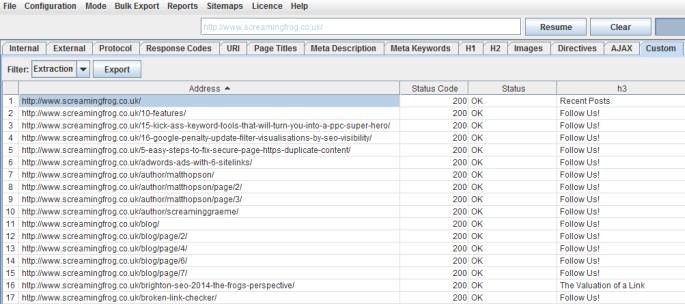
Mobile Annotations
If you wanted to pull mobile annotations from a website, you might use an Xpath such as –
//link[contains(@media, '640') and @href]/@href

Which for the Huffington Post would return –
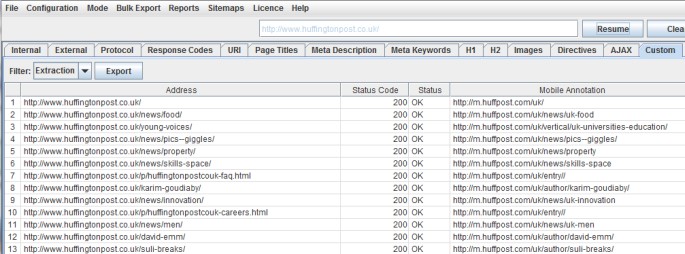
Hreflang
We are working on a more robust report for hreflang as there can be so many types of errors and problems with the set-up, but in the meantime you can collect them using the new custom extraction feature as well. You might need to know how many hreflang there are on a page first –
(//*[@hreflang])[1]
(//*[@hreflang])[2]
etc.

The above will collect the entire HTML element, with the link and hreflang value.
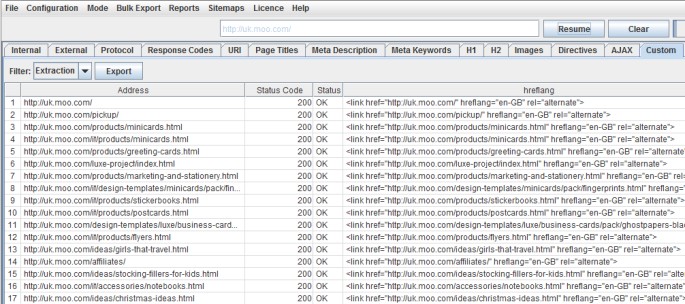
So, perhaps you wanted just the hreflang values, you could specify the attribute using @hreflang –

This would just collect the language values –
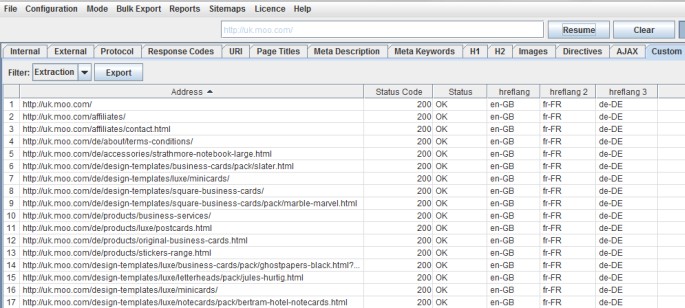
Social Meta Tags
You may wish to extract social meta tags, such as Facebook Open Graph tags or Twitter Cards. Your set-up might be something like –
//meta[starts-with(@property, 'og:title')][1]/@content
//meta[starts-with(@property, 'og:description')][1]/@content
//meta[starts-with(@property, 'og:type')][1]/@content
etc
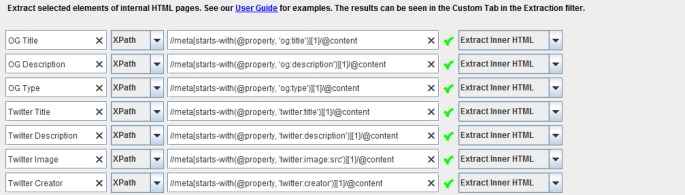
Which on Moz, would collect some lovely social meta tag data –
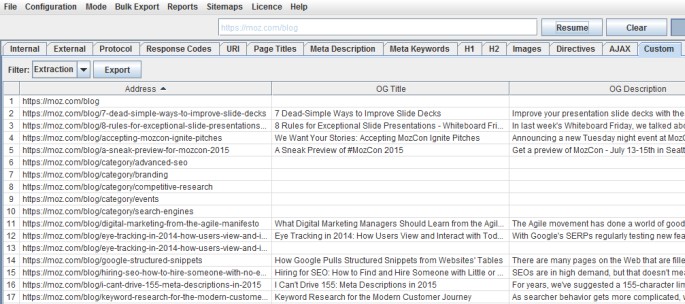
Schema
You may wish to collect the types of various Schema on a page, so the set-up might be –
(//*[@itemtype])[1]/@itemtype
(//*[@itemtype])[2]/@itemtype
etc

And the extracted data is –
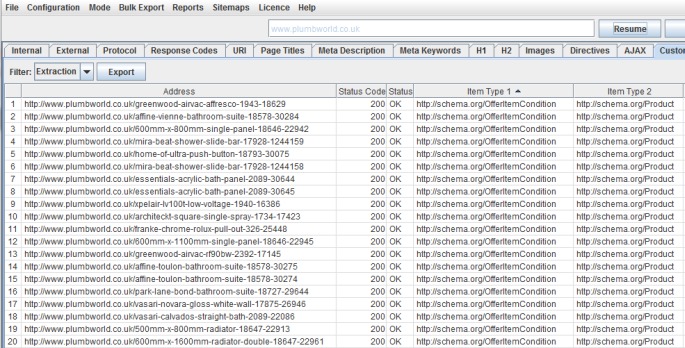
Email Addresses
Perhaps you wanted to collect email addresses from your website or websites, the Xpath might be something like –
//a[starts-with(@href, 'mailto')][1]
//a[starts-with(@href, 'mailto')][2]
etc

From our website, this would return the two email addresses we have in the footer on every page –
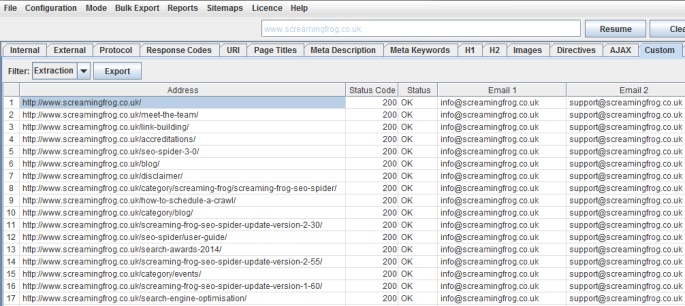
That’s enough examples for now, and I am sure you will all have plenty of other smart ways this feature can be used. My Xpath is probably fairly poor, so feel free to improve! You can read our web scraping guide with more examples.
To help us avoid a sudden influx of queries about Xpath, CSS Path and regex syntax, please do read some of the really useful guides out there on each, before submitting a support query. If you have any guides you’d like to share in the comments, they are more than welcome too!
Other Updates
Some of you may notice there is an ‘address’ and ‘URL encoded Address’ field within the ‘URL Info’ tab in the lower window pane. This is because we have carried out a lot of internal research around URL encoding and how Google crawl and index them. While this feature isn’t as exiciting as those above, it’s a fairly significant improvement.
When loading in crawl files saved from previous releases the new ‘URL Encoded Address’ and ‘Address’ are not updated to the new behaviour implemented in version 4.0. If you want this information to be 100% accurate, you will need to re-crawl the site.
We have also performed other bug fixes and smaller updates in version 4.0 of the Screaming Frog SEO Spider, which include the following –
- Improved performance for users using large regex’s in the custom filter & fixed a bug not being able to resume crawls with these quickly.
- Fixed an issue reported by Kev Strong, where the SEO Spider was unable to crawl urls with an underscore in the hostname.
- Fixed X-Robots-Tags header to be case insensitive, as reported by Merlinox.
- Fixed a URL encoding bug.
- Fixed an bug where the SEO Spider didn’t recognise text/javascript as JavaScript.
- Fixed a bug with displaying HTML content length as string length, rather than length in bytes.
- Fixed a bug where manual entry in list mode doesn’t work if a file upload has happened previously.
- Fixed a crash when opening the SEO Spider in SERP mode and hovering over bar graph which should then display a tooltip.
Small Update – Version 4.1 Released 16th July 2015
We have just released a small update to version 4.1 of the Screaming Frog SEO Spider. There’s a new ‘GA Not Matched’ report in this release, as well as some bug fixes. This release includes the following –
GA Not Matched Report
We have released a new ‘GA Not Matched’ report, which you can find under the ‘reports’ menu in the top level navigation.
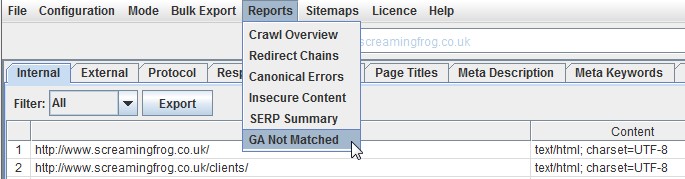
Data within this report is only available when you’ve connected to the Google Analytics API and collected data for a crawl. It essentially provides a list of all URLs collected from the GA API, that were not matched against the URLs discovered within the crawl.
This report can include anything that GA returns, such as pages in a shopping cart, or logged in areas. Hence, often the most useful data for SEOs is returned by querying the landing page path dimension and ‘organic traffic’ segment. This can then help identify –
- Orphan Pages – These are pages that are not linked to internally on the website, but do exist. These might just be old pages, those missed in an old site migration or pages just found externally (via external links, or referring sites). This report allows you to browse through the list and see which are relevant and potentially upload via list mode.
- Errors – The report can include 404 errors, which sometimes include the referring website within the URL as well (you will need the ‘all traffic’ segment for these). This can be useful for chasing up websites to correct external links, or just 301 redirecting the URL which errors, to the correct page! This report can also include URLs which might be canonicalised or blocked by robots.txt, but are actually still indexed and delivering some traffic.
- GA URL Matching Problems – If data isn’t matching against URLs in a crawl, you can check to see what URLs are being returned via the GA API. This might highlight any issues with the particular Google Analytics view, such as filters on URLs, such as ‘extended URL’ hacks etc. For the SEO Spider to return data against URLs in the crawl, the URLs need to match up. So changing to a ‘raw’ GA view, which hasn’t been touched in anyway, might help.
Other bug fixes in this release include the following –
- Fixed a couple of crashes in the custom extraction feature.
- Fixed an issue where GA requests weren’t going through the configured proxy.
- Fixed a bug with URL length, which was being incorrectly reported.
- We changed the GA range to be 30 days back from yesterday to match GA by default.
I believe that’s everything for now and please do let us know if you have any problems or spot any bugs via our support. Thanks again to everyone for all their support and feedback as usual.
Now go and download version 4.1 of the SEO Spider!






With these 2 updates you guys rock the world. Both are awesome features, and must have for any seo tool.
Nice! I love your new features! Thank you for this update!
Great tool, thanks for keeping up with new features.
Love the Analytics functionality guys, thanks for this great update.
Was just wondering, where’s the ‘too short’ option gone from the H1 and h2 dropdown fields? That’d be nice to have back again!
Hey Luke,
Good to hear it’s helping!
We actually removed those filters back in November 2012. So maybe you were using a really old version?
We felt they were not particularly useful, as headings can be pretty short!
Cheers for the feedback!
Dan
Cheers for clarifying Dan,
My bad, I was actually looking for same on Page Title tab, not H1, and they’re in there alright! Just a bit lost in the new nav, great update nonetheless!
Cheers,
Luke
Ahh, that makes sense and no worries!
Cheers Luke!
Great update! I’ve already lost an hour just exploring the new Analytics functionality!
Nice that you bundle the updates so you dont have to update every week.
Looking forward to testing the GA funktion.
I was waiting for this integration. Good Job!!!
I’ve just bought a license as I’m trying to extract all anchor elements that have an ID that starts with ‘Interstitial’ but so-far having no joy. I’m using Configuration > Custom > Extraction. I’m using this Xpath : //a[starts-with(@id, ‘Interstitial’)] but it only seems to get one hit per-page – I need it to get all of them as there is lots – can you help with this?
Hey Jon,
It will be one per filter currently, there’s no way to collect multiple elements I’m afraid (just yet!).
Cheers.
Dan
Ok, shame, but thanks for the info. Is there a good alternative to this requirement – or – when will this functionality be added? Thanks
Just added this to our FAQ as we build up more use cases – https://www.screamingfrog.co.uk/seo-spider/faq/#all_tags_matching_xpath
We did give this some consideration pre release and have this on our development list to add. Do you want to pop through an email to support (https://www.screamingfrog.co.uk/seo-spider/support/), I’d be interested in hearing how you’d like this to work (we could separate the data using commas, pipes etc).
Cheers.
Dan
Great news :) Now all the necessary data will be in one tool :)
Hi Dan, awesome to include the extract feature, this is truly great and saves a great deal of time switching between Screaming Frog & SEO Tools for Excel.
Question — for a regex match like http://regexr.com/3bbh8 <– Screaming Frog is pulling in multiple lines when I'd expect it to stop at the highlighted query. Any ideas?
Hey Stephen,
Very cool to hear :-)
Just put together an FAQ for this one as well, which you can read here – https://www.screamingfrog.co.uk/seo-spider/faq/#regex_extracts_too_much
Cheers.
Dan
What a huge update! Really excited to use the new custom extract feature, so many possible uses. There were a handful of times I needed a specific item that wasn’t available in the normal crawl.
Superb, this was the update I needed to stop messing about with 80 Legs for most of my crawls!
Any update increase my statisfaction, I discovered you some years ago!
Interesting update, though I can see some usabilities problems on the ga use, especially when it covers to the date selection.
That would be more useful to be asked prior a crawl start rather than being confined into a relatively hidden configuration tab.
Hope it makes sense.
Hi Andrea,
We had an internal debate whether to include ‘date’ within the initial account tab.
However, the argument was that this is very much an ‘account’ tab and ‘date’ in theory has no place there. It was a difficult one, we had it the other way around to start with!
Having a separate tab for ‘date’ (which I’d argue is pretty clear to see still) also allows us to add additional presets in time to cover different date ranges etc as well.
Cheers for the feedback.
Dan
Wow. thanks for the GA Integration.
Holy Sh*t YES YES YES xpath scraping has been the one missing feature on this tool!
Amazing work!
Hahaha! Cheers John, good to hear you like!!
Dan
What an awesome job you guys do!!!
I can’t nearly imagine any SEO person without Screaming Frog now!
This is some of the best news I’ve had all year. Goodbye vlookup, hello GA Integration!
Wawww it’s a great update ! Good job
Very well done! I’m already testing the new features for my tasks and projects and it really makes work easier. ;)
Thanks and all the best!
Great new features guys, Christmas come early! Really looking forward to trying some of these out :)
Very nice update – thanks guys.
I just love the screaming frog.
It makes my job soooo much easier.
Thanks for Analytics and xPath additions.
Finally! Scraping! Thanks!
These are really powerful updates, turning points in in how to integrate and analize on-page factors within one tool. Congrats!
As we may use the Analytics feature addictively it would be great to have a timestamp option (analytics_sessions_above_0_today’s_date) when exporting, so that you do not accidentally overwrite previous exports. Thanks
I wasn’t using this tool for a long time, but with these new features i’m gonna give him a second chance. It seems a lot more useful now. Good job guys :)
holy you-know-what!
really awesome update – can’t wait to see what comes from this!
hope to see some video training sessions on how people are using this.
Wish there was a Master Class on this somewhere – please let us know if you start to make or see them.
There’s something new to learn every day!
keep up the really awesome work!
Fantastic! I’m using these new features as I type this. Great work.
Hi. Both features are perfect. I will use them daily.
I had to for search using Open/Google Refine and pairing pages with GA data via Excel.
Is possible to make feature that will find hidden content – cloaking?
Thanks.
I can’t get the schema or open graph custom extractors to work.
I got it!
These look beast! Good Work SF, I tip my hat to you all.
I’m not the greatest with xpath, is there any way I could pull a whole group of specific schema elements, kind of like how you pull the OG and Twitter elements?
Hi Alex,
Sorry, I missed this completely.
We have some examples for Schema above, but depends on what you want to extract specifically. Pop through what you want to do with a live example (https://www.screamingfrog.co.uk/seo-spider/support/) and we can help.
Cheers.
Dan
excellent- thanks for the update!
Any tips on how to extract multiple instances of the same code using regex? I can extract the first match but not the multiple matches on the same page.
Hi Fabrizio,
We have an FAQ over here which might help – https://www.screamingfrog.co.uk/seo-spider/faq/#regex_multiple_matches
Thanks,
Dan
Best update of the year, and for sure !
Orphan Pages identification is a must !
Add your http log files to this and your are the king of the world :)
Fantastic! I’m using these new features as I type this. Great work
Thanks for this great tool, thanks for keeping up with new features.
Great new features, but it would really be useful if you could add this scraping feature to XML sitemaps as well. For example, I’d like to be able to extract hreflang and mobile annotations for each URL in an XML sitemap and as far as I can tell, this is currently not possible with the current version of your software.
Hi Gabe,
We plan on developing these as proper features, rather than developing the ability to scrape an XML sitemap.
Cheers.
Dan
Were you planning to refresh the graphic design of your program in the future?
I think your application is excellent – very intuitive and useful but the interface is a little bit archaic :)
Heheheh! Thanks Szymon.
A face only a mother could love ;-) I won’t argue with that, but we’ve heard that’s also kinda part of the Spider’s appeal!
We may update in the future though, you can switch to a Windows look and feel if you’d prefer (under Configuration > User Interface).
Cheers.
Just had a quick look but it looks great again. Love the Analytics integration.
Love the Analytics functionality guys, thanks for this great update. I’ve already lost an hour just exploring the new Analytics functionality! The best tool.
We are waited for this update for a long time. Our customers will certainly appreciate it – reports will be more valuable :)
Hello,
Really great addition.
Can you please tell me to what value Sessions corresponds to in GA?
I mean, I’m not seeing the same numbers for GA sessions in SF vs GA.
Does that correspond to Entrance, Unique Pageviews?
Thatt’s what I see if I look at Landing pages
http://i.imgur.com/9Hu3XvE.jpg
Thanks
Hi Nadeer,
Thanks!
It looks like you’re looking under ‘behaviour > site content > all pages’ in GA, when the default dimension in the SEO Spider is for landing pages, which you can see under ‘behaviour > site content > landing pages’. For ‘pages’ entrances, is the same thing as LP sessions.
There are some reasons they might not match 100% (and are actually more accurate than in GA) discussed here – https://www.screamingfrog.co.uk/seo-spider/faq/#ga_data_match
Cheers.
Dan
Hey Dan,
Oh….I see, I should have noticed that ahah, now it makes more sense, thanks!
Very good update! I am already 2 hours in trying to comprehend it all!
Due to a custom GTM config, my url on analytics are slightly different than the URL on screaming frog.
So, no matches.
I have tried to with URL rewriting but no way… any suggestion?
Hey VSEO,
We cover the common causes and offer some suggestions over here – https://www.screamingfrog.co.uk/seo-spider/faq/#no_ga_data
We always recommend keeping one ‘untouched’ Google Analytics view. Perhaps a new view (without filters, or with) to match URLs might work in the longer-term!
Cheers.
Dan
Very nice update. Great work!
Hi Dan,
Very cool GA integration.
This update add lot of value at the crawling process
You have become an indispensable tool
Many thx ;) from Spain
Seriously good updates, guys. Seriously good.
Great to see an integration with Search Console! It would be great to have the top 10 keywords per URL like in URL Profiler. ;-)
Thanks Benoît!
Think you left this on the wrong post (should have been 5.0?), but appreciate the suggestion.
Cheers.
Dan
Hi Screaming Frog Team,
I really like this new version , thanks.
Do you know if we would be able to extract the Twitter user name from a list of url ? What would be the regex ?
We indeed need to get the Twitter names, in addition to emails, from a list of urls.
For instance, let’s say that on this url, http://www.testurl.com, I want to extract the Twitter account that is published on it. How could I do that ?
Thanks a lot for help
Hi Raul,
A regex like this should work –
twitter.com/(.*?)[‘”]
Or
twitter.com.*?twitter.com/(.*?)[‘”]
Depending on what you want to collect! ;-)
Cheers.
Dan
Many thanks for the answer. I tried with no success on this page:
techdivision.com/blog/viernull-das-neue-kostenlose-online-magazin-fur-industrie-4-0-und-das-internet-der-dinge/
You will see at teh bottome of the page twitter name
<a href="https://twitter.com/name……
Do you think we can extract https://twitter.com/name ?
Thanks again
Ah, thanks for the example. This regex will work :-) –
(https://twitter.com/.*?)”
Cheers.
Dan
Thanks for the advice.
I tried the code with no success, end the field Extractor1 remains empty. Maybe you should try with the url I sent you.
It works, but the quotations in a web page come out differently, so copy it from here –
http://pastebin.com/7Vjb5UNH
Moving forward, just send an email to support where we will be able to respond a lot quicker – https://www.screamingfrog.co.uk/seo-spider/support/ :-)
Cheers
Dan
Great tool. Thanks guys for keeping up the good work :)
I was waiting for this integration. Great tool!!!
Superb. Good update, guys. I love your tool. Use it every day :)
Tengo una pregunta,
Como podría extraer la Url + etiqueta titulo + Alt de una imagen “”
Utilizo Screamingflog –> Custom
y me gustaría poder sacar esa información utilizando Xpath o Csspath …
seria de mucha ayuda!
Hey Victor,
I am using Google translate to understand the query and respond.
You mind popping through to support – https://www.screamingfrog.co.uk/seo-spider/support/?
We can try and help!
Cheers.
Dan
Hervorragend. Gute Update , Jungs. Ich liebe dein Werkzeug . Verwenden Sie es jeden Tag :)
You do indeed live up to the name Screaming Frog. Well done!
Also nice to have a tool that support Mac.
The tools works perfectly for small and medium size sites. I’ve been able to get all urls within hours.
But the only issue i face is with large sites with atleast, 100k total links.
Though i’ve extended the ram till 4 Gb out of 8 Gb (i’ve had 4 gb ram before) but still i face hanging problem in the system due to the tool.
4 gb takes the tools and rest processes face hard time to process like excel or anything.
You guys working towards this ?
Hey Mera,
Thanks for the comment. If you have 8GB of RAM in a 64bit machine, I recommend allocating it all – https://www.screamingfrog.co.uk/seo-spider/user-guide/general/#memory
You should then be able to crawl fairly sizeable websites. The amount of memory required does depend on the website, but it should be good for 100k in most situations!
I have about 8GB allocated in a desktop at home, and have crawled a lot more.
We are working towards more scalable solutions as well anyway.
Cheers.
Dan
Thanks Dan for the prompt reply.
Will do the trick!
I wish you guys all best, your tool is the best SEO tool so far (My all time favorite too).
Thanks!
Great update, looking forward to it.
We use this tool on daily basis for our clients. Didnt even knew that it was updated, but hey. Thanks
Where can i report a bug? We use this weekly, but recently i had a bug everytime i used the tool. The same bug.
Still at great tool.
Hey Daniel,
Please do pop through to us here –
https://www.screamingfrog.co.uk/seo-spider/support/
Cheers.
Dan
Why do I download urlprofiler on urlprofiler.com and my antivirus software says there is a virus. Is it safe?
We’re migrating an old GA (hardcoded) set up to a GTM verison – we’re seeing some discrepancy as you;d expect, but its a bit too far. We want to verify that Tag Manager is across all the page / same pages as the old set up to rule out issues. How would I do the same Search / Extraction funciton for the UA code but for our GTM account?
Hey Will,
You’re commenting on an old blog post from 2015, which I only just caught.
Perhaps pop through your query to us via support (https://www.screamingfrog.co.uk/seo-spider/support/) and we can help?
Cheers.
Dan