Screaming Frog SEO Spider Update – Version 5.0
Dan Sharp
Posted 4 September, 2015 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 5.0
In July we released version 4.0 (and 4.1) of the Screaming Frog SEO Spider, and I am pleased to announce the release of version 5.0, codenamed internally as ‘toothache’.
Let’s get straight to it, version 5.0 includes the following new features –
1) Google Search Analytics Integration
You can now connect to the Google Search Analytics API and pull in impression, click, CTR and average position data from your Search Console profile. Alongside Google Analytics integration, this should be valuable for Panda and content audits respectively.

We were part of the Search Analytics beta, so have had this for some time internally, but delayed the release a little, while we finished off a couple of other new features detailed below, for a larger release.
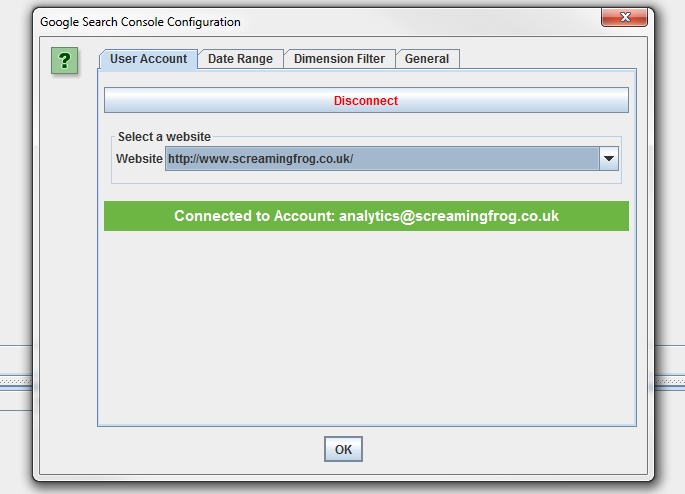
For those already familiar with our Google Analytics integration, the set-up is virtually the same. You just need to give permission to our app to access data under ‘Configuration > API Access > Google Search Console’ –

The Search Analytics API doesn’t provide us with the account name in the same way as the Analytics integration, so once connected it will appear as ‘New Account’, which you can rename manually for now.

You can then select the relevant site profile, date range, device results (desktop, tablet or mobile) and country filter. Similar again to our GA integration, we have some common URL matching scenarios covered, such as matching trailing and non trailing slash URLs and case sensitivity.
When you hit ‘Start’ and the API progress bar has reached 100%, data will appear in real time during the crawl under the ‘Search Console’ tab, and dynamically within columns at the far right in the ‘Internal’ tab if you’d like to export all data together.
There’s a couple of filters currently for ‘Clicks Above 0’ when a URL has at least a single click, and ‘No GSC Data’, when the Google Search Analytics API did not return any data for the URL.
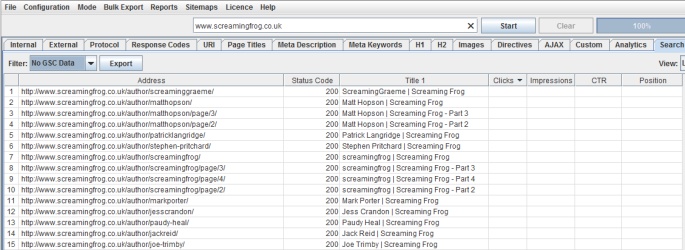
In the example above, we can see the URLs appearing under the ‘No GSC Data’ filter are all author pages, which are actually ‘noindex’, so this is as expected. Remember, you might see URLs appear here which are ‘noindex’ or ‘canonicalised’, unless you have ‘respect noindex‘ and ‘respect canonicals‘ ticked in the advanced configuration tab.
The API is currently limited to 5k rows of data, which we hope Google will increase over time. We plan to extend our integration further as well, but at the moment the Search Console API is fairly limited.
2) View & Audit URLs Blocked By Robots.txt
You can now view URLs disallowed by the robots.txt protocol during a crawl.
Disallowed URLs will appear with a ‘status’ as ‘Blocked by Robots.txt’ and there’s a new ‘Blocked by Robots.txt’ filter under the ‘Response Codes’ tab, where these can be viewed efficiently.

The ‘Blocked by Robots.txt’ filter also displays a ‘Matched Robots.txt Line’ column, which provides the line number and disallow path of the robots.txt entry that’s excluding each URL. This should make auditing robots.txt files simple!
Historically the SEO Spider hasn’t shown URLs that are disallowed by robots.txt in the interface (they were only available via the logs). I always felt that it wasn’t required as users should know already what URLs are being blocked, and whether robots.txt should be ignored in the configuration.
However, there are plenty of scenarios where using robots.txt to control crawling and understanding quickly what URLs are blocked by robots.txt is valuable, and it’s something that has been requested by users over the years. We have therefore introduced it as an optional configuration, for both internal and external URLs in a crawl. If you’d prefer to not see URLs blocked by robots.txt in the crawl, then simply untick the relevant boxes.
URLs which are linked to internally (or externally), but are blocked by robots.txt can obviously accrue PageRank, be indexed and appear under search. Google just can’t crawl the content of the page itself, or see the outlinks of the URL to pass the PageRank onwards. Therefore there is an argument that they can act as a bit of a dead end, so I’d recommend reviewing just how many are being disallowed, how well linked they are, and their depth for example.
3) GA & GSC Not Matched Report
The ‘GA Not Matched’ report has been replaced with the new ‘GA & GSC Not Matched Report’ which now provides consolidated information on URLs discovered via the Google Search Analytics API, as well as the Google Analytics API, but were not found in the crawl.
This report can be found under ‘reports’ in the top level menu and will only populate when you have connected to an API and the crawl has finished.
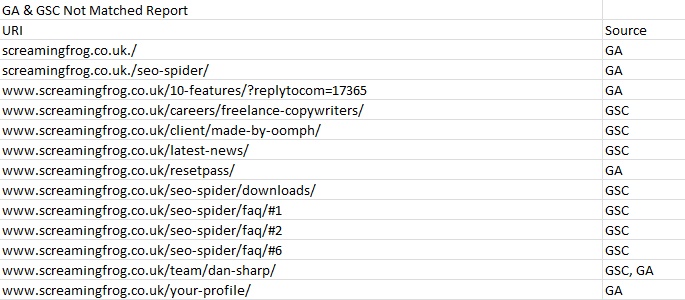
There’s a new ‘source’ column next to each URL, which details the API(s) it was discovered (sometimes this can be both GA and GSC), but not found to match any URLs found within the crawl.
You can see in the example screenshot above from our own website, that there are some URLs with mistakes, a few orphan pages and URLs with hash fragments, which can show as quick links within meta descriptions (and hence why their source is GSC rather than GA).
I discussed how this data can be used in more detail within the version 4.1 release notes and it’s a real hidden gem, as it can help identify orphan pages, other errors, as well as just matching problems between the crawl and API(s) to investigate.
4) Configurable Accept-Language Header
Google introduced local-aware crawl configurations earlier this year for pages believed to adapt content served, based on the request’s language and perceived location.
This essentially means Googlebot can crawl from different IP addresses around the world and with an Accept-Language HTTP header in the request. Hence, like Googlebot, there are scenarios where you may wish to supply this header to crawl locale-adaptive content, with various language and region pairs. You can already use the proxy configuration to change your IP as well.
You can find the new ‘Accept-Language’ configuration under ‘Configuration > HTTP Header > Accept-Language’.
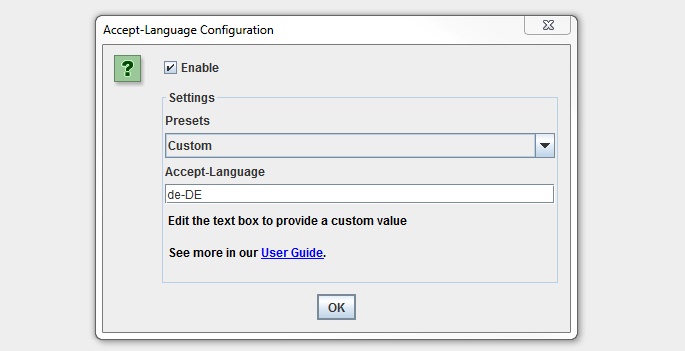
We have some common presets covered, but the combinations are huge, so there is a custom option available which you can just set to any value required.
Smaller Updates & Fixes
That’s the main features for our latest release, which we hope you find useful. Other bug fixes and updates in this release include the following –
- The Analytics and Search Console tabs have been updated to allow URLs blocked by robots.txt to appear, which we believe to be HTML, based upon file type.
- The maximum number of Google Analytics metrics you can collect from the API has been increased from 20 to 30. Google restrict the API to 10 metrics for each query, so if you select more than 10 metrics (or multiple dimensions), then we will make more queries (and it may take a little longer to receive the data).
- With the introduction of the new ‘Accept-Language’ configuration, the ‘User-Agent’ configuration is now under ‘Configuration > HTTP Header > User-Agent’.
- We added the ‘MJ12Bot’ to our list of preconfigured user-agents after a chat with our friends at Majestic.
- Fixed a crash in XPath custom extraction.
- Fixed a crash on start up with Windows Look & Feel and JRE 8 update 60.
- Fixed a bug with character encoding.
- Fixed an issue with Excel file exports, which write numbers with decimal places as strings, rather than numbers.
- Fixed a bug with Google Analytics integration where the use of hostname in some queries was causing ‘Selected dimensions and metrics cannot be queried together errors’.
Small Update – Version 5.1 Released 22nd October 2015
We released a small update to version 5.1 of the SEO Spider, which just include some bug fixes and tweaks as below.
- Fixed issues with filter totals and Excel row numbers..
- Fixed a couple of errors with custom extraction.
- Fixed robots.txt total numbers within the overview section.
- Fixed a crash when sorting.
That’s everything for this release!
Thanks to everyone for all the suggestions and feedback for our last update, and just in general. If you spot any bugs or issues in this release, please do just drop us a note via support.
Now go and download version 5.0 of the SEO Spider!






Great update as always!
The only thing thats lacking is the option to save the column order in the reports :)
Hey Emanuele,
Thank you, good to hear you like it.
Column ordering has been bumped up our ‘todo’ list for the next version. So you will be able to customise columns in the UI (and for reporting too).
Cheers for the nudge as well.
Dan
Still holding my breath, Dan :-)
Hi guys,
Thank you for the great work :)
Is there any chance for life-time license?
Hey Idan,
No worries, hope it helps out.
At this moment, we don’t have any plans for a life-time licence, just annual.
Cheers.
Dan
Could you contact me by email to get annual licence for agency?
Hey Dogan,
Please do drop us a note through to support about what you need, and we can help – https://www.screamingfrog.co.uk/seo-spider/support/
Thanks,
Dan
Still waiting for the lifetime license :)
Just picked up a license a few weeks ago for work on some bigger sites :)
I got super pumped when I saw the new feature to integrate Google Analytics data! This saves lots of time from having to append that data manually, and helps us make better decisions by letting us read a story told via metrics… <3
what about adding yandex metrika (metrica.yandex.com) support?
I’ve a similar question/problem
Good question. I’ll include it on our list to discuss for possible development!
Thanks for the suggestion.
Dan
When will you guys have an API for the entire program? Can’t wait for that day !!!
Another great update of this extremelly usefull software. Not just like you, i really love you guys :D Every SEO in the world must use your tool if he wants to rank well in SERP.
p.s. Same question as above asked by mr. Casano “what about adding yandex metrika (metrica.yandex.com) support?”
Thanks Dimitar!
To your query (and Antonio’s earlier), thanks for the suggestion. We will take a look :-)
Thanks for combining updates together in one release!
Excellent! This is going to save us a lot of time and Vlookup headaches.
Cheers Everett, good to hear!
Quick question, but is there a way to audit sitemaps across all URLs? For example, this URL is included in the sitemap – keep up the good work!
Hey John,
Quick answer, no, not right now – another on the list!
The only way to do it at the moment, is upload in list mode (you can upload the .xml file directly), crawl and compare against a site crawl.
Cheers.
Dan
Love it Dan. Love all the updates as always. Screaming Frog is indeed a tool that I can’t be without on my laptop. This is probably the only tool that I install on a new laptop after I install Chrome and some extensions :). Love it. Cheers.
Great Update! Been waiting for these features!
Going to love the blocked robots.txt function. Just another check to make sure that I don’t miss something!
The Google Search Analytics integration is awesome !! Thanx !
Best Update at this time ;-) i will stay tuned
Best Regards
Dan – probably obvious (haven’t tried it I admit!) but is it straightforward to connect GA/GSC to various/different IDs/Logins?
Many/most of us have different credentials based on client(s), so easy to add them all and swap around/choose?
Ta
(the best just gets better and better!)
Dan
(COYG)
Hey Dan,
Yeah you can add multiple Google Accounts (for GA / GSC), so it’s easy to just choose and switch to the one you want, you don’t need to re-type & re-authorise each time etc :-)
Cheers
Dan
How many links this spider software can crawl?
Any facility for unlimited pages crawl in this.
Hey Weddingplz :-)
It’s not unlimited I am afraid, you can read more in our FAQ over here – https://www.screamingfrog.co.uk/seo-spider/faq/#29
Cheers.
Dan
Best update! no i can view URLs disallowed by the robots.txt <3 Thank You Screaming Frog – work without You would be hard :)
How?
Number 2 in the blog post above :-)
Hello,
I don’t see very important info, which dissapears in version 5.0 => where is “from localization” eg. for external links (info about subpages where is highlighted, on the main table, external link) ?
In version 4.x it was in the bottom table (now is name and value column only).
??
Hi Bizzit,
We’ve never had anything named ‘from localization’?
I’m not entirely sure what you mean unfortunately either. You could revert back to 4.0 (amend the download URL from our SEO Spider download page) and send me a screenshot?
Cheers.
Dan
Great software, one of the best seo tools ever. keep up the good work!
A very useful tool. To me it helped a lot in finding all the links on my site. I learned a lot and I work with him regularly every day. Well done, keep up the bad work
What happen option a create sitemap is removed free?
thanks.. im used 4.0 is good work! … 5.0 not work more. dafuq
Hey Sandro,
The sitemap creation feature is still available in free!
Nothing has changed here between 4.0 and 5.0 :-)
Cheers.
Dan
Thats awesome! Good job guys.
Its great to see you guys evolving and continuing to be creative and innovative. Thanks for the analytics integration, means a lot.
cheers
Josh
I’m just getting starting using the tool, so far it has proved invaluable already at quickly highlighting ways to improve my site, many thanks for the free option
Your software is amazing! Saves heaps of time! :)
Keep up the good work.
The only missing still is being compatible with anyone who has a filter set up in their GA account to show the full URL.
Right now the GA results in SF still show blank.
Hey Tom,
Yeah, we haven’t included this as a option just yet (like matching trailing slashes or upper & lowercase characters).
Extended URI filters appear to be pretty common though, so we will do this at some point.
For now (if possible), I’d recommend just using a raw untouched ‘view’ in GA (always recommend everyone has at least one).
Cheers.
Dan
+1 for this. The problem with using your ‘No Filters’ view for this is that the point of the filters in some cases is rolling up reporting numbers when you’re working in the context of a terrible, legacy CMS with duplicate content mapped all over the place, so the analytics nums won’t be ‘right’.
All told I’m a huge fan & don’t want to ignore the many awesome features included in the last release – I just want to be able to use them! Thanks for all your hard work.
Amazing software. Great work!
This is the first version that does not run very well if I can get it to run. Most of the time I can’t even get it to launch unless I restart the computer and don’t run anything else. No problems at all with previous version. Maybe the overhead is much higher or something but it’s sad to see a great product start to have issues.
Hi Adam,
Sorry to hear you’re having problems, but this is lighter than previous versions and more powerful ;-)
First point of call, is to make sure you have the latest version of Java installed – http://www.java.com/en/download/manual.jsp. Obviously the 64bit version if you’re on a 64bit machine.
You didn’t mention what machine you’re using, but we have a couple of Mac specific issues covered in our FAQ (running slow on a Macbook Pro – https://www.screamingfrog.co.uk/seo-spider/faq/#46 or closing immediately – https://www.screamingfrog.co.uk/seo-spider/faq/#why_does_the_seo_spider_open_then_immediately_close).
If that doesn’t help, just pop through all the details to our support and we can help – https://www.screamingfrog.co.uk/seo-spider/support/. Our team are super quick!
Cheers.
Dan
Great software saves a lot of time each organic SEO, thanks
Nice update ! Thank you for your great job. :)
A really nice update with helpful features for SEO guys :)
Thanks.
Great release! Any plans to give visibility into the Google Search Console keywords?
Hi Anthony,
Thanks for the suggestion. Honest answer, probably not, but I’ll give it some thought. The guys are URL Profiler do this I believe, so I recommend checking them out.
We’ve added a filter so you can exclude/include certain keywords though which should make it more useful (so you can exclude brand etc).
Cheers.
Dan
Good software!)
Good job, guys.
This is a very helpful SEO Tool, how much is a lifetime Licence? After buying this latest version software after that, you can upgrade on software after I will pay with another money or one-time payment you can support with lifetime and upgrade automatically. I’m waiting for your answer.
Hey Solonia,
We only do an annual licence at the moment, which includes upgrades and support, too.
Cheers.
Dan
I use software to search expired domain on .edu and .gov websites. It’s very usefull for me. Thx ;)
thanks for the update
Super update, thanks ;)
The best software I worked with no doubt at all!
Most recommended SEO software today!
Can anyone provide some help? I am able to link to both GA and GSC, but there is no data in either of both tabs belonging to GA and GSC.
The columns for the page/URL analytics are empty. Based on what i have seen in other sites that reference the integration they have data being displayed? I am not really sure if I am doing something wrong here.
any help will be appreciated.
Cesar
Hi Cesar,
It sounds like a URL matching issue. This FAQ will help – https://www.screamingfrog.co.uk/seo-spider/faq/#no_ga_data
Thanks,
Dan
Hi, I can not find help using the error STATUS: DNS lookup failed. By this I can not find fault 405. Can I ask for help?
Hi Fenix,
You can find more details on error codes over here – https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#4xx_Client_Error
If you need any help, you can pop through the example to our support – https://www.screamingfrog.co.uk/seo-spider/support/
Cheers.
Dan
Are we able to save the search console data – so that we have a record past 90 days ?
Hi Cassi,
You can run a crawl, collect search console data for 90 days and save it as a project.
But you can’t just download search console data and save it (has to be part of the crawl etc).
Cheers.
Dan
Thanks for the update! :)
I ran a crawl and SF says there is no GA or SC data but yet when looking at both i see data. Any reason SF would say there is none when connected to the APIs?
Hey Jacob,
We’ve covered off the common reasons for you over here – https://www.screamingfrog.co.uk/seo-spider/faq/#no_ga_data
Cheers.
Dan
Great tool. I teach on this tool, on courses I teach!
:-)
hands down one of the best SEO tools out there!
Great update as always. This is very helpful SEO tool. Thanks!
I agree
Hi, first of all you would like to thank you for the amazing product you guys have, secondly when I’m crawling a site and the site has some URL’s that are blocked for robots, can I configure the the Frog in some way that it will still fetch the info blocked from crawling ?
thank you
Hi Tom,
Appreciate the kind words!
Yes, you can choose to ‘ignore robots.txt’ (under the spider configuration) to crawl pages which are blocked :-)
Cheers.
Dan
Thank you !
I have to admit that this tool has become my favourite SEO tool, cheers ;)
Antoine
Hi, I’d like to ask about the feature that shows URLs blocked by robots.txt. – Does this feature only works in the spider mode? What my problem is – when I upload a .txt file with URLs that I know they are blocked in robots.txt it didn’t show me that. I assume that this is because in list mode there can be 100 urls from 100 different domains and SF would have to check 100 different robots.txt files?
Hi Zico,
When you upload URLs in list mode, the ‘ignore robots.txt’ configuration gets automatically ticked (as it assumes you want to crawl them, not be blocked).
You can untick this box and then view URLs blocked by robots.txt.
Cheers.
Dan
Great software as always
Hi Dan, love the software and I like the GA integration a lot. However, I still run into quite a few urls not being matched with Analytics (where all GA cells remain empty), even when these page urls match exactly with the url in Analytics. Any idea what causes this and how this can be fixed? Or is there a limit on data being pulled from GA?
Hi David,
Thanks for the kind comments.
The limit is set to 100k in the settings (which you can change). We cover some of the common reasons for data not populating here as well –
https://www.screamingfrog.co.uk/seo-spider/faq/#why-doesnt-ga-data-populate-against-my-urls
Also, we explain ways to test it etc.
If you have a specific example, you can pop through to us at support as well – https://www.screamingfrog.co.uk/seo-spider/support/
But essentially, it’s generally just the URL doesn’t match, or the API isn’t returning it based upon the configuration chosen.
Cheers.
Dan
Hi I have a question, as soon as the program is being run-it does give the result in real time? wean we fixed a problem?
Hello :-)
Yes, the SEO Spider runs and displays data in real-time. So if you’ve fixed an issue, then run a crawl, it will give you the latest changes.
Obviously it doesn’t fix any issues for you, it just crawls and displays the data in real-time.
Cheers.
Dan
Hey, can i buy lifetime license?
Good job guys, one of the best seo tools ever!
Just purchased this tool 4 days ago and my technical understanding of SEO has increased dramatically already. I believe I’ll be using ScreamingFrog for a long time and every SEO that is serious should purchase it as well. Thank you guys!
Hey,
The Best Software for SEO, Best Price.
my favourite SEO tool,
Cheers,
Shay
I just downloaded the Screaming frog SEO, so just wanted to say thank you so much creating such a wonderful tool. Really really appreciate it a million.
Still my favorite tool – keep up the good work.
Great software!! one of the best SEO tools ever. save a lot of time very recommended
I know I’m late to the party but I this is hands down a must have tool. The GA integration is outstanding… our team wouldn’t be as efficient without it. Definitely had a few quirks at first but everything has come together smoothly. Thank YOU guys!
Excellent software.
Using it for some time.
Worth every penny
Screaming Frog is the best tool when you have to migrate from one domain to another. Last time I had to move site with almost 1 million URLs. Imagine how long would it take if I had to do it manualy.
Hi,
Great great software, very useful!
What about integrating a double spider for testing mobile websites (different user-agents) at the same time? I have to always launch 2 spidering sessions at a time…
Thank you!
Roberto
Wow! Simply my favorite tool for fixing errors and finding pages with “no response” for my clients websites. Great features and very precise compared to other SEO tools that I checked. Thank you Dan
The Google Search Analytics integration is awesome !! Thanx !
Excellent software.
Using it for some time
Love this Frog :)
My favorit tool! i always recommend my SEO students to use it.
Thank you!