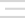
Screaming Frog SEO Spider Update – Version 2.30
Dan Sharp
Posted 20 March, 2014 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 2.30
I am really pleased to announce version 2.30 of the Screaming Frog SEO spider code-named ‘Weckl’. This update includes new features that provide greater control of crawls, as well as how the data is analysed. Thanks again to everyone for their continued feedback, suggestions and support.
We still have lots of features currently in development and planned on our roadmap, so we expect to make another release fairly soon. For now, version 2.30 of the SEO Spider includes the following –
1) Pixel Width Calculated For Page Titles & Meta Descriptions
Back in 2012 Google changed the way they display snippets in their search results. Historically this was simply a character limit of around 70 characters for page titles and 156 characters for meta descriptions. However, Google switched this to determine the actual pixel width of the characters used, which we believe is currently a limit of 512 pixels for page titles which they truncate with CSS. You may expect meta descriptions to be simply double this 512px div figure (1,024px), however they appear to be approximately 920 pixel width.
Page titles or meta descriptions with lots of thin characters (such as ‘i’ or ‘l’ etc) can have more characters than the old set limit. Conversely, if particularly wide characters are used, Google can show far less than the old limits. I believe the first experiments around this behaviour at the time were from Darren Slatten, who had already built a very cool SERP Snippet tool long before.
Therefore, while character counts are still useful, they are not a particularly accurate measurement for characters that will display in the SERPs. We have been meaning to calculate pixel width in the tool for sometime and with Google’s recent search result redesign we reverse engineered Google’s logic to calculate pixel width to provide greater accuracy.
You can read more about our analysis, emulator logic and caveats for this in our page title and meta description pixel width explanation post as it’s an interesting (!) discussion.
2) SERP Snippet Tool
We have also introduced a ‘SERP snippet’ emulator into the lower window tabs, which will show you how a page (when selected in the top window pane) might look in the Google search results based upon the pixel width logic described above.

The emulator provides detail on the width in pixels and how many pixels a title or description is over or under the limit. Please note, this won’t always be exact and it is our first iteration. This feature will be developed over time to include much more (like dates, item counts, rich snippets etc.), based upon the ever changing search results of Google (and possibly even other search engines).
3) Configurable Preferences
We have introduced a ‘preferences’ tab into the spider configuration which puts you in control over the character (and pixel width) limits and therefore filters for things like URLs, page titles, meta descriptions, headings, image alt text and image size.

So if you have performed your own research, or wish to amend the limits and filters in the interface, you can.
4) Canonicals Are Now Crawled
The SEO Spider now crawls canonicals whereas previously the tool merely reported them. Now if a URL has not already been discovered, the URL will be added to the queue and they will be crawled as a search bot would do.
Canonicals are not counted as ‘In Links’ (in the lower window tab) as they are not links in a traditional sense. Hence, if a URL does not have any ‘In Links’ in the crawl, it might well be due to discovery from a canonical. We recommend using the ‘Crawl Path Report‘ to show how the page was discovered, which will show the full path and whether it was via a canonical.
5) More In-Depth Crawl Limits
We have moved a few options into a ‘limits’ tab under the spider configuration and introduced new options such as limiting crawl by maximum URL length, maximum folder depth and by the number of parameter query strings.
I have been asked for a regex to exclude crawling of all parameters in a URL a lot over the past 6-months (it’s .*\?.* by the way), so this will mean users don’t have to brush up on regex to use the exclude function for query parameters. The new ‘limit number of query strings’ option can simply be set to ‘0’.
6) Microsoft Excel Support
We added Excel support for .xlsx and .xls for both writing and reading (in list mode).
The SEO Spider will automatically remember your preferred file type.
Other Smaller Updates
We also made a number of other smaller updates, tweaks and bug fixes which include the following items –
- Configuration for the maximum number of redirects to follow under the ‘advanced configuration’.
- A ‘Canonicalised’ filter in the ‘directives’ tab, so you can easily filter URLs which don’t have matching (or self referencing) canonicals. So URLs which have been ‘canonicalised’ to another location.
- The custom filter drop downs now have descriptions based on what’s inserted in the custom filter configuration.
- Support for Mac Retina displays.
- Further warnings when overwriting a file on export.
- New timing to reading in list mode when uploading URLs.
- Right click remove and re-spider now remove focus on tables.
- The last window size and position is now remembered when you re-open.
- Fixed missing dependency of xdg-utils for Linux.
- Fixed a bug causing some crashes when using the right click function whilst also filtering.
- Fixed some Java issues with SSLv3.
As always, please just drop support an email if you discover any issues or have any problems. As mentioned above, we are working on another release fairly imminently, so any issues with the above can be quickly resolved.
Please do update your SEO Spider now to try out all the new features.






You have made me beyond happy with this. I want to kiss a frog.
LOL – Thanks Travis!
Great News. Screaming Like..
Thanks Dan its always exciting when SF gets updated! Still waiting patiently for RegEx Find on URL to be added one day :)
Icing on the Cake!!
Great news about canonicals being crawled! probably my most wanted feature.
Just perfect :)
Cheers for the kind comments guys. Just included (for the next release) a configuration for canonical crawling.
There might be some circumstances you don’t want to crawl a canonical etc, it’s default will be to crawl though.
I am having real problems with getting this to run. im on windows 8.1 and after the screaming frog splash screen thingy all it is showing me is a java coffee cup icon and no programme :( java is working and is fully updated.
i have tried uninstalling and reinstalling a couple of times. Anyone else experiencing similar problems?
Hi Dave,
Our support page is over here with common issues – https://www.screamingfrog.co.uk/seo-spider/support/
Sounds like you need to install Java. If it’s already installed, uninstall & reinstall manually – http://www.java.com/en/download/manual.jsp
That should fix it. If not, please contact support as per the URL above.
Cheers.
Dan
Hadn’t seen this, ooops!(possibly should send an email when people reply to comments?)
I have emailed you.
Thanks,
Dave
Wow, I’m really impressed with the quick update for title tag pixel width and the preference filter is awesome. Thanks!
Boy, that query string feature would have been helpful last month!
Thanks for the update!
You guys, monster effort. Keep it up!
Another great update! Well done guys…
Thanks Dan! Pixel width and canonical crawl are very useful features.
really helpfull upgrade for CPU of my notebook :) thanks
pixel width is an amazing addition! Seems to be a lot lighter on system resources as well.
2) SERP
Really nice feature! Keep up the good work
A must have SEO tool and great updates. Thanks ! Antoine
really nice! great job!
SEO spider proves helpful for SEO learning guy like me. It saves a lot of time to analyze many seo elements. Thanks for developing this!