22 Ways To Analyse Logs Using The Log File Analyser
Dan Sharp
Posted 12 April, 2017 by Dan Sharp in Screaming Frog Log File Analyser
22 Ways To Analyse Logs Using The Log File Analyser
Log Files are an incredibly powerful, yet underutilised way to gain valuable insights about how each search engine crawls your site. They allow you to see exactly what the search engines have experienced, over a period of time.
Logs remove the guesswork, and the data allows you to view exactly what’s happening. This is why it’s vital for SEOs to analyse log files, even if the raw access logs can be a pain to get from the client (and or, host, server, and development team).
Why Log File Analysis Is Important
Log file analysis can broadly help you perform the following 5 things –
- Validate exactly what can, or can’t be crawled.
- View responses encountered by the search engines during their crawl.
- Identify crawl shortcomings, that might have wider site-based implications (such as hierarchy, or internal link structure).
- See which pages the search engines prioritise, and might consider the most important.
- Discover areas of crawl budget waste.
Alongside other data, such as a crawl, or external links, even greater insights can be discovered about search bot behaviour.
The Concept of Crawl Budget
Before we go straight into the guide, it’s useful to have an understanding of crawl budget, which is essentially the number of URLs Google can, and wants to crawl for a site.
Both ‘crawl rate limit’, which is based on how quickly a site responds to requests, and ‘crawl demand’, the popularity of URLs, change frequency and Google’s tolerance to ‘staleness’ in their index, all have an impact on how much Googlebot will crawl.
Google explain that “many low-value-add URLs can negatively affect a site’s crawling and indexing”. Their study found that the low-value-add URLs fall into the following categories, in order of significance.
- Faceted navigation and session identifiers.
- On-site duplicate content.
- Soft error pages.
- Hacked pages.
- Infinite spaces and proxies.
- Low quality and spam content.
So, it’s useful to avoid wasting time and energy crawling URLs like this, as it will drain activity and cause crawl delays for pages which are important.
In this guide, we’ve put together a big list of insights you can get from analysing log files in a variety of ways, using our very own Screaming Frog Log File Analyser software for inspiration.
1) Identify Crawled URLs
There’s plenty of ways to gather and analyse URLs from a site, by performing a crawl, Google Search Console, analytics, an XML sitemap, or directly exporting from the database and more. But none of those methods tells you exactly which URLs have been requested by the search engines.
The foundation of log file analysis is being able to verify exactly which URLs have been crawled by search bots. You can import your log file by just dragging and dropping the raw access log file directly into the Log File Analyser interface and automatically verify the search engine bots.
You can then use the ‘verification status’ filter to only display those that are verified and the ‘user-agent’ filter to display ‘all bots’ or just ‘Googlebots’, for example. It will then display exactly which URLs have been crawled under the ‘URLs’ tab in order of log events. Simple.

It will confirm which URLs have been crawled and they know exist, but at a more advanced level, it can help diagnose crawling and indexing issues. Perhaps you want to verify that Google is able to crawl URLs loaded by JavaScript, or if they are any old URLs from a legacy section still indexed.
2) Identify Low Value-Add URLs
Being able to view which URLs are being crawled and their frequency will help you discover potential areas of crawl budget waste, such as URLs with session IDs, faceted navigation, infinite spaces or duplicates. You can use the search function to search for a question mark (?), which helps identify areas of crawl waste, such as URL parameters.

In this instance, we can turn off threaded comments that WordPress automatically include. You can also click on the ‘URL’ column heading in the ‘URLs’ tab, which will sort URLs alphabetically. This will allow you to quickly scan through the URLs crawled, and spot any patterns, such as duplicates, or particularly long URLs from incorrect relative linking.
There’s lots of other ways to identify potential areas of crawl budget waste, which we continue to touch upon throughout this guide.
3) Most & Least Crawled URLs
The frequency at which Googlebot requests a page is based upon on a number of factors, such as how often the content changes, but also how important their indexer – Google Caffeine believe the page to be. While it’s not quite as simple as your most important URLs should be crawled the most, it is useful to analyse as an indication and help identify any underlying issues.
The URLs tab already orders URLs by ‘number of events’ (the number of separate crawl requests in the log file). There are individual counts for separate bots and the filter can be useful to only view specific user-agents.

You can click the ‘num events’ heading to sort by least.
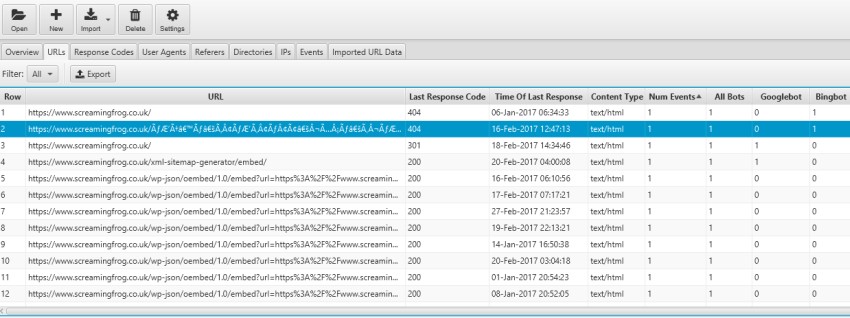
This may help you discover deeper issues with site structure, hierarchy, internal linking or more. At every step of the way when performing log file analysis, you can ask yourself whether Google is wasting their time crawling the URLs.
4) Crawl Frequency of Subdirectories
It’s also useful to consider crawl frequency in different ways. If you have an intuitive URL structure, aggregated crawl events by subdirectories can be very powerful.
You can discover which sections of a site are being crawled the most; service pages, or the blog, or perhaps particular authors.
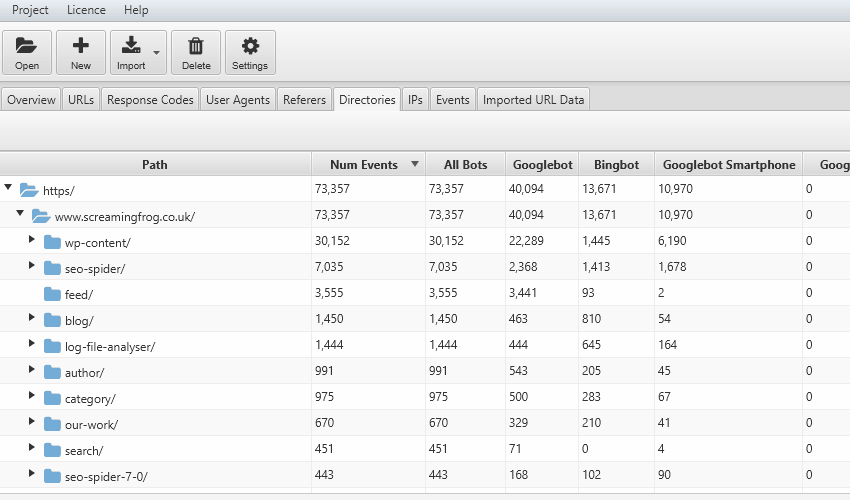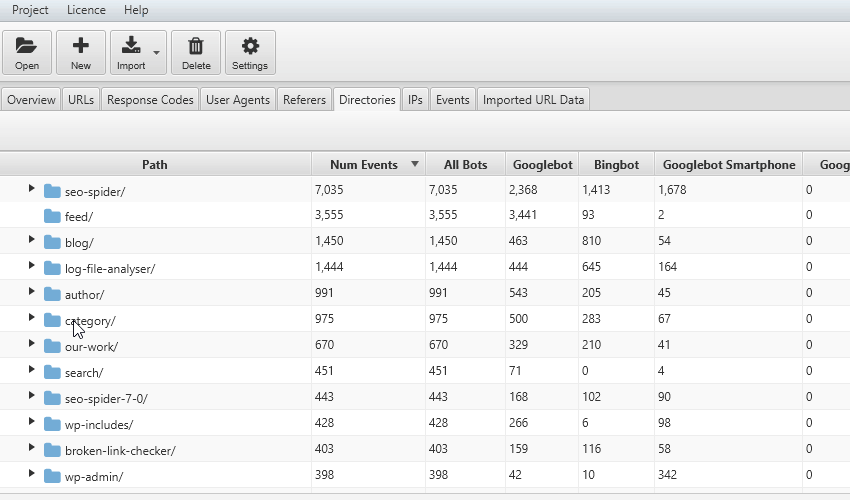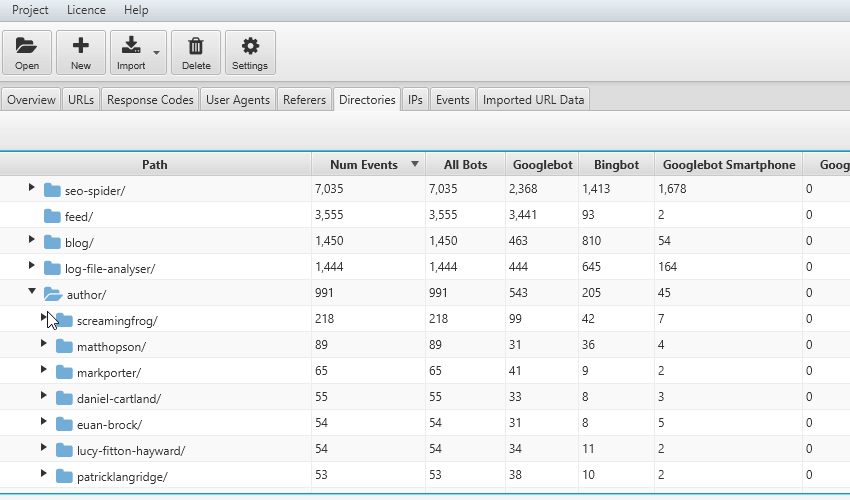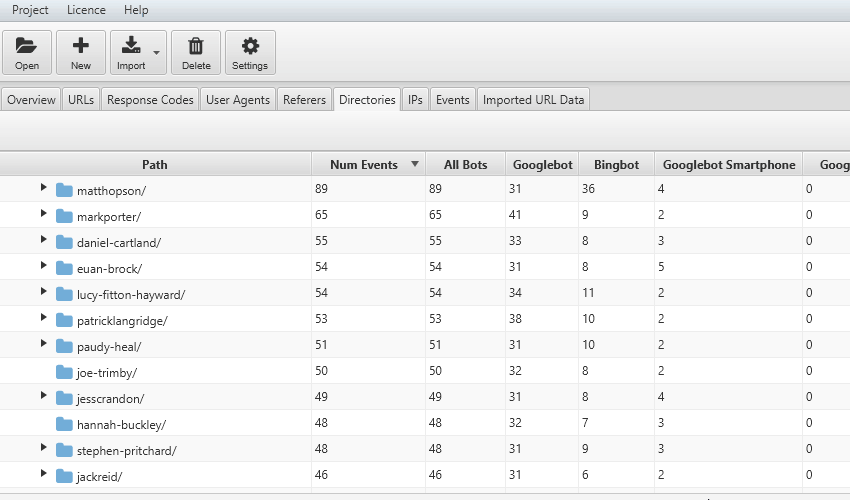
This also often makes it easier to spot areas of crawl budget waste.
5) Crawl Frequency by Content Type
While log files themselves don’t contain a content type, the Log File Analyser sniffs URLs for common formats and allows filtering to easily view crawl frequency by content type, whether HTML, Images, JavaScript, CSS, PDFs etc.
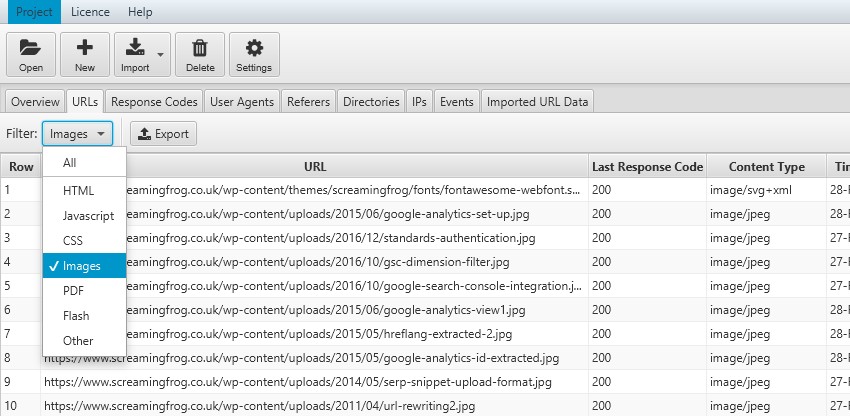
This allows you to analyse how much time proportionally Google is spending crawling each content type.
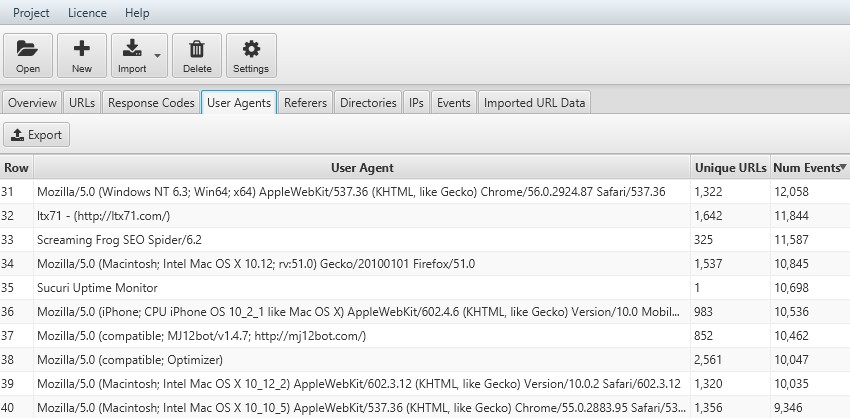
6) Crawl Frequency by User-Agent
You can analyse crawl frequencies of different user-agents, which can help provide insight into respective performance across each individual search engine.
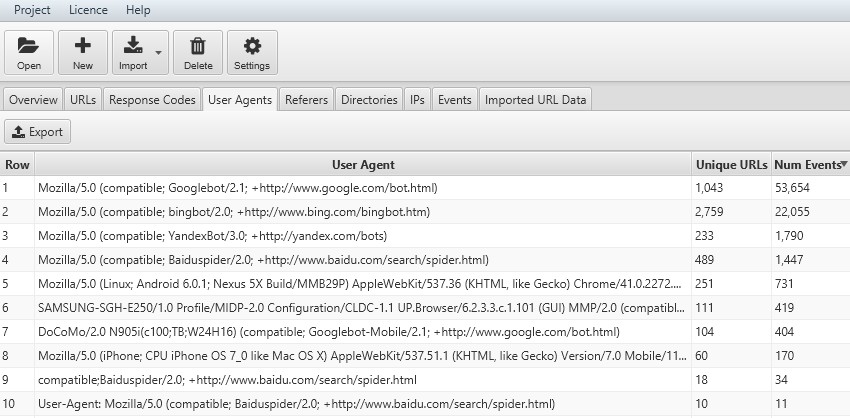
The number of unique URLs crawled over the time period you’re analysing, will give you a rough indication of how long each search engine might take to crawl all your URLs on the site.
7) URLs Crawled Per Day, Week or Month
Log file data can help guide you on crawl budget. They can show you how many unique URLs have been crawled in total, as well as the number of unique URLs crawled each day. You can then approximate how many days it might take for the search engines to fully re-crawl all your URLs.
In the ‘overview’ tab, the Log File Analyser provides a summary of total events over the period you’re analysing, as well as per day.
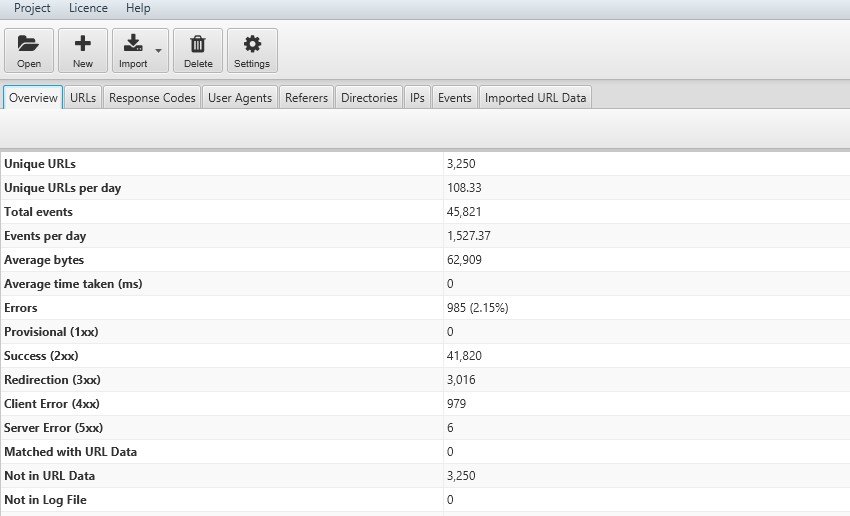
The graphs show the trends of response codes, events and URLs over time.
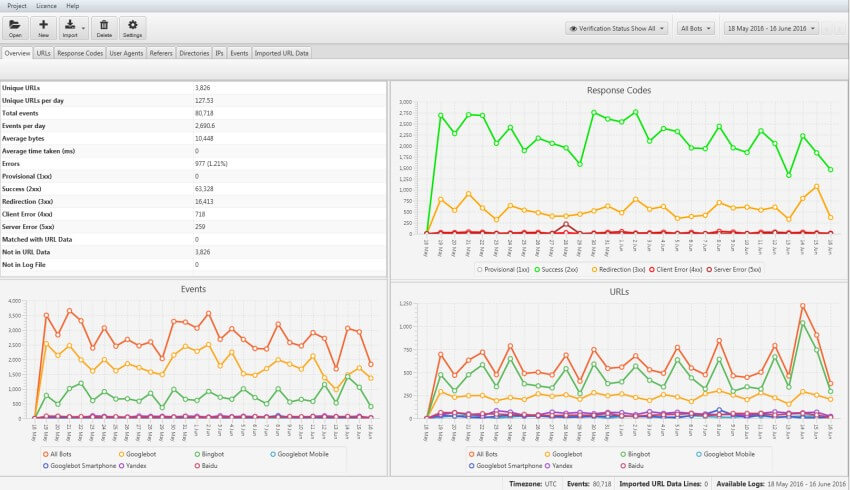
You can click on the graphs to view more granular data such as events, URLs requested or response codes for each hour of the day to identify when specific issues may have occurred.
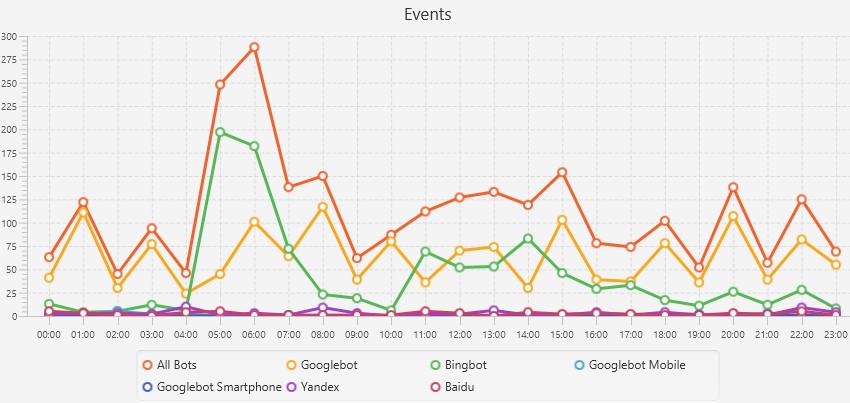
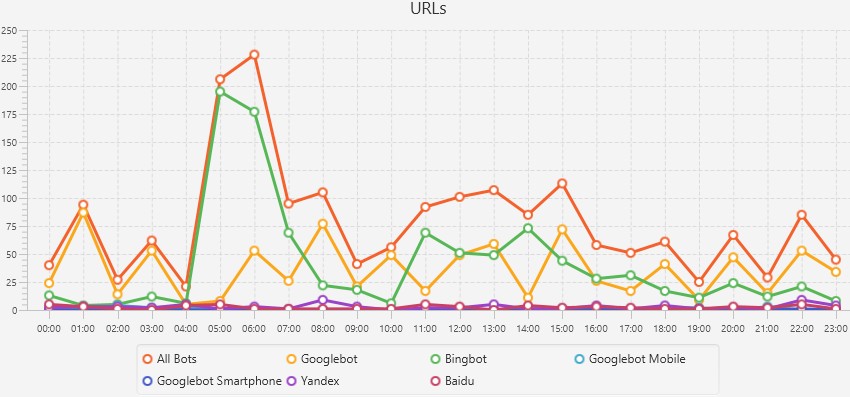

This is really useful if you’re analysing both general trends, or digging into a particular problematic URL.
8) Discover Crawl Errors (Broken Links or Server Errors)
Logs allow you to quickly analyse the last response code the search engines have experienced for every URL they have crawled. Under the ‘response codes’ tab, you can use the filter to view any 4XX client errors, such as broken links, or 5XX server errors. Only logs or Google Search Console’s fetch and render can provide this level of accuracy.
You can also see which are potentially the most important URLs to fix, as they are ordered by crawl frequency.
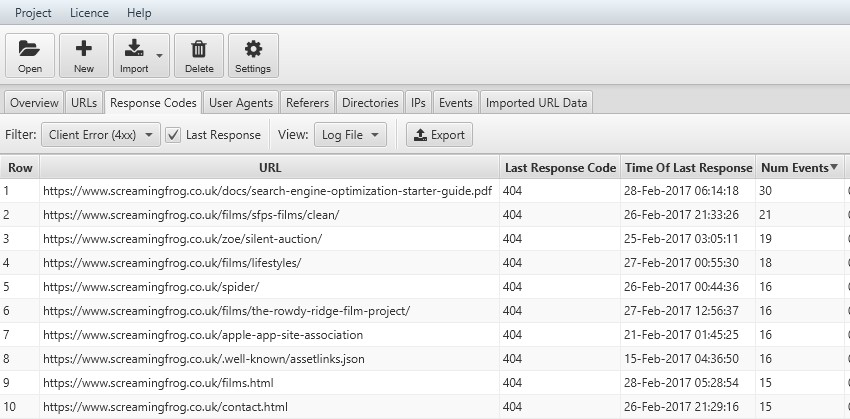
Remember to tick the ‘last response’ box next to the filter or the Log File Analyser will display URLs which have a matching event over time (rather than just the very ‘last response’), which leads us nicely onto the next point.
9) Find Inconsistent Responses
The Log File Analyser also groups events into response code ‘buckets’ (1XX, 2XX, 3XX, 4XX, 5XX) to aid analysis for inconsistency of responses over time. You can choose whether to view URLs with a 4XX response from all events over the time period, or just the very last response code shown in the example above.
You can use the filter to only view ‘inconsistent’ responses in more detail.
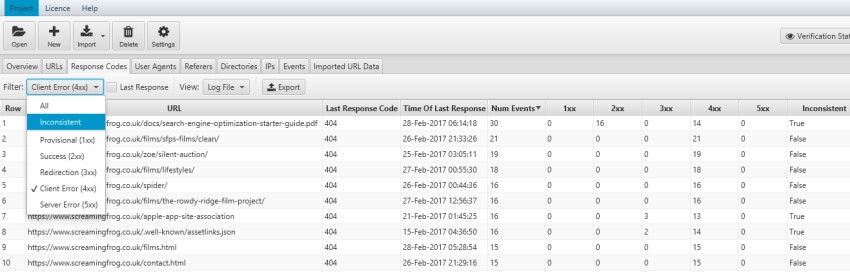
You might experience inconsistent responses as an example because a broken link has subsequently been fixed, or perhaps the site experiences more internal server errors under load and there is an intermittent issue that needs to be investigated.
10) View Errors by Subdirectories
With an intuitive URL structure, you can easily spot which sections of a website are experiencing the most technical errors, by viewing by subfolder.
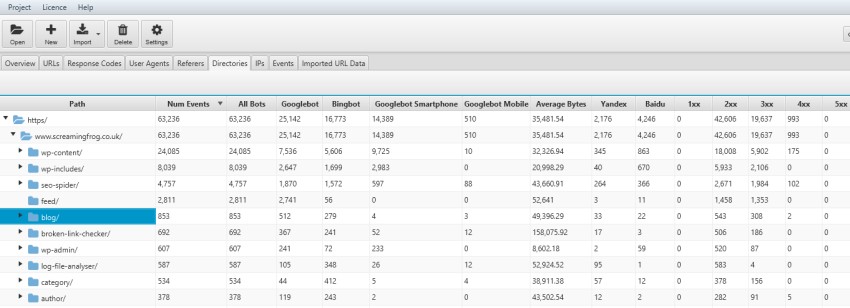
This can help diagnose issues impacting specific areas of the site, and help you prioritise where to focus your time.
11) View Errors Experienced by User-Agent
As well as viewing errors by URL or folder path, it can also be useful to analyse by user-agent to see which search engine is encountering most issues. Perhaps Googlebot is encountering more errors due to a larger link index, or their Smartphone user-agent is experiencing more 302 response codes, due to faulty redirects for example.
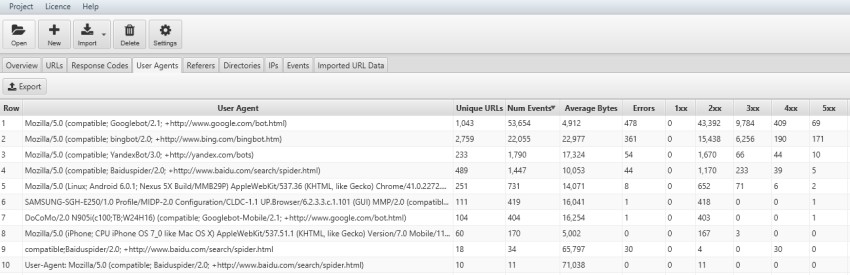
This granular level of analysis will help you spot any technical problems that need to be resolved.
12) Audit Redirects
You can view every URL that the search engines request that results in a redirect. So, this won’t just be redirects live on the site, but also historic redirects, that they still request from time to time. Use the ‘Response Codes’ tab and ‘Redirection (3XX)’ filter to view these, alongside the ‘last response’ tickbox.
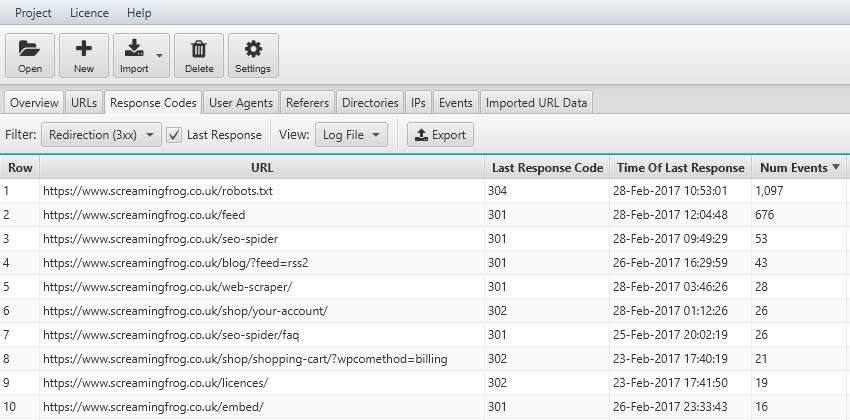
Remember, a 304 response is quite normal and just lets the search engines know the page hasn’t been modified, so there’s no need to send the document again.
13) Identify Bots & Spoofed Search Bot Requests
The IPs tab and ‘verification status’ filter set to ‘spoofed’ allow to quickly view IP addresses of requests emulating search engine bots, by using their user-agent string, but not verifying.
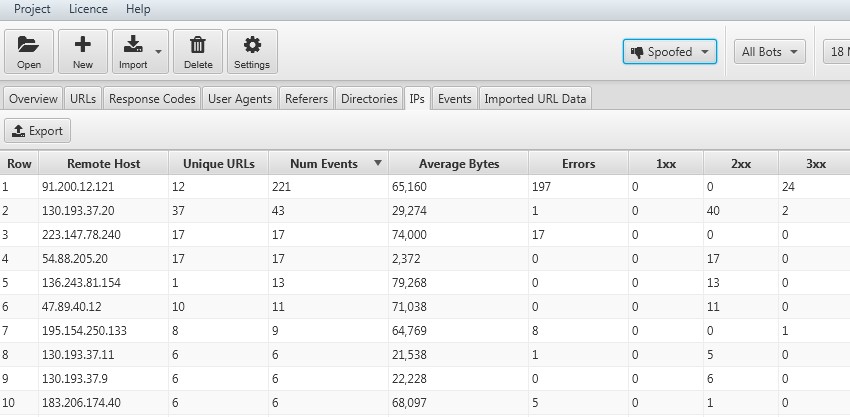
This might be you, or an agency performing a crawl, or it might be something else that you wish to block, and avoid wasting resources on.
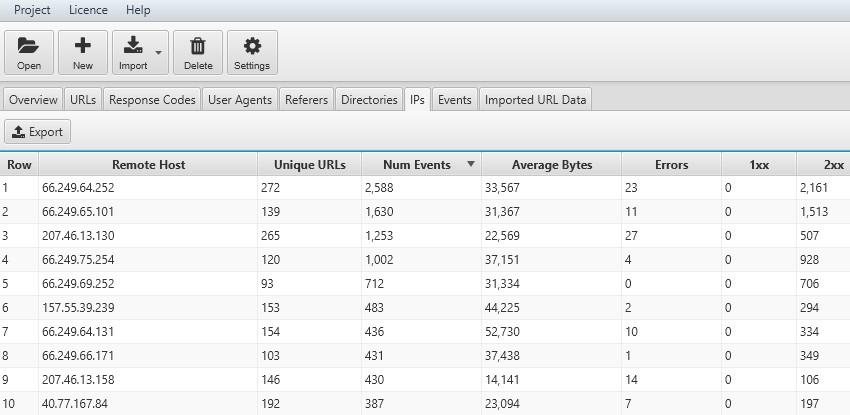
14) Verify Search Bot IPs
If you change the ‘verification status’ filter to ‘verified’, you can view all the IPs from verified search engine bots. This can be useful when analysing websites which have locale-adaptive pages and serve different content based on country.
Googlebot now supports geo-distributed crawling with IP’s outside of the USA (as well as within the USA), and they crawl with an Accept-Language field set in the HTTP header. By analysing IP, you can check which locations Google is accessing content and evaluate against country organic indexing and performance.
15) Identify Large Pages
We know that response times impact crawl budget, and large files will certainly impact response times! By analysing the ‘average bytes’ of URLs, it’s quick and easy to identify areas that could be optimised.
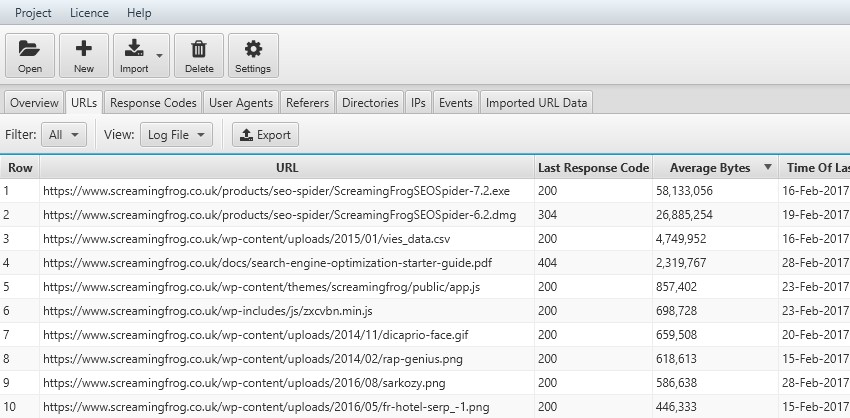
We can see that our SEO software, as well as CSVs, PDFs and images, are the largest on our website. There’s certainly some improvements that can be made there!
16) Identify Slow Pages
Slow responses will reduce crawl budget; so by analysing ‘average response time’ that the search engines are actually experiencing, you can identify problematic sections or URLs for optimisation.
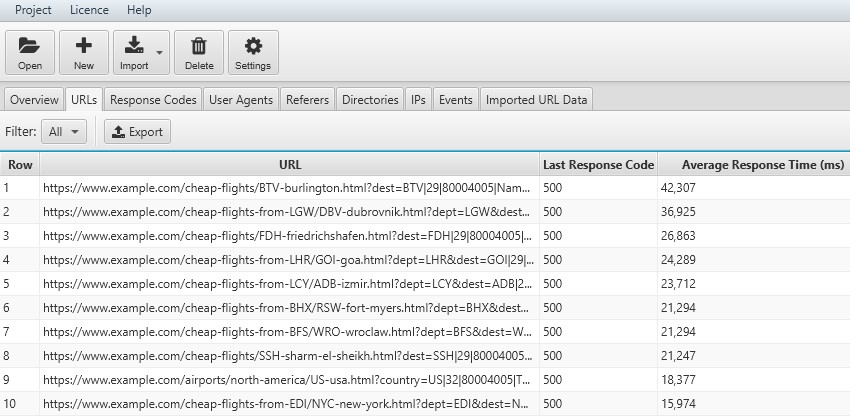
In this example, the pages with the highest average response time are 500 internal server errors. So, this is certainly something that requires further investigation.
17) Find Orphan Pages
By matching log file and crawl data, you can identify orphan pages. Orphan pages are those that the search engines know about (and are crawling) but are no longer linked-to internally on the website.
All you need to do is import a crawl by dragging and dropping an export of the ‘internal’ tab of a Screaming Frog SEO Spider crawl into the ‘Imported URL Data’ tab window. This will import the data quickly into the Log File Analyser ‘Imported URL data’ tab and database.
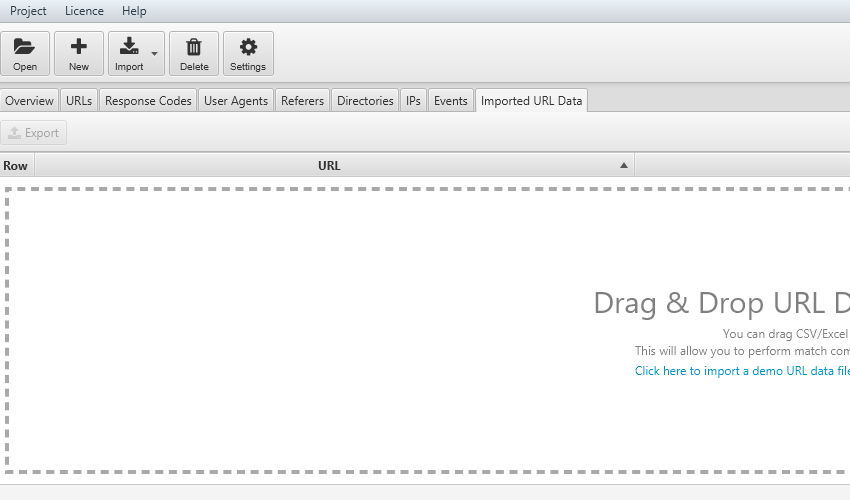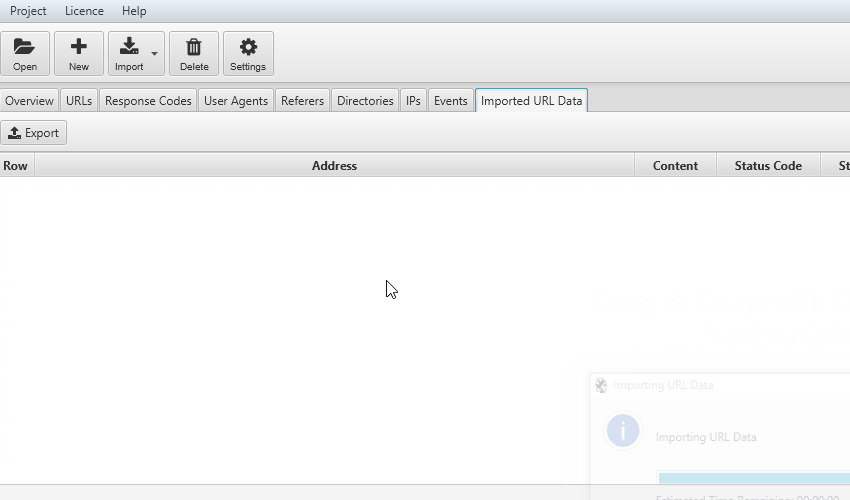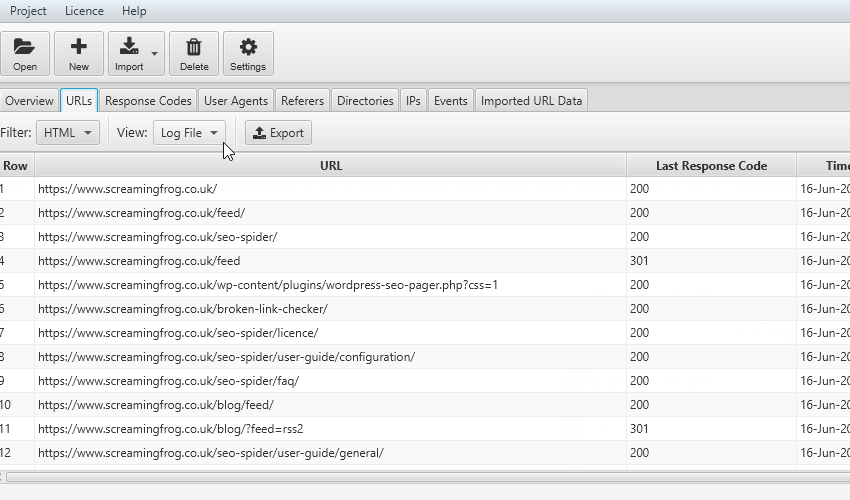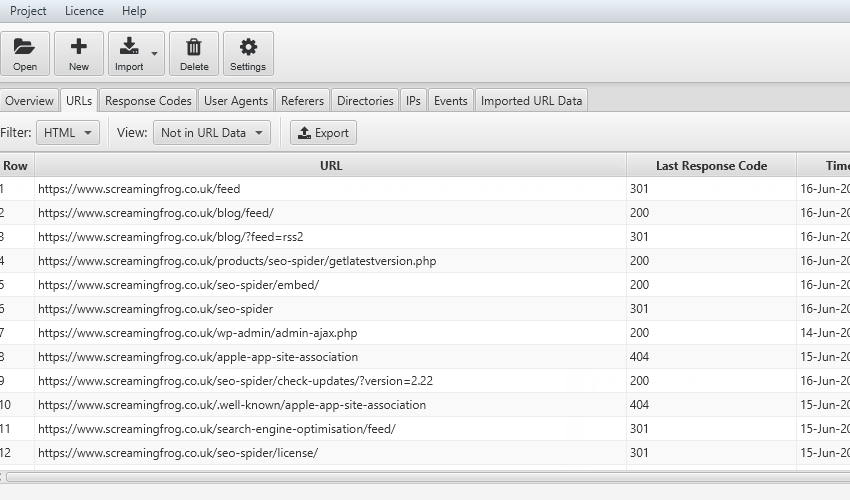
The ‘Imported crawl data’ tab only shows you the data you imported, nothing else. However, you can now view the crawl data alongside the log file data, by using the ‘View’ filters available in the ‘URLs’ and ‘Response Codes’ tabs. ‘Not In URL Data’ will show you URLs which were discovered in your logs, but are not present in the crawl data imported. These might be orphan URLs, old URLs which now redirect, or just incorrect linking from external websites for example.
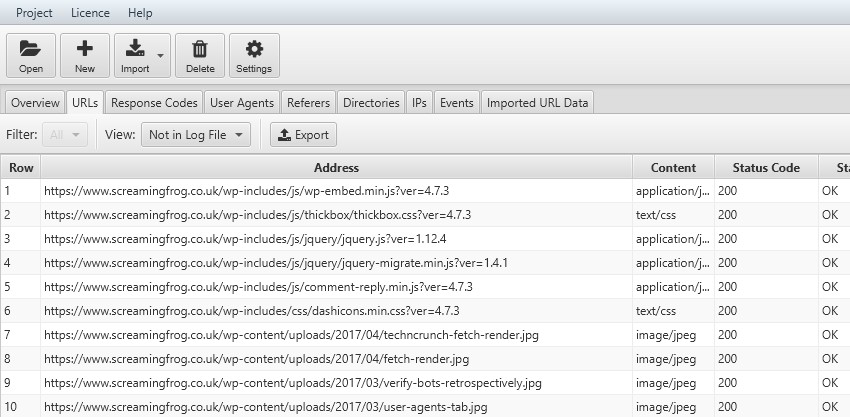
18) Discover Uncrawled URLs
After importing a crawl, the ‘Not In Log File’ filter will show you URLs which have been found in a crawl but are not in the log file. These might be URLs which haven’t been crawled by search bots, or they might be new URLs recently published for example.
19) Block Spam Bots
While we are mostly interested in what the search engines are up to, you can import more than just search engine bots and analyse them to see if there are any user-agents performing lots of requests and wasting server resource.
Respectful bots can then be blocked in robots.txt, or .htaccess can be used to deny requests from specific IPs, user-agents or unknown bots.
20) Analyse Crawl Frequency By Depth & Internal Links
After matching a crawl with logs, the ‘matched with URL data’ filter will allow you to view the depth (‘level’) of a page, and the number of internal ‘inlinks’, together alongside log file event data. This allows you to analyse whether changes to the depth or inlinks to a page have an impact on crawl frequency and perceived importance to the search engines.
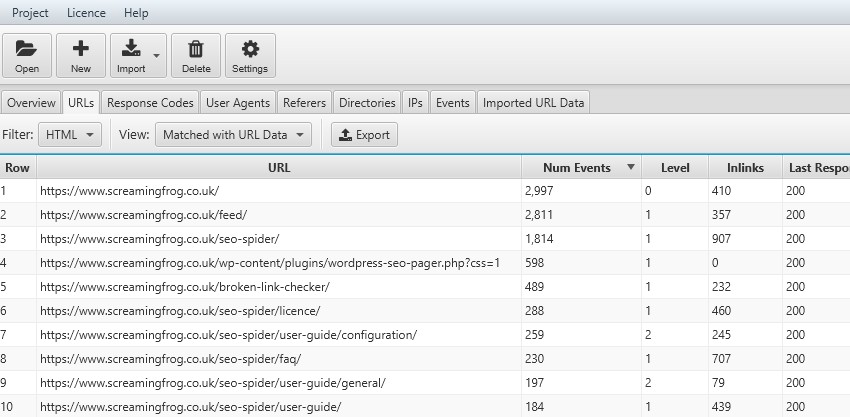
You can export into a spreadsheet easily, and count up the number of events at varying depths and internal link counts for trends. This can help you identify any issues with hierarchy and site structure.
21) Crawl Frequency By Meta Robots & Directives
Matching a crawl with logs also allows you to see the impact of directives, such as whether URLs that are canonicalised or have a ‘noindex’ tag decrease in crawl frequency.
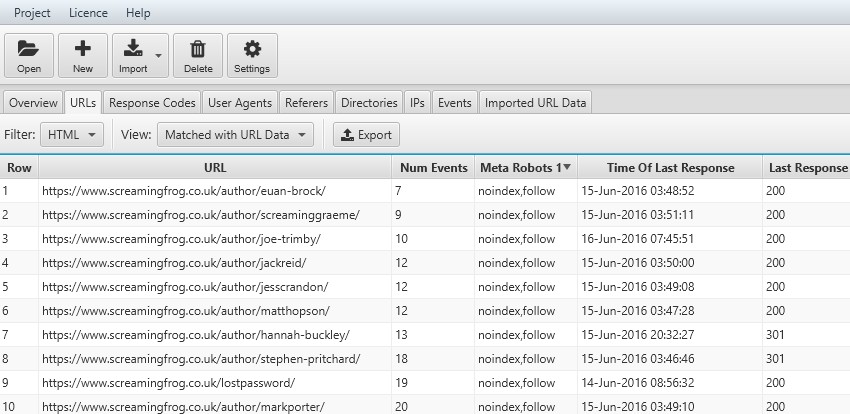
You can view the number of events and the time of the last request. This can be helpful when reviewing crawl budget waste, and whether to use robots.txt instead or remove and consolidate pages.
22) Crawl Frequency By External Linking Root Domains (Page Authority etc)
Instead of importing a crawl, you can import a ‘top pages’ report from your favourite link analysis software, and analyse crawl frequency against the number of linking root domains, or page-authority scores. In this example, we used Majestic.
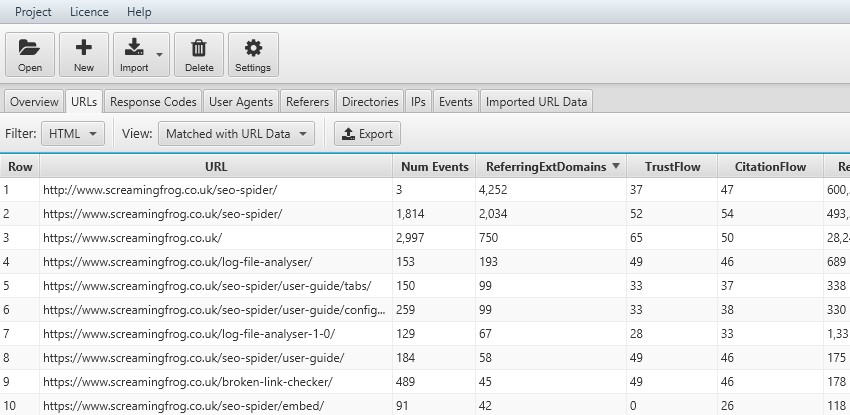
Again, you can export this data straight into a spreadsheet and analyse correlations to see whether there are areas which would benefit from external links.
Don’t Stop There
There are lots of other data sources that can be matched up and analysed alongside log data, such as Analytics, Google Search Console search queries, XML Sitemaps and more. This guide is meant to act as inspiration on analysing log files, and we hope users find other unique and valuable ways to gain insight into crawl activity.
We also highly recommend the following guides on log analysis for further inspiration –
- The Ultimate Guide To Log File Analysis – From BuiltVisible.
- Crawl Budget Optimization – From AJ Kohn.
- Server Log Essentials For SEO – From David Sottimano.
- 7 Fundamental Technical SEO Questions To Answer With Log Analysis – From Aleyda Solis.
- A Complete Guide to Log Analysis with Big Query – From Distilled.
- An Introduction To Log Files – From Screaming Frog.
Let us know any other insights you get from log files or combining with other data sources. You can download the Log File Analyser and analyse up to 1k log events for free.






Appreciate the detailed post with all the diagrams. All 22 points have been well explained and well illustrated with many examples. Nice work.
Very nice features, thank’s for the detailed post
Dan this is epic and I just purchased the software.
One thing I can’t get my head around is whether log files only record bot hits, or if they also record real human user hits? In all the articles, I’m seeing references to bots only.
Hey Joe,
Very cool to hear!
By default the tool will analyse bots only, but you can untick the ‘Store Bot Events Only’ configuration when starting a project (https://www.screamingfrog.co.uk/log-file-analyser/user-guide/general/#projects), which will mean user events can also be analysed :-)
Cheers.
Dan
Gotcha – will try that.
I’m using it for a huge project where I have to identify thousands of redirects on a URL by URL basis. For the ones identified as 301 or 302, is there a way to see their destination URLs or do I have to export those and then run them through the SF spider?
Also, any ideas why a site would be crawled 10x more by Bingbot than Googlebot? My theory would be that since Googlebot is more advanced it may be better at ignoring the cruft.
Hi Joe,
There’s no way to see the destination URLs, as the log files don’t contain that. So you’re right, you’d need to upload them in list mode in the SEO Spider. I’d recommend auditing them using this method btw – https://www.screamingfrog.co.uk/audit-redirects/ (which is how we do it internally).
With regards to higher Bingbot activity – That does sound like a lot more! We often see higher crawl rates from Bing, as it feels less efficient (as Googlebot seems to be more intelligent about when it needs to re-crawl etc). But that does sound like a lot more! I’d recommend verifying the bots and just making sure there’s no spoofing anyway.
Cheers.
Dan
Sounds promising indeed. Never thought that analyzing log files for crawled URLs could be carried out in such an organised way and prove to be more than just fruitful at the same time. Although, I still haven’t tried it. But I will try this method for sure.
Great round up and resources post. The insights you get out of the Log File Analyser are fantastic, will add the SEO Spider data to it as pointed on point #17 :-)
Any chances we can customize the Overview Response Code graph by removing the 2xx codes? It would be more visually useful to see 3xx and 4xx when 200s takes 95% of the response codes.
Hi Samuel,
Thank you! And that’s an excellent suggestion.
We had discussed being able to click on the various response codes which would deselect/select them in the graph and make it resize (the same with Events, and URLs with user-agents).
Hopefully that will help, appreciate the feedback.
Cheers.
Dan
I’m using the log file analyzer for a client of mine and noticed that none of the crawl activity is considered verified. I input one month’s worth of log files, but when I switch the selector at the top to “verified,” all data disappears. Is it possible for a site not to have any search engine’s crawling it for a whole month? Given my experience, that seems unlikely, particularly since we’ve been submitted crawl requests.
It might be helpful for others like me experiencing this if this article addressed what happens when no verified bots appear.
Thanks for any help you can provide!
Hi Joanna,
Thanks for the comment. I’d say that was highly unlikely and that there’s probably an issue with your log file.
If you could pop us a message via support (https://www.screamingfrog.co.uk/log-file-analyser/support/) and share 10 log file lines, we’ll be able to help identify the problem.
Cheers.
Dan
Thank you very much for your help! I’ll contact you via the support channel.
This is an awesome tool. I was getting frustrated with the delay in Search Console for crawler stats and this tool puts things into perspective. I look forward to learning more from this tool and its usefulness.
is there any way to save the log for longer, I use kinsta as a server and the log there is only for 3 days, is there anything to keep it longer?