Robots.txt
Robots.txt
Table of Contents
The robots.txt is a file that sits on the root of a domain, for example:
https://www.screamingfrog.co.uk/robots.txt
This provides crawling instructions to bots visiting the site, which they voluntarily follow. In this guide, we’ll explore why you should have a robots.txt, what to include, uses, common issues and more.
Why Is a robots.txt File Important?
The robots.txt can be used to prevent pages on a website from being crawled. If a page can’t be crawled, search engines cannot see what the page is about, making it less likely to be included in the search results. If an entire site cannot be crawled then it is unlikely to rank well for any searches.
Blocking URLs via robots.txt can help avoid duplicate, low-value add or unintended URLs from being accessed improving crawl efficiency.
Robots.txt Use Cases
A robots.txt file isn’t required for every website. If you don’t want to prevent anything from being crawled, then you don’t necessarily need a robots.txt.
A common practical use of robots.txt is to block search pages from crawling. These can be very large and waste crawl budget. Similarly, parameters used by a faceted navigation are also often worth blocking.
The robots.txt can also be used to prevent the crawling of development/staging versions of the site. If you are looking to prevent search engines from crawling and indexing a development site, using password protection and/or IP restricting are typically better options.
It’s important to note that robots.txt prevents crawling, rather than indexing. If URLs blocked by robots.txt can be found via internal or external links, then Google may still index them, even though they can’t crawl and see the content on the page.
Sitemaps can be included in the robots.txt which can help search engines with page discovery if they have not been submitted via search console.
Robots.txt Setup
The robots.txt is applicable to URLs with the same protocol and subdomain as it, for example:
- https://screamingfrog.co.uk/robots.txt
- Is valid for https://screamingfrog.co.uk/ and https://screamingfrog.co.uk/blog
- Is not valid for https://shop.screamingfrog.co.uk/ or http://screamingfrog.co.uk/ (non-secure version)
- https://shop.screamingfrog.co.uk/robots.txt
- Is valid for https://shop.screamingfrog.co.uk/
- Is not valid for https://blog.screamingfrog.co.uk/
- Note, www. is considered a subdomain
- https://screamingfrog.co.uk/seo/robots.txt
- This is not a valid robots.txt file. A robots.txt file must be located in the root directory of a domain
If your robots.txt file returns anything other than a 2xx (success) response code, this may cause issues. While each search engine may treat robots.txt response codes differently, Google states that they will treat a 4xx (client errors) response code as if the robots.txt file doesn’t exist (except 429, which means too many requests).
For URLs that redirect (3xx response code), Googlebot will follow up to 10 redirect hops. However, in the case of the robots.txt file, Googlebot will only follow 5 redirect hops before treating the robots.txt file as a 404 response code.
Robots.txt Rules
The robots.txt rules followed by Google are:
- User-agent: Specifies what search bots should obey the rules immediately following it (e.g. * (wildcard, all search bots), Googlebot, Bingbot etc.)
- Disallow: Indicates which URLs should be blocked from.
- Allow: Indicates which URLs should be allowed for crawling.
- Sitemap: Indicates the URL of an XML sitemap.
The below are examples of the impact of these rules if they were used within a robots.txt hosted on the Screaming Frog domain:
- User-agent: *
- This indicates that any following rules apply to all user-agents.
- Disallow: /products/
- Blocks any URLs in the https://www.screamingfrog.co.uk/products/ folder from being crawled.
- Disallow: /?s=*
- Blocks any URLs that begin with https://www.screamingfrog.co.uk/?s= e.g. https://www.screamingfrog.co.uk/?s=seo+spider&post_type%5B%5D=all&x=0&y=0
- Disallow: /products/spider/
- Allows the crawling of any URLs in the https://www.screamingfrog.co.uk/products/spider/ folder despite the higher level disallow of the /products/ folder.
Below is an example of a simple robots.txt file:
User-agent: Googlebot
User-agent: *
Disallow: /nobots/
Sitemap: https://www.example.com/sitemap.xml
Grouping
Grouping within a robots.txt file allows you to have different sets of rules and directives for different user agents, or apply rules to multiple user agents at once without having to duplicate them.
The below is an example of a robots.txt file that utilises grouping for different (made up) user agents:
# Protection of frog team
User-agent: the-french
Disallow: /frogs/legs/
User-agent: pesticides
User-agent: salt
Disallow: /frogs/
# Protection of frog teams sanity
User-agent: recruitment-agencies
Disallow: /frogs/phones/
The above example has 3 groups:
- One group for the user agent ‘the-french’
- One group for both the user agents ‘pesticides’ and ‘salt’
- One group for the user agent ‘recruitment-agencies’
Order of Precedence
When it comes to the structure of a robots.txt file, the order in which user agents and directives are specified is important. If directives are not specific enough, it may result in unintended behaviour or conflicts.
Order of Precedence for User Agents
It’s important to only have one group of directives per user agent, otherwise you risk confusing search engines which may result in unintended behaviour. Google states that in the event that there are multiple groups of directives for the same user agent, the rules are combined into a single group. Wildcard user agent groups (*), are not combined.
The below details how search engine crawlers, more specifically Google, would treat a robots.txt file with multiple user agent groups:
# Group 1
User-agent: Googlebot
# Group 2
User-agent: Googlebot-Image
# Group 2
User-agent: *
- Googlebot
- Would adhere to the rules within Group 1
- Googlebot Image (Googlebot-Image)
- Would adhere to the rules within Group 2
- Googlebot News (Googlebot-News)
- Would adhere to the rules within Group 3, as there isn’t a specific Googlebot-News group
- Googlebot Video (Googlebot-Video)
- Would adhere to the rules within Group 3, as there isn’t a specific Googlebot-Video group
Order of Precedence for Rules
Be as specific as possible when writing robots.txt rules. The most specific matching rule based on the character length of the rule path will be used, but in the event that there are conflicting rules, including those that use a wildcard, Google will follow the least restrictive rule.
The below examples highlight the order of precedence for certain rules:
allow: /p
disallow: /
For the URL https://www.screamingfrog.co.uk/products the above applicable rule would be allow: /p. This is because it is the most specific rule in relation to the sample URL.
allow: /spider
disallow: /spider
For the URL https://www.screamingfrog.co.uk/spider/buy the above applicable rule would be allow: /spider. This is because there are conflicting rules, and in this instance Google uses the least restrictive.
allow: /frog
disallow: /*.htm
For the URL https://www.screamingfrog.co.uk/frog.htm the above applicable rule would be allow: /*.htm. This is because the rule path is longer and matches more characters in the URL, thus it is more specific.
Wildcard Use
Wildcards can be used for both user agents and rules. For rules, you’re also able to stipulate the end of a URL using $. For example:
User-agent: *
Disallow: /frog*.php
Would match any path that starts with /frog and .php (in that order), for example /frog.php and /frogspecies/spiderfrog.php?q=tree.
And:
User-agent: *
Disallow: *.php$
Would match any path that ends with .php.
Common Robots.txt Issues
If a robots.txt gives any 5xx status code or a 429 status code then Google will not crawl the site at all. Other 4xx status codes are fine. Google’s treatment of different status codes for robots.txt can be found here.
Google use resources on web pages in the same way a browser does. Blocking some CSS and JavaScript files can impact how the page looks to search engines. This could lead to pages not being considered mobile friendly or content to be missed entirely on sites with a heavy reliance on JavaScript.
Although hard to do, if a robots.txt file exceeds 500kb in size it will be ignored by Google. Size can be reduced by consolidating rules, and by utilising subfolders for content that you know you want permanently excluded.
Checking Robots.txt
Visiting the web address of the robots.txt URL in a browser is a good starting point.
The Screaming Frog SEO Spider will report any URLs encountered while crawling that are robots.txt blocked. The SEO Spider can also be used to fetch the robots.txt of a particular site:
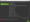
This can be customised and used to check what rules block or allow specific URLs:
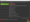
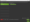
Google also have their own robots.txt testing tool.
Final Thoughts
The robots.txt is a useful tool for managing crawl budget and mistakes with it can have significant repercussions with a sites ability to rank. It is important to make sure that pages you want search engines to crawl are not blocked and that search engines can access resources used on the page.




