HTTP Status Codes
HTTP Status Codes
Table of Contents
- What Are HTTP Status Codes - 1 min
- Why Are HTTP Status Codes Important? - 1 min
- What Do Different HTTP Status Codes Mean? - 3 mins
- Viewing Status Codes - 2 mins
- Why Do HTTP Status Codes Differ Between Tools? - 1 min
- Final Thoughts
It’s useful to have an understanding of HTTP status codes when working with websites, particularly for SEO. They can help you identify errors and ensure both search engines and users can access a website as intended.
In this guide we take you through the fundamentals, the common HTTP status codes and their meaning and how you can analyse them effectively.
What Are HTTP Status Codes?
Status codes are part of the HTTP response a server gives when a URL is requested by a web browser or bot. The status code provides specific details about the URL that has been requested.
As well as the numerical status code, there is an accompanying text status that gives more detail about the response in question.
Why Are HTTP Status Codes Important?
Status codes are important for SEO as they impact search engines’ crawling and indexing of websites, letting them know if URLs have resolved successfully, moved to another location, content has been removed, or if there are server issues.
While status codes are not something a user will generally see, they directly impact how a user interacts with a page, such as whether they are given a working page, an error, a redirect etc.
What Do Different HTTP Status Codes Mean?
Status codes can be broken down into a number of different groups, these groups and some of the more common statuses found in them are:
1xx Information Responses
1xx statuses indicate that the request was received and understood. These are issued provisionally while the request processing continues.
As these are a ‘mid-point’ to the other statuses, these are something that are rarely encountered on their own.
2xx Successful Responses
200 (OK) – The request was successful
While not a guarantee that the URL will be indexed, at a minimum a page needs to respond with a 2xx status code.
3xx Redirection Responses
301 (moved permanently) – An indication that the content of the URL has permanently moved to a different URL. Often encountered when a site has changed its URL structure.
302 (found) – An indication that the content of the URL has temporarily moved to a different URL. Often found where content can only be accessed by logging into a secure area.
303 (see other) – Similar to a 302 redirect but encountered less frequently.
307 (temporary redirect) – Similar to a 302 redirect. Often seen with the implementation of HSTS.
Googlebot will follow redirects to find the target content, so long as there are no more than ten redirects in a chain. Google will not index a redirecting URL and instead index the redirect target, so long as that returns a 200 status.
Take a look at our SEO guide to redirects if you’re interested in learning more.
4xx Client Error Responses
400 (bad request) – The server cannot process the request due to some error with it.
403 (forbidden) – The server refuses access the resource. Often an intentional block of the request by a server due to the user-agent of the request.
404 (not found) – The server cannot find the requested resource. Often related to broken links but is an applicable status for any non-existent content.
410 (gone) – Similar to a 404, but an indication that the content has been permanently removed.
429 (too many requests) – the server has received too many requests in a short period of time. Often seen when using a web crawler.
Google will not any index a page that gives a 4xx status, and any previously indexed page giving a 4xx will be removed eventually. The exception is a 429 status which is treated like a 5xx status.
5xx Server Error Responses
500 (internal server error) – The server has encountered a situation it doesn’t know how to handle.
502 (bad gateway) – The server is acting as a gateway/proxy to another server and received an invalid response from it.
503 (service unavailable) – The server is not ready to handle the request. Often seen when a site is down for maintenance.
5xx statuses (and 429s) causes Google to slow its crawling, in case this is responsible for the server issues. If indexed pages consistently respond with server errors, then these will eventually be dropped from the index.
Specific details on how Google treats these and other status codes can be found here.
If you’re experiencing difficulty crawling a website with the Screaming Frog SEO Spider, then reviewing the status code is often the first step in diagnosing the issue and how to crawl it.
Read our Why Won’t My Website Crawl?‘ guide for practical steps to resolve different status codes.
Viewing Status Codes
Browser
One of the most direct ways to see the full response code of a page including the code is using Chrome Developer Tools. Right click on the page and then select Inspect (or use the shortcut Ctrl + Shift + I), select the Network tab, reload the page, click on the resource you would like to view the status code of. HTTP headers can be viewed in the same manner in Firefox.

There are browser extensions allow you to see this information more easily.
The Ayima Redirect Path will provide the Status and Status code as well as visualise any redirect chains:

Google Search Console
There are various reports in Google Search Console that include information on status codes.
The URL Inspection Tool ‘live test’ feature can show you the response received by Googlebot when a page is requested.

While this can be useful, Google actually show you the response of the final URL in a request. So if you request a URL which redirects to another URL, Google will show you the response of the final URL rather than the URL requested. This can cause confusion and is important to remember!
The Index Coverage report will tell you if Google is not indexing pages due to it returning a specific status code. This is a good way to see if pages have been seen giving a consistent status code over time, as well as longer-term large-scale changes, such as in increase in the number of pages seen giving a 404.

The Crawls Stats report is a more thorough record of the specific responses Googlebot encountered when visiting the site. This is better for spotting sudden increases in error statuses before they go on to impact the Index Coverage reports, as well as spotting temporary inconsistencies that would not be reflected in the Index Coverage report.
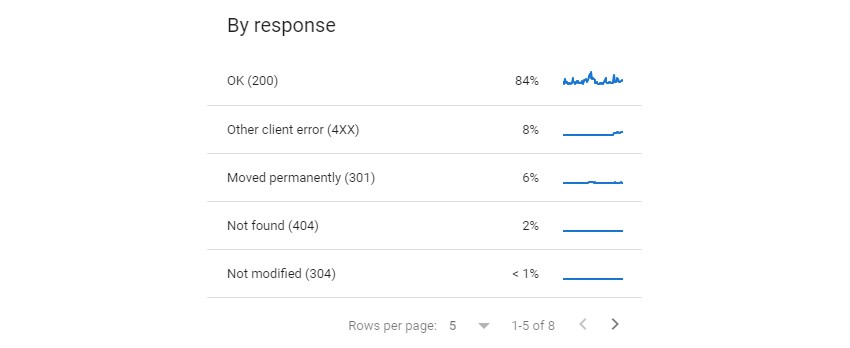
SEO Spider
The Screaming Frog SEO Spider will report the status codes of the URLs it encounters during a crawl.
A full list of the statuses the Spider encountered while crawling can be found in the Response Codes tab, as well as reporting on any URLs where it was unable to get a response from the server (DNS lookup failed, robots.txt blocked, connection timeout, etc.)

An overview of the different status codes encountered on a site can be seen in the corresponding section of the Overview Tab.
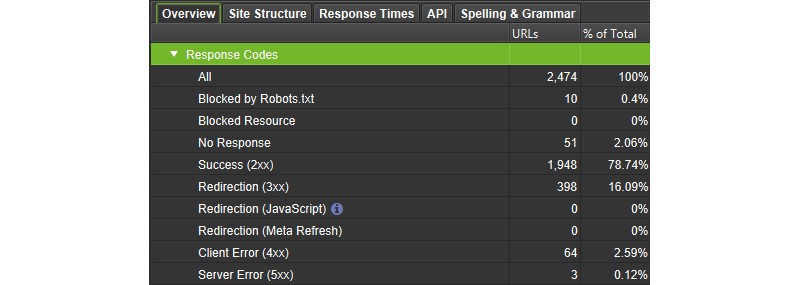
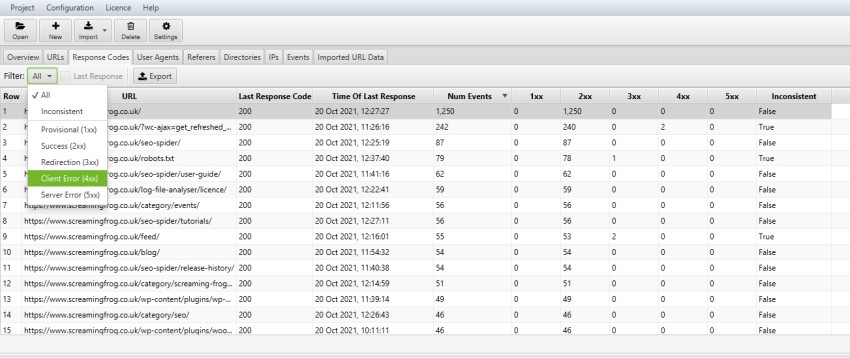
The SEO Spider can be used to find elements like broken links (links pointing to 404 pages) using the various reports available like ‘Bulk Export > Response Codes > Error (4xx) Inlinks’. Please see our guide on finding broken links for more details on using the SEO Spider.
The status codes reported in the SEO Spider can also help diagnose why a website cannot be crawled.
Log Files
You can see the status codes of requests made by both search engines and browsers by analysing server log files.
To do this, you can analyse logs in a spread sheet, or easier still – use a Log File Analyser tool.
Check out our guide for inspiration on a variety of ways to use log file analysis for SEO.
Why Do HTTP Status Codes Differ Between Tools?
Browsers and tools request a page in different ways, with a different requests, which can sometimes mean you see different responses between them.
This does not mean any tool or browser is ‘incorrect’, just that the server is responding differently.
Some of the common factors that can cause servers to give a different response to a tool, such as the SEO Spider are –
- User-Agent – Tools such as the SEO Spider often use their own user-agent, and so do browsers. If you adjust the user-agent in your browser or tool, you may experience a different response. Some CDNs such as Cloudflare will also perform verification on user-agents making request. For example, if a request is made from Googlebot, they check it is coming from known Google IP range and if they believe it is spoofed, they will return a ‘403’ response.
- Accept-Language Header – Your browser will supply an accept language header with your language. Google crawl without setting Accept-Language in the request header, as do most tools. Some websites use the accept-language header in region specific redirection.
- Speed – Servers can respond differently when under stress and load. Their responses can be less stable. So if you’re crawling using a tool such as the SEO Spider, it may put more load on the server and return a different response.
Google Search Console provides an excellent way to verify the response seen by Google, but do remember that the URL Inspection Tool shows the response from the final destination, so if a URL redirects, it won’t be the URL requested.
Final Thoughts
This guide should give you a basic understanding of the common HTTP status codes you may encounter on a website.
It’s vital to understand their meaning, and how they can impact search engine crawling and indexing for SEO, and users experience visiting the website.
It’s important to remember that different requests can lead to different responses as well. So a request from a ‘Chrome’ user-agent, might receive a different response to a request from ‘Googlebot’, or a crawler.
Use the tools available above to verify responses and ensure search engines and users are both receiving the expected response.
Further Reading
- HTTP Status Codes Crawling With The Screaming Frog SEO Spider - From Screaming Frog
- How HTTP status codes, network & DNS errors affect Google Search - From Google




