Duplicate Content
Duplicate Content
Table of Contents
- What is Duplicate Content? - 1 min
- Duplicate vs Similar vs Thin Content - 1 min
- Why Does Duplicate Content Matter for SEO? - 2 mins
- Is There a Duplicate Content Penalty? - 1 min
- What are the Causes of Duplicate Content? - 3 mins
- How to Find Duplicate Content on Your Site - 2 mins
- How to Fix Duplicate Content Issues - 3 mins
- Final Thoughts - 1 min
Mark Twain once remarked that ‘There is no such thing as an original idea’. Now, whether or not you agree with the famously grumpy American author, original content is something that a lot of SEOs and website owners stress about.
That’s because its counterpart, duplicate content, can be a possible cause of SEO issues. In this guide we’ll examine everything from what duplicate content is and where it comes from, to how to spot and fix it.
What is Duplicate Content?
According to Google, duplicate content is:
Substantive blocks of content within or across domains that either completely match other content or are appreciably similar. Mostly, this is not deceptive in origin.
This is a suitably wordy way of saying that duplicate content is the same content appearing on multiple URLs. This can be on the same website, or across different websites.
The last sentence of the above quote from Google is perhaps the most important. The majority of duplicate content on the web is accidental rather than the result of trying to game the system.
Nevertheless, carelessness is not an excuse. Duplicate content can be avoided and fixed. Just read on to find out how.
Duplicate vs Similar vs Thin Content
Just like ice cream, content issues come in multiple flavours. Three, in fact. Though, rather than being distinct flavours, the differences are more subtle. Like different types of red wine, for instance.
We already know what duplicate content is: it’s the same content appearing across different URLs. But how is it different to similar and thin content?
Similar content is only slightly different. From the quote we took from Google earlier, duplicate content can also be content that’s ‘appreciably similar’. Essentially, this means content that’s only been gently tweaked from the original. Think copying and pasting your homework from Wikipedia but changing some of the words to synonyms.
And thin content is when a single page adds very little value to the user due to the paucity of content on it. Examples of thin content include: a category page with only a few items on it, a page with automatically generated content, or a thin affiliate page. Google also sees scraped content and doorway pages as thin content. In all these cases, Google will see them as low-quality and will de-value them accordingly.
Why Does Duplicate Content Matter for SEO?
Duplicate content matters because it can harm your site’s performance in search engines. This can be for a number of reasons.
-
1. The inefficiency of crawling the same content multiple times
Crawl budget is defined as the maximum ‘fetching rate’ for a given site. In essence, this means that when Googlebot visits a website, it won’t crawl every page at once, but will crawl the site for a set time.
The amount of time each site is allocated depends on a number of things, one of which is having low value pages. And you guessed it, duplicate content pages count as low value.
Wasting Googlebot’s time on pages like these will stop it from crawling your high value pages as quickly. This may cause delays in discovering and indexing your no-doubt awesome content.
-
2. The ‘wrong’ URL showing in search results
Google knows that users want diversity in search results. It’s one of the reasons behind the recent featured snippet deduplication and domain diversity updates.
So, it consolidates any duplicate URLs into a cluster, with the ‘best’ URL appearing in SERPs. This ‘best’ URL is decided by the algorithm but may not be your preferred version.
If the ‘wrong’ URL shows in search results, users may be less likely to click it, meaning traffic to your site may decrease. And you’ll no doubt want users to be visiting the page on your site that you deem to be the ‘best’.
-
3. The dilution of link signals across many URLs
Let’s say you’ve made some awesome, link-worthy content. But because of a technical hiccup, that content is duplicated. If the same content exists at multiple URLs, how do other sites know which is the ‘right’ one to link to? Short answer: they don’t.
This means that both versions will garner links, but the duplicate and the original will each have fewer than if there was only one URL to link to.
Now, due to the way Google treats duplicate content – the cluster approach described above – URL properties, such as link signals, should be consolidated to the chosen ‘best’ URL.
However, how Google should do something and what it actually does are sometimes two very different things. So, why make it more difficult for Google than it needs to be? Efficiency is always the best policy. There are many ways to deal with duplicate content, which we explore in more detail later.
Is There a Duplicate Content Penalty?
The answer to this question is every SEO’s favourite: it depends. In the vast majority of cases, there isn’t a penalty for duplicate content. But sometimes, there is. Confused yet? Read on for enlightenment.
It all stems back to the definition of duplicate content we saw earlier:
Substantive blocks of content within or across domains that either completely match other content or are appreciably similar. Mostly, this is not deceptive in origin.
When duplicate content is not deceptive, which is the majority of the time, there is no penalty. But the way Google deals with it leads some people to think they have been penalised.
The cluster approach we saw above means that only one of the duplicates will appear in search results. The remaining duplicate pages haven’t been penalised, just filtered out.
But there can be a penalty when duplicate content is assessed to be deceptive. If Google assesses that duplicate content is shown to deceive users or manipulate search results, it will make “appropriate adjustments”.
This bland euphemism means that a site judged to be deceiving users may suffer a drop in rankings. In the most serious cases it may even be removed from the index altogether. However, Google doesn’t tend to penalise sites as much as it did in the past, so it’s unlikely you’ll ever see a true duplicate content penalty in the wild.
What are the Causes of Duplicate Content?
By some estimates, more than a quarter of all the content on the internet is duplicate content. For this much to exist, there must be multiple causes. We’ll run through the most common causes of duplicate content below.
URL Parameters
URL parameters are the parts of URLs after a question mark. While they’re undoubtedly useful, they can cause SEO headaches.
This is especially true for duplicate content issues, as the same content can create multiple different URLs from combinations of different parameters. The two main reasons for using parameters are:
1. Filtering and sorting
Adding parameters to URLs is a way for users to filter or sort items on a page by specific features. This is most commonly seen in e-commerce sites, for example:
- screamingfrog.co.uk/frogs/?size=small
But combining filters leads to different URLs with either the same or similar content:
- screamingfrog.co.uk/frogs/?size=small
- screamingfrog.co.uk/frogs/?size=small&colour=green
- screamingfrog.co.uk/frogs/?size=small&colour=green&sort=scream-quiet-to-loud
And order doesn’t matter either:
- screamingfrog.co.uk/frogs/?size=small&colour=green
This is the same as:
- screamingfrog.co.uk/frogs/?colour=green&size=small
2. Tracking
Some websites use a unique string of numbers and/or letters to identify individuals currently on the site. These session IDs can be located in URL parameters. But different session IDs for the same URL will show the same content:
screamingfrog.co.uk?sessionID=123456 has the same page content as
screamingfrog.co.uk?sessionID=654321
Other websites use UTM codes added to the end of URLs to identify where traffic comes from. Different UTM codes appended to the same URL will be seen as duplicate content:
- screamingfrog.co.uk?utm_source=newsletter&utm_medium=email has the same content as
- screamingfrog.co.uk?utm_source=google&utm_medium=organic
Protocols and WWW Subdomain
Most information is sent over the internet via the HTTP protocol. But there are two options: the plaintext HTTP and the encrypted HTTPS (side note: you really should be using HTTPS):
- http://www.screamingfrog.co.uk
- https://www.screamingfrog.co.uk
But your site can be accessed at both variations if your server isn’t set up correctly, giving two identical versions of the site.
You can also choose either to use the www subdomain or not:
- https://www.screamingfrog.co.uk
- https://screamingfrog.co.uk
And again, if things aren’t set up correctly, your site could be accessible at both these URLs. So, in the worst-case scenario, there could be four separate versions of your site existing simultaneously.
URL Structure
Traditionally, non-trailing slash URLs were for files, and trailing slash URLs were for directories:
- screamingfrog.co.uk/search-engine-optimisation/ (a directory)
- screamingfrog.co.uk/search-engine-optimisation (a file)
This isn’t a huge deal nowadays, as long as your site is consistent in whether it uses a trailing slash or not. However, as Google treats both types of URL as unique, this can cause a potential duplicate content issue. This means that if the same content is accessible at both URLs, you’ve got yourself duplicate content.
Mobile Subdomains
Some mobile-friendly configurations involve separate URLs:
- www.screamingfrog.co.uk serving desktop users
- m.screamingfrog.co.uk serving mobile users
But by definition these URLs have the same content. So, if not accounted for, this will also give duplicate content.
AMP URLs
Accelerated Mobile Pages (AMP) are pages designed to load quickly on mobile. But they sit on separate URLs to non-AMP content despite displaying the same information:
- screamingfrog.co.uk/search-engine-optimisation/
- screamingfrog.co.uk/amp/search-engine-optimisation/
Geotargeting
Targeting users in different countries that speak the same language can be a recipe for, at the very least, similar content. In the worst cases this can even lead to duplicate content.
For example, we might be launching a new site, targeting Spain, Mexico and Argentina:
- ranagritando.com/es/posicionamiento-en-buscadores/
- ranagritando.com/mx/posicionamiento-en-buscadores/
- ranagritando.com/ar/posicionamiento-en-buscadores/
But as all these countries speak Spanish, the content will be the same across all three versions.
Note that the original UK version should not be seen as duplicate content, as versions in different languages are generally not treated as duplicates.
In these cases, using hreflang indicates to Google the most appropriate page for a language or region. Again, you can leave this for Google to figure out itself, but as we said before, efficiency is always the best policy.
Staging Sites
Finally, staging sites are development environments used to test any changes without doing it on the live site. They’re usually duplicates of the live site, so if your staging site is indexed, this will be duplicate content too.
How to Find Duplicate Content on Your Site
Using Google Search Console to Find Duplicate Content
The Coverage report or URL Inspection tool in Search Console will show the following warnings if duplicate content is present:

Duplicate without user-selected canonical
This means the page has one or more duplicates, none of which you’ve marked as the canonical version. Google has assessed that the page isn’t the canonical version.
Duplicate, Google chose different canonical than user
This means the page is marked as the canonical version for a set of duplicates, but Google has assessed another URL as a better canonical and indexed that one instead.
Duplicate, submitted URL not selected as canonical
This means the URL is one of a set of duplicates without a chosen canonical, and you’ve requested Google index the URL.
It hasn’t been indexed because it’s a duplicate and Google has assessed another URL as a better canonical. The canonical Google selected has been indexed instead.
In all three cases, using the URL Inspection tool for the URL should show the URL Google has selected as the canonical.
Using the Screaming Frog SEO Spider to Find Duplicate Content
The SEO Spider identifies exact duplicate content by default. But, to find near duplicates, you must configure the ‘Near Duplicate’ option under Config > Content > Duplicates.
This allows the SEO Spider to identify duplicates with a 90% similarity threshold. This can be adjusted to your preference. You can also choose whether to include non-indexable pages or not.

Once your crawl has finished, you can view the outcome under the Content tab. There are two filters related to duplicate content, Exact Duplicates and Near Duplicates. Near Duplicates requires crawl analysis to populate.

If you have any near duplicate pages, these should be manually reviewed. There are many legitimate reasons why some pages may be similar in content, such as different product configurations.
However, you should consider whether they should exist as separate pages–do they have unique value for the user? Alternatively, they can either be removed, consolidated or improved.
Finally, it’s worth noting that you can refine the similarity threshold post-crawl and rerun crawl analysis to find either more or fewer similar pages. You don’t have to run the crawl again from scratch.
The SEO Spider User Guide has a great in-depth guide on checking for duplicate content, which you can see at the link above.
How to Fix Duplicate Content Issues
Now that we know what they are and how to find them, how do we fix duplicate content issues?
The specific fix will depend on the exact issue involved, but most duplicate content issues can be solved by doing one of the following.
Specify a Canonical Link Element
One of the main weapons in your fight against duplicate content is the canonical link element. A canonical link is a way to indicate a preferred URL to Google for indexing when multiple pages have the same or similar content.
This helps to avoid duplicate content issues and consolidates any linking signals to a single URL. Including self-referencing canonicals on every page ensures all variations of the URL (such as those with parameters) are consolidated back to a single URL.
The canonical link element is found in the <head> of a HTML webpage:
<link rel="canonical" href="https://www.screamingfrog.co.uk/" />
You can also use the SEO Spider to view canonicals when crawling a site:
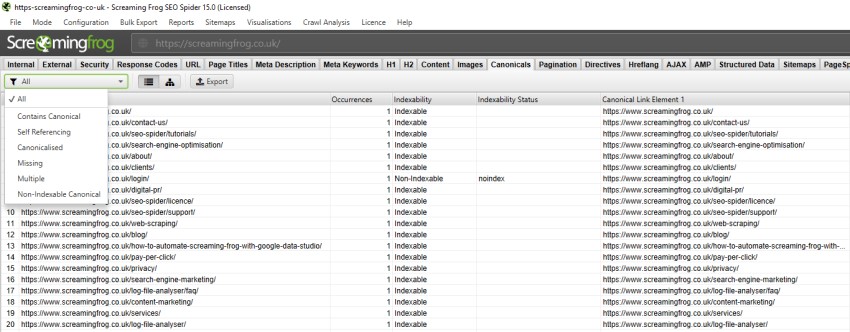
The Canonicals tab will tell you everything you need to know, from whether a page contains a canonical, to if that canonical is non-indexable.
Canonicals are a good solution for duplicate content issues caused by parameters, mobile subdomains and AMP URLs.
For mobile subdomains, you’ll need something else as well as the canonical. You’ll also need to use rel=“alternate” to tell search engines that it’s an alternate version of the desktop content.
And for AMP content, you’ll also need to use rel=“amphtml” to tell search engines that it’s the AMP version of the non-AMP content.
Use 301 Redirects
Another way to deal with duplicate content is the 301 redirect. This response code tells search engines that a page has permanently moved to a new URL.
This is useful for consolidating a duplicate to the original URL and for combining multiple duplicates into one page.
You can see and audit all redirects present on your site in the Response Codes tab of the SEO Spider.
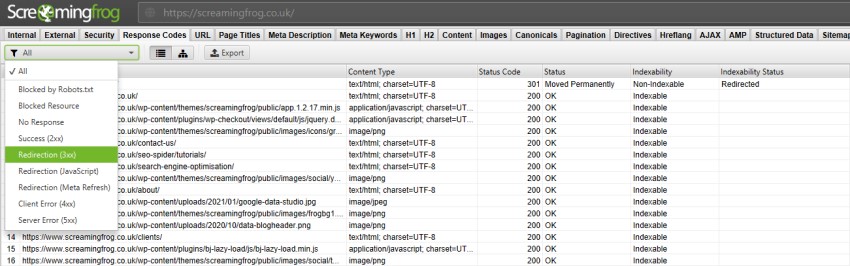
The major issues to look for here are long redirect chains, or internal links referencing redirecting URLs.
301 redirects are particularly useful for dealing with the www subdomain and trailing/non-trailing slash duplicate content issues. In both cases you use 301 redirects to point from the version you don’t want to show in search results to the version you do.
Use the Noindex Meta Tag
The ‘noindex’ meta tag prevents a page from being indexed by search engines. The page therefore will not show in search results.
This tag is added to the <head> of a HTML webpage:
<meta name="robots" content="noindex,follow"/>
You can also achieve the same effect by returning a ‘noindex’ header in the HTTP request. Both of these methods allow search engines to crawl the links on the page but won’t add them to the index.
In order for this to work correctly, you must allow the page to be crawled – it cannot be blocked by the robots.txt file. If the page can’t be crawled, search engines won’t know about the ‘noindex’ tag. So, the page can still appear in SERPs if it’s been found by following links from other pages.
Google also recommends not blocking crawling of duplicate content by the robots.txt file. It can’t then assess if URLs contain duplicate content and has to treat them as unique.
You can see whether pages have a ‘noindex’ tag by looking in the ‘Meta Robots’ column in the Internal tab of the SEO Spider:
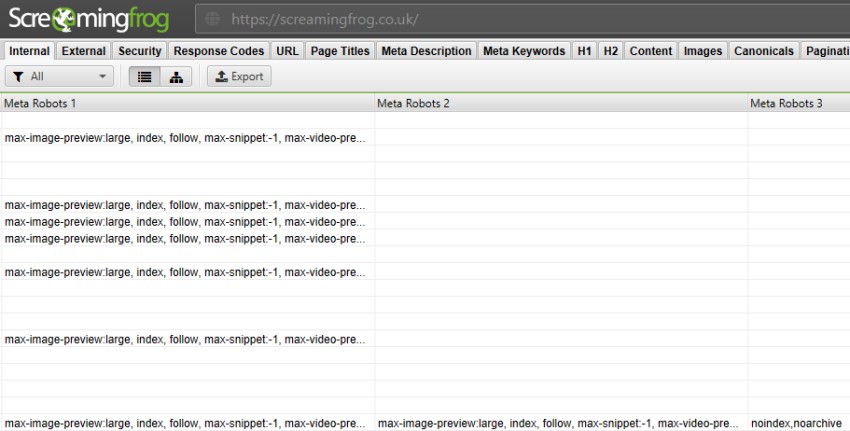
The ‘noindex’ tag is a useful solution to duplicate pages that can’t be dealt with by other methods, such as staging sites that have already been indexed. It’s also good for removing thin or placeholder pages from the index.
Use the URL Parameters Tool
The URL Parameters tool tells Google how to treat URL parameters on your site, with a caveat. Your site has to have more than 1,000 pages.
The other downside to using this tool is that it only tells Google what to do. Other search engine bots will not follow the same rules and you will need to use their respective webmaster tools to achieve the same thing.
Final Thoughts
Duplicate content probably causes more stress than it needs to. In most cases search engines will deal with it without you even noticing or needing to do anything.
Google has even said in the past that, ‘if you don’t want to worry about sorting through duplication on your site, you can let us worry about it instead’.
Despite this, there are actions you can take to be proactive about duplicate content. We’ve listed some of the most common causes in this article and how you can address them.
Duplicate content only becomes a serious problem at scale, or if you’re doing it to manipulate search results. In these cases, sorting it should definitely be a priority.




