URL Structure
URL Structure
Table of Contents
- What Is a URL? - 1 min
- What Is An ‘SEO Friendly’ URL? - 1 min
- Anatomy of a URL - 1 min
- Why Are URLs Important? - 2 mins
- How Are URLs Displayed in The Search Results? - 1 min
- Is There an Optimum Length for URLs? - 1 min
- URL Structure Best Practices - 10 mins
- Should You Change Your URL Structure? - 1 min
- How Can You Analyse URL Structure? - 1 min
- Final Thoughts - 1 min
Having simple, logical, and relevant URLs is vital for both users and search engines in understanding a website structure, and the content of a page.
In this guide we take you through the fundamentals, as well as more advanced considerations when choosing the best URL structure for your website.
What Is a URL?
A uniform resource locator (URL) is a human-readable address of a unique resource on the web.
They can reference file transfer (FTP), or email (mailto), but the most common is for web pages over HTTP in browsers, which we focus upon here.
A typical URL such as https://www.screamingfrog.co.uk/learn-seo/url-structure/ is made up of a protocol (http or https), a hostname (www.screamingfrog.co.uk), and a path (/learn-seo/url-structure/).
What Is An ‘SEO Friendly’ URL?
This is a phrase that is used to describe URLs that are designed for the search engines. They are often keyword rich to improve SEO and help users.
However, in reality it can be used as a phrase to merely describe URLs that are crawlable and indexable by search engines, which all URLs should be in their most basic form. It doesn’t always mean they are really optimised for users or SEO.
Anatomy of a URL
URLs are composed of different components, which some are mandatory and others optional. Together they help determine how and which content is accessed on a server.
Some components are less intuitive for users and should be avoided, which we cover later in the guide.

The diagram above covers the main components of a URL, which include the following:
- Protocol – the scheme for exchanging data (either HTTP or HTTPS)
- Subdomain – a domain that is part of another domain (www. is part of example.com)
- Second Level Domain – the second domain name in this hierarchy
- TLD – the top-level domain; the highest level in the ‘domain name system’ hierarchy
- Subfolder – a folder path to the location of a URL
- Filename – the page name of the unique resource
- Query Parameters – key and value pairs that can alter the web page
- Fragment Identifier – an anchor or ‘jump link’ to a specific section in the page
Why Are URLs Important?
There are four key reasons why a logical URL structure can be crucial.
1) They Are Good for Usability
Above everything, they help users.
A URL that reads https://www.screamingfrog.co.uk/learn-seo/url-structure/ is more helpful than a cryptic URL such as https://www.screamingfrog.co.uk/cat/page/290846abb/?key=true.
2) They Help Search Engines
Search engines need a unique URL per piece of content to be able to crawl, index, and rank it.
Overly complex URLs with identical or similar content can make indexing and ranking the right content harder.
A logical URL structure can also help search engines better understand the architecture of a site.
3) They Help SEO
Keywords in URLs are a small relevance ranking signal in the search engines.
4) They Increase Clicks In The Search Results
URLs are displayed in the SERPs — so useful, logical, and relevant URLs will have a better CTR.
How Are URLs Displayed in The Search Results?
In Google, URLs appear at the top of each result snippet. Google display URLs in a breadcrumb format and try and include the relevant portion of the URL in the results that best match the searcher’s query.

Is There an Optimum Length for URLs?
Typically the shorter the URL, the simpler it is to understand and often, more aesthetically pleasing.
There are a couple of hard limits to be aware of –
- The RFC does not specify any requirement for URL length; however, some browsers such as IE have a hard limit of 2,083 characters.
- Sitemaps.org protocol stipulates URLs must be less than 2,048 characters.
However, if you’re getting anywhere near 2k characters in a URL, then it’s way too long.
Google typically show around 50 characters (or 335px) in the search results. They try and show the most relevant portion of the URL that matches the query, but don’t always show what a user may want.
Take for example this snippet for a ‘best mortgage deals’ query:

The URL of the indexed page is rather long (https://www.which.co.uk/money/mortgages-and-property/mortgages/getting-a-mortgage/finding-the-best-mortgage-deals-a08dy8g1xy0q), so it has been truncated as expected.
The ellipsis (…) shows where Google has excluded the first two subfolders of the URL to show the more relevant portion towards the end. However, the query was ‘best mortgage deals’ and it hasn’t shown the ‘best mortgage deals’ section right at the end of the URL in the search results.
URL Structure Best Practices
The URL structure across the domain should be consistent and ideally obey the following best practices:
Use HTTPS
This should be the default on the web today for security and user trust. Browsers will display a ‘Not Secure’ alert to users without it. There is also a very small ranking boost using HTTPS over HTTP.
HTTP URLs should 301 redirect to HTTPS versions and HSTS should be enabled.
Make URLs Simple & Organised
Keep your URL structure logical for users. Use subfolders for hierarchy and grouping content where it makes sense.
Allow users to strip folders from a URL to move backwards to a subcategory. Well organised URLs and subfolders help users.
Use the site’s information architecture and taxonomy as a guide, without being restricted by it.
Keep URLs Short
Try and keep URLs as short as possible so they are easy to read and digestible for users.
This doesn’t mean all URLs should live on the root; use subfolders logically.
Use One Single URL For Each Unique Piece Of Content
This avoids search engines crawling the same content multiple times and ensures that it is clear which page should appear in search results.
You can use various methods to avoid duplicate content, such as canonicals or robots.txt. However, ideally only canonical indexable URLs should be crawlable and indexable.
As an example, if you run an e-commerce site which uses categories in URLs, and products appear in multiple categories, it can lead to duplicate content, such as the example below:
www.example.com/category/subcategory/cool-product/
www.example.com/brand/subcategory/cool-product/
In this type of scenario, using a /products/ subfolder such as www.example.com/products/cool-product/ might be a better approach to avoid duplicate URLs.
Use Target Keywords In URLs
Use descriptive and relevant keywords, remove words that are not useful.
Be concise and without repetition. Wherever possible, URLs should be intuitive to users.
Include Lowercase Characters Only
URLs are case sensitive, and technically they could lead to different content. So do not use uppercase characters, or mix upper and lowercase characters in the path, filename or parameters of a URL.
Implement rules to 301 redirect uppercase to lowercase character URL versions.
Be Consistent With Trailing Slashes
Pick one — it doesn’t matter as URLs with and without trailing slashes are treated as separate URLs. Only one of these versions should resolve and be linked internally, while the other should 301 redirect to its equivalent.
This does not apply to URLs that have a file extension. Do not worry about the trailing slash on the hostname (“https://www.example.com/” is seen as “https://www.example.com”).
Use Hyphens As Word Separators
Do not use underscores or spaces, as these are not always seen as word separators by search engines.
Go with hyphens (-) as word separators.
Avoid Complex Parameters & Dynamic URLs
Limit the use of parameters in URLs where possible. The search engines can crawl them, but they are less useful for users. Logical parameters for URLs such as pagination is not a problem.
If parameters are utilised, then use ?key=value URL parameters rather than ?value where possible, as they allow Google to understand your site’s structure and crawl and index more efficiently.
Session IDs should never be parsed into the URL — use cookies. Don’t include UTM tracking parameters in URL strings.
Avoid Duplicates By Updating The Page Without Changing The URL
For sorting or filtering page content consider using JavaScript to update the page content, rather than creating new URLs which lead to near-duplicate content.
This will save you from having to use robots.txt, or canonicals to solve unnecessary crawling or duplicate content.
Don’t Use Fragments For Indexable URLs
Fragments are often used as an anchor to a specific section within a page (‘jump links’), but they can also be used by single-page applications (SPAs) for different views of a web app.
However, they will not be indexed as separate URLs. Google will ignore anything after the fragment (#) and not index them. This is fine for jump links as part of the same page, but a problem when the URL and content should be indexed as a unique page.
SPAs should implement the history API and internal links should use HTML anchor tags for indexing. Do not use hashbang URLs (#!) as Google has long since deprecated the old AJAX crawling scheme.
Use Safe Characters & Avoid Non-ASCII characters
This includes characters such as ” > # { | \ ^ ~ [ or whitespaces. Standards outline that URLs can only be sent using the ASCII character set, and some users may have difficulty with subtleties of characters outside this range.
URLs must be converted into a valid ASCII format, by encoding links to the URL with safe characters (made up of % followed by two hexadecimal digits). Today, browsers and the search engines are largely able to transform URLs accurately.
Use Absolute URLs
There are pros and cons of absolute and relative URLs.
However, there are far more benefits of absolute URLs as they can avoid various accidents that can occur with relative URLs, such as infinite spider traps, and some security issues.
Exclude Unnecessary Stop Words
Excluding stop words such as ‘the’, ‘and’, ‘a’, ‘an’ etc. can make URLs shorter and more readable.
Avoid Separate Mobile URLs
Use a responsive design with a single URL structure for both desktop and mobile users.
It’s easier for users when sharing your content; it’s easier for Google in crawling, indexing, and ranking, and it often requires less development time than maintaining multiple pages for the same content.
Avoid Unnecessary Subdomains
Subdomains can be seen as separate websites by search engines, this means any value from external links will not always be shared between the different subdomains. They should be used when there is a clear separation of content, business or audience targeting.
Avoid unnecessarily using a subdomain for a blog as an example, when it can sit in a subfolder.
Consolidate Site Versions
Google differentiates between the ‘www’ and ‘non-www’ version of a URL or site (for example, www.example.com or ‘example.com’), as technically www. is a subdomain. Pick one version and 301 redirect the other version to it.
When adding your website to Search Console, add all versions – http:// and https://, as well as the ‘www’ and ‘non-www’ versions.
Ensure Paginated Pages Have Unique URLs
Paginated pages in a series should each have their own unique URL that are crawlable and indexable.
Google see URL mistakes the most in paginated URL structures, and getting this wrong could mean URLs that are only found on paginated pages are not discovered.
Don’t Keep Changing URLs
URLs should remain the same, with as little changes as possible over time. Migrating to new URLs means search engines can take time to crawl, index, and rank the right page.
For example, if you run an event multiple times a year, use a URL without the date, so it doesn’t have to be updated constantly. Then have pages underneath it with specific dates of each event if necessary. Avoid including dates in blog post URLs if they are evergreen!
Should You Change Your URL Structure?
Changing URLs is a big decision that should be properly considered. If your website doesn’t follow some of the best practices outlined above, but it is not affecting your users or organic performance, then it’s often not worth changing your URL structure alone.
However, if you are experiencing more serious issues for users, or crawling, indexing, and ranking in search engines, then a move to a new URL structure might be necessary.
Remember to take an archive of your existing URLs, and set-up 301 permanent redirects to new URL equivalents of every URL upon migrating to a new URL structure.
If URLs are not properly redirected, then the history and PageRank from external URLs will be lost, which can cause significant issues in indexing and ranking.
How Can You Analyse URL Structure?
You can view URLs in browsers, use analytics or database data, but the best approach is to use a crawler, and for the more advanced you can analyse log files.
The Screaming Frog SEO Spider helps uncover common issues around URL structure in the URL tab:
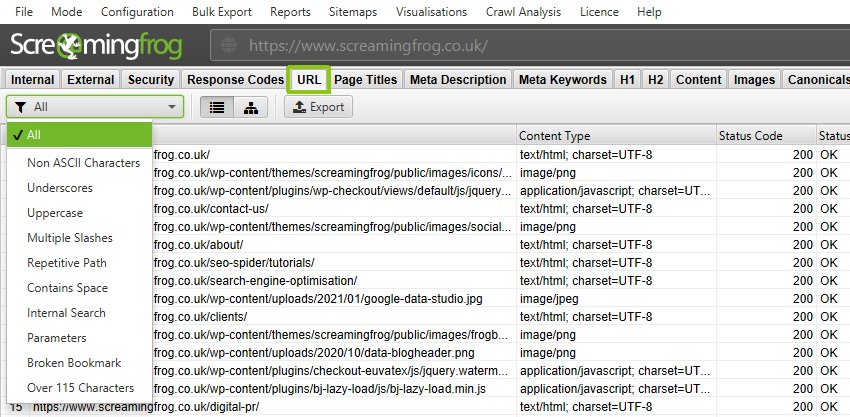
Additionally, it can be used to help find broken links, broken jump links and audit redirects in an URL migration.
Final Thoughts
Setting up a logical and descriptive URL structure can be fairly simple, but it can quickly become more challenging when working with large complex websites with many filters and facets.
However, keeping to the best practices outlined above should help both users and search engines better understand your website.
Further Reading
- Search Engine Optimization (SEO) Starter Guide - From Google
- Keep a simple URL structure - From Google
- Designing a URL structure for ecommerce sites - From Google




