Screaming Frog SEO Spider Update – Version 20.0
Dan Sharp
Posted 7 May, 2024 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 20.0
We’re delighted to announce Screaming Frog SEO Spider version 20.0, codenamed internally as ‘cracker’.
It’s incredible to think this is now our 20th major release of the software, after it started as a side project in a bedroom many years ago.
Now is not the time for reflection though, as this latest release contains cool new features from feedback from all of you in the SEO community.
So, lets take a look at what’s new.
1) Custom JavaScript Snippets
You’re now able to execute custom JavaScript while crawling. This means you’re able to manipulate pages or extract data, as well as communicate with APIs such as OpenAI’s ChatGPT, local LLMs, or other libraries.
Go to ‘Config > Custom > Custom JavaScript’ and click ‘Add’ to set up your own custom JS snippet, or ‘Add from Library’ to select one of the preset snippets.

You will also need to set JavaScript rendering mode (‘Config > Spider > Rendering’) before crawling, and the results will be displayed in the new Custom JavaScript tab.
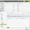
In the example above, it shows the language of the body text of a websites regional pages to identify any potential mismatches.
The library includes example snippets to perform various actions to act as inspiration of how the feature can be used, such as –
- Using AI to generate alt text for images.
- Triggering mouseover events.
- Scrolling a page (to crawl some infinite scroll set ups, or trigger lazy loading).
- Downloading and saving various content locally (like images, or PDFs etc).
- Sentiment, intent or language analysis of page content.
- Connecting to SEO tool APIs that are not already integrated, such as Sistrix.
- Extracting embeddings from page content.
And much more.
While it helps to know how to write JavaScript, it’s not a requirement to use the feature or to create your own snippets. You can adjust our templated snippets by following the comments in them.
Please read our documentation on the new custom JavaScript feature to help set up snippets.
Crawl with ChatGPT
You can select the ‘(ChatGPT) Template’ snippet, open it up in the JS editor, add your OpenAI API key, and adjust the prompt to query anything you like against a page while crawling.
At the top of each template, there is a comment which explains how to adjust the snippet. You’re able to test it’s working as expected in the right-hand JS editor dialog pre-crawling.

You can also adjust the OpenAI model used, specific content analysed and more. This can help perform fairly low-level tasks like generating image alt text on the fly for images for example.
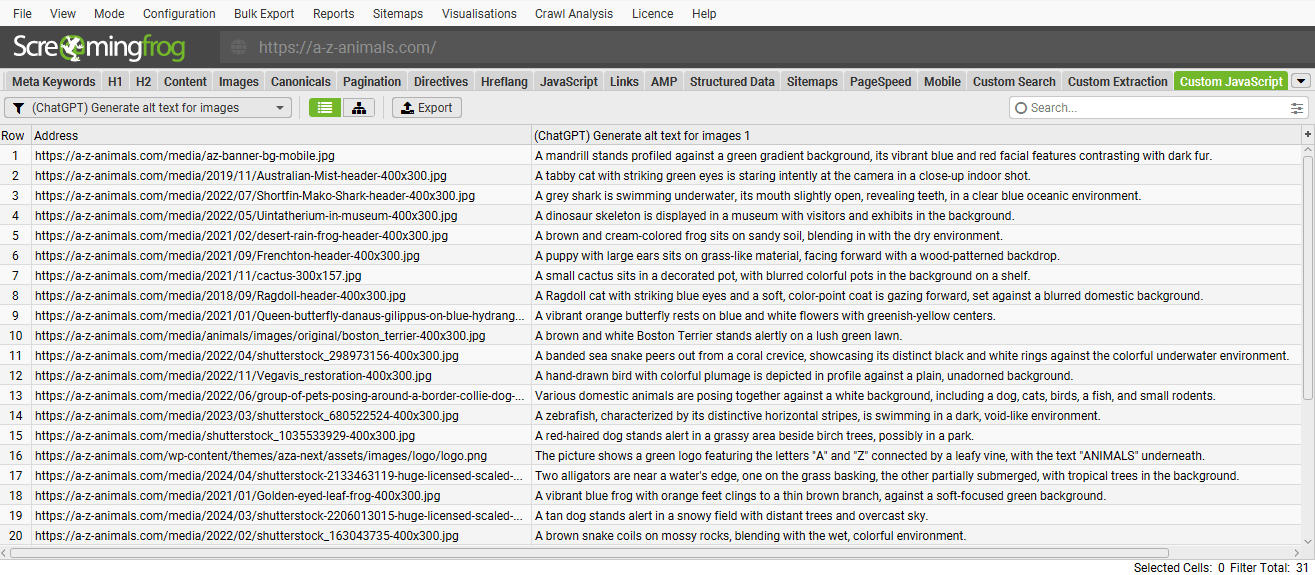
Or perhaps coming up with new meta descriptions for inspiration.
Or write a rap about your page.

Possibly too far.
There’s also an example snippet which demonstrates how to use LLaVa (Large Language and Vision Assistant) running locally using Ollama as an alternative.
Obviously LLMs are not suited to all tasks, but we’re interested in seeing how they are used by the community to improve upon ways of working. Many of us collectively sigh at some of the ways AI is misused, so we hope the new features are used responsibly and for genuine ‘value-add’ use cases.
Please read our new tutorial on ‘How To Crawl With ChatGPT‘ to set this up.
Share Your Snippets
You can set up your own snippets, which will be saved in your own user library, and then export/import the library as JSON to share with colleagues and friends.
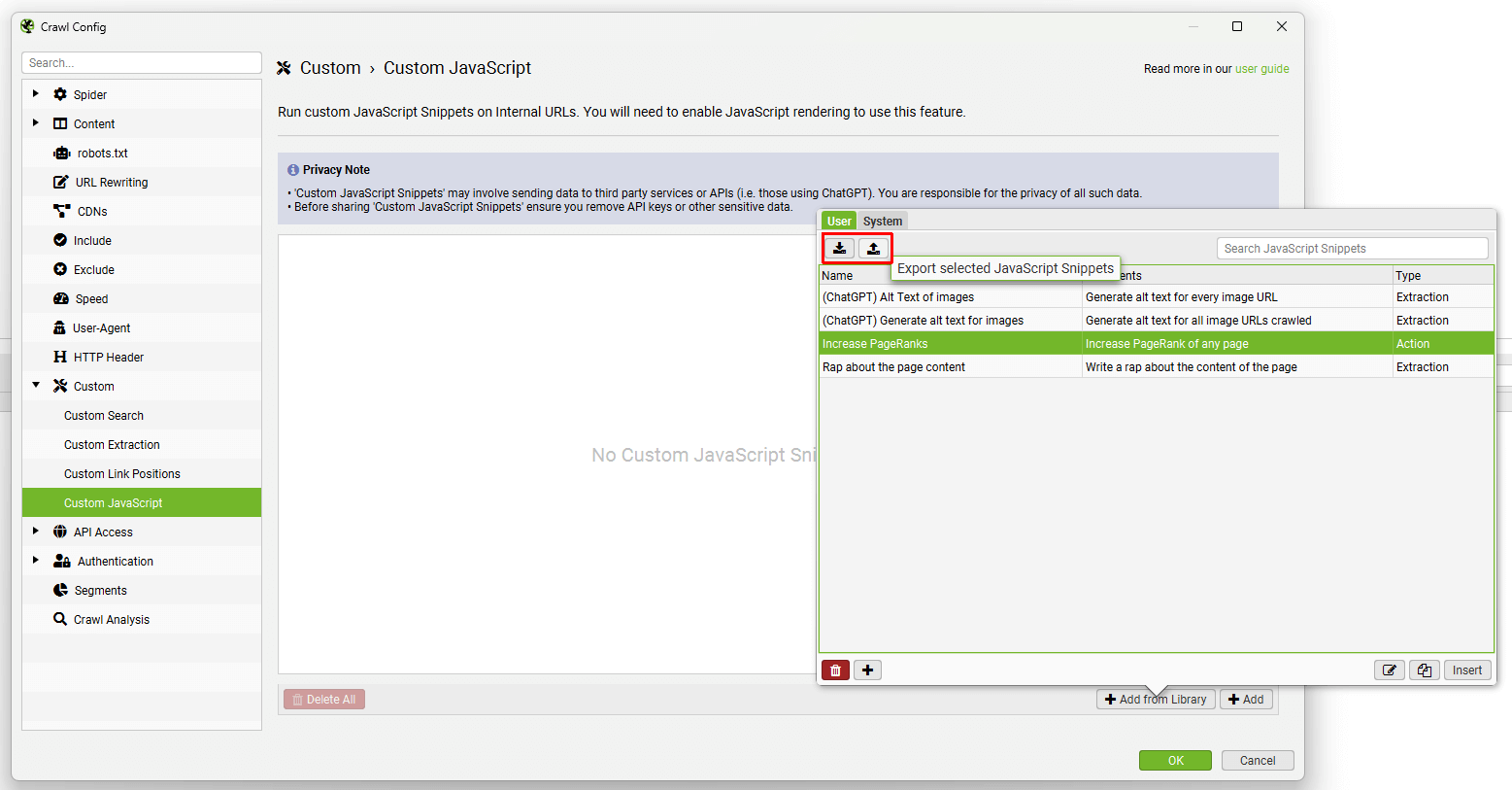
Don’t forget to remove any sensitive data, such as your API key before sharing though!
Unfortunately we are not able to provide support for writing and debugging your own custom JavaScript for obvious reasons. However, we hope the community will be able to support each other in sharing useful snippets.
We’re also happy to include any unique and useful snippets as presets in the library if you’d like to share them with us via support.
2) Mobile Usability
You are now able to audit mobile usability at scale via the Lighthouse integration.
There’s a new Mobile tab with filters for common mobile usability issues such as viewport not set, tap target size, content not sized correctly, illegible font sizes and more.
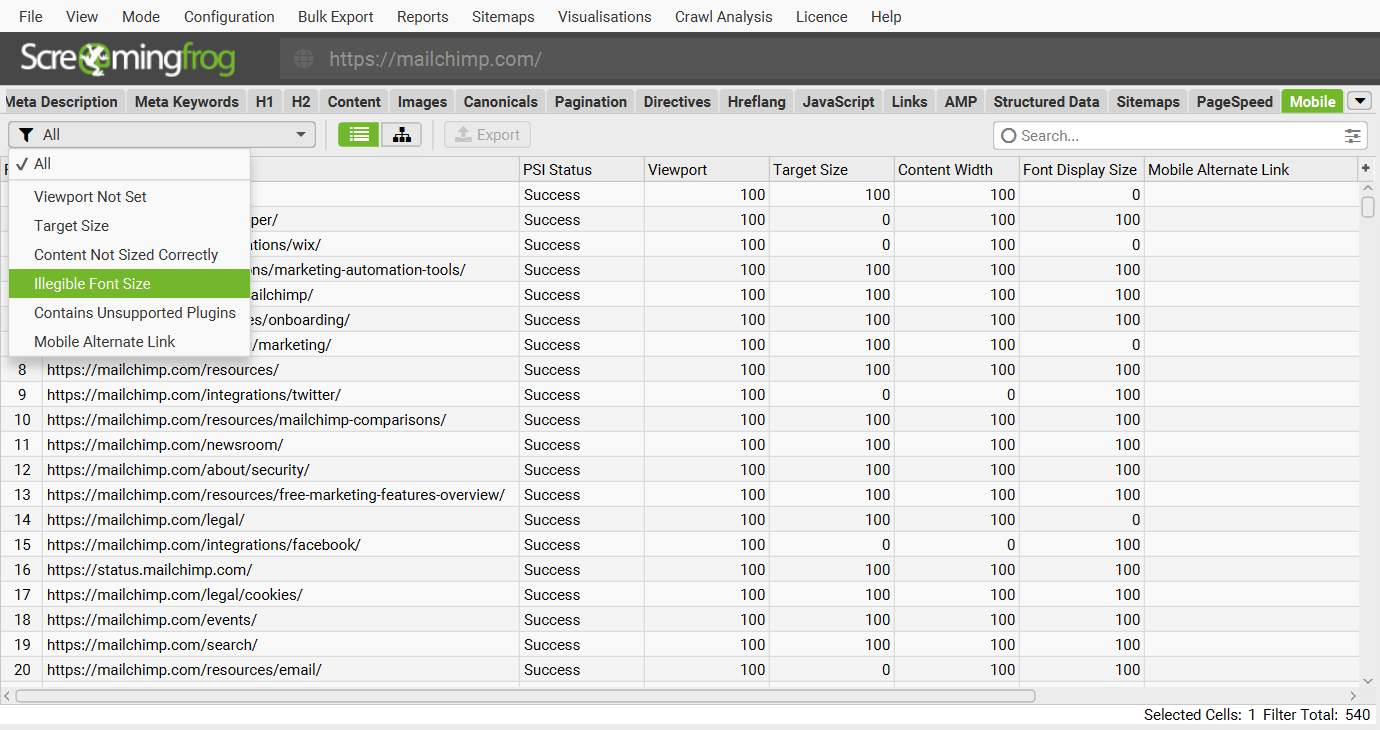
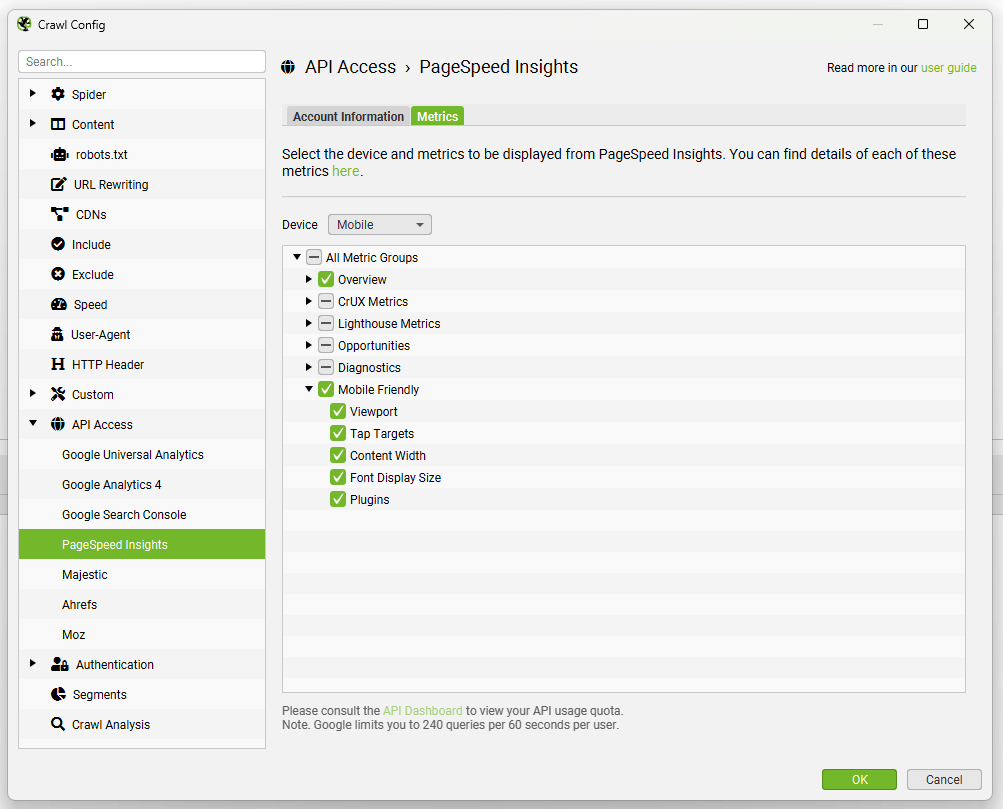
This can be connected via ‘Config > API Access > PSI’, where you can select to connect to the PSI API and collect data off box.
Or as an alternative, you can now select the source as ‘Local’ and run Lighthouse in Chrome locally. More on this later.
Granular details of mobile usability issues can be viewed in the lower ‘Lighthouse Details’ tab.

Bulk exports of mobile issues including granular details from Lighthouse are available under the ‘Reports > Mobile’ menu. Please read our guide on How To Audit Mobile Usability.
3) N-grams Analysis
You can now analyse phrase frequency using n-gram analysis across pages of a crawl, or aggregated across a selection of pages of a website.
To enable this functionality, ‘Store HTML / Store Rendered HTML’ needs to be enabled under ‘Config > Spider > Extraction’. The N-grams can then be viewed in the lower N-grams tab.
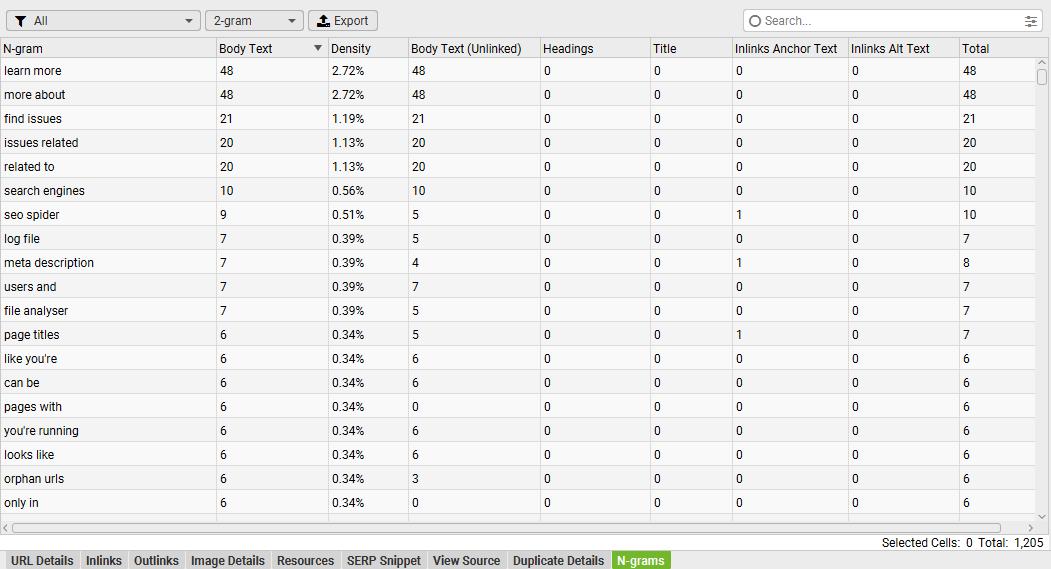
While keywords are less trendy today, having the words you want to rank on the page typically helps in SEO.
This analysis can help improve on-page alignment, identify gaps in keywords and also provide a new way to identify internal link opportunities.
New Approach to Identifying Internal Linking Opportunities
The N-grams feature provides an alternative to using Custom Search to find unlinked keywords for internal linking.
Using n-grams you’re able to highlight a section of a website and filter for keywords in ‘Body Text (Unlinked)’ to identify link opportunities.
Click on the image to see a larger version.
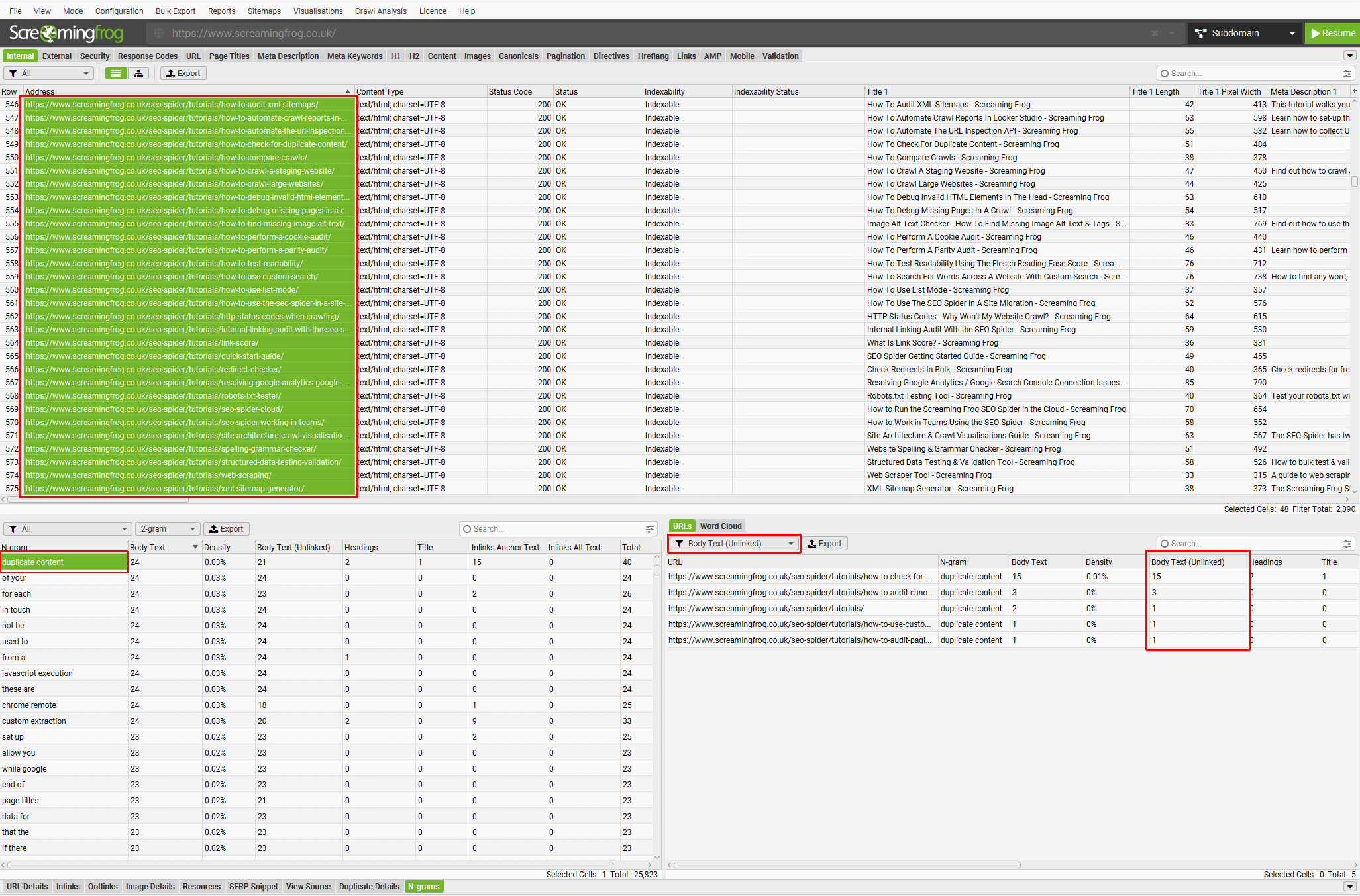
In the example above, our tutorial pages have been highlighted to search for the 2-gram ‘duplicate content’.
The right-hand side filter has been set to ‘Body Text (Unlinked)’ and the column of the same name shows the number of instances unlinked on different tutorial pages that we might want to link to our appropriate guide on how to check for duplicate content.
Multiple n-grams can be selected at a time and exported in bulk via the various options.
This feature surprised us a little during development at how powerful it could be having your own internal database of keywords to query. So we’re looking forward to seeing how it’s used in practice and could be extended.
Please read our guide on How To Use N-Grams.
4) Aggregated Anchor Text
The ‘Inlinks’ and ‘Outlinks’ tab have new filters for ‘Anchors’ that show an aggregated view of anchor text to a URL or selection of URLs.
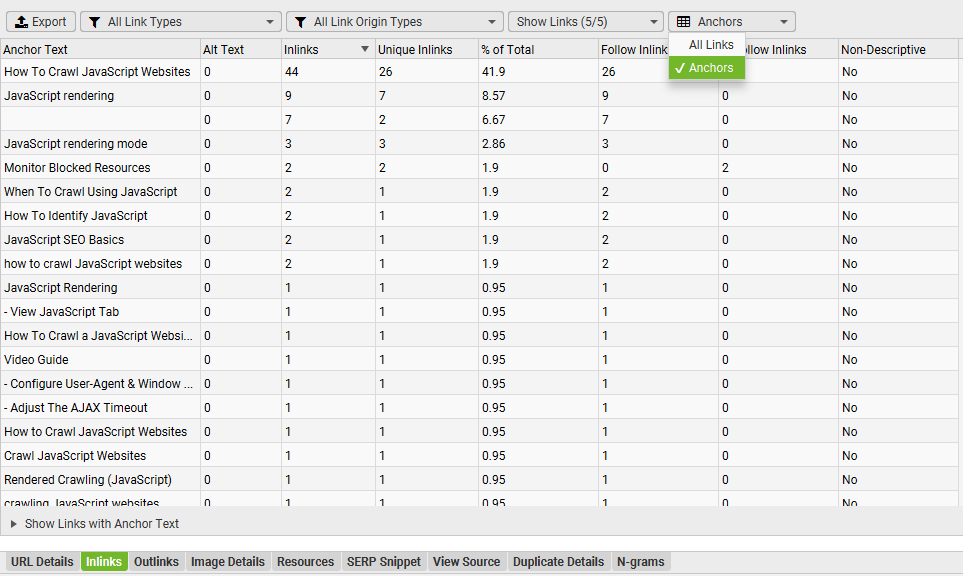
We know the text used in links is an important signal, and this makes auditing internal linking much easier.
You can also filter out self-referencing and nofollow links to reduce noise (for both anchors, and links).
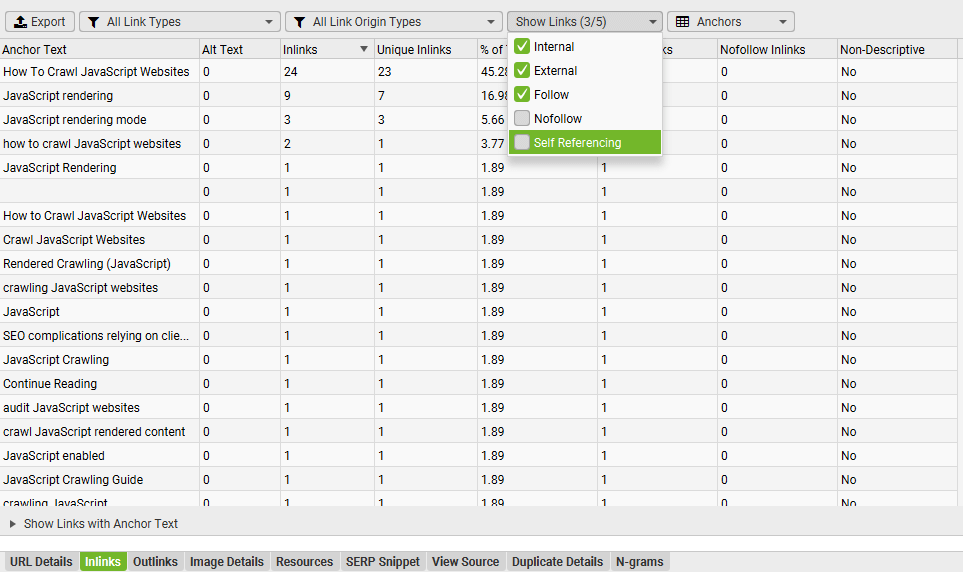
And click on the anchor text to see exactly what pages it’s on, with the usual link details.
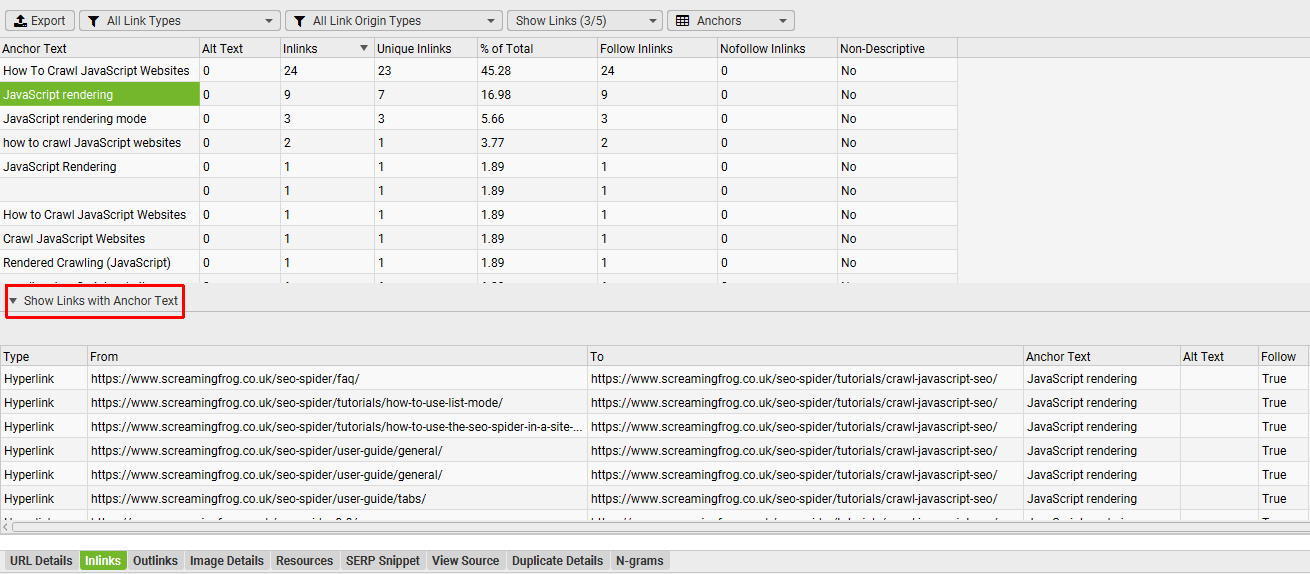
This update should aid internal anchor text analysis and linking, as well as identifying non-descriptive anchor text on internal links.
5) Local Lighthouse Integration
It’s now possible run Lighthouse locally while crawling to fetch PageSpeed data, as well as Mobile as outlined above. Just select the source as ‘Local’ via ‘Config > API Access > PSI’.
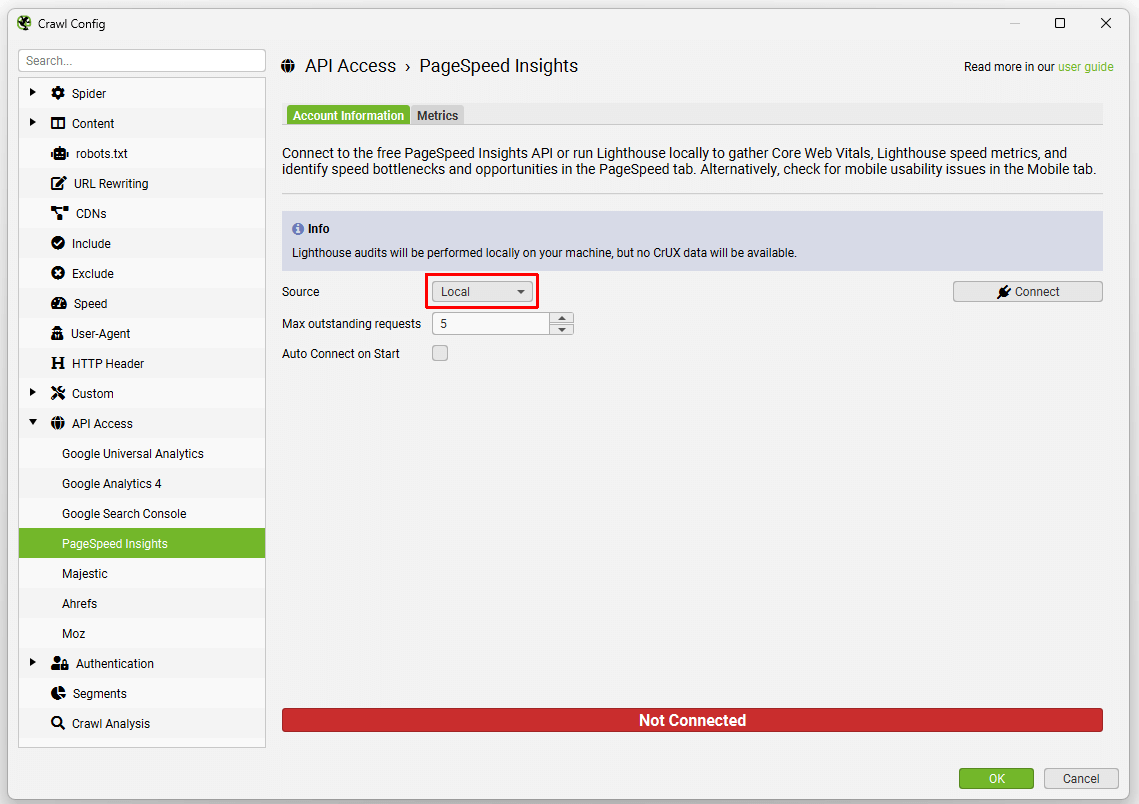
You can still connect via the PSI API to gather data externally, which can include CrUX ‘field’ data. Or, you can select to run Lighthouse locally which won’t include CrUX data, but is helpful when a site is in staging and requires authentication for access, or you wish to check a large number of URLs.
This new option provides more flexibility for different use cases, and also different machine specs – as Lighthouse can be intensive to run locally at scale and this might not be the best fit for some users around the world.
6) Carbon Footprint & Rating
Like Log File Analyser version 6.0, the SEO Spider will now automatically calculate carbon emissions for each page using CO2.js library.
Alongside the CO2 calculation there is a carbon rating for each URL, and new ‘High Carbon Rating’ opportunity under the ‘Validation’ tab.
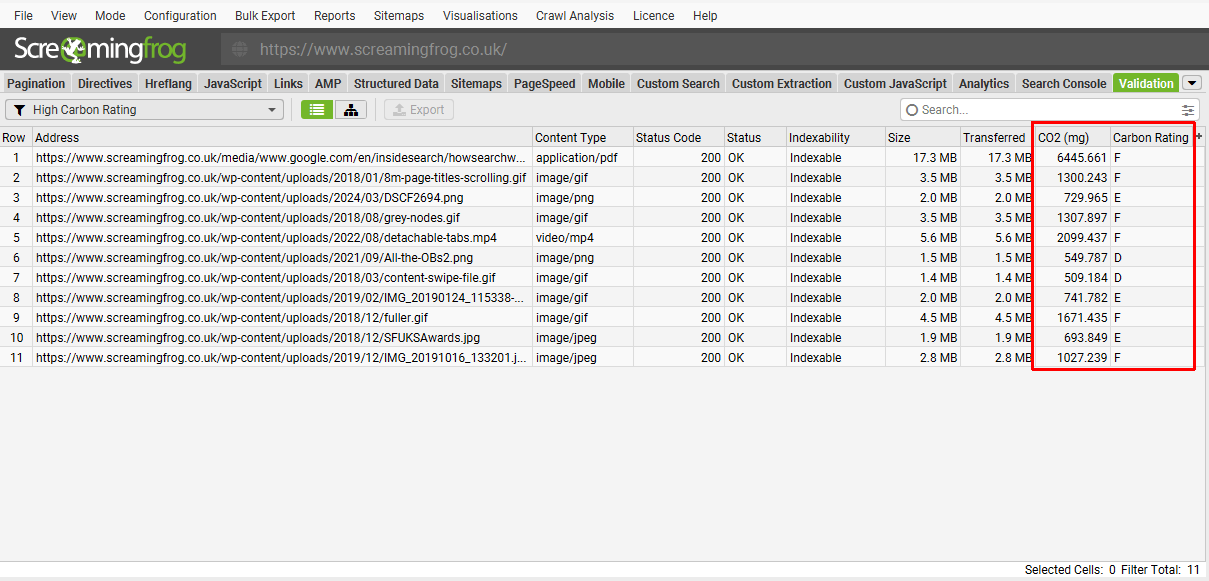
The Sustainable Web Design Model is used for calculating emissions, which considers datacentres, network transfer and device usage in calculations. The ratings are based upon their proposed digital carbon ratings.
These metrics can be used as a benchmark, as well as a catalyst to contribute to a more sustainable web. Thank you to Stu Davies of Creative Bloom for encouraging this integration.
Other Updates
Version 20.0 also includes a number of smaller updates and bug fixes.
- Google Rich Result validation errors have been split out from Schema.org in our structured data validation. There are new filters for rich result validation errors, rich result warnings and parse errors, as well as new columns to show counts, and the rich result features triggered.
- Internal and External filters have been updated to include new file types, such as Media, Fonts and XML.
- Links to media files (in video and audio tags) or mobile alternate URLs can be selected via ‘Config > Spider > Crawl’.
- There’s a new ‘Enable Website Archive‘ option via ‘Config > Spider > Rendering > JS’, which allows you to download all files while crawling a website. This can be exported via ‘Bulk Export > Web > Archived Website’.
- Viewport and rendered page screenshot sizes are now entirely configurable via ‘Config > Spider > Rendering > JS’.
- APIs can ‘Auto Connect on Start’ via a new option.
- There’s a new ‘Resource Over 2mb‘ filter and issue in the Validation Tab.
- Visible page text can be exported via the new ‘Bulk Export > Web > All Page Text’ export.
- The ‘PageSpeed Details’ tab has been renamed to ‘Lighthouse Details’ to include data for both page speed, and now mobile.
- There’s a new ‘Assume Pages are HTML’ option under ‘Config > Spider > Advanced’, for pages that do not declare a content-type.
- Lots of (not remotely tedious) Google rich result validation updates.
- The SEO Spider has been updated to Java 21 Adoptium.
That’s everything for version 20.0!
Thanks to everyone for their continued support, feature requests and feedback. Please let us know if you experience any issues with this latest update via our support.
Small Update – Version 20.1 Released 20th May 2024
We have just released a small update to version 20.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Updated carbon ratings and ‘High Carbon Rating‘ opportunity to be displayed only in JavaScript rendering mode when total transfer size can be accurately calculated.
- ChatGPT JS snippets have all been updated to use the new GPT-4o model.
- Added new Google Gemini JS Snippets. The Gemini API is available in select regions only currently. It’s not available to the UK, or other regions in Europe. Obviously it’s the users responsibility if they circumvent via a VPN.
- Included a couple of user submitted JS snippets to the system library for auto accepting cookie pop-ups, and AlsoAsked unanswered questions.
- Re-established the ‘Compare’ filter in the ‘View Source’ tab in Compare mode that went missing in version 20.
- Fixed issue loading in crawls saved in memory mode with the inspection API enabled.
- Fixed a few issues around URL parsing.
- Fixed various crashes.
Small Update – Version 20.2 Released 24th June 2024
We have just released a small update to version 20.2 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Update to PSI 12.0.0.
- Schema.org validation updated to v.27.
- Updated JavaScript Libary to use Gemini 1.0.
- Show more progess when opening a saved crawl in memory mode.
- Retry Google Sheets writing on 502 responeses from the API.
- Added Discover Trusted Certificates option to make setup for users with a MITM proxy easier.
- Added ‘Export’ button back to Lighthouse details tab.
- Fixed intermittent hang when viewing N-Grams on Windows.
- Fixed issue with UI needless resizing on Debian using KDE.
- Fixed issue preventing High Carbon Rating being used in the Custom Summary Report.
- Fixed handling of some URLs containing a hash fragment.
- Fixed various crashes.
Small Update – Version 20.3 Released 23rd September 2024
We have just released a small update to version 20.3 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Fixed bug where the SEO Spider was incorrectly flatting iframes found in the head when inserted via JS.
- Fixed bug with URLs in list mode not being imported if they had capital lettings in the protocol.
- Fixed bug with filtering column in custom extraction.
- Fixed bug in basic authentication with non ASCII usernames.
- Fixed various crashes.
- Update Java to 21.0.4.
Small Update – Version 20.4 Released 22nd October 2024
We have just released a small update to version 20.4 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Fixed an issue with JavaScript rendering on macOS Sequoia.
- Fixed freeze in a crawl if sitemap is discovered late in the process.
- Fixed crash when connecting via RDP.






Thank you, Dan, for this helpful update guide.
Hi,
Are you thinkinh about integration with indexing api?
Will be great add to index urls form “indexable URL not indexed” by one click :)
One small step for a frog. A big one for the SEO universe ;-)
Not seeing the field for. “There’s a new ‘Enable Website Archive’ option via ‘Config > Spider > Rendering > JS’, which allows you to download all files while crawling a website. This can be exported via ‘Bulk Export > Web > Archived Website’.”
Amazing update btw!
Hi Pablo,
Thank you! Just to check, have you downloaded and installed version 20?
It should be there, at the bottom of the options underneath ‘JavaScript’ (and ‘Enable Rendered Page Screenshots’ etc). Quite well hidden!
Cheers
Dan
bro, i had like to know is there a ways to download all web.archive.org
html, js, css, img in the latest snapshot without duplicate url ??
The inclusion of artificial intelligence and new features are nice. Thank you for your work.
Writing a rap about your pages might be the most inspirational function I’ve ever come across.
Thank you Dan, these are great updates. I really like the custom Javascript snippet and chat GPT integration.
Excited to try the CHAT GPT integrations. Especially the image alt tags part, not sure how accurate these will be. Did not have good experience with some of the AI plugins in WordPress doing image alt tags.
The possibilities linked to Javascript and the possibility of interacting with AI tools is a major advance which switches ScreamingFrog from a tool which only does auditing to a tool which does auditing and which also allows suggest improvements.
What is the tool’s roadmap? Moving towards SEO project management?
¡Muchas gracias! La nueva funcionalidad por la cual reconoce el contenido en diversos idiomas, incluido español, es perfecta.
Muchas gracias por seguir mejorando con regularidad esta herramienta :)
Wow guys. So many new features, super useful! Love the website archive option. Also, ChatGPT integration is a game changer. The best SEO crawler now is powered by AI :)
These new features are excellent. ChatGPT integration and n-grams analysis are superb. Our team loves how you are adding more semantic and data science features to the crawler. Everyone in the agency uses it daily!
Thanks a lot. In particular, I was very excited about the (Custom JavaScript Snippets) AI and N-grams Analysis features. The Word Cloud in N-gram Analysis is incredible.
You guys have done it again! Screaming Frog is the only online product I have ever used that consistently provide great updates. Keep it up Particularly excited with OpenAI and Carbon Calculator stuff
Thanks, JC – appreciate that!
I am very excited for these new features. Especially the GPT integration.
The update to version 20.0 of Screaming Frog SEO Spider is undoubtedly the most significant and innovative ever. Your innovations and commitment to developing such advanced tools have completely convinced me to become your next customer. Thank you guys, keep it up!
Thanks for showing us the way to integrate the OpenAI API. Keep up the good work.
That ChatGPT integration is really going to open up the door for some interesting use cases, great update!
Hi guys! Version 20.0 for macOS (Intel) version 10.14 or 10.15 is not working. We are still in 19.2. Are you going to end the support for old Macs?
Hi Lautaro,
That’s correct, if you are running macOS version 10.14 “Mojave” or 10.15 “Catalina” you will not be able to use version 19.3 or later unless you update your operating system.
Most users will be able to update their OS. If you’re unable to as your machine is too old, you will have to remain on Spider 19.2 until you update your machine.
This is due to modern requirements of components used in the software.
Cheers.
Dan
Thanks for your reply Dan. I’m sorry to hear that and I guess it’s time to buy a new Mac :)
Top ! Merci Dan pour cet article :)
Je vais tester tout de suite la nouvelle technique pour optimiser le maillage interne !
Fantastic update! The integration with AI offers a wealth of possibilities. I have a question: after crawling a website, is there a way to find out how long it took? I can’t seem to find this information, but it would be extremely helpful to show it to the client after technical optimization.
Hi Wojciech,
Good to hear! We don’t have a duration time currently, but it’s ‘on the list’.
You could check the logs (help > debug > save logs) to see the start and finish times though.
Cheers.
Dan
Nice Update, Thank you. We are very excited.
I just wanted to say Thank You for this wonderful tool!
It helped me a lot to quickly identify the problems on my website, so I made a blog post for you :)
https://maecenium.org/free-website-audit-tool/
Thank you once again.
From Texas,
Alex
A really great update. We are looking forward to use the new AI features and are pleased that you always have your finger on the pulse.
Keep up the good work!
ScreamingFrog’s new features, like website archive and ChatGPT integration, are fantastic! It’s evolving from an auditing tool to an SEO project management powerhouse. Excited to see where this roadmap leads! huge shoutout to you.
Great update! The integration with AI brings a multitude of opportunities.
20.0 version is just awesome!
Screaming frog is definitively the best technical SEO tool of the world!
If I can add a little request.
I regularly need to use “Report” exports to see redirect chains.
Could you consider building a dedicated in-App tab (with filters and segmentation) to help us saving time ?
Thank you so much for your tool and the updates !
Wow, awesome update! You guys working on a possibility to work with Python snippets as well?
I think this is the most interesting update by far. Replacing a lot of Chrome extensions and even some of the scrapebox functionalities for which I was not using SF. It makes the whole experience easier. Custom Search, CUstom extractions were big, but actually integrating with openai in this super fast crawler. Chapeau !
Hei Dan, when can you have a solution to be able to crawl sites with the AntiBOT system of siteground hosting? meta refresh redirects do not allow it
Hi David,
Not actually one I’ve come across before, at least that name.
Are you able to share a site where you’ve seen the issue?
Cheers
Dan
Your tool is very helpful for SEO, and your updates make it more useful day by day. So thanks for providing this.
Great update as usual, with many cool features. The AI integrations are particularly promising and show great potential in the near future. Can’t wait to see the next versions of one of my favourite SEO tools.
Great update as usual, with many cool features. The AI integrations are particularly promising and show great potential in the near future. Can’t wait to see the next versions of one of my favourite SEO tools.
Great update! Excited to get using it for clients
The update is great. Number one tool for SEO.
Thanks for making the GPT integration possible, it’s surely going to save quite a lot of time for those who have many images to generate alts for!
The possibility to use GPT-4 might be what pushes me to finally buy Screaming Frog, well done guys.
This is a major update : you guys have set the bar really higher with all those new features, and the fact that GPT is integrated is certainly one of the best part of it. Congrats !
Cool! Thanks Dan!
Hi,
So can you make it automatically generate Meta descriptions with ChatGPT??
I assume that it changes them in the file and if you want to recover the original ones you have to crawl again.
Very good guide, thank you very much.
Best update ever! Custom JavaScript, ChatGPT, N-grams – I don’t know how I ever managed without it before.
Nice new features, N-grams, openai intration, aggregation of anchors is cool xD
Thank you for Chat GPT integration.
Is there a way to retrograde back to v19? I have project and exported crawls of our websites that I can now no longer open in the tool – it comes up with an error.
I don’t know another way to fix the error other than retrograde to the previous version that worked.
I also don’t want to risk googling to a pack of dodgy sites with the old versions supposedly posted on them. Would like to get from official source.
Site is very big so crawl takes an extremely long time to complete and I do not want to do it again to view the issues/errors/concerns that the crawler picked up on.
Hi Ryan,
Just pop us an email via support and we can advise – https://www.screamingfrog.co.uk/seo-spider/support/
Old crawls should open in new versions as an side.
Cheers
Dan
Nice new features @Dan, thank you GPT :-)
Version 20 is fantastic; thanks to Liam, Dan, and the team for the continuous updates and bug fixes. Support has been top-notch.
Thanks for the update and the article. GPT <3
Great tools and great updates again. Thanks
Update to 20.4 is not working for me and my colleaques. Screaming Frog is just shutting down and if I reopen the update note pops up again :(
Hi Kevin,
You can pop in your logs (Help > Debug > Save Logs) so we can take a look? ([email protected])
Alternatively, you can just download directly here – https://www.screamingfrog.co.uk/seo-spider/
Cheers
Dan
Screaming Frog has always been my go-to tool if you want anything properly analyzed during my more than 20 years of SEO.
This release actually gave me some new ideas of running audit even deeper and getting things done faster.
Thanks for a really great program!