10 Features In The SEO Spider You Should Really Know
Dan Sharp
Posted 22 January, 2015 by Dan Sharp in Screaming Frog SEO Spider
10 Features In The SEO Spider You Should Really Know
I wanted to write a quick post about some of the features in our Screaming Frog SEO Spider tool, that are a little hidden away and are quite often missed, even by experienced users.
Some of these are actually my favourite features in the tool and have saved me countless hours, so hopefully some of these will help you, too.
1) List Mode Is Unlimited
Some of this post will include featues only available with a SEO Spider licence, however, did you know ‘list mode’ in the free lite version, isn’t limited to 500 URLs like regular ‘spider’ mode? It’s actually unlimited.

So you can upload 10k URLs and crawl them, without the need to buy a licence.
Update – Please note, this has changed since this post was published in 2015. List mode is now limited to 500 URLs, without a licence.
2) Auditing Redirects In A Migration
This is by some distance my personal favourite feature due to the amount of time it has saved.
I used to find it a pain to audit redirects in a site (and, or domain) migration, checking to ensure a client had set-up permanent 301 redirects from their old URLs, to the correct new destination.
Hence, we specifically built a feature which allows you to upload a list of your old URLs, crawl them and follow any redirect chains (with the ‘always follow redirects’ tickbox checked), until the final target URL is reached (with a no response, 2XX, 4XX or 5XX etc) and map them out in a single report to view.
This report does not just include URLs which have redirect chains, it includes every URL in the original upload & the response in a single export, alongside the number of redirects in a chain or whether there are any redirect loops.
Click on the tiny incomprehensible image below to view a larger version of the redirect mapping report, which might make more sense (yes, I set-up some silly redirects to show how it works!) –
You can read more about this feature in our ‘How to audit redirects in a site migration‘ guide.
3) The Crawl Path Report
We often get asked how the SEO Spider discovered a URL, or how to view the ‘in links’ to a particular URL. Well, generally the quickest way is by clicking on the URL in question in the top window and then using the ‘in links’ tab at the bottom, which populates the lower window pane (as discussed in our guide on finding broken links).
But, sometimes, it’s not always that simple. For example, there might be a relative linking issue, which is causing infinite URLs to be crawled and you’d need to view the ‘in links’ of ‘in links’ (of ‘in links’ etc) many times, to find the originating source. Or, perhaps a page wasn’t discovered via a HTML anchor, but a canonical link element.
This is where the ‘crawl path report’ is very useful. Simply right click on a URL, go to ‘export’ and ‘crawl path report’.

You can then view exactly how a URL was discovered in a crawl and it’s shortest path (read from bottom to top).

Simple.
4) AJAX Crawling
I’ve been asked quite a few times when we will support crawling of JavaScript frameworks such as AngularJS. While we don’t execute JavaScript, we will crawl a site which adheres to the Google AJAX crawling scheme.
You don’t need to do anything special to crawl AJAX websites, you can just crawl them as normal. We will fetch the ugly version and map it to the pretty version, just like Google.
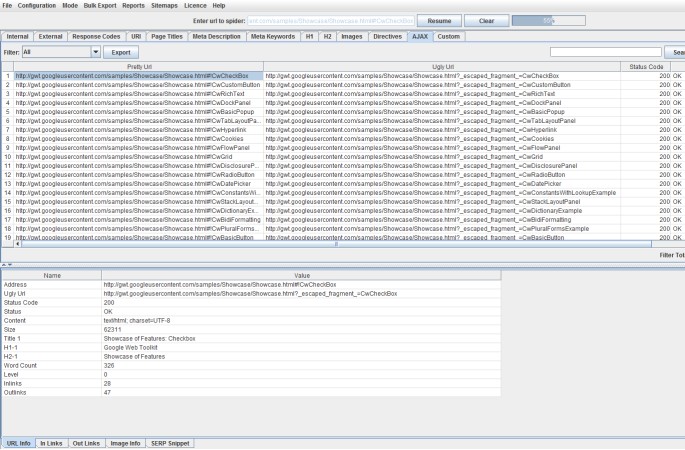
You can view this all under the ‘AJAX’ tab obviously.
There’s also a ‘with hash fragment’ and ‘without hash fragment’ filters for this tab. This can be useful to identify AJAX pages which only use the meta fragment tag and hence require Google to double crawl (to crawl the page, see the tag and then fetch the ugly version) which can put extra load on your servers.
5) Page Title & Meta Description Editing Via The SERP Snippet Emulator
We developed a SERP snippet emulator in the lower window tab, which allows you to edit page titles and meta descriptions directly in the SEO Spider.
It can be pretty challenging to work out pixel widths in Excel, so you can just edit them directly in the tool and they will update in the interface, to show you pixel width and how they might be displayed in the search results.
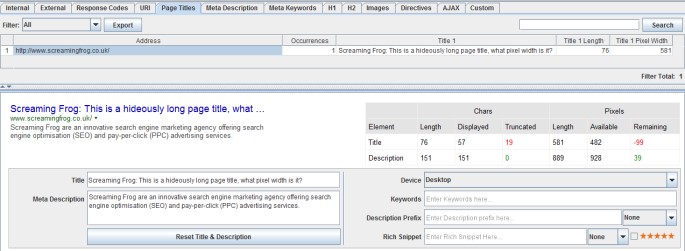
Any changes made are automatically saved in the tool (unlesss you use the ‘reset’ button), so you can make as many edits as you like, then export and send diretly to the client to approve or upload when you’ve finished.
6) SERP Snippets By Device
We all know that 2015 (like every year, for the last 5+ years) is ‘year of the mobile’, so did you know that pixel width cut off points are different when viewed on mobile & tablet devices, than desktop?
You can switch device type to get a better idea of how they might display across all devices.
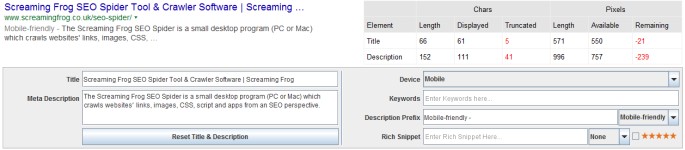
The ‘Mobile Friendly’ prefix will be available in our next iteration of the SEO Spider due for release shortly (I am using a beta in the screenshot).
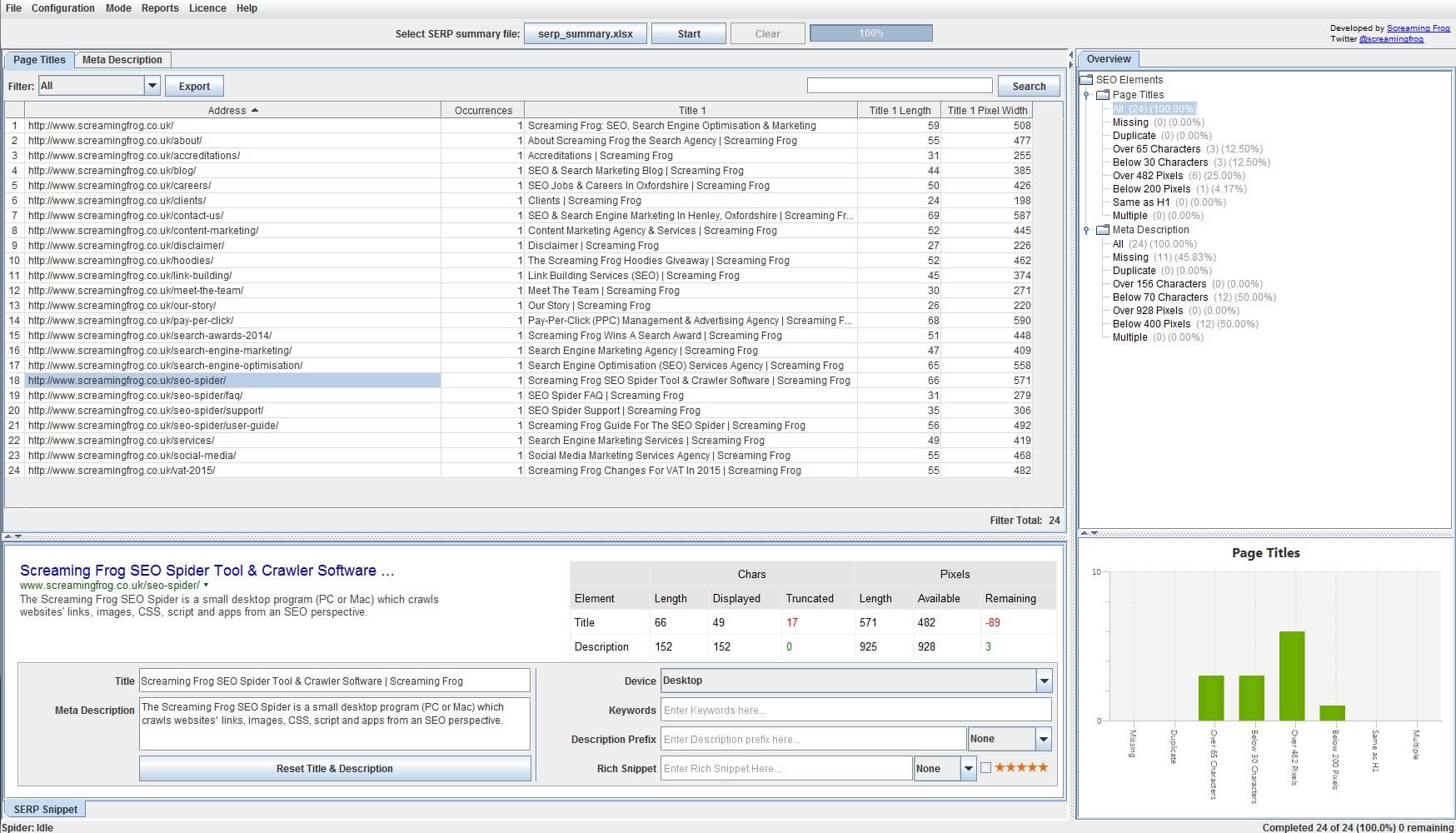
7) SERP Mode
While we are on the subject of SERP snippets, if you switch to ‘SERP mode’, you can upload page titles and meta descriptions directly into the SEO Spider to calculate pixel widths (and character lengths!). There is no crawling involved in this mode, so you can test them before they are put live on a website.
8) XML Sitemap Auditing
Did you know that you didn’t need to convert your XML sitemap into a list of URLs for us to crawl it? You can simply save the XML sitemap and upload it in list mode and we will crawl the XML format natively.
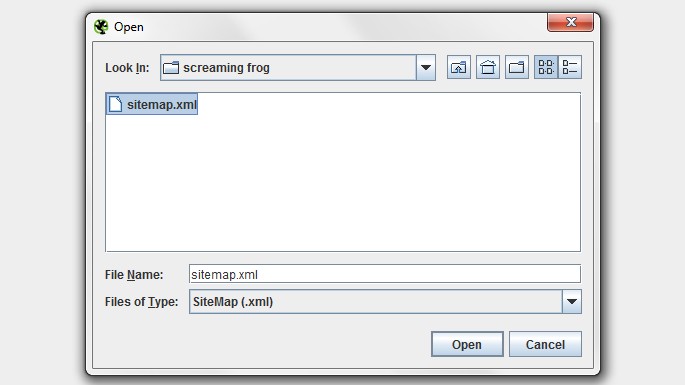
A quick and easy way to ensure you don’t have a dirty sitemap, to avoid the search engines reducing their trust in it.
9) Canonical Errors
By default the SEO Spider will crawl canonicals for discovery and these URLs will appear as usual within the respective tabs. However, there’s also a canonical errors report under the ‘reports’ menu, which can be easy to miss and provides a quick summary of canonical related errors and issues.
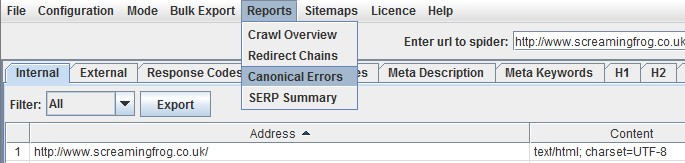
The report will show canonicals which have no response, 3XX redirect, 4XX or 5XX error (anything other than a 200 ‘OK’ response) and highlight any URLs discovered only via a canonical, that are not linked to internally from the sites own link structure (in the ‘unlinked’ column when ‘true’).
10) Crawling Authenticated Staging Sites
This feature isn’t very obvious, but essentially the SEO Spider supports basic and digest authentication, meaning you can crawl staging sites or development servers, which require a login to access.
Often sites in development will also be blocked via robots.txt as well, so make sure this is not the case or use the ‘ignore robot.txt configuration‘, insert the staging site URL and crawl.
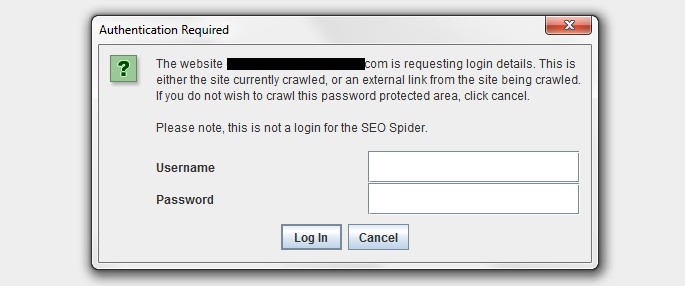
At this point an authentication box will pop up automatically (as shown above) and ask you to insert the username and password credentials to crawl.
Your Turn
Are there any hidden away features I’ve missed? If so, please do share them in the comments.
We hope to have a new version of the Screaming Frog SEO Spider ready for release within the next two weeks, so expect a lot more to come, too.






Great list! I personally didn’t know that you could just upload an XML sitemap in list mode (number 8).
My favourite feature has to be the custom option in the configuration menu.
Want to know if your site has Google Analytics on all the pages on your site? Just enter the tracking code in here and Screaming Frog will tell you.
Hi Tom,
Good to hear you find this one useful. We’ve seen lots of interesting uses of this feature, including identifying Schema, ‘soft 404’ messaging, ‘out of stock’ pages etc.
Cheers.
Dan
How would I configure the Custom option in order to find “Soft 404”? When I do a crawl I see no indication about soft 404s, thanks.
Should also add that Google Search Console gives me soft 404 errors.
I’ve been using Screaming Frog for years and it keeps improving. Looks like there are a lot features I can use, which I didn’t really use before.
Great work.
excellent article! thanks for the tips
very helpful
cheers
Thanks for stating these awesome features.
This is great! Thank you for the post – there are just so many features, and only so much time in life to explore on my own, so I had not known about some of these! I am excited to add even more value to my site audits now like the sitemap auditing and canonical errors reports…
Perfect, thanks for the post. I didn’t know how to export crawl path (in links) for given URL. Now I know.
Nothing like an post like this to make you realise you still got loads to learn!! Thanks
Not long started using Screaming Frog however it has helped, with immediate effect, the productivity of my marketing team by excluding websites with errors.
However, when using Screaming Frog to look at over 10,000 websites once half way through it comes up with a message about there not being ‘enough space’. Then when it hits about 7-8,000 in my list it slows right down.
Is this because of the need for more space? How do I create/give the programme more space?
Thanks
Hey Scott,
Good to hear it’s helping out.
Yes exactly – The memory warning window links to the user guide which provides instructions on increasing your memory allocation.
Apologies if that’s not clear, but here are the details on how to increase your memory to crawl more – https://www.screamingfrog.co.uk/seo-spider/user-guide/general/#6
Cheers.
Dan
Many thanks, that should help with future crawls.
New and exciting features of my favorite SEO tool.
Thanks for helping us with your´s tips in our daily work .
Regards from Spain
Great list!
I have been using Screaming Frog for years, and yet this tool continues to amaze me.
Crawl a sitemap? How on earth have I missed this feature!? Thank you, thank you, thank you.
Great tips! Screeming frog is one of my favorite SEO tool. It helps me a lot. I would recommend it to everyone. :)
Good overall software with nice features.
Great post, Dan. Screaming Frog is definitely my number 1 tool.
Screaming Frog has helped, with immediate effect,when it hits about 9,000 in my list it slows down a little.
why is this?
Thanks
Hi Owen,
Thanks – Good to hear you find it useful.
Any slown down will generally be due to reaching memory allocation. So I’d recommend increasing memory, more here – https://www.screamingfrog.co.uk/seo-spider/faq/#33
Cheers.
Dan
Wish I had seen this earlier, have been using SF for years but have only just discovered crawl path reports.
Thanks for the useful post
Thanks for sharing such a great article. Shared!
#3 is news to me, and for the first time I’m about to try #6 and #7 for a client who has poor Titles and Descriptions.
I much prefer auditing with ScreamingFrog than using other SAAS products. Far more powerful, insightful and reliable, and it only falls down on PC capacity when looking at big sites.
Ever considered offering it as a cloud service?
Hi George,
Thanks for the kind comments.
Yes, we have considered cloud and more scalable solutions and you probably won’t be surprised to hear we have something in development!
I think desktop and cloud both have their advantages and disadvantages and it depends on your own preference, plus the job at hand :-)
Cheers.
Dan
Thanks for telling us about the awesome features of SEO spider. Before it, I don’t know about point 7 features.
Great list!
I have been using Screaming Frog for years, and yet this tool continues to amaze me.
Hello I want to crawl all link in this page automatically, the page with number like this :
http://www.mysite.com/search?id=result&page=1
http://www.mysite.com/search?id=result&page=2
http://www.mysite.com/search?id=result&page=3
etc
I use to manual copy paste that links to the screamfrog search form box, is there any way to automatic crawling after page=1 finish, then it go to page=2, etc ?
Thanks,
Hi Dudeski,
Yes, you just need to use ‘list’ mode – https://www.screamingfrog.co.uk/seo-spider/user-guide/configuration/#15
Cheers.
Dan
Great post, Dan. Screaming Frog is definitely my number 1 tool. Makes audits so much easier!
Now this is what you call a useful list. I am new to screaming frog and this list is going to help me so much. Will be looking forward for more of these in the future. Thanks!
Screaming frog team,
excellent! you guys continue to amaze me and your company and the little frog is a great contribution to our seo industry. Would like to commend on the tip no. #3 especially – good way to understand your crawl pattern and the url / page priorities set by crawlers.. good insights team. looking forward for more!
Cheers, Josh
webmasters desk seo
Your provide great info about your tool. Thanks a lot man.
Such a sick tool!
1st I love this tool. I just discovered the “tree” view, which is amazing. I’m wondering, though, is there a way to export the tree view? I tried and it spit out the ‘normal’ report with all html.
Thanks for an amazing tool that has saved me a ton of time and frustration!
Hey Dash,
Thank you, much appreciated.
With regards to ‘tree view’, please check out my reply over here to Jinnat –
https://www.screamingfrog.co.uk/seo-spider-3-0/#comment-14735
Cheers.
Dan
Thanks for in-depth review, never heard of this tool before. Looks like worth the try when my old subscription will end.
The authentication is good, but what about those sites where it does not pop up a window, but the login is on the webpage? Is there any way to crawl pages behind this type of login?
Hey JP,
More detail on the types of authentication we support here – https://www.screamingfrog.co.uk/seo-spider/faq/#35
That’s it at the moment, but we do have plans to support other logins and forms.
Cheers.
Dan
Since the tool crawls the whole site, it would be useful to be able to find all instances of any arbitrary code fragment that I am looking to investigate. e.g. class=”node node-page clearfix”
Simply getting a list of all the pages that use this fragment would be useful.
Hey Ash,
You should be able to use the custom search feature to find those – https://www.screamingfrog.co.uk/seo-spider/user-guide/configuration/#search
Hope that helps!
Cheers.
Dan
Hello,
Is it possible to upload multiple .seospider files at once in order to compare links from other crawls (i had to crawl 4 separate lists and would like to combine them all into one .seospider file if possible).
Thank you!
Best,
RR
Hey RR,
No, unfortunately you can’t upload multiple .seospider files! I’m not sure what you’re trying to do, but you can obviously export the data from each, combine and then upload in list mode again and crawl together.
Cheers.
Dan
Hi,
I think the previous question may have had to do with change. If I can upload A and then run against current B, then I can gain a measure of change.
If website need authentication, how will i be able to crawl the website?
Can i pass User ID and Password in this tool?
Thanks,
Renuka
Hi Renuka,
Presuming you didn’t make it to number 10 on the list?
Cheers.
Dan
Hi Dan,
The website i mentioned above require end user to login/register before entering into website.(Please do not expose this website url in post)
If i enter (removed) in url field of tool, it is unable to crawl these pages which require authentication. Only pages which are not behind authentication like privacy policy, login,contact us are crawled.
Hey Renuka,
No worries, I removed the URL in your comment above to keep it confidential.
This type of login is not supported in the SEO Spider. The only type of authentication we support is as per the FAQ I am afraid.
Thanks,
Dan
Hi,
I really love to work with Screaming Frog. However since our site depends heavily on AngularJS I would like to know if you are considering to render javascript in Screaming Frog in the future.
Thanks!
//Micke
Hey Micke,
Awesome to hear! Yes, this is in our development list and something we are looking into :-)
Cheers.
Dan
And I thought I knew everything about the Screaming Frog Spider tool ;)
I love the crawl path report, as well as SERP snippet emulator features.
This article is very informative. Thanks for sharing!
Hello,
I have purchased SEO frog license last week and have crawled the website once only. But now the software is not crawling the website, it shows content 0 and moreover for my another website in staging server, it doesn’t display the login popup. I have check the configuration, the request authentication is checked. Please solve the issue asap.
Thanks
Hey Tarun,
Thanks for your message below. Just to mention, you’re commenting on a post that’s 16-months old, when you can get help directly via our support – https://www.screamingfrog.co.uk/seo-spider/support/
So just pop through the full details there, including the site you’re trying to crawl :-) We reply really fast.
For the login popup to appear, please do make sure you have the ‘ignore robots.txt’ configuration ticked – https://www.screamingfrog.co.uk/seo-spider/faq/#can-the-seo-spider-crawl-staging-or-development-sites-that-are-password-protected-or-behind-a-login
Cheers.
Dan
Great article. Shared. Thanks.
I <3 Screaming Frog – working with this tool all day long.
Impressive features, I have just read about SEO spider’s features. But I want to ask… Is it only for Crawling related features and analyze for on page?
What about off-page, any other tool for off page SEO/ Backlinks?
Hi Ramandeep,
It’s on onsite tool, very different to a backlink analysis tool.
I’d recommend checking out Majestic, Open Site Explorer or Ahrefs for that.
Cheers.
Dan
Is there any way to compare the results of 2 crawls.
Example:
Crawl #1 crawled 100k URLs
Crawl#2 Crawled 150k URLs and I would like to know what cause this difference…
The software support URLs with hashbang (#!)? I’m trying to crawl a website with these and there’s no report for that.
Hey Ricardo,
Yes, it does! These URLs will appear under the ‘internal’ tab and the ‘AJAX’ tab (if set-up correctly as per Google’s now deprecated AJAX crawling scheme).
You can pop through the site URL if you’re having issues to our support – https://www.screamingfrog.co.uk/seo-spider/support/
Cheers
Dan
Hi,
we get a licence, the tool is nice, very easy to use. But there are two main limitations that may be adressed ?
1. the url src from where each url in the report are extracted are not reported : this could answer the question : in what page this 404 url is embedded ?
2. login forms and session management are not handled : how get report of both connected and main pages together ?
Thanks,
Simon
Hi Simon,
Thanks for the comment.
1) You can view the source links of any URL or error, have a read here – https://www.screamingfrog.co.uk/broken-link-checker/
2) We support basic and digest authentication at the moment, but more to come – https://www.screamingfrog.co.uk/seo-spider/faq/#can-the-seo-spider-crawl-staging-or-development-sites-that-are-password-protected-or-behind-a-login
Cheers.
Dan
No doubt the best tool for everything! You guys over screamingfrog maybe using some extra tool to create visual and nice internal linking maps? Looking at the Crawl Path Report links is hard for me. Im more of a visual guy.. Would appreciate if you could point me to any post or maybe personally you can recommend any thirdparty addon? Only thing I found was SF with nodeXL but its a darn .exe file http://www.stateofdigital.com/visualize-your-sites-internal-linking-structure-with-nodexl/
Hey Fixura,
Thanks for the cool comment.
We don’t actually create internal linking maps internally, but this is something we have discussed for a while. A way of visualising internal linking, alongside depth etc. It’s on the ‘todo’ list, but we haven’t quite got there yet! I’ve seen Gephi been used in a similar way – https://www.briggsby.com/how-visualize-open-site-explorer-data-in-gephi/
Cheers.
Dan
Cheers Dan!
Screaming Frog is definitely my number 1 tool. Makes audits so much easier!
Love all your top features in this tool. Here is one that I am missing. Perhaps I have missed how. I would like to be able to capture the charts and image graphs that screaming frog so nicely looks in the bottom rigthhand corner. I can save and export all kinds of data. Is it possible to save and use the images/charts/graphs in reports?
I’ve enjoyed using Screaming Frog, but I was wondering why there isn’t a web-based version. I often use a Chromebook at home and while traveling, and would like to be able to run crawls and reports on a non-Windows machine.
Hey Michael,
There isn’t a web based version currently I am afraid.
However, you can get it to run on your Chromebook using these tips – https://www.screamingfrog.co.uk/seo-spider/faq/#can-the-seo-spider-work-on-a-chromebook
Cheers.
Dan
Want to export the external links details along with the website URLs on which links are (inlinks ) – how to do that ?
Not getting the option .
Hi,
You can use the ‘bulk export > all outlinks’ report to do this.
When you have the spread sheet open, add a custom filter to the destination URL for ‘does not include’ yourdomain.com to just show outlinks to external sites.
Cheers.
Dan
Is there any way to crawl links embedded within javascript? I have a client who has hidden away a part of his website behind a map. You can click on an icon to show a location with a link. Google has been able to find those pages, but I’m wondering if I can crawl them with SF so I can get a more solid picture of the website structure and architecture. There are a significant number of pages (about 300-400) that I’m unable to examine efficiently.
Hey Brett,
This is an old post and we have introduced lots of new features since this was published. The SEO Spider can now render JavaScript, and we have a guide here –
https://www.screamingfrog.co.uk/crawl-javascript-seo/
Cheers
Dan
One of my many favorite features is in screaming frog is the the “GA & GSC Not Matched”. If you have configured “API Access” to “Google Analytics” and “Google Search Console”, then the GA & GSC Not Matched report will give you a list of your “Orphaned Pages”. This used to take a lot of manual work.
You may really be surprised by the pages that users are finding on your website. This report has allowed me to find pages on the website that the site owner should have redirected or removed 2 or 3 migrations ago.
FYI: Orphaned pages are those pages that have no internal links to them for any number of reasons. Keep in mind that some orphan pages are supposed to be that way, for example checkout pages of an eCommerce website or form conformation pages).
Perfect, thanks for the post. I didn’t know how to export crawl path (in links) for given URL. Now I know.
Great stuff Dan, we been using screaming frog for last 5month and we are well happy. Great price and quality. For future you could offer excel workbooks as additional stuff.
Thanks
M
Great list Dan !
And I thought I knew everything about the Screaming Frog Spider tool ;)
I love the crawl path report, as well as SERP snippet emulator features.
Hi,
Impossible to upload a XML file. Only files with “.seospider” extension are available with “File > Open”.
Or maybe I’m doing something wrong ?
Thank you !
Hi Pierre,
To crawl an XML sitemap file, you need to switch to list mode (mode > list), and then click ‘upload > from a file’, and choose ‘files of type’ as a ‘Sitemap.xml’.
Or, much quicker – You can just switch to list mode and click ‘download sitemap’ if it’s already live :-)
Cheers.
Dan
Crawling Authenticated Staging Sites
Very interesting feature, which we did not know before.
We have to test on new sites that are still without public access :)
Hi,
is it possible to generate a visual sitemap based on the paths of an url?
LG
Hey Tom,
Not yet, but we do have some visualisations on our ‘todo’.
Cheers.
Dan
Hi ,
How can we download the tree/folder structure report of a website?
Thanks for sharing the best SEO tool! For an effective SEO, we need a best tool that can minimize our efforts and maximize our productivity. Screaming frog is No.1 tools for SEO On-Page Work.
Hi..
How to download structure report ?
Thanks for sharing valuable information about features.
Hi Helly,
The ‘Site Structure’ tab data is just in the ‘Internal’ tab and ‘crawl depth’ column.
Thanks,
Dan
Can I Know how works SEO Spider?
Thank you for this article. Screaming frog seems awesome and I’ve been reading the features on your site about all I can do with it, definitely gonna give it a try.
Hi,
Thank you for this article.
Screamingfrog has a lot of useful features.
I’ve been using this and recommending it to people I train in my SEO courses. This is one heck of a tool, and 500 URLs tat the free version gives you is quite sufficient for most SEOs out there. Thanks for a bringing this to the community.
Recommended features: A spell check in the crawl and maybe a visual representation of the silo structures (both virtual and physical) if possible! Thanks :)
Crawling authenticated staging sites really saved me recently, had no idea this was available in Screaming Frog and was just about to launch a site. Did not want to crawl it live! Awesome tool guys, I was using Xenu for years lol..
Will the article be updated?
Good afternoon,
I am selecting the export option from the internal links report, and I see where the exported spreadsheet contains an inlink count number. Is there a way to export internal links, but have the actual inlink URL referenced along with the internal link instead of just the count? I am spending some time manually copying inlinks out of the report to associate them with other internal links and would like to streamline this process if possible.
Thanks!
Matt R.
Hi Matt,
You can use the ‘bulk export’ menu for exporting URLs with their ‘inlink’ data.
Cheers.
Dan
Thank you for this article. I use Screaming Frog few years, but SERP Mode and SERP Snippet I never used.
Screaming Frog has amazing SEO and development features. We can save a lot of time finding out website errors.
Thank you Dan, I love screaming frog <3
Hi Screaming Frog Gentleman, Is there a way to break my audit and export it to multiple CSV. files? I’ve crawled a very large site, so large that the excel file after exporting isn’t opening. What would be ideal is if I could export 50,000 URL’s at a time to different spreadsheets. Is this possible?
Great Article! I working with Screaming Frog everyday.
Thank You Dan!
Great article bro, i just started using the screaming frog for my seo journey. by far this is the best too which increased my productivity by reducing the time taking process like seo audits etc..
List mode is absolutely the best. Especially if you combine it with the extract function. You can easily search list of URLs for anything you want, which in turn really increases your productivity.
Highly recommend that combo.
The second point (Auditing Redirects In A Migration) is really good. Screaming Frog was a life saver (traffic saver actually :P) when we were doing migration 2 months ago. We realised we need to make redirects only after the migration, so SF let us do it quickly.
Thanks guys! :)
exceedingly helpful listing! thank you
screamingfrog is my favorite SEO tool :)
Crawl Path – i think it’s a most important function in all SF, that i’m using every time – it spares whole years with cheking “strange” URLs :)
For me useful tool is a List Mode – indispensable mode by all migrations or just checking new redirections
My favorite is “canonical errors”, I like “list mode” as well “Crawl Path”,
Other bullets- I just haven’t found it before and haven’t used it
the best feature: Auditing Redirects In A Migration
reason? big time saving
1 and 2 true life savers (and time) especially combined together. I don’t know how many times client/dev forgot to make some redirects despite the fact they were given a list of all urls or messed up something that already was fine.
Don’t know about you guys, but with big portals with more than a few thousands urls i like to make fast crawls with list mode for specific views to get a picture of some changes the client might forgot to mention. Not once or twice “someone” switched titles and descriptions to defaults.
Is there an option not to transfer subdomains in the generated site map in sf?
Wish I had seen this earlier, have been using screaming frog for years but have only just discovered these reports now, Thank you
Screaming frog. The Crawl Path Report the best function. Thank you for this report
List mode is absolutely the best. Especially if you combine it with the extract function. You can easily search a list of URLs for anything you want, which in turn really increases your productivity.
Highly recommend that combo.
Thank you, bro!
Started using Screaming Frog SEO Spider for a couple of days now, can’t imagine a life without it.
Didn’t know a couple of these features yet.
Thank you for this article.
I’ve been using Screaming Frog for years, and I didn’t know we could do much more. My favorite feature is the simple sitemap auditing process explained in the article. I am excited to use it in my next site audit report.