Screaming Frog SEO Spider Update – Version 11.0
Dan Sharp
Posted 5 March, 2019 by Dan Sharp in Screaming Frog SEO Spider
Screaming Frog SEO Spider Update – Version 11.0
We are delighted to announce the release of Screaming Frog SEO Spider version 11.0, codenamed internally as ‘triples’, which is a big hint for those in the know.
In version 10 we introduced many new features all at once, so we wanted to make this update smaller, which also means we can release it quicker. This version includes one significant exciting new feature and a number of smaller updates and improvements. Let’s get to them.
1) Structured Data & Validation
Structured data is becoming increasingly important to provide search engines with explicit clues about the meaning of pages, and enabling special search result features and enhancements in Google.
The SEO Spider now allows you to crawl and extract structured data from the three supported formats (JSON-LD, Microdata and RDFa) and validate it against Schema.org specifications and Google’s 25+ search features at scale.

To extract and validate structured data you just need to select the options under ‘Config > Spider > Advanced’.

Structured data itemtypes will then be pulled into the ‘Structured Data’ tab with columns for totals, errors and warnings discovered. You can filter URLs to those containing structured data, missing structured data, the specific format, and by validation errors or warnings.

The structured data details lower window pane provides specifics on the items encountered. The left-hand side of the lower window pane shows property values and icons against them when there are errors or warnings, and the right-hand window provides information on the specific issues discovered.
The right-hand side of the lower window pane will detail the validation type (Schema.org, or a Google Feature), the severity (an error, warning or just info) and a message for the specific issue to fix. It will also provide a link to the specific Schema.org property.
In the random example below from a quick analysis of the ‘car insurance’ SERPs, we can see lv.com have Google Product feature validation errors and warnings. The right-hand window pane lists those required (with an error), and recommended (with a warning).
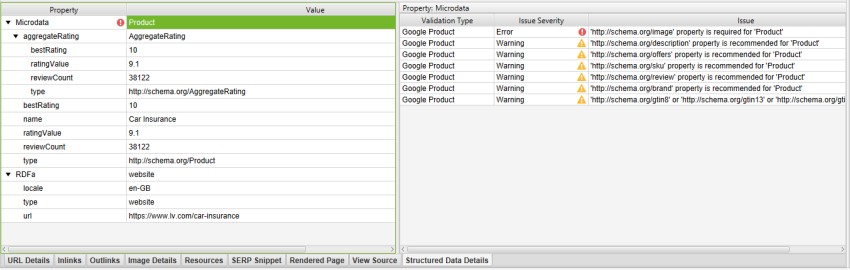
As ‘product’ is used on these pages, it will be validated against Google product feature guidelines, where an image is required, and there are half a dozen other recommended properties that are missing.
Another example from the same SERP, is Hastings Direct who have a Google Local Business feature validation error against the use of ‘UK’ in the ‘addressCountry‘ schema property.
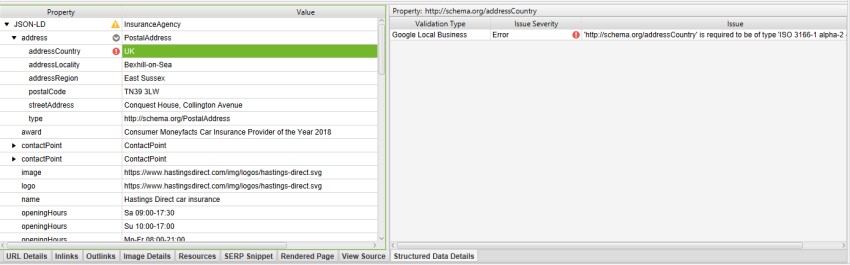
The right-hand window pane explains that this is because the format needs to be two-letter ISO 3166-1 alpha-2 country codes (and the United Kingdom is ‘GB’). If you check the page in Google’s structured data testing tool, this error isn’t picked up. Screaming Frog FTW.
The SEO Spider will validate against 26 of Google’s 28 search features currently and you can see the full list in our structured data section of the user guide.
As many of you will be aware, frustratingly Google don’t currently provide an API for their own Structured Data Testing Tool (at least a public one we can legitimately use) and they are slowly rolling out new structured data reporting in Search Console. As useful as the existing SDTT is, our testing found inconsistency in what it validates, and the results sometimes just don’t match Google’s own documented guidelines for search features (it often mixes up required or recommended properties for example).
We researched alternatives, like using the Yandex structured data validator (which does have an API), but again, found plenty of inconsistencies and fundamental differences to Google’s feature requirements – which we wanted to focus upon, due to our core user base.
Hence, we went ahead and built our own structured data validator, which considers both Schema.org specifications and Google feature requirements. This is another first to be seen in the SEO Spider, after previously introducing innovative new features such as JavaScript Rendering to the market.
There are plenty of nuances in structured data and this feature will not be perfect initially, so please do let us know if you spot any issues and we’ll fix them up quickly. We obviously recommend using this new feature in combination with Google’s Structured Data Testing Tool as well.
2) Structured Data Bulk Exporting
As you would expect, you can bulk export all errors and warnings via the ‘reports’ top-level menu.
The ‘Validation Errors & Warnings Summary’ report is a particular favourite, as it aggregates the data to unique issues discovered (rather than reporting every instance) and shows the number of URLs affected by each issue, with a sample URL with the specific issue. An example report can be seen below.
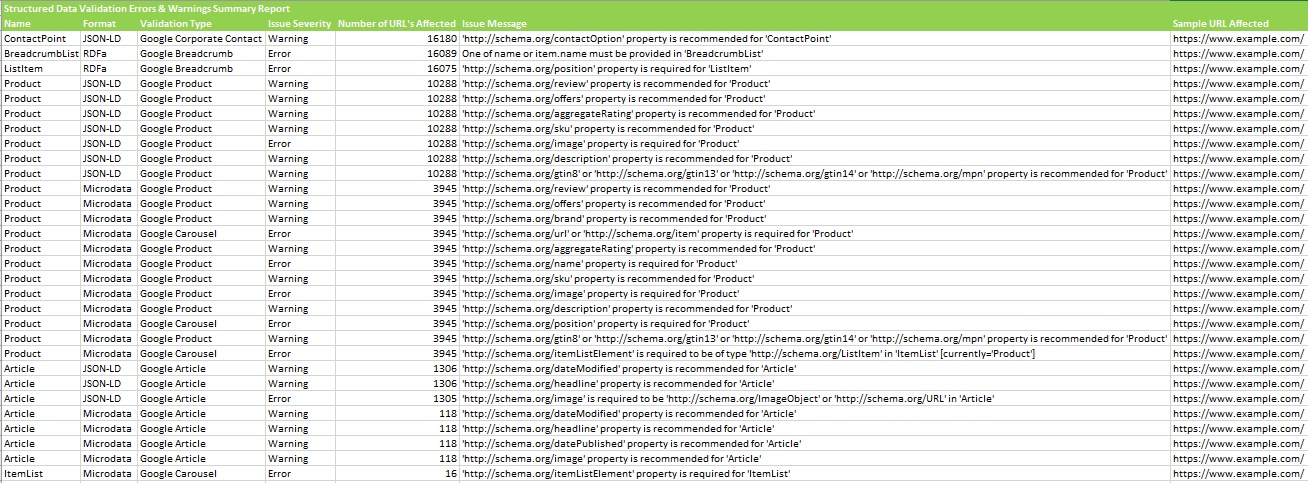
This means the report is highly condensed and ideal for a developer who wants to know the unique validation issues that need to be fixed across the site.
3) Multi-Select Details & Bulk Exporting
You can now select multiple URLs in the top window pane, view specific lower window details for all the selected URLs together, and export them. For example, if you click on three URLs in the top window, then click on the lower window ‘inlinks’ tab, it will display the ‘inlinks’ for those three URLs.
You can also export them via the right click or the new export button available for the lower window pane.
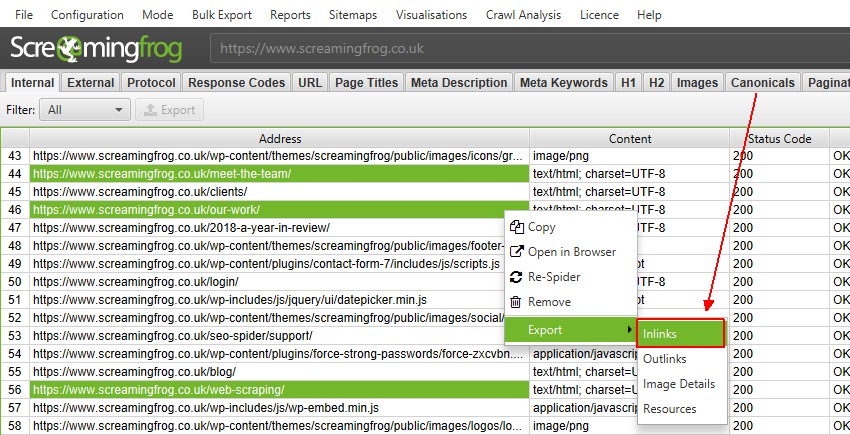
Obviously this scales, so you can do it for thousands, too.
This should provide a nice balance between exporting everything in bulk via the ‘Bulk Export’ menu and then filtering in spreadsheets, or the previous singular option via the right click.
4) Tree-View Export
If you didn’t already know, you can switch from the usual ‘list view’ of a crawl to a more traditional directory ‘tree view’ format by clicking the tree icon on the UI.
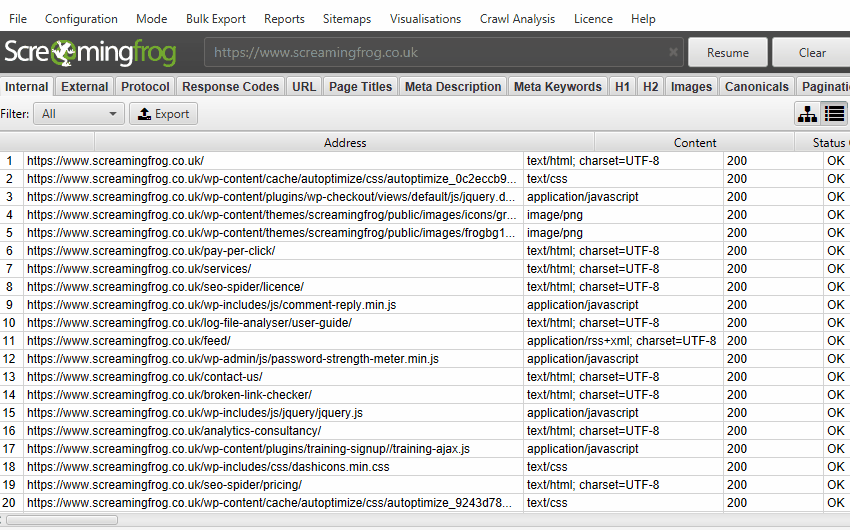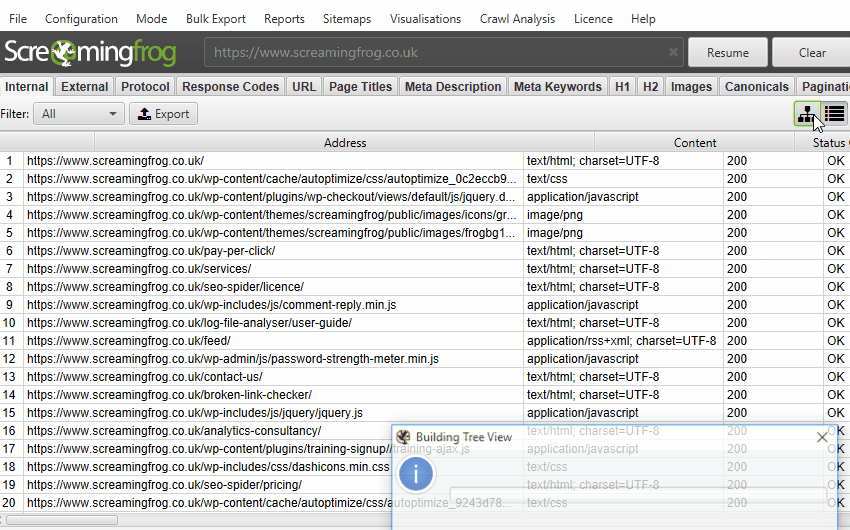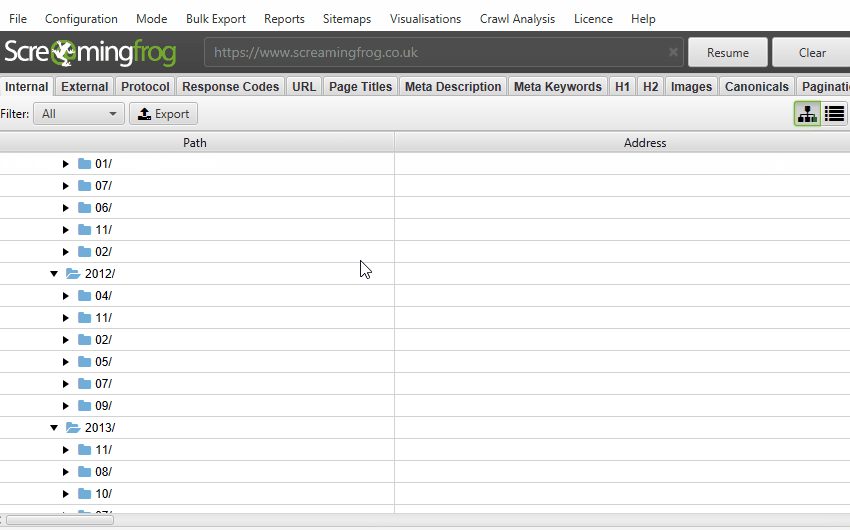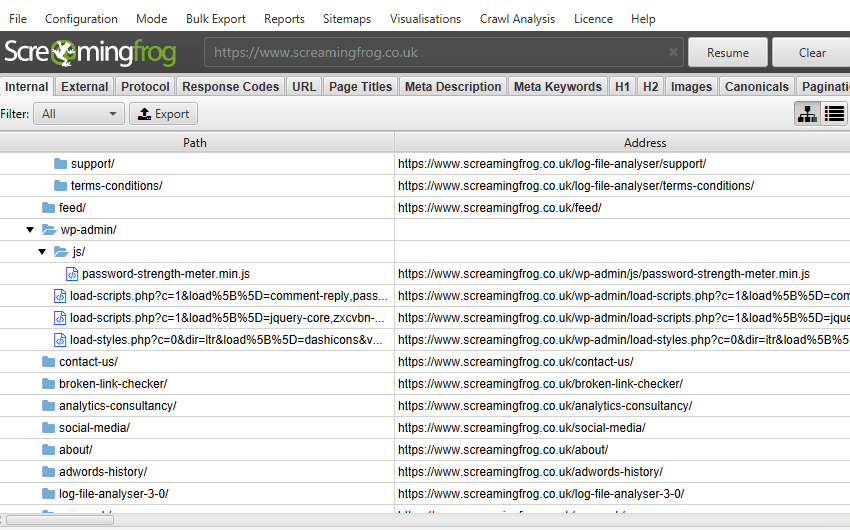
However, while you were able to view this format within the tool, it hasn’t been possible to export it into a spreadsheet. So, we went to the drawing board and worked on an export which seems to make sense in a spreadsheet.
When you export from tree view, you’ll now see the results in tree view form, with columns split by path, but all URL level data still available. Screenshots of spreadsheets generally look terrible, but here’s an export of our own website for example.
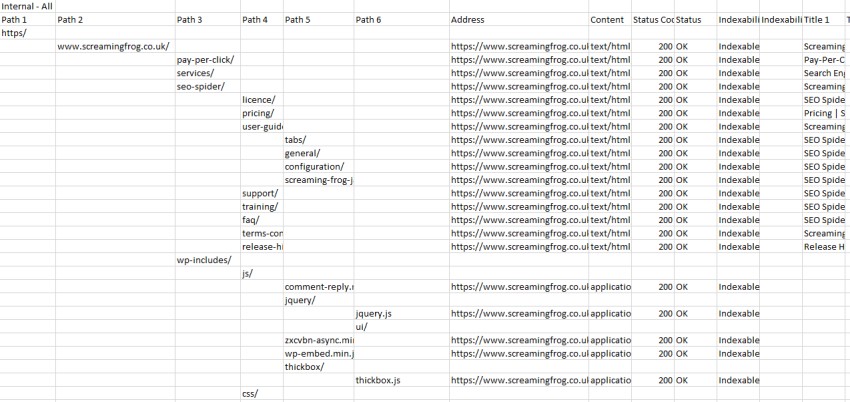
This allows you to quickly see the break down of a website’s structure.
5) Visualisations Improvements
We have introduced a number of small improvements to our visualisations. First of all, you can now search for URLs, to find specific nodes within the visualisations.
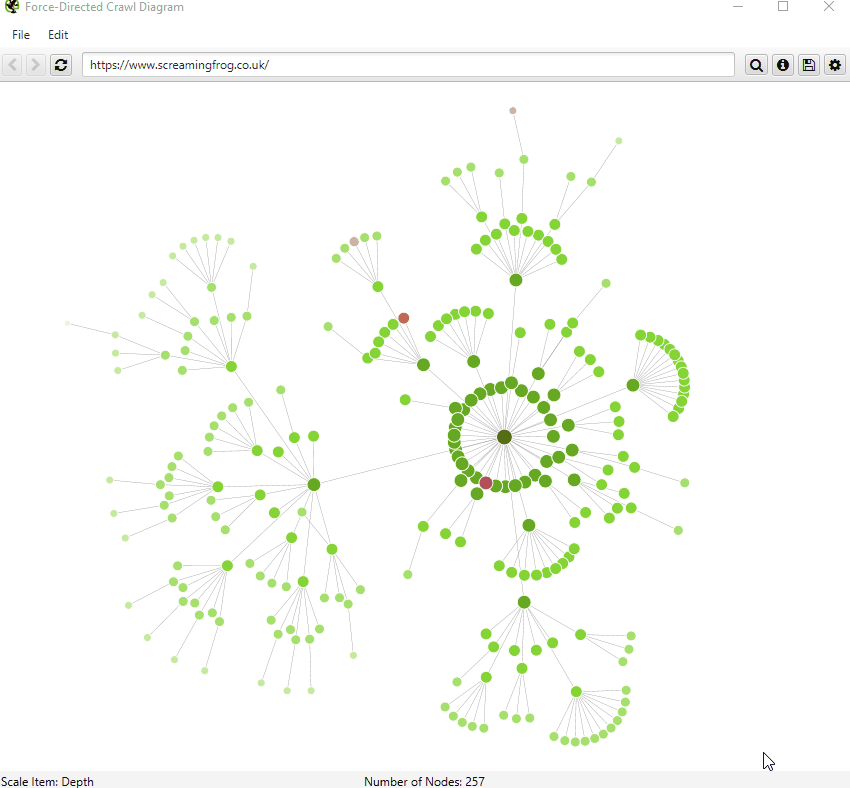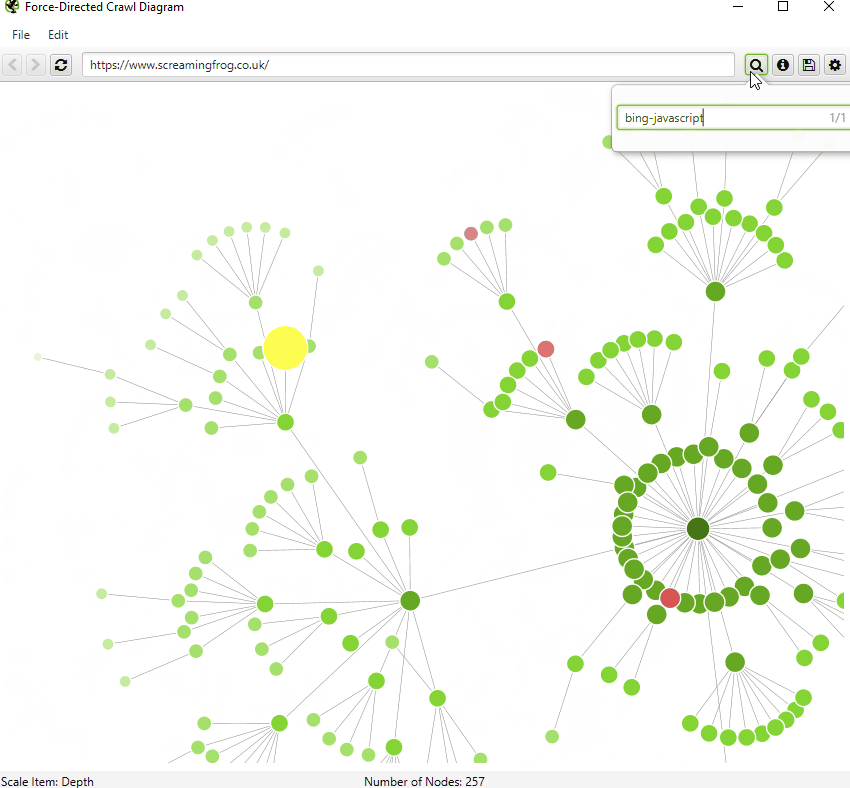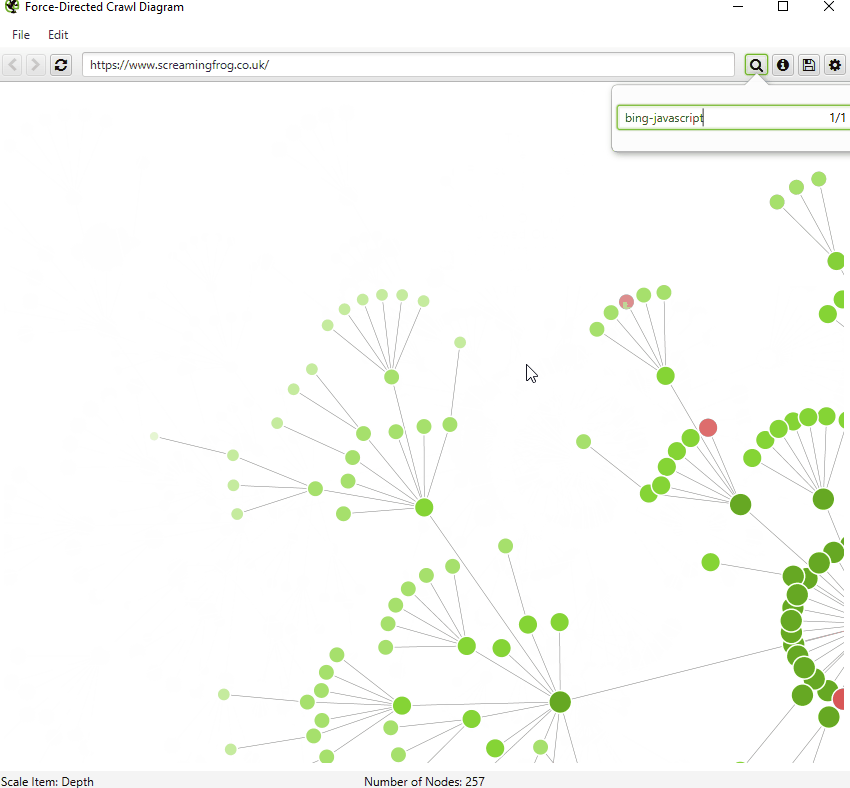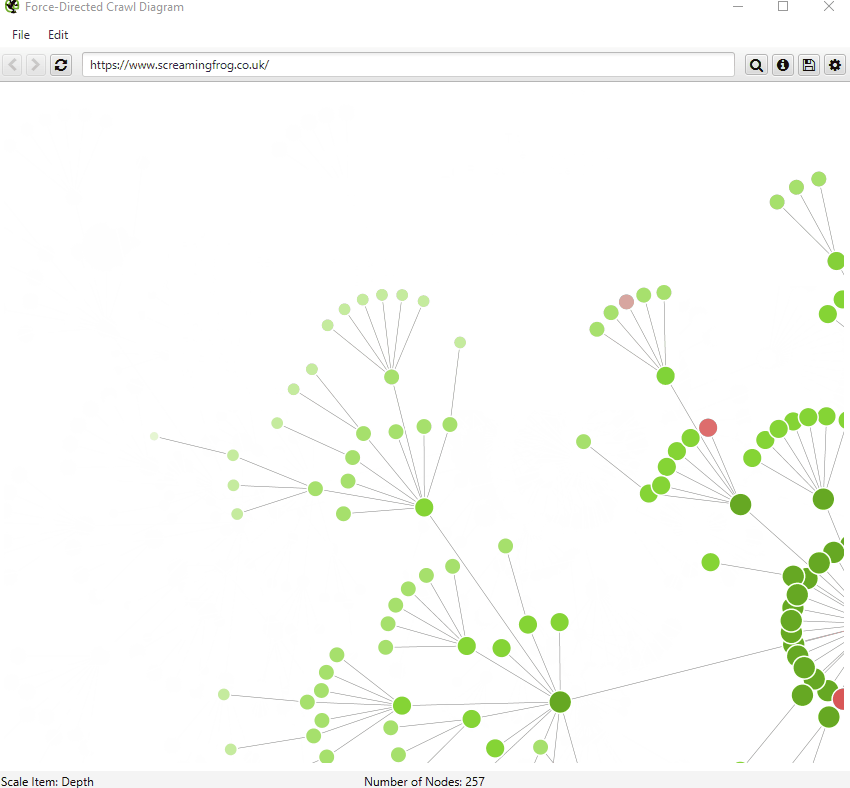
By default, the visualisations have used the last URL component for naming of nodes, which can be unhelpful if this isn’t descriptive. Therefore, you’re now able to adjust this to page title, h1 or h2.
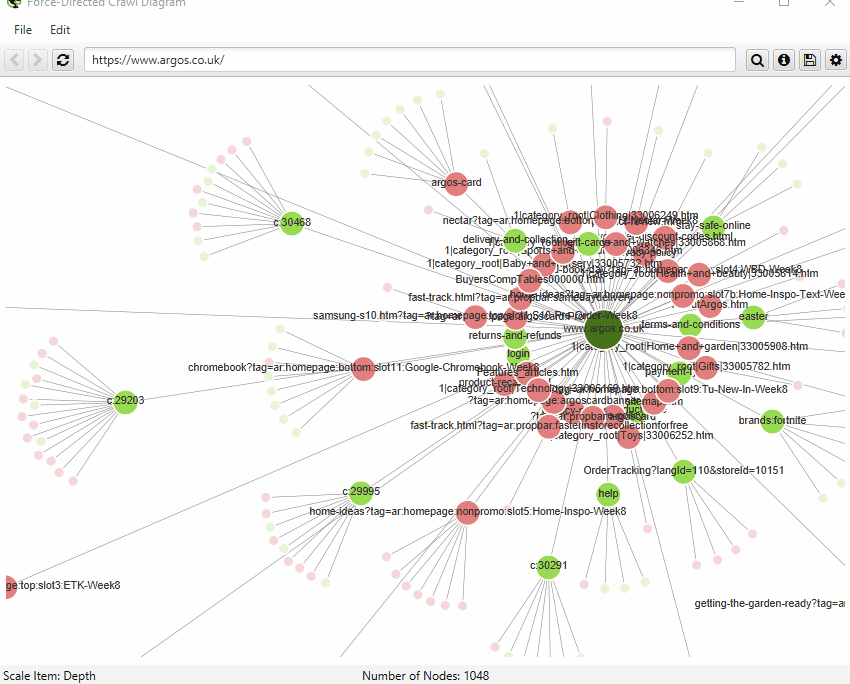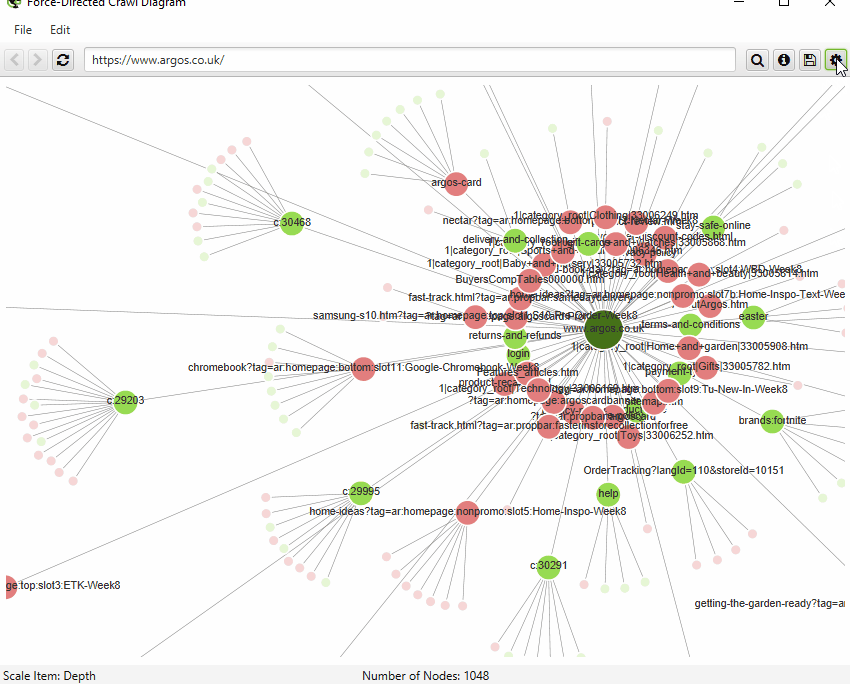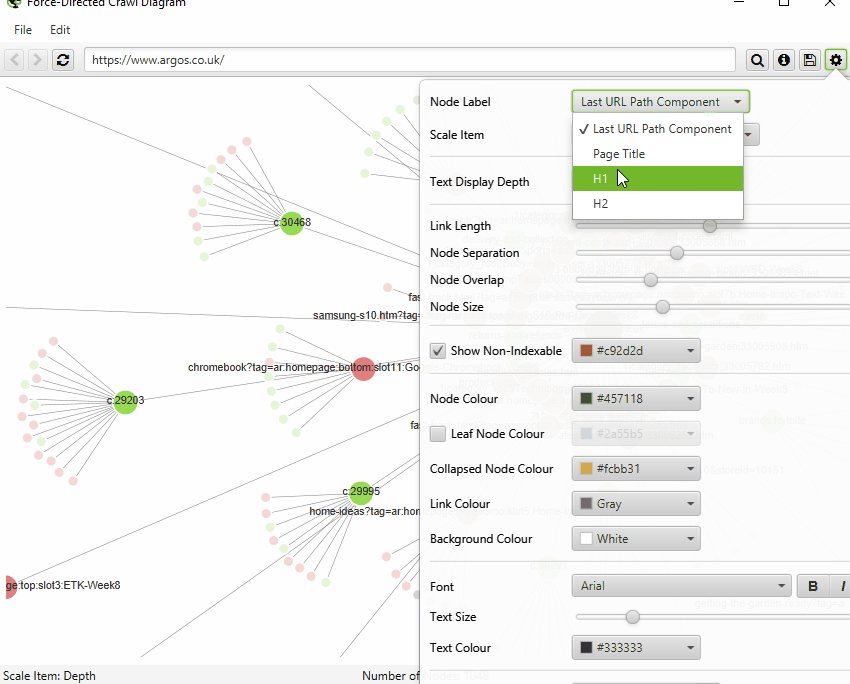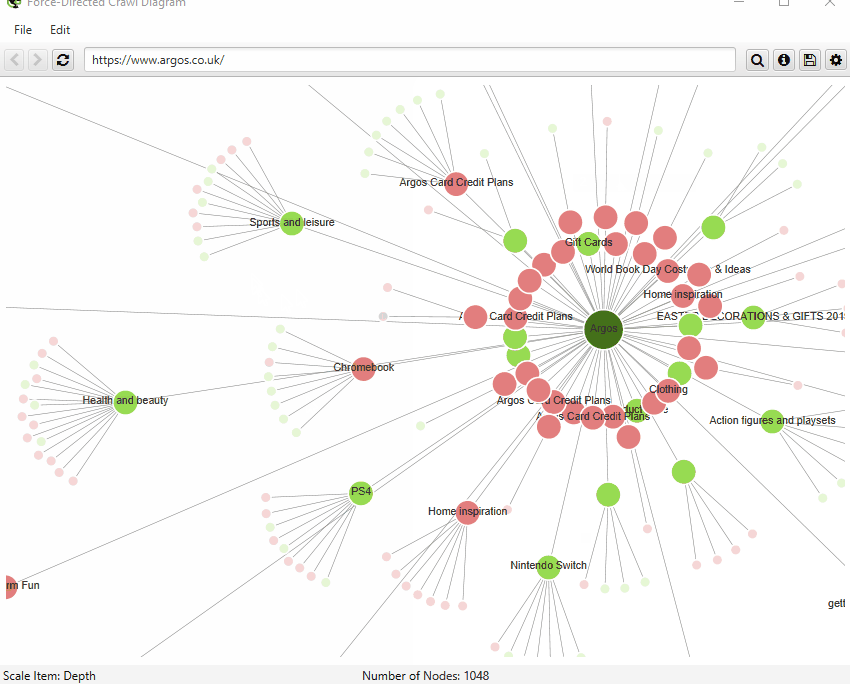
Finally, you can now also save visualisations as HTML, as well as SVGs.
6) Smart Drag & Drop
You can drag and drop any file types supported by the SEO Spider directly into the GUI, and it will intelligently work out what to do. For example, you can drag and drop a saved crawl and it will open it.
You can drag and drop a .txt file with URLs, and it will auto switch to list mode and crawl them.
You can even drop in an XML Sitemap and it will switch to list mode, upload the file and crawl that for you as well.
Nice little time savers for hardcore users.
7) Queued URLs Export
You’re now able to view URLs remaining to be crawled via the ‘Queued URLs’ export available under ‘Bulk Export’ in the top level menu.

This provides an export of URLs discovered and in the queue to be crawled (in order to be crawled, based upon a breadth-first crawl).
8) Configure Internal CDNs
You can now supply a list of CDNs to be treated as ‘Internal’ URLs by the SEO Spider.
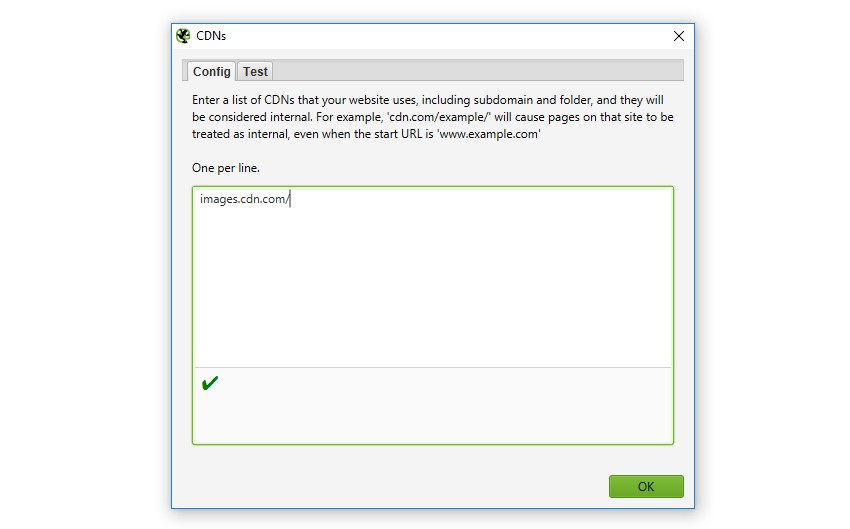
This feature is available under ‘Configuration > CDNs’ and both domains and subfolder combinations can be supplied. URLs will then be treated as internal, meaning they appear under the ‘Internal’ tab, will be used for discovery of new URLs, and will have data extracted like other internal URLs.
9) GA Extended URL Matching
Finally, if you have accounts that use extended URL rewrite filters in Google Analytics to view the full page URL (and convert /example/ to www.example.com/example) in the interface, they break what is returned from the API, and shortcuts in the interface (i.e they return www.example.comwww.example.com/example).
This means URLs won’t match when you perform a crawl obviously. We’ve now introduced an algorithm which will take this into account automatically and match the data for you, as it was really quite annoying.
Other Updates
Version 11.0 also includes a number of smaller updates and bug fixes, outlined below.
- The ‘URL Info’ and ‘Image Info’ lower window tabs has been renamed from ‘Info’ to ‘Details’ respectively.
- ‘Auto Discover XML Sitemaps via robots.txt’ has been unticked by default for list mode (it was annoyingly ticked by default in version 10.4!).
- There’s now a ‘Max Links per URL to Crawl’ configurable limit under ‘Config > Spider > Limits’ set at 10k max.
- There’s now a ‘Max Page Size (KB) to Crawl’ configurable limit under ‘Config > Spider > Limits’ set at 50k.
- There are new tool tips across the GUI to provide more helpful information on configuration options.
- The HTML parser has been updated to fix an error with unquoted canonical URLs.
- A bug has been fixed where GA Goal Completions were not showing.
That’s everything. If you experience any problems with the new version, then please do just let us know via support and we can help. Thank you to everyone for all their feature requests, bug reports and general support, Screaming Frog would not be what it is, without you all.
Now, go and download version 11.0 of the Screaming Frog SEO Spider.
Small Update – Version 11.1 Released 13th March 2019
We have just released a small update to version 11.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Add 1:1 hreflang URL report, available under ‘Reports > Hreflang > All hreflang URLs’.
- Cleaned up the preset user-agent list.
- Fix issue reading XML sitemaps with leading blank lines.
- Fix issue with parsing and validating structured data.
- Fix issue with list mode crawling more than the list.
- Fix issue with list mode crawling of XML sitemaps.
- Fix issue with scheduling UI unable to delete/edit tasks created by 10.x.
- Fix issue with visualisations, where the directory tree diagrams were showing the incorrect URL on hover.
- Fix issue with GA/GSC case insensitivty and trailing slash options.
- Fix crash when JavaScript crawling with cookies enabled.
Small Update – Version 11.2 Released 9th April 2019
We have just released a small update to version 11.2 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Update to schema.org 3.5 which was released on the 1st of April.
- Update splash screen, so it’s not always on top and can be dragged.
- Ignore HTML inside amp-list tags.
- Fix crash in visualisations when focusing on a node and using search.
- Fix issue with ‘Bulk Export > Queued URLs’ failing for crawls loaded from disk.
- Fix issue loading scheduling UI with task scheduled by version 10.x.
- Fix discrepancy between master and detail view Structured Data warnings when loading in a saved crawl.
- Fix crash parsing RDF.
- Fix ID stripping issue with Microdata parsing.
- Fix crashing in Google Structured Data validation.
- Fix issue with JSON-LD parse errors not being shown for pages with multiple JSON-LD sections.
- Fix displaying of Structured Data values to not include escape characters.
- Fix issue with not being able to read Sitemaps containing a BOM (Byte Order Mark).
- Fix Forms based Authentication so forms can be submitted by pressing enter.
- Fix issue with URLs ending ?foo.xml throwing off list mode.
- Fix GA to use URL with highest number of sessions when configuration options lead to multiple GA URLs matching.
- Fix issue opening crawls via .seospider files with ++ in their file name.
Small Update – Version 11.3 Released 30th May 2019
We have just released a small update to version 11.3 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Added relative URL support for robots.txt redirects.
- Fix crash importing crawl file as a configuration file.
- Fix crash when clearing config in SERP mode
- Fix crash loading in configuration to perform JavaScript crawling on a platform that doesn’t support it.
- Fix crash creating images sitemap.
- Fix crash in right click remove in database mode.
- Fix crash in scheduling when editing tasks on Windows.
- Fix issue with Sitemap Hreflang data not being attached when uploading a sitemap in List mode.
- Fix configuration window too tall for small screens.
- Fix broken FDD HTML export.
- Fix unable to read sitemap with BOM when in Spider mode.






Hi There
Just a quick question, if i can see the structured data errors in screaming frog, how can i fix them?
Cheers Puneet
Great update! The structured data validation is really helpful. Thanks for the update.
THX FOR ALL!!!
Great update! Really love that we can multi-select URLs and bulk export now.
The structured data tool got my hopes up and it’s not perfect sadly! Don’t get me wrong… I think that you have launched an amazing tool and I love the improvements you made. However, when I launch the tool, I get many warnings and issues that don’t exist in the Structured Data Testing Tool and vice-versa. I am not sure that I am ready to trust this report at scale in its present form… (Note: I only got these inconsistencies with the JobPosting JSON Structured Data).
Hi Jean-Christophe,
Thanks for your comment, but there will be differences between the two validators.
For a start, we do lots of validations Google don’t do, and I am sure there will be subtleties we haven’t got completely correct with a new feature too.
As outlined above, from the huge amount of testing we performed when building the tool, Google’s SDTT does not get it right all the time, and often mixes up issues from their own documentation :-) It’s built by a developer that reviewed their docs (like we did) afterall.
So, I don’t think you should be immediately distrusting due to the above, I’d recommend analysing the issues reported to see what is accurate, and using it to compliment your auditing process :-)
We link you to the Schema.org guidelines, and Google have amazing documentation on their search features for required and recommended properties. It’s often as simple as reviewing them, and I plan on writing up a guide on the process we use for this!
If there are any that you’re unsure of, would like a second opinion, or if you spot any bugs, please just fire them through to us via support.
Cheers.
Dan
Hi Dan.
There are some really good validations and I will fix as many as possible.
Only there are many “Errors” that are not markedup as RDFa at all.
rel=”canonical”
rel=”alternate”
rel=”nofollow”
rel=”stylesheet”
…
When I’m making a list, the pattern is clear.
BUG: All valid html rel attributes are reported as RDFa Schema.org Error.
Hey Marco,
Awesome to hear! Do you mind popping over any example URLs via [email protected]?
We’ll get anything fixed up!
Cheers.
Dan
Super, I was waiting for such an update!
That’s really nice. You guys did great work. I will recommend this to my friends too.
Just wanted to say thanks guys for another brilliant update! Love how much work you put into this and how you continuously add really useful functionality. My personal favourites are the visualisation improvements and GA Extended URL Matching. Will give it a go today.
Hi Kerstin,
Thanks so much for the kind comments.
Glad you’re enjoying the visualisations and GA Extended URL Matching updates, the latter in particular was such a frustrating one sometimes, we had to find a solution.
Cheers.
Dan
Hi!
I noticed what seem to be an issue with the list mode-crawl.
The crawl depth option is set to zero and greyed out in the Config menu, but the crawler still follows links – so the list mode crawl behaves just like a normal crawl.
I had to manually check the crawl depth option and set it to zero to get the desired result.
Cheers!
//Lucas, Sweden
Hey Lucas,
When you’re in list mode, if you go to ‘File > Config > Clear Default Config’, and then crawl, does that solve the issue as well?
Cheers.
Dan
Hi Dan!
Yes, that also did the trick.
When looking under Config > Spider > Limits the “Limit crawl depth” is ticked and set to zero, i.e. the same thing I had to do manually to get it to work earlier.
So I guess the problem lies in the Default Config for list mode?
Cheers
Lucas
If you do the same in Spider mode, that should fix it as well.
Essentially, each mode can have a different saved config if that makes sense.
If you reset both, they should then be default (which is no crawl depth set for ‘Spider’ mode, and 0 crawl depth for ‘list’ mode).
If that’s not the case, can you let me know? Sorry that’s been a pain!
Cheers.
Dan
Great new features – thanks! Only downside: All my carefully adjusted settings for columns in each view are gone. Completely gone :-(
In this update, when the site map is loaded via the Download Sitemap imdex tab, the incomplete URLs list is now loaded.
The xml-sitemap contains 28357 URLs, and only 7791 are loaded.
In the previous version, the xml-sitemap was fully loaded.
Why is this happening?
Hey Ivan,
Pop through your example to us, and we can take a look – https://www.screamingfrog.co.uk/seo-spider/support/
Cheers.
Dan
I think I understood exactly how wrong SEO Spider is reading xml-sitemap with several pages.
If the xml-sitemap of the domain. com /sitemap.xml contains, suppose three pages (sitemap.xml?page=1, sitemap.xml?page=2, sitemap.xml?page=3), the SEO Spider will only read links from the third page of the sitemap, while these links will be collected on three.
I think it is worth checking whether this is so.
Thanks, Ivan.
Are you able to send in your real world example? That’s always super useful for us, and it would be appreciated.
Cheers.
Dan
This can be seen on the sitemap of healthline .com/sitemap.xml
Since there are 4 pages, SEO Spider will check only the fourth page of hlan.xml and each link from it will be collected 4 times.
Hi Ivan,
Thanks for sharing. We’ve had a look, and it sounds like a known bug we’ve fixed up.
We’re planning a new beta tomorrow, if you’re interested in using it, pop us an email via support.
Thanks again for providing more detail.
Cheers.
Dan
Great update !
Hello,
Following this update, the Mode List now is crawling the full website and not only the ones from the list. Bug?
Hi Laurence,
As per the comment above, please go to ‘File > Config > Clear Config’ when you’re in list mode.
This will resolve the issue!
Cheers.
Dan
Very cool, good to see improvements every now and then!
Makes it so much easier to identify the SEO potential of a website.
Have you been thinking of adding more than 10 extractors and scheduling a crawl based on a sitemap URL?
Tnks!
You do not plan to translate the program into other languages?
Screaming Frog thanks for comprehensive guide of update, necessary! Greets
Your piece of software is becoming more powerful time, thanks for the great work!
One question though, since I have just tested the structed data validation tool: many properties are considered invalid when I use the “Google Validation” type, whereas when I test through the Google structured data testing web interface (https://search.google.com/structured-data/testing-tool) , it just looks good (no warning, no errors). Is the API used more restrictive?
Hi Adrien,
Yeah, as above, we find errors (as per Google’s documentation), that they don’t.
When this occurs, I’d suggest reviewing the specific feature documentation from Google and you should see, that we are accurate.
Any questions or if you want a second opinion, pop through to us via support.
Cheers.
Dan
ottimo lavoro!!
Validating the structured data is little crucial. I hope this update will simplify everything.
Thank you for sharing such an awesome post screaming frog!
Great updates! Looking forward to checking out the Schema crawling and validation.
What I would love to see in future versions is a “Export and open” option besides the existing Export button. I hate having to go dig up the file.
Would also be idea if there were some way to automatically format the resulting export file to be an Excel Table, with certain columns hidden or deleted, other columns filtered (by Indexation Status, for example) and columns added (I always add 3: LEN, Page Type and Actions)
Lastly, I typically use the crawl to build a “Page Inventory” pivot table off of. Wish there was a way to help with that process. As it requires a lot of manual categorization of pages into “Blog”, “Product”, “Company”, etc page types, I realize it’s unlikely but still nice to dream.
Please apologize for my bad english. I have just tried the free version and am very surprised about the many features! I first have to familiarize myself with the program, but I am already excited. Many Thanks!
Thank you for the structured data feature – much anticipated :)
I just updated from 10.4 to 11.3, and SF won’t crawl anything other than the URL I put in. I downgraded back to 10.4 and the crawl works correctly. Any idea what’s going on?
Hi Nikki,
It could be a configuration issue, so I’d recommend going to ‘File > Config > Clear’ after installing 11.3 and seeing if that helps.
If not, have a look at the status code and status when you crawl, as this will provide a hint (https://www.screamingfrog.co.uk/http-status-codes-when-crawling/).
If the above doesn’t help, get in touch with us via support – https://www.screamingfrog.co.uk/seo-spider/support/
Thanks,
Dan
Hi! Can you add support robot.txt directive “clean-param” for yandex bot? (Work like “Configure URL parameters” in Search Console. it may be also useful for Google if it is configured).
Great update! Great work.
In the past few months I have not been able to test the update.
Today I installed it again on a new laptop and it’s fantastic.
Merit burden.
Grande Screaming Frog … one of the most useful tools for SEO.
Thanks again.
Oh God, this update is fantastic. Great guys, keep it up, now yours is the best SEO spider
Feature request: Allow for bulk exporting of Structured Data Details.
This would help when auditing large sets of URLs to determine if dynamic schema implementations are working as intended. Often this sort of thing doesn’t result in an error or warning necessarily, but it doesn’t mean it’s accurate either.
Thanks!
Hey Jerod,
Thanks for the request.
Does ‘Bulk Export > Contains Structured Data’ do what you need? :-)
Cheers.
Dan
Great update!
Do you have a link or a site (in french) for tutorials on screamingfrog, which explain the tools
Thanks
Finally crawling and extracting structured data from JSON-LD format. Thanks a lot. This is what Iwas looking for. Schema is such an important factor these days.
you are right
Great update. SEO Spider is more powerful and useful tool now. Is it possible to create other language versions? Thank you for the good work!
Great update! Thank you for the good work! :))
A huge Screaming Frog fan for years… the improvements to the SEO visualization nodes are very cool!